The application of OFDM technology to radios operating in the 60 GHz band has stimulated
much interest in the research community. The implementation of these systems has brought a
series of design challenges since a successful design must traverse multiple design
representation layers and experience numerous transformations. This thesis focuses on the
implementation of an OFDM baseband processing system for 60 GHz radios supporting data
rates of up to 1.5 Gbps. It covers the system level, architectural level and implementation
level design issues. A framework for OFDM system level design, including the identification
of key design parameters, a design tool to rapidly explore the design space, and an SoC-
oriented system functional model, has been proposed and implemented. A systematic finite-
word-length effect evaluation method based on statistical analysis and bit-true simulation has
been adopted to transform the algorithm into an area-efficient fixed-point implementation.
Architectures for critical building blocks are carefully explored to meet the required
performance specifications with acceptable cost. The whole system has been coded in
Verilog, verified, synthesized and implemented in a Xilinx FPGA.
Acknowledgements
I would like to thank my advisor Professor Glenn Gulak for his guidance, encouragement and
support throughout the course of this research. He has taught me many things that will
continue to guide me in the future.
Thanks to Dr. Javad Omidi for his advice, encouragement and all the detailed discussions.
I would not have been able to understand the OFDM theory so thoroughly without his help.
I would like to take the opportunity to thank Professor Paul Chow for lending me the Xilinx
FGPA board, without which this research would not have been possible.
Thanks to my fellow graduate-students for their friendship and help. Also, thanks to Jaro
Pristupa and Eugenia Distefano for their help and hard work to maintain the computer
systems.
I wish to express my gratitude to my parents and brothers for their support and love.
Finally, I would like to thank my wife Stella for her love, support, understanding and
patience.
- IV - IV
Table of Contents List of Figures ................................................................................................................... VI
List of Tables ..................................................................................................................VIII
List of Symbols ................................................................................................................. IX
List of Acronyms .............................................................................................................. XI
Na Number of altered samples at either the head or the tail of an OFDM
symbol due to the time-domain windowing
Ngi GI length in number of samples
No Number of samples overlapping with adjacent symbol at either the head
or the tail of an OFDM symbol
Nes Number of samples in an OFDM mega-symbol
Bch Channel bandwidth in Hertz
Fs Sampling frequency in Hertz
γ Sampling factor
NFFT Size of the FFT used in an OFDM system
Nsc Number of subcarriers used
Nds Number of data subcarriers used
β Nds to NFFT ratio
Nps Number of pilot and signaling subcarriers
δ Nps to NFFT ratio
Ndn Number of DC & notch subcarriers
θ Ndn to NFFT ratio
Ts Sample period in seconds
Tus Un-extended symbol length in seconds
Tgi GI length in seconds
α Tgi to Tus ratio
Tes Extended symbol length in seconds
- X - X
Fss Subcarrier spacing in Hertz
Bsc Major energy bandwidth in Hertz
ς Filter sharpness factor
DRraw Max. uncoded data rate in bits/second
DR Max. data rate in bits/second
σ Variance of a random process or random variable
η Spectral efficiency in bits/second/Hertz
W Base of the twiddle factors
- XI - XI
List of Acronyms
ADC Analog-to-Digital Converter
AGC Automatic Gain Control
ASIC Application Specific Integrated Circuit
ATPG Automatic Test Pattern Generation
AWGN Additive White Gaussian Noise
BER Bit Error Rate
BIST Built-In Self Test
BO Butterfly Operation
BPSK Binary Phase-Shift Keying
CA Cross Adder
CCT Compensation Coefficient Table
CIR Channel Impulse Response
CLB Configurable Logic Block
COM COMmutator
DFT Discrete Fourier Transform, or Design For Testability
DAC Digital-to-Analog Converter
DCM Digital Clock Manager
DIF Decimation-In-Frequency
DIT Decimation-In-Time
DVB-H Digital Video Broadcast –Handheld
DVB-T Digital Video Broadcast –Terrestrial
EDA Electronic Design Automation
ENOB Effective Number Of Bits
FDCT Frequency Domain Correction Table
FEC Forward Error Correction
FFT Fast Fourier Transform
FIFO First-In, First-Out
FO4 Fanout Of 4
GI Guard Interval
GWE Gigabit Wireless Ethernet
- XII - XII
HDTV High Definition TV
IDFT Inverse Discrete Fourier Transform
IFFT Inverse Fast Fourier Transform
ICI Inter-Carrier-Interference
IP Intellectual Property
ISI Inter-Symbol Interference
ISQ Input SeQuencer
ISVT In-phase Symbol Value Table
LOS Line-Of-Sight
LUT Look-Up Table
MCM MultiCarrier Modulation
MDC Multi-path Delay Commutator
MMSE Minimum Mean Square Error
MPEG Moving Picture Experts Group
m-QAM m-array Quadrature Amplitude Modulation
NLOS Non-Line-Of-Sight
OFDM Orthogonal Frequency Division Multiplexing
OSQ Output SeQuencer
PAN Personal Area Network
PAPR Peak-to-Average Power Ratio
P&R Place And Route
PDU Payload Data Unit
PE Processing Element
PLL Phase Lock Loop
PSCT Pulse Shaping Coefficient Table
QPSK Quadrature Phase-Shift Keying
QSVT Quadrature Symbol Value Table
RCT Read ConTrol
RM Reference Model
RMS Rooted Mean Square
RS Reed-Solomon
RTL Register Transfer Level
- XIII - XIII
SDC Single-path Delay Commutator
SDF Single-path Delay Feedback
SDTV Standard Definition TV
SFG Signal Flow Graph
SNR Signal-to-Noise Ratio
SoC System-on-a-Chip
SOW Start Of a Window
SBT Segment Boundary Table
SVT Step Value Table
TFM Twiddle Factor Memory
UCF User Constraints Files
UWB Ultra-WideBand
WCT Write ConTrol
WIGWAM WIreless Gigabit With Advanced Multimedia
ZF Zero Forcing
ZOH Zero-Order-Hold
- 1 -
1. Introduction
1.1 Motivation
The past decade has witnessed the exploding development of the Internet and digital
multimedia. Recently the demand for “anywhere” multimedia applications, such as
Gigabit Wireless Ethernet (GWE) and high-speed connections for uncompressed HDTV-
quality signals between displays and miscellaneous video sources, has spurred
considerable interest in the design and implementation of high speed wireless networks
with data rates of up to Gbps. For instance, the WIGWAM project (Wireless Gigabit with
Advanced Multimedia), a collaboration of 27 research partners, is aimed at designing a
1 Gbps system for the home/office, public access and high velocity scenarios [FI05]; the
802.15.3a working group has proposed an ultra-wideband (UWB) system to provide a
wireless PAN (Personal Area Network) with data-rates of up to 1.32 Gbps [PAN04].
Huge bandwidth requirements and high data processing throughputs have presented many
system implementation challenges.
An OFDM (Orthogonal Frequency Division Multiplexing) based system proposed in
this thesis, operating at 60 GHz with data-rates of up to 1.6 Gbps, is a promising solution
for these types of networks. The FCC has assigned the 59-64 GHz frequency band for
unlicensed wireless communications [FCC98]. In addition to the huge bandwidth,
wireless channels at 60 GHz exhibits large attenuation of 10 – 15 dB/km due to oxygen
absorption and that makes frequency re-use easier [Smu02]. However, a wide-band
channel also means higher probability of severe frequency selectivity, the major obstacle
that traditional single carrier modulation systems have been struggling to overcome.
Fortunately, OFDM is an appealing technology to combat this channel impairment, and
its relatively simple implementation based on FFT (Fast Fourier Transform) makes the
solution feasible and cost-effective.
A fully functional OFDM communication system incorporates high-performance RF
components, complex signal processing algorithms and enormous hardware/software
cooperation. Based on increasing capability for device integration in silicon, a System-
on-a-Chip (SoC) approach provides the benefits of integrating a large number of
- 2 -
functional units, yielding a cost effective implementation approach for our proposed
OFDM system. On the other hand, SoC design has created great challenges for the design
community. For instance, with such a large number of devices and the time-to-market
pressure, timing closure and functional verification are two dominant problems [KB02].
A remedy to the problems is to have high quality, reusable Intellectual Property (IP) for
most of the SoC system, and leave the major design task at the system level as the
integration of the IPs. Thus the success of a SoC solution depends heavily on the
availability and quality of the IP cores. For our proposed OFDM system, high quality IP
cores are especially important due to the high performance requirements of the system.
Yet it is challenging to design the needed IP cores. The following aspects require careful
consideration:
An ideal design requires a thorough understanding of relevant communication
theory and the adoption of appropriate algorithms and design parameters. OFDM
theory, due to its nature, is more complicated than single carrier communication theory.
There exist many interrelationships among the related aspects and design parameters of
the system. Algorithm choice and parameter trade-offs will affect not only the final
performance of the system, but also the implementation cost and complexity;
Good architectures are very important for the high performance targets. Even if
excellent algorithms could be proposed, to meet the high throughput requirements,
reasonable trade-offs among timing, area and power have to be carefully made;
A systematic, highly productive design methodology is the key for the timely
progress of the design. Since the IP cores must evolve from concept to algorithms, then
to architectures and eventually to silicon, considerable transformations of design
representations exist and so do many chances for errors. How to efficiently express the
design idea, thoroughly explore the design space, quickly yet accurately transform the
design forms, and effectively verify the design, are heavily relying on the design
methodology, i.e. principles, tools, techniques and flows.
1.2 Objectives
As mentioned above, the mission of designing IP cores for the proposed OFDM system
involves multi-disciplinary tasks, multi-trade-offs, and a series of design challenges
- 3 -
during different design phases. The research presented in this thesis has been carried out
with the following objectives:
• To address key design issues of the core baseband functionality for the 60 GHz
Radio;
• To provide fully functional building blocks for the principle components of the
OFDM engine;
• To experiment and summarize a systematic design methodology.
It is desirable to build a complete working system. However, due to the complexity of the
OFDM system and available time and resource, only the modulation and demodulation
core blocks are covered in the research, while other important blocks such as channel
estimation and synchronization have to be excluded. It is also tempting to tackle the
OFDM SoC design problem as a whole subject, but unfortunately the overall problem of
OFDM SoC is beyond the scope of the thesis, although the thesis research has been
carried out bearing the SoC in mind and relevant information will be discussed wherever
appropriate.
1.3 Thesis Outline
This thesis is organized as follows. In Chapter 2, the basic fundamentals of OFDM will
be introduced, followed by a discussion of practical OFDM system implementation
considerations, and then concluded by a brief introduction to four OFDM international
standards. Chapter 3 will focus on system level design, revealing the intricate
interrelationships among the design parameters, and the proposed OFDM baseband
design for 60 GHz radios will be elaborated. In Chapter 4, the architecture of proposed
system will be discussed, with the emphasis on the most important block, the FFT/IFFT
block. Chapter 5 will report the implementation results of the system and Chapter 6 will
conclude the thesis with a summary and future research directions.
- 4 -
2. OFDM System
This chapter provides an overview of the basic ideas behind OFDM (Orthogonal
Frequency Division Multiplexing) technology. It starts with a discussion of the
limitations of single-carrier systems to achieve high data rates in frequency selective
channels, and then proceeds to introduce the solution provided by multi-carrier systems,
focusing on the basic theory of OFDM, the usage of IDFT (Inverse Discrete Fourier
Transform)/DFT (Discrete Fourier Transform) and Guard Intervals (GI). IDFT/DFT is
used to implement the modulation and demodulation onto the basic orthogonal
subcarriers, while GI tries to guarantee that the orthogonality among the subcarriers will
not be altered so that no Inter-Symbol Interference (ISI) or Inter-Carrier Interference (ICI)
would occur. Following that, additional functional blocks to implement the OFDM
modulation core and demodulation core are elaborated, including time domain
windowing and frequency domain compensation and correction. These functional blocks
are needed to shape the spectrum of the OFDM signal and improve the system
performance. To end this chapter, the features of four OFDM-based international
standards are introduced.
2.1 From Single Carrier Modulation to Multicarrier Modulation
A digital communication system consists of a transmitter, a receiver and a channel, as
shown in Figure 2.1. In a single carrier modulation system, data symbols are modulated
on a single carrier, i.e. the spectrum of the baseband equivalent signal is shifted to the
passband centered on one single carrier frequency. It is desirable for any digital
communication system to achieve the required data rate with acceptable BER under the
constraints of a given signal bandwidth and signal power, while the implementation
should have reasonable complexity and cost. However, as explained below, it is not easy
for single carrier modulation systems to achieve this under certain circumstances.
In any digital communication system, there are two major impairments applied to the
signal when it traverses from the transmitter via the channel to the receiver: linear
distortion and additive noise. Linear distortion is caused by the “memory effect”
introduced by the channel, such as multi-paths existing in wireless communication
- 5 -
channels, or reflections of un-appropriately terminated cables in fixed-wire
communication scenarios, while noise could be caused by different sources such as
thermal movement of the electrons of the receiver front-end, energy leaked from
neighbouring channels, and so on. As shown in Figure 2.1, the transmitted signal, s(t),
will convolve with the channel impulse response (CIR), h(t), and the result of the
convolution will be added with the noise, n(t), resulting in the received signal r(t) at the
receiver:
r(t) = s(t) * h(t) + n(t). (2.1)
Transmitter ReceiverLinear
Distortation( )
+
Noise ( )Channel
( )( )
Figure 2.1 Block diagram of a digital communication system
In the following section, we will focus on the linear distortions, whose effect on a
digital communication system could be demonstrated in either the time domain or the
frequency domain. In the time domain, ideally h(t) should be an impulse, but due to the
memory effect mentioned above, in most cases it is a dispersive signal with a
considerable length before attenuating to zero. After s(t) convolves with h(t), ISI will be
introduced at the receiver side since any transmitted symbol will be extended by the
dispersive CIR and intrude into successive symbol(s). The length of the dispersion
determines the severity of the ISI and when the ISI is comparable to the length of the
symbol, the quality of the transmission is severely degraded. In the frequency domain, the
frequency response of the above-mentioned channel, H(jω), is not flat, but has deep fades
in certain frequency bands, i.e. a frequency selective channel, as depicted in Figure 2.2(a).
Even if the fades correspond to only a portion of the transmitted signal spectrum, the
transmission is degraded, as the received signal’s spectrum illustrates in Figure 2.2(b).
- 6 -
ω
(a)
ω
(b)
ω
Guard bands
(c)
Figure 2.2 Effect of frequency selective channel on single carrier and multicarrier systems. (a)
Amplitude response of the channel; (b) Effect on a single carrier system; (c) Effect on a
multicarrier system
To combat the degradation, an equalizer could be adopted in the receiver to shape the
CIR toward an ideal impulse, or as its name implies, to “equalize” the frequency response
and make it flat. However, the implementation cost of the equalizer is high; besides,
- 7 -
when the equalizer tries to boost attenuated frequency components, noise is also
amplified and the overall performance shows diminishing improvement.
For single carrier systems to reach high data rates, shorter symbol length must be
adopted and unfortunately the dispersion of the channel will have greater effect, therefore
the performance will become worse.
A solution is to use MultiCarrier Modulation (MCM): divide the wide-band required
by the high data rate into many (say, N) narrow-band sub-channels and transmit
information in these sub-channels simultaneously by modulating the data stream on N
corresponding subcarriers. In the time domain, for each subcarrier modulation, the
symbol period is much larger than otherwise required by a single carrier modulation, so
the effect of ISI can be mitigated. An additional benefit of the longer symbol length is
that the impulse noise existing in certain channels will do less harm to the MCM than to
the single carrier modulation systems [Bin90]. In the frequency domain, there are two
benefits associated with MCM: since the deep fades of the channel correspond to limited
number of sub-channels, only those sub-channels will be affected, as shown in Figure
2.2(c). An adaptive modulation scheme could even be adopted to exploit this fact, e.g.
avoiding transmitting in these sub-channels. Another benefit is, because the frequency
band corresponding to a particular sub-channel could be regarded as a flat channel,
equalization could be achieved using a one term complex number multiplication, as will
be discussed later.
However, for this simple form of MCM, in order to prevent interference between
adjacent subcarriers, i.e. ICI, guard bands must be introduced, as in Figure 2.2(c), so the
spectral efficiency is lower than that of a single carrier system. It is desirable to have a
“compact” MCM system where the spectrum of the subcarriers could be overlapping with
each other yet it is still possible to separate them in the receiver side. OFDM is such a
system where the spectrums of the sub-channels are orthogonally overlapping with each
other, as shown in Figure 2.3. The detail of this Figure and other intricate concepts of
OFDM will be discussed next.
- 8 -
Figure 2.3 Spectra of OFDM subcarriers
2.2 OFDM Basics
The initial concept of OFDM was proposed in the 1960s [CG68]. However, the
complexity of this idea had kept it from being implemented until 1971 when Weinstein
and Ebert proposed to use IDFT and DFT to generate the orthogonal subcarriers in the
baseband [WE71].
Figure 2.4 Discrete-time equivalent block diagram of DFT/IDFT based OFDM
The discrete-time equivalent block diagram of this IDFT/DFT based OFDM system is
shown in Figure 2.4. At the transmitter side, the input binary data stream is mapped into
data symbols using an amplitude and/or phase modulation scheme such as BPSK, QPSK
Serial
to
Parallel
X0
XN-1
x0
xN-1
IDFT Add GI
Parallel
to
Serial
X0
XN-1
x0
xN-1
DFT Remove GI
Serial
to
Parallel
Channel
.
.
.
.
.
.
.
.
.
.
.
.
Input Data
Output Data
Constellation
Mapping
Constellation
Demapping
Parallel
to
Serial
- 9 -
and m-QAM. The data symbol stream is divided by a serial-to-parallel converter into N
parallel sub-streams, each corresponding to a subcarrier. An IDFT is applied to a
frequency domain sequence consisting of N data symbols X0, X1, …, XN-1, one from every
sub-stream, to transform the sequence into a time domain sequence x0, x1, …, xN-1. The
sequence is converted back to serial form, and a cyclic prefix is added to the sequence as
a guard interval (GI) to eliminate ISI and ICI (as explained in section 2.2.2). A reverse
procedure happens in the receiver side: the time-domain sequence x0, x1, …, xN-1 is
retrieved from the received data stream, then transformed back to the frequency domain
sequence X0, X1, …, XN-1 by a DFT, and finally demapped into the original binary data
stream.
The most important idea here is the usage of the DFT/IDFT and the GI, as described
below.
2.2.1 Usage of DFT/IDFT
The IDFT is used to modulate the parallel sub data streams onto N subcarriers with equal
distance away from each other in the frequency spectrum, and at the same time achieve
orthogonality among the subcarriers. As well-known, the IDFT is defined as:
21
0
1[ ] [ ]
−
=
= ∑j nkN
N
k
x n X k eN
π
n = 0, 1, …, N-1. (2.2)
Its continuous time counterpart could be written as
21
0
1( ) [ ]
−
=
= ∑ s
j ktNNT
k
x t X k eN
π
0 ≤ ≤s
t NT , (2.3)
where Ts is the sampling period of the discrete system. It is revealing to interpret (2.3) as
the sum of N complex modulated signals, each of which is generated by modulating one
complex symbol X[k] with rectangular pulse shaping onto a complex subcarrier
2
s
j kt
NTe
π
, or
in other words, to modulate the in-phase and quadrature components of X[K] into
2cos
s
kt
NT
πand
2sin
s
kt
NT
πrespectively. All the subcarriers are orthogonal to each other,
since for any two subcarriers sk(t) and sm(t),
- 10 -
2 2
*
0
( ) ( )0
−∞
−∞
= = =
≠∫ ∫
S
s s
j kt j mtNT
SNT NT
k m
NT k ms t s t dt e e dt
k m
π π
. (2.4)
Since each modulated subcarrier in (2.3) contains the information of a data symbol,
the sum itself is named a mega-symbol. Figure 2.5 shows an example of how the
modulated subcarriers add up to generate one mega-symbol. A QPSK modulation scheme
has been assumed and only the quadrature component is displayed. The orthogonalites
could be demonstrated as that during the symbol time of length NTs, every subcarrier has
an integer number of cycles, while adjacent subcarriers differ with each other by exactly
one cycle.
The orthogonalities could also be checked in Figure 2.3, where the spectrum of each
subcarrier goes to zero at the points corresponding to the maxima of every other
subcarrier1, thus at the receiver side it is possible to obtain those maxima values without
interference from other sub-channels, i.e. without ICI. To achieve this, the DFT is used as
a reverse procedure of the IDFT; In addition, there must be no carrier or timing recovery
error in the receiver side, so that the DFT could be carried out at the centers of the
subcarriers.
A third viewpoint to interpret the orthogonality is that the Nyquist Criterion is met in
the frequency domain, and no ICI should exist if we can sample the information at
exactly the center of each subcarrier [HMC03].
1 Why the spectrum is like this will be discussed in section 2.3.
- 11 -
...
1 ( )
2 ( )
3 ( )
4 ( )
1
( )=
∑N
i
i
S t
Figure 2.5 The sum of modulated subcarriers as the mega-symbol
- 12 -
2.2.2 Usage of GI
A cyclic prefix GI is generated by copying the last Ngi (Ngi ≤N) samples of the original
mega-symbol and attaching them to the beginning of the original mega-symbol, as shown
in Figure 2.6. In this thesis, the original mega-symbol is also named “un-extended mega-
symbol” or “un-extended symbol” where the distinction is necessary.
Figure 2.6 Generation of GI
The GI is used to further reduce ISI and avoid ICI. How that is achieved will be
described next. It might be argued that by using multiple subcarriers, the length of ISI is
so trivial compared with the length of the symbol that ISI will have no effect on detection,
just as in a single carrier system. However, the demodulation of OFDM is completely
different from that of a single carrier system: in order to determine the original data
symbol value, the DFT is carried out on every data sample within the DFT window to
calculate the frequency content of each subcarrier. So if ISI is longer than a sample, it
will affect the detection. The effect of GI can be observed in the time domain by checking
the waveform of one transmitted subcarrier. In the time domain, the convolution of a
dispersive CIR with a modulated subcarrier is the sum of a series of subcarriers with the
same frequency but different amplitudes and delays due to the multiple terms of the CIR.
To illustrate the effect of the channel, Figure 2.7(a) shows the quadrature components of
two extreme subcarriers, the ones with the minimum delay and the maximum delay
respectively, for two consecutive symbol periods. It is obvious there is one phase shift on
one of the waves within the receiver side DFT window. The DFT will detect the
information leaked from the first symbol into the second symbol marked by this phase
transition. It is possible to insert a guard interval consisting of zero values to eliminate ISI,
as in Figure 2.7(b). However, there is still a sudden waveform change inside the DFT
window, and it generates higher spectrum components that will be detected by the DFT
Original mega-symbol Cyclically-extended mega-symbol
- 13 -
as ICI. A cyclic prefix, as depicted in Figure 2.7(c), will guarantee there is no phase
change within the DFT window and every sine wave has an integer number of cycles
within the DFT window, so that no ISI or ICI will occur.
Another viewpoint to understand the GI is from the perspective of discrete-time signal
processing: the cyclic prefix transfers the linear convolution of the transmitted signal with
CIR into a cyclic convolution. This is equivalent to a scalar multiplication in the
frequency domain and so the orthogonality will be maintained [Eng02].
We also need to keep in mind that the orthogonality could be kept only when the
dispersion of the channel is shorter than the GI, and there is no carrier or timing error.
Thus the longer the GI, the more robust the system is against channel dispersion. On the
other hand, a longer GI means more overhead. The strategy of choosing the GI length
will be discussed in Chapter 3, and next we need to first have a look at the whole picture
in the context of a practical OFDM SoC implementation.
- 14 -
( -1)th symbol th symbol
a)
DFT window
( -1)th symbol th symbol
b)
DFT window
( -1)th symbol th symbol
c)
DFT window
GI
GI
Waveform with min. delay
Waveform with max. delay
Waveform with max. delay
Waveform with min. delay
Waveform with min. delay
Waveform with max. delay
Figure 2.7 Benefit of cyclic prefix [HP03] (a) OFDM without guard interval; (b) OFDM
with zero guard interval; (c) OFDM with cyclic prefix guard interval.
- 15 -
2.3 A Practical OFDM System
Figure 2.8 Functional Block diagram of an OFDM SoC
Additional functional blocks beyond those shown in Figure 2.4 are needed to implement
a functioning OFDM SoC, as shown in Figure 2.8. Generally the system can be divided
into the baseband processing part and RF/IF part. The functions of each block are briefly
summarized below.
At the transmitter side, a FEC Encoder provides channel coding for the input data, to
lower the Bit Error Rate (BER) of the system with the cost of certain overhead. The
encoded data is modulated in the modulation core, which contains the following blocks:
Constellation Mapping: map the encoded binary data into complex symbol value
based on the adopted modulation scheme.
Frequency Domain Processing: normalizes the amplitude of the complex values
such that all modulation schemes have similar average power, and compensates the
Zero-Order-Hold (ZOH) effect of the DAC or other defects of the analog system by
multiplying the complex values in the frequency domain with an appropriate
compensation function.
IFFT: Inverse Fast Fourier Transform, a fast algorithm to calculate the IDFT,
transforming each data symbol from the frequency domain into the time domain.
Data out
FEC
Encoder
Constellation
Mapping
Time Domain
Processing
FEC
Decoder
Constellation
Demapping
Freq. Domain
Correction
Frame
Synchronization
Freq. Domain
Processing
Channel Estimation
FFT
Modulation Core
DAC
Channel
Demodulation Core
Analog
Front-end
ADC Analog
Front-end
IFFT
Frequency & Timing
Synchronization
Data in
Baseband Processing RF/IF
- 16 -
Time Domain Processing: inserts the GI, multiplies the time domain values with a
certain window function to help shape the transmitted signal spectrum, and adjusts
the PAPR (Peak-to-Average Power Ratio) 2 to an acceptable level.
The modulated OFDM baseband signal, x(t) as shown in equation (2.3), is a complex
signal, and the transmitted RF signal3 is
2( ) Re{ ( ) } ( )cos(2 ) ( )sin(2 )= = −cj F tre c im cs t x t e x t F t x t F t
π π π , (2.5)
where Re{} represents the operation to take the real part of a complex signal, while xre(t)
and xim(t) are the real and imaginary parts of x(t) respectively. So one way to generate the
RF signal is to use two DACs to generate xre(t) and xim(t), up-converted to the carrier
frequency and mixed to generate s(t) following (2.5). The RF signal is then amplified and
transmitted by the analog front-end.
At the receiver side, the received signal is down-converted, separated into in-phase
and quadrature components and then sampled by two ADCs. The digital samples are
demodulated by the demodulation core, which contains the following sub-blocks.
Frame Synchronization: identifies each data symbol, and allocates the FFT
window location under the control of the timing synchronization block, as discussed
later.
FFT: Fast Fourier Transform, a fast algorithm to calculate the IDFT, transforming
each data symbol from the time domain into the frequency domain.
Frequency Domain Correction: corrects the linear amplitude and phase distortion
of the channel by multiplying the complex symbol value of each sub-channel with
one complex coefficient corresponding to the frequency response of that particular
sub-channel provided by the channel estimation block.
Constellation Demapping: demaps the corrected data symbol to restore the binary
data.
The demodulated data is then fed to the FEC Decoder for generating the original un-
coded data. Meanwhile, the frequency and timing synchronization block provides
important timing information: It works with the analog front-end to recover an accurate
2 Also written as PAR in some research literature. 3 In wireline OFDM system such as HomePlug [LNL03], baseband signal is directly transmitted. One way
to generate such a signal is to make the input signal of the IFFT complex conjugate, and then the output is a
real signal that can be transmitted directly.
- 17 -
carrier frequency so that the signal could be correctly down-converted to the baseband; It
also adjusts the sampling clock for the ADC and so there is no frequency shift that may
cause additional ICI [FK03]; Finally it helps to allocate the FFT window location, such
that within the FFT window, there is no phase shift of the subcarriers, and so there is no
ICI, as discussed before.
As stated earlier, this thesis will focus on the modulation core and the demodulation
core, to this end the following discussion will focus on those blocks. One obvious
question is why the practical implementation needs the “additional” blocks presented in
Figure 2.8, compared with Figure 2.4. A short answer is to shape the OFDM signal
generated by the simple method in Figure 2.4 in the time domain and the frequency
domain, such that the constraints imposed by the operating environment and the
feasibility of implementation could be met, while achieving the performance goal. In the
following sections, the time domain processing and the frequency domain processing
functions will be further discussed.
2.3.1 Time domain windowing
Time domain windowing is performed to help shape the spectrum of the transmitted
signal. To understand this, we need to first check the spectrum of the simple OFDM
signal as generated in Figure 2.4, which has the famous side-lobe problem due to the
rectangular pulse shaping, and the un-desired high frequency components caused by the
sharp phase transition at the OFDM symbol boundaries, as explained below.
When we discuss the “spectrum” of the OFDM signal, we need to be careful which
section of the signal is referred to – the un-extended mega-symbol, or the signal
consisting of many extended symbols – and where the observation point is. Figure 2.3 is
often claimed to be the spectrum of OFDM signals, as stated in some of the literature
about OFDM, for example [NP00]. Strictly speaking it is only the spectrum of an un-
extended symbol, or in other words, the spectrum “detectable” by the FFT in the receiver
side. This part of the signal is generated by using the IFFT, so according to the definition
of IDFT, if this section of the signal is duplicated to generate a periodic signal,
21'
0
( ) [ ]−
=
=∑ s
j ktNNT
k
x t X k e
π
−∞ < < ∞t , (2.6)
- 18 -
then its spectrum is a series of Dirac pulses located at the subcarrier frequencies. Since an
un-extended symbol is only a cycle of (2.6), it could be imagined as the product of (2.6)
with a rectangular pulse with length of NTs. Thus its spectrum is the convolution of the
above-mentioned Dirac pulses with the spectrum of the rectangular pulse, a sinc function.
The convolution will be the sum of a series of shifted sinc functions with the same shape,
generating the spectrum in Figure 2.3. A sinc function has unlimited number of decaying
side-lobes, so the sum of the above mentioned sinc functions results in a slowly decreased
edge of the spectrum.
The spectrum of the actual transmitted signal will have a much less severe side-lobe
problem, since the signal is not an isolated symbol, and the reconstruction filter of the
DAC also helps to shape the spectrum. However, sharp phase transitions exist in the
symbol boundaries due to the rectangular pulse shaping, as in Figure 2.7, so high
frequency components will be generated and it will make the out-of-band spectrum
control more difficult [NP00]. Although guard subcarriers and the reconstruction filter of
the DAC are the major mechanisms to shape the final spectrum, it is still desirable to
have some improvement methods in the baseband processing. One such method is to
smooth the phase transition across symbol boundaries by multiplying the original symbol
with a window function. One possible implementation is shown in Figure 2.9: the first Na
and the last Na samples of each symbol are altered, at the same time adjacent symbols are
overlapped with each other over a region of No samples to further smooth the transition,
while Nm samples are un-changed. Please notice by doing this the nominal length of a
symbol, Nes, is No samples shorter than the original length, Noes.
Figure 2.9 Time domain windowing
- 19 -
One possible candidate for the window function is the raised cosine window Wrc[n],
defined as
0.5 0.5cos( / ) 0
[ ] 1.0
0.5 0.5cos(( ) / ) 2
+ + ≤ ≤
= ≤ ≤ + + − − + ≤ ≤ +
a a
rc a m a
m a a m a m a
n N n N
W n N n N N
n N N N N N n N N
π π
π
. (2.7)
Please note that the rising and falling edge of the window is relatively short. This will
make the implementation easy since only a small part of the symbol needs to be changed.
More importantly, by doing this, enough region of the symbol has been left unchanged
for maintaining the orthogonality between the subcarriers4. Some researchers have
proposed to use other window functions which have much longer rising and falling edges
so that the orthogonality is not maintained [Mol01]. This technique, known as “soft pulse
shaping”, has been claimed to have much better spectrum shape control and make OFDM
less prone to synchronization errors. This idea needs further scrutiny and will not be
adopted in the proposed system.
2.3.2 PAPR adjusting
A baseband OFDM signal is the sum of multiple modulated complex exponential
functions, and so its in-phase and quadrature components might add up to very large
values when the modulating data sequence has certain bits stream. In fact, consider the
definition of the IFFT as in equation (2.2):
21
0
1[ ] [ ]
−
=
= ∑j nkN
N
k
x n X k eN
π
n = 0, 1, …, N-1, (2.2)
where X[k] is the complex data symbol sequence. We can define the PAPR (Peak-to-
Average Power Ratio) of the OFDM signal in dB as:5
4 To maintain the orthogonality, the FFT window at the receiver side will not be at the same position as the
IFFT window in the transmitter side, but rather a few samples ahead. This will not be a problem, since once
the FFT is still inside a symbol, shifting the FFT window will only cause phase rotation that could be taken
into account by the frequency domain correction. In fact, FFT window will be shifted for synchronization
purposes anyway.
5This is a widely-adopted definition of PAPR (e.g. in [KMC05]). In some literature (e.g. [NP00]), the peak
power is defined as the power of a sine wave with an amplitude equal to the maximum envelope value of
the signal, and so an un-modulated carrier has a PAPR of 0 dB.
- 20 -
( )2
10 2
max ( )10log
E ( )=
x nPAPR
x n. (2.8)
Since the signal is zero-mean, the average power2
E ( )
x n in (2.8) is also the variance of
the signal.
Without loss of generality, assume the modulation scheme is 16-QAM with power-
normalized complex symbols of
1( 1 j)
10± ±
,
1( 1 3j)
10± ±
,
1( 3 j)
10± ±
,
1( 3 3j)
10± ±
,
then the in-phase and quadrature components of each modulated subcarrier are both
random processes with zero means and the same variance
2 1
2=SCσ . (2.9)
When the FFT size N is large, according to the central limit theorem, both the in-
phase and quadrature components of the OFDM signal are very close to a Gaussian
process with zero mean and variance
2
2
2
1
2= =
SCN
N N
σσ . (2.10)
So the amplitude of the OFDM signal has a Rayleigh distribution, and the PAPR can be
relatively high with certain probability. For instance, simulation in [NP00] shows that for
1024 subcarriers, the probability that a mega-symbol has a PAPR of less than 8 dB is
approximately 0.1. The high PAPR scenario requires higher DAC and ADC resolution
and larger RF front-end linearity range, so it must be adjusted to be kept within certain
levels.
This PAPR control problem has been a central topic in the OFDM research. [NP00]
systematically categorizes the proposed solutions as non-distortion and distortion
methods. The non-distortion method will not alter the “correct” sample values; rather it
adopts such approaches as PAPR reduction codes which only produce OFDM symbols
with PAPR below certain level, or multiple symbol scramblings where only the
scrambled result with the smallest PAPR is transmitted. The distortion method, as
- 21 -
implied by its name, would sacrifice the “correct” value for lower PAPR. Clipping is the
simplest distortion method which clips the signal amplitudes exceeding a certain
threshold. However, this method generates sharp signal changes and thus results in out-
of-band power radiation. To lower this radiation, other distortion methods smooth the
transition by multiplying the samples above the threshold and their neighboring samples
with a window function, so that the signal amplitude and the out-of-band power radiation
could both be lowered.
For the proposed baseband processing system, the clipping method will be adopted
and it will be further discussed in Chapter 4.
2.3.3 Frequency domain compensation
In the transmitter side, since the frequency domain information is available at no
additional cost, some approaches could be taken to compensate the frequency domain
defects of the system. One example is to compensate the ZOH effect of the DAC6, as
discussed next.
An ideal DAC consists of an impulse modulator that transfers the digital values into
an impulse train, and an ideal low pass filter to reconstruct the analog signal. However,
the ideal low pass filter cannot be implemented in practise, so in a real DAC
implementation it is replaced by a zero-order hold that transfers the impulse train into a
square wave train, and an approximate low-pass filter, as shown in Figure 2.10.
Figure 2.10 Implementation of DAC
6 In over-sampled system, the ZOH effect is small so it may not be worthy of the compensation.
Nevertheless ZOH effect is used here as an example of the frequency domain compensation.
Pulse Train
Modulation
Zero Order
Hold
Reconstruction
Filter
0101110…
- 22 -
The zero-order hold could be regarded as a linear filter whose impulse response is a
square wave with width Ts, the sampling period. The frequency response of this filter is a
sinc function
/ 2sin( / 2)( )
/ 2
−= sjTsTH j e
ωωω
ω. (2.11)
As indicated by the amplitude response of this filter shown in Figure 2.11, the high
frequency components are attenuated.
| ( )|
Ts
2π/-2π/
Figure 2.11 Amplitude response of the zero-order hold
To accurately compensate the loss in the low-pass reconstruction filter is almost
impossible, but it is much easier to achieve it by multiplying the complex symbol value
before the IDFT with the following window function
/ 2/ 2
( )sin( / 2)
= sjT
s
H j eT
ωωω
ω. (2.12)
Of course, this compensation function could be modified to take other defects of the
system into consideration.
As for the non-ideal low pass filter, although it is possible to lower the filter sharpness
requirement by adopting an up-sampling approach, considering the cost and the spectrum
of the OFDM signal, it is more convenient to introduce guard subcarriers, i.e. non-used
subcarriers, at the edge of the spectrum. Now the number of the used subcarriers, Nsc, is
smaller than the FFT size. More of this topic will be covered in Chapter 3.
- 23 -
2.3.4 Frequency domain correction
At the receiver side, the linear amplitude and phase distortion imposed by the channel
could be corrected as follows. For a mega-symbol, assume Si is the symbol corresponding
to the ith subcarrier, then following (2.1), the received symbols could be expressed as:
= +i i i iR H S V i= 0, 1, … N-1 , (2.13)
where Hi is the frequency response of the channel at the frequency point of the ith
subcarrier, Vi represents the contribution of the noise, and it is assumed that no ICI has
occurred. Hi represents the contribution of the dispersive effect, i.e. each subcarrier is
amplitude-changed and phase-rotated. We could use a one-tap equalizer to equalize each
subcarrier, i.e. use a simple symbol corrector to combat the dispersive effect of the
channel by multiplying each symbol with a correction coefficient Ci, and the corrected
symbols are:
' = = +i i i i i i i iR C R C H S CV i= 0, 1, … N-1 . (2.14)
A simple choice for Ci is 1/Hi such that the correction is ZF (Zero Forcing) [FK03].
The second term in (2.14) implies that this may lead to noise enhancement. A more
sophisticated approach is to apply MMSE (Minimum Mean Square Error) equalization
[FK03]. However MMSE equalization is equivalent to ZF when the channel SNR is high,
and it has been suggested that ZF may be better than MMSE equalization [BM01].
This approach is better than the time domain equalizer because it is a simple one term
multiplication while the time domain equalization involves digital filters consisting of
many taps. Of course, this approach relies on the channel estimation block to provide an
accurate estimation of the channel, which is challenging considering the dynamic and
noisy characteristics of the channel.
- 24 -
2.4 OFDM Standard
In recent years, OFDM technology has played a vital role in both wireline and wireless
communication systems. A group of international standards has been proposed and
widely accepted. Table A.1 in Appendix A summarizes the most important system
parameters from four of the latest standards; a brief discussion follows.
DVB-T / DVB-H [DVB04]
DVB-T (Digital Video Broadcast –Terrestrial) is a European standard for digital
terrestrial television, while DVB-H is an improved version of DVB-T for handheld
terminals, and they are aimed at providing HDTV (High Definition TV), SDTV
(Standard Definition TV) and other multimedia broadcasting services. Both of them
support the 2K and 8K modes in Table A.1 and the 4K mode is for the DVB-H only.
Since the systems need to co-exist with traditional analog TV, they only have 8 MHz7
bandwidth while suffering the strong interferences introduced by existing analog TV
signals. The systems are supposed to operate in an environment with huge multi-path
delays due to the nature of large-scale TV broadcasting, so the GI length and symbol
length are much larger than other systems listed in the table. This results in a relatively
large number for the FFT/IFFT size, and a very small subcarrier spacing, which makes
the system susceptible to synchronization errors and so a large number of subcarriers are
used as pilots for synchronization purposes. The systems utilize a concatenated Reed-
Solomon (RS) and convolutional code as channel coding to provide high quality video
broadcasting service. The structure of RS code is fixed since the systems only need to
transport the 188-byte MPEG-2 transport packet, while in other systems, the packet
lengths are variable and so the RS code, if used, must be adaptive.
IEEE 802.11a / 802.11g [LAN99] [LAN03]
These two standards are used for wireless LAN. They are identical except that 802.11a is
for the 5 GHz band while 802.11g is for the 2.4 GHz band. Besides, 802.11g includes
7 8 MHz is one of the standard TV channel bandwidths worldwide. The other two are 6 MHz and 7 MHz.
An additional non-traditional TV band of 5 MHz has also been proposed in the standard for possible
adoption. All four bandwidth scenarios use the same architecture so that by adjusting the sampling clock
frequency an implementation could be used in all situations, of course with different data rates.
- 25 -
other modulation methods in addition to OFDM. A significant feature of the standards is
simplicity: there is no optional setting or multiple configurations, and the channel coding
is relatively simple. This is one of the features that contribute to the huge commercial
success of wireless LAN systems.
IEEE 802.16 WirelessMAN-OFDM [MAN04]
This is one of the two OFDM-based PHYs8 of IEEE 802.16, the Air Interface for Fixed
Broadband Wireless Access Systems. The system is targeted at the frequency bands
below 11 GHz, with NLOS (non-line-of-sight) environment. Considering the NLOS
assumption and the size of the area needed to be covered, relatively large GI length and
symbol length have been adopted. One prominent feature of the targeted band is that
there are many different sized continuous frequency slots, so the standard has not
constrained the channel bandwidth to be any specific value, rather it states that the
bandwidths “shall be limited to the regulatory provisioned bandwidth divided by any
power of 2, rounded down to the nearest multiple of 250 kHz”. Therefore there will be a
large number of different possibilities. Meanwhile the standard provides some guideline
profiles for typical implementations, two of which are shown in Table A.1. Fortunately,
by adjusting the sampling clock frequency, an implementation could be used in all
bandwidth scenarios.
HomePlug 1.0[LNL03]
This is the OFDM-based standard for power line communication. Power line is
ubiquitous, but as a communication media, its frequency response is frequency dependent
with many peaks and notches, some of which are due to the bands reserved for amateur
radio, worsened by the large impulsive noise and background noise [Esm03]. On the
other hand, the channel is almost time-invariant, so based on the channel estimation,
some of the subcarriers could be turned off. The system is operating at baseband, and this
leads to two significant features: One is that the IFFT could take in the complex symbol
and its conjugate counterpart to straightforwardly generate a real time signal without up-
8 The other one is WirelessMAN-OFDMA, orthogonal frequency division multiple access, an OFDM-based
PHY with the capability to support multiple access and advanced antenna arrays.
- 26 -
converting, with the cost of doubled IFFT/FFT size. The other is that no pilot subcarrier
is necessary since there is no need for carrier recovery and the timing recovery could be
achieved using the preamble.
It can be seen from the table that there are a series of important parameters associated
with each standard. One important step to design an OFDM system is to determine the
values for these parameters. However, this is not easy since there are multiple trade-offs
and inter-dependences among them. The next chapter will demonstrate a systematic
approach to tackle this challenge.
- 27 -
3. System-Level Design
This chapter describes the system-level design for the proposed OFDM system. First,
design challenges are introduced. Next, an Excel-based design tool called the OFDM
Calculator and the ideas behind the tool are discussed in detail. Afterwards, the design
parameters of the proposed OFDM baseband system for the 60 GHz radio are reported.
3.1 Design Challenges and Proposed Solution
System-level design is the design phase that captures the abstract high-level behavior of
the system, without considering the exact implementation details. The design activities of
a particular system-level design depend on the essence of the targeted system, which
might be a standalone system or a subsystem of a bigger project, e.g. a SoC, whose
subsystems could be roughly categorized as the control digital subsystem, the algorithmic
digital subsystem, and the analog/RF subsystem [Wil04]. The modulation and
demodulation cores belong to the algorithmic digital subsystem, which specializes in
algorithmic calculation and thus has complicated data paths and relatively simple global
control. The system-level design of an algorithmic digital subsystem is also named
algorithmic design since the design activities focus on the choice of the algorithm and the
key system parameters. The system-level design challenge for the algorithmic digital
subsystem is that the design should be:
Quantitative: Models should be built that could be exercised to reveal the
quantitative characteristics of the design choices, instead of mere qualitative
descriptions.
Accurate: The design should be maintained at an appropriate abstraction level, yet
the important aspects of the design should be precisely described.
Coherent: The inter-dependency of the system parameters should be explicitly
represented; the design should not constrain the implementation details but the
implementation feasibility should be highlighted.
Time Efficient: The design process should be straight-forward and quick.
- 28 -
For OFDM modulation and demodulation cores, these requirements are quite challenging
considering the many parameters9 to be determined and the inter-relationships among
them. The key parameters of an OFDM system, including those shown in Table A.1 of
Appendix A, could be classified into three categories, namely: design performance,
design constraints, and implementation features:
Design performance: parameters desired by a particular application, e.g. data-rate,
Bit-Error-Rate (BER), spectral-efficiency, etc.
Design constraints: parameters constrained by physical resource, or implementation
cost/feasibility, e.g. available bandwidth, delay spread of the channel, allowed Peak-
characteristics of the system, e.g. FFT size, number of data subcarriers, number of
cyclic prefix samples in an OFDM mega-symbol, etc.
The major activities in the OFDM system-level design stage could be regarded as trying
to determine the implementation features so that the required design performance could
be achieved within the defined design constraints. However, this is not an easy task, since
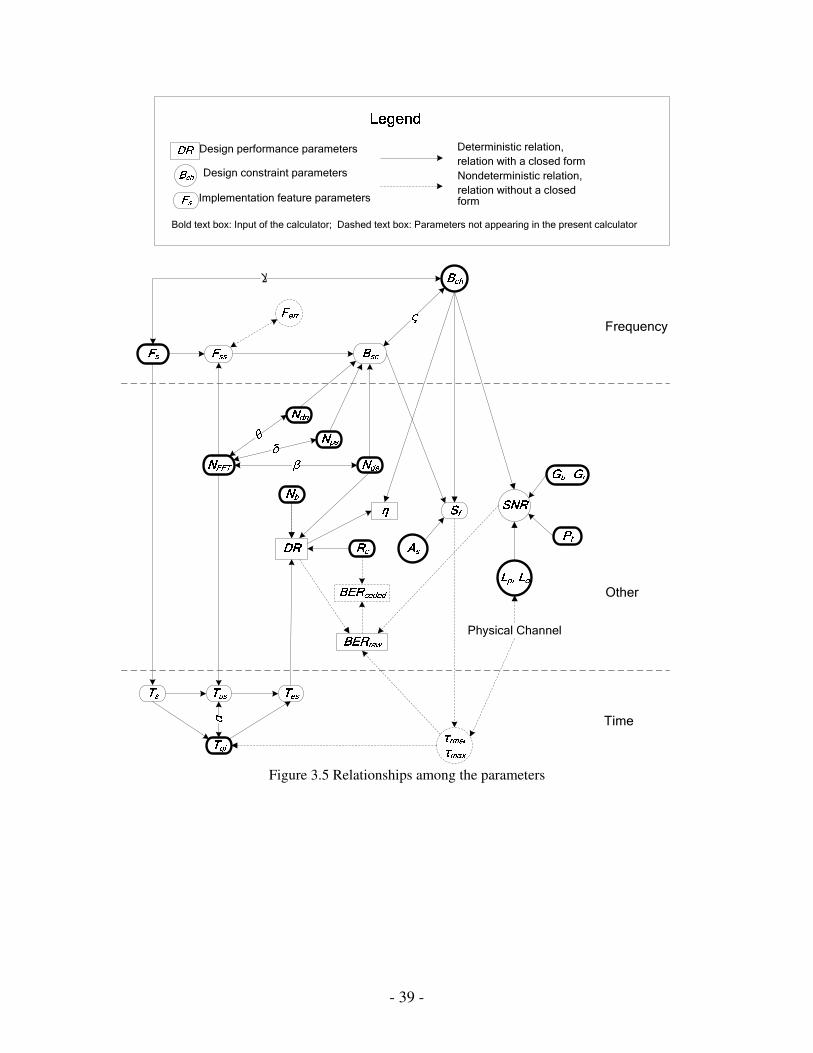
the three classes of parameters are inter-dependent, as depicted by Figure 3.1. For
instance, in order to make the system more robust against multi-path delay, a longer GI
length is desired and so is a longer symbol length. However, the symbol length is
restricted by the coherence time of the channel. More importantly, a longer symbol length
requires larger FFT size and smaller subcarrier spacing, making the system more costly
and more susceptible to synchronization error.
Traditionally, a Matlab model needs to be built to evaluate a specific design choice.
An ad-hoc approach might be to set some parameters, and then evaluate the overall
system performance. This method is time-consuming and the performance is not readily
predictable.
9 Although not every parameter mentioned below is directly related to the modulation and demodulation
cores, they will be discussed to give an overall picture. Emphasis will be put on the most relevant
parameters.
- 29 -
Design performance parameters
Implementation feature parameters
Design constraints parameters
Figure 3.1 Key parameters of an OFDM system and their relationship
To tackle the design challenges, a two-step approach has been proposed, as shown in
Figure 3.2. An Excel-based tool, called the OFDM Calculator, was used for rapid
exploration, concentrating on the most important relationships in the system, and then a
detailed model, written in Matlab, was built using the results of the OFDM Calculator to
fully explore the design space.
The OFDM Calculator explicitly and quickly demonstrates the impact of design
parameter adjustment, avoiding possible errors associated with manually tracking the
design changes. Different parameters sets can be compared side-by-side, to help the
efficient exploration of the design space. Detailed Matlab simulations precisely evaluate
the performance of a particular set of parameters, giving more insight further justifying
the design choices. Design iterations can be carried out quickly, since the two steps could
be seamlessly connected together by the parameter specification file generated by the
OFDM Calculator.
In Section 3.2, the ideas behind the OFDM Calculator will be elaborated. Following
that, the system-level design results of the proposed 60 GHz system will be described in
Section 3.3.
- 30 -
Rapid Exploration(OFDM Calculator)
Parameters Acceptable?
Y
Detailed Exploration(Matlab Simulation)
Specifications met?
Y
Next Design Phase(Architectural-Level
Design)
N
N
Parameter Spec. File
Step One
Step Two
Figure 3.2 Two-step system-level design approach
3.2 OFDM Calculator
The interrelationships between the key parameters are either deterministic or non-
deterministic. For the former, it is always possible to find an analytic equation between
the relevant parameters; for the latter, we can either utilize estimates of the parameters
involved wherever possible, or define a fourth category of parameters, so-called relation
parameters, to help describe the relationships.
Based on the above idea, the OFDM Calculator has been implemented, which takes a
subset of the parameters as basic inputs and automatically generates other parameters.
The core of the OFDM Calculator is the calculation of design performance parameters, i.e.
data-rate, spectral efficiency and BER estimate, while the design constraints and
- 31 -
implementation features will directly or indirectly contribute to the calculation. In
addition, a link budget calculation and other additional features have also been
implemented.
3.2.1 Data rate and spectral efficiency calculation
Assume all the subcarriers used adopt the same modulation scheme, i.e. without bit-
loading10
, it is easy to find that the un-coded data-rate DRraw is directly related to the un-
extended symbol length Tus, the guard interval length Tgi, the number of data subcarriers
Nds, and the number of bits per subcarrier per symbol Nb (the parameter representing the
modulation scheme), as follows:
=+
ds b
raw
us gi
N NDR
T T. (3.1)
Notice Tus is also the length of one FFT window, so for a system with FFT size NFFT,
sampling period Ts and sampling frequency Fs, Tus is:
= =FFT
us FFT S
s
NT N T
F. (3.2)
Thus (3.1) could be rewritten as:
11
= = × ++
ds b ds s b
raw
giFFT gi FFT
uss us
N N N F NDR
TN T N
TF T
. (3.3)
In order to reflect the impact of parameter choice on the system performance, we can
define a series of relation parameters, namely the guard interval (GI) to un-extended
symbol length ratio α, the data subcarrier number to FFT size ratio β, and the sampling
factor [MAN04] γ, to be:
=gi
us
T
Tα , (3.4)
10Equation (3.1) could be easily modified to take bit-loading into consideration. However, since the
proposed system, as a wireless transport system, will not adopt bit-loading, the OFDM Calculator has not
implemented this feature.
- 32 -
=ds
FFT
N
Nβ , (3.5)
=s
ch
F
Bγ , (3.6)
respectively, where Bch is the channel bandwidth, then the un-coded data rate could be
written as:
1=
+
ch b
raw
B NDR
βγ
α. (3.7)
Assume the channel coding rate is Rc, then the coded data rate DR and the spectral
efficiency of the system η, are:
1=
+
ch b cB N RDR
βγ
α, (3.8)
1=
+
b cN Rβγη
α. (3.9)
Now we can discuss the effect on the data rate and the spectral efficiency, and other
important aspects of the system, when adjusting relevant parameters.
First we need to check the significance of α . It indicates the transmission capacity
loss due to the time domain processing. This loss could also be expressed as SNR loss.
Since no information is transmitted during the GI period, the SNR loss due to the
insertion of the GI, SNRloss, could be calculated as [Eng02]:
10 10
110log 10log
1
= − = −+ +
usloss
us gi
TSNR
T T α. (3.10)
Based on (3.8) and (3.9), it is obvious we should reduce α , i.e. increase Tus and/or
reduce Tgi to get a higher data rate and spectral efficiency. However, their values are not
obvious to determine. For Tgi, enough length should be given for combating the ISI.
[NP00] suggests it be two to four times of rmsτ , the root-mean-squared delay spread11
,
while [Eng02] suggests that it should be as long as the length of the channel impulse
11 More on rmsτ will be discussed in section 3.3.
- 33 -
response, and furthermore, the filter response (of all the filters cascaded inside the system)
also needs to be incorporated into the channel impulse response.
As for Tus, there are two major constraints regarding its length. One constraint is the
channel coherence time: If the OFDM symbol is too long then the channel could not be
taken as time-invariant between consecutive channel estimation intervals and so the
performance will be degraded. The second, a more important constraint, is the
relationship between carrier recovery error Ferr and subcarrier spacing Fss, the inverse of
Tus. A detailed analysis of the effects of carrier recovery error is beyond the scope of this
thesis12
. An empirical requirement provided by [FK03] is:
0.02= <err
err us
ss
FF T
F. (3.11)
So Tus should take an appropriate value to alleviate the difficulty of carrier recovery.
Next we will check the significance of β andγ . β could be interpreted as the FFT
efficiency, representing how much of the FFT computation capability is contributing to
information transmission13
, while γ could be interpreted as the cost associated with
flexible up-sampling frequency choice, which can relax the reconstruction and anti-
aliasing filter sharpness requirement.
Based on (3.8) and (3.9), it seems that both β and γ should be increased to achieve
higher data rate and spectral efficiency. However, these two parameters are restricted by
the filtering requirement, as explained in the next section.
3.2.2 Filter sharpness requirement
As seen in Figure 3.3(a), the frequency band corresponding to Fs is divided into NFFT
equal-sized slots. In addition to Nds as the data subcarriers number, assume the number of
subcarriers used for pilot and signalling is Nps, for DC-Offset and notch is Ndn, then the
bandwidth corresponding to (Nds + Nps + Ndn) subcarriers is defined as the major energy
12 Simply put, carrier recovery error will introduce ICI and its effect could be modeled as AWGN if the
number of subcarriers is considerable. 13 This interpretation holds even when the FFT is used to directly manipulate only real signals, where β is
always less than 1/2 since in the frequency domain, half of the points are only the complex conjugate of the
other half. But the loss of FFT calculation capability has the payback of requiring only a single ADC and a
single DAC.
- 34 -
bandwidth (Bsc). The amplitude response mask specification for the low-pass
reconstruction and anti-aliasing filter14
is shown in Figure 3.3(b), where the passband and
stopband corner frequencies are ωp and ωs respectively, while the amplitudes for
passband and stopband are assumed to be 0 dB and As dB respectively.
(a)
(b)
Figure 3.3 Filter sharpness requirement. (a) Relationship between Bsc, Bch and Fs; (b) Filter
amplitude response requirement
14 In over-sampled system, the digital low-pass anti-aliasing filters are also included
- 35 -
The sharpness of the filter is a very critical parameter since it determines the degree
and thus the cost of the filter. It can be represented by the slope of the line in the
transition band, Sf, in dB/decade, calculated as:
1010loglog
= =
−
s s
f
scs
chp
A AS
B
B
ω
ω
. (3.12)
Since for a particular system, As is determined by the allowed radiated power into
neighbouring bands and the ADC resolution, it is normally a fixed known value. We
could thus define a filter sharpness factor, ς, to describe the filter sharpness requirement,
as following:
( ) ( )+ + + += = =
ds ps dn ss ds ps dnsc
FFT SSch FFT
N N N F N N NB
N FB N
γς
γ
. (3.13)
If we define the pilot and signaling subcarrier number to FFT size ratio δ, the DC-
Offset and notch subcarrier number to FFT size ratio θ, to be:
=ps
FFT
N
Nδ , (3.14)
=dn
FFT
N
Nθ , (3.15)
then (3.13) could be rewritten as:
( )= + +ς β δ θ γ . (3.16)
δ and θ could be interpreted as the FFT computation capability loss due to the overhead
of pilot and signaling, DC-Offset and notch, respectively. Meanwhile, since ς must be
less than 1, β and γ cannot be arbitrarily raised to achieve higher data rate and spectral
efficiency, as mentioned in last section.
While ( )+ +β δ θ γ represents the filter sharpness requirement, ( )1− + +β δ θ γ
could be interpreted as the capacity loss due to filtering. It is desirable to decrease this
loss, but a sharper filter will add additional dispersion to the channel impulse response,
- 36 -
and the GI length may need to be increased to combat the additional loss. It is possible to
find theoretical optimal values of the GI length and the filter specification such that the
overall capacity loss is minimized [Fau00], but considering the dynamic nature of the
channel, and the implementation cost, empirical choices are made instead.
So far the impact of the modulation scheme and channel coding, i.e. Nb and Rc, have
not been mentioned. They are heavily determined by achievable Signal-to-Noise-Ratio
(SNR), desired BER, and implementation cost, as discussed later.
3.2.3 BER estimate
In an Additive White Gaussian Noise (AWGN) channel, the BER performance of an
OFDM system should be the same as that of a single carrier system, except that the
equivalent SNR should take the power loss due to the guard interval into consideration.
Take a system with BPSK or QPSK for example, the BER is given as [HP03]:
( ),
1
2= =b AWGN bBER P erfc SNR , (3.17)
where erfc(x) is the complementary error function given by
22( )
∞−= ∫
t
x
erfc x e dtπ
, (3.18)
and SNRb is the effective SNR per bit that has taken the SNRloss as given by (3.10) into
account.
For an M-ary square QAM modulation scheme (e.g. 16-QAM used in the proposed
system), there is no a simple closed form equation to calculate the BER. The probability
of symbol error could be approximated by [Hay01]:
( ),
1 32 1
2 1
− −
b
s AWGN
SNRP erfc
MM� , (3.19)
and for the M-ary square QAM using Gray code (as will be implemented in the proposed
system), it can be shown that [Hay01]:
,
,
2log
≤ ≤s AWGN
s AWGN
PBER P
M. (3.20)
- 37 -
So these two bounds can be used to estimate BER.
In a more realistic channel, e.g. a Rayleigh fading channel, [HP03] has provided a
thorough theoretical analysis. We propose a more general approach assuming the channel
is known. Based on the channel knowledge, the equivalent SNR per bit of each subcarrier
could be calculated as
, ( )=b i bSNR SNR H i (3.21)
where H(i) is the term of the transfer function corresponding to subcarrier i. The BER for
each subcarrier could be calculated based on SNRb,i, and the BER of the system could be
calculated as the average of the BER for each subcarrier. However, this is only a loose
lower bound of the real system since the channel impulse response is supposed to be
known, and other noise in the system, e.g. the noise introduced by synchronization error,
and the noise smearing caused by the FFT windowing in the receiver side [Bin00], has
not been taken into account.
3.2.4 Link Budget calculation
A link budget is used to determine if the power and noise related operating conditions,
such as transmitted power level, transmitter antenna gain and receiver antenna gain could
guarantee the required SNR, and if so, how much design margin is left.
Tx Antenna Gain
Rx Antenna Gain
Path Loss Other Loss Noise FigureTx Power
Antenna Thermal Noise Power
Rx Power +
Figure 3.4 Link budget model
As shown in Figure 3.4, the received signal power Pr (expressed in dBm) is:
= + − − +r t t p o rP P G L L G , (3.22)
where
Pt is the transmitted power in dBm;
Gt is the transmitter antenna gain in dB;
Lp is the path loss in dB;
- 38 -
Lo is other loss in dB, caused by the channel, such as shadow, reflection, etc;
Gr is the receiver antenna gain in dB.
The path loss Lp could be calculated as [LMC04]:
10
420log
=
cp
dFL
c
π, (3.23)
where d is the distance between the transmitter and the receiver, Fc is the carrier
frequency, and c is the speed of light (3x108 m/s).
The noise in the system could be modeled as two parts, the thermal noise picked up
by the antenna, represented by Pn, and the noise added by the receiver analog front-end,
represented by the noise figure NF. Pn could be calculated in dBm as[LMC04]:
( )1010log 30= +n chP kTB , (3.24)
where k is Boltzmann’s constant (1.38x10-23
J/K), T is the Kelvin temperature of the
antenna, and Bch is the channel bandwidth.
So the achievable SNR is
= − −r nSNR P P NF , (3.25)
and if the required SNR is SNRreq, then the design margin is
= −m reqSNR SNR SNR . (3.26)
The above model only provides a first-order estimate, since the physical channel has
been simplified, and other sources of the noise, e.g. the transmitter noise, transmitter non-
linearity [LMC04] and the interferences from neighboring channels, have been ignored.
However, the result could still provide insight into the achievable SNR.
So far the interrelationships among the parameters have been briefly discussed. Figure
3.5 diagrammatically summarizes the relationships. Based on the rapid exploration results
generated by the OFDM Calculator, a detailed Matlab model for the proposed 60 GHz
radio was built, which will be introduced in the next section.
- 39 -
Physical Channel
Frequency
Other
Time
Design performance parameters
Design constraint parameters
Implementation feature parameters
Deterministic relation,
relation with a closed form
Nondeterministic relation,
relation without a closed form
3
Bold text box: Input of the calculator; Dashed text box: Parameters not appearing in the present calculator
Figure 3.5 Relationships among the parameters
- 40 -
3.3 Proposed 60 GHz System
This section will demonstrate the system-level design results of the proposed OFDM-
based 60 GHz radio. First the adopted channel model will be introduced, and then the
design results will be elaborated.
3.3.1 Channel model
A channel model plays a vital role in digital communication systems, and it is especially
true for OFDM systems where the overhead, efficiency and BER performance are
directly or indirectly related to the characteristics of the channel, as depicted in Figure 3.5.
60 GHz in-door channel models have been widely studied in the research community
[DT99][MC02][PKH98][BRO03]. A complete channel model covers three mechanisms
existing in the physical channels, namely path loss, shadowing and multi-path
interference, via large-scale and small-scale channel models, revealing both static and
dynamic features of the channels [PRA04]. Considering the impact on OFDM system
design, the introduction of a channel model in this section will focus on the most
important aspects of the multi-path interference, and related results for 60 GHz in-door
channels.
A multi-path channel consists of multiple paths each of which could be characterized
by its amplitude, phase and the propagation delay. The time-variant impulse response of
the channel, as a contribution of all the paths, can be denoted as h(t, τ), representing the
impulse response of the channel at time t due to an impulse applied at time t- τ [FK03].
The complex baseband equivalence of h(t, τ) is [BRO03] [Pra04]:
( ) ( )1
0
,−
=
= −∑k
k
Nj
k k
k
h t a eθτ δ τ τ , (3.27)
where Nk is the variable number of paths, ak, θk and τk are the amplitude, phase and
propagation delay of the kth path respectively, and δ( ) is the Dirac delta function. Based
on the impulse response, the channel transfer function is
( ) ( )1
2
0
,−
−
=
= ∑k
k k
Nj f
k
k
H f t a eθ π τ
. (3.28)
- 41 -
Generally ak, θk and τk are time variant and many studies have been carried out on the
modeling and measurement of their statistics. We are especially interested in the
propagation delay of the channel due to its impact on the OFDM systems. The maximum
delay τmax and the root mean square delay spread τrms could be defined to summarize the
propagation delay feature. Assume that the shortest path has a propagation delay of zero,
then τmax is the longest delay among all the paths, while τrms is
12 2
0
12
0
( )−
=−
=
−
=∑
∑
k
k
N
k m k
krms
N
k
k
a
a
τ τ
τ , (3.29)
where τm is the mean delay spread defined as
12
0
12
0
−
=
−
=
=∑
∑
k
k
N
k k
km
N
k
k
a
a
τ
τ . (3.30)
The channel impulse response of an in-door channel, and hence τmax and τrms are
determined by the room geometry and material, relative locations of the transmitter and
receiver, antenna radiation patterns, and whether it is LOS or NLOS situation. Due to the
above factors, different research results have been reported. For example, [MC02]
presents a multi-ray-tracing model for a long corridor of 44x2.20x2.75 m3, with brick and
plasterboard surface wall and LOS situation. The simulated τrms varies with transmitter
and receiver distance from 0.57 ns to 2.32 ns using isotropic antennas. When the value of
τrms using isotropic antennas is 2.13 ns for a transmitter and receiver distance of 30 m, it
changes to 1.18 ns and 1.58 ns with Omni-Omni and Horn-Horn antennas respectively.
[PKH98] gives both measurements and a statistical model results for a typical office with
windows, partitions and furniture. Different relative position and antenna configurations
were carried out and the τrms is less than 55 ns for all possibilities. [DT99] used a ray-
tracing based model for an office with furniture. The cumulative distribution function of
the τrms shows that τrms is up to 20 ns, while the probability of τrms > 10 ns is 6% to 20%
depending on the receiver antenna types.
- 42 -
In our research, both AWGN and time-invariant multi-path channel are used to
simplify the simulation. The multi-path channel model is generated by assuming a
number of propagation paths with random lengths, and restricting τrms <55 ns.
3.3.2 Design results
With the objective of supporting the Gigabit Wireless Ethernet (GWE), the most crucial
parameters for the proposed 60 GHz system are summarized in Table 3.1, and a detailed
comparison with other OFDM standards is given in Appendix A, where another
comparison of our proposed design with other two 60 GHz OFDM projects is also given.
Parameter Symbol Value
Channel bandwidth Bch 512 MHz
Sampling frequency Fs 512 MHz
Sampling factor γ 1
FFT size NFFT 1024
Number of used subcarriers Nsc 912
Number of data subcarriers Nds 880
Nds to NFFT ratio β 0.86
Number of pilot and signaling subcarriers Nps 32
Nps to NFFT ratio δ 0.03125
Number of DC & notch subcarriers Ndn 1
Ndn to NFFT ratio θ 1/1024
Sample period Ts 1/512 µs
Un-extended symbol length Tus 2 µs
GI length Tgi 0.25 µs
Tgi to Tus ratio α 1/8
Extended symbol length Tes 2.25 µs
Sub carrier spacing Fss 500 kHz
Major energy bandwidth Bsc 456.5 MHz
Filter sharpness factor ς 0.89
Modulation BPSK, QPSK, 16-QAM
FEC coding TBD
Max. uncoded data rate DRraw 1.56 Gbps
Max. data rate DR TBD
Max. spectral efficiency (uncoded) ηraw 3 b/s/Hz
Table 3.1 Proposed 60 GHz OFDM System
Some important considerations when choosing these parameters are:
- 43 -
o The maximum DRraw reaches 1.56 Gbps, so with reasonable channel coding,
supporting GWE is possible. However, the choice of channel coding technique
needs further research.
o The maximum spectral efficiency for the uncoded system is 3 b/s/Hz.
o The BER performance target is application dependant. For instance, MPEG-2
video requires BER=10-11
, and in DVB-T this is achieved using a concatenated
convolutional code and Reed-Solomon code, while the BER performance after the
Viterbi decoding for the convolutional code (i.e. the inner code performance) is
required to be 2×10-4
[DVB04]. For the proposed baseband system without coding,
a BER performance target of 10-4
is considered. To meet this BER performance
target, the RF front-end proposed by [Yao05] is assumed, which can provide
transmitter power (Pt) of 20 dBm15
and transmitter antenna gain (Gt) of 20 dB.
When the distance is 10 m, the SNR is 19.55 dB with 20 dB design margin.
o Fs is chosen to be 512 MHz so that the DAC and ADC with the required ENOB
(Effective Number Of Bits) of 10 bits16
are technically feasible.
o NFFT is 1024 so that a radix-4 FFT/IFFT could be adopted.
o The choice of Tgi as 250 ns is based on the observation that τrms is less than 55 ns
in [PKH98] and the rule of thumb that GI should be two to four times of τrms as
proposed in [NP00].
o The impact of FSS17
needs further research.
o Nps and Ndn need further research.
The proposed modulation and demodulation core will incorporate all the functions as
shown in Figure 2.8. Some of the involved design aspects cannot be described by Table
3.1, e.g. the exact form of the time domain window, and the frequency domain processing.
These features are embedded into the Matlab model and simulated to evaluate the design
choice. The BER performance simulation results for the system-level model, a double-
15 This is within the 40 dBm EIRP (Effective Isotropic Radiated Power) emission regulation of the 60 GHz
band [Yao05][FCC05]. 16 See the finite word-length effect evaluation section of Chapter 4. 17 The Broadway project, targeting in next-generation wireless LAN operating at 60 GHz, chooses FSS to be
512 kHz [BRO04].
- 44 -
precision-floating-point number based model, can be found in Appendix C, where it is
compared with architectural level model simulation result.
- 45 -
4. Architectural Level Design
This chapter describes the architectural level design for the proposed OFDM system. First,
the design challenges and proposed solution are introduced, and then the overall design is
summarized. Next the detailed fixed-point model transformation and hardware
transformation of the FFT/IFFT block are elaborated.
4.1 Design Challenges and Proposed Solution
Architectural level design is the design phase that transfers a system level model into a
hardware oriented model, exploring the intrinsic parallelism of the algorithm, studying
implementation alternatives and making architectural decisions.
The most dominant design challenge at the architectural level of the design is to
achieve the desired performance with minimum cost. Architectural level design has
considerable impact on the intrinsic hardware performance and cost criteria such as
timing, area and power. For the modulation and demodulation cores, the timing
requirements are especially challenging. Furthermore, functional performance criteria are
also affected by architectural level design choices, – when the algorithmic model is
transformed into an architectural model, the ideal assumptions made in the algorithmic
model are usually simplified or replaced by the non-ideal hardware to lower the
implementation cost with acceptable performance loss. For example, finite word-length
effects impose additional noise onto the system, and the BER performance will be
degraded.
An iterative design flow is adopted, as shown in Figure 4.1. Major architectural level
design tasks of the proposed system include:
Fixed-point model transformation. Unlike the unlimited-precision algorithmic
model used in the system level design, the architectural model is based on fixed-point
number18
with finite word-length. To alleviate the degradation caused by possible
truncation, rounding or overflow due to the finite word-length, sufficient word-length,
18 An algorithm can also be implemented in floating-point format, but with higher area and power cost.
Besides, the floating-point implementation is not necessary for the proposed system.
- 46 -
appropriate position of the decimal points, and proper scaling should be assigned to all
the data operands. On the other hand, wider word-lengths will result in larger area, slower
data-path and larger power consumption. A systematic method must be adopted for
optimizing the finite word-lengths in the system to balance the performance loss and the
area and timing penalty.
Word-length optimization
Functional Performance Acceptable?
Y
Performance and cost Acceptable?
Y
Next design phase(RTL design and backend flow)
N
N
Fixed-point model transformation
Hardware transformation
Allocation
Scheduling
Binding
Figure 4.1 Architectural level design flow
Hardware transformation. An ideal solution for the hardware transformation
problem is to have a high-level synthesizer to automatically synthesize the algorithmic
model into RTL (register transfer level) model. Some commercial tools, e.g. [ACC05],
are presently available. Due to the high throughput requirements and the complexity of
the design considered in this thesis, a manual transformation process is adopted.
- 47 -
Nevertheless, like the high-level synthesis EDA tools [GR94], the following three tasks
also exist in the manual procedure:
Allocation: Determining the number and functionality of the processing elements (PEs);
Scheduling: Deciding the start time of individual operation;
Binding: Assigning the operations to available PEs.
These steps could occur repeatedly at different granularity until the RTL code could be
easily generated from the specification. For instance, generally two granularity levels, the
macro architectural design and the micro architectural design will happen, where the
former focuses on functional block identification, block interface definition, global
control and data flow arrangement, while the latter focuses on pipelining and parallel
processing unit arrangement, detailed data-path and local control design.
As seen in Figure 4.1, the fixed-point model transformation and the hardware
transformation may happen iteratively, because the word-lengths of the fixed-point model
will affect the architecture choices. For instance, operations involving the same function
and same word-length could easily share one PE, while it may be better to allocate
different PEs for the operations with different word-lengths even if the operations are
identical.
For the baseband processing system, the fixed-point model transformation will be
carried out using statistical analysis and simulation, while a graph projection technique
[Kun88] will be utilized to tackle the three tasks involved in the hardware transformation
simultaneously.
4.2 Overview of the Design
The block diagram of the macro architecture is shown in Figure 4.2. It is different from
the functional block diagram of Figure 2.8 since the blocks in Figure 4.2 correspond to
the physical building units instead of abstract functionality.
The system works in one of two modes: transmitter mode, where all the blocks with a
dark background are involved, or receiver mode, where all the blocks with a light
background are involved. The functions of the individual blocks are:
- 48 -
Input Buffer Modulator Framer
Output Buffer Demodulator Deframer
FFT/ IFFT
I, Q I, Q
I, QI, Q
Data in
Data out
DAC data
(I, Q)
ADC data
(I, Q)
Figure 4.2 Architectural block diagram of the proposed system
Input Buffer / Output Buffer: Isolate the modulation and demodulation core from the
rest of the system, so that flow control could be simplified and the system can work in
a “best effect” manner with simplified global control.
Modulator: Implements the constellation mapping and frequency domain processing
functions with a loop-up table based method as discussed later.
Demodulator: Implements the frequency domain correction and constellation
demapping functions.
FFT/IFFT: Acts as IFFT block in transmitter mode and FFT block in receiver mode.
Framer: Implements the time domain processing functions.
Deframer: Implements the frame synchronization functions.
In the transmitter mode, once the input buffer is filled above a configurable threshold
depth, the transmitter path will begin working to periodically generate the OFDM mega-
symbols, until the buffer is empty. Zero values may need to be padded into the data
stream read from the buffer to generate a complete mega-symbol.
In the receiver mode, a start-of-symbol signal initiates the receiving processing
procedure, and the demodulated data stream is stored in the output buffer, waiting to be
read out.
At the macro architectural level, a macro pipeline is formed by all the blocks with the
workload unit of a mega-symbol. That is, each mega-symbol will encounter an identical
processing flow in any block, while different blocks could work on different mega-
symbols simultaneously. Meanwhile, each block contains its own micro pipeline with the
- 49 -
workload unit of a data sample, so a block could work on multiple samples that belong to
either one mega-symbol or adjacent mega-symbols simultaneously. This two layered
pipelining provides a processing stream that has short latency and high PE efficiency.
To provide enough throughput, in addition to the pipelining, four parallel processing
datapaths are also used, as explained later.
Of all the blocks shown in Figure 4.2, the FFT/IFFT block is the most critical and
challenging block, since it is the performance bottleneck and its finite word-length effects
determines the overall fixed-point model of the system. Other blocks in Figure 4.2 can be
(relatively) easily implemented based on their functional description. So in the following
sections, the FFT/IFFT block will be further described.
4.3 FFT/IFFT Block
For the 1024-point FFT/IFFT used in the proposed system, both radix-2 and radix-4
algorithms are possible architectural alternatives, but a radix-4 architecture is used since
it is possible to implement 4 parallel data-paths to meet the throughput requirement
without introducing a critical timing closure problem. To illustrate the algorithm, the SFG
(Signal Flow Graph) of a radix-4 DIF (Decimation In Frequency) 64-point FFT is shown
in Figure 4.3, where the base of the twiddle factors, ( )/8−=
jW e
π. A basic building block,
the radix-4 butterfly is shown in Figure 4.4, which consists of four 4-input complex
number adders (also named the crossadder due to the geometric shape) and 3 complex
number multipliers (also named the rotator since the complex number multipliers only
rotate the phases of the input complex number without changing their amplitudes).
The following sections will discuss the fixed-point model transformation and the
hardware transformation of the IFFT/FFT block in detail.
- 50 -
X[0]
X[4]
X[8]
X[12]
X[1]
X[5]
X[9]
X[13]
X[2]
X[6]
X[10]
X[14]
X[3]
X[7]
X[11]
X[15]
W0
W0
W0
W0
W0
W1
W2
W3
W0
W2
W4
W6
W0
W3
W6
W9
W0
W0
W0
W0
W0
W0
W0
W0
W0
W0
W0
W0
W0
W0
W0
W0
x[0]
x[1]
x[2]
x[3]
x[4]
x[5]
x[6]
x[7]
x[8]
x[9]
x[11]
x[12]
x[13]
x[14]
x[15]
x[10]
Figure 4.3 16-point radix-4 DIF FFT SFG
Figure 4.4 Butterfly of radix-4 DIF FFT
- 51 -
4.3.1 Fixed-point model transformation of the FFT/IFFT block
4.3.1.1 Issues for fixed-point model transformation
When transferring the FFT/IFFT block into a fixed-point model, sources of noise include
the round-off noise in rounding the results of the complex multipliers to retain certain
word-lengths, the round-off noise in scaling the data to prevent overflows, and the
quantization noise in representing the twiddle factors using finite-word-length. These
effects happen in each stage of the algorithm and are propagated along the calculation
path. In addition, other factors such as number representation scheme also affect the
characteristics of the noise. Specifically, in the context of OFDM systems, one needs to
determine the following issues for the fixed-point model transformation:
Number representation scheme. The number representation choice will affect the
type of computational elements and implementation costs. A two’s complement number
system is chosen since it generally gives good results and it is well supported by the
dedicated multipliers of the targeted prototype FPGA19
.
Single word-length vs. multiple word-length. In a single word-length scheme, a
uniform word-length is used to represent all data operands, while in a multiple word-
length scheme, the word-lengths for individual data operands could be freely chosen
when necessary [CCL01] [CCL04]. We will focus on the multiple word-length scheme
since it can provide a good balance between performance and cost.
Word-lengths of individual objects. For each FFT stage, the word-lengths for the
crossadder input and output, the twiddle factors, the intermediate results and the final
results all need to be determined. This will be a major task and it will be further discussed
later.
Static scaling vs. dynamic scaling. In a static scaling scheme, the scaling factor of
each FFT stage is fixed, so the implementation is simple but the range of represented data
is also fixed. A dynamic scaling scheme, such as the convergent Block Floating Point
(BFP) [BCJ95] scheme, will decide the scaling factor according to the calculation result
on-the-fly, and it could combine the benefits of both the floating-point and the fixed-point
19 For an ASIC version, DesignWare from Synopsys also supports two’s compliment arithmetic well.
- 52 -
paradigms. The static scaling scheme will be chosen since consecutive OFDM samples
are transmitted in the same signal amplitude level and thus require the same word-length
format, so it is not necessary to consider the dynamic scheme, at least in the transmitter
side. In addition, as shown later, the static scheme could meet the performance
requirements with reasonable cost.
Degradation schemes. Whenever an overflow is about to happen20
, a choice must be
made to let it overflow freely or saturate instead. Meanwhile, choice must be made
between rounding and truncation to constrain word-length increase.
Numerical value mapping. The modulated complex symbols from the modulator as
shown in Figure 4.2, e.g. 1
( 3 3j)10
± ± for a modulation scheme of 16-QAM, need to be
further mapped into appropriate values to make the best use of the calculation capability
of the architecture, so that the highest possible SNR could be achieved. At the same time,
the DAC/ADC has certain ENOB limits, so the sample values after the IFFT need to be
mapped into the DAC appropriately so that the achieved PAPR and the SNR degradation
are within specification.
In the following sections, based on previous research on the finite word-length effects
of the FFT, a proposed solution particularly targeted at the overall fixed-point model
transformation for the OFDM system will be described.
4.3.1.2 Summary of previous research on the finite word-length effects of FFT
Appendix B gives a detailed description of two previous studies on the effect of finite
word-length on FFTs. Some useful observations are:
1). Overflow is regarded as a severe degradation, and so it is to be avoided by all
means. Scaling is a widely used approach to prevent overflow. One scaling method is to
only scale the input of the FFT, and it has been shown in [OSB99] that such a scaling
method in the single word-length FFT implementation has the signal-to-noise ratio of
2
2
2=
B
fweSNRN
, (4.1)
20 Overflow can be totally avoided in the FFT algorithm itself by appropriate scaling. However, as will be
seen later, when the time-domain sample values are mapped to DAC input, overflow events are still of
concern.
- 53 -
for an N-point radix-2 DIT (Decimation In Time) FFT with word-length of (B+1)-bits.
An improved scaling method to prevent overflow is to scale the input of each FFT stage.
It has been shown in [OSB99] that once the input to the FFT could guarantee no overflow
in the first stage21
, then for a radix-2 FFT simply scaling the input of each FFT stage by
½ can prevent overflow in all stages and the signal-to-noise ratio is now
22
4=
B
fweSNRN
. (4.2)
2). Since scaling will generate additional noise, a better method to prevent overflow is
to increase the word-length of each FFT stage. Once the input to the FFT could guarantee
no overflow in the first stage22
, then for a radix-2 FFT simply increase the word-length of
each FFT stage by one bit can prevent overflow. This is actually the root of multiple
word-length scheme used in FFT.
3). A combination of scaling and word-length expanding lets the word-length increase
for the early stages, and maintain a fixed word-length but use scaling after a certain stage
to achieve a balance of performance and area cost, because the noise source in the early
stages have more negative effect and so it is better to avoid scaling in the early stages.
[PD01] presents a detailed noise model for analyzing this kind of combined
implementation.
The above finite word-length effects analysis can provide a good insight and guideline
for the appropriate word-length choice. It is also worth noting that the above method can
be adapted for any radix algorithm, once the word-length scheme is static and uniform
per stage. Take radix-4 FFT/IFFT for example, to prevent overflow, the required scaling
is 1/4 or the required word-length expansion is 2 bits.
However, to fully resolve all the issues for the fixed-point model transformation, the
cascade of individual blocks in the signal processing chain needs further analysis. Besides,
21 If all numbers are interpreted as fractional number, then a scaled sequence whose real and imaginary
parts are uniformly distributed between 1/ 2− and1/ 2 is a sufficient sequence to guarantee no overflow
in the first FFT stage. However, since this input also needs to be scaled by 1/2 before the first stage, we can
supply a sequence whose real and imaginary parts are uniformly distributed between 1/ 2 2− and1/ 2 2 ,
and only scale the inputs of other stages except the first stage.
22Again a scaled sequence whose real and imaginary parts are uniformly distributed between 1/ 2−
and1/ 2 is a sufficient sequence to guarantee no overflow in the first FFT stage.
- 54 -
no clue has been given for the numerical value mapping issue. The following section will
present an overall solution.
4.3.1.3 Proposed solution
The general idea of the proposed solution is: First, assume the IFFT, FFT are ideal
without finite word-length effects, and the quantization only happens at the DAC/ADC,
then find the appropriate ENOB for the DAC/ADC and the numerical value mapping
scheme to meet the PAPR requirement and BER requirement; Second, analyze and
choose the appropriate FFT/IFFT word-length scheme so that the achieved performance
of the previous step will not be seriously degraded; Finally, verify and fine-tune the
choice with simulation. Detailed description of this solution follows.
Assume the IFFT and FFT are ideal, then the statistics of the time-domain OFDM
signal need to be studied to evaluate the quantization effect of the DAC and ADC. As
explained in Chapter 2, both the in-phase and quadrature components of the OFDM
signal are very close to a Gaussian process with zero mean and variance σ2 , and two
DACs and two ADCs are needed in the transmitter side and the receiver side respectively.
To quantize these two signals, two questions need to be answered:
What range of the signal needs to be quantized? As seen in Figure 4.5, if [-uσ, uσ] is
the range of the signal to be quantized, then what is an appropriate value for u?
How many bits are needed to quantize this data range? i.e. what should the ENOB be ?
The quantization procedure could be modeled as an ideal quantization with infinite
precision followed by two kinds of additive quantization noise, the clipping noise and the
rounding noise, as shown in Figure 4.5. A clipping noise is introduced once clipping
happens and the variance of the noise is inversely proportional to the value of u, while the
rounding noise happens for every data sample and is determined by both u and the ENOB:
if u is unchanged, then larger ENOB will result in smaller rounding error variance; if
ENOB is unchanged, then larger u will result in bigger rounding error variance.
- 55 -
+Quantized signal
Rounding noise
Clipped value
2 steps
Clipping noise
Infinite
-
Figure 4.5 DAC/ADC quantization model with clipping noise and rounding noise
So the clipping noise and rounding noise present conflicting requirements in the
selection of u. At the same time, considering the allowed PAPR of the system, especially
the achievable linearity range of the analog front-end, it is desirable to have a smaller u.
An empirical value of u provided by [HP03] is around 3 or 4, since under such values the
clipping probabilities are about 3x10-3
and 6x10-5
respectively, and are negligible
compared with other noise sources in the system. However, the corresponding PAPRs are
about 9.5 dB and 12 dB respectively, probably still too high for the analog front-end. So
the final choice may depend on the overall allowed PAPR of the analog front-end.
For the rounding noise, assume BQ bits are used for both the DAC and the ADC23
.
Since the in-phase and quadrature are both Gaussian distributed, it can be proved that the
rounding noise is zero-mean and its variance is [SS77]:
( )2
2 2 2 2
2 2 21
112 21 exp
12
∞
=
− ∆= + −
∆ ∑
n
Q
n
n
n
π σσ
π, (4.3)
where ∆ is the quantization step defined as
2
2∆ =
QB
uσ. (4.4)
It can also be shown that when / 1σ ∆ ≥ , (4.3) is very close to 2 /12∆ and so the error
follows a uniform distribution. This condition is easily satisfied since
23 The ENOB for ADC should not be less than that of DAC, so that the performance achieved at the
transmitter could not be lost by the ADC, at the same time certain margin is left for the AGC (Automatic
Gain Control) misalignment. For brevity, here the ENOBs for ADC and DAC are assumed to be the same.
- 56 -
12 −
=∆
QB
u
σ. (4.5)
We are very interested in the signal-to-noise ratio, which is
22
2 2 2
2
3 2
12
⋅= =
∆
QB
Q u
σ σ
σ, (4.6)
or in dB form:
2
2 2
10 10 10 102
3 210log 10log 3 20 log 2 20log
⋅= = + −
QB
Q
Q
B uu
σ
σ. (4.7)
So one more bit of BQ will give 6 dB more signal-to-noise ratio. Table 4.1 illustrates a
series of possible design choices for the proposed baseband processing system. The
signal-to-noise ratio should be interpreted with caution: First, the clipping noise of the
quantization procedure has been ignored under particular choice of u; Second, the
rounding error is uniformly distributed, so its effect on the final BER performance is not
Gaussian. Nevertheless, it still gives a good insight into possible system performance, and
its usage will be justified by simulation.
u BQ SNRid_fft
3 8 43.4 dB
3 10 55.4 dB
3 12 67.4 dB
4 8 40.9 dB
4 10 52.9 dB
4 12 64.9 dB
Table 4.1 Signal-to-rounding-noise ratio with ideal IFFT/FFT
Now the finite word-length effects of the IFFT and FFT and the numerical value
mapping scheme should be considered. Figure 4.6(a) illustrates all the blocks that are
closely related to the finite word-length effects of the IFFT and FFT, and the word-
lengths between adjacent block boundaries. Only the in-phase component of the complex
baseband signal is demonstrated for brevity since the quadrature component will traverse