21
Artificial Artificial Intelligence Intelligence Methods Methods Neural Networks Neural Networks Lecture 4 Lecture 4 Rakesh K. Bissoondeeal Rakesh K. Bissoondeeal
| Date post: | 31-Dec-2015 |
| Category: |
Documents |
| Upload: | valencia-cruz |
| View: | 21 times |
| Download: | 0 times |

Artificial Intelligence Artificial Intelligence Methods Methods
Neural NetworksNeural NetworksLecture 4Lecture 4
Rakesh K. BissoondeealRakesh K. Bissoondeeal

Learning in Multilayer Networks Learning in Multilayer Networks
Backpropagation LearningBackpropagation Learning
A Multi-Layer neural network trained using the Backpropagation learning algorithm is one of the most powerful forms of supervised neural network system.
The training of such a network involves three stages: 1) the feedforward of the input training pattern, 2) the calculation and backpropagation of the associated error, 3) and the adjustment of the weights.

Architecture of NetworkArchitecture of Network
In a typical Multilayer network, the input units (Xi) are fully connected to all hidden layer units (Yj) and the hidden layer units are fully connected to all output layer units (Zk).

Architecture of NetworkArchitecture of Network Each of the connections
between the input to hidden and hidden to output layer units has an associated weight attached to it (Wij or Vij).
The hidden and output
layer units also receive signals from weighted connections (bias) from units whose values are always 1.

Architecture of NetworkArchitecture of Network Activation Functions The choice of activation function to use in a backpropagation network is limited to functions that are continuous, differentiable and monotonically non-decreasing. Furthermore, for computational efficiency, it is desirable that its derivative is easy to compute. Usually the function is also expected to saturate, i.e. approach finite maximum and minimum values asymptotically.
One of the most typical activation functions used is the binary sigmoidal function:
f(x) = 1 . 1 + exp(-x)
where the derivative is given by: f ’(x) = f(x)[1 - f(x)]

Backpropagation Learning Backpropagation Learning AlgorithmAlgorithm
During the feedforward phase, each of the input units (Xi) is set to its given input pattern value
Xi = input[i]
Each input unit is then multiplied by the weight of its connection. The weighted inputs are then fed into the hidden units (Y1 to Yj).
Each hidden unit then sums the incoming signals and applies an activation function to produce an output.
Yj = f( bj + XiWij)

Backpropagation Learning Backpropagation Learning AlgorithmAlgorithm
Each of the outputs of the hidden units is then multiplied by the weight of its connection and the weighted signals are fed into the output units (Z1 - Zk).
Each output unit then sums the incoming signals from the hidden units and applies an activation function to form the response of the net for a given input pattern.
Zk = f( bk + YjVjk)

Backpropagation Learning Backpropagation Learning AlgorithmAlgorithm
Backpropagation of errorsBackpropagation of errors
During training, each output unit then compares its output (Zk) with the required target value (dk) to determine the associated error for that pattern. Based on this error, a factor k is computed that is used to distribute the error at Zk back to all units in the previous layer.
k = f ’(Zk)(dk - Zk)
Each hidden unit then computes a similar factor j that is a weighted sum of all the backpropagated delta terms from units in the previous layer multiplied by the derivative of the activation function for that unit.
j = f ’(Yj) k Vjk

Weight adjustmentWeight adjustment After all the delta terms have been calculated, each hidden
and output layer unit updates its connection weights and bias weights accordingly.
Output layer:bk(new) = bk(old) + k Vjk(new) = Vjk(old) + k Yj
Hidden Layer: bj(new) = bj(old) + j Wij(new) = Wij(old) + j Xi
Where is a learning rate coefficient that is given a value between 0 and 1 at the start of training.

Test stopping conditionTest stopping condition After each epoch of training (one epoch = one cycle
through the entire training set) the performance of the network is measured by computing the average (Root Mean Square(RMS)) error of the network for all of the patterns in the training set and for all of the patterns in a validation set. These two sets being disjoint.
Training is terminated when the RMS value for the training set is continuing to decrease but the RMS value for the validation set is starting to increase. This prevents the network from being OVERTRAINED (i.e. memorising the training set) and ensures that the ability of the network to GENERALISE (i.e. correctly classify non-trained patterns) will be at its maximum.
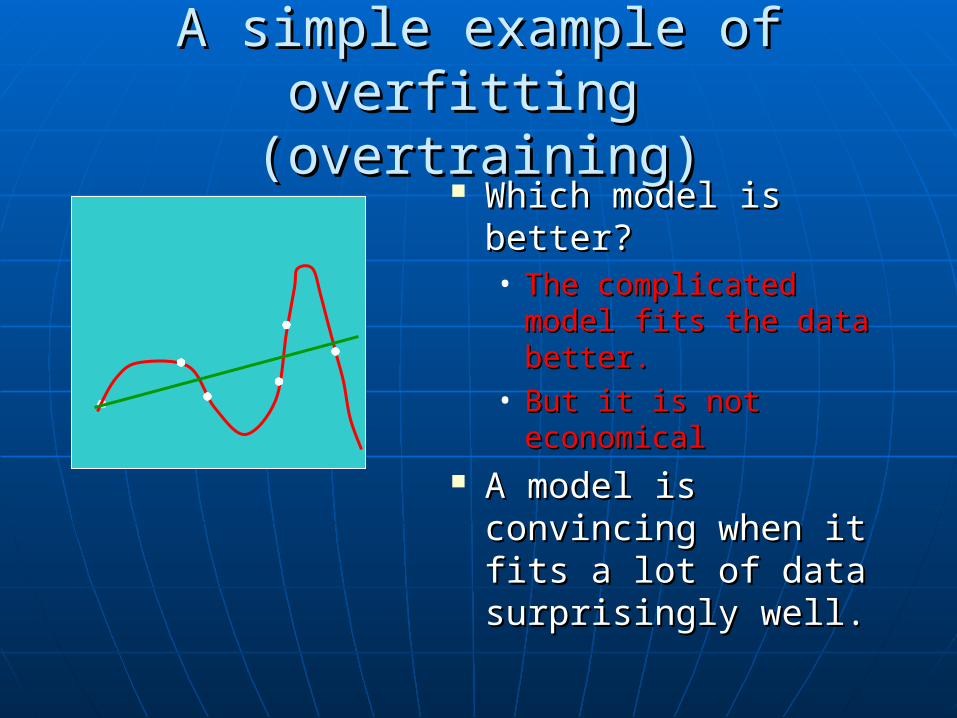
A simple example of overfitting A simple example of overfitting (overtraining)(overtraining)
Which model is Which model is better?better?• The complicated The complicated
model fits the data model fits the data better.better.
• But it is not But it is not economicaleconomical
A model is convincing A model is convincing when it fits a lot of when it fits a lot of data surprisingly well.data surprisingly well.

E
Validation
Training
amount of training,parameter adjustment
Stop training here
ValidationValidation

Problems with basic Problems with basic BackpropagationBackpropagation
One of the problems with the basic backpropagation algorithm is that it is possible for the network to get ‘stuck’ in a local minimum area on the error surface rather than in the desired global minimum.
The weight updating therefore ceases in a local minimum and the network becomes trapped because it cannot alter the weights to get out of the local minimum.

Local MinimaLocal Minima
Local Minimum
Global Minimum

Backpropagation with Backpropagation with MomentumMomentum
One solution to the problems with the basic backpropagation algorithm is to use a slightly modified weight updating procedure. In backpropagation with momentum, the weight change is in a direction that is a combination of the current error gradient and the previous error gradient.
The modified weight updating procedures are:
Wij(t+1) = Wij(t) + jXi + [Wij(t) - Wij(t - 1)]
Vjk(t+1) = Vjk(t) + kYj + [Vjk(t) - Vjk(t - 1)]
where is a momentum term coefficient that is given a value between 0 and 1 at the start of training.
The use of the extra momentum term can help the network to ‘climb out’ of local minima and can also help speed up the network training.
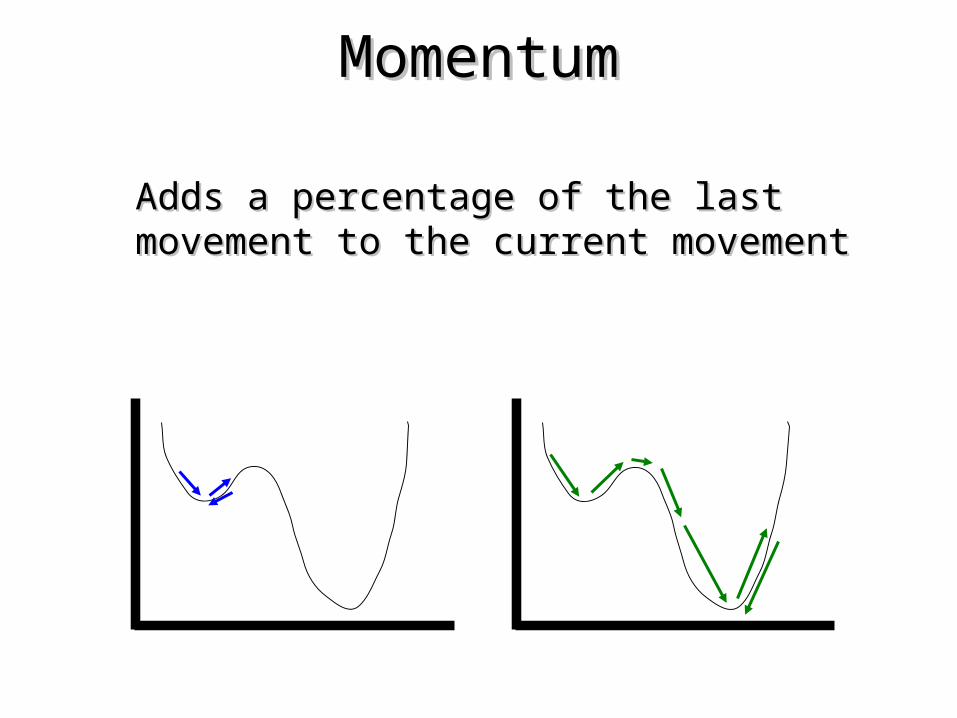
MomentumMomentum
• Adds a percentage of the last movement Adds a percentage of the last movement to the current movementto the current movement

Choice of Parameters Choice of Parameters
Initial weight set
Normally, the network weights are initialised to small random values before training is started. However, the choice of starting weight set can affect whether or not the network can find the global error minimum. This is due to the presence of local minima within the error surface. Some starting weight sets may therefore set the network off on a path that leads to a given local minimum whilst other starting weight sets avoid the local minimum.
It may therefore be necessary for several training runs to be performed using different random starting weight sets in order to determine whether or not the network has achieved the desired global minimum.

Choice of ParametersChoice of Parameters
Number of hidden neurons Number of hidden neurons Usually determined by experimentation Usually determined by experimentation Too many – network will memorise training set and will not Too many – network will memorise training set and will not
generalise wellgeneralise well Too few – risk that network may not be able to learn the pattern in Too few – risk that network may not be able to learn the pattern in
the training setthe training set
Learning rateLearning rate Value between 0 and 1Value between 0 and 1 Too low – training will be very slowToo low – training will be very slow Too high – network may never reach a global minimum Too high – network may never reach a global minimum It is often necessary to train the network with different learning It is often necessary to train the network with different learning
rates to find the optimum value for the problem under rates to find the optimum value for the problem under investigationinvestigation

Choice of Parameters Choice of Parameters Training, validation and test setsTraining, validation and test sets
Training set - Training set - The choice of training set can also affect the ability of the network to reach the global minimum. The aim is to have a set of patterns that are representative of the whole population of patterns that the network is expected to encounter.
Example Example Training set – 75%Training set – 75% Validation set -10%Validation set -10% Test set – 5%Test set – 5%

Pre-processing and Post-Pre-processing and Post-processingprocessing
Pre-process Train network Post-process Pre-process Train network Post-process data datadata data Why pre-process?Why pre-process? Input variables sometime differ by several orders of Input variables sometime differ by several orders of
magnitude and the sizes of the variables do not necessarily magnitude and the sizes of the variables do not necessarily reflect their importance in finding the required outputreflect their importance in finding the required output
Types of pre-processingTypes of pre-processing input normalisation – normalised inputs will fall in the range input normalisation – normalised inputs will fall in the range
[-1,1][-1,1] Normalise mean and standard deviation of training set so Normalise mean and standard deviation of training set so
that input variables will have 0 mean and standard 1 that input variables will have 0 mean and standard 1

Recommended Reading Recommended Reading
Fundamentals of neural networks; Fundamentals of neural networks; Architectures, Algorithms and Applications, Architectures, Algorithms and Applications, L. Fausett, 1994.L. Fausett, 1994.
Artificial Intelligence: A Modern Approach, Artificial Intelligence: A Modern Approach, S. Russel and P. Norvig, 1995.S. Russel and P. Norvig, 1995.
An Introduction to Neural Networks. 2An Introduction to Neural Networks. 2ndnd Edition, Morton, IM.Edition, Morton, IM.

















