13
www.globalbigdataconference .com Twitter : @bigdataconf
| Date post: | 18-Aug-2015 |
| Category: |
Documents |
| Upload: | navneet-gupta |
| View: | 78 times |
| Download: | 3 times |

www.globalbigdataconference.comTwitter :
@bigdataconf

● Data Governance - Democratizing data at Flipkart● Divided into three sub-teams called Ingestion, Processing and Consumption.● Was created out of the vision to make Flipkart a data centric company. (Some
examples are Facebook, Google and LinkedIn) ● Work with all teams in Flipkart and act as a broker between teams for exchanging
data (raw or processed).● Provides capabilities around data processing/consumption but is agnostic to any
knowledge about any business processes. Does not build any apps itself on top of data collected.
● Examples of applications on top of FDP - Seller Analytics
Flipkart Data Platform (FDP)

● Responsibility to push data to FDP lies with source teams.● Responsibility to report data availability lies with FDP. Should call out if
source teams not pushing data.● All the business processes are modeled as entities/events and FDP
provides console to define those entities/events using custom Schema management (Open source solutions include Avro, Thrift, Protocol Buffers).
● Validation is bundled with schema definition.● Having Schema helps to have strong assumptions about fields in data
More about FDP ...

● Flipkart teams work with varied datastores like MySQL, MongoDB, CouchDB, HBase, Hadoop
● Some teams onboard later than others. Bootstrapping of huge volumes of data is performed at times.
● A single ingestion mechanism might not be suitable for all teams at Flipkart. Some teams prefer streaming ingestions, others want batch and some teams want support to ingest their data in a Hadoop Cluster
● Data could be present in many formats like binary blobs, JSON, XML, CSV. We don’t want to deal with each format and support only JSON payloads currently
Data has many faces at Flipkart !

● Almost 2 billion ingestions seen on an average day● Half of those ingestions happening in streaming fashion (HTTP endpoint)● Other ingestion mechanisms
○ Hadoop based ingestion○ Java library ○ Daemons process on source machines ○ Cmdline tools to ingest file in one shot
● Plan to support 5-10x of ingestion numbers for next BBD
Some numbers ...
● Dropwizard based Java app. Endpoints defined for ingesting data● Performs schema validation online.● Relays validated data to KAFKA.● Validation failures go through a different flow and customers are alerted if
the no of failures breaches some rules. ● Clients get 200 response code as well as a traceId when data ingested is
actually accepted by the service● Monitoring is built for the service by exposing JMX metrics which goes to
a central monitoring service.
Streaming Ingestion
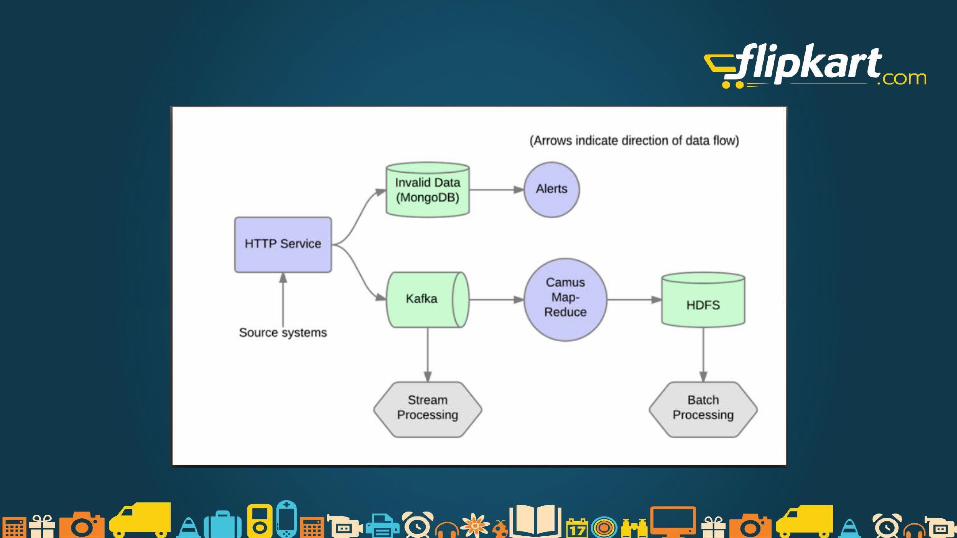

● Kafka is distributed, partitioned, replicated and fault tolerant publish subscribe system (but with a unique design)
● Invented at LinkedIn, Used by many other large companies today (Yahoo, Twitter, Netflix, Uber, Goldman Sachs)
● Has notion of Producers, Consumers, Brokers, Topics, Partitions● Messages are persistent. Multiple consumers can consume messages. Can
consume the same message again by resetting the offset (replay)● Highly scalable and highly configurable● Excellent documentation and community support. ● Battle tested and easy to administor.
More about Kafka


● Kafka is a temporary store and contains data only till last 30 days (configurable by no of days or size)
● Current consumers of our Kafka cluster include batch processing and real-time processing flows.
● We use CAMUS to copy data from Kafka to Hadoop. Camus instance runs every hour currently to copy all the new data in Kafka to Hadoop.
● Stream processing flow built on top of Storm uses official KafkaSpout to consume data from Kafka.
Onto downstream systems ...

● Streaming Ingesting and Processing at FDP - speakerdeck.com/sids/streaming-ingestion-and-processing-at-flipkart
● Kafka - http://kafka.apache.org/081/documentation.html● LinkedIn Camus - https://github.com/linkedin/camus● Apache Avro - http://avro.apache.org/docs/current/● Dropwizard - http://www.dropwizard.io/● Blog on building stream data platform -
http://blog.confluent.io/2015/02/25/stream-data-platform-2/
References

Questions?
BTW, We are hiring !! careers.flipkart.com


















