37
| Date post: | 27-Jan-2016 |
| Category: |
Documents |
| Upload: | sanjeev-singh |
| View: | 25 times |
| Download: | 7 times |


SAP Business Information Warehouse Getting a better view of the business

The SAP Business Information Warehouse (SAP BW) allows you to analyze data from operative SAP applications and other business applications, and external data sources such as databases, online services and the Internet. The administrator functions are designed for controlling, monitoring and maintaining all data retrieval processes. It becomes critical to keep the BW healthy to have optimal results.
Let’s see how!

1. Compress Data Regularly

ScenarioWhen data is loaded into an InfoCube, the data is
organized by requests (InfoPackage ID's). Each request has its own request ID, which is included in the primary key of fact table and in the packet dimension. However, because the request ID is included in the primary key of the fact table, it is possible that the same data record (all characteristics agree, with the exception of the request ID) can be written more than once in the fact table. This unnecessarily increases the volume of data, and reduces performance in reporting.
The system must perform aggregation using the request ID every time a query is executed !

Compression solves this problem.Compressing the InfoCube eliminates the duplicate
records by converting all request IDs to ZERO and rolling up the key figures for records that have common values for all characteristics.

Therefore…InfoCubes should be compressed regularly.
Uncompressed cubes increase data volume and have negative effect on query and aggregate build performance. If too many uncompressed requests are allowed to build up in an InfoCube, this can eventually cause unpredictable and severe performance problems.
After compressing InfoCube 0SD_C03, the runtime was reduced from 30 min to 5 min !

2. Build Indices

Inefficient SQLs can be Expensive !The SELECT does a FULL Table Scan !

INDEXES Solves the problemAn Index is a data structure sorted by values
containing pointers to data records of a table.An Index can improve reading performance when data
is searched for values of fields contained in the index.

It’s WORTH the maintenanceBuild Secondary Indexes wherever necessary to improve the loading performance.
An Index can improve the following operations: . Select...where <table fields> = <value> . Update...where <table fields> = <value . Delete...where <table fields> = <value . Table Joins (<table1.field1> = <table2.field2>
We did this for tables /BIC/AYCPSSPBI00 and /BIC/AYCPSSPBH00
and received a 90 % performance improvement

3. Partitioning – Divide and Rule

What is it ?Basically partitioning helps in accessing the data in
smaller chunks rather than going thru complete fact table.
By using partitioning you can split up the whole dataset for an InfoCube into several, smaller, physically independent and redundancy-free units. Thanks to this separation, performance is increased when reporting, or also when deleting data from the InfoCube
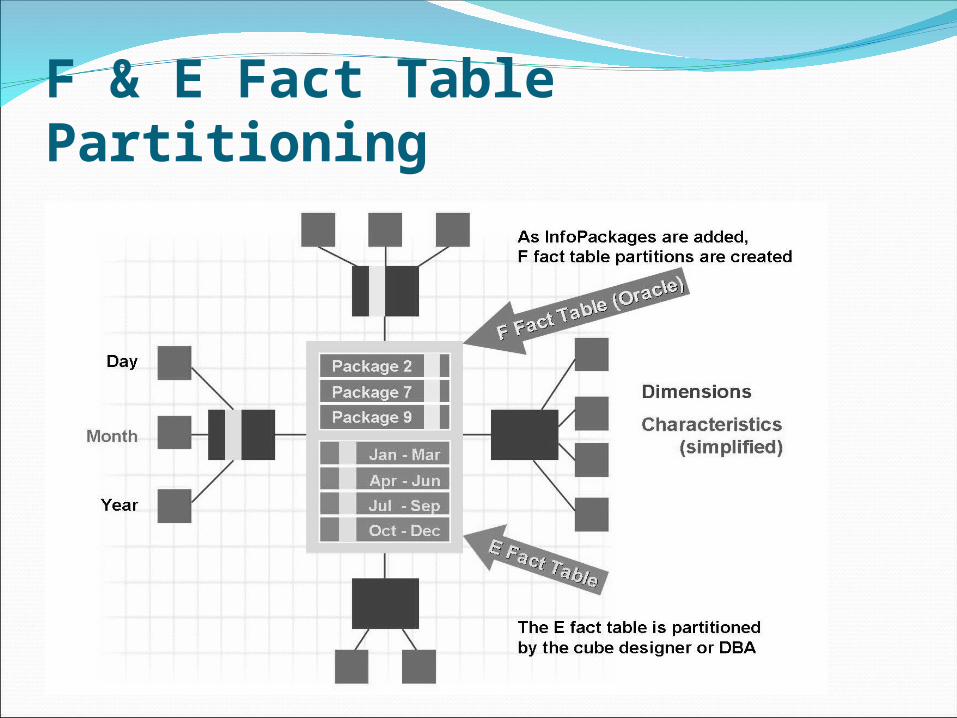
F & E Fact Table Partitioning

BENEFITS
Almost every reasonable OLAP query has a restriction based on time. Such restrictions can be exploited by the query optimizer to focus on those fact table partitions/fragments that contain the relevant data.
The technical term for this is partition pruning, as the query processing is pruned to the relevant partitions/fragments of the fact table.
Irrelevant partitions/fragments can be discarded at an early stage.

4.Build Aggregates – Let’s have some baby Cubes

Resources aren’t Free!The main limited resources on the database server are:CPU capacityMemory capacityNumber of physical I/O operations that can be performed
efficiently
Expensive SQL statements read too much data from the database compared to what is needed in the query. Expensive SQL statements can have a negative impact onperformance overall. Improper or unnecessary use of the
database buffers results in displacements of other data blocks, and
affects overall system performance

Indicators of Missing Aggregates

Indicators of Missing AggregatesRatio records selected (DBSEL) / records
transferred (DBRANS) > 10Records selected > 10,000Database time over 30 percent of total runtimeDatabase time higher than three seconds
Query performance may be poor due to missing aggregates: If much data has to be selected on the database, much more data than necessary is selected onthe database.

It works!After the creation of aggregate for the InfoCube
YDME_CA1, the performance of the query YSDMGTCAMPAIGNCA was improved by 97% from 1150 seconds to 30 seconds.
Coke is in process of creating a number of aggregates
for all major reports.

5. Archive Data – Old is not always GOLD

Archiving Process

ILM – Information Lifecycle Management

Clear the unused

ILM - Benefits

6. Star Schema – Design it Well
Text
SID Tables
Master
Hierarchies
Hierarchies
Master
SID Tables
Text
Hierarchies
Master
SID Tables
Text
Hierarchies
Master
SID Tables
Text
Hierarchies
Master
SID Tables
Text
Hierarchies
Master
SID Tables
Text
Text
SID Tables
Master
Hierarchies
Text
SID Tables
Master
Hierarchies
Text
SID Tables
Master
Hierarchies
DimensionTable
Text
SID Tables
Master
Hierarchies
DimensionTable
DimensionTable
DimensionTable
DimensionTable
Hierarchies
Master
SID Tables
Text
FACT

Big Performance comes in small size
Small dimensions.
Few dimensions (less important than small dimensions).
Only as many details as necessary.
Hierarchies only if necessary.
Time-dependent structures only if necessary.
Avoid MIN, MAX - Aggregation for key figures in huge InfoCubes

RSRV Tool Check and correct the dimensions in RSRV to remove
the unused entries in the dimension tables.Run the transaction RSRV.Select 'All elementary tests' -> 'Transaction data'.Double click on 'Entries not used in the Dimension of
an InfoCube'.Click on both new entries and enter the InfoCube
name and the dimension name. Then ‘Execute’ to get the check result.
To correct entries in the dimension tables, click
'Correct Error' button.

First hand experienceAfter reducing the size of dimension table /BIC/DYCPS_MRP23 , the performance was improved by 73% - That’s SUBSTNCIAL !

7. PSA Maintenance – Make it a HabitPSA Size can adversely affect the performance of the Production system.
Vigil your PSA Tablespace Size.Do a monthly review of Top 30 PSAs in the system.Include PSA Deletion steps in the Process chains.Do a weekly PSA Deletion process.
After incorporating these processes we could save 600-700 GB Space !

8. Parallelism – Time is moneyAvoid FULL Loads as far as possible.
Divide the heavy loads in parallel loads based on selections.
Check if the old data is no longer needed and the data selection can be reduced.
Design Process chains with parallelism.
Always perform adequate testing on the optimal parallelism and performance… don’t go overboard.

9. CO-PA Datasource Lock

Coke Bone of Contention for past 5 yrs
CO-PA Datasource extracts Actual & Plan Data
CO-PA deltas are based on Timestamp with a safety interval of 30 minutes.
The CO-PA Actual extractor runs every hour during Business critical weeks.
The CO-PA Actual extractor was failing every hour with error message
“ The selected datasource is locked by another process”

The 5 year Legacy met its endWe could identify the root cause by debugging the
Extractor thoroughly from head to toe.
A conflict between CO-PA and VF01 was unearthed.
VF01 is a billing transaction which establishes an update lock on structure CESVB.
CO-PA extractor also accesses the CSEVB structure while actual and plan extraction and fails if it doesn’t get the lock on it.

ResolutionWe designed the below solution and made it a Best Practice during the Business critical weeks.
Vigil SM12 in R/3 for CESVB.Stop CO-PA Extractor if there is a lock on CESVB.Monitor this lock as VF01 holds it for few seconds.If the lock persists for quite some time, delete the
lock after taking necessary approvals.Start the CO-PA extractor once CESVB lock is
released.We also discussed this with SAP and an extractor
code change in WIP, which will try to access CESVB 10 times before failing. Presently the try is only once.

10.Miscellaneous
Drop index of a cube before loading.Distribute work load among multiple server instancesPrefer delta load: as it loads only newly added or
modified records.We should deploy parallelism. Multiple Info packages
should be run simultaneously.Update routines and transfer routines should be
avoided unless necessary. And the routine should be a optimized code.
We should prefer to load master data and then transaction data because when u load master data, SID is generated and this SID is used in Transaction
data.

THANK YOU

















