50
Better decision making in presence of faults: formal modelling and analysis Professor Muffy Calder Dr Michele Sevegnani Computing Science 1 December 2013
| Date post: | 01-Jan-2016 |
| Category: |
Documents |
| Upload: | marshall-cook |
| View: | 217 times |
| Download: | 4 times |

Better decision making in presence of faults: formal modelling and analysis
Professor Muffy Calder Dr Michele Sevegnani
Computing Science
1 December 2013

Better decision making in presence of faults: do I need to fix a fault now or can I wait until tomorrow?
Professor Muffy Calder FREng Dr Michele Sevegnani
Computing Science
2 December 2013

A stochastic event-based model and analysis of the NATS communications links monitoring system
Professor Muffy Calder Dr Michele Sevegnani
Computing Science
3 December 2013

4
Outline• Who am I
Part I• Why model; what to model
Part II• How to model and analyse
Part III• Results for example sites and sectors; inference from field data• Decision making
Part IV• Implementation and GUI; how to use the model(s)
Part V• Conclusions; next steps

5
Who am I - Related work
Domestic Network and Policy Management • real-time analysis of policies and configurations – spatial and temporal (on router)
Feature interactions in advanced telecomms • logical properties (off-line, on-line)
Homecare sensor system: assessing configurations for usability, interaction modality • real-time logical analysis (on system hub)
Populations of users of ubiquitous computing/mobile apps• stochastic models and logical analysis of actual use – from user traces Cellular biology• signalling pathways for coordination/cancer; phosphorylation is signal

6
Part I: Why model Motivation
• engineering team maintain large number of complex systems, many different management systems, reliance on experience
• a low level fault can give rise to a plethora of alarms • systems do not allow easy visualisation, interrogation of current state, or
prediction of future• need to quantify criticality or urgency• need to relate asset behaviour to service behaviour

7
Why model Event based, stochastic modelling based on monitored behaviours
• quantify service quality across different sectors and dynamically changing assets/systems
• experiment with different monitoring strategies and system architectures• experiment with different strategies for repair and maintenance • visualise criticality • better decision making: ATC users, engineers, technical staff, management
Quantify how system • is designed to meet requirements• actually meets requirements

8
Why model Analysis allows us to answer questions like:
• What is probability of no service from a given degraded configuration in a given frequency/sector/site over next 48 hours?
• What proportion of time is the service functioning, in the long run?
sector RRR mean repair times: 20h, 15h

9
Why model Analysis allows us to answer questions like:
• What is probability of no service from a given degraded configuration in a given frequency/sector/site over next 48 hours?
• What is the effect of an intervention?

10
What to model Monitoring Systems• radar - communication links - oceanic routes - local machines - voice -
weather - power lines Communication links monitoring• civilian, military, emergency, oceanic frequencies • sectors, sites, frequencies and channels• 35 sectors, each with set of frequencies (+ emergency)• 17 sites, each with antennas (channels) that (send) Tx and (receive) Rx on
different frequencies • redundancy:
• a frequency is covered by more than one site• each site has main channel A and backup channel B
• site environment: powerline status, comm link status, flooding, intrusion

11
What to model Monitoring system colour codes
Green functioningRed faulty -- alarm goes off Blue under maintenanceAmber not fully functioning/reduced redundancy
(e.g. a frequency when one antenna is down)
We model sectors (comprising) sites( comprising) channels

12
What to model Event-based, parameterised model
parameters:- number of sites in a sector- rates of events in a site - state of Tx and Rx in a site
assumptions:- events are independent, unless explicitly linked

Overview of project
Field Data
Event Rates
Parameterised Model
CTMC for counter abstraction of
subsystem
Static Analysis
Safety CasesBusiness Cases
Prediction
Predictive temporal properties
e.g. transient probability of no service
Validation
Predictive temporal properties
e.g. steady state probability of no service, reduced redundancy, etc.
inference
PRISMmodel checker
PRISMmodel checker
GUI
13
possibleaction(s)

14
Part II: How to model Principles
• model observed/recorded events between discrete states• an events occurs with a rate• rate determines probability of reaching a state by a given time• possibility of race conditions
k
l

15
How to model Principles
• model observed/recorded events between discrete states• an events occurs with a rate• rate determines probability of reaching a state by a given time• possibility of race conditions
• At rate k:
• Continuous time Markov chain
ktetP 1)(

16
Simple Example: Markov chain
S
F
M
S serviceableF faultyM under maintenance rate1
rate3
rate2
rate4
A Markov chain has no memory.
A rate only depends on the current state, not how we got to a state.
We can reason about paths.
We can reason about the probability, over time, to reach a state.
e.g. what is probability to reach state M in 4 hours?

17
Overview of modelchannel component: (counter abstraction) A and B channels
Tx or Rx SS
SF
FF
SM
FM
MM
A/B CHANNELS
S serviceableF faultyM under maintenance

18
Overview of modelchannel component
SS
SF
FF
SM
FM
MM
A/B CHANNELS
S serviceableF faultyM under maintenance
reduced redundancy
no service

19
Overview of modelchannel component
SS
SF
FF
SM
FM
MM
E
A/B CHANNELS
S serviceableF faultyM under maintenanceE external site failure

20
Overview of modelsite environment component
S serviceableF faultyM under maintenanceE external site failure
E0
E2
E1
SITE ENVIRONMENT
Synchronise red events green events

21
Overview of modelA site consists of 3 concurrent components: Tx, Rx, Env
At any moment, a site is in a configuration
Examples:
(SS,SS,E0) green - serviceable site(SF,SS,E1) amber - reduced redundancy site(FF,*,*) red - reduced redundancy site
NB: Not all configurations are reachable.
S serviceableF faultyM under maintenanceE external site failure

22
Overview of model
Every component is represented in PRISM by a generic module.
Modules for• channel (pair) • site environment • site • n-ary sector (n= 2…5)
Rates of events vary from site to site (sector to sector).

23
AnalysisUse (stochastic) logic for analysis to
• validate long run behaviour against (long run) observations What is the % time in a no service state? E.g. 8.5 E -4What is the % time in a reduced redundancy state? E.g. 30%
• predict a transient behaviourWhat is the probability of being in a no service state over the next t hours?
P =? [F<=T noservice_sector(X)]How does the probability change over those t hours?How does the probability distribution depend on the current state?
Possible action: If the prediction from the current state is unacceptable, then change state to one with a more acceptable prediction.

24
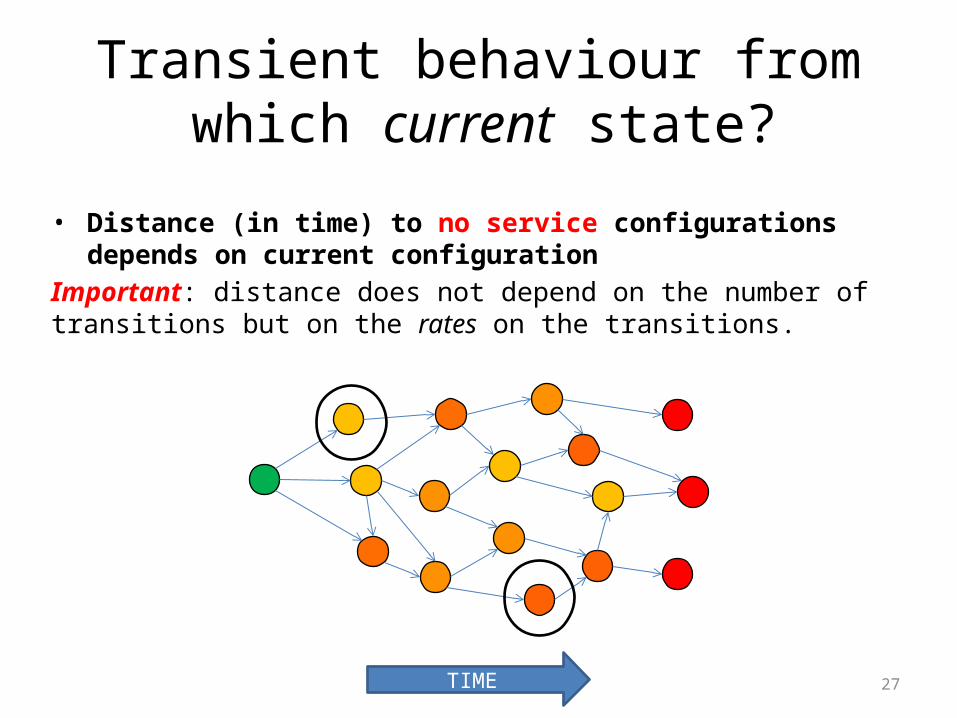
Transient behaviour from which current state?
• Distance (in time) to no service configurations depends on current configuration
The colour code adopted by the monitoring system does not allow to quantify this distance or to compare possible current configurations. The model allows us to do this!
TIME

25
Transient behaviour from which current state?
• Distance (in time) to no service configurations depends on current configuration
The colour code adopted by the monitoring system does not allow to quantify this distance or to compare possible current configurations. The model allows us to do this!
TIME

26
Transient behaviour from which current state?
• Distance (in time) to no service configurations depends on current configuration
The stochastic model allows to measure the distance precisely:
TIME
27
Transient behaviour from which current state?
• Distance (in time) to no service configurations depends on current configuration
Important: distance does not depend on the number of transitions but on the rates on the transitions.
TIME

28
Part III: Analysis results for example sectors/sites
• Example sector with three sitesFIR sector (sites CGL, WHD and LWH).Each site consists of the synchronisation of two channel components (Tx/Rx) and a site environment component.Total number of components for FIR: 6 channels and 3 environments.Event rates are inferred from historical data (Feb 2012 – Feb 2013) - maintenance and failure data for FIR sector and individual sites.
• Analysis of the transient behaviour from different sector statesOut of all the possible configurations (389,017 states) we compare the expected behaviour of selected states over the next 48 hours.
A state represents a configuration of a sector, e.g. three sites, two of which are serviceable and one is no service.

29
Inference from field data • All the events occurred in sector FIR from Feb 2012 to Feb 2013 are
counted and categorised• Total number of alarms: 61• Total number of site events: 24
• Events are used to derive transition rates:• Mean inter-failure time: 452 h• Mean repair time: 23 h• Response: 57 m• Site event: 1107 h• Percentage of quick repairs: 15%• Site failure: extremely rare event 1 every 11.33 years

30
Analysis results for example sectors/sites
• Selected sector configurations
• Configuration W corresponds to configuration (Tx,Rx,Env) = (SS,SS,E0)• Configuration N corresponds to configuration (Tx,Rx,Env) = (FF,*,*), (FM,*,*), (MM,*,*), (E,E,E2)• Configuration R corresponds to configuration (Tx,Rx,Env) = (SF,(SM|SF |SS),(E0|E1)), (SM,(SM|SF |SS),(E0|E1))
Site CGL Site WHD Site LWH
W W W
W W N
W N N
W W R
W R R
R R R
R R N
R N N
W= serviceable (working) siteR = reduced redundancy siteN = no service site

Examples
And how to interpret results….
31

Steady state for example sectors/sites
No Service is 1.03E-832

3 Sites 2 Sites 1 Site
Ratio R 13.46% 9.03% 4.45%Ratio W 86.54% 91.09% 95.51%Ratio N 0.00% 0.00% 0.03%
11.54% 6.19% 2.88% 88.46% 93.80% 96.85% 0.00% 0.00% 0.26%
ValidationCompare historical data (over 1 year) model steady state analysis
Historical data
Steady state analysis
33

34
Transient properties

35
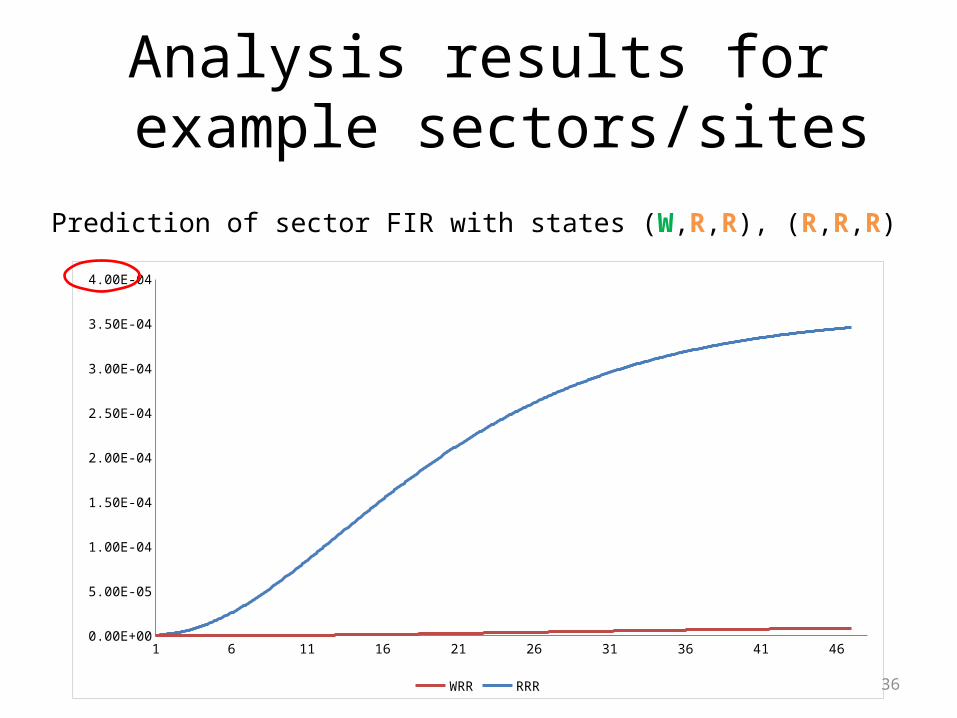
Analysis results for example sectors/sites
Prediction of sector FIR from states (W,W,W), (W,W,R), (W,W,N)
1 6 11 16 21 26 31 36 41 460.00E+00
1.00E-07
2.00E-07
3.00E-07
4.00E-07
5.00E-07
6.00E-07
7.00E-07
8.00E-07
WWW WWR WWN
36
Analysis results for example sectors/sites
Prediction of sector FIR with states (W,R,R), (R,R,R)
1 6 11 16 21 26 31 36 41 460.00E+00
5.00E-05
1.00E-04
1.50E-04
2.00E-04
2.50E-04
3.00E-04
3.50E-04
4.00E-04
WRR RRR

37
Analysis results for example sectors/sites
Prediction of sector FIR with states (R,N,N) (W,R,N), (R,R,N), (W,N,N),
1 6 11 16 21 26 31 36 41 460
0.001
0.002
0.003
0.004
0.005
0.006
0.007
0.008
RNN WRN RRN WNN

Make an intervention to move into a better state.
38
Decision making

39
Analysis from RRR solid line, mean repair time is 20 hours (unsafe at 20 hrs) dashed line, mean repair time is 15 hours (unsafe at 34 hrs) WRR is state with one site repaired
Decision making

40
WRR dashed line – under standard assumptions solid line, site repaired after 20 hours 20 = random value when mean repair time is 15 hours
Decision making

41
Idea: catalogue of scenarios and interventions
Decision making- real-time support

42
Part IV: Implementation• Implementation of the model in PRISM (probabilistic model checker)
Source code is a text file
Example module Channel_A_Tx status_A_Tx: [0..4]; //0 = servicable, 1 = faulty, 2 = repairing, 3 = under maintenance, 4 = site-event [] status_A_Tx =0 -> rate_failure:(status_A_Tx'=1); [] status_A_Tx =1 -> rate_ack:(status_A_Tx'=2); [] status_A_Tx =2 -> rate_repair:(status_A_Tx'=0) + rate_send_fix:(status_A_Tx'=3); [] status_A_Tx =3 -> rate_fix:(status_A_Tx'=0); [event] status_A_Tx =0 | status_A_Tx =1 | status_A_Tx =2 -> (status_A_Tx'=4); [fix] status_A_Tx =4 -> (status_A_Tx'=0); endmodule
PRISM is freely available software www.prismmodelchecker.org
(32/64 bit Windows, linux, MacOS -- Java)
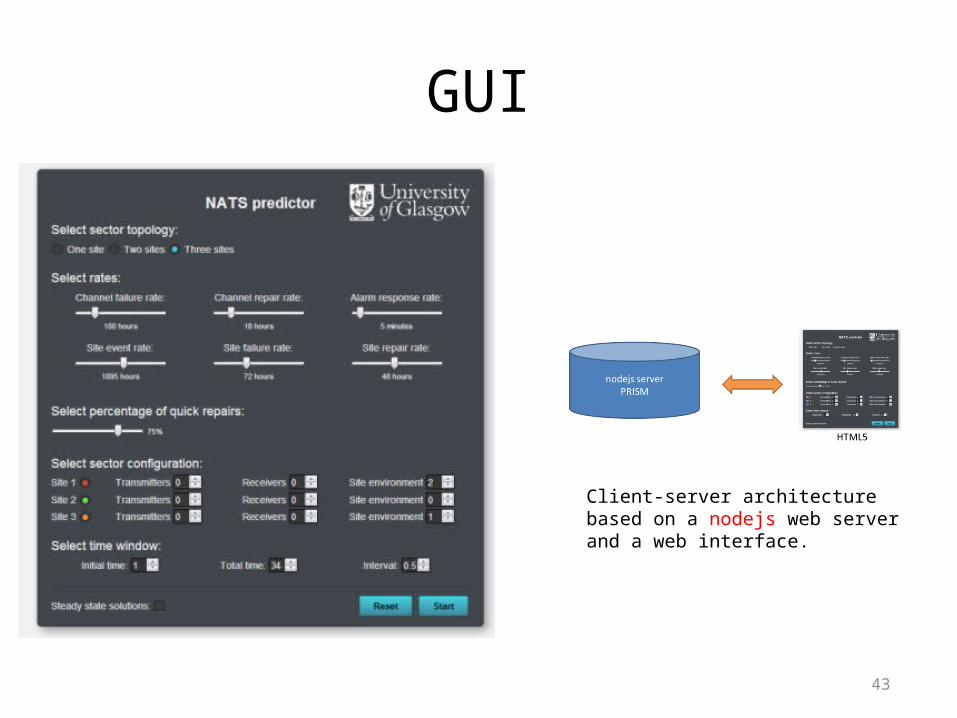
GUI
43
Client-server architecture based on a nodejs web server and a web interface.
44
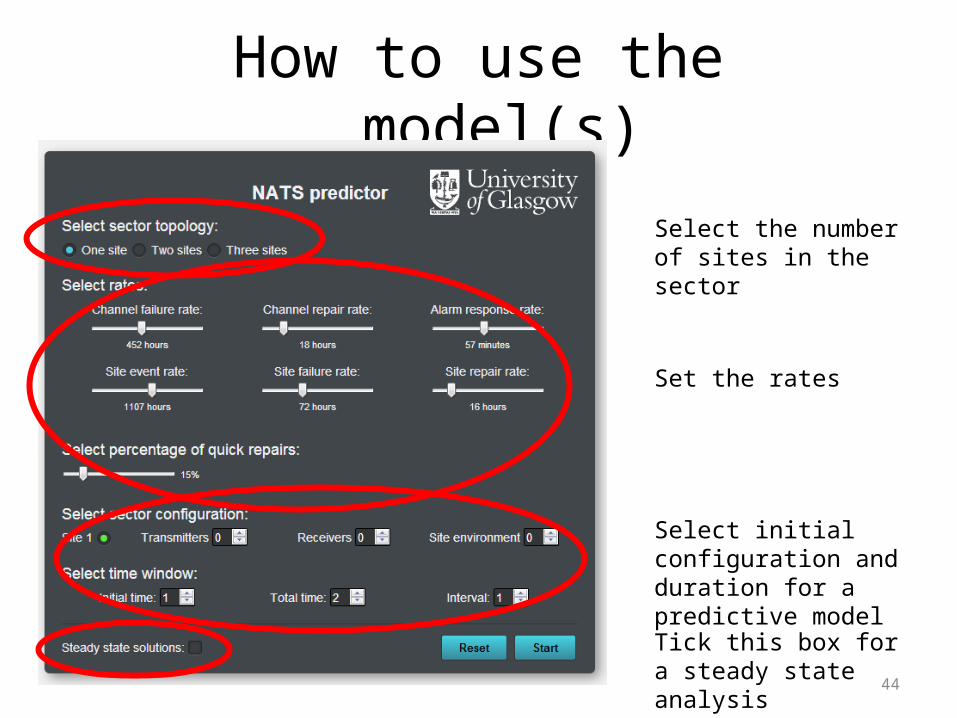
How to use the model(s)
Set the rates
Select the number of sites in the sector
Select initial configuration and duration for a predictive model
Tick this box for a steady state analysis

Android implementation
45

46
More on field data • Scheduled maintenance
• The model assumes stochastic failure rates
• Combined failures• Failure events in the Tx and Rx modules are assumed independent• However, only 16% of the faults (over the entire dataset) affect only one module
• Quick repairs• The entries of the database do not record if the fault was repaired locally (quick repair)
or if an engineering team call was required• Even when a fault is fixed quickly locally, the equipment is often monitored for some time
• Site failures• More data is required for statistical significance.• Positive result: the data confirms these are extremely rare events.

47
Conclusions What we have done• Entire framework is implemented• Instantiated for communications subsystem• Parameterised model driven by a bespoke GUI• Parameter instances derived from field data• Model validation, leading to … • Model as predictor “can I wait 4 hours to fix problem at site X?”
What we uncovered • Some issues about field data
• retrieval from SAP• formats for recording (free text)
What we published“Do I need to fix a failed component now, or can I wait until tomorrow” Submitted to: 10th European Dependable Computing Conference

48
Next steps 1. Field data• More data – longitudinal and spatial• Automated inference from data, every time dataset updated• Automated updating of model from inferred rates
Fully automated, self-updating model of monitoring system
2. Extend model to more sectors, subsystems etc• model all sectors; model all subsystems• include spatial aspects; frequency redundancy
3. Decision making• Role of online model; catalogue of scenarios
4. Modify model• dependent events and scheduled maintenance• experiment with other types of formalisms
5. Feedback into other processes • alignment with safety and business cases; SLAs; ticketing
49
Thank you

Representation
50

















