40
Building a Big Data Solution by Using IBM DB2 for z/OS Session #IDZ-4759A Jane Man, IBM Jason Cu, IBM Rick Chang © 2014 IBM Corporation
| Date post: | 16-Feb-2017 |
| Category: |
Data & Analytics |
| Upload: | jane-man |
| View: | 193 times |
| Download: | 0 times |

Building a Big Data Solution by Using IBM DB2 for z/OSSession #IDZ-4759A
Jane Man, IBM
Jason Cu, IBM
Rick Chang
© 2014 IBM Corporation

Please Note
• IBM’s statements regarding its plans, directions, and intent are subject to change orwithdrawal without notice at IBM’s sole discretion.
• Information regarding potential future products is intended to outline our general product direction and it should not be relied on in making a purchasing decision.
• The information mentioned regarding potential future products is not a commitment, promise, or legal obligation to deliver any material, code or functionality. Information about potential future products may not be incorporated into any contract.
• The development, release, and timing of any future features or functionality described for our products remains at our sole discretion.
Performance is based on measurements and projections using standard IBM benchmarks in a controlled environment. The actual throughput or performance that any user will experience will vary depending upon many factors, including considerations such as the amount of multiprogramming in the user’s job stream, the I/O configuration, the storage configuration, and the workload processed. Therefore, no assurance can be given that an individual user will achieve results similar to those stated here.
2

BigInsights “Connector” for DB2 for z/OS
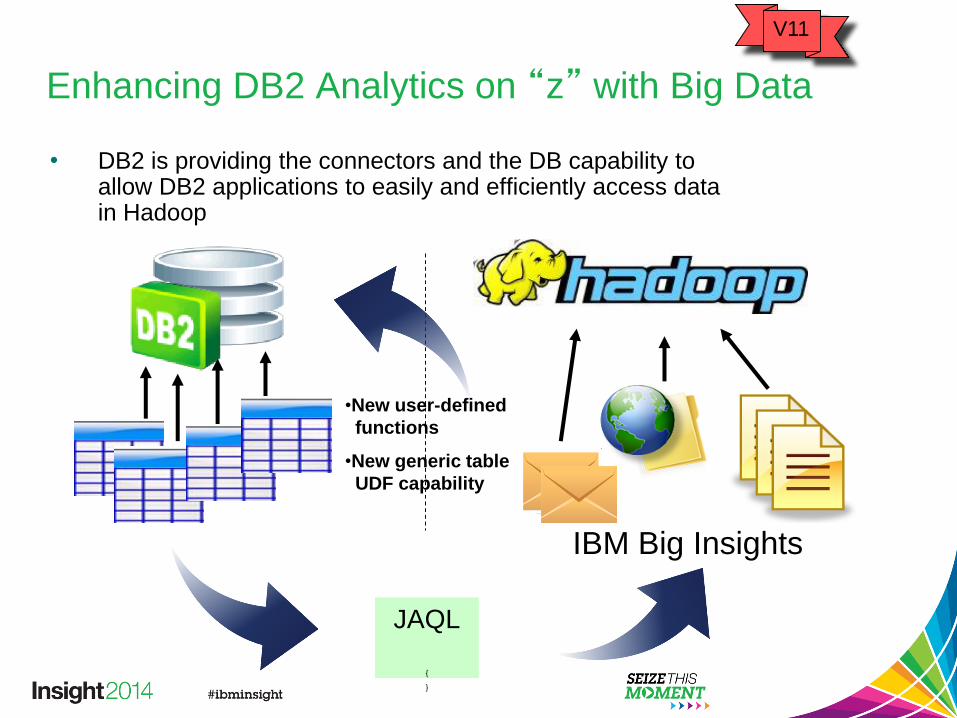
Enhancing DB2 Analytics on “z” with Big Data
• DB2 is providing the connectors and the DB capability to allow DB2 applications to easily and efficiently access data in Hadoop
•New user-defined
functions
•New generic table
UDF capability
V11
JAQL
{
}
IBM Big Insights

5
DB2 11 Support for BigData
1. Analytics jobs can be specified using JSON Query Language (Jaql)
1. Submitted to BigInsights
2. Results stored in Hadoop Distributed File System (HDFS).
2. A table UDF (HDFS_READ) reads the Bigdata analytic result from HDFS, for subsequent use in an SQL query.
HDFS_READ output table can have variable shapes
– DB2 11 supports generic table UDF, enabling this function
Goal: Integrate DB2 for z/OS with IBM's Hadoop based
BigInsights Bigdata platform. Enabling traditional
applications on DB2 for z/OS to access Big Data analytics.

BigInsights “Connector” for DB2 for z/OS
• Two DB2 “sample” functions:
JAQL_SUBMIT – Submit a JAQL script for execution on BigInsights from DB2
HDFS_READ – Read HDFS files into DB2 as a table for use in SQL
• Notes:
Functions are developed by DB2 for z/OS
• Shipped with DB2 11 in prefix.SDSNLOD2
• Functions are not installed by default
Functions and examples are documented by BigInsights
• http://www.ibm.com/support/docview.wss?uid=swg27040438

BigInsights Connector Usage
• Key Roles:
DB2 for z/OS DBA, Sysprog
• Issue CREATE FUNCTION DDL on DB2
– Refer to SDSNLOD2 dataset member
– Determine an appropriate WLM environment
BigInsights Analytics Team
• Develop Jaql (or other) analytics on BigInsights
DB2 for z/OS Application or Analytics Team
• Use BigInsights Connector functions in DB2 to execute BigInsights analytics and retrieve results

JAQL_SUBMIT
SET RESULTFILE =
JAQL_SUBMIT
('syslog = lines("hdfs:///idz1470/syslog3sec.txt");
[localRead(syslog)->filter(strPos($,"$HASP373")>=0)->count()]->
write(del(location="hdfs:///idz1470/iod00s/lab3e2.csv"));’,
'http://bootcamp55.democentral.ibm.com:14000/webhdfs/v1/idz1470/
iod00s/lab3e2.csv?op=OPEN',
'http://bootcamp55.democentral.ibm.com:8080',
''
);
JAQL script
containing the
analysis
Intended
HDFS file to
hold the
result
URL of the BigInsights clusteroptions
Submit a JAQL script for execution on BigInsights from DB2

JAQL – JSON Query Language
• Java MapReduce is the “assembly language” of Hadoop.
• JAQL is a high-level query language included in BigInsights with three objectives:
Semi-structured analytics: analyze and manipulate large-scale semi-structured data, like JSON data
Parallelism: uses the Hadoop MapReduce framework to process JSON data in parallel
Extensibility: JAQL UDFs, Java functions, JAQL modules
• JAQL provides a hook into any BigInsights analysis

HDFS_READ Example
SET RESULT_FILE = JAQL_SUBMIT(. . . . . );
SELECT BIRESULT.CNT FROM
TABLE(HDFS_READ(RESULT_FILE, '')
AS BIRESULT(CNT INTEGER);
HDFS_READ
Read a file from HDFS, present the file as a DB2 table for use in SQL
URL of the CSV file to be read
Definition of the “table”, how to
present the results to SQL
options

Example of HDFS_Read
The following is an example of a CSV file stored in HDFS
1997,Ford, E350,"ac, abs, moon",3000.00
1999,Chevy, "Venture ""Extended Edition""", ,4900.00
1996,Jeep,Grand Cherokee,"MUST SELL! AC, moon roof, loaded",4799.00
Example SQL statement:
SELECT * FROM TABLE (HDFS_Read('http://BI.foo.com/data/controller/dfs/file.csv',
‘'))
AS X (YEAR INTEGER, MAKE VARCHAR(10), MODEL VARCHAR(30),
DESCRIPTION VARCHAR(40), PRICE DECIMAL(8,2));
• ResultYEAR MAKE MODEL DESCRIPTION PRICE
-------- -------- --------------------- ------------------------------ -----------
1997 Ford E350 ac, abs, moon 3000.00
1999 Chevy Venture "Extended Edition" (null) 4900.00
1996 Jeep Grand Cherokee MUST SELL! AC, moon 4799.00
roof, loaded

Integrated Query Example
INSERT INTO BI_TABLE (CNT)
(SELECT CNT FROM TABLE
(HDFS_READ
(JAQL_SUBMIT
('syslog = lines("hdfs:///idz1470/syslog3sec.txt");
[localRead(syslog)->filter(strPos($,"$HASP373")>=0)->count()]->
write(del(location="hdfs:///idz1470/iod00s/lab3e2.csv"));' ,
'http://bootcamp55.democentral.ibm.com:14000/webhdfs/v1/idz1470/
iod00s/lab3e2.csv?op=OPEN',
'http://bootcamp55.democentral.ibm.com:8080',
''
),
''
)
)
AS BIGINSIGHTS(CNT INTEGER));
JAQL_SUBMIT can be
embedded in HDFS_READ for a
synchronous execute/read
workflow

DB2 – BigInsights Integration Use Case

14
DB2-BigInsights Integration Use Case 1
1. BigInsights ingests data that usually is not ingested by established structured data analysis systems like DB2
• e.g. email from all clients sent to an insurance company.
2. DB2 kicks off a Hadoop job on BigInsights that analyzes the emails and identifies customers who have expressed dissatisfaction with the service and the word ‘cancel’, ‘terminate’, ‘switch’ or synonyms thereof, or names of the competitors.
3. BigInsights job runs successfully, creates a file of results (names and email addresses of customers at risk) and terminates.
4. DB2 reads the BigInsights result file using user defined table function (HDFS_READ).
5. DB2 joins the result with the Agent table and alerts the agents of the at-risk customers. The agents act upon the at-risk customer and offer a promotion to stave off defection.

15
Use Case 2 – syslog analysis1. DB2 Syslog is sent to BigInsight for analysis
2. Issue SQL statements to
1. Count the number of lines in our syslog
2. Count the number of jobs started in our syslog
3. Show the lines containing $HASP373 messages
4. Show job names together with start time
5. Count the occurrences of each job
6. Show which jobs hand more than one occurrence
7. Produce a report of jobs with occurrence, departments, and owner names
DB2 11 for z/OS Infosphere BigInsights 2.1
internet

16
Syslog sample
17
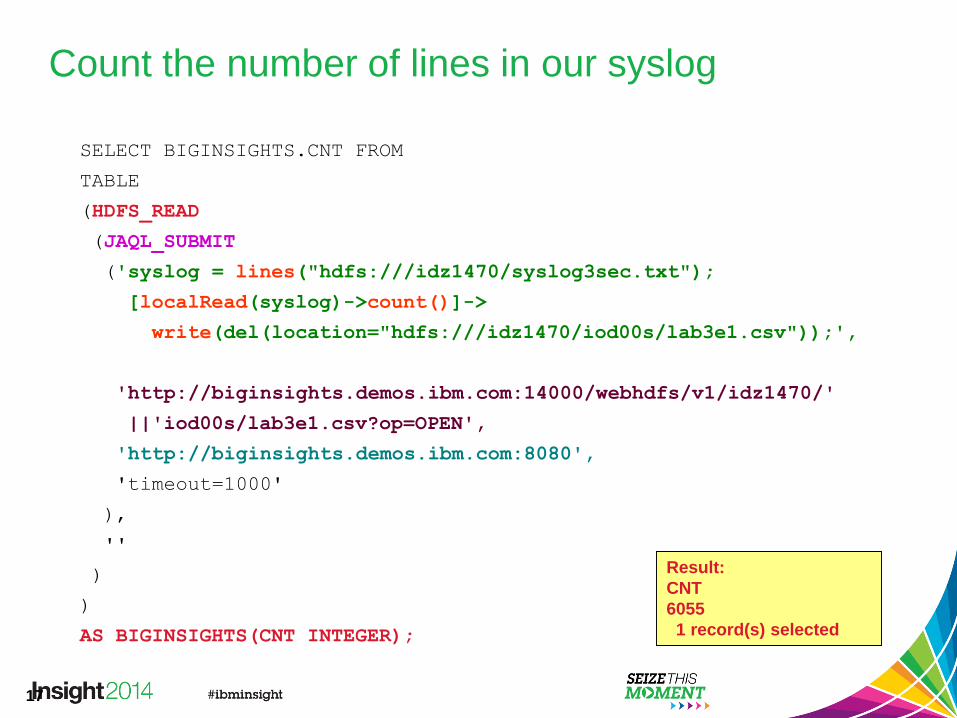
Count the number of lines in our syslog
SELECT BIGINSIGHTS.CNT FROM
TABLE
(HDFS_READ
(JAQL_SUBMIT
('syslog = lines("hdfs:///idz1470/syslog3sec.txt");
[localRead(syslog)->count()]->
write(del(location="hdfs:///idz1470/iod00s/lab3e1.csv"));',
'http://biginsights.demos.ibm.com:14000/webhdfs/v1/idz1470/'
||'iod00s/lab3e1.csv?op=OPEN',
'http://biginsights.demos.ibm.com:8080',
'timeout=1000'
),
''
)
)
AS BIGINSIGHTS(CNT INTEGER);
Result:
CNT
6055
1 record(s) selected

18
Show the lines containing $HASP373 messagesSELECT BIGINSIGHTS.LINE FROM
TABLE
(HDFS_READ
(JAQL_SUBMIT
('syslog = lines("hdfs:///idz1470/syslog3sec.txt");
localRead(syslog)->filter(strPos($,"$HASP373")>=0)->
write(del(location="hdfs:///idz1470/iod00s/lab3e3.csv"));',
'http://biginsights.demos.ibm.com:14000/webhdfs/v1/idz1470/'
||'iod00s/lab3e3.csv?op=OPEN',
'http://biginsights.demos.ibm.com:8080',
'timeout=1000'
),
''
)
)
AS BIGINSIGHTS(LINE VARCHAR(116));

19
Result:
LINE
N 4000000 STLAB28 13189 20:30:00.20 JOB07351 00000010 $HASP373 PJ907163 STARTED - INIT PJ - CLASS V - SYS 28
N 4000000 STLAB28 13189 20:30:00.20 JOB07348 00000010 $HASP373 C5LEG003 STARTED - INIT K1 - CLASS L - SYS 28
N 4000000 STLAB28 13189 20:30:00.21 JOB07288 00000010 $HASP373 T1XRP010 STARTED - INIT D6 - CLASS 8 - SYS 28
N 4000000 STLAB28 13189 20:30:00.21 JOB07290 00000010 $HASP373 T1XRP018 STARTED - INIT D9 - CLASS 8 - SYS 28
N 4000000 STLAB28 13189 20:30:00.21 JOB07287 00000010 $HASP373 T1XRP022 STARTED - INIT D7 - CLASS 8 - SYS 28
N 4000000 STLAB28 13189 20:30:00.21 JOB07289 00000010 $HASP373 T1XRP002 STARTED - INIT D5 - CLASS 8 - SYS 28
N 4000000 STLAB28 13189 20:30:00.26 JOB07413 00000010 $HASP373 PJ907165 STARTED - INIT PJ - CLASS V - SYS 28
N 4000000 STLAB28 13189 20:30:00.26 JOB07419 00000010 $HASP373 PJ907164 STARTED - INIT PJ - CLASS V - SYS 28
N 4000000 STLAB28 13189 20:30:08.71 JOB07349 00000010 $HASP373 T1XRP006 STARTED - INIT D0 - CLASS 8 - SYS 28
N 4000000 STLAB28 13189 20:30:08.71 JOB07350 00000010 $HASP373 T1XRP014 STARTED - INIT D8 - CLASS 8 - SYS 28
N 4000000 STLAB28 13189 20:30:17.25 JOB07490 00000010 $HASP373 T1XRP022 STARTED - INIT D7 - CLASS 8 - SYS 28
N 4000000 STLAB28 13189 20:30:17.25 JOB07492 00000010 $HASP373 T1XRP002 STARTED - INIT D5 - CLASS 8 - SYS 28
N 4000000 STLAB28 13189 20:30:17.28 JOB07494 00000010 $HASP373 PJ907289 STARTED - INIT PJ - CLASS V - SYS 28
N 4000000 STLAB28 13189 20:30:17.29 JOB07495 00000010 $HASP373 PJ907287 STARTED - INIT PJ - CLASS V - SYS 28
....
161 record(s) selected

20
Count the number of jobs started in our syslogSELECT BIGINSIGHTS.CNT FROM
TABLE
(HDFS_READ
(JAQL_SUBMIT
('syslog = lines("hdfs:///idz1470/syslog3sec.txt");
[localRead(syslog)->filter(strPos($,"$HASP373“)>=0)->count()]->
write(del(location="hdfs:///idz1470/iod00s/lab3e2.csv"));',
'http://biginsights.demos.ibm.com:14000/webhdfs/v1/idz1470/'
||'iod00s/lab3e2.csv?op=OPEN',
'http://biginsights.demos.ibm.com:8080',
'timeout=1000'
),
''
)
)
AS BIGINSIGHTS(CNT INTEGER);
Result:
CNT
161
1 record(s) selected

21
Integrating HDFS_READ with SQL
-- read file from exercise lab3e4, group to
occurrences in db2
SELECT JOBNAME, COUNT(*) AS OCCURS
FROM TABLE
(HDFS_READ
(
'http://biginsights.demos.ibm.com:14000/webhdfs/v1/'
||'idz1470/iod00s/lab3e4.csv?op=OPEN',
''
)
)
AS BIGINSIGHTS(JOBNAME CHAR(8), START TIME)
GROUP BY JOBNAME
HAVING COUNT(*) > 1;
Result:
JOBNAME OCCURS
C5LEG003 8
C5SQ2003 5
T1CMD28 2
T1LEG002 5
T1NES002 3
T1QDM28 3
T1XRP002 8
T1XRP006 7
T1XRP010 8
T1XRP014 7
T1XRP018 8
T1XRP022 8
12 record(s) selected

22
Report of Jobs with Job description and Occurrence
-- join to JOBCAT table
SELECT T1.JOBNAME, J.COMMENT, T1.OCCURS
FROM
TABLE
(HDFS_READ
('http://biginsights.demos.ibm.com:14000/webhdfs/v1/'
||'idz1470/iod00s/lab3e5.csv?op=OPEN',
'')
)
AS T1(JOBNAME CHAR(8), OCCURS SMALLINT),
IOD02S.JOBCAT J
WHERE J.JOBNAME = T1.JOBNAME;
IOD02S.JOBCAT table
OWNERDEPT JOBNAME COMMENT
21020 C5CPX002 RUN XMLTABLE JOB
21020 C5EAX003 RUN XMLQUERY JOB
21020 C5EAX007 RUN XMLTABLE JOB
21020 C5LEG003 RUN XML PERFORMANCE JOB
21020 C5NES001 RUN XML INDEX JOB
21020 C5NES002 RUN XMLQUERY JOB
21020 C5NES004 RUN XMLTABLE JOB
21020 C5SQ2003 RUN XMLEXISTS JOB
…….
Result
JOBNAME COMMENT OCCURS
C5CPX002 RUN XMLTABLE JOB 1
C5EAX003 RUN XMLQUERY JOB 1
C5EAX007 RUN XMLTABLE JOB 1
C5LEG003 RUN XML PERFORMANCE JOB 8
C5NES001 RUN XML INDEX JOB 1
C5NES002 RUN XMLQUERY JOB 1
C5NES004 RUN XMLTABLE JOB 1
C5SQ2003 RUN XMLEXISTS JOB 5
PJ906521 TEST UDFS JOB 100 1
……
23
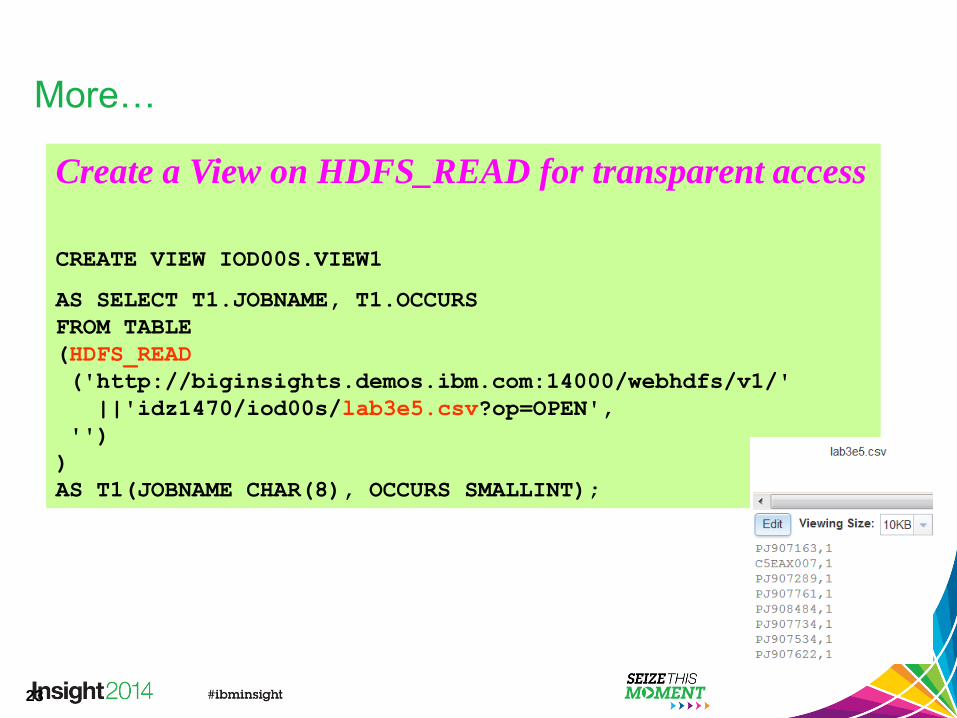
More…
Create a View on HDFS_READ for transparent access
CREATE VIEW IOD00S.VIEW1
AS SELECT T1.JOBNAME, T1.OCCURS
FROM TABLE
(HDFS_READ
('http://biginsights.demos.ibm.com:14000/webhdfs/v1/'
||'idz1470/iod00s/lab3e5.csv?op=OPEN',
'')
)
AS T1(JOBNAME CHAR(8), OCCURS SMALLINT);

24
More…
Write HDFS_READ result to another table
-- CREATE table to hold job names & start times
CREATE TABLE IOD00S.JOB_STATS
(JOBNAME CHAR(8),
STARTTIME TIME);
-- INSERT into the newly created table
INSERT INTO IOD00S.JOB_STATS
SELECT JOBNAME, START TIME
FROM
TABLE
(HDFS_READ
(‘http://biginsights.demos.ibm.com:14000/webhdfs/v1/'
||'idz1470/iod00s/lab3e4.csv?op=OPEN',
''
)
)
AS T1(JOBNAME CHAR(8), START TIME);
SELECT * FROM
iod02s.JOB_STATS
ORDER BY
STARTTIME DESC
JOBNAME
STARTTIME
PJ930233 20:32:59
PJ908567 20:32:59
PJ908611 20:32:59
PJ908568 20:32:59
C5LEG003 20:32:58
T1QDM28 20:32:58
T1NES002 20:32:58
…

25
More…
Using with Common Table Expressions
WITH JOBS(JOBNAME, START) AS
(SELECT JOBNAME, START TIME
FROM TABLE
(HDFS_READ
(
'http://biginsights.demos.ibm.com:14000/webhdfs/v1/idz1470/'
||'iod02s/lab3e4.csv?op=OPEN',
'') )
AS T1(JOBNAME CHAR(8), START TIME)
)
SELECT J1.JOBNAME, J1.START
FROM JOBS J1
WHERE J1.START >= (SELECT J2.START FROM JOBS J2
WHERE J2.JOBNAME='SMFDMP28')
Result:
JOBNAME START
C5LEG003 20:32:33
T1XRP002 20:32:33
T1XRP022 20:32:33
T1XRP018 20:32:33
PJ908331 20:32:33
PJ908332 20:32:33
SMFDMP28 20:32:33
PJ908330 20:32:33
PJ908390 20:32:33
T1XRP006 20:32:41
T1XRP014 20:32:41
……

Other
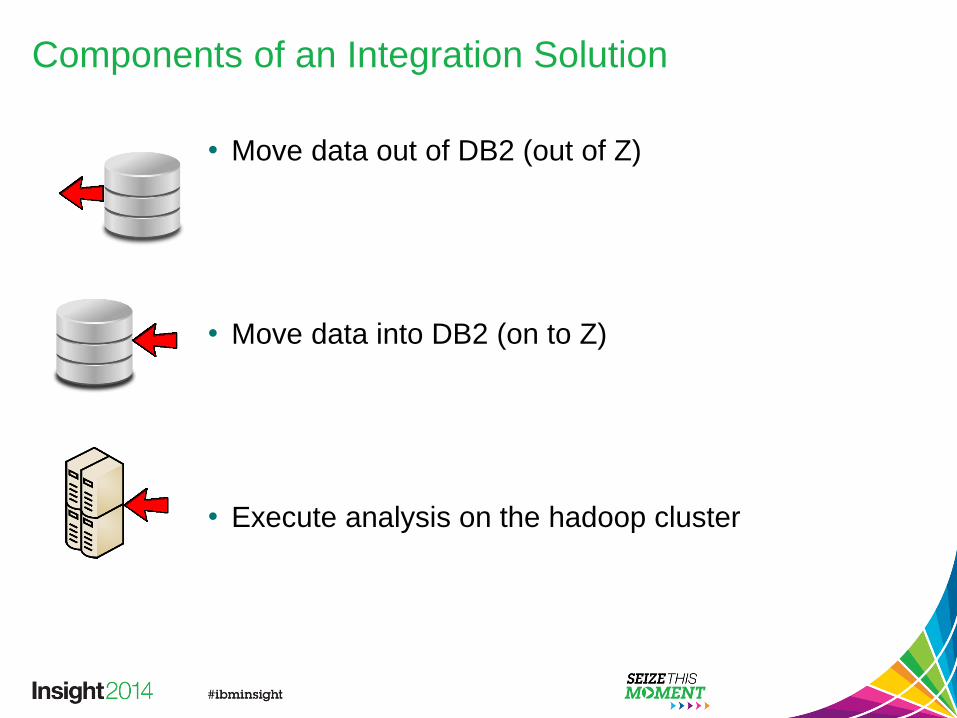
Components of an Integration Solution
• Move data out of DB2 (out of Z)
• Move data into DB2 (on to Z)
• Execute analysis on the hadoop cluster

Loading BigSQL from JDBC data source
• A JDBC URL may be used to load directly from external data source
• It supports many options to partition the extraction of data
Providing a table and partitioning column
Providing a query and a WHERE clause to use for partitioning
• Example usage:
LOAD USING JDBC
CONNECTION URL 'jdbc:db2://myhost:50000/SAMPLE'
WITH PARAMETERS (
user = 'myuser',
password='mypassword'
)
FROM TABLE STAFF WHERE "dept=66 and job='Sales'"
INTO TABLE staff_sales
PARTITION ( dept=66 , job='Sales')
APPEND WITH LOAD PROPERTIES (bigsql.load.num.map.tasks = 1)
;

Co:Z Launcher Example
//COZJOB JOB ...,
//*=====================================
//*
//* run analysisScript on linux
//*
//*=====================================
//STEP1 EXEC PROC=COZPROC,
// ARGS=‘[email protected]'
//STDIN DD *
# This is input to the remote shell
/home/jason/bin/analysisScript.sh | \
/home/hadoop/hadoop-2.3.0/bin/hdfs dfs -put -
/hadoop/db2table.toz
OpenSSH user credentials
Shell script to be run on target
system

Co:Z Dataset Pipes Streaming Example//COZJOB JOB ...,
//*
//STEP1 EXEC DSNUPROC,UID='USSPIPE. LOAD',
// UTPROC='', SYSTEM=‘DB2A'
//UTPRINT DD SYSOUT=*
//SYSUT1 ...
//SORTOUT ...
//SYSIN DD *
TEMPLATE DATAFIL PATH='/u/admf001/test1'
RECFM(VB) LRECL(33)
FILEDATA(TEXT)
LOAD DATA FORMAT DELIMITED
COLDEL X'6B' CHARDEL X'7F' DECPT X'4B'
INTO TABLE JASON.TABLE2
(C1 POSITION(*) INTEGER,
C2 POSITION(*) VARCHAR)
INDDN DATAFIL
Use a TEMPLATE to point to a
USS pipe
LOAD using the TEMPLATE,
listens to the pipe
//COZJOB2 JOB ...
//STEP1 EXEC PROC=COZPROC,
// ARGS='[email protected]‘
//STDIN DD *
/home/hadoop/hadoop-2.3.0/bin/hdfs dfs -cat /hadoop/db2table.toz | \
tofile '/u/admf001/test1'
A separate job to write to the
pipe from the remote system

Apache Sqoop
• Open Source top-level Apache product
http://sqoop.apache.org/
Transfers data between HDFS and RDBMS (like DB2!)
Uses DB2 SQL INSERT and SELECT statements to support export and import
No custom DB2 for z/OS connectormeans default performance options
sqoop export
--driver com.ibm.db2.jcc.DB2Driver
–-connect jdbc:db2://9.30.137.207:59000/SYSTMF1
--username JASON --password xxxxxxxx
--table SYSADM.NYSETB02
--export-dir "/user/jason/myFile.txt"
-m 9
DB2’s JDBC driver
My server,
credentials, and
table
Specify parallelism on
the remote cluster

Veristorm Enterprise
• http://www.veristorm.com/
(Not an IBM product)
zDoop : Veristorm hadoop distribution on z/Linux
User-friendly GUI allows point and click data movement
Copies z/OS VSAM, DB2, IMS, datasets and log files into zDoop

IBM InfoSphere System z Connector for Hadoop
System z Mainframe
CP(s)
z/OS
IFL…
z/VM
S
M
F
Linux for System z
InfoSphere BigInsights
HDFS
MapReduce, Hbase, Hive
IFL IFL
Hadoop on your platform of choice
IBM System z for security
Power Systems
Intel Servers
Point and click or batch self-
service data access
Lower cost processing & storage
DB2
VSAM
IMS
Logs
System z
Connector
For Hadoop
System z
Connector
For Hadoop

Summary
JAQL_SUBMIT – Submit a JAQL script for execution on BigInsights from DB2. Results are stored in Hadoop Distributed File System (HDFS).
HDFS_READ – A table UDF read HDFS files (containing BigIsights analytic result) into DB2 as a table for use in SQL.
DB2 11 for z/OS. enables traditional applications on
DB2 for z/OS to access IBM's Hadoop based
BigInsights Bigdata platform for Big Data analytics.

Resources
• BigInsights (including JAQL documentation)
http://www-01.ibm.com/software/data/infosphere/biginsights/
• JAQL_SUBMIT and HDFS_READ
http://www.ibm.com/support/docview.wss?uid=swg27040438
• Integrate DB2 for z/OS with InfoSphere BigInsights, Part 1: Set up the InfoSphere BigInsights connector for DB2 for z/OS
http://www.ibm.com/developerworks/library/ba-integrate-db2-biginsights/index.html
• Integrate DB2 for z/OS with InfoSphere BigInsights, Part 2: Use the InfoSphere BigInsights connector to perform analysis using Jaql and SQL
http://www.ibm.com/developerworks/library/ba-integrate-db2-biginsights2/index.html

36
InfoSphere BigInsights Quick Start is the newest member of the BigInsights family
What is BigInsights Quick Start? •No charge, downloadable edition that allows you to
experiment with enterprise-grade Hadoop features
•Simplifies the complexity of Hadoop with easy-to-follow
tutorials and videos
•No time or data limitations to allow you to experiment
for a wide range of use cases
ibm.co\QuickStartDownload
Now!
Watch the
videos!ibmurl.hursley.ibm.com/3
PLJ

IBM Silicon Valley Laboratory - 2014 WW Tech Sales Boot Camp

Acknowledgements and Disclaimers Availability. References in this presentation to IBM products, programs, or services do not imply that they will be available in all countries in which IBM operates.
The workshops, sessions and materials have been prepared by IBM or the session speakers and reflect their own views. They are provided for informational purposes only, and are neither intended to, nor shall have the effect of being, legal or other guidance or advice to any participant. While efforts were made to verify the completeness and accuracy of the information contained in this presentation, it is provided AS-IS without warranty of any kind, express or implied. IBM shall not be responsible for any damages arising out of the use of, or otherwise related to, this presentation or any other materials. Nothing contained in this presentation is intended to, nor shall have the effect of, creating any warranties or representations from IBM or its suppliers or licensors, or altering the terms and conditions of the applicable license agreement governing the use of IBM software.
All customer examples described are presented as illustrations of how those customers have used IBM products and the results they may have achieved. Actual environmental costs and performance characteristics may vary by customer. Nothing contained in these materials is intended to, nor shall have the effect of, stating or implying that any activities undertaken by you will result in any specific sales, revenue growth or other results.
© Copyright IBM Corporation 2014. All rights reserved.
— U.S. Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp.
IBM, the IBM logo, ibm.com, BigInsights, and DB2 are trademarks or registered trademarks of International Business Machines Corporation in the United States, other countries, or both. If these and other IBM trademarked terms are marked on their first occurrence in this information with a trademark symbol (® or TM), these symbols indicate U.S. registered or common law trademarks owned by IBM at the time this information was published. Such trademarks may also be registered or common law trademarks in other countries. A current list of IBM trademarks is available on the Web at
•“Copyright and trademark information” atwww.ibm.com/legal/copytrade.shtml
•Other company, product, or service names may be trademarks or service marks of others. DoveTail Co:Z, Apache Sqoop, Veristorm Enterprise
38

DB2 for z/OS info & New DB2 11 Book
• worldofdb2.com
• IBMDB2 twitter
• What's On DB2 for z/OS
• IDUG International DB2 User Group
• Facebook - DB2 for z/OS
• You Tube
39
Get your Copy of the 2015 DB2 11 book

Thank You

















