27
Big Data Processing – An introduction (and how it’s implemented at Detik) Jony Sugianto IT R&D Engineer at Detik.com Saturday, November, 1 rd 2014

Big Data Processing – An
introduction (and how it’s implemented at Detik)Jony Sugianto
IT R&D Engineer at Detik.comSaturday, November, 1rd 2014

Agenda
What is Big Data?
Examples of Big Data
Big Data Elements
Big Data Ecosystems
Hadoop Overview
Other Big Data Tools
Big Data Processing at Detik
QA Session

What is Big Data?
Big Data refers to a collection of data sets so large and
complex, it’s impossible to process them with the usual databases and tools.
Because of its size and associated numbers, Big Data is hard to capture, store, search, share, analyze and visualize.

What is Big Data?
Big Data spans four dimensions[1]:Volume: Enterprises are awash with ever-growing data easily amassing terabytes—even petabytes—of information.
Velocity: Sometimes 2 minutes is too late. For time-sensitive
processes such as catching fraud, big data must be used as it streams into your enterprise in order to maximize its value.
Variety: Big data is any type of data - structured and
unstructured data such as text, sensor data, audio, video, click streams, log files and more.
Veracity: Establishing trust in big data presents a huge challenge as the variety and number of sources grows.

Examples of Big Data
10,000 payment card transactions are made every second around the world.
Walmart handles more than 1 million customer transactions an hour.
340 million tweets are sent per day. That's nearly 4,000 tweets per second.
Facebook has more than 901 million active usersgenerating social interaction data.
Detik?
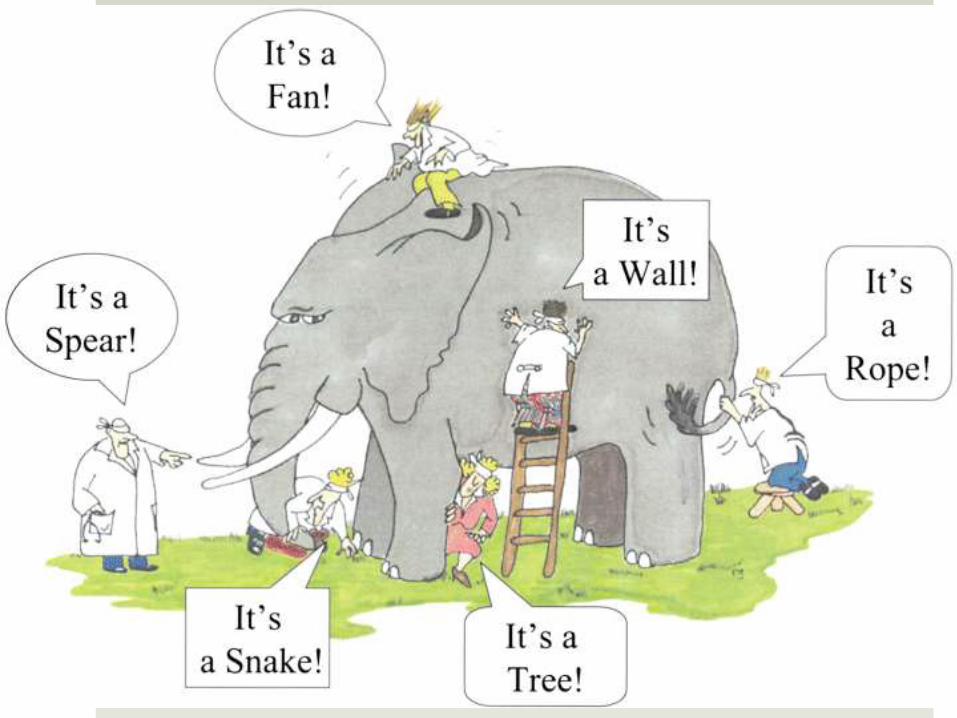

How Big is Big Data?
The definition of “Big Data” varies greatly depending
upon which part of the “animal” you touch, and where your interests lie
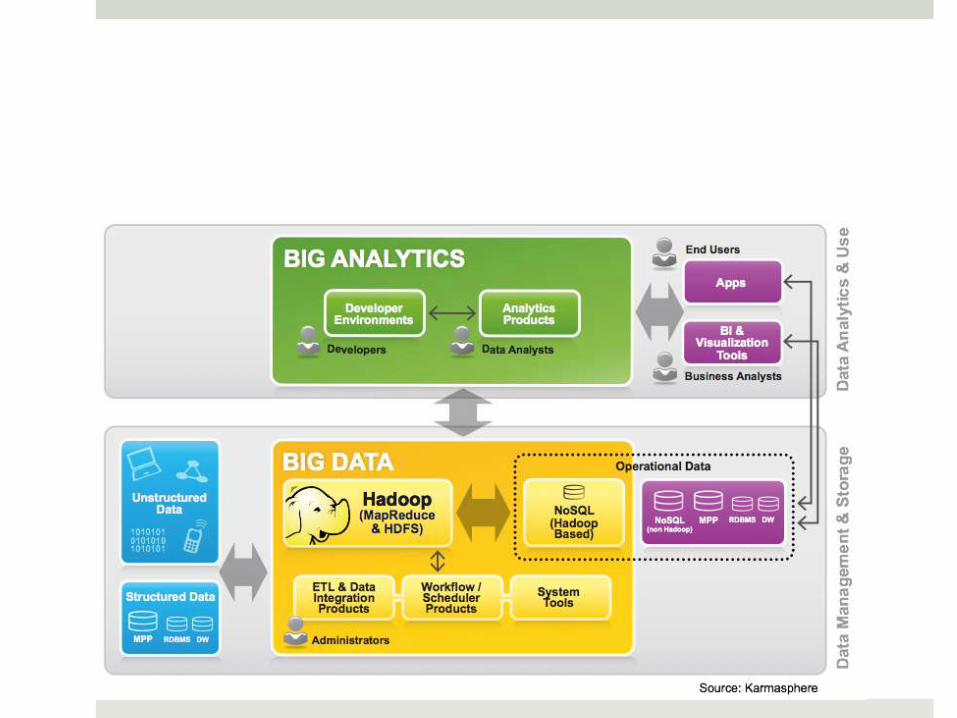
Big Data Elements
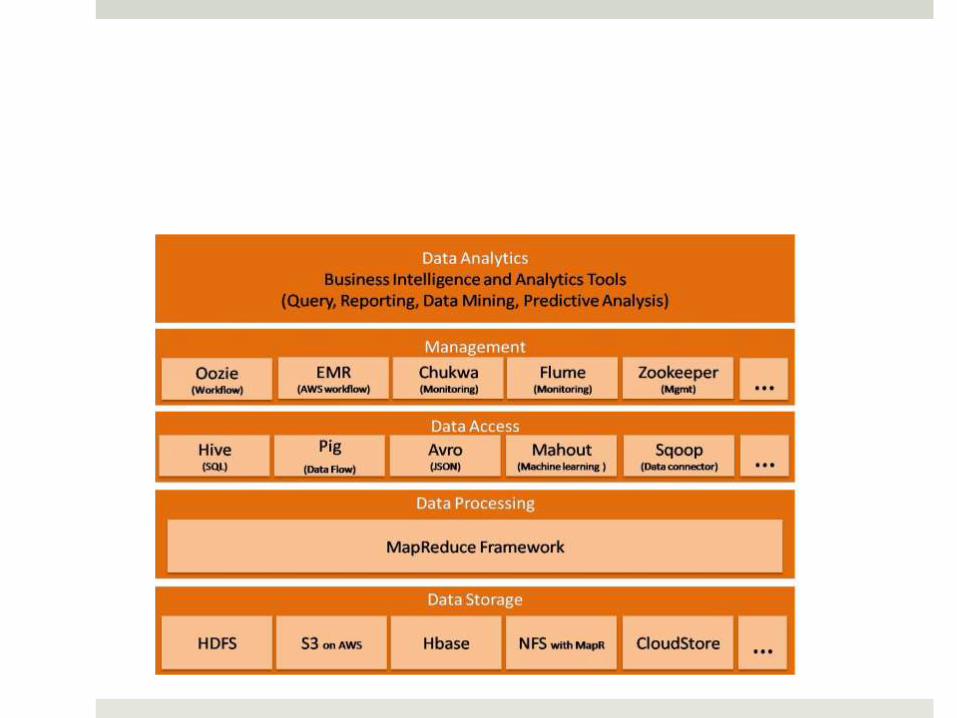
Big Data Ecosystems

Hadoop Overview
Apache™ Hadoop® is an open source software project
that enables the distributed processing of large data sets across clusters of commodity servers.
It is designed to scale up from a single server to thousands of machines, with a very high degree of fault tolerance.
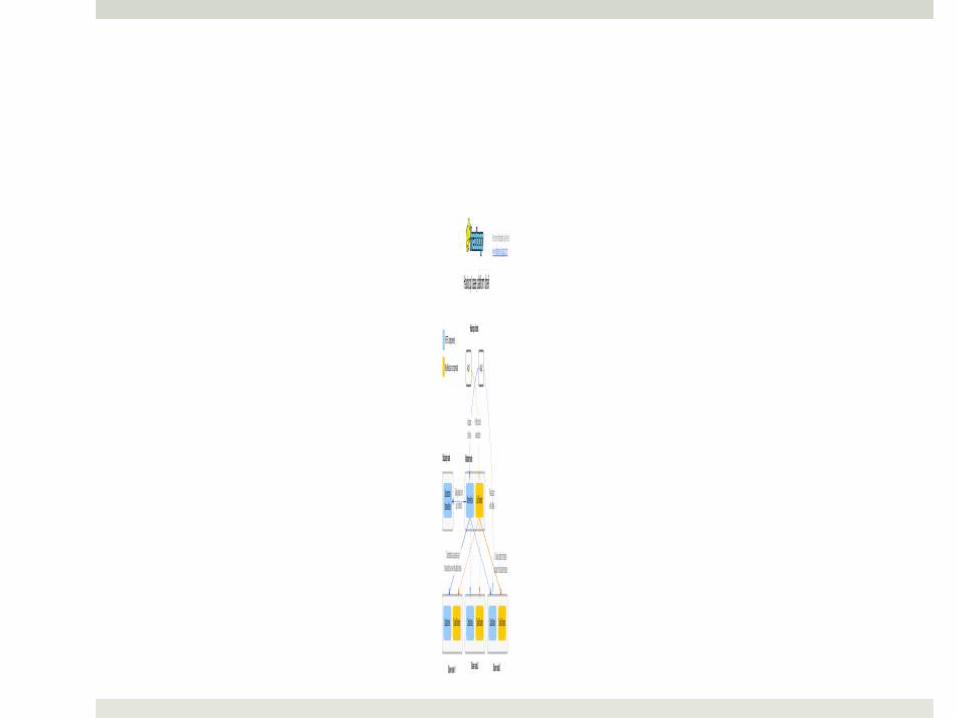
Hadoop Overview: Components

Hadoop Overview: Components
NameNode: The master of HDFS that directs the slave DataNode daemons to perform the low-leve I/O tasks
DataNode: The slave of HDFS that perform the grunt work
of the distributed filesystem (read and write HDFS blocks to actual files on the local file system)
Secondary NameNode: Assistant daemon for monitoring
the state of the cluster HDFS. It communicates with the NameNode to take snapshots of the HDFS metadata

Hadoop Overview: Components
JobTracker: Determines the execution plan by
determining which files to process, assign nodes to different tasks, and monitors all tasks as they’re running
TaskTracker: Manages the execution of individual tasks on each slave node
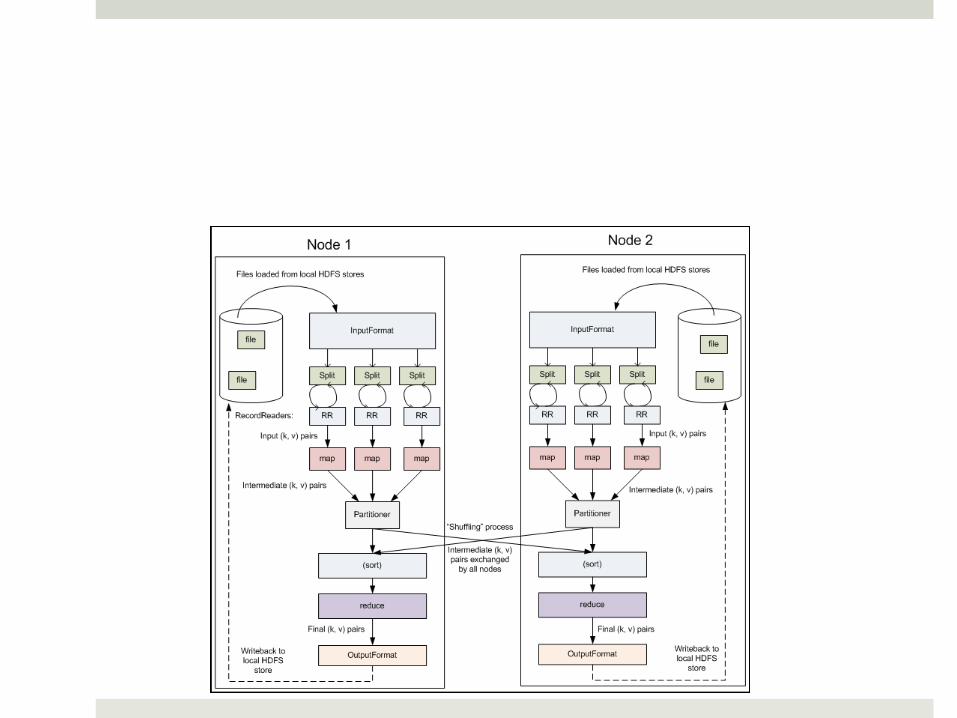
Hadoop Overview: MR Process
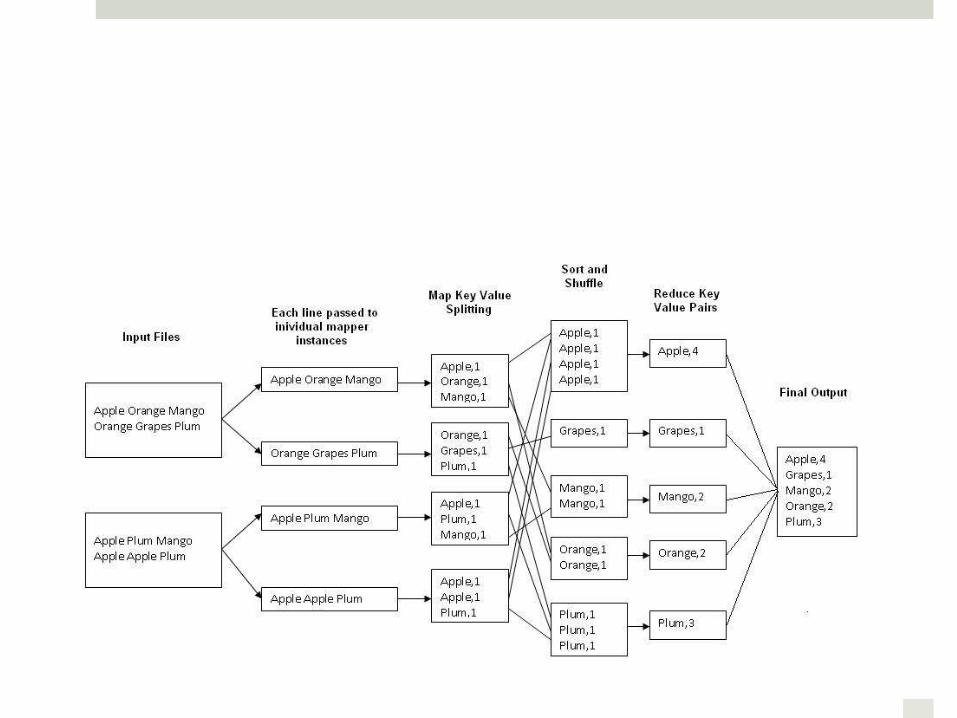
Hadoop Overview: Example

Other Big Data Tools: Hive
Hive allows you to define a structure for your unstructured
big data, simplifying the process of performing analysis and
queries by introducing a familiar, SQL-like language called HiveQL
Hive is for data analysts familiar with SQL who need to do
ad-hoc queries, summarization and data analysis on their HDFS data

Other Big Data Tools: Pig
Pig is an extension of Hadoop that simplifies the ability to query large HDFS datasets
Pig was created at Yahoo! to make it easier to analyze
the data in your HDFS without the complexities of writing a traditional MapReduce program
Pig is made up of two main components:A SQL-like data processing language called Pig Latin
A compiler that compiles and runs Pig Latin scripts
With Pig, you can develop MapReduce jobs with a few lines of Pig Latin

Other Big Data Tools: Pig vs Hive
Pig and Hive work well together
Hive is a good choice:when you want to query the data
when you need an answer to a specific questions
if you are familiar with SQL
Pig is a good choice:for ETL (Extract -> Transform -> Load)
preparing your data so that it is easier to analyze
when you have a long series of steps to perform
At Detik, we use both Pig and Hive together

Other Big Data Tools: FlumeNG
Flume is a distributed, reliable, and available service for
efficiently collecting, aggregating, and moving large amounts of log data

Big Data Processing at Detik
Most PopularGenerates most popular articles within 15 minutes timespan
Employ weightings to balance computation
4 nodes (1 Master + 3 Slaves)
± 2 Gb / 15 mins
Hadoop is used to store and parse Internet log files
Only one Hadoop job for each execution
Akka is used to download Internet log files in parallel and distribute work loads evenly to each slaves

Big Data Processing at Detik
Detik Analytics:Tracking information about web access (similar with Google Analytics/Urchin)
Still in development phase
3 Nodes (1 Master + 2 Slaves)
Hadoop is used to store the input Internet log data and the output Internet log data
Akka is used to manage work balance
Hive is used to generate intermediate tables for calculation process and for calculating some rudimentary metrics
Pig is used to calculate a more complex metrics

Big Data Processing at Detik
Example Analytics Metric:Exit Rate: For all pageviews to the page, the exit rate is the percentage that were the last in the session.
Bounce Rate: For all sessions that start with the page, bounce
rate is the percentage that were the only one of the session.
The bounce rate calculation for a page is based only on visits that start with that page.
Currently DetikForum has 7,756,010 number of processed records
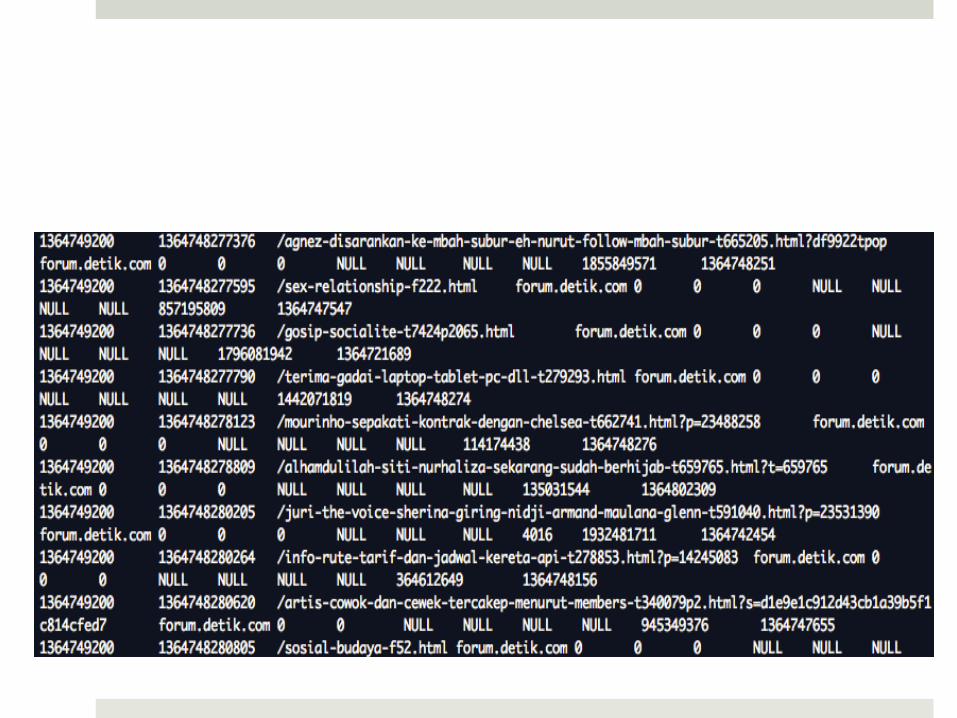
Big Data Processing at Detik

Big Data Processing at Detik
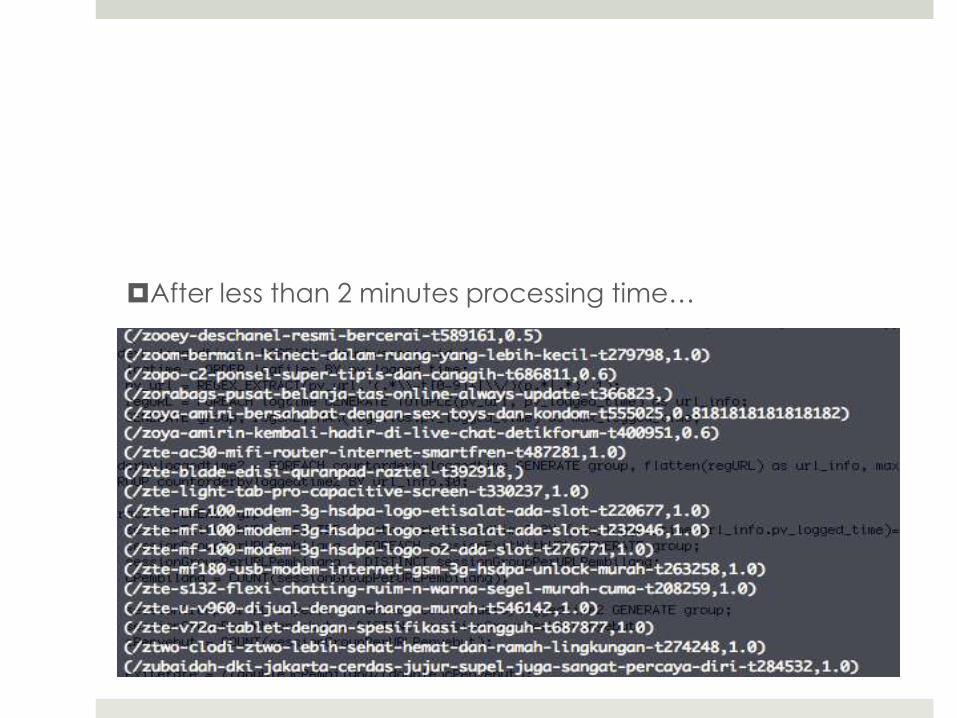
After less than 2 minutes processing time…
Big Data Processing at Detik

Question & Answer?
Thank You!

References
[1] http://www-01.ibm.com/software/data/bigdata/
[2] http://www.sas.com/big-data/

















