46
Presented By: Shubham Rastogi B.Tech ( 5 TH Semester ) Roll No. 1231110020 Branch: Computer Science INTRODUCTION TO BIG DATA ANALYTICS AND HADOOP
| Date post: | 18-Aug-2015 |
| Category: |
Data & Analytics |
| Upload: | shubham-rastogi |
| View: | 114 times |
| Download: | 1 times |

Presented By: Shubham Rastogi
B.Tech ( 5TH Semester ) Roll No. 1231110020
Branch: Computer Science
INTRODUCTION TO BIG DATA ANALYTICS AND HADOOP
Simple to start
• What is the maximum file size you have dealt so far?• Movies/Files/Streaming video that you have used?• What have you observed?
• What is the maximum download speed you get?• Simple computation
• How much time to just transfer.

What is Big Data ?

Big Data
• Every day, we create 2.5 quintillion bytes of data — so much that 90% of the data in the world today has been created in the last two years alone. This data comes from everywhere: sensors used to gather climate information, posts to social media sites, digital pictures and videos, purchase transaction records, and cell phone GPS signals to name a few.
This data is “big data.”

The Social Layer in an Instrumented Interconnected World
2+ billion
people on the
Web by end 2011
100 billion RFID tags today (1.3B in 2005)
4.6 billion camera phones
world wide
100s of millions of GPS
enabled devices
sold annually
200 million smart meters in 2014… 500M by 2020
22+ TBs of tweet data
every day
35+ TBs oflog data
every day
? T
Bs
of
dat
a ev
ery
da
y

Big Data EveryWhere!
• Lots of data is being collected and warehoused
• Web data, e-commerce• purchases at department/
grocery stores• Bank/Credit Card
transactions• Social Network

Big Data: A definition
• Big data is a collection of data sets so large and complex that it becomes difficult to process using on-hand database management tools.
• The challenges include capture, curation, storage, search, sharing, analysis, and visualization.
• The Challenges are like prevention of diseases and determine real-time roadway traffic conditions.
• Big data is the realization of greater business intelligence by storing, processing, and analyzing data that was previously ignored due to the limitations of traditional data management technologies

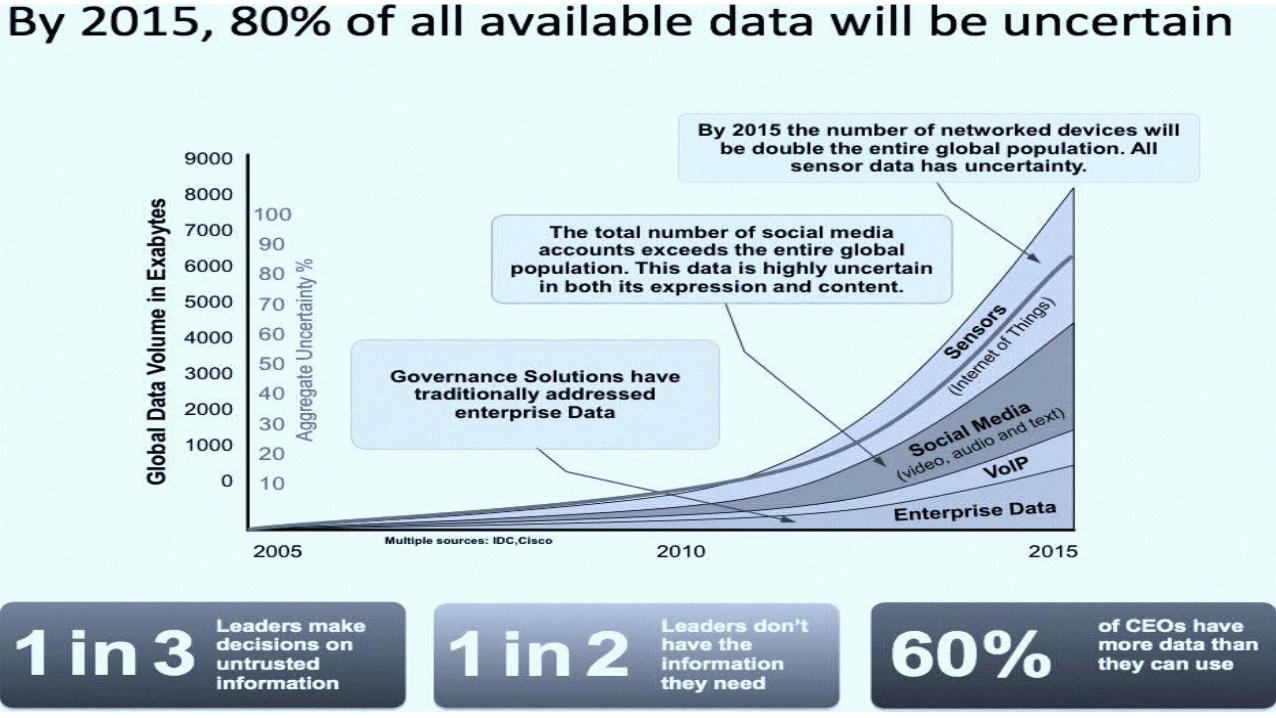
IN 2010 THE DIGITAL UNIVERSE WAS
1.2 ZETTABYTES
IN A DECADE THE DIGITAL UNIVERSE WILL BE
35 ZETTABYTES
90% OF THE DIGITAL UNIVERSE IS
UNSTRUCTURED IN 2011 THE DIGITAL UNIVERSE WAS
300 QUADRILLION FILES
Customer Challenges: The Data Deluge
The Economist, Feb 25, 2010

BIG DATA is not just HADOOP
Manage & store huge volume of any data
Hadoop File System
MapReduce
Manage streaming data Stream Computing
Analyze unstructured data Text Analytics Engine
Data WarehousingStructure and control data
Integrate and govern all data sources
Integration, Data Quality, Security, Lifecycle Management, MDM
Understand and navigate federated big data sources
Federated Discovery and Navigation

“BIG DATA ANALYTICS”
“TRADITIONAL BI”
GBs to 10s of TBs
Operational
Structured
Repetitive
s of TB to 100’s of PB’s10
External + Operational
Mostly Semi-Structured
Experimental, Ad Hoc
Big Data Versus Business Intelligence

Moving very quickly
Large volume of data
Different Formats

What does Big Data trigger?
• From “Big Data and the Web: Algorithms for Data Intensive Scalable Computing”

“The future is here, it’s just not evenly distributed yet.”
Web 2.0 is “Data-Driven”

The world of Data-Driven Applications
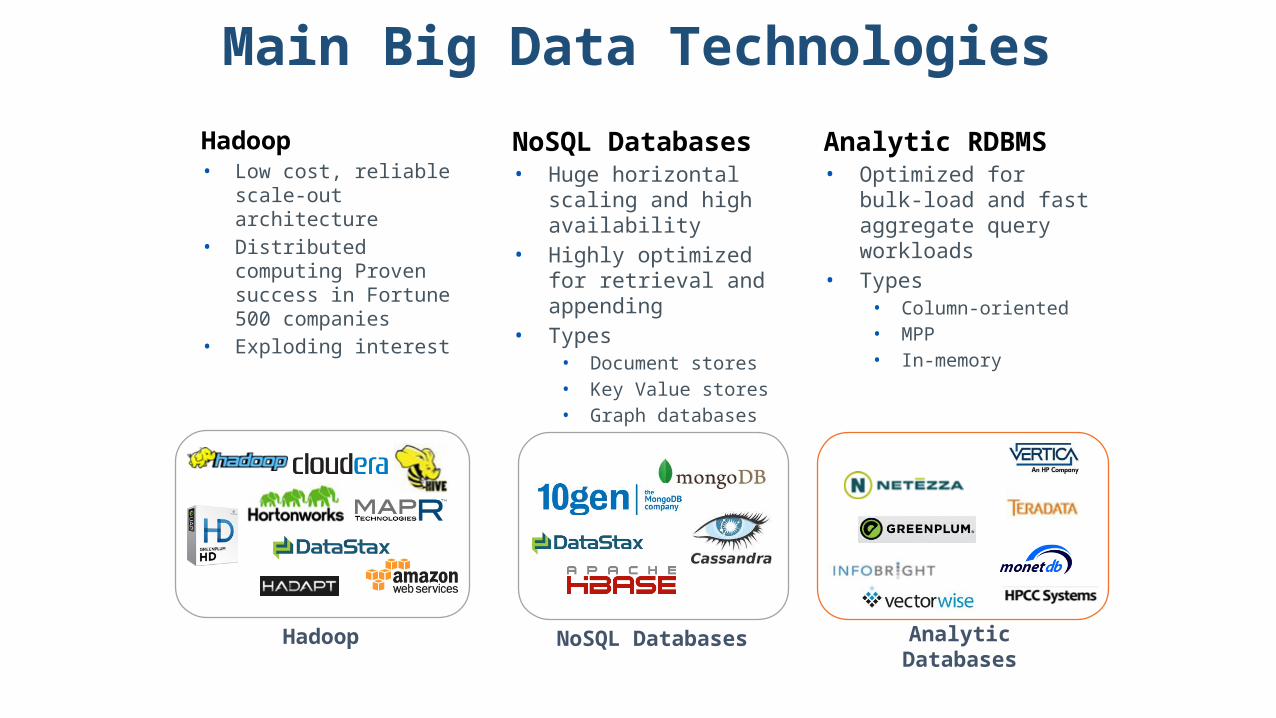
Main Big Data Technologies
Hadoop NoSQL Databases Analytic Databases
Hadoop• Low cost, reliable
scale-out architecture• Distributed computing
Proven success in Fortune 500 companies
• Exploding interest
NoSQL Databases• Huge horizontal scaling
and high availability• Highly optimized for
retrieval and appending• Types
• Document stores• Key Value stores• Graph databases
Analytic RDBMS• Optimized for bulk-load
and fast aggregate query workloads
• Types• Column-oriented• MPP• In-memory

Retail •CRM – Customer Scoring •Store Siting and Layout •Fraud Detection / Prevention •Supply Chain Optimization
Advertising & Public Relations •Demand Signaling •Ad Targeting •Sentiment Analysis •Customer Acquisition
Financial Services •Algorithmic Trading •Risk Analysis •Fraud Detection •Portfolio Analysis
Media & Telecommunications •Network Optimization •Customer Scoring •Churn Prevention •Fraud Prevention
Manufacturing •Product Research •Engineering Analytics •Process & Quality Analysis •Distribution Optimization
Energy •Smart Grid •Exploration
Government •Market Governance •Counter-Terrorism •Econometrics •Health Informatics
Healthcare & Life Sciences •Pharmaco-Genomics •Bio-Informatics •Pharmaceutical Research •Clinical Outcomes Research
Industries are embracing Big Data

Huge amount of data
• There are huge volumes of data in the world:From the beginning of recorded time until 2003,
We created 5 billion Gigabytes (Exabyte) of data.In 2011, the same amount was created every two daysIn 2013, the same amount of data is created every 10 minutes.

How are revenues looking like….
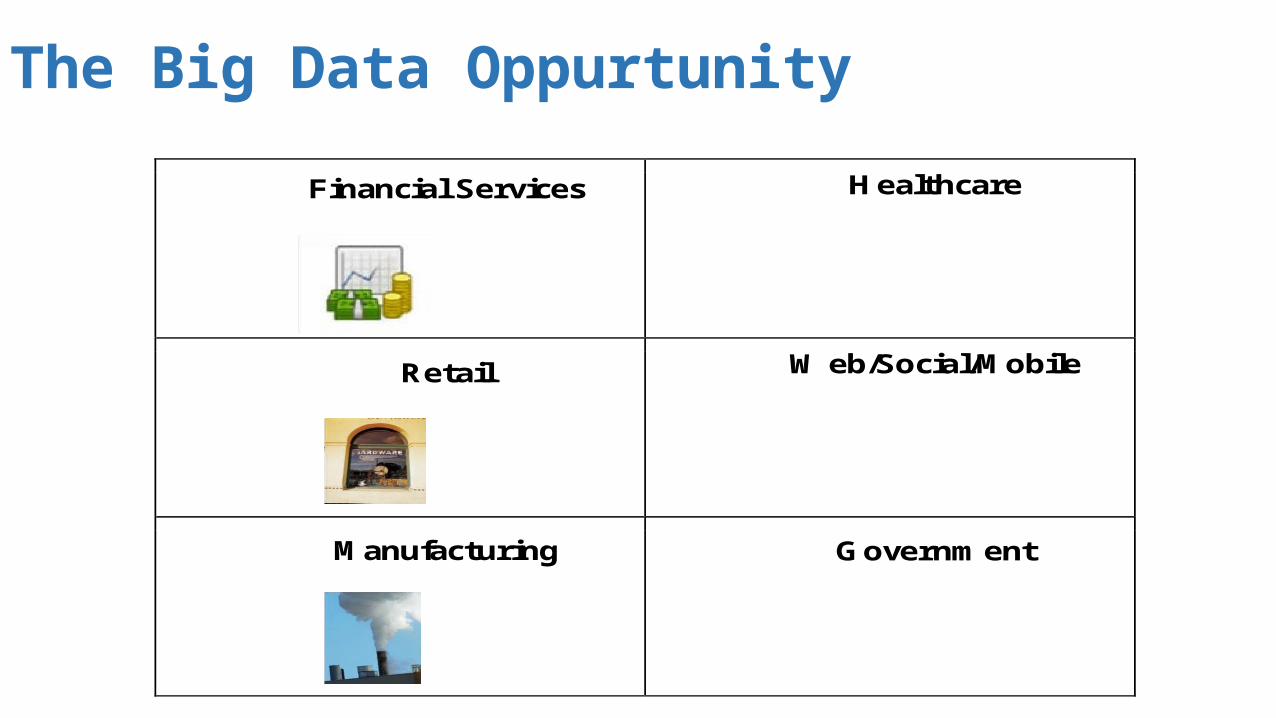
The Big Data Oppurtunity
Financial Services
Healthcare
Retail
Web/Social/Mobile
Manufacturing
Government

What is Hadoop ?

Industries who adopted Hadoop

• Hadoop is a scalable fault-tolerant distributed system for data storage and processing.
• Core Hadoop has two main components:-a) Hadoop Distributed File System (HDFS): self-healing, high-bandwidth clustered storage
Reliable,redundant, distributed file system optimized for large files
b) MapReduce: fault-tolerant distributed processing
Programming model for processing sets of data
Mapping inputs to outputs and reducing the output of multiple Mappers to one (or a few) answer(s)
• Operates on unstructured and structured data .• A large and active ecosystem .• Open source under the friendly Apache License ( http://wiki.apache.org/hadoop/ )• Yahoo is the main Contributor of Hadoop.
What is Hadoop?

Hadoop Specifications
Scalability (petabytes of data, thousands of machines)
Flexibility in accepting all data formats (no schema)
Commodity inexpensive hardware
Efficient and simple fault-tolerant mechanism
Performance (tons of indexing, tuning, data organization tech.)
Features: - Provenance tracking - Annotation management - ….

Why Hadoop?
ANSWER: Big Datasets!

Why Hadoop ? Social media/web data is
unstructured. Amount of data is immense. New data sources arise weekly.


HDFS
Hadoop Distributed File System – Data is organized into files & directories – Files are divided into blocks, distributed across cluster nodes – Block placement known at runtime by mapreduce = computation
co-located with data – Blocks replicated to handle failure – Checksums used to ensure data integrity
Replication: one and only strategy for error handling, recovery and fault tolerance – Self Healing – Make multiple copies

Client Client Client Client Client Client Client Client
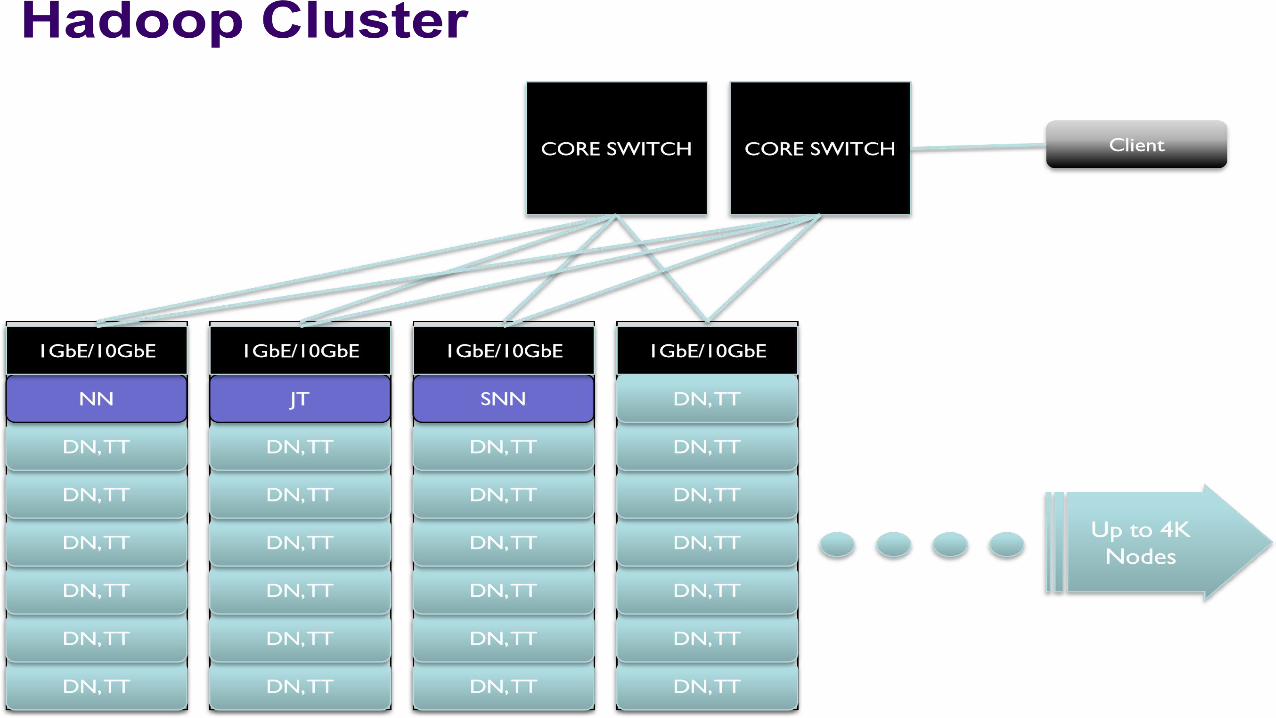
Hadoop Server Roles
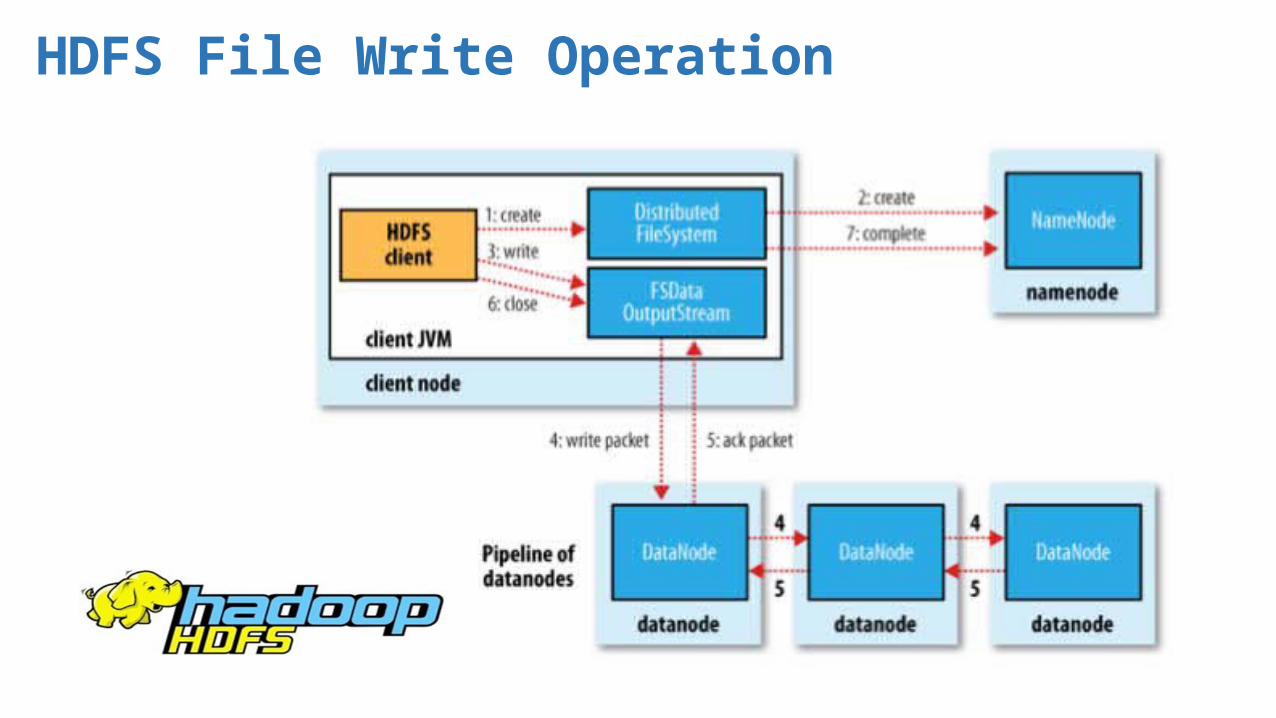
HDFS File Write Operation

HDFS File Read Operation

MapReduce Functional Programming meets Distributed Processing
MapReduce Provides Automatic parallelization and distribution Fault Tolerance Status and Monitoring Tools A clean abstraction for programmers Google Technology RoundTable: MapReduce

What is MapReduce?
A method for distributing a task across
multiple nodes.
Each node processes data stored on that node
Consists of two developer-created phases
1. Map
2. Reduce
In between Map and Reduce is the Shuffle and
Sort
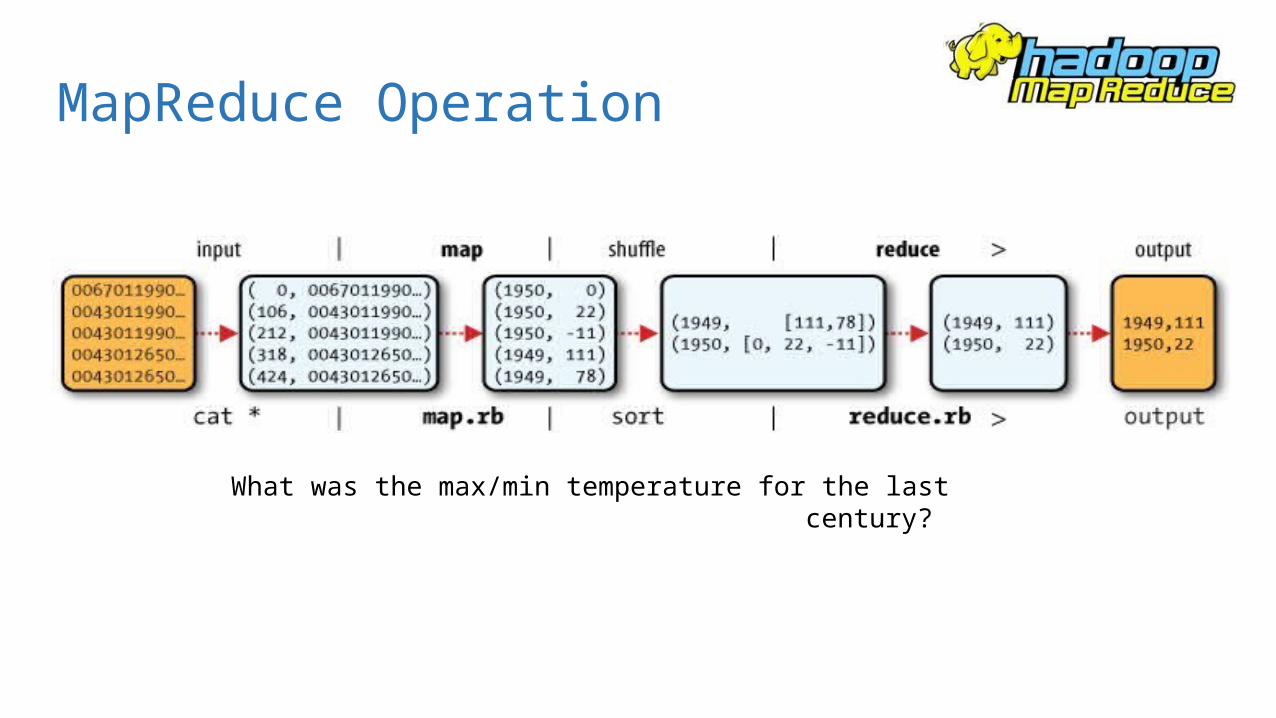
What was the max/min temperature for the last century?
MapReduce Operation

Traditional RDBMS MapReduce
Data Size Gigabytes (Terabytes) Petabytes (Exabytes)
Access Interactive and Batch Batch
Updates Read / Write many times Write once, Read many times
Structure Static Schema Dynamic Schema
Integrity High (ACID) Low
Scaling Nonlinear Linear
DBA Ratio 1:40 1:3000
Comparing RDBMS and MapReduce

Key MapReduce Terminology Concepts
• A user runs a client program on a client computer • The client program submits a job to Hadoop • The job is sent to the JobTracker process on the Master Node • Each Slave Node runs a process called the TaskTracker • The JobTracker instructs TaskTrackers to run and monitor tasks • A task attempt is an instance of a task running on a slave node • There will be at least as many task attempts as there are tasks which
need to be performed

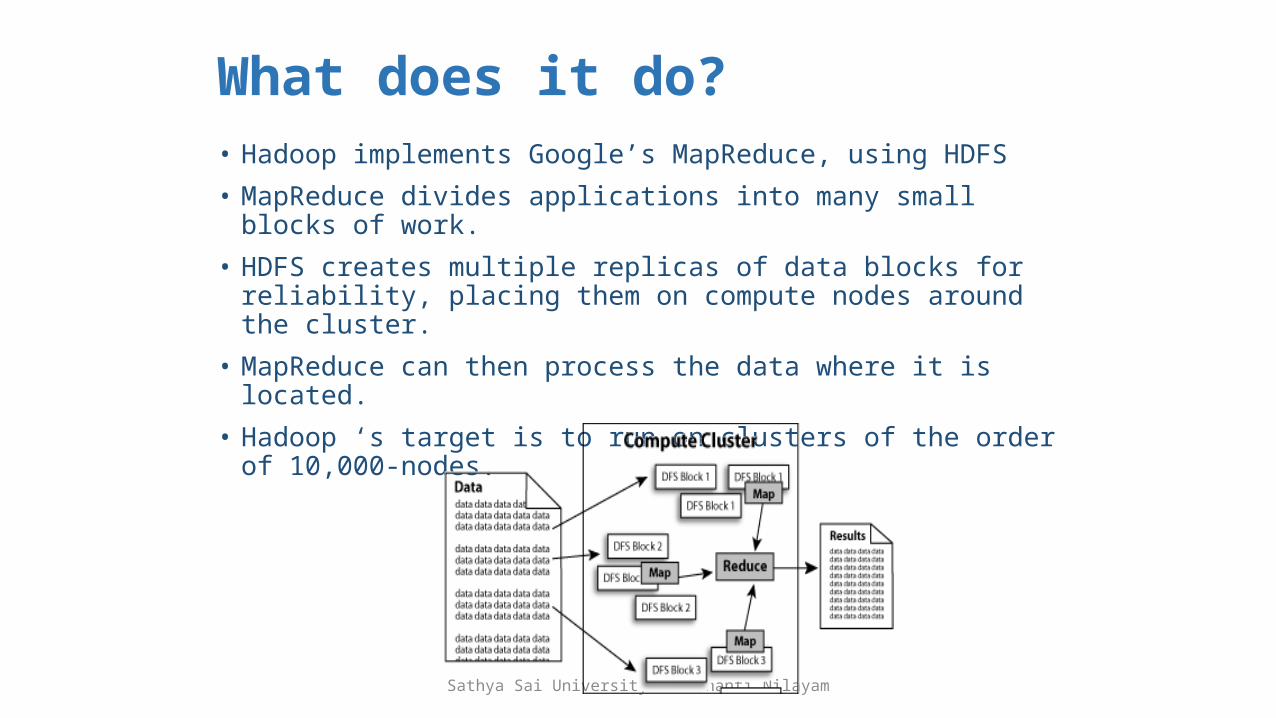
What does it do?• Hadoop implements Google’s MapReduce, using HDFS
• MapReduce divides applications into many small blocks of work.
• HDFS creates multiple replicas of data blocks for reliability, placing them on compute nodes around the cluster.
• MapReduce can then process the data where it is located.
• Hadoop ‘s target is to run on clusters of the order of 10,000-nodes.
Sathya Sai University, Prashanti Nilayam

Apache Hadoop Wins Terabyte Sort Benchmark (July 2008)
• One of Yahoo's Hadoop clusters sorted 1 terabyte of data in 209 seconds, which beat the previous record of 297 seconds in the annual general purpose (daytona) terabyte sort benchmark. The sort benchmark specifies the input data (10 billion 100 byte records), which must be completely sorted and written to disk.
• The sort used 1800 maps and 1800 reduces and allocated enough memory to buffers to hold the intermediate data in memory.
• The cluster had 910 nodes; 2 quad core Xeons @ 2.0ghz per node; 4 SATA disks per node; 8G RAM per a node; 1 gigabit ethernet on each node; 40 nodes per a rack; 8 gigabit ethernet uplinks from each rack to the core; Red Hat Enterprise Linux Server Release 5.1 (kernel 2.6.18); Sun Java JDK 1.6.0_05-b13
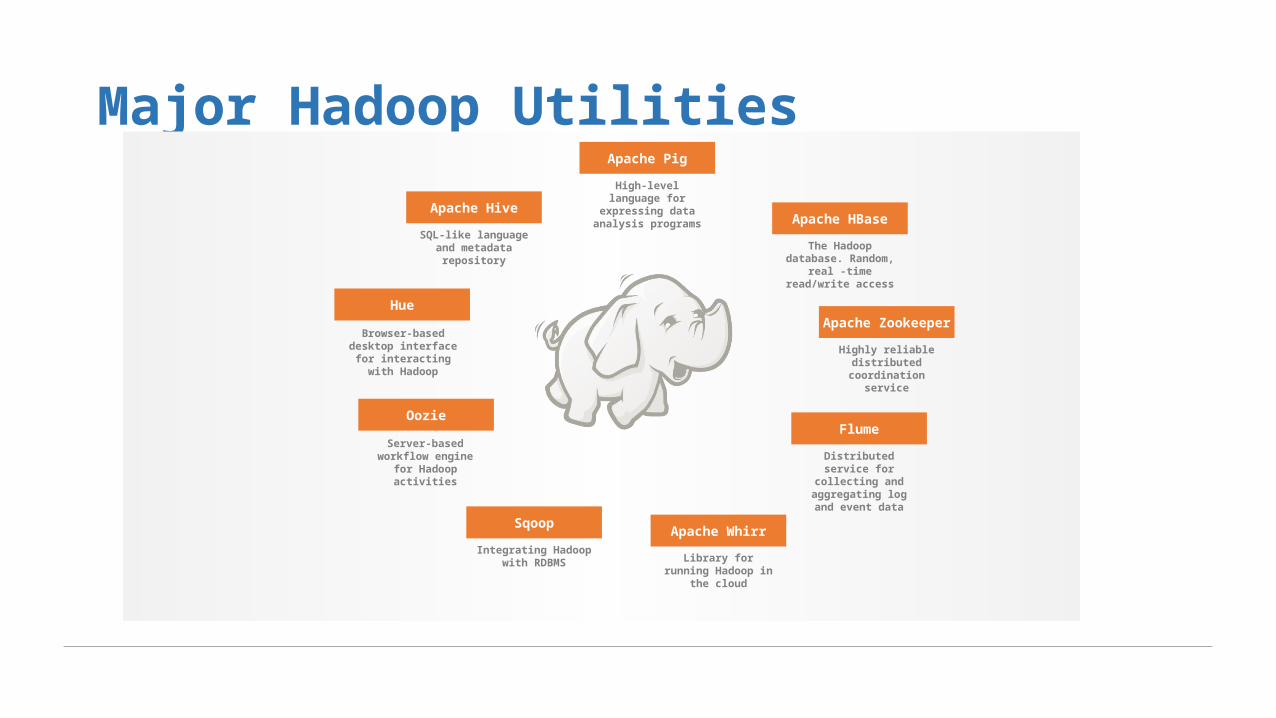
Major Hadoop Utilities
Apache Hive
Apache Pig
Apache HBase
Sqoop
Oozie
Hue
Flume
Apache Whirr
Apache Zookeeper
SQL-like language and metadata
repository
High-level language for
expressing data analysis programs
The Hadoop database. Random,
real -time read/write access
Highly reliable distributed
coordination service
Library for running Hadoop in the
cloud
Distributed service for collecting and aggregating log and event data
Browser-based desktop interface
for interacting with Hadoop
Server-based workflow engine
for Hadoop activities
Integrating Hadoop with
RDBMS

•Cloud Computing• A computing model where any computing infrastructure can run on the cloud• Hardware & Software are provided as remote services• Elastic: grows and shrinks based on the user’s demand• Example: Amazon EC2

Summary
• What is big data?• Big Data is not just Hadoop.• Main Big Data Technologies.• Future scope of Big Data• What is Hadoop? • Components of Hadoop- HDFS & MapReduce

THANK YOUFor
Your attention

?

















