1 Unsupervised Learning Enemble Methods 1 Unsupervised Learning -- Ana Fred Outline Partitional Methods : K-Means : Spectral Clustering : EM-based Gaussian Mixture Decomposition Part 3.: Validation of clustering solutions Cluster Validity Measures Part 4.: Ensemble Methods Basic Formulation Evidence Accumulation Clustering Multi-Criteria EAC From Single Clustering to Ensemble Methods - April 2009 Unsupervised Learning Enemble Methods 2 Unsupervised Learning -- Ana Fred Clustering is a Challenging Research Field Clustering is a difficult problem: clusters can have different : Shapes : Sizes : Data sparseness : Degree of separation : Noise : Types of data From Single Clustering to Ensemble Methods - April 2009
Transcript
1
Unsupervised Learning Enemble Methods
1
Unsupervised Learning -- Ana Fred
Outline
Partitional Methods
: K-Means
: Spectral Clustering
: EM-based Gaussian Mixture Decomposition
Part 3.: Validation of clustering solutions
Cluster Validity Measures
Part 4.: Ensemble Methods
Basic Formulation
Evidence Accumulation Clustering
Multi-Criteria EAC
From Single Clustering to Ensemble Methods - April 2009
Unsupervised Learning Enemble Methods
2
Unsupervised Learning -- Ana Fred
Clustering is a Challenging Research Field
Clustering is a difficult problem: clusters can have different
: Shapes
: Sizes
: Data sparseness
: Degree of separation
: Noise
: Types of data
From Single Clustering to Ensemble Methods - April 2009
2
Unsupervised Learning Enemble Methods
3
Unsupervised Learning -- Ana Fred
Clustering Ensembles: Motivation
Clustering is a difficult problem: clusters can have different shapes,
size, data sparseness, degree of separation and noise.
No single clustering algorithm can adequately handle all types of
cluster shapes and structures.
Each clustering algorithm addresses differently issues of cluster
validity, number of clusters, and structure imposed on the data.
Different data partitions are produced by different algorithms.
A single clustering algorithm can produce distinct results on the
same data set due to dependency on initialization.
From Single Clustering to Ensemble Methods - April 2009
Unsupervised Learning Enemble Methods
4
Unsupervised Learning -- Ana Fred
Clustering Ensembles: Motivation
Clustering results on the same data using different algorithms with
different parameters
Single-Link
t=.55
Single-Link
nc=8
K-Means
K=8
Complete-Link
nc=8
From Single Clustering to Ensemble Methods - April 2009
3
Unsupervised Learning Enemble Methods
5
Unsupervised Learning -- Ana Fred
Clustering Ensembles: Motivation
Clustering is a difficult problem: clusters can have different shapes,
size, data sparseness, degree of separation and noise.
No single clustering algorithm can adequately handle all types of
cluster shapes and structures.
Each clustering algorithm addresses differently issues of cluster
validity, number of clusters, and structure imposed on the data.
Different data partitions are produced by different algorithms.
A single clustering algorithm can produce distinct results on the
same data set due to dependency on initialization.
For a given data,
. How to choose an appropriate algorithm?
. How to interpret different partitions produced by different
clustering algorithms?
From Single Clustering to Ensemble Methods - April 2009
Unsupervised Learning Enemble Methods
6
Unsupervised Learning -- Ana Fred
Clustering Ensembles and Ensemble Methods
Clustering Ensemble:
Ensemble methods:
: Combination of data partitions produced by multiple algorithms or
data representations, trying to benefit from the strengths of each
algorithm, with the objective of producing a better solution than the
individual clusterings.
},...,,{ 21 NPPP
iiK
i nCCCCP #},,,,{ 21
EAC
From Single Clustering to Ensemble Methods - April 2009
4
Unsupervised Learning Enemble Methods
7
Unsupervised Learning -- Ana Fred
Combining Data Partitions:
Evidence Accumulation Clustering (EAC)
[Fred, MCS 2001] A. Fred, “Finding Consistent Clusters in Data Partitions”, in Multiple Classifier Systems, J. Kittler and F. Roli (Eds), vol LNCS 2096, pp 309-318. Springer, 2001.
[Fred & Jain, SSPR 2002] A. Fred and A. K. Jain, “Evidence Accumulation Clustering based on the K-Means Algorithm”, in SSPR 2002.
[Fred & Jain, CVPR 2003] A. Fred and A. K. Jain, “Robust Data Clustering”, in CVPR 2003.
[Fred & Jain, TPAMI 2005] A. Fred and A. K. Jain, “Combining Multiple Clusterings Using Evidence Accumulation”, IEEE Trans. PAMI, Vol 27, No 6, 2005.
[Lourenço & Fred, WACV 2005] A. Lourenço and A. Fred, “Ensemble Methods in the Clustering of String Patterns”, in WACV 2005.
[Fred & Jain, ICPR 2006] A. Fred and A. K. Jain, “Learning Pairwise Similarity for Data Clustering”, in ICPR 2006.
Evidence Accumulation using a voting mechanism on pairs of patterns
From Single Clustering to Ensemble Methods - April 2009
Unsupervised Learning Enemble Methods
8
Unsupervised Learning -- Ana Fred
Combining Data Partitions: Related Work
A. Strehl and J. Gosh, “Cluster Ensembles – a Knowledge Reuse
Framework for Combining Multiple Partitions”. In Proc. AAAI 2002,
Edmonton. AAAI/MIT Press, July 2002.
: Consensus clustering: find the K-cluster consensus data
partition
: Propose three combination mechanisms:
. Hyper-graph-partitioning algorithm (HPGA)
. Meta-clustering algorithm (MCLA)
. Explores pairwise similarities (CSPA)
Topchy, Jain and Punch, “A Mixture Model of Clustering Ensembles”. In
Proc. SIAM Conf. on Data Mining, 2004.
: Probabilistic model of the consensus partition in the space
of clusterings (EM)
From Single Clustering to Ensemble Methods - April 2009
5
Unsupervised Learning Enemble Methods
9
Unsupervised Learning -- Ana Fred
Combining Data Partitions: Related Work
Hyper-graphs
: Vertices: samples
: Hyper-graph – each cluster links a set of vertices
Strehl e Ghosh, 2002
From Single Clustering to Ensemble Methods - April 2009
Unsupervised Learning Enemble Methods
10
Unsupervised Learning -- Ana Fred
Combining Data Partitions: Related Work
The clustering Ensemble is mapped into a hyper-graph
Heuristics for obtaining a consensus data partition:
From Single Clustering to Ensemble Methods - April 2009
6
Unsupervised Learning Enemble Methods
11
Unsupervised Learning -- Ana Fred
Combining Data Partitions: Related Work
Multinomial Mixtures –EM
yl
N
j
j
mlj
j
mmlm yPyP1
)()(||
jK
k
ky
jm
j
mlj
j
m kyP1
),()()(|
Topchy, Jain, Punch, 2004
K
m
mlmml yPyP1
|)|( l(1) l(2) l(3) l(4)
x1 1 2 1 1
x2 1 2 1 2
x3 1 2 2 1
x4 2 3 2 1
x5 2 3 3 2
x6 3 1 3 3
x7 3 1 3 2
From Single Clustering to Ensemble Methods - April 2009
Unsupervised Learning Enemble Methods
12
Unsupervised Learning -- Ana Fred
Objectives
Given X, a set of n objects or patterns, and N different partitions of
X, called a clustering ensemble P ={P1, P2, …, PN} , produce a
partition P* which is the result of a combination of the N
partitions in P. Ideally, P* should satisfy the following properties:
i. Consistency with the clustering ensemble P -- the combined data partition P* should somehow agree with the individual partitions P1
ii. Robustness to small variations in P -- the number of clusters in P*, as well as the cluster membership of the patterns in P*, should not change significantly with small perturbations in P
iii. Goodness of fit with ground truth information -- P* should be consistent with external cluster labels, or with perceptual evaluation of the data.
From Single Clustering to Ensemble Methods - April 2009
7
Unsupervised Learning Enemble Methods
13
Unsupervised Learning -- Ana Fred
Evidence Accumulation Clustering (EAC)
Combine the results of multiple clusterings into a single data
partition by viewing each clustering result as an independence
evidence of data organization
Steps:
1. Produce a clustering ensemble
2. Combine Evidence
3. Extract the final data partition
From Single Clustering to Ensemble Methods - April 2009
Unsupervised Learning Enemble Methods
14
Unsupervised Learning -- Ana Fred
Step 1: How to Produce Clustering Ensembles ?
Produce a clustering ensemble by either:
: Choice of data representation or by perturbing the data
(subspaces, bootstrapping, boosting)
: Choice of clustering algorithms or algorithmic parameters
. Combine results of different clustering algorithms
. Running a given algorithm many times with different parameters or
initializations
. Run the K-means algorithm N times using k randomly initialized clusters
centers.
– K - fixed
– K - randomly chosen within a range [kmin, kmax]
. Run spectral clustering with different k values and scale parameters s
. Run different algorithms
. Use different dissimilarity measures
1 2, , , NP P P P=
From Single Clustering to Ensemble Methods - April 2009
8
Unsupervised Learning Enemble Methods
15
Unsupervised Learning -- Ana Fred
EAC
Clustering
Ensemble(Individual
Partitions)
The labeling in partition induces a 0-1 similarity measure
between patterns, represented by the co-association matrix
1 if patterns and co-exists in the same cluster of
,0 otherwise
l
l i j Pi j
C
lP
From Single Clustering to Ensemble Methods - April 2009
Unsupervised Learning Enemble Methods
16
Unsupervised Learning -- Ana Fred
EAC
Clustering
Ensemble(Individual
Partitions)
The labeling in partition induces a 0-1 similarity measure
between patterns, represented by the co-association matrix
1 if patterns and co-exists in the same cluster of
,0 otherwise
l
l i j Pi j
C
lP
From Single Clustering to Ensemble Methods - April 2009
9
Unsupervised Learning Enemble Methods
17
Unsupervised Learning -- Ana Fred
Step 2: Combining Evidence:
Voting Mechanism => New Similarity Matrix
Clustering
Ensemble(Individual
Partitions)
Sample i
Sample j
Sample k
Sample l
Sample m
Sample p
Co-association
matrix
Evidence
Accumulation
1
,
, ,
Nl
ijl
i jn
i jN N
C
CCo-association
matrix
- the number of times the pattern pair (i,j) is assigned to the same cluster among the N clusterings
ijn
From Single Clustering to Ensemble Methods - April 2009
Unsupervised Learning Enemble Methods
18
Unsupervised Learning -- Ana Fred
Step 3: Extract the Final Data Partition
The co-association matrix can be seen as representing a
graph, with nodes corresponding to patterns and edges expressing
similarity between pattern pairs.
The combined data partition is obtained by applying some
clustering algorithm to this co-association matrix. Examples shown
use the Single Link algorithm (SL) and other hierarchical
agglomerative clustering methods.
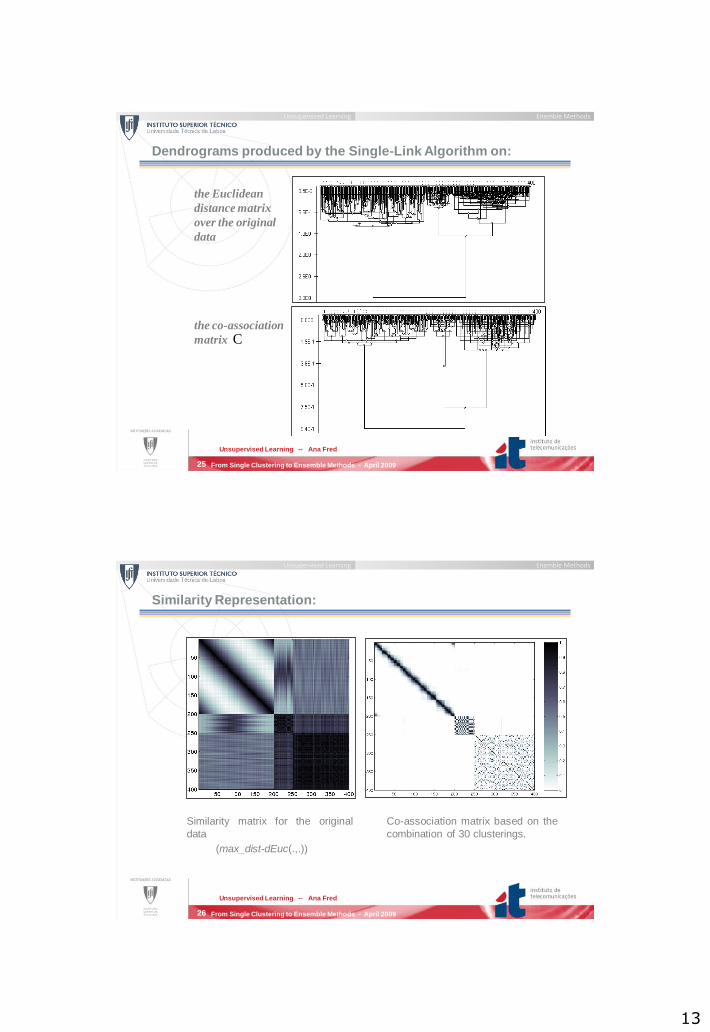
We define lifetime of a k-cluster partition as the absolute difference
between its birth and merge thresholds on the dendrogram
produced by the SL algorithm.
The final data partition is chosen as the one with the highest
lifetime.
C
From Single Clustering to Ensemble Methods - April 2009
10
Unsupervised Learning Enemble Methods
19
Unsupervised Learning -- Ana Fred
K-Means based Evidence Accumulation Clustering
Producing the clustering ensemble:
: Run the K-means algorithm N times using k randomly
initialized clusters centers.
- K - fixed
- K - randomly chosen within a range [kmin, kmax]
Single run of K-Means
: Dependence on initialization
: Spherically shaped clusters
: k known a priori
From Single Clustering to Ensemble Methods - April 2009
Unsupervised Learning Enemble Methods
20
Unsupervised Learning -- Ana Fred
K-Means Based Evidence Accumulation Clustering (KM-EAC)
Split-and-merge approach:
: Split: Decompose multidimensional data into a large number, k, of
small, “spherical” clusters using K-means. Run K-means algorithm
N times with random seeds.
. K - fixed
. K - randomly chosen within a range [kmin, kmax]
: Merge: Combine N data partitions into a new similarity or
co-association matrix between patterns, [C(i,j)]
: Find “consistent” clusters using the Single Link (SL) technique on
the co-association matrix, C.
Detects arbitrary shaped clusters
,
, (# times and, in the same cluster) =i j
i j i jn
C i j nN
From Single Clustering to Ensemble Methods - April 2009
11
Unsupervised Learning Enemble Methods
21
Unsupervised Learning -- Ana Fred
-20 -10 0 10 20-15
-10
-5
0
5
10
15
-20 -10 0 10 20-15
-10
-5
0
5
10
15
-20 -10 0 10 20-15
-10
-5
0
5
10
15
-20 -10 0 10 20-15
-10
-5
0
5
10
15
Data set
K-means K-means K-means
K=25 K=11 K=30
1P 2P NP
...
...
Clustering
Ensemble
Step 1
From Single Clustering to Ensemble Methods - April 2009
Unsupervised Learning Enemble Methods
22
Unsupervised Learning -- Ana Fred
-20 -10 0 10 20-15
-10
-5
0
5
10
15
-20 -10 0 10 20-15
-10
-5
0
5
10
15
-20 -10 0 10 20-15
-10
-5
0
5
10
15K-means K-means K-means
K=25 K=11 K=30
1P 2P NP
...
...
-20 -10 0 10 20-15
-10
-5
0
5
10
15
1C 2C NC
-20 -10 0 10 20-15
-10
-5
0
5
10
15
-20 -10 0 10 20-15
-10
-5
0
5
10
15
...
12
Unsupervised Learning Enemble Methods
23
Unsupervised Learning -- Ana Fred
+...
-20 -10 0 10 20-15
-10
-5
0
5
10
15
Combine evidence:
Co-Association Matrix
C
Graph associated
with the co-association
matrix C
-20 -10 0 10 20-15
-10
-5
0
5
10
15
1C 2C NC
-20 -10 0 10 20-15
-10
-5
0
5
10
15
-20 -10 0 10 20-15
-10
-5
0
5
10
15
...
From Single Clustering to Ensemble Methods - April 2009
Step 2
Unsupervised Learning Enemble Methods
24
Unsupervised Learning -- Ana Fred
-20 -10 0 10 20-15
-10
-5
0
5
10
15
Combined
Data Partition
Dendrogram
Given by the
Single-Link
Algorithm
: -cluster partition lifetimekl k
-20 -10 0 10 20-15
-10
-5
0
5
10
15
C
From Single Clustering to Ensemble Methods - April 2009
13
Unsupervised Learning Enemble Methods
25
Unsupervised Learning -- Ana Fred
Dendrograms produced by the Single-Link Algorithm on:
the Euclidean
distance matrix
over the original
data
the co-association
matrix C
From Single Clustering to Ensemble Methods - April 2009
Unsupervised Learning Enemble Methods
26
Unsupervised Learning -- Ana Fred
Similarity matrix for the original
data
Co-association matrix based on the
combination of 30 clusterings.
(max_dist-dEuc(.,.))
Similarity Representation:
From Single Clustering to Ensemble Methods - April 2009
14
Unsupervised Learning Enemble Methods
27
Unsupervised Learning -- Ana Fred
-20 -10 0 10 20-15
-10
-5
0
5
10
15
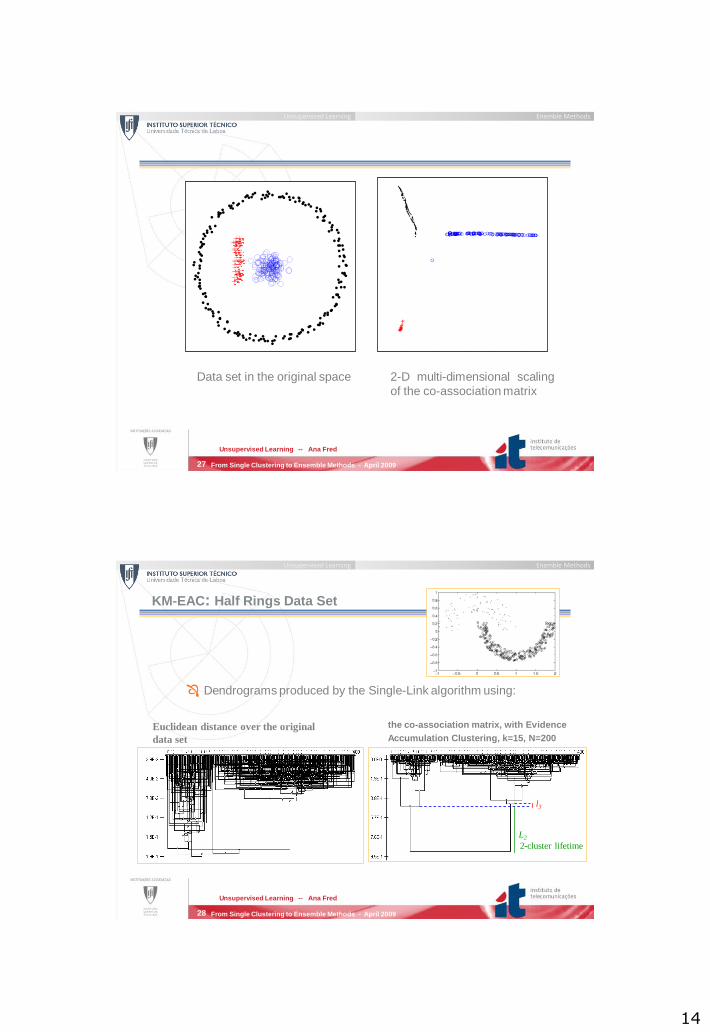
Data set in the original space 2-D multi-dimensional scaling
of the co-association matrix
From Single Clustering to Ensemble Methods - April 2009
Unsupervised Learning Enemble Methods
28
Unsupervised Learning -- Ana Fred
KM-EAC: Half Rings Data Set
Dendrograms produced by the Single-Link algorithm using:
Euclidean distance over the original
data set
the co-association matrix, with Evidence
Accumulation Clustering, k=15, N=200
L2
2-cluster lifetime
l3
From Single Clustering to Ensemble Methods - April 2009
15
Unsupervised Learning Enemble Methods
29
Unsupervised Learning -- Ana Fred
KM-EAC: Half Rings Data Set - fixed k
Evidence Accumulation Clusteringk=80, N=200
Evidence Accumulation Clusteringk=5, N=200
From Single Clustering to Ensemble Methods - April 2009
Unsupervised Learning Enemble Methods
30
Unsupervised Learning -- Ana Fred
KM-EAC: Half Rings Data Set - variable k
[2;20]k [2;80]k
• More Robust •
From Single Clustering to Ensemble Methods - April 2009
16
Unsupervised Learning Enemble Methods
31
Unsupervised Learning -- Ana Fred
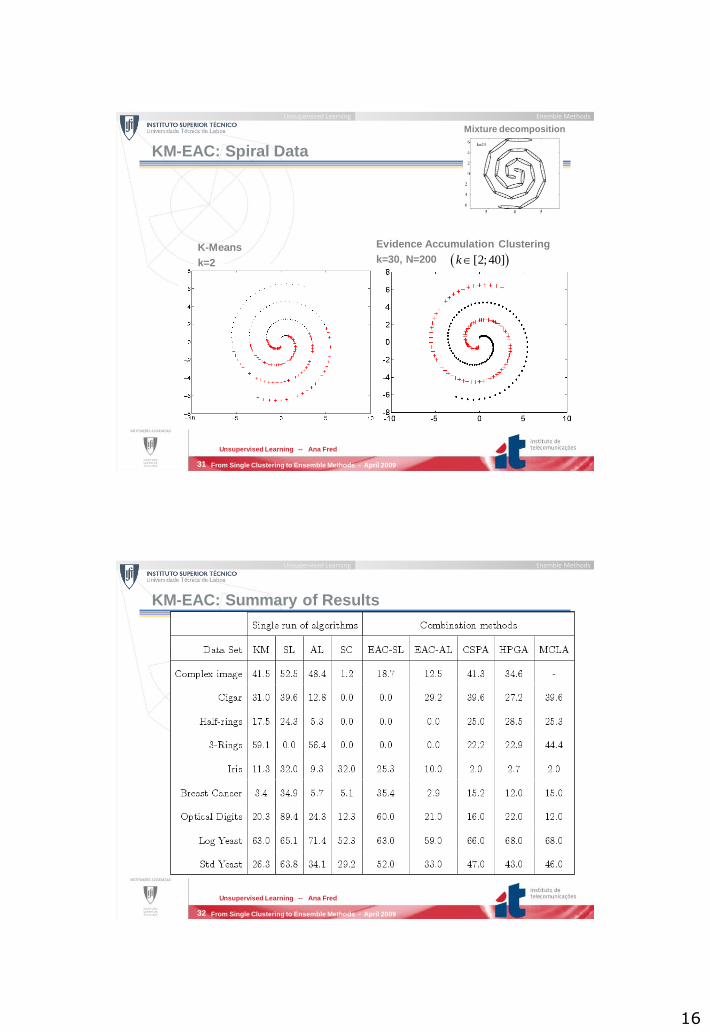
KM-EAC: Spiral Data
Evidence Accumulation Clustering
k=30, N=200K-Means
k=2 [2;40]k
Mixture decomposition
From Single Clustering to Ensemble Methods - April 2009
Unsupervised Learning Enemble Methods
32
Unsupervised Learning -- Ana Fred
KM-EAC: Summary of Results
From Single Clustering to Ensemble Methods - April 2009
17
Unsupervised Learning Enemble Methods
33
Unsupervised Learning -- Ana Fred
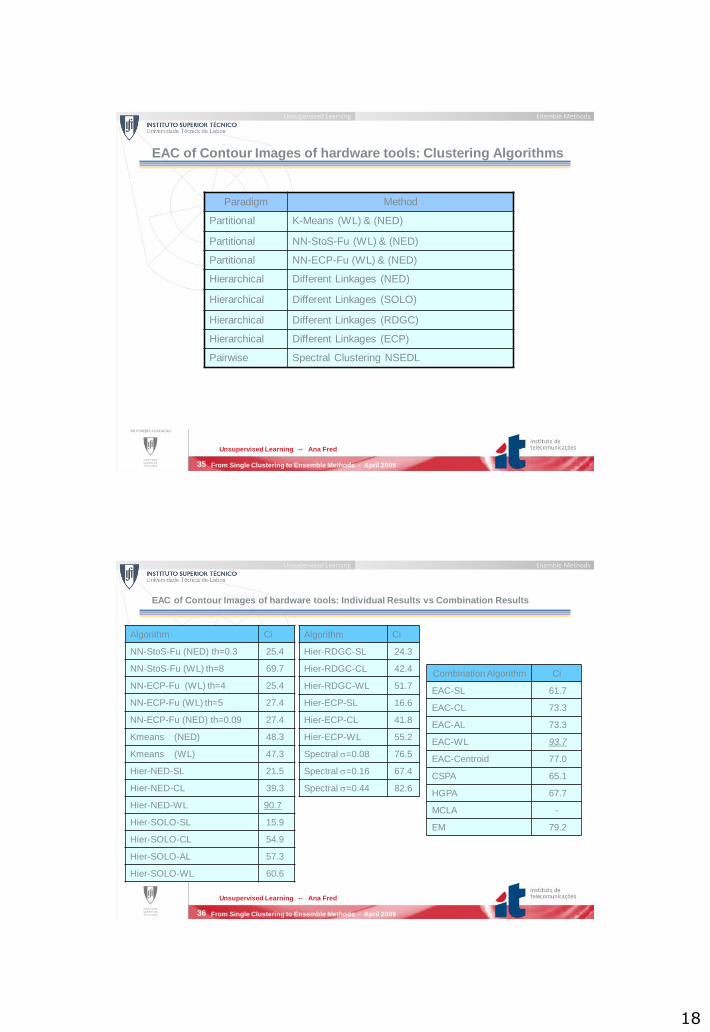
EAC of Contour Images of hardware tools
The data set is composed by 634 contour images of 15 types of
hardware tools: t1 to t15.
When counting each pose as a distinct sub-class in the object type,
we obtain a total of 24 classes.
From Single Clustering to Ensemble Methods - April 2009
Unsupervised Learning Enemble Methods
34
Unsupervised Learning -- Ana Fred
EAC of Contour Images of hardware tools: Proximity Measures
From Single Clustering to Ensemble Methods - April 2009
Unsupervised Learning Enemble Methods
46
Unsupervised Learning -- Ana Fred
Illustrative Example
From Single Clustering to Ensemble Methods - April 2009
24
Unsupervised Learning Enemble Methods
47
Unsupervised Learning -- Ana Fred
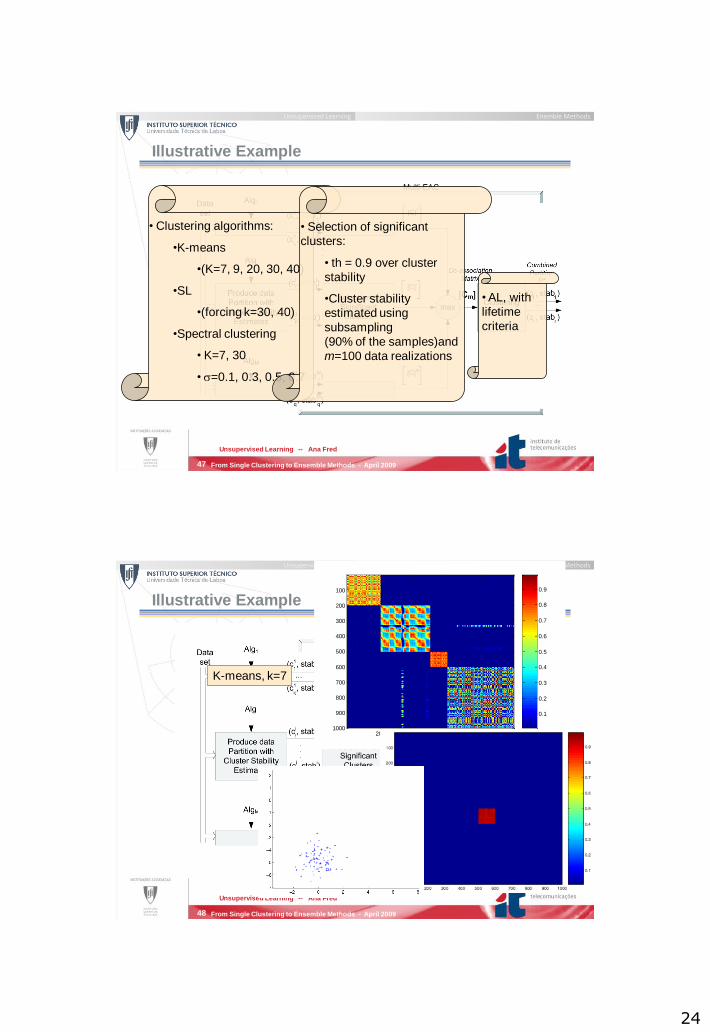
Illustrative Example
• Clustering algorithms:
•K-means
•(K=7, 9, 20, 30, 40)
•SL
•(forcing k=30, 40)
•Spectral clustering
• K=7, 30
• s=0.1, 0.3, 0.5, 0.7
• Selection of significant
clusters:
• th = 0.9 over cluster
stability
•Cluster stability
estimated using
subsampling
(90% of the samples)and
m=100 data realizations
• AL, with
lifetime
criteria
From Single Clustering to Ensemble Methods - April 2009
Unsupervised Learning Enemble Methods
48
Unsupervised Learning -- Ana Fred
Illustrative Example
200 400 600 800 1000
100
200
300
400
500
600
700
800
900
1000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
K-means, k=7
From Single Clustering to Ensemble Methods - April 2009
25
Unsupervised Learning Enemble Methods
49
Unsupervised Learning -- Ana Fred
Illustrative Example
SL, k=30
200 400 600 800 1000
100
200
300
400
500
600
700
800
900
1000
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
From Single Clustering to Ensemble Methods - April 2009
Unsupervised Learning Enemble Methods
50
Unsupervised Learning -- Ana Fred
Illustrative Example
K-means, k=7
From Single Clustering to Ensemble Methods - April 2009
26
Unsupervised Learning Enemble Methods
51
Unsupervised Learning -- Ana Fred
Illustrative Example
Similarity matrix from Euclidean distance
Co-association matrix produced by EAC technique
Learned co-association matrix
From Single Clustering to Ensemble Methods - April 2009
Unsupervised Learning Enemble Methods
52
Unsupervised Learning -- Ana Fred
Experimental Results – UCI repository
Clustering Algorithms
Cluster stability: m = 100; subsampling (90% of samples)
Cluster selection: threshold is initially set at 0.95 and automatically
adjusted based on % of unassigned patterns
. if the learned similarity matrix has more than 10% samples unassigned, the threshold is lowered by 0.05 steps, until a 90% coverage of the data is achieved or when the threshold reaches levels below 0.75
From Single Clustering to Ensemble Methods - April 2009
27
Unsupervised Learning Enemble Methods
53
Unsupervised Learning -- Ana Fred
Experimental Results – UCI repository
* clusters in final partition have average stability below .75
Clustering Ensembles: K-means, SL
EAC Multi-EAC
Classification accuracy (%)
(k-known)
Classification accuracy (%)
(k-unknown)
Synthetic 84.8 99.4
Iris 68.7 88.7
Breast-Cancer 65.4 96.2
Optidigits 30.6 76.5
Log-yeast 35.2 35.2*
Std-yeast 36.2 34.4*
From Single Clustering to Ensemble Methods - April 2009
Unsupervised Learning Enemble Methods
54
Unsupervised Learning -- Ana Fred
Multi-EAC Remarks
A cluster ensemble approach to learn pairwise similarity
Introduced a stability measure for the selection of meaningful
clusters by individual clustering algorithms in the ensemble
The proposed approach estimates the pairwise similarity without a
priori information about the number of clusters or other user-
specified parameters – a parameter free solution
Experimental results show that the learned similarity is able to
reveal the underlying clustering structure in many datasets
From Single Clustering to Ensemble Methods - April 2009