28
Beam-Width Prediction for Efficient Context-Free Parsing Nathan Bodenstab, Aaron Dunlop, Keith Hall, Brian Roark June 2011
| Date post: | 26-Dec-2015 |
| Category: |
Documents |
| Upload: | arleen-short |
| View: | 215 times |
| Download: | 1 times |

Beam-Width Prediction for Efficient Context-Free Parsing
Nathan Bodenstab, Aaron Dunlop, Keith Hall, Brian Roark
June 2011

OHSU Beam-Search Parser (BUBS)
2
• Standard bottom-up CYK
• Beam-search per chart cell
• Only “best” are retained

Ranking, Prioritization, and FOMs
• f() = g() + h()
• Figure of Merit– Caraballo and Charniak (1997)
• A* search– Klein and Manning (2003)
– Pauls and Klein (2010)
• Other– Turrian (2007)
– Huang (2008)
• Apply to beam-search
3

Beam-Width Prediction
• Traditional beam-search uses constant beam-width
• Two definitions of beam-width:– Number of local competitors to retain (n-best)– Score difference from best entry
• Advantages– Heavy pruning compared to CYK– Minimal sorting compared to global agenda
• Disadvantages– No global pruning – all chart cells treated equal– Conservative to keep outliers within beam
4

5
Beam-Width Prediction
• How often is gold edge ranked in top N per chart cell– Exhaustively parse section 22 + Berkeley latent variable grammar
Gold rank <= N
Cum
ulat
ive
Gol
d E
dges

6
Beam-Width Prediction
• How often is gold edge ranked in top N per chart cell– Exhaustively parse section 22 + Berkeley latent variable grammar
Gold rank <= N
Cum
ulat
ive
Gol
d E
dges

7
Beam-Width Prediction
• Beam-search + C&C Boundary ranking: – How often is gold edge ranked in top N per chart cell:
Gold rank <= N
Cum
ulat
ive
Gol
d E
dges
To maintain baseline accuracy, beam-width must be set to 15 with C&C Boundary ranking (and 50 using only inside score)
To maintain baseline accuracy, beam-width must be set to 15 with C&C Boundary ranking (and 50 using only inside score)

8
Beam-Width Prediction
• Beam-search + C&C Boundary ranking: – How often is gold edge ranked in top N per chart cell:
Gold rank <= N
Cum
ulat
ive
Gol
d E
dges
To maintain baseline accuracy, beam-width must be set to 15 with C&C Boundary ranking (and 50 using only inside score)
To maintain baseline accuracy, beam-width must be set to 15 with C&C Boundary ranking (and 50 using only inside score)
• Over 70% of gold edges are already ranked first in the local agenda
• 14 of 15 edges in these cells are unnecessary
• We can do much better than a constant beam-width
• Over 70% of gold edges are already ranked first in the local agenda
• 14 of 15 edges in these cells are unnecessary
• We can do much better than a constant beam-width

Beam-Width Prediction
• Method: Train an averaged perceptron (Collins, 2002) to predict the optimal beam-width per chart cell
• Map each chart cell in sentence S spanning words wi … wj to a feature vector representation:
• x: Lexical and POS unigrams and bigrams, relative and absolute span• y:1 if gold rank > k, 0 otherwise (no gold edge has rank of -1)
• Minimize the loss:
• H is the unit step function
9
k
k

Beam-Width Prediction
• Method: Use a discriminative classifier to predict the optimal beam-width per chart cell• Minimize the loss:
• L is the asymmetric loss function:
• If beam-width is too large, tolerable efficiency loss• If beam-width is too small, high risk to accuracy• Lambda set to 102 in all experiments
10
k

11
Beam-Width Prediction
Special case: Predict if chart cell is open or closed to multi-word constituents

12
Beam-Width Prediction
• A “closed” chart cell may need to be partially open• Binarized or dotted-rule parsing creates new “factored”
productions:

13
Beam-Width Prediction
Method 1: Constituent Closure

14
Beam-Width Prediction
• Constituent Closure is a per-cell generalization of Roark & Hollingshead (2008)– O(n2) classifications instead of O(n)

15
Beam-Width Prediction
Method 2: Complete Closure

16
Beam-Width Prediction
Method 3: Beam-Width Prediction

17
Beam-Width Prediction
Method 3: Beam-Width Prediction
• Use multiple binary classifiers instead of regression (better performance)
• Local beam-width taken from classifier with smallest beam-width prediction
• Best performance with four binary classifiers: 0, 1, 2, 4– 97% of positive examples have beam-width <= 4– Don’t need a classifier for every possible beam-
width value between 0 and global maximum (15 in our case)

18
Beam-Width Prediction

19
Beam-Width Prediction
1.0
0.8
0.6
0.4
0.2
0.0

20
Beam-Width Prediction
• Section 22 development set results
• Decoding time is seconds per sentence averaged over all sentences in Section 22
• Parsing with Berkeley latent variable grammar (4.3 million productions)
Parser Secs/Sent Speedup F1
CYK 70.383 89.4
CYK + Constituent Closure 47.870 1.5x 89.3
CYK + Complete Closure 32.619 2.2x 89.3

21
Beam-Width Prediction
Parser Secs/Sent Speedup F1
CYK 70.383 89.4
CYK + Constituent Closure 47.870 1.5x 89.3
CYK + Complete Closure 32.619 2.2x 89.3
Beam + Inside FOM (BI) 3.977 89.2
BI + Constituent Closer 2.033 2.0x 89.2
BI + Complete Closure 1.575 2.5x 89.3
BI + Beam-Predict 1.180 3.4x 89.3

22
Beam-Width Prediction
Parser Secs/Sent Speedup F1
CYK 70.383 89.4
CYK + Constituent Closure 47.870 1.5x 89.3
CYK + Complete Closure 32.619 2.2x 89.3
Beam + Inside FOM (BI) 3.977 89.2
BI + Constituent Closer 2.033 2.0x 89.2
BI + Complete Closure 1.575 2.5x 89.3
BI + Beam-Predict 1.180 3.4x 89.3
Beam + Boundary FOM (BB) 0.326 89.2
BB + Constituent Closure 0.279 1.2x 89.2
BB + Complete Closure 0.199 1.6x 89.3
BB + Beam-Predict 0.143 2.3x 89.3

Beam-Width Prediction
23
Parser Secs/Sent Speedup F1
CYK 70.383 89.4
CYK + Constituent Closure 47.870 1.5x 89.3
CYK + Complete Closure 32.619 2.2x 89.3
Beam + Inside FOM (BI) 3.977 89.2
BI + Constituent Closer 2.033 2.0x 89.2
BI + Complete Closure 1.575 2.5x 89.3
BI + Beam-Predict 1.180 3.4x 89.3
Beam + Boundary FOM (BB) 0.326 89.2
BB + Constituent Closure 0.279 1.2x 89.2
BB + Complete Closure 0.199 1.6x 89.3
BB + Beam-Predict 0.143 2.3x 89.3
Most recent numbers 0.053 6.2x 89.x

24
Beam-Width Prediction
• Section 23 test results• Only MaxRule is marginalizing over latent variables and
performing non-Viterbi decoding
Parser Secs/Sent F1
CYK 64.610 88.7
Berkeley CTF MaxRule Petrov and Klein (2007)
0.213 90.2
Berkeley CTF Viterbi 0.208 88.8
Beam + Boundary FOM (BB) Caraballo and Charniak (1998)
0.334 88.6
BB + Chart Constraints Roark and Hollingshead (2008; 2009)
0.244 88.7
BB + Beam-Prediction 0.125 88.7

Thanks.
25
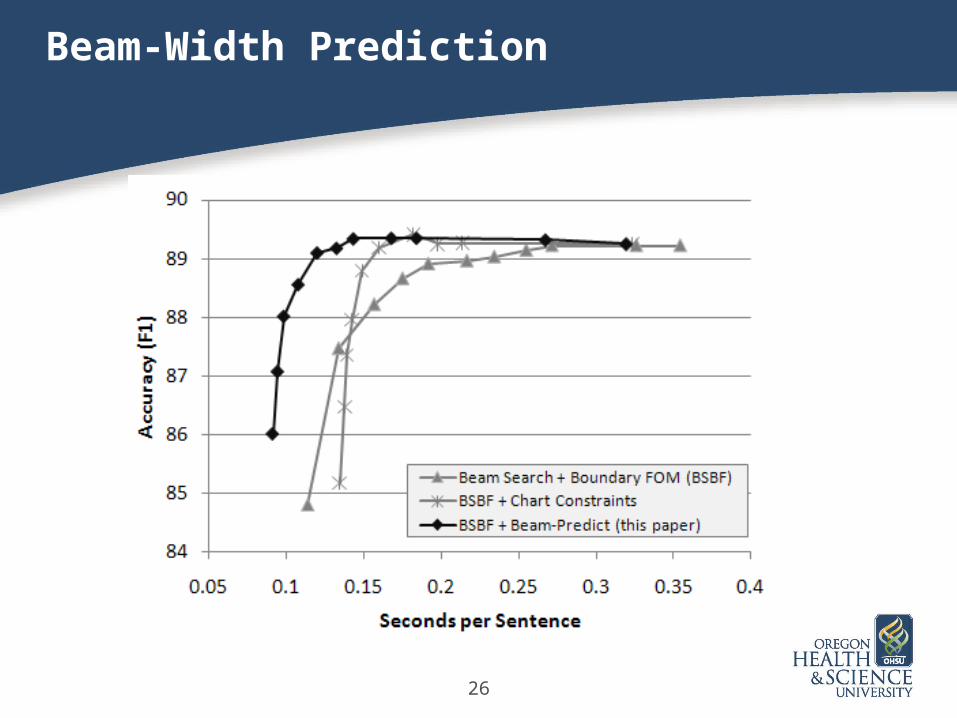
26
Beam-Width Prediction

27
FOM Details
• C&C FOM Details– FOM(NT) = Outsideleft * Inside * Outsideright
– Inside = Accumulated grammar score
– Outsideleft = MaxPOS [ POS forward prob * POS-to-NT transition prob ]
– Outsideright = MaxPOS [ NT-to-POS transition prob * POS bkwd prob ]

28
FOM Details
• C&C FOM Details

















