30
SYSTAP LLC | © 2006-2015 All Rights Reserved MLConf @ NYC: March 27, 2015
| Date post: | 15-Jul-2015 |
| Category: |
Technology |
| Upload: | sessionsevents |
| View: | 536 times |
| Download: | 0 times |

SYSTAP LLC | © 2006-2015 All Rights Reserved
MLConf @ NYC: March 27, 2015

SYSTAP LLC | © 2006-2015 All Rights Reserved
Graph Databases Grew at Over 500% in the Last Two YearsPopularity changes per category – March 2015
Popu
larit
y Ch
ange
s
Graph Databases
SYSTAP LLC | © 2006-2015 All Rights Reserved
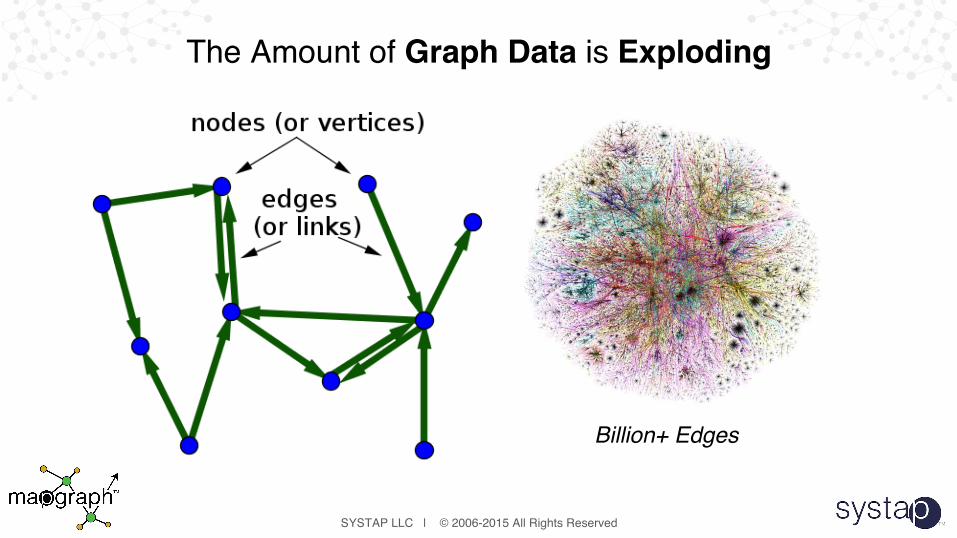
The Amount of Graph Data is Exploding
Billion+ Edges

SYSTAP LLC | © 2006-2015 All Rights Reserved
Graphs are different. You need the right paradigm and hardware to scale.
https://datatake.files.wordpress.com/2014/09/latency.png
Graph Cache Thrash The CPU just waits for graph data from main memory...
Type
of C
ache
or M
emor
y
Access Latency Per Clock Cycle

SYSTAP LLC | © 2006-2015 All Rights Reserved
SYSTAP Solves the Graph Scaling Problem Using GPUs
● 100s of Times Faster than CPU main memory-based systems
● Up to 40X Cheaper
● 10,000X Faster than disk-based technologies
● High Level API

SYSTAP LLC | © 2006-2015 All Rights Reserved
Uncovering influence links in molecular knowledge networks to streamline personalized medicine | Shin, Dmitriy et al.Journal of Biomedical Informatics , Volume 52 , 394 - 405
Finding the Next Cure for Cancer is a Billion+ Edge Graph Challenge

SYSTAP LLC | © 2006-2015 All Rights Reserved
Graph is BIG and changing(Trillion+ Edges)

SYSTAP LLC | © 2006-2015 All Rights Reserved
Graphs Enable People to Find Knowledge
A Bunch of Pages An Answer

http://BlazeGraph.com http://MapGraph.io
Parallel&Breadth&First&Search&on&GPU&Clusters&
SYSTAP™, LLC © 2006-2015 All Rights Reserved
1 3/15/15
This work was (partially) funded by the DARPA XDATA program under AFRL Contract #FA8750-13-C-0002. This material is based upon work supported by the Defense Advanced Research Projects Agency (DARPA) under Contract No. D14PC00029. The authors would like to thank Dr. White, NVIDIA, and the MVAPICH group at Ohio State University for their support of this work. Z. Fu, H.K. Dasari, B. Bebee, M. Berzins, B. Thompson. Parallel Breadth First Search on GPU Clusters. IEEE Big Data. Bethesda, MD. 2014.
h6p://mapgraph.io&

http://BlazeGraph.com http://MapGraph.io
Many?Core&is&Your&Future&
SYSTAP™, LLC © 2006-2015 All Rights Reserved
2 3/10/15

http://BlazeGraph.com http://MapGraph.io
MapGraph:&Extreme&performance&
• GTEPS&is&Billions&(10^9)&of&Traversed&Edges&per&Second.&– This&is&the&basic&measure&of&performance&for&graph&traversal.&
Configura)on* Cost* GTEPS* $/GTEPS*
4?Core&CPU& $4,000& 0.2& $5,333&
45Core*CPU*+**K20*GPU* $7,000* 3.0* $2,333*
XMT?2&(rumored&price)& $1,800,000& 10.0& $188,000&
64*GPUs*(32*nodes*with*2x*K20*GPUs*per*node*and*InfiniBand*DDRx4*–*today)*
$500,000* 30.0* $16,666*
16*GPUs*(2*nodes*with*8x*Pascal*GPUs*per*node*and*InfiniBand*DDRx4*–*Q1,*2016)*
$125,000* >30.0* <$4,166*
SYSTAP™, LLC © 2006-2015 All Rights Reserved
3 3/10/15

http://BlazeGraph.com http://MapGraph.io
SYSTAP’s&MapGraph&APIs&Roadmap&
• Vertex&Centric&API&– Same&performance&as&CUDA.&
• Schema?flexible&data?model&– Property&Graph&/&RDF&– Reduce&import&hassles&– Opera_ons&over&merged&graphs&
• Graph&pa6ern&matching&language&• DSL/Scala&=>&CUDA&code&genera_on&
SYSTAP™, LLC © 2006-2015 All Rights Reserved
Ease&of&Use&
4 3/10/15

http://BlazeGraph.com http://MapGraph.io
Breadth&First&Search&
• Fundamental&building&block&for&graph&algorithms&
– Including&SPARQL&(JOINs)&• In&level&synchronous&steps&
– Label&visited&verDces&• For&this&graph&
– IteraDon&0&– IteraDon&1&– IteraDon&2&
• Hard&problem!&
– Basis&for&Graph&500&benchmark&
SYSTAP™, LLC © 2006-2015 All Rights Reserved
10 3/10/15
0&
1&1&
2&
1&
1&
2&
2&2&
2&
1&
3&
2&
3&
2&
2& 3&
2&
http://BlazeGraph.com http://MapGraph.io
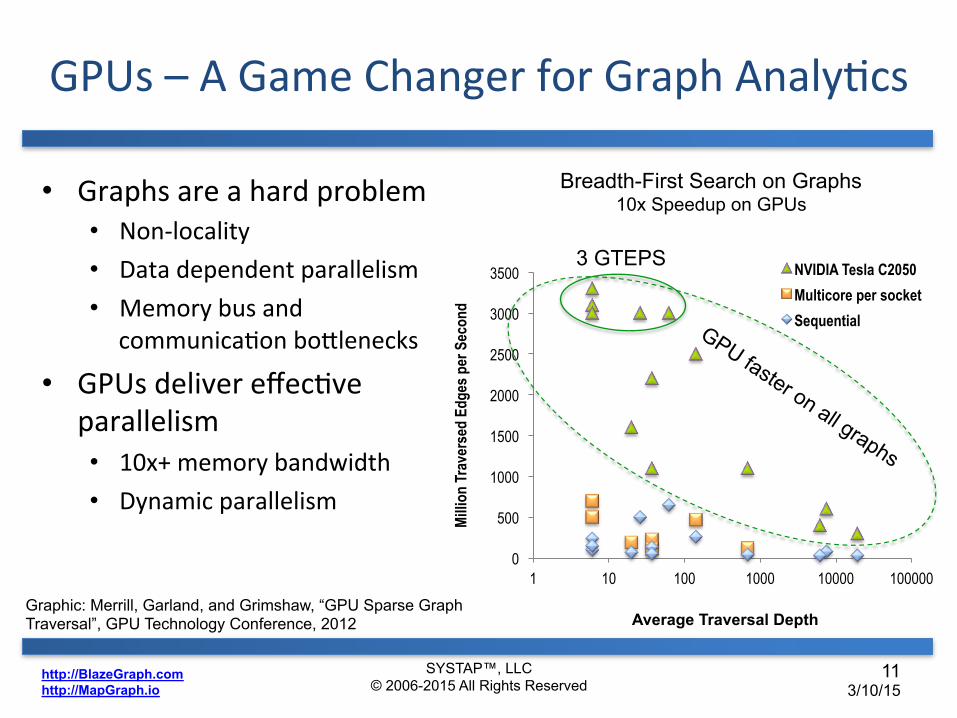
GPUs&–&A&Game&Changer&for&Graph&AnalyDcs&
0
500
1000
1500
2000
2500
3000
3500
1 10 100 1000 10000 100000
Mill
ion
Trav
erse
d Ed
ges
per S
econ
d
Average Traversal Depth
NVIDIA Tesla C2050
Multicore per socket
Sequential
Breadth-First Search on Graphs 10x Speedup on GPUs
3 GTEPS
• Graphs&are&a&hard&problem&
• Non?locality&• Data&dependent¶llelism&
• Memory&bus&and&
communicaDon&bo6lenecks&
• GPUs&deliver&effecDve¶llelism&
• 10x+&memory&bandwidth&
• Dynamic¶llelism&
SYSTAP™, LLC © 2006-2015 All Rights Reserved
11 3/10/15
Graphic: Merrill, Garland, and Grimshaw, “GPU Sparse Graph Traversal”, GPU Technology Conference, 2012

http://BlazeGraph.com http://MapGraph.io
2D&Par__oning&(aka&Vertex&Cuts)&• p&x&p&compute&grid&
– Edges&in&rows/cols&– Minimize&messages&
• log(p)&(versus&p2)&– One&par__on&per&GPU&
• Batch¶llel&opera_on&– Grid&row:&out?edges&– Grid&column:&in?edges&
• Representa_ve&fron_ers&
SYSTAP™, LLC © 2006-2015 All Rights Reserved
5 3/10/15
G11
G22
G33
G44
C1
C2
C3
C4
R1
In2
t
Out1
t
Out2
t
Out3
t
Out4
t
In1
tIn
3
tIn
4
t
R2
R3
R4
Source&Ver_ces&
Target&Ver_ces&
out-edges
in-e
dges
BFS& PR&Query&
• Parallelism&–&work&must&be&distributed&and&balanced.&
• Memory&bandwidth&–&memory,¬&disk,&is&the&bo6leneck&

http://BlazeGraph.com http://MapGraph.io
1
10
100
1,000
10,000
100,000
1,000,000
10,000,000
0 1 2 3 4 5 6
Fron
tier S
ize
Iteration
Scale&25&Traversal&• Work&spans&mul_ple&orders&of&magnitude.&
SYSTAP™, LLC © 2006-2015 All Rights Reserved
6 3/10/15

http://BlazeGraph.com http://MapGraph.io
Distributed&BFS&Algorithm&
SYSTAP™, LLC © 2006-2015 All Rights Reserved
7 3/10/15
1: procedure BFS(Root, Predecessor)2: In0
ij
LocalVertex(Root)3: for t 0 do4: Expand(Int
i
, Outtij
)5: LocalFrontier
t
Count(Outtij
)6: GlobalFrontier
t
Reduce(LocalFrontiert
)
7: if GlobalFrontiert
> 0 then8: Contract(Outt
ij
, Outtj
, Int+1
i
, Assignij
)9: UpdateLevels(Outt
j
, t, level)10: else11: UpdatePreds(Assign
ij
,Predsij
, level)12: break13: end if14: t++15: end for16: end procedure
Figure 3. Distributed Breadth First Search algorithm
1: procedure EXPAND(Int
i
, Outtij
)2: L
in
convert(Inti
)
3: Lout
;4: for all v 2 L
in
in parallel do5: for i RowOff[v],RowOff[v + 1] do6: c ColIdx[i]7: L
out
c8: end for9: end for
10: Outtij
convert(Lout
)
11: end procedure
Figure 4. Expand algorithm
1: procedure CONTRACT(Outtij
, Outtj
, Int+1
i
, Assignij
)2: Prefixt
ij
ExclusiveScanj
(Outtij
)
3: Assignedij
Assignedij
[ (Outtij
� Prefixt
ij
)
4: if i = p then5: Outt
j
Outtij
[ Prefixtij
6: end if7: Broadcast(Outt
j
, p , ROW )8: if i = j then9: Int+1
i
Outtj
10: end if11: Broadcast(Int+1
i
, i, COL)12: end procedure
Figure 5. Global Frontier contraction and communication algorithm
1: procedure UPDATELEVELS(Outtj
, t, level)2: for all v 2 Outt
j
in parallel do3: level[v] t4: end for5: end procedure
Figure 6. Update levels
1: procedure UPDATEPREDS(Assignedij
, Predsij
, level)2: for all v 2 Assigned
ij
in parallel do3: Pred[v] �14: for i ColOff[v],ColOff[v + 1] do5: if level[v] == level[RowIdx[i]] + 1 then6: Pred[v] RowIdx[i]7: end if8: end for9: end for
10: end procedure
Figure 7. Predecessor update
for finding the Prefixtij
, which is the bitmap obtained byperforming Bitwise-OR Exclusive Scan operation on Outt
ij
across each row j as shown in line 2 of Figure 5. Thereare several tree-based algorithms for parallel prefix sum.Since the bitmap union operation is very fast on the GPU,the complexity of the parallel scan is less important thanthe number of communication steps. Therefore, we use analgorithm having the fewest communication steps (log p)[14] even though it has a lower work efficiency and doesp log p bitmap unions compared to p bitmap unions for workefficient algorithms.
At each iteration t, Assignedij
is computed as shown inline 3 of Figure 5. In line 7, the contracted Outt
j
bitmapcontaining the vertices discovered in iteration t is broadcastback to the GPUs of the row R
j
from the last GPU inthe row. This is done to update the GPUs with the visitedvertices so that they do not produce a frontier containingthose vertices in the future iterations. It is also necessary forupdating the levels of the vertices. The Outt
j
becomes theInt+1
j
. Since both Outtj
and Int+1
i
are the same for the GPUsin the diagonal (i = j), in line 9, we copy Outt
j
to Int+1
i
inthe diagonal GPUs and then broadcast across the columnsC
i
using MPI_Broadcast in line 11. Communicators weresetup along every row and column during initialization tofacilitate these parallel scan and broadcast operations.
During each BFS iteration, we must test for terminationof the algorithm by checking if the global frontier size iszero as in line 6 of Figure 3. We currently test the globalfrontier using a MPI_Allreduce operation after the GPU localedge expansion and before the global frontier contractionphase. However, an unexplored optimization would overlapthe termination check with the global frontier contractionand communication phase in order to hide its component inthe total time.
D. Computing the Predecessors
Unlike the Blue Gene/Q [7], we do not use remotemessages to update the vertex state (the predecessor and/orlevel) during traversal. Instead, each GPU stores the lev-els associated with vertices in both Int
j
frontier and Outtj
frontier (See Figure 6 for the update level algorithm). This
! Data parallel 1-hop expand on all GPUs
! Termination check
! Local frontier size ! Global frontier size
! Compute predecessors from local In / Out levels (no communication) ! Done
! Starting vertex
! Global Frontier contraction (“wave”) ! Record level of vertices in the In /
Out frontier
! Next iteration

http://BlazeGraph.com http://MapGraph.io
Distributed&BFS&Algorithm&
SYSTAP™, LLC © 2006-2015 All Rights Reserved
8 3/10/15
1: procedure BFS(Root, Predecessor)2: In0
ij
LocalVertex(Root)3: for t 0 do4: Expand(Int
i
, Outtij
)5: LocalFrontier
t
Count(Outtij
)6: GlobalFrontier
t
Reduce(LocalFrontiert
)
7: if GlobalFrontiert
> 0 then8: Contract(Outt
ij
, Outtj
, Int+1
i
, Assignij
)9: UpdateLevels(Outt
j
, t, level)10: else11: UpdatePreds(Assign
ij
,Predsij
, level)12: break13: end if14: t++15: end for16: end procedure
Figure 3. Distributed Breadth First Search algorithm
1: procedure EXPAND(Int
i
, Outtij
)2: L
in
convert(Inti
)
3: Lout
;4: for all v 2 L
in
in parallel do5: for i RowOff[v],RowOff[v + 1] do6: c ColIdx[i]7: L
out
c8: end for9: end for
10: Outtij
convert(Lout
)
11: end procedure
Figure 4. Expand algorithm
1: procedure CONTRACT(Outtij
, Outtj
, Int+1
i
, Assignij
)2: Prefixt
ij
ExclusiveScanj
(Outtij
)
3: Assignedij
Assignedij
[ (Outtij
� Prefixt
ij
)
4: if i = p then5: Outt
j
Outtij
[ Prefixtij
6: end if7: Broadcast(Outt
j
, p , ROW )8: if i = j then9: Int+1
i
Outtj
10: end if11: Broadcast(Int+1
i
, i, COL)12: end procedure
Figure 5. Global Frontier contraction and communication algorithm
1: procedure UPDATELEVELS(Outtj
, t, level)2: for all v 2 Outt
j
in parallel do3: level[v] t4: end for5: end procedure
Figure 6. Update levels
1: procedure UPDATEPREDS(Assignedij
, Predsij
, level)2: for all v 2 Assigned
ij
in parallel do3: Pred[v] �14: for i ColOff[v],ColOff[v + 1] do5: if level[v] == level[RowIdx[i]] + 1 then6: Pred[v] RowIdx[i]7: end if8: end for9: end for
10: end procedure
Figure 7. Predecessor update
for finding the Prefixtij
, which is the bitmap obtained byperforming Bitwise-OR Exclusive Scan operation on Outt
ij
across each row j as shown in line 2 of Figure 5. Thereare several tree-based algorithms for parallel prefix sum.Since the bitmap union operation is very fast on the GPU,the complexity of the parallel scan is less important thanthe number of communication steps. Therefore, we use analgorithm having the fewest communication steps (log p)[14] even though it has a lower work efficiency and doesp log p bitmap unions compared to p bitmap unions for workefficient algorithms.
At each iteration t, Assignedij
is computed as shown inline 3 of Figure 5. In line 7, the contracted Outt
j
bitmapcontaining the vertices discovered in iteration t is broadcastback to the GPUs of the row R
j
from the last GPU inthe row. This is done to update the GPUs with the visitedvertices so that they do not produce a frontier containingthose vertices in the future iterations. It is also necessary forupdating the levels of the vertices. The Outt
j
becomes theInt+1
j
. Since both Outtj
and Int+1
i
are the same for the GPUsin the diagonal (i = j), in line 9, we copy Outt
j
to Int+1
i
inthe diagonal GPUs and then broadcast across the columnsC
i
using MPI_Broadcast in line 11. Communicators weresetup along every row and column during initialization tofacilitate these parallel scan and broadcast operations.
During each BFS iteration, we must test for terminationof the algorithm by checking if the global frontier size iszero as in line 6 of Figure 3. We currently test the globalfrontier using a MPI_Allreduce operation after the GPU localedge expansion and before the global frontier contractionphase. However, an unexplored optimization would overlapthe termination check with the global frontier contractionand communication phase in order to hide its component inthe total time.
D. Computing the Predecessors
Unlike the Blue Gene/Q [7], we do not use remotemessages to update the vertex state (the predecessor and/orlevel) during traversal. Instead, each GPU stores the lev-els associated with vertices in both Int
j
frontier and Outtj
frontier (See Figure 6 for the update level algorithm). This
• Key&differences&• log(p)¶llel&scan&(vs&sequen_al&wave)&• GPU?local&computa_on&of&predecessors&• 1&par__on&per&GPU&• GPUDirect&(vs&RDMA)&
! Data parallel 1-hop expand on all GPUs
! Termination check
! Local frontier size ! Global frontier size
! Compute predecessors from local In / Out levels (no communication) ! Done
! Starting vertex
! Global Frontier contraction (“wave”) ! Record level of vertices in the In /
Out frontier
! Next iteration

http://BlazeGraph.com http://MapGraph.io
Global&Fron_er&Contrac_on&and&Communica_on&
SYSTAP™, LLC © 2006-2015 All Rights Reserved
9 3/10/15
1: procedure BFS(Root, Predecessor)2: In0
ij
LocalVertex(Root)3: for t 0 do4: Expand(Int
i
, Outtij
)5: LocalFrontier
t
Count(Outtij
)6: GlobalFrontier
t
Reduce(LocalFrontiert
)
7: if GlobalFrontiert
> 0 then8: Contract(Outt
ij
, Outtj
, Int+1
i
, Assignij
)9: UpdateLevels(Outt
j
, t, level)10: else11: UpdatePreds(Assign
ij
,Predsij
, level)12: break13: end if14: t++15: end for16: end procedure
Figure 3. Distributed Breadth First Search algorithm
1: procedure EXPAND(Int
i
, Outtij
)2: L
in
convert(Inti
)
3: Lout
;4: for all v 2 L
in
in parallel do5: for i RowOff[v],RowOff[v + 1] do6: c ColIdx[i]7: L
out
c8: end for9: end for
10: Outtij
convert(Lout
)
11: end procedure
Figure 4. Expand algorithm
1: procedure CONTRACT(Outtij
, Outtj
, Int+1
i
, Assignij
)2: Prefixt
ij
ExclusiveScanj
(Outtij
)
3: Assignedij
Assignedij
[ (Outtij
� Prefixt
ij
)
4: if i = p then5: Outt
j
Outtij
[ Prefixtij
6: end if7: Broadcast(Outt
j
, p , ROW )8: if i = j then9: Int+1
i
Outtj
10: end if11: Broadcast(Int+1
i
, i, COL)12: end procedure
Figure 5. Global Frontier contraction and communication algorithm
1: procedure UPDATELEVELS(Outtj
, t, level)2: for all v 2 Outt
j
in parallel do3: level[v] t4: end for5: end procedure
Figure 6. Update levels
1: procedure UPDATEPREDS(Assignedij
, Predsij
, level)2: for all v 2 Assigned
ij
in parallel do3: Pred[v] �14: for i ColOff[v],ColOff[v + 1] do5: if level[v] == level[RowIdx[i]] + 1 then6: Pred[v] RowIdx[i]7: end if8: end for9: end for
10: end procedure
Figure 7. Predecessor update
for finding the Prefixtij
, which is the bitmap obtained byperforming Bitwise-OR Exclusive Scan operation on Outt
ij
across each row j as shown in line 2 of Figure 5. Thereare several tree-based algorithms for parallel prefix sum.Since the bitmap union operation is very fast on the GPU,the complexity of the parallel scan is less important thanthe number of communication steps. Therefore, we use analgorithm having the fewest communication steps (log p)[14] even though it has a lower work efficiency and doesp log p bitmap unions compared to p bitmap unions for workefficient algorithms.
At each iteration t, Assignedij
is computed as shown inline 3 of Figure 5. In line 7, the contracted Outt
j
bitmapcontaining the vertices discovered in iteration t is broadcastback to the GPUs of the row R
j
from the last GPU inthe row. This is done to update the GPUs with the visitedvertices so that they do not produce a frontier containingthose vertices in the future iterations. It is also necessary forupdating the levels of the vertices. The Outt
j
becomes theInt+1
j
. Since both Outtj
and Int+1
i
are the same for the GPUsin the diagonal (i = j), in line 9, we copy Outt
j
to Int+1
i
inthe diagonal GPUs and then broadcast across the columnsC
i
using MPI_Broadcast in line 11. Communicators weresetup along every row and column during initialization tofacilitate these parallel scan and broadcast operations.
During each BFS iteration, we must test for terminationof the algorithm by checking if the global frontier size iszero as in line 6 of Figure 3. We currently test the globalfrontier using a MPI_Allreduce operation after the GPU localedge expansion and before the global frontier contractionphase. However, an unexplored optimization would overlapthe termination check with the global frontier contractionand communication phase in order to hide its component inthe total time.
D. Computing the Predecessors
Unlike the Blue Gene/Q [7], we do not use remotemessages to update the vertex state (the predecessor and/orlevel) during traversal. Instead, each GPU stores the lev-els associated with vertices in both Int
j
frontier and Outtj
frontier (See Figure 6 for the update level algorithm). This
! Distributed prefix sum. Prefix is vertices discovered by your left neighbors (log p)
! Vertices first discovered by this GPU.
! Right most column has global frontier for the row
! Broadcast frontier over row.
! Broadcast frontier over column.

http://BlazeGraph.com http://MapGraph.io
Global&Fron_er&Contrac_on&and&Communica_on&
SYSTAP™, LLC © 2006-2015 All Rights Reserved
10 3/10/15
1: procedure CONTRACT(Outtij
, Outtj
, Int+1
i
, Assignij
)2: Prefixt
ij
ExclusiveScanj
(Outtij
)
3: Assignedij
Assignedij
[ (Outtij
� Prefixt
ij
)
4: if i = p then5: Outt
j
Outtij
[ Prefixtij
6: end if7: Broadcast(Outt
j
, p , ROW )8: if i = j then9: Int+1
i
Outtj
10: end if11: Broadcast(Int+1
i
, i, COL)12: end procedure
!&Distributed&prefix&sum.&Prefix&is&ver_ces&discovered&by&your&lel&neighbors&(log&p)&
! Vertices first discovered by this GPU.
! Right most column has global frontier for the row
! Broadcast frontier over row.
! Broadcast frontier over column.
G11
G22
G33
G44
C1
C2
C3
C4
R1
In2
t
Out1
t
Out2
t
Out3
t
Out4
t
In1
tIn
3
tIn
4
t
R2
R3
R4
Source&Ver_ces&
Target&Ver_ces&

http://BlazeGraph.com http://MapGraph.io
Global&Fron_er&Contrac_on&and&Communica_on&
SYSTAP™, LLC © 2006-2014 All Rights Reserved
11 3/10/15
1: procedure CONTRACT(Outtij
, Outtj
, Int+1
i
, Assignij
)2: Prefixt
ij
ExclusiveScanj
(Outtij
)
3: Assignedij
Assignedij
[ (Outtij
� Prefixt
ij
)
4: if i = p then5: Outt
j
Outtij
[ Prefixtij
6: end if7: Broadcast(Outt
j
, p , ROW )8: if i = j then9: Int+1
i
Outtj
10: end if11: Broadcast(Int+1
i
, i, COL)12: end procedure
• We&use&a¶llel&scan&that&minimizes&communica_on&steps&(vs&work).&• This&improves&the&overall&scaling&efficiency&by&30%.&
!*Distributed*prefix*sum.*Prefix*is*ver)ces*discovered*by*your*leZ*neighbors*(log*p)*
! Vertices first discovered by this GPU.
! Right most column has global frontier for the row
! Broadcast frontier over row.
! Broadcast frontier over column.
G11
G22
G33
G44
C1
C2
C3
C4
R1
In2
t
Out1
t
Out2
t
Out3
t
Out4
t
In1
tIn
3
tIn
4
t
R2
R3
R4
Source&Ver_ces&
Target&Ver_ces&

http://BlazeGraph.com http://MapGraph.io
Global&Fron_er&Contrac_on&and&Communica_on&
SYSTAP™, LLC © 2006-2014 All Rights Reserved
12 3/15/15
1: procedure CONTRACT(Outtij
, Outtj
, Int+1
i
, Assignij
)2: Prefixt
ij
ExclusiveScanj
(Outtij
)
3: Assignedij
Assignedij
[ (Outtij
� Prefixt
ij
)
4: if i = p then5: Outt
j
Outtij
[ Prefixtij
6: end if7: Broadcast(Outt
j
, p , ROW )8: if i = j then9: Int+1
i
Outtj
10: end if11: Broadcast(Int+1
i
, i, COL)12: end procedure
• We&use&a¶llel&scan&that&minimizes&communica_on&steps&(vs&work).&• This&improves&the&overall&scaling&efficiency&by&30%.&
! Vertices first discovered by this GPU.
! Right most column has global frontier for the row
! Broadcast frontier over row.
! Broadcast frontier over column.
G11
G22
G33
G44
C1
C2
C3
C4
R1
In2
t
Out1
t
Out2
t
Out3
t
Out4
t
In1
tIn
3
tIn
4
t
R2
R3
R4
Source&Ver_ces&
Target&Ver_ces&
!*Distributed*prefix*sum.*Prefix*is*ver)ces*discovered*by*your*leZ*neighbors*(log*p)*

http://BlazeGraph.com http://MapGraph.io
Global&Fron_er&Contrac_on&and&Communica_on&
SYSTAP™, LLC © 2006-2014 All Rights Reserved
13 3/15/15
1: procedure CONTRACT(Outtij
, Outtj
, Int+1
i
, Assignij
)2: Prefixt
ij
ExclusiveScanj
(Outtij
)
3: Assignedij
Assignedij
[ (Outtij
� Prefixt
ij
)
4: if i = p then5: Outt
j
Outtij
[ Prefixtij
6: end if7: Broadcast(Outt
j
, p , ROW )8: if i = j then9: Int+1
i
Outtj
10: end if11: Broadcast(Int+1
i
, i, COL)12: end procedure
• We&use&a¶llel&scan&that&minimizes&communica_on&steps&(vs&work).&• This&improves&the&overall&scaling&efficiency&by&30%.&
! Vertices first discovered by this GPU.
! Right most column has global frontier for the row
! Broadcast frontier over row.
! Broadcast frontier over column.
G11
G22
G33
G44
C1
C2
C3
C4
R1
In2
t
Out1
t
Out2
t
Out3
t
Out4
t
In1
tIn
3
tIn
4
t
R2
R3
R4
Source&Ver_ces&
Target&Ver_ces&
!&Distributed&prefix&sum.&Prefix&is&ver_ces&discovered&by&your&lel&neighbors&(log&p)&

http://BlazeGraph.com http://MapGraph.io
Global&Fron_er&Contrac_on&and&Communica_on&
SYSTAP™, LLC © 2006-2014 All Rights Reserved
14 3/15/15
1: procedure CONTRACT(Outtij
, Outtj
, Int+1
i
, Assignij
)2: Prefixt
ij
ExclusiveScanj
(Outtij
)
3: Assignedij
Assignedij
[ (Outtij
� Prefixt
ij
)
4: if i = p then5: Outt
j
Outtij
[ Prefixtij
6: end if7: Broadcast(Outt
j
, p , ROW )8: if i = j then9: Int+1
i
Outtj
10: end if11: Broadcast(Int+1
i
, i, COL)12: end procedure
! Distributed prefix sum. Prefix is vertices discovered by your left neighbors (log p)
! Vertices first discovered by this GPU.
! Right most column has global frontier for the row
! Broadcast frontier over row.
! Broadcast frontier over column.
G11
G22
G33
G44
C1
C2
C3
C4
R1
In2
t
Out1
t
Out2
t
Out3
t
Out4
t
In1
tIn
3
tIn
4
t
R2
R3
R4
Source&Ver_ces&
Target&Ver_ces&

http://BlazeGraph.com http://MapGraph.io
Global&Fron_er&Contrac_on&and&Communica_on&
SYSTAP™, LLC © 2006-2014 All Rights Reserved
15 3/15/15
1: procedure CONTRACT(Outtij
, Outtj
, Int+1
i
, Assignij
)2: Prefixt
ij
ExclusiveScanj
(Outtij
)
3: Assignedij
Assignedij
[ (Outtij
� Prefixt
ij
)
4: if i = p then5: Outt
j
Outtij
[ Prefixtij
6: end if7: Broadcast(Outt
j
, p , ROW )8: if i = j then9: Int+1
i
Outtj
10: end if11: Broadcast(Int+1
i
, i, COL)12: end procedure
! Distributed prefix sum. Prefix is vertices discovered by your left neighbors (log p)
! Vertices first discovered by this GPU.
! Right most column has global frontier for the row
! Broadcast frontier over row.
! Broadcast frontier over column.
G11
G22
G33
G44
C1
C2
C3
C4
R1
In2
t
Out1
t
Out2
t
Out3
t
Out4
t
In1
tIn
3
tIn
4
t
R2
R3
R4
Source&Ver_ces&
Target&Ver_ces&
• All&GPUs&now&have&the&new&fron_er.&

http://BlazeGraph.com http://MapGraph.io
Weak&Scaling&• Scaling&the&problem&size&with&
more&GPUs&– Fixed&problem&size&per&GPU.&
• Maximum&scale&27&(4.3B&edges)&– 64&K20&GPUs&=>&.147s&=>&29>EPS&– 64&K40&GPUs&=>&.135s&=>&32>EPS&
• K40&has&faster&memory&bus.&0
5
10
15
20
25
30
35
1 4 16 64
GTE
PS
#GPUs
GPUs& Scale& Ver)ces& Edges& Time*(s)& GTEPS&
1& 21& 2,097,152& 67,108,864& 0.0254* 2.5&
4& 23& 8,388,608& 268,435,456& 0.0429* 6.3&
16& 25& 33,554,432& 1,073,741,824& 0.0715* 15.0&
64& 27& 134,217,728& 4,294,967,296& 0.1478* 29.1&
SYSTAP™, LLC © 2006-2015 All Rights Reserved
16 3/10/15
Scaling the problem size with more GPUs.

http://BlazeGraph.com http://MapGraph.io
Central&Itera_on&Costs&(Weak&Scaling)&
SYSTAP™, LLC © 2006-2015 All Rights Reserved
17 3/10/15
0.0000
0.0020
0.0040
0.0060
0.0080
0.0100
0.0120
4 16 64
Tim
e (S
econ
ds)
#GPUs
ComputationCommunicationTermination
• Communica_on&costs&are¬&constant.&
• 2D&design&implies&cost&grows&as&2*log(2p)/log(p)*
• How&to&scale?&– Overlapping&– Compression&
• Graph&• Message&
– Hybrid&par__oning&– Heterogeneous&
compu_ng&

http://BlazeGraph.com http://MapGraph.io
Costs&During&BFS&Traversal&
SYSTAP™, LLC © 2006-2015 All Rights Reserved
18 3/10/15
• Chart&shows&the&different&costs&for&each&GPU&in&each&itera_on&(64&GPUs).&• Wave&_me&is&essen_ally&constant,&as&expected.&• Compute&_me&peaks&during&the¢ral&itera_ons.&• Costs&are&reasonably&well&balanced&across&all&GPUs&aler&the&2nd&itera_on.&

http://BlazeGraph.com http://MapGraph.io
Strong&Scaling&• Speedup&on&a&constant&problem&size&with&more&GPUs&• Problem&scale&25&
– 2^25&ver_ces&(33,554,432)&– 2^26&directed&edges&(1,073,741,824)&
• Strong&scaling&efficiency&of&48%&– Versus&44%&for&BG/Q&
GPUs* GTEPS* Time*(s)*16* 15.2* 0.071*25* 18.2* 0.059*36* 20.5* 0.053*49& 21.8& 0.049*64* 22.7* 0.047*
SYSTAP™, LLC © 2006-2015 All Rights Reserved
19 3/10/15
Speedup on a constant problem size with more GPUs.

http://BlazeGraph.com http://MapGraph.io
MapGraph&Beta&Customer?&&
Contact&Bradley&Bebee&
20 3/10/15
SYSTAP™, LLC © 2006-2015 All Rights Reserved

















