Building a Virtualized Distributed Computing Infrastructure by Harnessing Grid and Cloud Technologies Alexandre di Costanzo, Marcos Dias de Assunção, and Rajkumar Buyya Grid Computing and Distributed Systems Laboratory Department of Computer Science and Software Engineering The University of Melbourne, Australia Abstract In this article, we present the realization of a system, termed as InterGrid, for interconnecting distributed computing infrastructures by harnessing virtual machines. The InterGrid aims to provide an execution environment for running applications on top of the interconnected infrastructures. The system uses virtual machines as the building blocks to construct execution environments that span multiple computing sites. An execution environment is a network of virtual machines created to fulfill the requirements of an application, thus running isolated from other execution environments. These environments can be extended to operate on Cloud infrastructure, such as Amazon EC2. The article provides an abstract view of the proposed architecture and its implementation; experiments show the scalability of an infrastructure managed by InterGrid and how the system can benefit from using Cloud infrastructure. Introduction Over the last decade, the distributed computing area has been characterized by the deployment of largescale Grids such as EGEE [1] and Grid’5000 [2],. Such Grids have provided the research community with an unprecedented number of resources, which have been used for various scientific endeavors. Several efforts have been made to enable interoperation between Grids by providing standard components and adapters for secure job submissions, data transfers, and information queries [3]. Despite these efforts, the heterogeneity of hardware and software has contributed to increasing complexity of deploying applications on these infrastructures. Moreover, recent advances in virtualization technologies [4] have led to the emergence of commercial infrastructure providers, also known as Cloud computing [5]. Handling the ever growing demands of
Transcript
Building a Virtualized Distributed Computing Infrastructure by
Harnessing Grid and Cloud Technologies
Alexandre di Costanzo, Marcos Dias de Assunção, and Rajkumar Buyya Grid Computing and Distributed Systems Laboratory
Department of Computer Science and Software Engineering The University of Melbourne, Australia
Abstract
In this article, we present the realization of a system, termed as InterGrid, for
interconnecting distributed computing infrastructures by harnessing virtual
machines. The InterGrid aims to provide an execution environment for running
applications on top of the interconnected infrastructures. The system uses
virtual machines as the building blocks to construct execution environments that
span multiple computing sites. An execution environment is a network of virtual
machines created to fulfill the requirements of an application, thus running
isolated from other execution environments. These environments can be
extended to operate on Cloud infrastructure, such as Amazon EC2. The article
provides an abstract view of the proposed architecture and its implementation;
experiments show the scalability of an infrastructure managed by InterGrid and
how the system can benefit from using Cloud infrastructure.
Introduction
Over the last decade, the distributed computing area has been characterized by
the deployment of large-‐scale Grids such as EGEE [1] and Grid’5000 [2],. Such
Grids have provided the research community with an unprecedented number of
resources, which have been used for various scientific endeavors. Several efforts
have been made to enable interoperation between Grids by providing standard
components and adapters for secure job submissions, data transfers, and
information queries [3]. Despite these efforts, the heterogeneity of hardware and
software has contributed to increasing complexity of deploying applications on
these infrastructures. Moreover, recent advances in virtualization technologies
[4] have led to the emergence of commercial infrastructure providers, also
known as Cloud computing [5]. Handling the ever growing demands of
distributed applications while addressing heterogeneity, remains a challenging
task that can require resources from both Grids and clouds.
In previous work, we presented an architecture for resource sharing between
Grids [6] inspired by the peering agreements established between Internet
Service Providers (ISPs) in the Internet, through which ISPs agree to allow traffic
into one another's networks. This work presents the realization of the
architecture, which is termed as InterGrid and relies on InterGrid Gateways
(IGGs) that mediate access to resources of participating Grids. The InterGrid also
aims at tackling the heterogeneity of hardware and software within Grids. The
use of virtualization technology can ease the deployment of applications
spanning multiple Grids as it allows for resource control in a contained manner.
In this way, resources allocated by one Grid to another are used to deploy virtual
machines. Virtual machines also allow the use of resources from Cloud
computing providers.
We first introduce the concepts on virtualization and Cloud computing. Then, we
describe the InterGrid project (www.gridbus.org/intergrid), which aims to
provide an infrastructure for deploying applications on several computing sites,
or Grids, by using virtualization technologies. These applications run on
networks of virtual machines or execution environments created on top of the
physical infrastructure. Next, the system design and implementation are
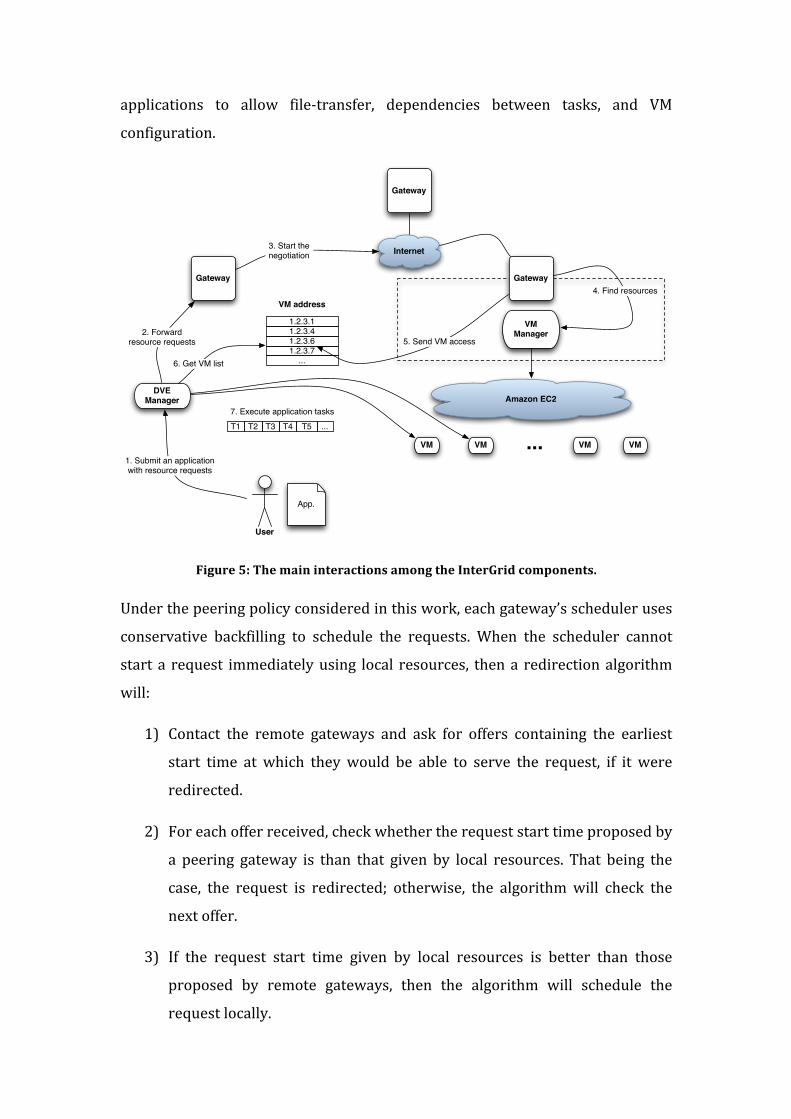
presented. To illustrate the different interactions among the system components,
we describe the InterGrid at runtime. Finally, experimental results demonstrate
the system scalability and show how applications can combine resources from
two cloud provider sites.
Background and Context
Virtualization Technology and Infrastructure as a Service
The increasing ubiquity of Virtual Machine (VM) technologies has enabled the
creation of customized environments atop physical infrastructure and the
emergence of business models such as Cloud computing. The use of VMs brings
several benefits such as:
(i) Server consolidation, allowing workloads of several under-‐utilized
servers to be placed in fewer machines;
(ii) The ability to create VMs to run legacy code without interfering with
other applications' APIs;
(iii) Improved security through the creation of sandboxes for running
applications with questionable reliability; and
(iv) Performance isolation, thus allowing a provider to offer some
guarantees and better QoS to customers' applications.
Existing virtual-‐machine based resource management systems can manage a
cluster of computers within a site allowing the creation of virtual workspaces [7]
or virtual clusters [8]. They can bind resources to virtual clusters or workspaces
according to a user's demand. These systems commonly provide an interface
through which one can allocate VMs and configure them with the operating
system and software of choice. These resource managers, also named Virtual
Infrastructure Engines (VIE), allow the user to create customized virtual clusters
using shares of the physical machines available at the site.
As explained earlier, virtualization technology minimizes some security concerns
inherent to the sharing of resources among multiple computing sites. We utilize
virtualization software to realize the InterGrid architecture because existing
cluster resource managers relying on VMs can provide us with the building
blocks, such as the availability information, required for the creation of virtual
execution environments. In addition, relying on VMs eases the deployment of
execution environments on multiple computing sites; the user application can
have better control over the software installed on the resources allocated
without compromising the operation of the hosts' operating systems at the
computing sites.
Virtualization technologies have also facilitated the realization of Cloud
Computing services. Cloud computing includes three kinds of services accessible
by the Internet: Software as a Service (SaaS), Platform as a Service (PaaS), and
Infrastructure as a Service (IaaS). This work considers only IaaS. IaaS aims to
give provide computing resources or storage as a service to users. One of the
major players in Cloud computing is Amazon with its Elastic Compute Cloud
(EC2)1, which comprises several data centers located around the world. EC2
allows users to deploy VMs on demand on Amazon’s infrastructure and pay only
for the computing, storage and network resources they use.
Related Work
Existing work has shown how to enable virtual clusters that span multiple
physical computer clusters. A broker is responsible for managing a virtual
domain (i.e. a virtual cluster) in VioCluster [1], and can borrow resources from
another broker. Brokers have borrowing and lending policies that define when
machines are requested from other brokers and when they are returned,
respectively.
Systems for virtualizing a physical infrastructure are also available. Montero et
al. [2] investigated the deployment of custom execution environments using
Open Nebula. They investigated the overhead of two distinct models for starting
virtual machines and adding them to an execution environment. Montero et al.
[3] also used GridWay to deploy virtual machines on a Globus Grid; jobs are
encapsulated as virtual machines. Montero et al. showed that the overhead of
starting a virtual machine is small for the application evaluated.
Several load-‐sharing mechanisms have been investigated in the distributed
systems realm. Iosup et al. [4] proposed a matchmaking mechanism for enabling
resource sharing across computational Grids. Surana et al. [5] addressed the load
balancing in DHT-‐based P2P networks.
[1] P. Ruth, P. McGachey, and D. Xu. VioCluster: Virtualization for dynamic computational
domain. In IEEE International on Cluster Computing (Cluster 2005), pages 1–10, Burlington,
USA, September 2005. IEEE.
[2] R. S. Montero, E. Huedo, and I. M. Llorente. Dynamic deployment of custom execution
environments in Grids. In 2nd International Conference on Advanced Engineering Computing 1 http://aws.amazon.com/ec2/
and Applications in Sciences (ADVCOMP ’08), pages 33–38, Valencia, Spain,
September/October 2008. IEEE Computer Society.
[3] A. Rubio-Montero, E. Huedo, R. Montero, and I. Llorente. Management of virtual machines on
globus Grids using GridWay. In IEEE International Parallel and Distributed Processing
Symposium (IPDPS 2007), pages 1–7, Long Beach, USA, March 2007. IEEE Computer Society.
[4] A. Iosup, D. H. J. Epema, T. Tannenbaum, M. Farrellee, and M. Livny. Inter-operating Grids
through delegated matchmaking. In 2007 ACM/IEEE Conference on Supercomputing (SC
2007), pages 1–12, New York, USA, November 2007. ACM Press.
[5] S. Surana, B. Godfrey, K. Lakshminarayanan, R. Karp, and I. Stoica. Load balancing in
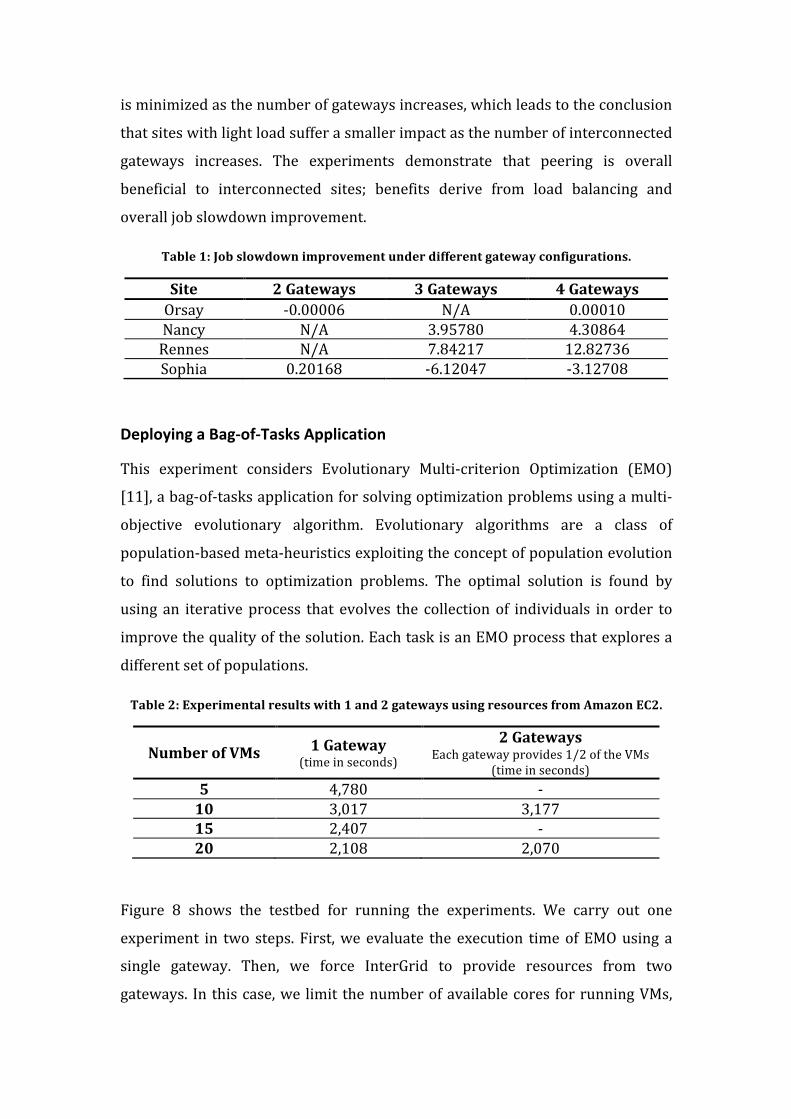
Figure 8 shows the testbed for running the experiments. We carry out one
experiment in two steps. First, we evaluate the execution time of EMO using a
single gateway. Then, we force InterGrid to provide resources from two
gateways. In this case, we limit the number of available cores for running VMs,
and the DVE Manager submits two requests. For 10 VMs, both gateways are
limited to nine cores and the DVE Manager sends two requests for five VMs each.
Next, for 20 VMs gateways set the limit to 20 cores and the DVE Manager
requests 10 VMs twice. The two gateways use resources from EC2. The requests
demand a small EC2 instance running Windows 2003 Server. Table 2 reports the
results of both experiments. The experiments show that the execution time of
the bag-‐of-‐tasks application does not suffer important performance degradations
with one or two gateways.
Amazon EC2
IGG-1 IGG-2
USA
site 1
USA
site n...
Getting Virtual Machine from the Cloud
Negotiating resources
Figure 8: Testbed used to run EMO on a Cloud Computing provider.
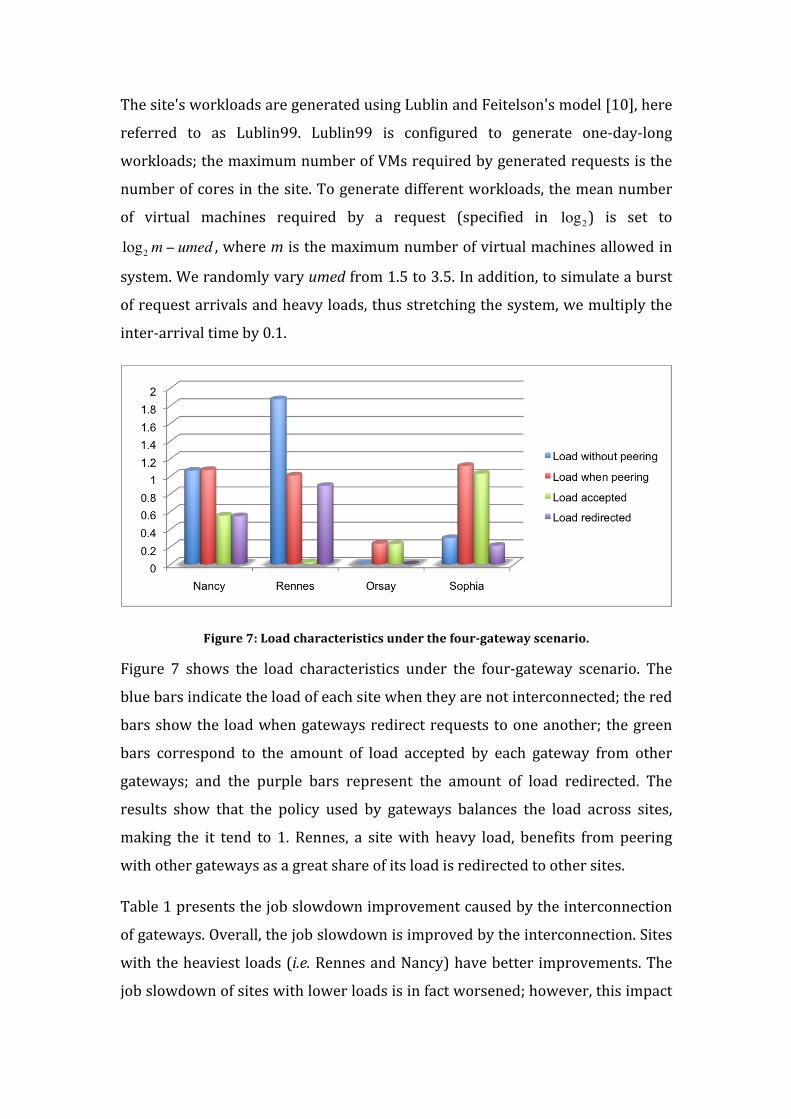
Conclusion
This article presented a system, the InterGrid, for deploying applications on
multiple-‐site execution environments. The system relies on gateways inspired by
the peering agreements between ISPs. We described the virtualization
technology used by InterGrid to abstract physical infrastructures. Then, we
showed the motivation and the realization of the InterGrid system.
As the management of the local resource is based on virtual infrastructure
engines, we detail how the gateway interacts with these engines to control
virtual machines. In addition, the InterGrid can instantiate VMs on Amazon EC2
and deploy system images on Grids, such as Grid’5000.
Experimental results emulating a real Grid showed the performance of allocation
decisions made by gateways. We also presented a runtime scenario for deploying
a parallel evolutionary algorithm for solving optimization problems. With that
application, we validated the realization of the InterGrid by comparing the
runtime execution of the application when obtaining resources from one
gateway at a time and from two gateways, which were deploying VMs on
Amazon EC2.
In future work, we plan to improve the VM template directory to allow users to
submit their own VMs and to synchronize the available VMs between gateways.
In addition, the security aspects have not been addressed in this work because
they are handled at the operating system and network levels, it would be
interesting to address those aspects at the InterGrid level.
Acknowledgments
We thank Mohsen Amini for helping in the system implementation. This work is
supported by research grants from the Australian Research Council and
Australian Department of Innovation, Industry, Science and Research. Marcos'
PhD research is partially supported by NICTA. Some experiments were carried
out using the Grid'5000 experimental testbed, being developed under the INRIA
ALADDIN development action with support from CNRS, RENATER, several
universities, and other funding bodies (see https://www.grid5000.fr).
References [1] Enabling Grids for E-‐sciencE (EGEE) project, http://public.eu-‐egee.org
(2005).
[2] F. Cappello, E. Caron, M. Dayde, F. Desprez, Y. Jegou, P. Primet, E. Jeannot, S. Lanteri, J. Leduc, N. Melab, G. Mornet, R. Namyst, B. Quetier, and O. Richard. “Grid’5000: a large scale and highly reconfigurable grid experimental testbed”. In 6th IEEE/ACM International Workshop on Grid Computing, 2005.
[3] Grid Interoperability Now Community Group (GIN-‐CG), http://forge.ogf.org/sf/projects/gin (2006).
[4] X. Zhu, D. Young, B. Watson, Z. Wang, J. Rolia, S. Singhal, B. McKee, C. Hyser, D. Gmach, R. Gardner, et al. 1000 Islands: Integrated Capacity and Workload Management for the Next Generation Data Center. In Autonomic Computing, 2008. ICAC’08. International Conference on, pages 172–181, 2008.
[5] M. Armbrust, A. Fox, R. Griffith, A. D. Joseph, R. H. Katz, A. Konwinski, G. Lee, D. A. Patterson, A. Rabkin, I. Stoica, and M. Zaharia. Above the clouds: A berkeley view of cloud computing. Technical Report UCB/EECS-‐2009-‐28, EECS Department, University of California, Berkeley, Feb 2009.
[6] M. D. de Assunção, R. Buyya, S. Venugopal, InterGrid: A case for internetworking islands of Grids, Concurrency and Computation: Practice and Experience (CCPE) 20 (8) (2008) 997–1024.
[7] K. Keahey, I. Foster, T. Freeman, X. Zhang, Virtual workspaces: Achieving quality of service and quality of life in the Grids, Scientific Programming 13 (4) (2006) 265–275.
[8] J. S. Chase, D. E. Irwin, L. E. Grit, J. D. Moore, S. E. Sprenkle, Dynamic virtual clusters in a Grid site manager, in: 12th IEEE International Symposium on High Performance Distributed Computing (HPDC 2003), IEEE Computer Society, Washington, DC, USA, 2003, p. 90.
[9] M. D. de Assunção, A. di Costanzo and R. Buyya. Evaluating the Cost-‐Benefit of Using Cloud Computing to Extend the Capacity of Clusters, In Proceedings of the International Symposium on High Performance Distributed Computing (HPDC 2009), Munich, Germany, 11-‐13 Jun. 2009.
[10] U. Lublin and D. G. Feitelson. The workload on parallel supercomputers: Modeling the characteristics of rigid jobs. Journal of Parallel and Distributed Computing, 63 (11) (2008) 1105–1122.
[11] M. Kirley, and R. Stewart, “Multiobjective evolutionary algorithms on complex networks”, in Proc. of the Fourth International Conference on Evolutionary Multi-‐Criterion Optimization, Lecture Notes Computer Science 4403, Springer Berlin, Heidelberg, 2007, pp. 81–95.
Alexandre di Costanzo is a research fellow at the University of Melbourne. His
research interests are distributed computing and especially grid computing. Di
Costanzo has a PhD in computer science from the University of Nice Sophia