21
Breeding Decision Trees Using Evolutionary Techniques Written by Athanasios Papagelis Dimitris Kalles Presented by Alexandre Temporel
| Date post: | 27-Dec-2015 |
| Category: |
Documents |
| Upload: | nicholas-wilkinson |
| View: | 217 times |
| Download: | 0 times |

Breeding Decision Trees Using Evolutionary Techniques
Written by
Athanasios Papagelis
Dimitris Kalles
Presented by Alexandre Temporel

AbstractThe idea is to make use of evolutionary techniques to evolve
decision trees.
Can the learner:
• search efficiently simple & complex hypotheses space?• Discover conditionally dependant attributes?
irrelevant
• Tests using standard concept learning and also compared to two known algorithms:
– C4.5 (Quinlan, 1993)– OneR (Holte, 1993)
GOAL: demonstrates the potential advantages of this evolutionary techniques compared to other classifiers.

Outline1) Problem Statement
2) Construction of GATree System.
- Operators
- Fitness function
- Advanced features
3) Experiments
- 1st exp: search efficiently simple & complex hypotheses space
- 2nd exp: conditionally dependant attributes
irrelevant attributes
- 3rd exp: search target concepts on standard databases
4) Discussion on the search type of GATree
5) Conclusion

Related workGas have widely been used for classification and concept learning tasks:
J.Bala, J.Huang and H.Valaie (1995)Hybrid Learning Using Genetic Algorithms and Decision Trees for Pattern ClassificationSchool of Information and Engineering
Work on their ability as a tool to evolve decision trees:
Burnett C.Nathan (may 2001)Evolutionary Induction of Decision Trees
Kenneth A.De Jong, William M.Spears and Dianna F.GordonUse Genetic Algorithms for concept learningNaval Research Laboratory
Koza R. KozaConcept formation and decision tree induction using the genetic programming paradigm
Martijn C.J. Bot and William B.LangdonApplication of Genetic Programming to Induction of Linear Classification Trees
H.Kennedy, C.Chinniah, P.Bradbeer, L.MorssThe construction and Evaluation of Decision Trees: a comparison of Evolutionary and Concept Learning MethodsNapier University
Problem statement(1/2)
Also if presence of irrelevant attributes in a data set...
Mislead the impurity functions...
Produce bigger, less comprehensible andlower performance tree.
Using these Evolutionary techniques allow us to:• overcome the use of greedy heuristics• search the hypotheses space in a natural way• evolve simple, accurate, robust and simple decision trees
Problem statement(2/2)
Decision trees used in many domains (i.e.: pattern classification)
Proven to be NP complete (Murthy, 1998)
Current inductive learning algorithms use:• Information gain, gain ratio (Quinlan, 1986)• Gini Index (Breiman 1984)
Assumption: attributes are conditionally independents
Poor performance on ‘strong conditional dependence’ data-set

GATree system(1/3): Operators
GATree program uses GALIB (Wall, 1996), a robust C++ library of Genetic Algorithm components. http://lancet.mit.edu/ga/
Initial population: we use minimal binary decision trees
Crossover Operation
Mutation Operator

GATree system(2/3) : Fitness function
xtree
xssifiedCorrectClatreefitness
iii
2
2 *)(
))(),(()( iii treeSIZEtreeACCURACYftreepayoff
))(),(()( iii treeSIZEtreeACCURACYftreefitness
Factor Size x is a constant (i.e. x=1000)
• If x is small, the fitness figure decreases with bigger trees.» SMALLER TREES->BETTER FITNESS
• If x is large, we search bigger search space.» ONLY ACCURACY REALLY MATTERS

GATree system(3/3) : Advanced features
))(),(()( iii treeSIZEtreeACCURACYftreepayoff
• Overcrowding problem (Goldberg)
use of a scaled payoff function ( which reduces fitness of similar trees in a population )
• Use of alternative crossover and mutation operators
More Accurate sub-trees have less chance to be selected for crossover or mutation
• To Speed Up evolution, use of:
Limited Error Fitness (LEF) (GatherCole&Rose, 1997)
CPU timesaving with insignificant accuracy losses

Experiments: foreword(1/2)
1st experiment: we use DataGen (Melli,1999) to generate artificial data set using random rules (to ensure complexity variety).
The goal is to reconstruct the underlying knowledge.
2nd experiment: We use more or less complicated target concepts (Xor, parity....) and see how GATree performs against C4.5.
3rd experiment: We use WEKA (Witten & Frank, 2000) to test C4.5 and OneR algorithms.
==> Use of 5 fold cross-validation
Experiments: foreword(2/2)
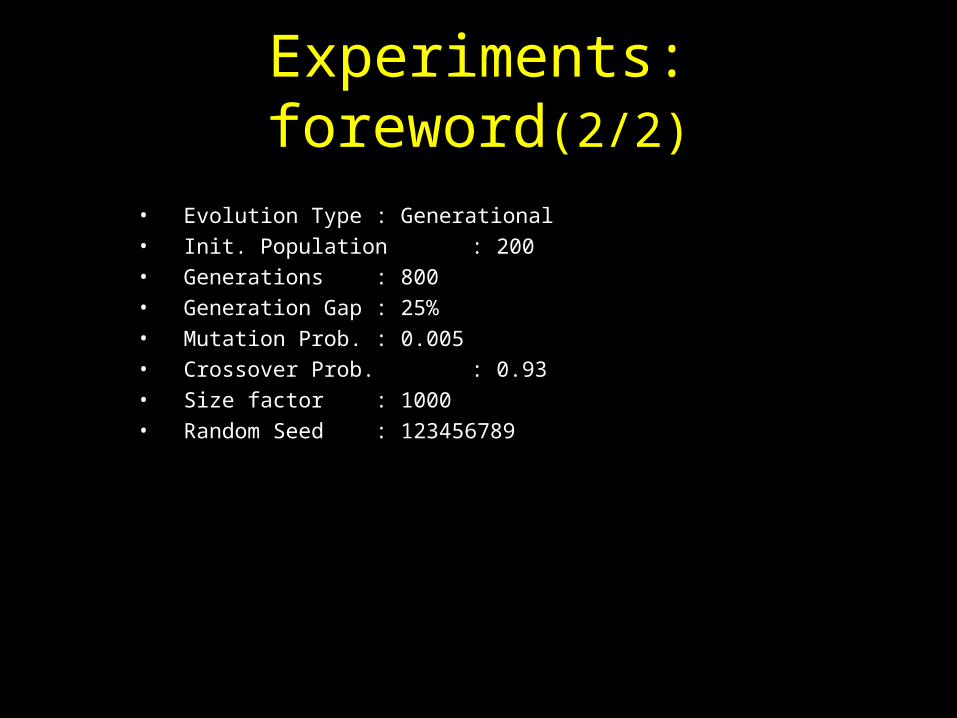
• Evolution Type : Generational• Init. Population : 200• Generations : 800• Generation Gap : 25%• Mutation Prob. : 0.005• Crossover Prob. : 0.93• Size factor : 1000• Random Seed : 123456789

1st exp: Simple concept3 Rules to extract:(31.0%) c1 <- B=(f or g or j) & C=(a or g or j)(28.0%) c2 <- C=(b or e)(41.0%) c3 <- B=(b or i) & C=(d or i)
size
Best individual
Fitn
ess-
accu
racy
Size
Number of generations

1st exp: Complex concept8 Rules to extract:(15.0%) c1 <- B=(f or l or s or w) & C=(c or e or f or k)(14.0%) c2 <- A= (a or b or t) & B=(a or h or q or k).................................Etc....
size
Best individual
Fitn
ess-
accu
racy
Size
Number of generations
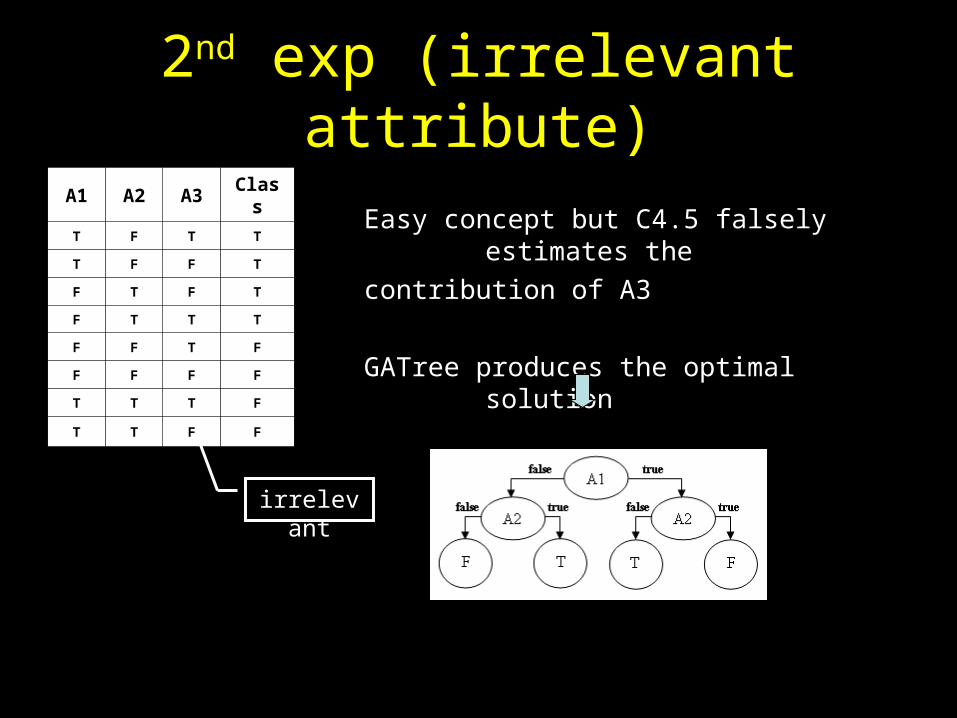
2nd exp (irrelevant attribute)A1 A2 A3 Class
T F T T
T F F T
F T F T
F T T T
F F T F
F F F F
T T T F
T T F F
Easy concept but C4.5 falsely estimates the
contribution of A3
GATree produces the optimal solution
irrelevant
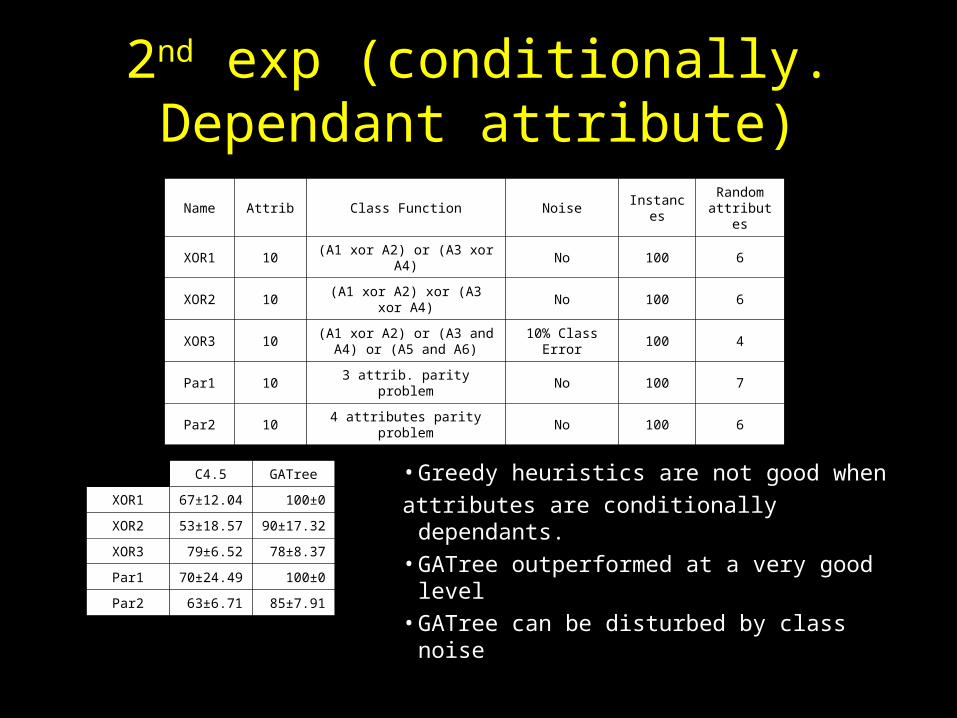
2nd exp (conditionally. Dependant attribute)
Name Attrib Class Function Noise InstancesRandom attributes
XOR1 10 (A1 xor A2) or (A3 xor A4) No 100 6
XOR2 10 (A1 xor A2) xor (A3 xor A4) No 100 6
XOR3 10(A1 xor A2) or (A3 and A4) or
(A5 and A6)10% Class
Error100 4
Par1 10 3 attrib. parity problem No 100 7
Par2 10 4 attributes parity problem No 100 6
• Greedy heuristics are not good when
attributes are conditionally dependants.• GATree outperformed at a very good level• GATree can be disturbed by class noise
C4.5 GATree
XOR1 67±12.04 100±0
XOR2 53±18.57 90±17.32
XOR3 79±6.52 78±8.37
Par1 70±24.49 100±0
Par2 63±6.71 85±7.91

3rd exp (results on standard sets)
Greedy heuristics are not good when
attributes are conditionally dependants.
GATree outperformed at a very good level
GATree can be disturbed by class noise
Accuracy Size
C4.5 OneR GATree C4.5 GATree
Colic 83.84±3.41 81.37±5.36 85.01±4.55 27.4 5.84
Heart-Statlog 74.44±3.56 76.3±3.04 77.48±3.07 39.4 8.28
Diabetes 66.27±3.71 63.27±2.59 63.97±3.71 140.6 6.6
Credit 83.77±2.93 86.81±4.45 86.81±4 57.8 3
Hepatitis 77.42±6.84 84.52±6.2 80.46±5.39 19.8 5.56
Iris 92±2.98 94.67±3.8 93.8±4.02 9.6 7.48
Labor 85.26±7.98 72.73±14.37 87.27±7.24 8.6 8.72
Lymph 65.52±14.63 74.14±7.18 75.24±10.69 28.2 7.96
Breast-Cancer 71.93±5.11 68.17±7.93 71.03±8.34 35.4 6.68
Zoo 90±7.91 43.8±10.47 82.4±4.02 17 10.12
Vote 96.09±3.86 95.63±4.33 95.63±4.33 11 3
Glass 55.24±7.49 43.19±4.33 53.48±4.33 60.2 8.98
Balance-Scale 78.24±4.4 59.68±4.4 71.15±6.47 106.6 8.92
AVERAGES 78.46 72.64 79.75 43.2 7.01

3rd exp (observations)
• GA trees performs as well as or a bit better than C4.5 on the
standard data sets.
• But trees size produces by GA trees are 6 times smaller than when using C4.5.
• OneR is good for noisy datasets but performs substantially worse
overall.

Discussion on Search type of GATree
GATree adopts a less greedy strategy than other learners
It tries to minimise the size of the tree and maximise the accuracy
GATree are not hill climbing searcher
exhaustive
But more a type of beam search (exploration / exploitation)
However when tuned properly they have the same characteristics

ConclusionDerived hypotheses of standard algorithms can substantially
deviate from the optimum.
Due to their greedy strategy
Can be solved by using global metrics
of tree quality
Compared to greedy induction, GATree produces:
Accurate trees
Small size
Comprehensible
GA adapt themselves dynamically on a variety of different target concepts

EncodingIt is important for a problem to select the proper encoding. Encoding represents the mapping of solved problem to one of the following dimensional space:
• Value encodingchromosome A: 45.9845 12.8375 102.46556 55.3857 36.39857
• Binary encodingChromosomes in binary encoding are strings of 0 or 1. They can look like that ones shown on next example : chromosome A: 10001010001111101010111
• Tree encodingGAs may also be used for program designing and construction. In that case chromosome genes represent programming language commands, mathematical operations and other components of program.We use Natural representation of the search space using actual decision trees and not binary strings....
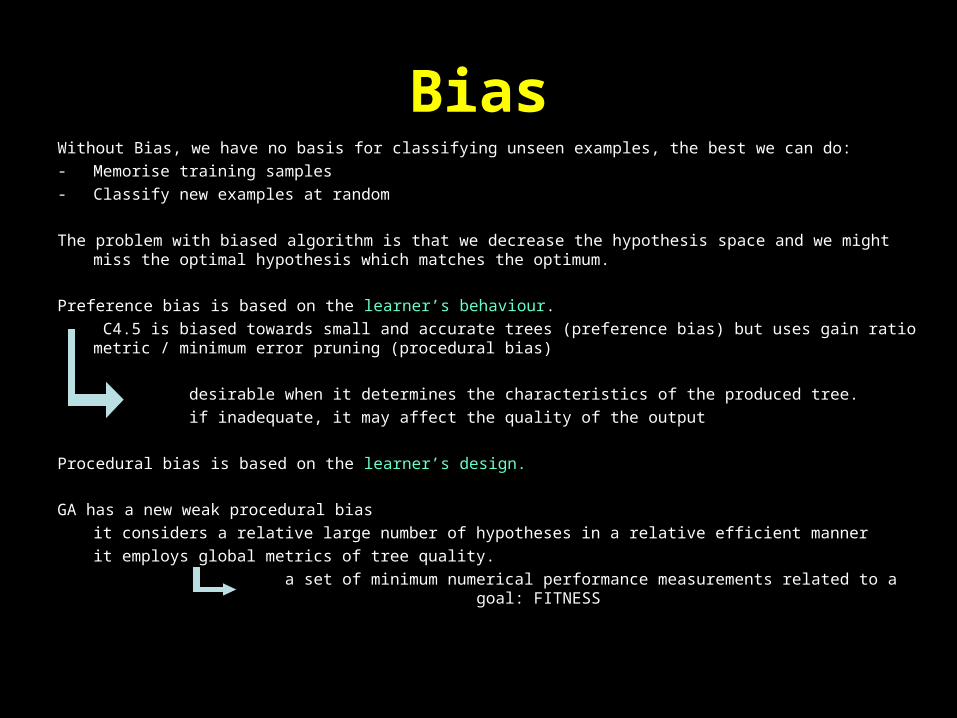
BiasWithout Bias, we have no basis for classifying unseen examples, the best we can do:- Memorise training samples- Classify new examples at random
The problem with biased algorithm is that we decrease the hypothesis space and we might miss the optimal hypothesis which matches the optimum.
Preference bias is based on the learner’s behaviour.
C4.5 is biased towards small and accurate trees (preference bias) but uses gain ratio metric / minimum error pruning (procedural bias)
desirable when it determines the characteristics of the produced tree.
if inadequate, it may affect the quality of the output
Procedural bias is based on the learner’s design.
GA has a new weak procedural bias
it considers a relative large number of hypotheses in a relative efficient manner
it employs global metrics of tree quality.
a set of minimum numerical performance measurements related to a goal: FITNESS

















