Abstract We present a new text-to-image re-ranking approach for improving the relevancyrate in searches. In particular, we focus on the fundamental semantic gap that exists betweenthe low-level visual features of the image and high-level textual queries by dynamicallymaintaining a connected hierarchy in the form of a concept database. For each textual query,we take the results from popular search engines as an initial retrieval, followed by a seman-tic analysis to map the textual query to higher level concepts. In order to do this, we designa two-layer scoring system which can identify the relationship between the query and theconcepts automatically. We then calculate the image feature vectors and compare them withthe classifier for each related concept. An image is relevant only when it is related to thequery both semantically and content-wise. The second feature of this work is that we loosenthe requirement for query accuracy from the user, which makes it possible to perform wellon users’ queries containing less relevant information. Thirdly, the concept database can bedynamically maintained to satisfy the variations in user queries, which eliminates the needfor human labor in building a sophisticated initial concept database. We designed our exper-iment using complex queries (based on five scenarios) to demonstrate how our retrievalresults are a significant improvement over those obtained from current state-of-the-art imagesearch engines.
The amount of image information is growing dramatically due to the rapid developmentof hardware technologies and the lower cost of storage. Thus, effectively searching large-scale image databases via textual queries becomes more and more critical. One of the mainobstacles for image retrieval (IR) is the semantic gap between the low-level image contentand human’s high-level interpretations (Zhao and Grosky 2002). Several efforts such as textdocument indexing retrieval and content-based image retrieval have made significant con-tributions to image retrieval (Wang et al. 2001; Dy et al. 2003; Gao and Fan 2006; Carneiroet al. 2006; Tao et al. 2006). However, they either annotate the image using the keywordsin the surrounding text but overlook the image semantics hinted in the image content; or,highly rely on the local feature descriptors and fail to handle the semantic inconsistencywith respect to the human’s perception of image semantics (i.e. image concepts). For exam-ple, two images with similar illumination and color transitions are likely to be classified intothe same category by a local feature-based machine. However, the content of each imagecan be telling different stories. Therefore, there is an urgent need to develop frameworksthat are able to bridge the semantic gap successfully.
The main goal of our work is to propose an image search re-ranking approach that fillsin this gap so as to improve the precision of semantic image retrieval via textual queries.The criterion to decide the relevancy of an image should involve the consideration of bothsemantic and image content, which requires: 1) a framework to represent the image whilemaintaining semantic consistency; and, 2) algorithms for mapping the query to the relatedimages. To address the first issue, we focus on the notion of “concept” which helps bridgethe semantic gap between textural queries and images by integrating their common featuresinto one overall entity. On the one hand, concept labels serve as the key words of a complexquery, such as subject and object. On the other hand, one single image may have differ-ent meanings due to the diversity of image contents with within-category variations, whichmakes it reasonable to treat an image as a combination of multiple objects or scenes. Eachof the objects or the scene itself in the image can be projected to some concept. Therefore,textual queries and images are matched together only when both can be assigned to at leastone concept. For example, “firefighter” and “fire” are the two concepts of the query “fire-fighters fighting fire”. Therefore, the retrieved images should include the features of theimage category “firefighter” and “fire”. To address the second issue, robust algorithms forimage concept reasoning and image classifier learning are needed to project the queries andimages onto the concepts. We design a novel scoring system that is able to match the queryto the related image concepts automatically. We then re-rank the images returned by thesearch engines in terms of their closeness to the semantic related concepts via classificationin content base.
1.1 Contributions
In order to improve performance and fill in the semantic gap in image retrieval or anno-tation, significant effort has been put into incorporating textual semantic analysis on thebasis of content-based image retrieval (CBIR) algorithms. However, no matter how muchCBIR has evolved, their results are not scalable and often only good on certain specificcategories. This becomes a bottleneck for the bottom-up approaches where the first levelimage classification is feature-based (Wang et al. 2001; Tsai 2009; Gao and Fan 2006). Partof the problem is that representing an image with simple features usually results in lossof information. Even when sophisticated features are used, such as Scale-invariant feature
J Intell Inf Syst
transform (SIFT)-based descriptors (Lowe 2004; Bosch et al. 2007), they still rely on pixelvalues. Failures often occur when the common objects are posed very differently in thetwo images. Therefore, we compensate for this limitation by applying a high-level seman-tic analysis that projects the query onto the salient objects in the first place and then usesthe low-level image classification for deciding whether the candidate image contains salientobjects to refine the retrieval results. This top-down framework instead of bottom-up one isinspired by the better performance of textual retrieval over image retrieval. One of the rea-sons is that the image data (pixel values) is typically very far from the way people interpretimages. This is not the case with textual data (words). A compromise method is to assign adocument fragment or some labels to the image and estimate the joint probability of imagefeatures and semantic labels (Feng and Lapata 2008; Wang et al. 2008; Carneiro et al. 2006;Lavrenko et al. 2003). However, it does not explicitly treat semantics as image categories,and therefore fails to guarantee that the semantic annotations are optimal in a retrieval sense.Pseudo relevance feedback (PRF) (Carbonell and et al. 1997) assumes that the top k rankedsearch results are highly relevant and can be used to build models for improving initialtext search results. Various results have shown the advantage of applying PRF in multi-media tasks (Yan et al. 2003; Natsev et al. 2005). For example, Hsu et al. (2007) presentstwo re-ranking approaches to explore recurrent patterns in visual features and text fea-tures separately, which unfortunately overlooked the semantic gap between these two medialevels.
Image retrieval using concepts that encode information from different levels has beenconsidered as a more cognitive approach than simply using text, speech or example images(Snoek and Smeulders 2010). In our work, a concept is defined as the integration of both tex-tual semantic and visual features. Each concept consists of a text description and an imageclassifier. We develop a strategy that can automatically attach a piece of textual descriptionbased on some authorized reference work such as Wikipedia to the image category for thesake of semantic analysis. Each text description will be stored in a document graph (DG)(Santos et al. 2001), which can help extract the key words contained in a sentence andremove the irrelevant information without losing the dependency relationship. The classi-fier is used to catch the low-level image properties and determine whether a given image’scontent is related to this image category or not. By carefully choosing the local featuresto represent the image using region-based CBIR techniques, we can build a classifier fromthe training image data of each image category. Then, an image is relevant only when it isrelated to the query both semantically and content-wise. Figure 1 depicts the structure of aconcept.
With respect to the matching techniques, most of the existing concept-based workfocuses on indexing keywords in the query with the label of image categories, like ourprevious work (Santos et al. 2008). Its drawback lay in the performance which is highlydependent on how the query is composed and how well a static large-scale concept database(e.g. concept ontology Hauptmann 2004; Gao and Fan 2006; Benitez and Chang 2003;Gupta et al. 2009) is constructed. They can easily fail when a user queries for specificsubjects like celebrities or subspecies. Similar to the idea of concept, advances have beenreported in the area of multi-modal retrieval systems (Rasiwasia et al. 2007; Blei et al.2003), e.g. Rasiwasia et al. (2010) applies a joint model to combine semantic abstractionfor both images and text. Instead of using different models for text and image represen-tation, they convert both images and text into two vector spaces and calculate image-textdistance based on the semantic mappings. However, most of these approaches require com-plex queries, e.g. multi-model queries with both image and text features. As a comparison,we will demonstrate our advantages in three ways: First, we only need textual queries since
J Intell Inf Syst
Fig. 1 Structure of concept “flower”: a combination of an image classifier and a description generated fromthe references
it offers a friendlier user interface. Furthermore, we loosen our requirement for queryac-curacy from users. Given a query, we detect its semantically related concepts through anautomatic semantic mapping scheme (SMS). SMS compares the query with each concept’stext description and uncovers two types of relationship: direct and indirect. These two rela-tionships represent the “closeness” between the query and the image category semantically.A direct relationship means that parts of the keywords (indicating the objects or scenes inthe image) in the query are matched in the description of certain image concepts whereasan indirect relationship suggests that no explicit relation can be found. However, consider-ing the fact that a detailed explanation may provide more assistance on better understandingand selecting a concept, it is reasonable to uncover the implicit relationships by extendingthe query with its references and borrow the visual characteristics of its indirectly relatedconcepts to help better match the images. For example, even if we have no knowledge baseabout the concept “rose”, with the aid of its reference “A rose is a perennial flower” wecan still visualize it as a kind of flower. Then, only the images containing the features of“flower” are likely to be a “rose”. Therefore, we increase the flexibility of writing a query,even when no query terms appear in the descriptions of the existing concepts.
Second, we reduce the human/manual labor needed to build a large-scale sophisticatedconcept database. Furthermore, the text descriptions from an online authorized referencecan offer a better explanation of the concepts, which makes it possible to automaticallymap a query to its textual semantically related concepts without specifying the ontologystructure of the concept database. We also show that it is not necessary to start with a large-scale database. In other words, even if the query on a specific subject fails to be mapped tosome specific concept that may not be found in the current knowledge base, it can still beindirectly mapped to a more generic concept. We will further demonstrate that our approachhas low sensitivity to the size of the initial concept database.
Third, besides the ability to map the query into concepts automatically, we also makesure that the concept database is adjustable with respect to users’ queries. In essence, wetreat the terms in the query that do not have reasonable mappings as new concepts in orderto extend the concept database.
In summary, the main contribution of this paper lies with automatic relationship identi-fication and new concept detection, which fills in the gap between the textual queries andlow-level image content while maintaining the advantages of the current popular image
J Intell Inf Syst
retrieval techniques. We design an experiment to evaluate the effectiveness of our approachat improving search engine retrieval precision by maintaining consistency between semanticand image content.
1.2 Background and related work
There are two popular approaches to image retrieval: CBIR and keyword-based search meth-ods. In CBIR (Wang et al. 2001; Veltkamp and Tanase 2000; Natsev et al. 2004), the imagesare retrieved based on their visual content without using external metadata such as annota-tions. Even though CBIR for general-purpose image databases is still a highly challengingproblem due to the uncontrolled imaging conditions and the difficulties of understandingimages, it has shown great promise in auto-mating the process of interpreting images whichis one of the reasons we incorporate CBIR in our system. In order to capture the visual fea-tures of each image concept in terms of the objects it contains, we apply a region-basedimage content representation in which regions of an image are obtained through an auto-matic image segmentation process (Vu et al. 2003; Carson et al. 2002). The regions sharingsimilar low-level features such as color and textures may represent a certain object or a scenein the image. Region-based retrieval methods are a widely used type of CBIR (Wang et al.2001; Chen and Wang 2002; Natsev et al. 2004). They perform well in handling compleximages. One drawback of these methods is that they take query images instead of a tex-tual query (Wang et al. 2001; Tsai 2009; Carson et al. 2002), which makes it inconvenientfor users. We extract the color and textural features from each region and apply cluster-ing algorithm for image segmentation. Instead of using k-means, we use mixture Gaussianclustering, because EM for a mixture of Gaussians does not require hand-tuning whereas ink-means, the selection of initial centroids can influence the clustering result. To representthe image, unlike Santos et al. (2008) who represent an image by aligning regions accord-ing to their area size, we leverage the approach from DDSVM (Chen and Wang 2004) andapply it to building the image classifier.
In comparison, keyword-based image retrieval methods are based on textual descriptionsabout the pictures, and have been employed in commercial search engines. However thesemethods suffer from lower precision especially for complex queries. With more informationcontained in the complex query, it is harder to determine the users’ main interest and sub-sequently retrieve the images whose contents are relevant to the query. Take Google as anexample, the precision of Google’s image search engine is reported to be only 39 % (Schroffet al. 2007). The keywords used by Google image search are mainly based on the image’sfilename, the link text pointing to the image, and surrounding text (Schroff et al. 2007).When we search for “US destroyer shells Polish shore” in Google, we expect the retrievedimages should include a “destroyer”, however, seven of the top ten images returned (on Nov7th, 2009), only partial matched the text information in the query, and the contents were noteven close (e.g. returning “cars” or “houses”) – the content of these images is not consis-tent with the query. Moreover, keyword-based methods are primarily useful to a user whoknows what keywords should be used to index the images. However, when the user does nothave a clear goal of what keywords to pick, it can become problematic. This may happenwhen the user only wants to search images related to a piece of news, but does not knowhow to organize the query. Our approach in contrast, combines keyword indexing with con-tent analysis to filter out the images that only match with the unimportant keywords in thequery. Feng et al. (2008) also incorporates auxiliary text information to help organize thesemantics. However, they segment the images into squares and make restrictive indepen-dence assumptions on the relationship between the text and regions. The required format of
J Intell Inf Syst
a document-caption-image tuple also makes it not scalable for online search. We will useimage search engines to narrow down the search space since they are already a rich sourceof images and are updated dynamically.
We build a bridge between the textual query and low level image features by mapping thequery to the related concepts through a semantic analysis process. Instead of using keyword-based models only to compare textual information, such as tf-idf and Latent DirichletAllocation (LDA) (Blei et al. 2003) based models, we translate the document into a docu-ment graph to capture the semantics. Let term nodes be nouns and noun phrases representingthe keywords of a sentence and let relation nodes represent the semantic relations amongthese terms. A document graph can be defined as:
Definition 1 A document graph (DG) for a document q is a directed acyclic graph dg =(V ∪ S, E), in which V = {v1, v2, . . . , vn}is the set of term nodes in q and S = {s1, s2, . . . ,sm}is the set of relation nodes disjoint from V, and E includes edges connecting V and S.
An example DG is shown in Fig. 2. Details on how to construct a DG from a sentenceor a piece of document can be found in our prior work (Santos et al. 2001). Although sev-eral approaches have used concepts to represent image categories, they are significantlydifferent from our approach. Gao et al. (2006) incorporated a hierarchical image annotationmodel aiming to identify the multi-level conceptual correlations of an ontology. However,the added complexity makes it applicable only in limited settings with small-size dictio-naries. Another automatic annotation method is ALIPR (Automatic Linguistic Indexing ofPictures - Real Time) (Li and Wang 2008), which tries to map low level features to keywordsin order to suggest annotation tags to users. Nevertheless, the probability of each conceptbeing associated with the image highly depends on whether certain annotation words appearin the description or not. Zhou and Dai (2007) also use keyword-based search to retrievecandidate images first, and then identify related images by assuming that the relevant imagesare similar in the feature space. However, such assumption highly relies on the performanceof keyword-based ranking such that it may fail on complex queries when some noisy regions(other than the key objects, e.g. backgrounds) could show high density as well. The mostrecent work from Wang et al. (2013) also aims to re-rank text based image search results by
Fig. 2 DG for the text “Bostonis mostly sunny with hightemperature”
J Intell Inf Syst
combining image features. However, instead of parsing the textual query and identifying theobject categories associated with the query automatically, they require users to identify the“query image” that is closest to users’ needs. They then refine the search results accordingto the similarities with the query image. To determine the similarity, they design a weightschema to combine multiple image features adaptive to the query image in order to captureuser intention. Nevertheless, they do not bridge the semantic gap, as they need a referenceimage that is annotated by the user. So if they are dealing with complicated queries whenthere are many irrelevant images in the search results, it will be a difficult for a user toannotate the perfect query image. Plus, if the “query image” only reflects parts of the query,forcing all images to appear similar to the “query image” may filter out many quantifiableimages. Though we also manually label some images for training, the off-line training pro-cess is conducted only once. So we do not need to manually annotate the query image forevery search. All these efforts have inspired us to design the multi-level semantic analysissystem. The requirement for query accuracy can be loosened by exploring an indirect rela-tionship between the query and concepts according to the references to the entities insidethe query. This makes it possible to map the query to concepts even when the words in thequery have not appeared in any of the concept descriptions.
2 Methodology
In this section, we describe the details of our image retrieval approach. We consider theproblem of re-ranking from a fraction of initial image retrieval results D = {d1,d2, . . . dn}with respect to a given textual query. The goal is to return the closest match in D.
2.1 Overview of our approach
Our image re-ranking approach consists of two steps. The first step is to map the queryto the high-level concepts through semantic analysis. For each query, we use commercialsearch tools (e.g. Google image search) to perform an initial filtering of the images in thesearch space. Meanwhile, we translate the query into a document graph and use a two-layerscoring system SMS (details in the next section) to detect the related concepts automatically.In the second step, we compare the image with the related concepts at the content-level.Only the images classified as relevant to a query’s related concepts will be returned. Theretrieval process is illustrated in Fig. 3. If no reasonable relationship has been detected,which suggests that the current concept database is not complete enough to reflect all objectinformation, then we gather the information contained in the query in order to add newconcepts.
2.2 Image segmentation and representation
To represent an image with low level features, we first partition the image into severalregions based on scalable color and homogeneous texture information using a mixture Gaus-sian algorithm. We borrowed the idea from SIMPLIcity (Wang et al. 2001) to initialize theregions using blocks of size 4 × 4 pixels. Each block is represented by a six dimensionalvector where the first three components are the average LUV color value in a block and thelast three features are the 2 × 2 Haar wavelet transform on the L component. Haar waveletsare employed due to their efficiency and good performance (Natsev et al. 2004). The featurevector corresponding to block i is defined as xi = {li , ui, vi, hli , lhi, hhi}, where hli , lhi
J Intell Inf Syst
Fig. 3 Example of image retrieval: the input image is matched with the query since both of them areprojected to the concepts “cow” and “grass”
and hhi are the high frequency components of the Haar wavelet transform in i. Nicu Sebeet al. (2003) proved that the wavelet-based detector captures texture features and leads to amore complete image representation.
We use a mixture Gaussian algorithm to cluster the block feature vectors. In order toimprove performance, we run k-means clustering to initialize the region. We cluster allblocks into 16 classes when each class corresponds to a region in the image. Each imagewill have a maximum of 16 regions since we find that 16 regions give good performance.We apply a diverse density (DD) function introduced in DDSVM (Chen and Wang 2004)to weigh and select the salient regions, and then map the regions into a new image featurespace. DDSVM is an extension of multiple-instance learning (MIL), a form of semi-supervised learning where there is only incomplete knowledge on the labels of the trainingdata (Zhou and Zhang 2007). Several works have applied MIL in image representation andclassification (Zhou et al. 2009; Zhou and Zhang 2007). Since developing MIL method isnot the primary purpose of this paper, we employ DDSVM as it has been shown to havegood performance on categorization of images into semantic classes. In DDSVM (Chen andWang 2004), each image feature space is learned from a training set of positive images andnegative images The DD function is defined over the region feature space, in which regionscan be viewed as points in that space. DD function measures a co-occurrence of similarregions from different images with the same label. A feature point with large diverse den-sity indicates that it is close to at least one region from every positive image and far awayfrom every negative image regions.
The DD function is defined as:
DD(x)=Pr(x|D,L)= Pr(x,D,L)
Pr(D, L)= Pr(L|x,D) Pr(x|D)Pr(D)
Pr(L|D)Pr(D)= Pr(L|x,D) Pr(x|D)
Pr(L|D)
J Intell Inf Syst
where x is a point in the region feature space, D is the training image set, and L is the labelcorresponding to the training images. Let < di, li > be an image/label pair in the trainingset. Assuming a uniform prior on x given D, using Bayes’ rule, the maximum likelihoodhypothesis turns into:
argmaxx
DD(x) = argmaxx
Pr(x|D,L) = argmaxx
m∏
i=1Pr(li |x, di)
with Pr (li |x, di) = 1 − |li − label (di |x)|and label (di |x) = max
j
(e‖xij−x|‖2
)
where xij corresponds to the j region vector in image i.Gradient based methods are then applied to find local maximized DD values. The regions
with large DD values are considered as salient regions used to construct the image featurespace. They represent a class of regions that are more likely to appear in positive imagesthan in negative images.
Finally, an image i will be represented as a feature vector {fj : j = 1 : n} based onthe n salient regions, the feature fj of image i is defined as the smallest Euclidean distancebetween salient region j and all regions of image i. Hence, it can also be viewed as ameasurement of the degree that a salient region shows up in the image. More discussion onthis image representation approach can be found in Chen and Wang (2004).
2.3 Creation of the concept database
We build a concept database which is a collection of fundamental concepts. Each concept isan annotation of a certain object or event, such as “dog” or “fire”. They consist of a piece oftextual description and an image classifier. Unlike Santos et al. (2008) which assumes man-ually generated descriptions, we define a strategy to automatically select core descriptionsentences from authoritative knowledge-sharing communities like Wikipedia. Wikipediahas been used in several projects (Auer et al. 2007; Banko et al. 2007; Taneva et al. 2010;Cowling et al. 2010) due to the fact that it is by far the largest collection of general-purposeknowledge bases on the web, with more than 1.6 million edited English articles, thus sup-plying reasonably reliable references for most terms. In addition, its entity-relationship datastructure also enables us to uncover the extra semantics (Taneva et al. 2010), such as con-cept affiliation which can be hard to capture through simple text annotations or captionssince they only focus on coexistence. For example, the entry that “A cathedral is a Christianchurch that contains the seat of a bishop” allows us to expand the semantic knowledge of“cathedral” with “church”. Actually, we will later show that our approach is insensitive tothe length of the text description, which allows for more flexibility in the reference sources.For concept c, we first download its description from the reference source (Wikipedia). Thedescription is a sequence of sentences {z1, z2, . . . zn} . We then transform each sentencefrom the description into a DG. Instead of using the whole description, we define an indi-cator function Ic to select the sentences which contain the most related information to thetarget concept. For a sentence zi , given concept c,
Ic(zi) ={
1 if zi or adjacent sentences contain c
0 otherwise.
J Intell Inf Syst
The criterion for critical sentence selection is a combination of two considerations: Thesentences containing the keywords such as the label of concept c are more likely to be adescription of c. In addition to these key sentences, some may not include the keywordsdirectly, but serve as a supplement. We take the sentences that are adjacent to the key sen-tences in order to expand the information related to concept c. The whole procedure ofretrieving description for concept c is:
1. Download reference for concept c from Wikipedia2. Transform each sentence zi in the reference into a DG.3. Initially, the description set L is empty.4. FOR each sentence zi, i = 1 to n
If Ic(zi) equals to 1, then add zi to L5. END FOR6. Return L.
The image classifier of each concept is generated from a training image set using the dis-criminative learning algorithm Support Vector Machines (SVM). The training set containspositive and negative images. Each image will be transferred into a feature vector. SVMtakes these image feature vectors as input to build the classifier. SVM has been widely usedin image classification and has a good reputation for binary classification with high reli-ability (Chen and Wang 2004). We use a universal kernel function based on the PearsonVII function PUK (Ustun et al. ) as the kernel, since it has been shown to have led to animprovement in the prediction accuracy of regression. The whole process of constructinga concept database is depicted in Fig. 4. Given the training images and use of referenceexplanations, the system can generate the concept automatically, which is an evolution fromsemi-automatic learning (Santos et al. 2008).
2.4 Image matching
The goal of our work is to re-rank the images returned by search engines and improveprecision by discarding the irrelevant ones. We use Google to perform an initial filtering ofthe images in the search space. In this paper, we download the top 20 results and store themas the potential relevant image database.
In order to find the semantic relationship between a user’s textual query and the concepts,we develop a semantic mapping scheme (SMS) (depicted in Fig. 5) to automatically assignthe query to semantically related concepts.
Fig. 4 Creation of concept library
J Intell Inf Syst
Fig. 5 SMS assignment of a query to the related concepts
SMS scoring model captures the relationship between query q and the concepts. Thisrelation can be described mathematically as follows:
f (q) = B
where B denotes the semantically related concept set. f is the scoring function that mapsbetween the query and concepts. f is composed of two-level relationship detection models:QDsim and QRsim. QDsim estimates how the terms in the query are matched in the descrip-tion of a certain concept. Let q and dg be two document graphs for the input query and thedescription of a concept c. We define QDsim as follows:
QDsim(q, dg) = 1
2n
n∑
i=1
T (vi, dg)
N∑
k=1T (vi, dgk)
+ 1
2m
m∑
j=1
T (sj , dg)
N∑
k=1T (sj , dgk)
T (x, dgk) ={
1 for dgk = (Vk ∪ Sk,Ek), if x ∈ Vk ‖x ∈ Sk0 otherwise,
(1)
where vi and sj denote the term and relation note in q respectively, n and m are the numberof term and relation nodes in q , and N is the total number of concepts in the concept library.Here, we use
∑Nk=1 T (vi, dgk) and
∑Nk=1 T
(sj , dgk
)as weights to measure the confidence
of the common nodes between the query and description. The logic behind this confidencemeasurement is that if a node keeps appearing throughout the concept database, then it isnot likely to be a feature for this concept. The query is considered to be directly related tothe concept ci if the QDsim value is larger than some threshold ξ1 (Based on preliminarytesting, we set ξ1 to 0.25).
Otherwise, we move on to the second relation detection function QRsim to uncover indi-rect relationships by extending the query with the references to its keywords. Back to our
J Intell Inf Syst
“rose” example, suppose the query is “rose” and the only concept we have is “flower” whichdoes not include any keyword of “rose”. However, the second relation detection schemereplaces “rose” with its references and extract the implicit information that “rose” is akind of “flower”, which suggests that the query “rose” is indirectly related to the concept“flower”.
To perform the indirect relationship detection, SMS first retrieves the descriptions foreach term node of the query from reference sources the same way as we did in the lastsection, and then combines them into a larger document graph q ′ = (V ′ ∪ S′, E′) as adescription for the query. QRsim takes q ′ and the concept description dg as input and returnsa value reflecting whether the query’s related information is close to concept c. Similar toQDsim, QRsim is defined as:
QRsim(q ′, dg) = 1
2n′n′∑
i=1
Cq ′,dgl (vi)N∑
k=1T (vi, dgk)
+ 1
2m′m′∑
j=1
Cq ′,dgl (sj )N∑
k=1T (sj , dgk)
Cq,dg(x) = min(f r(x, q), f r(x, dg))
T (x, dgk) ={
1 for dgk = (Vk ∪ Sk,Ek), if x ∈ Vk ‖x ∈ Sk0 otherwise,
(2)
where n′ and m′ are the total number of term and relation nodes in q ′. fr(x, y) returns thefrequency of node x appearing in document graph y. The underlying idea is to computethe similarity between two document graph q ′ and dgl by statistically measure the commonnodes of two types. We compare the QRsim value with threshold ξ2 (Based on preliminarytesting, we set ξ2 to 0.3). If the value is greater than ξ2, then the query is considered to havean indirect relationship with the concept.
The complexity of the relationship detection is no worse than O(nD2) where n is thenumber of keywords in query q and D is the maximum length of the text description. Inaddition, the computation time needed for retrieving the descriptions is quite low since weloosen the requirements for completeness of the description (as will be demonstrated inSection 3.3). Even a short piece of the explanation from the reference sources performswell, which guarantees that SMS can perform quickly.
Lastly, if the second scheme fails as well, then each term node in q will be alerted ofa new concept to add into the concept database. As we discussed in the last section, thewhole process of building a new concept can be done automatically unless the public imagedatabase is not large enough to contain training images for a particular new concept, whichthough is rare in our experiment. A detailed example of how we create the concept librarywill be discussed in the next section.
The final step is image content matching. Based on the related concepts, we comparethe images in the potential relevant database against the classifiers for the query’s relatedconcepts. By assuming that the more concepts an image is content-wise close to, the higherprobability it is related to the query, we re-rank the images by the number of concepts thatthey have been classified into. The images that are not projected to any concepts will beviewed as irrelevant. Continuing with the “rose” example, after being related to the concept“flower”, the system will use the classifier of “flower” to make sure that the images thathave no content close to “flower” will be thrown out, since they are also not likely to sharefeatures with “rose”.
J Intell Inf Syst
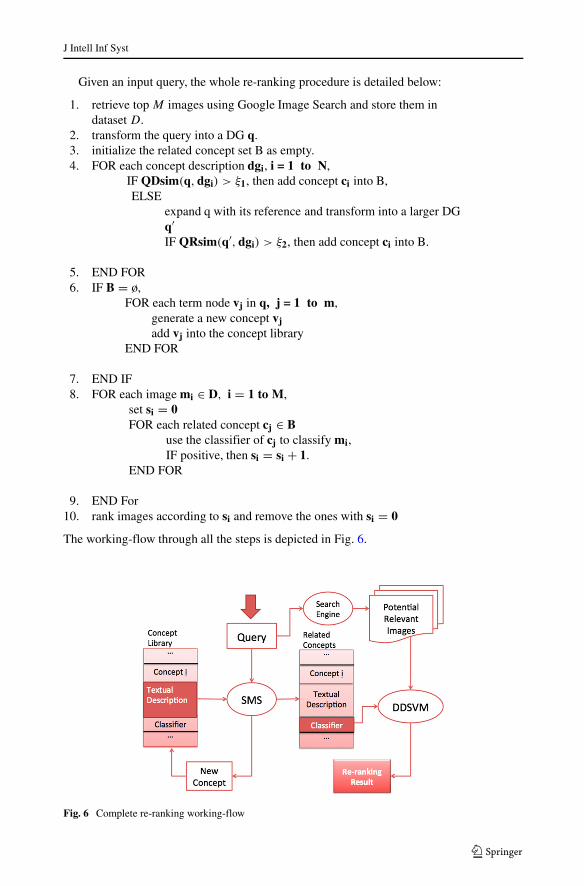
Given an input query, the whole re-ranking procedure is detailed below:
1. retrieve top M images using Google Image Search and store them indataset D.
2. transform the query into a DG q.3. initialize the related concept set B as empty.4. FOR each concept description dgi, i = 1 to N,
IF QDsim(q,dgi) > ξ1, then add concept ci into B,ELSE
expand q with its reference and transform into a larger DGq′IF QRsim(q′, dgi) > ξ2, then add concept ci into B.
5. END FOR6. IF B = ø,
FOR each term node vj in q, j = 1 to m,generate a new concept vjadd vj into the concept library
END FOR
7. END IF8. FOR each image mi ∈ D, i = 1 to M,
set si = 0FOR each related concept cj ∈ B
use the classifier of cj to classify mi,IF positive, then si = si + 1.
END FOR
9. END For10. rank images according to si and remove the ones with si = 0
The working-flow through all the steps is depicted in Fig. 6.
Fig. 6 Complete re-ranking working-flow
J Intell Inf Syst
3 Experiments
In this section, we setup experiments to test the overall improvement on a search engine’sretrieval results applying our re-ranking approach. We evaluate our approach in two steps.The first step is to demonstrate that DDSVM is a better image classification method thatsuits our purpose. Then we show how we can beat keyword-based methods by combiningCBIR techniques. As most of existing CBIR systems require image queries rather than textqueries, it becomes not appropriate to compare our framework with them.[-2pc]In referencelist, “Google Image Search” were removed and transferred/inserted in text, please checkif appropriate. Google Image Search. http://images.google.com/ is a popular search enginewith a huge amount of indexed images updated frequently. Therefore, we decided to take theresults from Google image search as a comparison in order to better reflect day-to-day use.
One feature of our approach is that we lower the requirement for query accuracy andallow users to input queries with irrelevant information. To demonstrate this, we use a col-lection of complex queries as a testbed. One kind of query is news which plays an importantrole in peoples’ daily lives and varies across a wide range of topics. We collected 150 imagesearch queries based on news titles as our query set. For each query, we provide 20 top-ranked images returned by Google image search and re-rank images using our approachrespectively.
We use a baseline which replaces our MIL extended image representation with SIFT-based descriptors. SIFT is probably the most popular features approach that have beenwidely used in object categorization, image annotation and classification. They have beenshown to be effective on both textured and structured scenes and are invariant to imagescale and rotation. In our implementation, SIFT-based descriptors are computed to captureappearance using PHOW descriptor (Bosch et al. 2007). These visual descriptors will thenbe clustered into a vocabulary of size 1000, and accumulated in a special histogram. Wecompare the results with the manually pre-labeled relevant images and report the retrievalprecision and the significance of the improvements.
3.1 Experimental setup and testbed creation
Previous image re-ranking data sets (Schroff et al. 2007; Fergus et al. 2004) contain imagesfor only a few categories, most of which are fairly concrete and specific (e.g. “bottle” Ferguset al. 2004 and “dolphin” Schroff et al. 2007). For our experiment, we selected five topicsthat are typical to daily life yet somewhat separated from each other: People, Architec-ture, Military, Animal, and Natural Disaster (ND). Under each topic, 30 related imagequeries based on the news titles from Google news are treated as our testbed. Some samplequeries are:
“Indonesia will face a more devastating earthquake” (ND)“Holiday puts black cats in spotlight” (Animal)“NASA launches test rocket on second try” (Military)“Obama to focus on deficit reduction and job creation in 2010” (People)“Cathedral development idea criticized” (Architecture)
Before we run the experiment on the test queries, an initial concept database is neces-sary. Even though we can start with an empty database and let SMS detect the new concepts,we will show in Section 3.4 that initializing the concept database with certain basic andgeneric concepts can better improve performance. In addition, once the size of the initialconcept database is beyond a certain threshold, the performance will not be sensitive to the
Fig. 7 Example of an initial concept database: concepts are represented by gray rectangle, when each ofthem is related to one or more scenarios
size, which makes it more likely to keep the size of database as small as possible. Eventhough our previous concept-based retrieval system IFGM (Santos et al. 2008) has alreadydemonstrated good performance, it is still a static approach like the other ontology basedannotation approaches whose semantic analysis highly relies on a rigid structured conceptdatabase. We eliminate the work involved in specifying an ontological structure of the con-cepts by making it possible to detect the affiliated concepts dynamically. To select the initialconcept database, we first expand the news title with a piece of textural description the sameway we use to expand the query in SMS. We record the frequency of each term node appear-ing in the description and selected the top 20 % as our initial concepts. The reason for doingthis is that the term with high frequency in an explanatory description is more likely to bea common and basic word, such as “flower” and “man”. We used 20 % as it is the minimalsize that performs well.
We used 42 concepts in total as the initial concept database. Part of the initial conceptdatabase is shown in Fig. 7. Intersections also occur when two scenarios share similar topicsas we learn more concepts.
We use the public image database LabelMe1 to build the image classifier of each concept.LabelMe provides a large collection of images with ground truth labels and has been well-used for object detection and recognition research. We selected 50 related images as positiveand 50 irrelevant images as negative to train the classifier. The learning process is conductedas described in Sections 2.3 to 2.4. Since the concepts usually represent basic or “ground-level” objects, we found that the classification results using 100 samples are sufficient.Experiments of using more samples for training did not yield significant improvements.
3.2 Results evaluation
Precision and recall metrics are commonly used to evaluate the retrieval results. However,since the possible relevant images indexed by the search engines are far larger than the usersneed, the precision within the first retrieval pages becomes more critical than recall. Whenthe document cut-off points (DCP) (Lin et al. 2003) is low, precision is shown to be moreaccurate than recall (Hull 1993). The precision α used in our evaluation is defined as:
α = r
n
1 The image data can be downloaded from: http://labelme.csail.mit.edu/
Table 1 Percentage of queries with no related concept
Scenario Architecture Animal Military ND People
(%) 33.3 0 16.7 0 6.67
where r is the number of retrieved images that are true relevant to users’ queries and n
is the total number. Only the top 20 results of each query are being evaluated, since theyare expected to be more representative and accurate. We pre-label the relevant images andirrelevant images and recorded the precision for each query. After that, we ran our proposedsystem and baseline (PHOW Bosch et al. 2007) in order to do a comparison.
We ran our system twice and use the precision α1 and α2 to measure the performance ofeach round. After the first round, it is possible that only partial queries have been related tothe concepts due to the limitations of our initial concept database. Table 1 shows the per-centage of queries with no matching concepts in terms of each topic. We treat the term nodesof the rest of the queries as new concepts to update the concept database. SMS guaranteesa mapping for all queries to their related concepts in the second round. More specifically,the queries with no related concept in the first round will be mapped to the new conceptsin the second round. Therefore, after the second run, the system will be able to refine theretrieval results for all queries. In practice, the concept database should converge after pro-cessing sufficient queries. Table 2 gives some examples on the related concepts detected bySMS and Table 3 presents the comparison of the precision between different algorithms.
The retrieval results between the first and second runs are not very different, whichimplies that most of the queries have been mapped to the concepts after the first run. There-fore, the initial concepts serve as fundamental concepts successfully. The results providedin Table 3 also suggest that our approach improves the performance of Google by more than10 % on average. There are only a few cases when the precision is lower than the origi-nal results. This happens when some relevant images have been misclassified as irrelevantones. Most of the objects in these images are too abstract to detect by our image descriptors.However, the frequency of these cases is less than 10 %. As a reference, we list the classi-fication precision from using DDSVM in Table 4. As shown in the table, the precision ofthe concept “Animal” is rather high, which explains the high improvement of the re-rankingresults we gain in Table 3 (0.64 in our approach vs 0.45 in Google).
The results of using dense vector quantized SIFT descriptors (PHOW) are not very sat-isfying. The average improvement is only 4 %, which is far from our expectation. PHOWdescriptors in this case either failed to detect the irrelevant images or result in false-negative.For example, the image in Fig. 8a fails to be categorized into the concept “dog” and theimage in Fig. 8b has been misclassified into the concept “building”. This is probably due to
Table 2 Example of related concepts detected by SMS
Queries Related concepts
“Plaza high-rise is ‘work of art’ ” Building
“Cathedral development idea criticized” church, building, sculpture
“Large Great White Shark Found Bitten in Half in Australia” Fish
“Firefighters Get Upper Hand on Flagstaff Wildfire” people, fire
“US destroyer shells Polish shore” ship, weapon
J Intell Inf Syst
Table 3 Image re-ranking results
Scenario Architecture Animal Military ND People Total
Mean GOOG 0.67 0.45 0.46 0.62 0.56 0.55
α1 0.71 0.64 0.57 0.69 0.63 0.65
α2 0.73 0.64 0.59 0.69 0.63 0.66
PHOW 0.70 0.54 0.51 0.63 0.57 0.59
Max GOOG 0.85 0.55 0.60 0.80 0.70 0.85
α1 0.87 0.83 0.82 0.90 0.86 0.90
α2 0.93 0.83 0.82 0.90 0.86 0.93
PHOW 0.85 0.70 0.75 0.80 0.75 0.85
Min GOOG 0.45 0.3 0.30 0.45 0.40 0.30
α1 0.43 0.42 0.29 0.47 0.42 0.29
α2 0.43 0.42 0.29 0.47 0.42 0.29
PHOW 0.45 0.3 0.30 0.42 0.40 0.30
the fact that SIFT-based descriptors rely highly on the local invariants such as interest points,which makes it hard to match the objects correctly especially when the input images arecomplex constructed and the poses of the target objects vary a lot from the training image.In contrast, since the MIL-based learning applied in our work represents the image basedon the weight of the regions, it guarantees insensitive to the region segmentation (Chen andWang 2004). Therefore, even when the test image contains noisy objects, it can still performwell on the small learning set (Fig 9).
Rather than just record average precision values, statistical tests can help to determinethe system’s performance strengths and limitations. We apply paired sample Student’s t-test between Google vs PHOW, Google vs first run and Google vs second run to examinewhether the performance difference in Table 3 is statistically significant. The p-value ispresented in Table 5. As we can see, the p-value of GOOG vs PHOW, is greater than 0.05 inthree out of five scenarios (Architecture, Natural Disaster and People). In comparison, thereis only one scenario “Architecture” in Google vs Alpha2 where the p-value is not less thanthe 0.05 significance level. So it is sufficient to conclude that the improvement of using ourre-ranking approach is significant for most of the scenarios.
Figure 10 shows an example of the retrieved images for the query “Iceland: TroublesomeVolcano Quiets”, which is a loose query whose key semantic information may fail to getindexed in a small ontology. Clearly, the images returned by Google contain several irrel-evant ones due to the noises in the query (e.g. images 2–4 in the first row of Fig. 10a). Bycomparison, as shown in Fig. 10b, our re-ranking approach has successfully removed mostof them since they have no feature similar with the high level semantic images. However,due to the limitation of the content-based classification technique, there are false negative
Table 4 Image classification results
Scenario Architecture Animal Military ND People
Precision 0.60 0.97 0.73 0.74 0.79
Recall 0.68 0.87 0.69 0.71 0.68
Overall accuracy 0.61 0.92 0.72 0.73 0.75
J Intell Inf Syst
Fig. 8 Example of the misclassified cases using SIFT-based descriptors
images that have been mistakenly classified as irrelevant. Take Fig. 10a as the example, thepositive image (the rightmost one in the second row) is filtered out by our approach. Thereason is that the image classifier failed to classify the image to “volcano”.
We also use One-Way ANOVA analysis to test the variance across the 5 topics. Weobtain an F-value of 33.724 which is much greater than the cut-off value of 2.45 for theF-distribution at 4 and 145 degrees of freedom and a 95 % confidence. Therefore, there issufficient evidence to conclude that our topics are different. By taking a closer look at theperformance of each scenario separately, we find that Google does not do well in “Animal”and “Military” and we improve the results significantly. This is due to the fact that Googleis keyword-based and sometimes there are abstract or ambiguous expressions in these twocategories. For example, “cat” sometimes represents more than just a kind of animal, butparticipates in expressing a totally different meaning, e.g. “black cat” is the name for a nightclub. Suppose we are searching the query “Holiday puts black cats in spotlight”. Parts ofGoogle’s results are related to that club but also to real cats. However, since our approachfocuses on the objects of the image which makes sure that once the query is related toconcept “cat”, all the retrieved images should have similar contents of “cat”.
On the other hand, the differences between the results on topics “Natural disaster” and“People” are smaller. This is because natural disasters and celebrities are more likely toappear as individual hot spots with the public paying them more specific attention, and,hence, more reports containing high quality pictures are released by the press. This allowsGoogle to more easily match the text and return the attached images.
3.3 Sensitivity to the text description length
We use Wikipedia as the reference source for the text description since it is a readily reliablesource. However, the completeness of the term explanation is not a rigid requirement forour approach. We now demonstrate that our approach is not sensitive to the length of text
Table 5 Significance of the improvements over five scenarios
p-value Architecture Animal Military ND People
GOOG vs PHOW 0. 183 4.78E-04 3.58E-03 0.325 0.289
GOOG vs alpha2 0. 083 1.66E-06 3.68E-05 0.046 0.052
PHOW vs alpha2 0. 096 2.59E-04 0.0045 0.044 0.055
J Intell Inf Syst
(a)
(b)
Fig. 9 Retrieval results for the query “Iceland: Troublesome Volcano Quiets”: a. top 20 images returned byGoogle Image Search; b after re-ranking using our approach
descriptions by comparing the results of each category with the size of description restrictedto 10, 25, 50, and 80 (the number of sentences used for extracting the description). Asindicated in Fig. 11, the longer the description we add to the concept, the higher precision
Fig. 10 Precision versus the length of the description
J Intell Inf Syst
Fig. 11 Precision versus the size of the initial concepts
we get, which suggests that with the knowledge bases gathered from Wikipedia, we areable to reveal more semantic information. However, with enough reference, even when thelength of descriptions decreases, the average accuracy does not drop much which indicatesthat the length of description is not a critical factor and will not become a bottleneck to theperformance. In other words, we have a loose requirement regarding the completeness ofthe text description.
3.4 Sensitivity to initial concepts configuration
Here, we test the sensitivity of our approach to the size of the initial concepts configuration.We compared the results of processing the queries from the same topic over the differentsizes of the initial concepts and plot the result in Fig. 11. As size grows, the precisionconverges. When the initial concepts library is small, many new concepts are added basedon the key words of the query. However these concepts may be too specific to reflect thefeatures of an image category resulting in content misclassification. As long as the basicconcepts library is large enough (as in our study, we select the top 20 % most frequent termsas our initial concept library), the results will eventually stabilize.
4 Conclusions and future works
This paper has proposed a new image re-ranking approach for improving the image rel-evancy rate in searches. The relevancy of an image is decided by the closeness with thequery both semantically and content-wise. The data structure of concepts connects bothqueries and images, which fills in the semantic gap. Another contribution of this work isthat we lower the requirement for query accuracy, which makes it possible to perform wellon queries containing irrelevant information. Thorough quantitative evaluations have shownthat the proposed approach significantly improves the search results retrieved by Googleimage search alone.
J Intell Inf Syst
Filling the semantic gap between textual queries and image is challenging. Althoughour approach improves the re-ranking results by filtering the images that are not seman-tically consistent with the queries, the mismatched concepts and misclassified images inbridging steps suggest that there is still room for further improvement. More sophisticatedclassification and concept matching techniques can certainly be applied to enhance the per-formance. However, the main idea of this paper is to point a new direction on handling thetext-to-image search based on how human identify relevant images.
Currently, the training samples used for learning the concept classifiers are manuallylabeled, which prevents us from building the concept library fully automatically. Eventhough we only require a small number of training images, this is still not practical foronline systems. Recently, some new techniques have been proposed to develop new compactdescriptors as the output of category-specific classifiers that manage to achieve satisfac-tory performance even when the training data is weakly labeled. We plan to incorporate thefeatures used in Wang et al. (2013) to expand the scale of our system in the future. Ourmain focus in this paper is to introduce a new idea for filling in the semantic gap in imageretrieval. Hopefully, we can use the data returned directly from search engines to build theclassifiers and fully automate the entire system.
Acknowledgments This work was supported in part by AFOSR Grant No. FA9550-07-1-0050. Theauthors would like to thank John Korah and Fei Yu for their helpful discussions.
References
Auer, S., Bizer, C., Kobilarov, G., Lehmann, J., Cyganiak, R., Ives, Z.G. (2007). Dbpedia: A nucleus for aweb of open data. Proc. International Semantic Web Conference (ISWC) (pp. 11–15).
Banko, M., Cafarella, M.J., Soderland, S., Broadhead, M., Etzioni, O. (2007). In “Open informationextraction from the web,”: Proc. International Joint Conference on Artificial Intelligence (IJCAI).
Benitez, A.B., & Chang, S.-F. (2003). Image classification using multimedia knowledge networks. Proc.IEEE International Conference on Image Processing (ICIP) (pp. 613–616).
Blei, D., Ng, A., Jordan, M. (2003). Latent Dirichlet allocation. Journal of Machine Learning Research, 3,993–1022.
Bosch, A., Zisserman, A., Munoz, X. (2007). Image classification using random forests and ferns. Proc.International Conference Computer Vision (ICCV).
Carbonell, J.G., et al. (1997). Translingual information retrieval: A comparative evaluation. Proc. int’l jointconf. artificial intelligence. Morgan Kaufmann, 708–715.
Carneiro, G., Chan, A.B., Moreno, P.J., Vasconcelos, N. (2006). Supervised learning of semantic classes forimage annotation and retrieval. IEEE Transactions on Pattern Analysis and Machine Intelligence, 29(3),394–410.
Carson, C., Belongie, S., Greenspan, H., Malik, J. (2002). Blobworld: image segmentation using expectation-maximization and its application to image querying. IEEE Transactions on Pattern Analysis and MachineIntelligence, 24(8), 1026–1038.
Chen, Y., & Wang, J.Z. (2002). A region-based fuzzy feature matching approach to content-based imageretrieval. IEEE Transactions on Pattern Analysis and Machine Intelligence, 24(9), 252–1267.
Chen, Y.X., & Wang, J.Z. (2004). Image categorization by learning and reasoning with regions. Journal ofMachine Learning Research, 5, 913–939.
Cowling, P.I., Remde, S.M., Hartley, P., Stewart, W., Stock-Brooks, J., Woolley, T. (2010). C-Link: conceptlinkage in knowledge repositories. AAAI Spring Symposium Series.
Dy, J.G., Brodley, C.E., Kak, A., Broderick, L.S., Aisen, A.M. (2003). Unsupervised feature selectionapplied to content-based retrieval of lung images. IEEE Transactions on Pattern Analysis and MachineIntelligence, 25(3), 373–378.
Feng, Y., & Lapata, M. (2008). Automatic image annotation using auxiliary text information. Proc. ACL (pp.272–280). Columbus, Ohio, USA.
J Intell Inf Syst
Fergus, R., Perona, P., Zisserman, A. (2004). A visual category filter for Google images. Proc. InternationalConference on Computer Vision ECCV (pp. 242–256).
Gao, Y., & Fan, J.P. (2006). Incorporating concept ontology to enable probabilistic concept reasoningfor multi-level image annotation. Proc. 8th ACM international workshop on Multimedia informationretrieval (SIGMM) (pp. 79–88).
Gupta, A., Rafatirad, S., Gao, M., Jain, R. (2009). Medialife: from images to a life chronicle. Proc. 35thSIGMOD international conference on Management of data (SIGMOD).
Hauptmann, A.G. (2004). Towards a large scale concept ontology for broadcast video. Proc. ACMInternational Conference on Image and Video Retrieval (CIVR) (pp. 674–675).
Hsu, W., Kennedy, L., Chang, S.-F. (2007). Novel reranking methods for visual search. IEEE Multimedia,14(3), 14–22.
Hull, D. (1993). Using statistical testing in the evaluation of retrieval experiments. Proc. 16nd annualinternational ACM SIGIR (pp. 329–338).
Lavrenko, V., Manmatha, R., Jeon, J. (2003). A model for learning the semantics of pictures. Proc. 17thAnnual Conference on Neural Information Processing Systems (NIPS).
Li, J., & Wang, J.Z. (2008). Real-time computerized annotation of pictures. IEEE Transactions on PatternAnalysis and Machine Intelligence, 30(6), 985–1002.
Lin, W.-H., Jin, R., Hauptmann, A. (2003). Web image retrieval re-ranking with relevance model. Proc. IEEEWeb Intelligence Consortium (WIC).
Lowe, D. (2004). Distinctive image features from scale-invariant keypoints. Journal of Computer Vision,2(60), 91–110.
Natsev, A., Naphade, M.R., Tesic, J. (2005). Learning the semantics of multimedia queries and conceptsfrom a small number of examples. Proc. ACM Int’l Conf. Multimedia (598–607). ACM Press.
Natsev, A., Rastogi, R., Shim, K. (2004). WALRUS: a similarity retrieval algorithm for image databases.IEEE Transactions on Knowledge and Data Engineering, 16(3), 316.
Rasiwasia, N., Costa Pereira, J., Coviello, E., Doyle, G., Lanckriet, G.R.G., Levy, R., Vasconcelos, N.(2010). A new approach to cross-modal multimedia retrieval. ACM Proceedings of the 15th internationalconference on multimedia. Florence, Italy.
Rasiwasia, N., Moreno, P., Vasconcelos, N. (2007). Bridging the gap: query by semantic example. IEEETransactions on Multimedia, 9(5), 923–938.
Santos, E. Jr., Nguyen, H., Brown, S.M. (2001). Kavanah: an active user interface information retrievalagent technology (pp. 412–423). Japan: Maebashi.
Santos, E. Jr., Santos, E., Nguyen, H., Pan, L., Korah, J., Huadong, X., Yu, F., Li, D. (2008). Analyst-ready large scale real time retrieval tool for e-governance. E-Government Diffusion, Policy and Impact:Advanced Issues and Practices, IGI Global, ISBN: 978-1-60566-130-8.
Schroff, F., Criminisi, A., Zisserman, A. (2007). Harvesting image databases from the web. Proc. IEEE 11thInternational Conference Computer Vision (ICCV) (pp. 14–21).
Sebe, N., & Lew, M.S. (2003). Comparing salient points detectors. Journal of Pattern Recognition Letters,24(1–3), 89–96.
Snoek, C.G.M., & Smeulders, A.W.M. (2010). Visual-concept search solved? Computer, 43(6), 76–78.Taneva, B., Kacimi, M., Weikum, G. (2010). Gathering and ranking photos of named entities with high pre-
cision, high recall, and diversity. Proc. ACM International Conference on Web Search and Data Mining(WSDM).
Tao, D., Tang, X., Li, X., Wu, X. (2006). Asymmetric bagging and random subspace for support vec-tor machines-based relevance feedback in image retrieval. IEEE Transactions on Pattern Analysis andMachine Intelligence (pp. 1088–1099).
Tsai, Y.H. (2009). Salient points reduction for content-based image retrieval. World Academy of Science,Engineering and Technology (WASET) (vol. 49).
Ustun, B., Melssen, W.J., L.Buydens, M.C. Facilitating the application of support vector regression by usinga universal pearson VII function based kernel. Chemometrics Intel. Lab. Syst (pp. 29–40). ChemometricsIntel.
Veltkamp, R.C., & Tanase, M. (2000). Content-based image retrieval systems: A survey. Technique. ReportNo. UU-CS-2000-34.
Vu, K., Hua, K.A., Tavanapong, W. (2003). Image retrieval based on regions of interest. IEEE Transactionson Knowledge and Data Engineering, 15(4), 1045–1049.
Wang, J.Z., Li, J., Wiederhold, G. (2001). SIMPLIcity: semantics–sensitive integrated matching forpicture libraries. IEEE Transactions on Pattern Analysis and Machine Intelligence, 23(9), 947–963.
Wang, X., Qiu, S., Liu, K., Tang, X. (2013). In Web image re-ranking using query-specific semanticsignatures. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI).
J Intell Inf Syst
Wang, C.H., Zhang, L., Zhang, H.J. (2008). Learning to reduce the semantic gap in web image retrieval andannotation. Proc. 31st annual international ACM SIGIR (pp. 355–362).
Yan, R., Hauptmann, A., Jin, R. (2003). Multimedia search with pseudo-relevance feedback. Proc. Int’l Conf.Image and Video Retrieval, LNCS 2728 (pp. 238–247). Springer.
Zhao, R., & Grosky, W.I. (2002). Negotiating the semantic gap: from feature maps to semantic landscapes.Journal of Pattern Recognition, 35(3), 593–600.
Zhou, Z.-H., Sun, Y.-Y., Li, Y.-F. (2009). Multi-instance learning by treating instances as non-i.i.d. samples.Proceedings of the 26th annual international conference on machine learning (pp. 1249–1256).
Zhou, Z.-H., & Zhang, M.-L. (2007). Multi-instance multi-label learning with application to scene classifi-cation. Advances in Neural Information Processing Systems 19 (NIPS’06). Cambridge: MIT press (pp.1609–1616).