Page 1
© 2015, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Keith Steward, Ph.D.,Specialist (EMR) Solutions Architect
September 29, 2016
Building Real-Time Processing Data Analytics Applications on AWSBuild powerful applications easily
Page 2
Agenda
1. Introduction to Amazon EMR and Kinesis
2. Real Time Processing Application Demo
3. Best Practices
Page 3
Amazon EMR?
Easy to UseLaunch a cluster in minutes
Low CostPay an hourly rate
ElasticEasily add or remove capacity
ReliableSpend less time monitoring
SecureManage firewalls
FlexibleCustomize the cluster
Page 4
Storage S3 (EMRFS), HDFS
YARNCluster Resource Management
BatchMapReduce
InteractiveTez
In MemorySpark
ApplicationsHive, Pig, Spark SQL/Streaming/ML,
Mahout, Sqoop
HBase / Phoenix
Presto
Hue (SQL Interface/Metastore Management)
Zeppelin (Interactive Notebook)Ganglia (Monitoring)HiveServer2/Spark
Thriftserver (JDBC/ODBC)
Amazon EMR service
Page 5
Options to submit jobs to EMR
Amazon EMR Step API
Submit a Spark application
Amazon EMR
Airflow, Luigi, or other schedulers on EC2
Create pipeline to schedule job
submission or create complex workflows
Use AWS Lambda tosubmit applications to
EMR Step API or directly
to Spark on your cluster
AWSLambda
AWS Data Pipeline
Page 6
Many storage layers to choose from
Amazon DynamoDB
Amazon RDS Amazon Kinesis
Amazon Redshift
EMR File System
(EMRFS)
Amazon S3
Amazon EMR
Page 7
EMR 5.0 - Applications
Page 9
Quick introduction to Spark
join
filter
groupBy
Stage 3
Stage 1
Stage 2
A: B:
C: D: E:
F:
= cached partition= RDD
map
• Massively parallel
• Uses DAGs instead of map-reduce for execution
• Minimizes I/O by storing data in DataFrames in memory
• Partitioning-aware to avoid network-intensive shuffle
Page 10
Spark components to match your use case
Page 11
Spark 2.0 – Performance Enhancements
• Second generation Tungsten engine
• Whole-stage code generation to create optimized bytecode at runtime
• Improvements to Catalyst optimizer for query performance
• New vectorized Parquet decoder to increase throughput
Page 12
Datasets & DataFrames (Spark 2.0)
Datasets• Distributed collection of data
• Strong typing, can use Lambda functions
• Object-oriented operations (similar to RDD API)
• Optimized encoders for better performance; minimize serialization /deserialization overhead
• Compile-time type safety for robust applications
DataFrames• Dataset organized into named
columns
• Represented as a Dataset of rows
Page 13
Spark SQL (Spark 2.0)
• SparkSession – replaces the old SQLContext and HiveContext
• Seamlessly mix SQL with Spark programs
• ANSI SQL Parser and subquery support
• HiveQL compatibility and can directly use tables in Hive metastore
• Connect through JDBC / ODBC using the Spark Thrift server
Page 14
Spark 2.0 – Structured Streaming
• Structured Streaming API: extension to the DataFrame/Dataset API (instead of DStream)
• SparkSession is the new entry point for streaming
• Better merges processing on static and streaming datasets, abstracting the velocity of the data
Page 15
Configuring Executors – Dynamic Allocation
• Optimal resource utilization
• YARN dynamically adjusts executors based on resource needs of Spark application
• Spark uses the executor memory and executor cores settings in the configuration for each executor
• Amazon EMR uses dynamic allocation by default, and calculates the default executor size to use based on the instance family of your Core Group
Page 16
Try different configurations to find your optimal architecture.
CPUc3 familyc4 family
cc1.4xlargecc2.8xlarge
Memorym2 familyr3 family
Disk/IOd2 familyi2 family
General
m4 familym3 familym1 family
Choose your instance types
Batch Machine Spark and Large
process learning interactive HDFS
Page 17
Zeppelin 0.6.1 – New Features
• Shiro Authentication• Notebook Authorization
Configurations to save notebook in S3zeppelin-env.sh:export ZEPPELIN_NOTEBOOK_S3_BUCKET = bucket_nameexport ZEPPELIN_NOTEBOOK_S3_USER = username(optional) export ZEPPELIN_NOTEBOOK_S3_KMS_KEY_ID = kms-key-id
Page 18
Amazon Kinesis Streams
Build your own custom applications that
process or analyze streaming data
Amazon Kinesis Firehose
Easily load massive volumes of streaming data into Amazon S3
and Redshift
Amazon Kinesis Analytics
Easily analyze data streams using
standard SQL queries
Amazon Kinesis: Streaming data made easyServices make it easy to capture, deliver, and process streams on AWS
Page 19
Amazon Kinesis ConceptsStreams: • Ordered sequence of data records
Data Records: • Unit of data stored in a Kinesis stream
Producers: • Anything that puts records into a Kinesis stream• Kinesis Producer Library (KPL)
Consumers: • End-points that get records from a Kinesis stream & processes them
• Kinesis Consumer Library (KCL)
Page 20
Amazon Kinesis Streams features…
• Kinesis Client Library in Python, Node.JS, Ruby…
• PutRecords API, up to 500 records or 5 MB of payload
• Kinesis Producer Library to simplify producer development
• Server-Side Timestamps
• individual max record payload up to 1 MB
• Low end-to-end propagation delay
• Stream Retention defaults to 24 hrs, but can increase to 7 days
Page 21
Real Time Processing Application
and Demo
Page 22
Real Time Processing Application
+
Kinesis Producer(KCL)
Amazon Kinesis
Apache Zeppelin+
Produce Collect Process Analyze
Amazon EMR
Page 23
Real Time Processing Application – 5 Steps http://bit.ly/realtime-aws
1. Create Kinesis Stream
2. Create Amazon EMR Cluster
3. Start Kinesis Producer
4. Ad-hoc Analytics• Analyze data using Apache Zeppelin on
Amazon EMR with Spark Streaming
5. Continuous Streaming• Spark Streaming application submitted to
Amazon EMR cluster using Step API
Amazon Kinesis
Amazon EMR
Amazon EC2
(Kinesis Producer)
(Kinesis Consumer)
Page 24
Real Time Processing Application
1. Create Kinesis Stream:
$ aws kinesis create-stream --stream-name spark-demo --shard-count 2
Page 25
Real Time Processing Application
2. Create Amazon EMR Cluster with Spark and Zeppelin:$ aws emr create-cluster --release-label emr-5.0.0 \
--applications Name=Zeppelin Name=Spark Name=Hadoop \ --enable-debugging \ --ec2-attributes KeyName=test-key-1,AvailabilityZone=us-east-1d \ --log-uri s3://kinesis-spark-streaming1/logs \ --instance-groups \ Name=Master,InstanceGroupType=MASTER,InstanceType=m3.xlarge,InstanceCount=1 \ Name=Core,InstanceGroupType=CORE,InstanceType=m3.xlarge,InstanceCount=2 \ Name=Task,InstanceGroupType=TASK,InstanceType=m3.xlarge,InstanceCount=2 \ --name "kinesis-processor"
Page 26
Real Time Processing Application
3. Start Kinesis Producer (Using Kinesis Producer Library)a. On a host (e.g. EC2), download JAR and run Kinesis Producer:
$ wget https://s3.amazonaws.com/chayel-emr/KinesisProducer.jar$ java –jar KinesisProducer.jar
b. Continuous stream of data records will be fed into Kinesis in CSV format:… device_id,temperature,timestamp …
Git link: https://github.com/manjeetchayel/emr-kpl-demo
Page 27
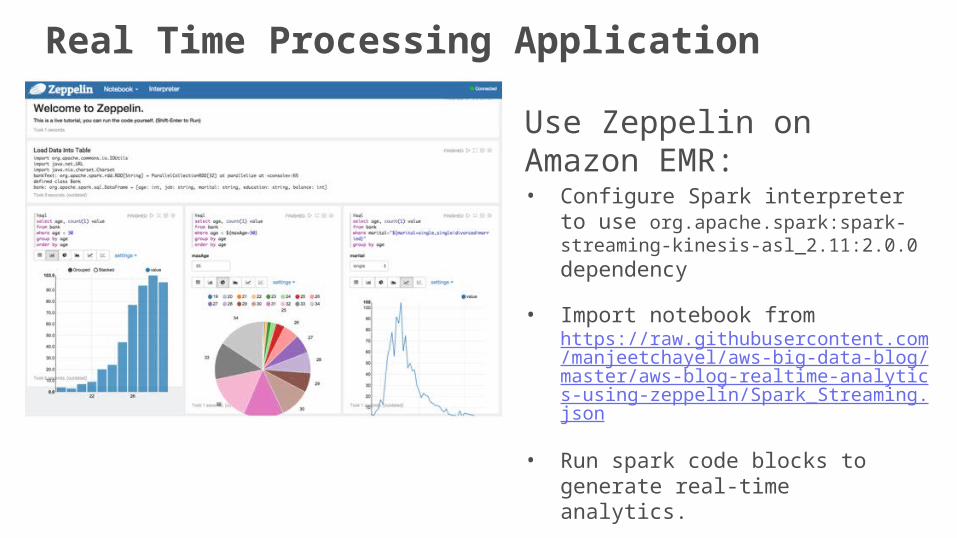
Real Time Processing Application
Use Zeppelin on Amazon EMR:• Configure Spark interpreter to use
org.apache.spark:spark-streaming-kinesis-asl_2.11:2.0.0 dependency
• Import notebook from https://raw.githubusercontent.com/manjeetchayel/aws-big-data-blog/master/aws-blog-realtime-analytics-using-zeppelin/Spark_Streaming.json
• Run spark code blocks to generate real-time analytics.
Page 29
Best Practices - Kinesis
• Use Kinesis Producer Library• Increase capacity utilization with Aggregation• Setup CloudWatch alarms
• Randomized Partitions key to distribute puts across Shards
• Deal with unsuccessful records
• Use PutRecords for higher throughput!
• Kinesis Scaling Utility for scaling Streams
Page 30
Best Practices – Amazon EMR + Spark Streaming
• Use Step API to submit long running applications
• Run Spark application in cluster mode
• Use maxResourceAllocation
• Unqiue Spark Application name for KCL DynamoDB metadata
• Setup CloudWatch alarms
• Use IAM roles
Page 31
Thank you!
[email protected] ://aws.amazon.com/emrhttp://blogs.aws.amazon.com/bigdata