26
SEMESTER PROJECT – WINTER SEMESTER 2004-2005 MARK KORNFILT BUILDING A DISTRIBUTED DATABASE USING A PEER-TO-PEER PLATFORM Advisor: Roman Schmidt Professor: Karl Aberer Date: February 2005

SEMESTER PROJECT – WINTER SEMESTER 2004-2005 MARK KORNFILT
BUILDING A DISTRIBUTED DATABASE USING A
PEER-TO-PEER PLATFORM
Advisor: Roman Schmidt
Professor: Karl Aberer
Date: February 2005

EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
Contents 1 PROJECT OVERVIEW AND GOALS ............................................................................... 3
1.1 Persistent data in Gridella ..............................................................................3 1.2 Performance issues.........................................................................................4
2 DATABASE CHOICE ..................................................................................................... 5
2.1 hsqldb particularities......................................................................................5 2.1.1 Data storage in hsqldb............................................................................6 2.1.2 Identity columns.....................................................................................6 2.1.3 Starting and stopping the database server ..............................................6
3 DATABASE SCHEMA .................................................................................................... 6
3.1 The XML heritage..........................................................................................7 3.2 Original XML schemas..................................................................................7 3.3 The database schema......................................................................................9 3.4 Relation between the XML schema and the database schema ......................9 3.5 Querying the database..................................................................................10
4 IMPLEMENTATION .................................................................................................... 11
4.1 Implementation modularity..........................................................................11 4.2 Class hierarchy in Gridella...........................................................................12 4.3 The DBManager class..................................................................................12
4.3.1 DBManager UML diagram..................................................................12 4.4 The DBDataTable class ...............................................................................13
4.4.1 Use of PreparedStatements ..................................................................14 4.4.2 Inserting file descriptions with database escape characters .................14 4.4.3 DBDataTable UML diagram ...............................................................15
4.5 The Exchanger Class....................................................................................15 4.5.1 A first inefficient approach ..................................................................16 4.5.2 The DBView approach ........................................................................16
4.6 The DBView class .......................................................................................17 4.6.1 DBView UML diagram .......................................................................18
4.7 The LocalRoutingTable class ......................................................................18 4.7.1 LocalRoutingTable UML diagram ......................................................19
5 TESTS AND EVALUATION .......................................................................................... 19
5.1 Testing environment ....................................................................................20 5.2 Exchanger evaluation...................................................................................21 5.3 Search evaluation .........................................................................................22 5.4 Database engine evaluation..........................................................................22
6 CONCLUSIONS AND POSSIBLE IMPROVEMENTS ....................................................... 23 7 APPENDIX A: AN EXAMPLE « .SCRIPT » FILE .......................................................... 25 8 APPENDIX B: INSTALLATION ................................................................................... 25 9 REFERENCES............................................................................................................. 26
2

EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
1 PROJECT OVERVIEW AND GOALS Gridella is a Java implementation of the distributed information management system P-Grid. The information stored in Gridella is currently represented by Java classes and XML documents at each peer. The goal of this project was to improve the performance of the overall system by integrating a database as a local storage for peers. This would allow us to speed-up several parts of the software, by using the already well-optimized database technologies. The steps taken in order to achieve this goal were:
- choose a database that would fit the requirements of the project - study the Gridella implementation - design a database schema - integrate the database into Gridella - test the performances - optimize the schema and queries - final performance tests and comparisons with the XML integration - code documentation
The database is distributed in the sense that P-Grid is used to partition the database into small fractions among the peers. The union of individual databases from each peer would form the distributed database. To better understand the project and its objectives, a short introduction to P-Grid and Gridella will first be made, followed by a discussion on the main improvements that had to be done to make the software more efficient. The choice of the database engine used for this project will then be clarified and the design will be explained. Next, specific implementation detail will be discussed, followed by tests and performance evaluations. Finally, possible improvements to the new implementation will be presented.
1.1 Persistent data in Gridella There are two types of information that Gridella keeps track of1: the data items and the hosts, which are related to two different concepts. The first type represents the data shared by the peers and is linked to the host that owns it. A data item could be associated to a file, to information concerning other peers or to anything else. A data item always has a unique key that identifies it. The second type represents information about these peers, i.e. a unique identifier (GUID) for the host, the internet address and port of the host, the path of the host in the P-Grid network etc. Persistence is achieved by storing the data into two XML files: the data items and their hosts are stored in a data table, which has a signature generated by using the keys of the data items it contains (i.e., two data tables will have the same key if and only if they contain exactly the same data items) and the information about how to route to other regions of the P-Grid tree is stored in a routing table.
1 The persistent data relative to program settings and the like is of course not covered here.
3

EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
Gridella loads these two files at startup and then handles the data directly in large collections in main memory.
Peer2
Peer1
PeerX
DataItems .XML RoutingTable
.XML
XML
XML
XML
DataItems .XML RoutingTable
.XML
DataItems .XML RoutingTable
.XML
Figure 1: Information in Gridella is exchanged using an XML protocol and data is stored at each
peer using two XML files. Figure 1 shows how Gridella uses XML to execute exchanges and to store data on the hard disk.
1.2 Performance issues To be able to efficiently integrate the database into Gridella, we first need to understand the main use of the data table and of the routing table. These two concepts will be shortly introduced here. When two peers meet, they decide, among other things, what part of their respective data tables they are going to exchange. This decision is defined by the P-Grid algorithm and based on various factors such as the peer’s path, the number of items shared and so on (see Figure 2)2. After this exchange, the data table that remains is a subset of the two original tables, and this subset can be a complex combination of set-operations. This exchange process therefore makes an extensive use of the data structures in memory. Another important use of the data items in Gridella is to process a search. A search may be either started locally by a user of Gridella or comes as a request from another peer. As we can see in Figure 2, each peer is only responsible for a limited set of data items, and a search in the P-Grid network will therefore always be forwarded, thanks to the routing table, to the peer responsible for the query. The data table in memory is then searched to find the data items corresponding to this query. In consequence, the main improvement to be done was to change the software to use the database rather than main memory to handle the data specified above. 2 For a more detailed description of the P-Grid algorithm, see Improving Data Access in P2P Systems, Karl Aberer, Manfred Hauswirth, Magdalena Punceva, Roman Schmidt, IEEE Internet Computing, 6(1), January/February 200.
4

EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
Figure 2: A P-Grid search tree example2
Figure 2 is an example search tree constructed by Gridella peers thanks to the P-Grid algorithm. The highlighted parts are where the performances had to be improved.
2 DATABASE CHOICE The choice for the database to be used in Gridella had to meet the following requirements:
• Support JDBC connections to be directly usable with Java. • Be open-source or free. • Be lightweight to be easily added to the Gridella package. • Consume low resources.
In addition to meeting all of the previous requirements, the Hypersonic SQL Database (hsqldb) engine offers an in-process standalone mode (see Section 2.1). This mode runs the database engine in the same Java Virtual Machine (JVM) as the application, which allows us to embed it directly in Gridella. This is very convenient in our case, as the database is only accessed by the application. Moreover, hsqldb is completely written in Java, supports referential integrity and its size is only about 100k. For these reasons a great number of open-source projects use hsqldb as a persistence engine. The reason why other, more popular relational database management systems (RDBMS) like MySQL or PostGreSQL where not chosen is that most of the advanced features offered by these, such as web servers, advanced security, or replication tools, are not necessary to us.
2.1 hsqldb particularities The hsqldb can run in several different modes. They are generally divided in two categories3: server mode and standalone mode (also called in-process mode). The first one runs the RDBMS independently in its own JVM and therefore allows it to listen
3 For more details, visit hsqldb - http://hsqldb.sourceforge.net/
5

EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
for incoming connections. The second mode runs the database engine in the same JVM as the program which instantiates the JDBC driver. This allows us to “attach” the database to our software. The general procedure to build a database application with hsqldb is to first develop it using the server mode to connect to the database from another application (such as a database manager) and to see its content. The standalone mode is then used to deploy the application.
2.1.1 Data storage in hsqldb The storage of the database in hsqldb is also quite different from other RDMS. In fact, the engine stores the data with SQL statements in a file with a .script extension. For example, if a database called “PGrid” is created, a “pgrid.script” file will be created (see Appendix A for a typical .script file). This can be a problem as the .script file is loaded at each startup and this process can take a significant amount of time if the quantity of data stored in the database is large. This matter will be handled in Section 5.4. A .log file is also created to log all the transactions done on the database. This file is deleted if the database is shut down properly, or used to restore the database if it is restarted after an improper shut down.
2.1.2 Identity columns As we will see in Section 3, some identity columns had to be added to our database design. These columns contain an auto-incrementing integer number generated by a sequence generator. They are also the primary key of our tables. The type could be easily changed to big integer if a large amount of data has to be inserted in the database.
2.1.3 Starting and stopping the database server In standalone mode, the database engine is started by instantiating the JDBC driver using a valid URL. The general standalone mode URL is: "jdbc:hsqldb:file:database_name”. To connect to the database in server mode, the URL would be: "jdbc:hsqldb:hsql://host_name/database_name". To shut down the engine properly, the SQL query “SHUTDOWN” has to be executed.
3 DATABASE SCHEMA There were several options to design the schema for the database. It naturally had to contain all the information stored in the xml files, respect the xml schema definition (see Figure 3 and Figure 4), but also several other requirements such as an optional relation between files and data items that we will consider later. The main difficulty in finding the right design for the database was to change from the hierarchical model of XML to the relational model of databases.
6

EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
3.1 The XML heritage Gridella uses an XML-protocol, defined in [PROTOCOL], to serialize data when exchanging information with other peers and to store data on the hard disk. When designing the database, it was to be kept in mind that Gridella still had to use an XML representation of data items. Even though the data isn’t queried directly in XML (using XPATH for example), it still had to be possible to efficiently convert the information queried from the database to an XML representation and vice-versa.
3.2 Original XML schemas The original specification of the data table, data items, the routing table and hosts are as follows:
Figure 3: XML schema for the DataTable
7

EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
Figure 4: XML schemas for the Routing Table and Host
Figure 3 and Figure 4 show that the two structures have overlapping information. The attributes in a data item of the host that owns it, i.e. the GUID, Address and Port, are a reference to a host contained in the Routing Table. As we will see in the schema, the design has enabled us to avoid duplicating this information.
8

EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
3.3 The database schema The schema for the database that has been designed is the following:
Figure 5: Gridella database schema
The data is represented by five tables and an additional table has been added to store various properties which have to be saved when Gridella shuts down and loaded at each startup, i.e. the GUID of the local host, the path of the local host and the signature of the data table.
3.4 Relation between the XML schema and the database schema As we can see in Figure 3, an XML data table has a signature attribute and is composed of 0..n data items, which each have the following attributes:
- The type of the item, e.g. “text/file”. - Information about the host this item belongs to, e.g. GUID, Address, etc. - Information concerning the represented file (if it is of type “text/file”), e.g. file
name, file path, etc.
The decision made to change this hierarchical representation into a relational representation was to divide the information contained in one data item into four
9

EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
entities in the database. Consequently, the data table is represented by these entities and their relations. The change had to respect the following requirements:
• Have an optional relation (M – N) between files and data items, because a data item does not necessarily represent a file and a file can be represented by various data items (there is in fact one data item for each substring of the file name).
• Have a necessary relation between hosts and data items and between types and data items (1-N): A data item can only be of one particular type and belong to one host.
The constraints and types of each attribute were straightforward to add and taken from the specifications in XML schema.
3.5 Querying the database To select the list of data items in the data table, the following query has to be executed:
Figure 6: Querying the database. This would correspond to the XPATH query
/datatable/dataitem Because the dataitems - files relation is an N-M relation, it is important to outer-join the files table so that dataitems not related with files can be returned by this query. As we explained in Section 3.1, the design had to provide an efficient way to build the XML data items out of the data stored in the tables. As we can see in Figure 6, this means joining four tables to provide the necessary information, i.e. the dataitems, files, hosts and types tables. Because joins are the most costly operations in a database, auto-incrementing unique identity columns have been added to each table to perform them more efficiently (see Section 2.1.2). These columns are automatically indexed by the database engine. Moreover, UNIQUE constraints have been added to ensure the uniqueness of data items, and these also build indexes on the columns. The routing table, defined in Figure 4, contains information about the peers in the P-Grid network. Part of this information is stored in the hosts table and the fidgetlist table. The reason the References and Replicas defined in the original schema are not stored as relations or entities in the database is that those lists are only subsets of the hosts table that we can query using special conditions on the paths. These conditions are:
- The Replicas are all the hosts contained in the hosts table that have a path equal to the local host.
- The hosts that do not have the same path as the local host are called References and they are grouped by level. These levels can be computed using their path.
10

EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
4 IMPLEMENTATION An important part of this project consisted in understanding the existing Gridella code to be able to efficiently extend it to use the database. Although this has taken some significant time, it has allowed me to better understand the use of the data. Four classes were created to integrate the database in Gridella: two classes that were to replace existing implementations and two utilities classes.
Figure 7: Integration of the database into Gridella. The highlighted parts are the ones that have
been deleted/replaced Figure 7 shows the integration of the database into Gridella. The two XML files have been deleted and the data is not stored anymore in memory but in the database. As we also see in this figure, the database is always accessed through the DBManager class.
4.1 Implementation modularity The existing class hierarchy enabled us to make the implementation very modular, in the way that one can switch from the XML data table to the database data table with little effort. This also has drawbacks such as the usual trade off between efficiency and modularity. The problem was to decide whether or not it would be allowed to query the database directly from every class that has to access the data. I decided not
11

EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
to do that as it would have compromised the adaptability of the software and increased the dependency on specific database issues, although I am conscious that some efficiency is probably lost. SQL statements can therefore only be found in the DBDataTable and LocalRoutingTable classes. For an example of possible efficiency loss see Section 4.4.1.
4.2 Class hierarchy in Gridella So far, data persistence was used only to load data in memory at startup by the DataTable class. This class is the super class of the XMLDataTable class which is used to parse and build XML objects, and the XMLDataTable itself was extended by LocalDataTable which was only used to load and save data on the hard disk. The hierarchy is the same for the RoutingTable (see Figure 7). Because we didn’t want to handle the items in-memory anymore, but in the database, the main work was to replace the LocalDataTable with the DBDataTable and to overload most of the methods in DataTable. The DBDataTable had to be kept at the bottom of the class hierarchy, so that it still inherited the methods of XMLDataTable used to parse and build XML data.
4.3 The DBManager class The DBManager class is the persistence layer of our implementation. It provides all the utilities to handle the database, i.e. create a JDBC connection, shut down the database, execute SQL queries, etc. Several methods have also been added to ensure the consistency of data. The shutdown() method, for example, first checks that both the DBDataTable and the RoutingTable have finished using the database before shutting it down, so that no information is lost. Although the implementation always uses auto-commit, various commit() methods are provided for future use in case they would be needed in further developments. Finally, a createTables() method allows us to load a Data Definition Language (DDL) file to create the database. The DDL file has to be a file containing valid SQL statements. The DBmanager implements the singleton pattern and can thus only have one instance. This was implemented using the same method as in Gridella, i.e. lazy instantiation4. Other classes can access this shared instance by using the sharedInstance() method. The unique instance of the class is created using the following statement: private static final DBManager SHARED_INSTANCE = new DBManager(JDBC_driver,JDBC_URL,user_name,password); To switch from the standalone mode of hsqldb to the server mode and vice-versa, only the JDBC_URL has to be changed (see Section 2.1.3).
4.3.1 DBManager UML diagram
4 See http://www.javaworld.com/javaworld/javatips/jw-javatip67.html for more details.
12

EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
Figure 8: DBManager UML Diagram
Figure 8 shows the UML diagram of the DBManager class. We can see that all the attributes of this class are private (symbolized in the figure by a lock next to the attribute name). This ensures, among other things, that no other class has access to the database connection.
4.4 The DBDataTable class The DBDataTable is the main class I worked on in this project, as it is the one providing access to the data. This class implements all the methods of the original LocalDataTable and overrides most of the methods found in the parent class DataTable, because data items are not handled in-memory anymore but in the database. In addition to these, it has methods to rebuild DataItem objects out of the tables in the database. When the DBDataTable is first instantiated, it ensure that all tables already exist in the database by calling the tableExists() method in the DBManager class and creates them otherwise. A shutdown flag is also present in the implementation, so that once the shutdown() method is called, no other operations are allowed on the database.
13

EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
4.4.1 Use of PreparedStatements The JDBC API provides different ways to improve the performance when executing SQL statements. One of them is PreparedStatements. When a basic SQL Statement object is executed, it is passed to the RDBMS, where it has to be parsed and compiled before it can be executed. When this statement has to be executed frequently, there is a way to significantly improve the efficiency of the application. This is done by using precompiled statements which are called PreparedStatements. PreparedStatements are used throughout the implementation as often as possible, although not in the most efficient manner. The reason is that I wanted to keep modularity and therefore it was not possible to modify the methods signature. As an example, let us consider the process of adding shared files in the data table. The FileManager manages the files of the shared folders of a peer and adds data items corresponding to each substring of the file, e.g. a file name “logtable.txt” will have a data item with the description “logtable.txt”, another one with “ogtable.txt”, another one with “gtable.txt”, etc. For each of these data items it calls the method addDataItem(), which only adds one item in the database. A better way to do that would be to create the PreparedStatement first and then add each item by using this preparedStatement. However, this would have compromised modularity and I decided to let this issue as a possible future improvement (see Section 6). To prepare this possible extension, the DBManager class provides the methods to create and use PreparedStatements.
4.4.2 Inserting file descriptions with database escape characters One problem encountered while designing the DBDataTable class was during the insertion of files in the database. Some files have special database escape characters in their filenames. To resolve this issue, JDBC PreparedStatement methods where used. These handle the conversion of these “prohibited” strings automatically.
14

EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
4.4.3 DBDataTable UML diagram
Figure 9: DBDataTable UML Diagram
Figure 9 shows the UML diagram of the DBDataTable class. Although this class does not directly access the database, it handles result sets and creates SQL statements. That is why the java.sql package is used here.
4.5 The Exchanger Class The exchanger class had to be modified to improve its performances. It uses the data tables most heavily and maintaining the data items in memory was quite ineffective when processing the exchanges.
15

EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
4.5.1 A first inefficient approach My first approach was to create a data table in the database that would store the items belonging to the remote host of an exchange. This was done by duplicating the four tables: dataitems, files, hosts and types and filling them every time an exchange would start with the data coming from the other host. These tables were then emptied at the end of the exchange.
Figure 10: The duplicated tables used by our first approach to perform the exchange process.
During the exchange process, database VIEWs were used to represent subsets of both databases and perform set-operations. When the exchange was finished, we had to replace the data in the four original tables with the data that was present in the final result VIEW and delete all the intermediate VIEWs that were created. For readers familiar with databases and their performance, it is clear that this choice was very ineffective. It forced performing intermediary joins that were compromising the overall efficiency and the final replacement of the original data table was very poor in terms of performance. However, even with this method, the results obtained were already better than the operations done in memory by the original implementation of Gridella.
4.5.2 The DBView approach It was finally decided to completely change the design of this process. My approach has been to add a column in the original dataitems table that would be a foreign key to the host table and would indicate the host that manages the data item. This enabled adding the data coming from the other host in the same table as the local data items and specifying that they do not belong to the local host. It was then possible to represent subsets of the data table also by specifying the conditions on this new column. For example, selecting the data items that have a key starting with “01” and belonging to the remote host of the exchange is easily done by creating a DBView object and giving the following parameters to the constructor: new DBView(“01”,remoteGUID)
where the remoteGUID is an exchange parameter and represents the unique identifier of the remote host. The DBView object translates this automatically to the following query:
16

EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
Figure 11 SQL Query returning the data items that have a key starting with "01" and that
belong to a remote Host All the operations relative to the exchange process can therefore easily be done thanks to the DBView. This approach has saved a very significant amount of time by removing the overhead of creating and deleting VIEWs in the database and performing unnecessary joins. We will now see how the DBView class is implemented.
4.6 The DBView class As explained in the last section, this class was created after having experienced some major performance problems with the database VIEWs. It was designed principally to cope with the requirements of the exchange process and is therefore used mainly during the processing of an exchange by the pgrid.core.exchanger class. A utility class that would allow to represent subsets of the data table depending on some parameters was needed. This class had to enable us to count the number of items in this subset, perform set-operations on it (unions and set-differences) and select data items based on a condition on the key. To show the use of this class, let us take a concrete case of an exchange between to peers that have the same path. In this case, as explained before, the two peers are replicas and have to store the same data. We therefore want to be able to perform the union set-operation on the two tables. The following code would have to be used:
Figure 12: Example use of the DBView class to perform the union of two data tables
As we see it in Figure 12, the DBView class allows us to first store the query to select all the local data items, then the query to select the data items belonging to the remote peer and finally create a new query that selects the union of both tables. The empty string parameter in the DBView constructor is used to specify that no condition is made on the key prefix, i.e. we select all the items for each peer. As we will see further on, this class made it possible to improve the processing time of the exchange considerably.
17
EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
4.6.1 DBView UML diagram
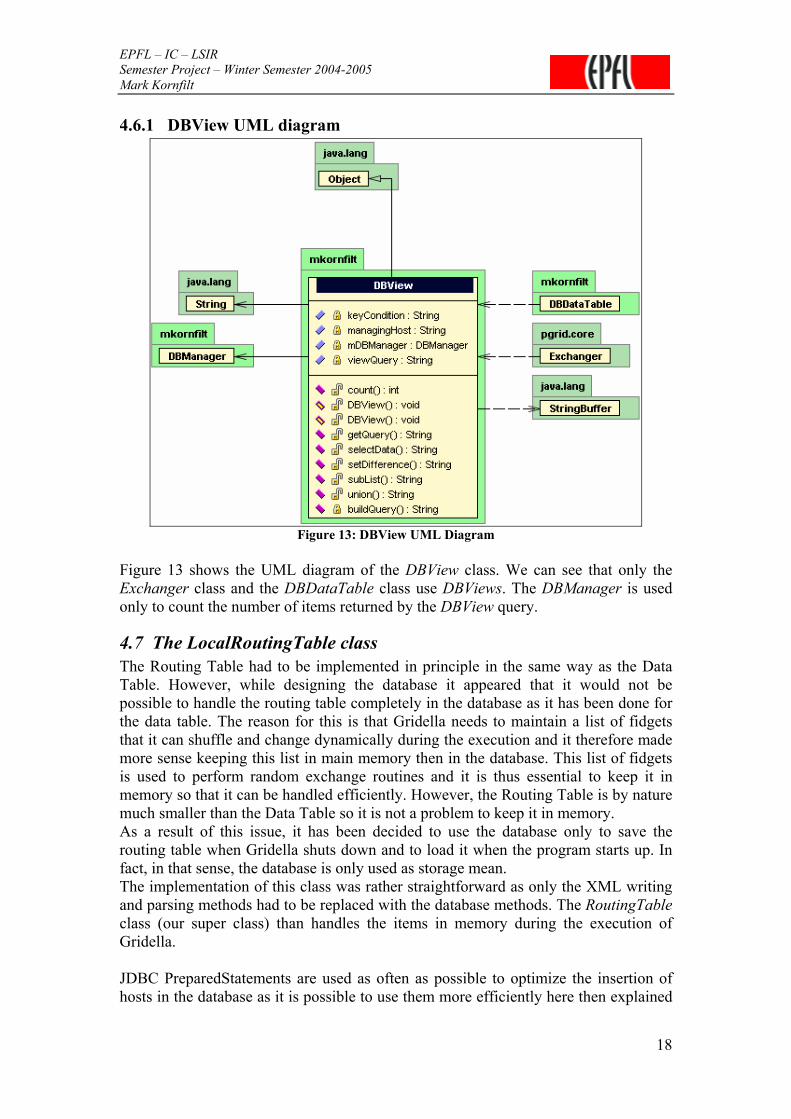
Figure 13: DBView UML Diagram
Figure 13 shows the UML diagram of the DBView class. We can see that only the Exchanger class and the DBDataTable class use DBViews. The DBManager is used only to count the number of items returned by the DBView query.
4.7 The LocalRoutingTable class The Routing Table had to be implemented in principle in the same way as the Data Table. However, while designing the database it appeared that it would not be possible to handle the routing table completely in the database as it has been done for the data table. The reason for this is that Gridella needs to maintain a list of fidgets that it can shuffle and change dynamically during the execution and it therefore made more sense keeping this list in main memory then in the database. This list of fidgets is used to perform random exchange routines and it is thus essential to keep it in memory so that it can be handled efficiently. However, the Routing Table is by nature much smaller than the Data Table so it is not a problem to keep it in memory. As a result of this issue, it has been decided to use the database only to save the routing table when Gridella shuts down and to load it when the program starts up. In fact, in that sense, the database is only used as storage mean. The implementation of this class was rather straightforward as only the XML writing and parsing methods had to be replaced with the database methods. The RoutingTable class (our super class) than handles the items in memory during the execution of Gridella. JDBC PreparedStatements are used as often as possible to optimize the insertion of hosts in the database as it is possible to use them more efficiently here then explained
18

EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
in Section 4.4.1 because the data is inserted in the database all at once when saving the routing table.
4.7.1 LocalRoutingTable UML diagram
Figure 14: LocalRoutingTable UML Diagram
Figure 14 shows the UML diagram of the LocalRoutingTable class. It uses the DBManager class to interact with the database.
5 TESTS AND EVALUATION Several performances had to be tested to evaluate the created implementation. The consistency of the data in the database was first tested to ensure that no information is lost, duplicated, or corrupted with regards to the data table and the routing table. Further, the improvements that have been made to the exchange process have been tested, as it was one of the key issues in this project. This has been measured in terms of the time taken to process different cases of exchange.
19

EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
Next, the search process had to be analyzed by comparing the time taken to perform the query on the local database and in memory, and then evaluating the consistency of the data returned. Finally, some specific database tests were executed to evaluate the performance of the hsqldb engine.
5.1 Testing environment For the purpose of testing, a version of the implementation that allowed to keep both the previous XML implementation and the database implementation running at the same time has been used. As a result, it was possible to test precisely the different functionalities and compare both the data provided and the time taken to provide it. A class that enabled to output the timing results in XML files has been created. These files were then used to generate the charts presented. The general timing method is the following:
Declare three timing variables of the type long, to ensure that no precision is lost. The variables are the start, stop and elapsed variables.
Get the exact time before the test starts. Get the time at the end of it and calculate and output the elapsed time in the XML file.
Do the same for the other implementation.
Figure 15: Timing method of our testing environment.
Figure 15 shows an example case of an exchange process. The highlighted parts are relative to the timing method. The time taken for the in-memory version of the data table to perform the union of two data tables is first evaluated, followed by a
20
EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
measurement of the time taken by the database to set the data table to the query provided by the union DBView. It is important to note that we use our database in an auto commit mode; which means that transactions are committed as they are performed. This part of the process is therefore also considered in our evaluation. Analyzing the consistency of the data in the data base was done by comparing the XML files with the information contained in the data base. Mostly, this was done by comparing the row count in the dataitems table and the number of data items in the XML data table. However, for specific issues such as the consistency of data returned by a search query, the elements were directly compared.
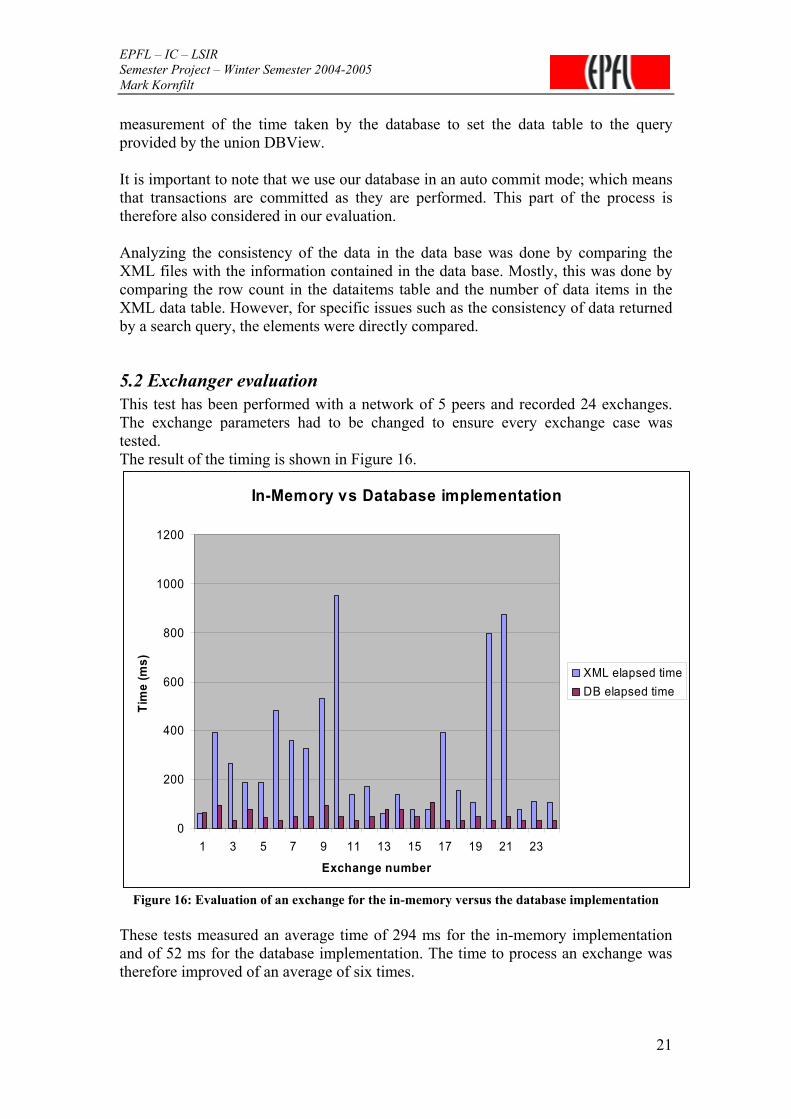
5.2 Exchanger evaluation This test has been performed with a network of 5 peers and recorded 24 exchanges. The exchange parameters had to be changed to ensure every exchange case was tested. The result of the timing is shown in Figure 16.
In-Memory vs Database implementation
0
200
400
600
800
1000
1200
1 3 5 7 9 11 13 15 17 19 21 23
Exchange number
Tim
e (m
s)
XML elapsed timeDB elapsed time
Figure 16: Evaluation of an exchange for the in-memory versus the database implementation
These tests measured an average time of 294 ms for the in-memory implementation and of 52 ms for the database implementation. The time to process an exchange was therefore improved of an average of six times.
21
EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
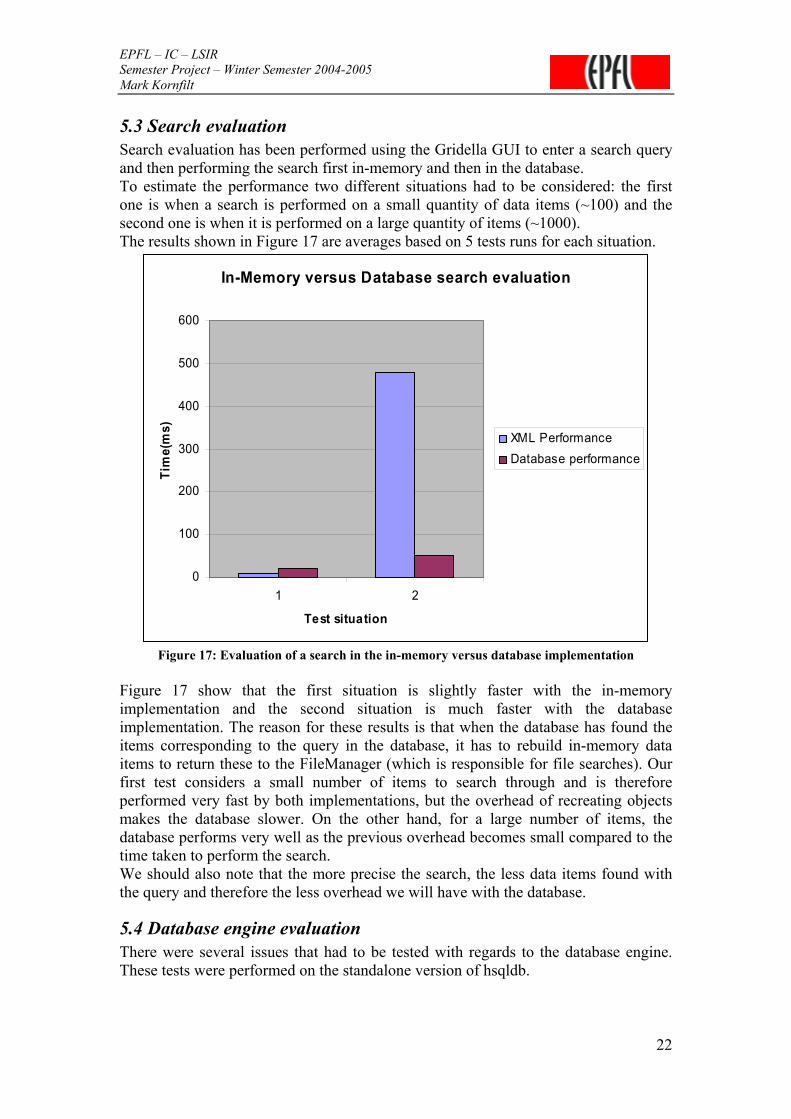
5.3 Search evaluation Search evaluation has been performed using the Gridella GUI to enter a search query and then performing the search first in-memory and then in the database. To estimate the performance two different situations had to be considered: the first one is when a search is performed on a small quantity of data items (~100) and the second one is when it is performed on a large quantity of items (~1000). The results shown in Figure 17 are averages based on 5 tests runs for each situation.
In-Memory versus Database search evaluation
0
100
200
300
400
500
600
1 2
Test situation
Tim
e(m
s)
XML PerformanceDatabase performance
Figure 17: Evaluation of a search in the in-memory versus database implementation
Figure 17 show that the first situation is slightly faster with the in-memory implementation and the second situation is much faster with the database implementation. The reason for these results is that when the database has found the items corresponding to the query in the database, it has to rebuild in-memory data items to return these to the FileManager (which is responsible for file searches). Our first test considers a small number of items to search through and is therefore performed very fast by both implementations, but the overhead of recreating objects makes the database slower. On the other hand, for a large number of items, the database performs very well as the previous overhead becomes small compared to the time taken to perform the search. We should also note that the more precise the search, the less data items found with the query and therefore the less overhead we will have with the database.
5.4 Database engine evaluation There were several issues that had to be tested with regards to the database engine. These tests were performed on the standalone version of hsqldb.
22

EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
The first one was the time taken by the database engine to start up. We had to test this because of the fact that hsqldb uses a script file to load the data in the database at startup (See section 2.1.1). We measured the startup 25 times with an increasing number of items in the tables. The results are shown in Figure 18.
Time to start the hsqldb database engine
0
500
1000
1500
2000
2500
3000
3500
4000
0 5000 10000 15000 20000 25000
Number of items
Tim
e(m
s)
Time (ms)
Figure 18: Time to start the hsqldb database engine
We can see from Figure 18 that the start up time grows in a more or less linear way. This could become a handicap if a large number of items have to be stored in the database, and it should be considered to change the RDBMS in that case. Next, the storage space taken by the database in comparison with the storage space that was taken by the XML files has been considered. It was observed that the amount of space was much less with the database. A 6MB DataTable XML file for example requires only 2MB in the database.
6 CONCLUSIONS AND POSSIBLE IMPROVEMENTS Several issues could not be resolved during this project due to the time constraints and the lack of expertise that I had at the beginning of the project. I will now present them for future improvements:
Prepared Statements: As I have explained in Section 4.4.1, inserting data with JDBC PreparedStatements is very efficient if the same SQL statement is executed several times. This is very often our case, but because I had to keep the implementation modular and wanted to change Gridella as little as possible, I could not use PreparedStatements efficiently. It would significantly
23

EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
improve the overall performance to use PreparedStatements to insert data. It could even be considered to use batch PreparedStatements as these give the ability to execute a large number of PreparedStatements all at once and therefore even further improve performances.
Database Triggers: A lot of data consistency checks are currently done in the java implementation. Using database triggers to perform them whenever possible would probably speed-up our implementation.
Testing with other RDBMS: Several other open-source databases are available and it would be interesting to test them with Gridella. One of them is the McKoi SQL Database5.
Keep up to date with hsqldb: Like many open-source projects, hsqldb evolves fast, and it would therefore be advisable to keep up-to-date with the future versions of the database engine.
Finally, I would like to conclude by saying that this project was a great experience for me. It has given me the opportunity to work on the very interesting P-Grid project and the Gridella implementation. As it was the first project of this size that I had to handle alone, I specially appreciated the availability of Roman Schmidt, Gridella’s main implementer and my advisor. I would like to thank Roman for his help, kindness and support, which have made this project the most interesting thing I have done in my studies up until now. I would also like to thank Professor Karl Aberer and the LSIR lab for allowing me to do a semester project in such a technically advanced and motivating environment.
5 McKoi SQL Database, http://mckoi.com/database/
24

EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
7 APPENDIX A: AN EXAMPLE « .SCRIPT » FILE Hsqldb stores the data in a .script file that contains only SQL statements. An example file could be:
Figure 19 Example hsqldb .script file
8 APPENDIX B: INSTALLATION The following steps are required to replace a clean Gridella project with the new implementation.
1) Add the hsqldb.jar to the project libraries. 2) Add the P-Grid.ddl file to the project root. 3) Import the mkornfilt package which contains:
a. DBDataTable.java b. DBManager.java c. DBView.java
4) Replace these original Gridella classes with the new classes: a. pgrid.core.LocalRoutingTable.java b. pgrid.core.DataItemManager.java c. pgrid.core.exchanger.java
25

EPFL – IC – LSIR Semester Project – Winter Semester 2004-2005 Mark Kornfilt
5) Change the following files: a. pgrid.PGrid.java: modify the constructor of LocalRoutingTable to
match new signature => remove constructor parameter. b. pgrid.core.Utils: make the signature(String signString, int
pageSize, int signLength) method public.
9 REFERENCES [PROTOCOL] Roman Schmidt, Manfred Hauswirth and John Renault, P-Grid Protocol Version 1.0, http://www.p-grid.org/specs/protocol.html [P-GRID] P-Grid, http://www.p-grid.org [ABERER01] Karl Aberer, Manfred Hauswirth, Magdalena Punceva, Roman Schmidt, Improving Data Access in P2P Systems, IEEE Internet Computing, 6(1), January/February 2002 [SCHMIDT] Roman Schmidt, Gridella: an open and efficient Gnutella-compatible Peer-to-Peer System based on the P-Grid approach, Technical University of Vienna, October 2002. [O’DONAHUE] John O’Donahue, Java Database Programming Bible, Wiley Publishing © 2002. [SPERKO] Richard Sperko, Java Persistence for Relational Databases, Apress © 2003 [HSQLDB] The hsqldb Development Group, hsql database engine, http://hsqldb.sourceforge.net/ [MCKOI] The McKoi SQL Database, http://mckoi.com/database/
26

















