28
BMI 731- Winter 2005 Chapter1: SNP Analysis Catalin Barbacioru Department of Biomedical Informatics Ohio State University
| Date post: | 18-Dec-2015 |
| Category: |
Documents |
| Upload: | donald-murphy |
| View: | 222 times |
| Download: | 0 times |

BMI 731- Winter 2005
Chapter1: SNP Analysis
Catalin Barbacioru
Department of Biomedical Informatics
Ohio State University

Biological Background
• Cells are fundamental working units of every living systems
• The nucleus contains a large DNA (Deoxyribonucleic acid) molecule, which carries the genetic instructions
• A DNA molecule consists of two strands that wrap around each other to resemble a twisted ladder.
• Each strand is composed of one sugar molecule, one phosphate molecule, and a base.
• Four different bases are present in DNA - adenine (A), thymine (T), cytosine (C), and guanine (G).
• The particular order of the bases arranged along the sugar - phosphate backbone is called the DNA sequence

Biological Background

Biological Background
• Each strand of the DNA molecule is held together at its base by weak hydrogen bonds.
• The four bases pair in a set manner: Adenine (A) pairs with thymine (T), while cytosine (C) pairs with guanine (G). These pairs of bases are known as Base Pairs (bp).
• The DNA is organized into separate long segments called chromosomes, where the number of chromosomes differ across organisms (46 for humans or 23 pairs, each parent contributes 23 chromosomes)

Glossary
• Allele = Alternative form of a gene. One of the different forms of a gene that can exist at a single locus.
• Genotype = The specific allelic composition of a cell, either of the entire cell or more commonly for a certain gene or a set of genes.
• Haplotype = A set of closely linked genetic markers present on one chromosome which tend to be inherited together (not easily separable by recombination).

Glossary
• Locus: A point in the genome, identified by a marker, which can be mapped by some means.
• Marker: Also known as a genetic marker, a segment of DNA with an identifiable physical location on a chromosome whose inheritance can be followed. A marker can be a gene, or it can be some section of DNA with no known function.
• Mutation: A permanent structural alteration in DNA.

Glossary
• Hardy-Weinberg equilibrium = The stable frequency distribution of genotypes, AA, Aa, and aa, in the proportions p^2, 2pq, and q^2 respectively (where p and q are the frequencies of the alleles, A and a) that is a consequence of random mating in the absence of mutation, migration, natural selection, or random drift.
• Linkage disequilibrium = When the observed frequencies of haplotypes in a population does not agree with haplotype frequencies predicted by multiplying together the frequency of individual genetic markers in each haplotype.

A Little Population Genetics
• Population genetics (and evolutionary genetics) deal with groups of organisms and families, usually natural populations.
• We can discern two strands of thought in the area. One is the study of very large ("ideal") idealized groups or populations, where models can be deterministic.
• The other is dealing with smaller populations, where the role of chance can play a larger role (so called genetic drift).

Genotype and allele frequencies
One question of crucial interest is this: how common are the different alleles at a given locus in a given population.
The percentages are our best estimate of the probability that an individual will carry that genotype in the population of London, Oxford and Cambridge. The observed heterozygosity is 49.6%.
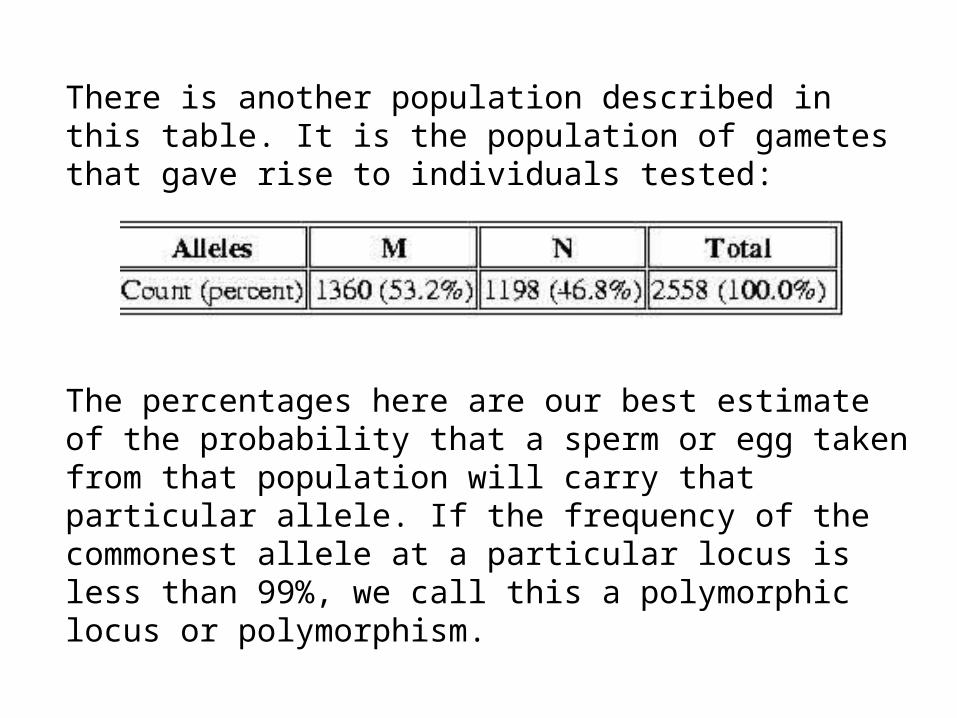
There is another population described in this table. It is the population of gametes that gave rise to individuals tested:
The percentages here are our best estimate of the probability that a sperm or egg taken from that population will carry that particular allele. If the frequency of the commonest allele at a particular locus is less than 99%, we call this a polymorphic locus or polymorphism.

Hardy-Weinberg equilibrium
• Hardy-Weinberg equilibrium describes the relationship between the gametic or allele frequencies, and the resulting genotypic frequencies. It holds if the following properties are true for the given locus,
1.Random mating or panmixia: the choice of a mate is not influenced by his/her genotype at the locus.
2.The locus does not affect the chance of mating at all, either by altering fertility or decreasing survival to reproductive age.

If these properties hold, then the probability that two gametes will meet and give rise to a new genotype is simply the product of the allele frequencies (a la binomial):
P(AA)= P(A) x P(A) = pA2
P(aa)= P(a) x P(a) = pa2
P(Aa)= 1 - P(AA) - P(aa) = 2 x P(A) x P(a) = 2pApa.

Tests for HWEFor a two-allele case, disequilibrium coefficient is :
D = PAA – pA2
where PAA = P(AA) the probability of AA genotype and
pA = P(A) is the probability of allele A.
If nAA, nAa, naa are the numbers of individuals with genotypes AA, Aa and aa respectively, from a total of n individuals, then estimators of the above probabilities are:
PAA = nAA/n, PAa = nAa/n, Paa = naa/n, where n =nAA+nAa+naa
pA = (2nAA+nAa)/2n, pa = (2naa+nAa)/2n and pa + pA = 1

Chi-square testfor HWE
Then under HWE
Genotype AA Aa aa
Observed nAA nAa naa
Expected npA2 2npApa npa
2
Obs-Exp nD -2nD nD

Chi-square testfor HWE
The goodness-of-fit chi-squared statistic is
XA2 = Σgenotypes (Obs-Exp)2/Exp
= (nD)2/npA2 + (-2nD)2/2npApa + (nD)2/npa
2
= nD2/pA2(1-pA)2
and the test rejects (H0) the assumption of HWE if
XA2 > 3.84
The usual problems associated with this test that it is sensitive to small expected values. An alternative version (Yates), which overcomes continuity assumptions is:
XA2 = Σgenotypes (|Obs-Exp|-0.5)2/Exp

Fisher (exact) test for HWE
Under HWE hypothesis, the probability of the observed set of genotypic counts nAA, nAa and naa in a sample of size n is
aaAaAA na
naA
nA
aaAaAAaaAaAA pppp
nnn
nnnnP )()2()(
!!!
!),,( 22
whereas the allele counts nA and na are binomially distributed if HWE holds:
aA na
nA
aAaA pp
nn
nnnP )()(
!!
)!2(),(

Fisher (exact) test for HWE
Putting together, the probability of the observed genotypic frequencies, assuming HWE, conditional on the observed allele frequencies is
)!2(!!!
2!!!
),(
),,,,(),|,,(
nnnn
nnn
nnP
nnnnnPnnnnnP
aaAaAA
naA
aA
aAaaAaAAaAaaAaAA
Aa
which can be expressed in terms of the allele A number andOf the number of heterozygotes nAa. We reject the HWE hypothesis if the above conditional probability is less than the significance level of type I error (α), usually 0.05.

HWE test - ExampleAA Aa aa D Probability(exact) Chi-square
9 1 30 0.1686 0.0000* 34.67*
8 3 29 0.1436 0.0000* 25.15*
7 5 28 0.1186 0.0001* 17.16*
6 7 27 0.0936 0.0024* 10.68*
5 9 26 0.0686 0.0229* 5.74*
0 19 21 -0.056 0.0823 3.88*
4 11 25 0.043 0.1793 2.32
1 17 22 -0.031 0.4101 1.20
3 13 24 0.018 0.6585 0.42
2 15 23 -0.006 1.0000 0.05
* Causes rejection of HWE at 5% significance level

Power and sample size of tests for HWE
•Statistical tests of hypothesis are subject to two kind of errors: a true hypothesis may be rejected (type I error or α or significance level or p-value) or a false hypothesis may not be rejected (type II error or β or 1-power of the test).•For the chi-square test, theory provides that, in large samples, X2 is distributed approximately as a chi-square with 1 d.f. when the hypothesis is true and as a noncentral chi-square when the hypothesis is false i.e.
X2 ~ Χ2(1) when H0 is true
X2 ~ Χ2(1, λ) when H0 is false
where λ is the noncentrality parameter (see tables).

Power and sample size of tests for HWE
The disequilibrium coefficient, D, required for attaining 90% power and a 0.05 significance level for the chi-square test is
nppD AA
5.10)1(
Alternatively, the number of samples required in order to attain 90% power and a 0.05 significance level for the chi-square test when the disequilibrium coefficient is D, is
2
22 )1(5.10
D
ppn AA
* If the required power is 50% or 80%, then 10.5 is replaced by 3.84 or 8.7

Linkage disequilibriumGametic disequilibrium at two loci
Measures the association of two alleles at two different loci.
Given two biallelic loci with alleles A, a and B, b respectively, let the disequilibrium coefficient be
DAB = pAB – pApB.
The (ML) estimator of DAB is DAB = pAB – pApB.
A chi-square statistic for the hypothesis of no disequilibrium, H0: DAB=0, is the test statistic
)1()1(
2 22
BBAA
ABAB pppp
nDX
and the test rejects H0 if XAB2 > 3.84 .

Linkage disequilibriumGametic disequilibrium at two loci
An exact test for gametic linkage disequilibrium depends on the probabilities of all possible samples of gametic numbers for the observed allele numbers. Under the assumption of no linkage disequilibrium
!!!!
)()()()()!2(
),,()( ,
abaBAbAB
nba
nBa
nbA
nBA
abaBAbABAB
nnnn
ppppppppn
nnnnPnP
abaBAbAB
and the allele probabilities are
bB
aA
nb
nB
bBaA
na
nA
aAaA
ppnn
nnnP
ppnn
nnnP
)()(!!
)!2(),(
)()(!!
)!2(),(

Linkage disequilibriumGametic disequilibrium at two loci
Taking the ratio between these quantities gives the probability of gametic numbers conditional on allele numbers:
)!2(!!!!
!!!!),|(
nnnnn
nnnnnnnP
abaBAbAB
bBaABAAB
which depends on n, nAB, nA and nB only. As in the case of HWE, this probability is compared with the chosen significance Level (p-value).

Linkage disequilibrium Genotypic disequilibrium
When genotypes are scored, it is often not possible to distinguish between the two double heterozygotes AB/ab and Ab/aB, so that the gametic frequencies cannot be inferred. Under the assumption of random mating, in which genotypic frequencies are assumed to be the products of gametic frequencies, it is possible to estimate gametic frequencies. A measure of (digenic) linkage disequilibrium between alleles A and B is:
BAAbaB
ABab
ABaB
ABAb
ABABAB ppPPPPP 2)(
2
12

Linkage disequilibrium Genotypic disequilibrium
If the 9 genotypic classes are numbered as
BB Bb bb
AA n1 n2 n3
Aa n4 n5 n6
aa n7 n8 n9
then an (ML) estimator for ΔAB is:
BAAB ppnnnnn
2)2
12(
15421

Linkage disequilibrium Genotypic disequilibrium
The chi-square test statistics for LD is
22
2_
2
,
)1(),1(
,))((
BBBBAAAA
BBBAAA
BBAA
AB
AB
pPDpPD
pppp
DD
nX
Note the explicit way in which departures from HW are Included in this expresion.

Δ2 represents the statistical correlation between two sites, and takes value 1 if only two haplotypes are present. It is arguably the most relevant measure for association between susceptibility loci and SNPs. For example, suppose SNP1 is involved in disease susceptibility, but we genotype cases and controls at a nearby site SNP2. Then, to achieve the same power to detect associations at SNP2 as we would have at SNP1, we need to increase our sample size by a factor of 1/ Δ2.

These measures are defined for pairs of sites, but for some applications we might instead want to measure how strong LD is across an entire region that contains many polymorphic sites — for example, for testing whether the strength of LD differs significantly among loci or across populations, or whether there is more or less LD in a region than predicted under a particular model. Measuring LD across a region is not straightforward, but one approach is to use the measure ρ, which measures how much recombination would be required under a particular population model to generate the LD that is seen in the data. The development of methods for estimating is now an active research. This type of method can potentially also provide a statistically rigorous approach to the problem of determining whether LD data provide evidence for the presence of hotspots.

















