32
DA 592 Project Kaggle Grupo Bimbo Contest Berker Kozan & Can Köklü 24/09/2016
| Date post: | 16-Apr-2017 |
| Category: |
Documents |
| Upload: | can-koeklue |
| View: | 1,198 times |
| Download: | 2 times |

DA 592 ProjectKaggle Grupo Bimbo Contest
Berker Kozan & Can Köklü
24/09/2016

Overview

Project Description
Kaggle Contest
Grupo Bimbo: Mexican company of fresh bakery products.
Products are shipped from storage facilities to stores.
The following week, unsold products are returned.
Need to predict the correct demand for shipping to stores.

Why Did We Pick This Project?Why Kaggle?
● Test our “Data Science” abilities in an international field
● Kaggle forum
● Clean data and clear goal
● More time for feature engineering and modelling
Why This Project?
● Very common problem
● Chance to work with a very large dataset
● Deadline of the competition (30 August)

Tools
● Python 2.7
● Github
● Jupyter Notebook and Pycharm (integrated with Github)
● NLTK
● XGBoost
● Pickle, HDF5
● Scikit-learn, NumPy, SciPy
● Garbage Collector

Platforms
● Ubuntu (16 GB RAM)
● Macbook Pro (16 GB RAM)
● EC2 Instance on Amazon (100 GB RAM, 16 core CPU)
○ 150$ for 2 days and extra 50$ for backup
● Google Cloud (100 GB RAM, 16 core CPU)
○ 50$ for 1 day
● Google Cloud Preemptible (208 GB RAM, 32 core CPU)
○ 60$ for 3 days
○ Linux command line, connecting with SSH
○ One problem!

Data Provided
Train.csv (3.2 GB)
the training set which includes week 3-9
Test.csv (251 MB)
the test set which includes week 10-11
Sample_submission.csv (69 MB)
a sample submission file in the correct format
cliente_tabla.csv
client names (can be joined with train/test on Cliente_ID)
producto_tabla.csv
product names (can be joined with train/test on Producto_ID)
town_state.csv
town and state (can be joined with train/test on Agencia_ID)
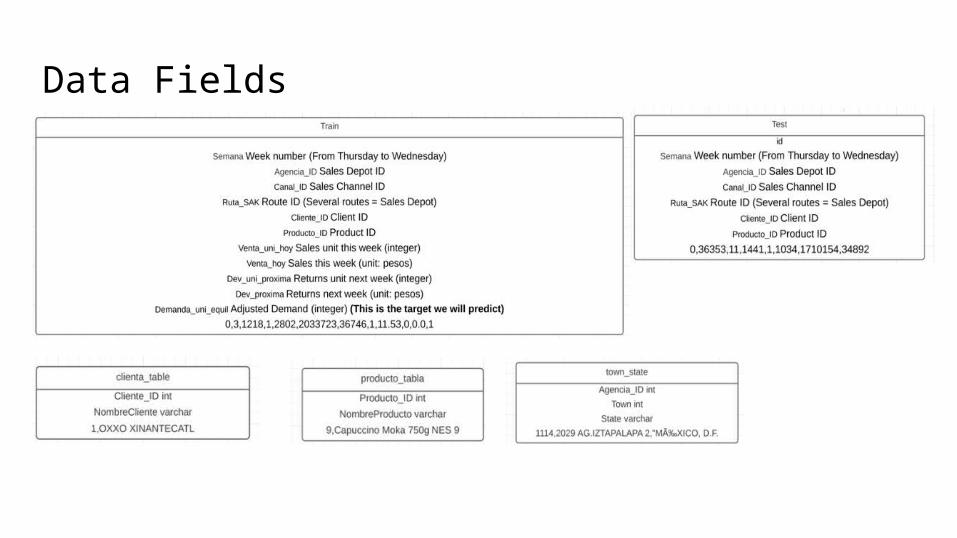
Data Fields
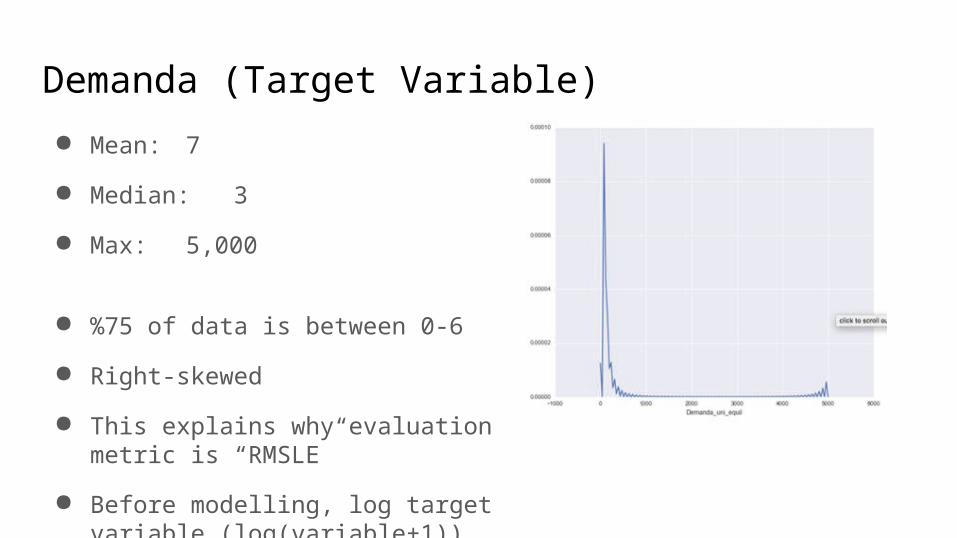
Demanda (Target Variable)● Mean: 7
● Median: 3
● Max: 5,000
● %75 of data is between 0-6
● Right-skewed
● This explains why evaluation metric is “RMSLE”
● Before modelling, log target variable (log(variable+1))
● Before submitting, take exponential (exp(variable)-1)

Evaluation Criteria
The evaluation metric is Root Mean Squared Logarithmic Error.
Public and Private Scores

Dealing with the Large Data
To optimize RAM use and speed up XGBoost performance:
● Forced type of the data explicitly
● Converted integers to unsigned ones
● Decreased the accuracy of floating points as much as possible
Memory usage is reduced from 6.1 GB to 2.1 GB.
An alternative approach would have been reading and processing in chunks.

Building Models

Model 1 - Naive Prediction
We first decided to create a naive approach without using Machine Learning.
● Group training data on Product ID, Client ID, Agency ID and Route ID and took mean of demand
● If this specific grouping doesn’t exist, default back to product’s mean demand
● If this doesn’t exist either, simply take the mean of demand
This method resulted in a score of 0.73 on public data when submitted.
Model 2 - NLTK Based Modelling

Feature Engineering
We utilized NLTK library to extract following information from the Producto file.
● Weight: In grams
● Pieces
● Brand Name: Extracted through a three letter acronym
● Short Name: Extracted from the Product Name field. We first removed the Spanish “stop words” and then used the stemming

Modeling
1. Separate x and y (label) of train;2. Delete train’s columns which don’t exist in test data;3. Match the order of train and test column orders same and append test to train
vertically;4. Merge table with Product Table;5. Use “count-vectorizer” of Scikit-learn on brand and short_name columns to
create sparse count-word matrices;6. Use the output of count-vectorizer to create dummy variables;7. Separate appended train and test data;8. Train XGBoost with default parameters on train data and predict test data.

Technical Problems● Garbage Collection
○ We had to remove unused objects and force garbage collection mechanism manually to free this memory
● Data size because of sparsity
○ 70+ million rows and 577 columns in memory would need ~161 GB
○ We solved this problem by using sparse matrices from SciPy library and memory was 5 GB
○ In the example below, we see “COO” sparse method that holds data only different from 0

Score and Conclusion
RMSLE score were as follows:
These scores were worse than the naive approach, so we started to think about a new model.
Validation Test 10 week Test 11 week
0.764 0.775 0.781
Model 3 - Comprehensive

Digging Deeper Data Exploration
Train - Test difference
● We analyzed missing products, clients, agencies, routes which exist in train but not in test
● There were 9663 clients, 34 products, 0 agencies and 1012 routes that doesn’t exist in test data.
● The important outcome of this analysis was that: we should build a general model that can handle new products, clients and routes which don’t exist in train data but in test data.
Feature Engineering - 1
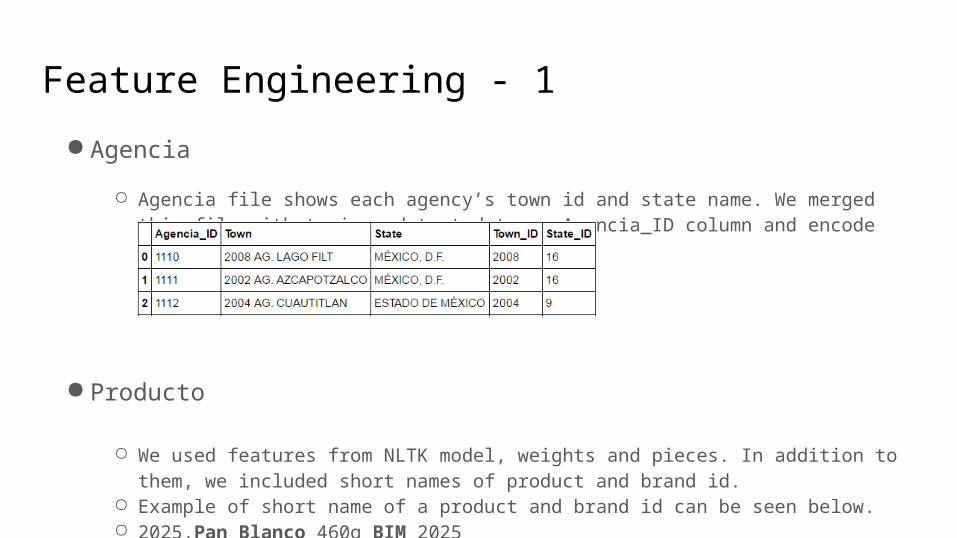
● Agencia
○ Agencia file shows each agency’s town id and state name. We merged this file with train and test data on Agencia_ID column and encode state columns into integers.
● Producto
○ We used features from NLTK model, weights and pieces. In addition to them, we included short names of product and brand id.
○ Example of short name of a product and brand id can be seen below.○ 2025,Pan Blanco 460g BIM 2025
2027,Pan Blanco 567g WON 2027

Feature Engineering - 2
We want to predict how many product are sold in a client came from an agency.
● Why don’t we look at the past numbers of this product which was sold in this client came from this agency?
● If doesn’t exist, why don’t we look at the past numbers of this product sold in this client?
Let’s try this logic with product’s short names and also brand id.
We named these features : Lag0, Lag1, Lag2 and Lag3

Feature Engineering - 3
Other features:
● Total $ amount of a client/product name/product id
● Total unit sold by a client/product name/product id
● Price per unit of a client/product name/product id
● Ratio of goods sold by client/product name/product id
Other features:
● Client per town
● Sum of returns of product
Total Data Size : 10.6 GB
Validation Technique
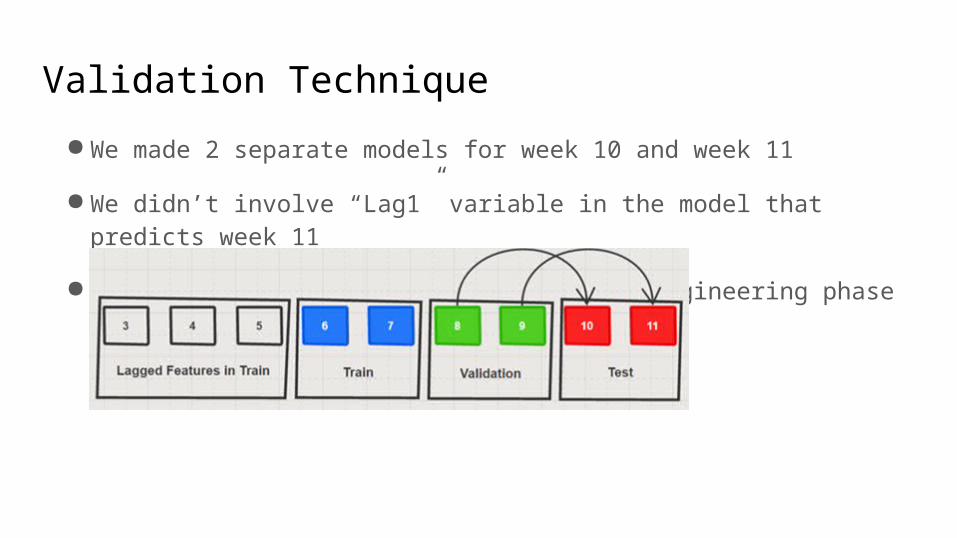
● We made 2 separate models for week 10 and week 11
● We didn’t involve “Lag1” variable in the model that predicts week 11
● We deleted first 3 weeks after feature engineering phase

XGBoost & Parameter Tuning
Why did we pick XGBoost?● Boosting Tree Algorithm
● Both Regression and Classification
● Compiled C++ code
● Multi-Thread
Parameter Tuning:Max depth
Subsample
ColSample
Learning Rate

Technical Problems
● Storing Data○ Picked HDF5 over pickle and csv
● Memory and CPU○ Max 32 core CPU, 75 GB ram
● Code Reuse and Automation○ Object Oriented Python Programming
○ Most of the work was automated. For example:parameterDict = { "ValidationStart":8, "ValidationEnd":9, "maxLag":3, "trainHdfPath":'../../input/train_wz.h5', "testHdfPath1":"../../input/test1_wz.h5".. }...
ConfigElements(1,[ ("SPClR0_mean",["Producto_ID", "Cliente_ID", "Agencia_SAK"], ["mean"]), ("SPCl_mean", ["Producto_ID", "Cliente_ID"], ["mean"])...
Model Comparison
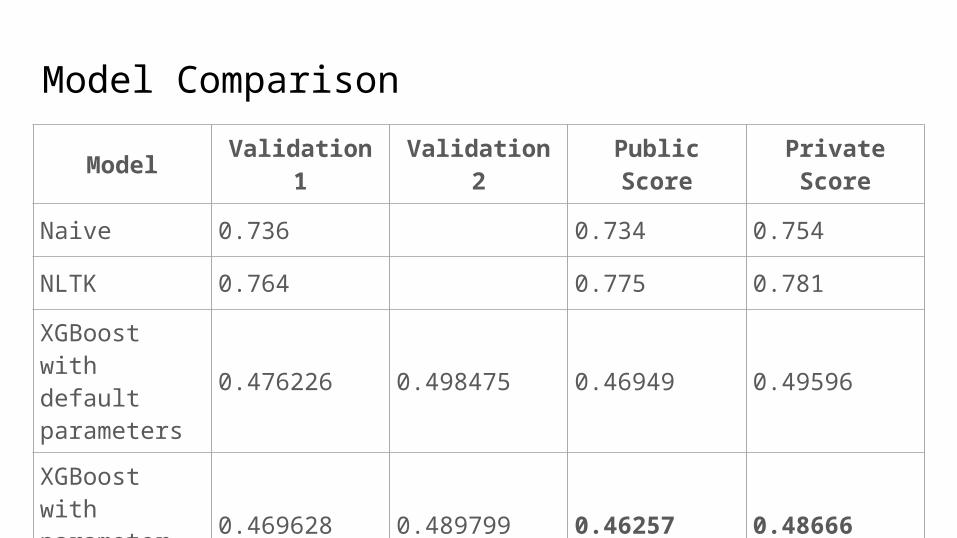
Model Validation 1 Validation 2 Public Score Private Score
Naive 0.736 0.734 0.754
NLTK 0.764 0.775 0.781
XGBoost with default parameters
0.476226 0.498475 0.46949 0.49596
XGBoost with parameter tuning
0.469628 0.489799 0.46257 0.48666

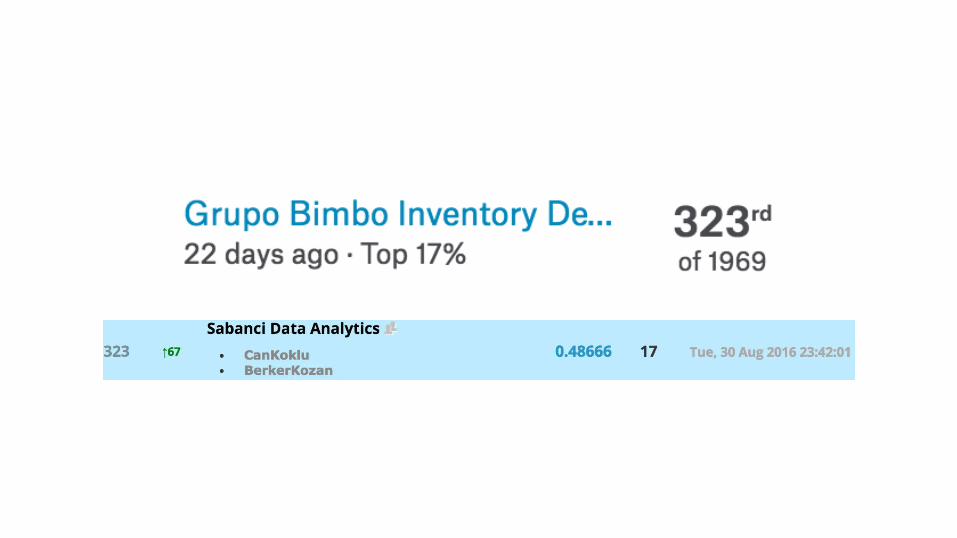
Final Score

Looking Back…
Critical Mistakes
Poor data exploration
Not preparing for system outages
Performing hyperparameter tuning too late

… and forward
Further Exploration
Partial Fitting
Multiple Models
Neural Networks


















