Early Dual Grid Voltage Integrity Verification by Mehmet Avci A thesis submitted in conformity with the requirements for the degree of Master of Applied Science Graduate Department of Electrical and Computer Engineering University of Toronto c Copyright by Mehmet Avci 2010
Transcript
Early Dual Grid Voltage Integrity Verification
by
Mehmet Avci
A thesis submitted in conformity with the requirements
for the degree of Master of Applied ScienceGraduate Department of Electrical and Computer Engineering
1.1 A 5-node grid . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2 Current configuration resulting in voltage overshoot for node A . . . . 3
2.1 A multiple-layer power distribution network [1] . . . . . . . . . . . . 62.2 Reduction of noise margins of CMOS circuits with technology scaling [1] 72.3 Power current requirements of high-performance microprocessors with
technology scaling [2] . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.4 An RLC model of an on-chip power distribution network [3] . . . . . 92.5 A hierarchical model of a power distribution network [4] . . . . . . . 102.6 An instance of a random walk game [5] . . . . . . . . . . . . . . . . . 12
4.1 Absolute error comparison for all nodes of a 437-node grid . . . . . . 544.2 Absolute error comparison for all nodes of a 4285-node grid . . . . . . 544.3 Relative error comparison for all nodes of a 437-node grid . . . . . . . 564.4 Relative error comparison for all nodes of a 4285-node grid . . . . . . 56
vii
List of Tables
4.1 Runtime and accuracy comparison of AINV and SPAI . . . . . . . . . 504.2 Runtime comparison of the interior point method and the network
352 1742 2.45 sec. 123904 9.58 sec. 123904 4.77 × 10−4
1019 5077 30.65 sec. 950679 234.53 sec. 920543 2.39 × 10−4
2145 10481 4.13 min. 3405684 19.74 min. 3259647 2.84 × 10−4
4594 10481 12.47 min. 8830532 40 min. 8543094 2.26 × 10−4
10580 50826 28.23 min. 16284736 2.45 h. 15924396 1.74 × 10−4
Table 4.1: Runtime and accuracy comparison of AINV and SPAI
is significantly faster than SPAI for our purposes. It is obvious that the inverse com-
puted with AINV method has more nonzeros than the original matrix. Although
we drop entries during the computation of z-vectors whose magnitude is less than
δ = e−6, the final stage of the Algorithm 3, which is A−1 = ZD−1ZT , results in
additional fill-in, and therefore the resulting approximate inverse has some entries
whose magnitude is less than δ. To reduce the number of nonzeros, one can drop
these insignificant entries after the computation of the approximated inverse.
Experimental results in [34] also show that AINV is more effective and faster than
the other approximate inverse methods. Therefore, we have adopted it for our imple-
mentation.
4.4.2 Network Simplex Method
We will show that the linear programs in our formulation can be efficiently solved
with the help of a network simplex method. Using the notation given in the previous
sections, we have the following linear program for each node:
50
4 Worst-Case Voltage Fluctuation
maximize / minimize: f(i)
subject to: 0 ≤ Ui ≤ iG
Mi = 0
0 ≤ i ≤ iL
(4.72)
where f(i) : Rn → R is the linear objective function of i. To simplify the notation,
we augment the matrices U and M into the matrix T , and we augment the vectors
iG and the zero-vector of size γ into the vector a:
T =
U
M
, a =
iG
0(µ)
where T is a matrix of size (µ + γ) × n, and a is a vector of size (µ + γ) × 1. With
this notation the linear program (4.72) can be rewritten as:
maximize / minimize: f(i)
subject to: 0 ≤ T i ≤ a
0 ≤ i ≤ iL
(4.73)
The constraint matrix T consists of entries which are 1s, -1s or 0s. It resembles the
node-arc incidence matrix (NAIM) of a network, in the sense that NAIM also has
entries which are 1s, -1s or 0s. This is the key observation that allows us to formulate
the optimization problem (4.73) as a network flow problem. In our optimization
problem, the equality constraints define flow conservation constraints of the network
flow problem, whereas local constraints define capacity constraints on the flow along
the edges in the network. Furthermore, global constraints define side constraints on
51
4 Worst-Case Voltage Fluctuation
the sum of the flows along the edges. For a more detailed discussion of network flow
problems, the reader is referred to [35].
Network flow problems can be efficiently solved with the help of the network simplex
method. Empirical results have shown that the method is significantly faster than
the standard simplex method, when applied to the same network problem [36]. Fur-
thermore, it is shown in [37] that significant computational speed up can be achieved
if closely related instances of network flow problems are solved sequentially. This
observation is quite beneficial for our problem in the sense that the feasibility space
of currents remains the same at each instance of the optimization problem. Thus, we
have the same optimization problem for each node except different objective functions.
Previous work for grid verification [19], [20] used the interior point method to
solve the required linear programs. To compare the runtime characteristics of the
interior point method and the network simplex method, we have conducted several
experiments to solve linear programs resulting from grid verification. To solve the
linear programs, the Mosek optimization package [38] was used. The computations
were carried on a 64-bit Linux machine with 8 GB memory. The results of the
experiments are presented in Table 4.2. Column 1 reports the size of the optimization
problem, whereas column 2 and 3 show the runtime to solve the problem using the
interior point method and the network simplex method, respectively. It can be seen
from Table 4.2 that the network simplex method is significantly faster than the interior
point method.
4.5 Experimental Results
To test our method, we have implemented Algorithms 1, 2, and 3 in C++. We have
set ǫ = e−5 to stop the main loop of Algorithm 1. To solve the required linear pro-
52
4 Worst-Case Voltage Fluctuation
Problem Interior Point Method Network Simplex Method
size runtime runtime
365 2.17 sec. 0.11 sec.
742 6.46 sec. 0.46 sec.
2143 28.89 sec. 2.73 sec.
6750 2.47 min. 15.92 sec.
14358 6.45 min. 46.29 sec.
24836 14.74 min. 1.56 min.
Table 4.2: Runtime comparison of the interior point method and the network simplexmethod
grams, we have used the hot-start option of the Mosek network simplex solver for
fast objective function switching. Several experiments were conducted on a set of
test grids, which were generated from user specifications, which include grid dimen-
sions, metal layers (M1-M9), pitch and width per layer, and C4 and current source
distribution. Minimum spacing and sheet and via resistances were specified accord-
ing to a 65 nm technology. A global constraint is specified for each macroblock, and
additional global constraints were specified covering the entirety of the grid area. The
computations were carried on a 64-bit Linux machine with 8 GB memory.
Table 4.3 shows the speed and the accuracy of our proposed solution technique for
the computation of the vectors of lower and upper bounds on the worst-case voltage
fluctuations. The results are compared with each other and the maximum absolute
difference between the upper and the lower bound vector is reported in column 6,
where the relative error is defined as (vub(∞) − vlb(∞))/vlb(∞). The results show
that our solution technique resulted in a maximum absolute error of 2.72mV across
all nodes of all test grids. The number of time steps shown in column 3 and 5 reports
the number of time steps for which the lower and upper bound algorithms converge.
The runtime for each one of two methods is also shown in the table.
Figure 4.1 and 4.2 show scatter plots with the lower bound on the worst-case
53
4 Worst-Case Voltage Fluctuation
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.160
0.5
1
1.5
2
2.5
3
3.5
lower bound on worst−case voltage fluctuation(V)
abso
lute
err
or(m
V)
Figure 4.1: Absolute error comparison for all nodes of a 437-node grid
0 0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.160
0.5
1
1.5
2
2.5
3
3.5
lower bound on worst−case voltage fluctuation(V)
abso
lute
err
or(m
V)
Figure 4.2: Absolute error comparison for all nodes of a 4285-node grid
54
4 Worst-Case Voltage Fluctuation
Table 4.3: Runtime and accuracy of lower and upper bound algorithms
Grid Lower Bound Upper Bound
nodes runtime time steps runtime time steps maximum absolute error
65 2.25 sec. 7 4.63 sec. 3 0.87mV
102 4.13 sec. 5 8.48 sec. 4 1.75mV
437 39.33 sec. 4 57.49 sec. 3 2.52mV
1052 1.98 min. 4 2.43 min. 5 2.67mV
4285 14.66 min. 5 16.73 min. 4 2.59mV
8628 40.74 min. 4 46.35 min. 3 2.34mV
18,472 1.57 h. 6 2.14 h. 3 2.65mV
31,974 3.74 h. 7 4.73 h. 4 1.45mV
76,753 9.45 h. 6 10.68 h. 4 2.72mV
104,943 10.79 h. 4 12.45 h. 3 1.84mV
192,974 18.55 h. 3 23.16 h. 3 1.39mV
voltage fluctuation on one axis and the absolute error on the other axis, for a 437-
node grid and a 4285-node grid, respectively, where the absolute error is defined as
(vub(∞) − vlb(∞)). The figures show that the absolute error between the upper and
the lower bound is very small, meaning that the proposed method is very accurate.
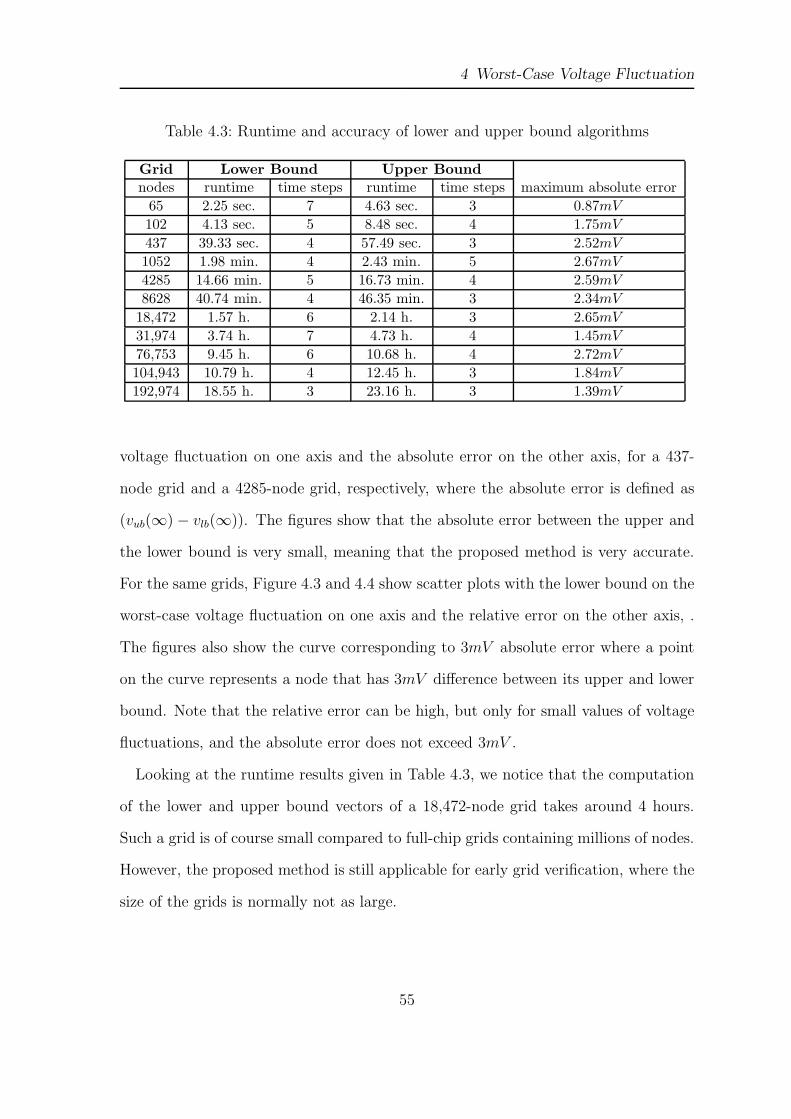
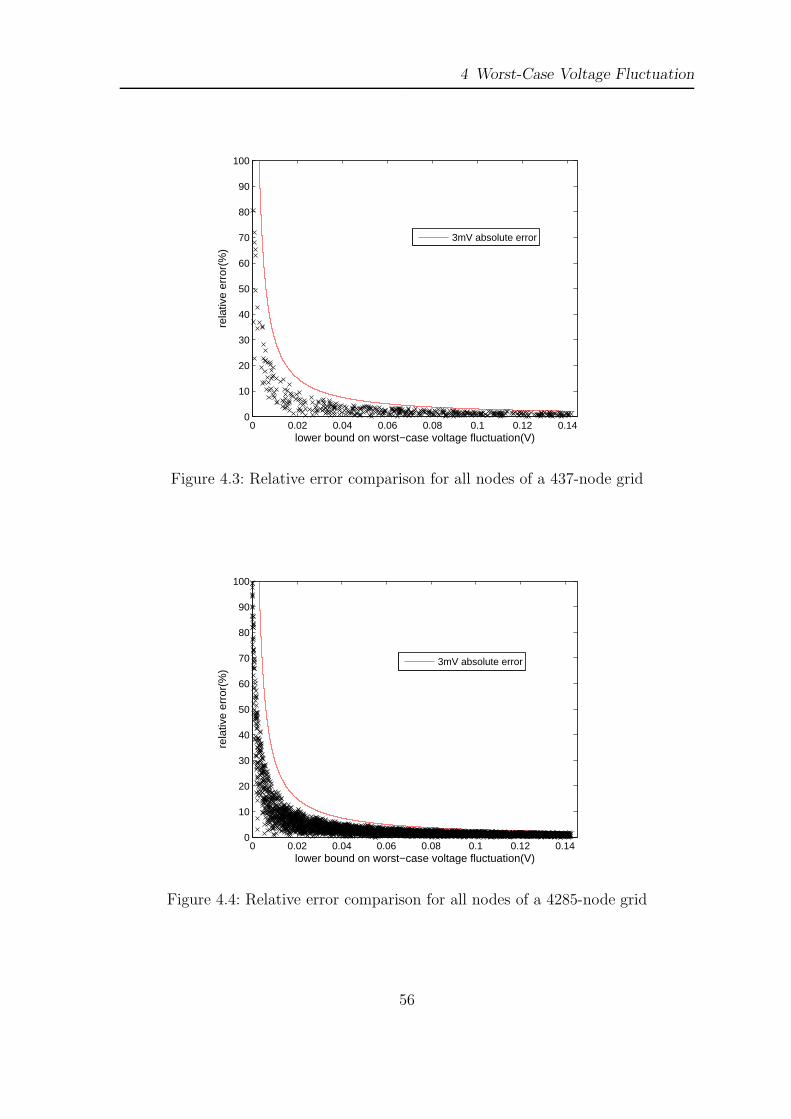
For the same grids, Figure 4.3 and 4.4 show scatter plots with the lower bound on the
worst-case voltage fluctuation on one axis and the relative error on the other axis, .
The figures also show the curve corresponding to 3mV absolute error where a point
on the curve represents a node that has 3mV difference between its upper and lower
bound. Note that the relative error can be high, but only for small values of voltage
fluctuations, and the absolute error does not exceed 3mV .
Looking at the runtime results given in Table 4.3, we notice that the computation
of the lower and upper bound vectors of a 18,472-node grid takes around 4 hours.
Such a grid is of course small compared to full-chip grids containing millions of nodes.
However, the proposed method is still applicable for early grid verification, where the
size of the grids is normally not as large.
55
4 Worst-Case Voltage Fluctuation
0 0.02 0.04 0.06 0.08 0.1 0.12 0.140
10
20
30
40
50
60
70
80
90
100
lower bound on worst−case voltage fluctuation(V)
rela
tive
erro
r(%
)
3mV absolute error
Figure 4.3: Relative error comparison for all nodes of a 437-node grid
0 0.02 0.04 0.06 0.08 0.1 0.12 0.140
10
20
30
40
50
60
70
80
90
100
lower bound on worst−case voltage fluctuation(V)
rela
tive
erro
r(%
)
3mV absolute error
Figure 4.4: Relative error comparison for all nodes of a 4285-node grid
56
5 Extensions to Single Grid Verification
5.1 Introduction
In this chapter, we will first show that the linear programs in single grid verification
can be efficiently solved, if we assume that the global constraint matrix U has no
overlapping constraints, i.e. each column of U has only one nonzero element. We will
start with a base case, in which we assume that there is only one global constraint,
and we will present the solution to the general problem based on this base case. Then,
we will present the optimal solution to our linear programs with tree-structured global
constraint matrices based on [39].
5.2 Solution for Non-overlapping Global Constraints
5.2.1 Base Case
Define x as a vector variable of size m representing the current sources, and f(x) :
Rm → R as a vector function of x. Assuming that we have only one global constraint
(and since we don’t have any equality constraints in the single grid model), we have
the following linear program:
57
5 Extensions to Single Grid Verification
maximize: f(x) = aT x
subject to: cT x ≤ b
0 ≤ x ≤ d
(5.1)
where a is a vector of size m that defines the coefficients in the objective function and
c is a vector of size m whose each entry is equal to 1. b is a positive number which is
the upper bound defining the global constraint and d is the local constraint vector of
size m. The linear program (5.1) resembles the fractional knapsack problem, except
the fact that the coefficients in the constraint matrix of a fractional knapsack problem
can be any nonnegative value [40]. Similar to the optimal solution of the fractional
knapsack problem, we will now show that the linear program (5.1) is solvable by a
greedy strategy.
Assume without loss of generality that:
a1 ≥ a2 ≥ . . . ≥ am ≥ 0 (5.2)
Thus a is sorted in a descending order and it consists of only nonnegative entries.
Assume that cT d > b, because otherwise x = d is optimal. Now let k be the index
satisfying:
k−1∑
i=1
di < b and
k∑
i=1
di ≥ b (5.3)
Define:
η = b −
k−1∑
i=1
di (5.4)
58
5 Extensions to Single Grid Verification
We first state the following theorem [41], which will be useful for the proof of claim 5.2.2:
Theorem 5.2.1. (Strong Duality) If x∗ is a feasible solution to the primal prob-
lem max{aT x | Ax ≤ b, x ≥ 0} and u∗ is a feasible solution to the dual problem
min{bT u | AT u ≥ a, u ≥ 0}, then x∗, u∗ are primal-dual optimal if and only if
aT x∗ = bT u∗.
Now define:
J =
cT
I
, ζ =
b
d
(5.5)
where I is an m×m identity matrix. Notice that J is an (m + 1)×m matrix, and ζ
is a vector of size m + 1. With the help of (5.5), we modify the linear program (5.1)
to be in the format of the primal problem in theorem 5.2.1 as:
maximize: f(x) = aT x
subject to: Jx ≤ ζ
x ≥ 0
(5.6)
Claim 5.2.2. The optimal solution to the linear program (5.6) is given by:
x∗i =
di i = 1, . . . , k − 1
η i = k
0 i = k + 1, . . . , m
(5.7)
Proof. The dual of the linear program (5.6) is given by:
59
5 Extensions to Single Grid Verification
minimize: ζTu
subject to: JT u ≥ a
u ≥ 0
(5.8)
Now define y = u1 and zi = ui+1 for i = 1, . . . , m. Then we can rewrite (5.8) as:
minimize: by + dTz
subject to: y + zi ≥ ai i = 1, . . . , m
y, z ≥ 0
(5.9)
Now choose the variables y∗ and z∗ as:
u∗1 = y∗ = ak (5.10)
u∗i+1 = z∗i =
ai − ak i = 1, . . . , k − 1
0 i = k, . . . , m(5.11)
Notice that the solution u∗ given by (5.10) and (5.11) is a feasible solution to the dual
problem (5.9) and that the solution x∗ given by (5.7) is a feasible solution to the primal
problem (5.6). If we can show that x∗ and u∗ satisfy the condition aT x∗ = ζTu∗, then
they are primal-dual optimal by theorem 5.2.1. Using x∗ given by (5.7), we write:
aT x∗ =k−1∑
i=1
aidi + akη =k−1∑
i=1
aidi + ak(b −k−1∑
i=1
di) = akb +k−1∑
i=1
aidi − ak
k−1∑
i=1
di (5.12)
Using u∗ given by (5.10) and (5.11), we write:
60
5 Extensions to Single Grid Verification
ζTu∗ = by∗ + dTz∗ = akb +
k−1∑
i=1
di(ai − ak) = akb +
k−1∑
i=1
aidi − ak
k−1∑
i=1
di (5.13)
Thus aT x∗ = ζTu∗ for x∗ given by (5.7) and for u∗ given by (5.10) and (5.11).
Therefore, they are primal-dual optimal by theorem 5.2.1. This completes the proof.
In (5.6), we assumed that the coefficients of the objective function are nonnegative.
However, the objective function can have negative coefficients under the RLC model
of the grid. Now we will show that the optimization variables that correspond to the
negative coefficients of the objective function in the linear program (5.6) will always
be equal to 0 in the optimal solution. We first state the following theorem [41]:
Theorem 5.2.3. (Complementary Slackness) If x∗ is a feasible solution to the
primal problem max{aT x | Ax ≤ b, x ≥ 0}, where A is an l × n matrix and u∗ is
a feasible solution to the dual problem min{bT u | AT u ≥ a, u ≥ 0}, then x∗, u∗ are
primal-dual optimal if and only if the following hold:
(a) For i = 1, 2, . . . , l, if u∗i > 0, then A[i,:]x
∗ = bi
(b) For j = 1, 2, . . . , m, if x∗j > 0, then (u∗)T A[:,j] = aj
where A[i,:] corresponds to ith row of A, and A[:,j] corresponds to jth column of A.
Now assume without loss of generality that:
a1 ≥ a2 ≥ . . . ≥ am (5.14)
Let h be the index satisfying:
ah ≥ 0 and ah+1 < 0 (5.15)
61
5 Extensions to Single Grid Verification
Claim 5.2.4. The entries x∗h+1, . . . , x
∗m of the optimal solution x∗ to the linear pro-
gram (5.6) are equal to 0.
Proof. Assume that the optimal solution to the dual problem (5.9) is given by u∗.
Applying the condition (b) of theorem 5.2.3 to (5.6), we have:
For j = 1, 2, . . . , m, if x∗j > 0, then u∗
1 + u∗j = aj
Since aj is negative for j > h and since u ≥ 0, meaning u∗1 +u∗
j ≥ 0, we conclude that
x∗j 6> 0 for j > h, leading to x∗
j = 0 for j > h. This completes the proof.
Thus the optimization variables that have negative coefficients in the objective func-
tion can be simply ignored.
5.2.2 General Case
Let us have a look into the general problem in which we have more than one global
constraint that are not overlapping. Suppose that there are p non-overlapping global
constraints. Denote the variables belonging to ith global constraint by x(i), their
part of the objective function by fi(x(i)) and their feasible space due to ith global
constraint and local constraints of x(i) by Fi. It is shown in [42] that if the variables
x(i) do not appear in common constraints, they are independent and the optimal
value can be obtained by simply solving p independent subproblems and summing
the results of each p subproblem. Define:
ei = max∀x(i)∈Fi
fi(x(i)) (5.16)
where ei is the optimal solution to ith global constraint. The optimal solution e of
the maximization problem due to p non-overlapping global constraints can be written
62
5 Extensions to Single Grid Verification
Problem Proposed Method
size runtime
483 0.01 sec.
1139 0.01 sec.
5392 0.02 sec.
10536 0.05 sec.
26943 0.23 sec.
53329 0.56 sec.
Table 5.1: Effectiveness of the method given in claim 5.2.2
as the sum of the optimal solutions due to p independent maximization problems as
follows:
e = max∀x∈F
f(x) = e1 + e2 + . . . + ep (5.17)
Notice that the optimal solution to each subproblem in (5.17) is given by (5.7). Since
every minimization problem can be converted into a maximization problem by simply
negating the coefficients in the objective function, (5.17) is valid for minimization
problems as well.
5.2.3 Experimental Results
To see the runtime behavior of the method given in claim 5.2.2, we have conducted
several experiments to solve linear programs resulting from single grid verification. To
sort the coefficients of the objective function, we have used Quicksort algorithm [43].
The computations were performed on a 64-bit Linux machine with 8 GB memory.
The results of the experiments are presented in Table 5.1. Column 1 shows the size
of the optimization problem and column 2 reports the runtime to solve the problem
using the method given in claim 5.2.2. It can be seen from Table 5.1 that the proposed
method is significantly fast, solving the large linear programs in less than a second.
63
5 Extensions to Single Grid Verification
5.3 Solution for Tree-structured Global Constraints
In [39], the authors solve a simple class of linear programs with tree-structured con-
straint matrices. The special linear programming structure is in the following form:
maximize:∑
j∈J
cjxj
subject to:∑
j∈J(i)
ajxj ≤ bi, i = 1, . . . , m
0 ≤ xj ≤ uj, j ∈ J
(5.18)
where bi, cj and aj are positive scalars, J = ∪mi=1J(i), and the sets J(i) are nested
meaning that if i 6= k, either J(i) and J(k) are disjoint, or one set is properly contained
in the other. We may assume that bi < bk, whenever J(i) is a proper subset of J(k).
When m = 1, (5.18) reduces to the fractional knapsack problem with upper bounds
on variables.
In each column of the constraint matrix, all nonzero entries are equal and positive.
This is also the case for the tree-structured linear programs in our formulation, be-
cause all nonzero entries in the global constraint matrix are 1s. The only difference
between (5.18) and the linear programs in our formulation is the lower bound for the
global constraints. However, it is shown in [44] that the results obtained in [39] are
valid for linear programs with nonnegative lower bounds for the constraint matrices.
The solution method shown in [39] separates the problem into a sequence of frac-
tional knapsack problems. Each of these fractional knapsack problems require linear
time to solve, for total solution time no worse than proportional to the number of
nonzero entries in the original constraint matrix. The optimal solution is obtained
by giving each variable their minimum value from the list obtained by solving the
sequence of fractional knapsack problems.
64
6 Future Work and Conclusion
With technology scaling, the decrease in the transistor feature size has led to the
decrease of the supply voltage. As a result, the functionality of modern ICs is becom-
ing increasingly sensitive to voltage fluctuations of the power distribution network.
Significant voltage fluctuation can cause soft errors, can lead to electromigration, and
as a result, can degrade the circuit performance. Therefore, the power distribution
network verification has become an important part of the design process.
The main difficulty in power distribution network verification is that the number
of possible input vectors is very large. Since one needs to simulate the grid for a large
number of vector sequences at each node, grid simulation is clearly not practical.
Another drawback of the grid simulation is that it does not allow the designer to
verify the grid before the complete circuit has been designed. For these reasons, we
adopt the notion of current constraints to capture the uncertainty about the circuit
behavior and currents. These constraints define upper bounds on the currents drawn
by the underlying transistor circuitry, as well as upper bounds on the sum of currents.
In this thesis, we take both power and ground grids into account. We first formulate
the grid verification problem as an optimization problem to compute the exact worst-
case voltage fluctuations at each node subject to current constraints, which is seen to
be too expensive. As an alternative, we propose a solution approach that formulates
both upper and lower bounds on the worst-case voltage fluctuations. Experimental
results show that the proposed method has errors in the range of a few mV . The
65
6 Future Work and Conclusion
power of our approach is that it finds tight upper and lower bounds on the worst-case
voltage fluctuations under all feasible current combinations. It is a unique approach
that offers this type of guarantee.
We also present extensions to the single grid verification to reduce the complexity
of the problem. These extensions are only applicable to the linear programs in the
single grid verification, because of the additional equality constraints in the dual grid
verification problem. Therefore further research is needed to extend the results for
the dual grid.
The grid model presented in this work is an RC model of the grid. Since the signal
and clock frequencies are increasing, the grid inductance contributes significantly to
the voltage fluctuation. The future work on the dual grid verification should take
the inductive effects into account. Besides, the current constraints used in this work
are DC constraints. The dual grid verification problem should also be extended and
solved under transient current constraints.
66
Appendices
67
A Matrix Equalities
In this chapter, we will prove additional claims that are useful in the context of
section 4.3.1. We start with the following claim:
Claim A.0.1. I − Dp is invertible for any integer p.
Proof. From (4.59), we know that ρ(Dp) < 1, for an integer p. We also know that
the series∑∞
q=0 Xq for a square matrix X is known to converge [25] if and only if
ρ(X) < 1, under which condition the series limit is (I − X)−1, meaning that I − Dp
is invertible for an integer p. This completes the proof.
With the help of claim A.0.1, we will prove the following claim:
Claim A.0.2. Suppose W (p) is a function of p for p ≥ 1 defined as:
W (p) = (I − Dp)−1
p−1∑
k=0
DkH (A.1)
Then W (p) = W (1), ∀p ≥ 1.
Proof. The case for p = 1 is satisfied trivially. The claim is true by induction if we
prove the following, ∀p ≥ 2:
W (p − 1) = W (1) ⇒ W (p) = W (1) (A.2)
Left multiplying both sides of (A.1) with (I −Dp), and breaking the sum∑p−1
k=0 DkH
into∑p−2
k=0 DkH and Dp−1H , we obtain:
68
A Matrix Equalities
(I − Dp)W (p) =
p−2∑
k=0
DkH + Dp−1H (A.3)
From claim A.0.1, we know that I−Dp is invertible for an integer p. Left multiplying
both sides of (A.3) with (I − Dp−1)−1, we get:
(I − Dp−1)−1(I − Dp)W (p) = (I − Dp−1)−1
p−2∑
k=0
DkH + (I − Dp−1)−1Dp−1H (A.4)
Since (I−Dp−1)−1∑p−2
k=0 DkH = W (p−1), we can replace it with W (1). Rearranging
the terms of (A.4), we have:
(I − Dp−1)−1((I − Dp)W (p) − Dp−1H
)= W (1) (A.5)
Left multiplying both sides of (A.5) with (I − Dp−1) leads to:
W (p) − DpW (p) − Dp−1 = W (1) − Dp−1W (1) (A.6)
Adding Dp−1W (1) to both sides of (A.6) and rearranging the terms, we obtain:
W (p) − W (1) = (I − Dp)−1Dp−1(H − (I − D)W (1)) (A.7)
Replacing W (1) on the left-hand side of (A.7) with (I − D)−1H leads to:
W (p) − W (1) = (I − Dp)−1Dp−1(H − H) = 0 (A.8)
Meaning that W (p) = W (1). This completes the proof.
Finally, our main result is captured in the following claim:
69
A Matrix Equalities
Claim A.0.3. For any integer p ≥ 1,
DpK = K −
p−1∑
k=0
DkH (A.9)
Proof. Since W (p) = W (1) by A.0.2, meaning that:
(I − Dp)−1
p−1∑
k=0
DkH = (I − D)−1H (A.10)
Left multiplying both sides of (A.10) with (I − Dp), we obtain:
p−1∑
k=0
DkH = (I − Dp)(I − D)−1H (A.11)
Since D = A−1B and B = A −G, we have D = A−1(A −G) = I − A−1G, leading to
I − D = A−1G. Since K and H are the matrices obtained as the first m columns of
G−1 and A−1, respectively, we can write K = (I − D)−1H , leading to:
p−1∑
k=0
DkH = (I − Dp)K (A.12)
Rearranging the terms of (A.12), we get:
K = (I − Dp)−1
p−1∑
k=0
DkH (A.13)
which completes the proof.
70
References
[1] M. Popovich, A. V. Mezhiba, and E. G. Friedman. Power distribution networkswith on-chip decoupling capacitors. Springer, New York, USA, 2008.
[2] Semiconductor Industry Association. International technology roadmap for semi-conductors, 2001.
[3] T. Chen and C. C. Chen. Efficient large-scale power grid analysis based onpreconditioned Krylov-subspace iterative methods. In ACM/IEEE Design Au-tomation Conference (DAC’01), pages 559–562, Las Vegas, NV, June 18-22 2001.
[4] M. Zhao, R. V. Panda, S. S. Sapatnekar, T. Edwards, R. Chaudhry, andD. Blaauw. Hierarchical analysis of power distribution networks. In ACM/IEEEDesign Automation Conference (DAC’00), pages 150–155, Los Angeles, CA, June5-9 2000.
[5] H. Qian and S. S. Sapatnekar. Random walks in a supply network. In ACM/IEEEDesign Automation Conference (DAC’05), pages 93–98, Anaheim, CA, June 2-62003.
[6] Semiconductor Industry Association. International technology roadmap for semi-conductors, 2009.
[7] D. Kouroussis and F. N. Najm. A static pattern-independent technique for powergrid voltage integrity verification. In ACM/IEEE Design Automation Conference(DAC’03), pages 99–104, Anaheim, CA, June 2-6 2003.
[8] M. Nizam, F. N. Najm, and A. Devgan. Power grid voltage integrity verification.In ACM/IEEE International Symposium on Low Power Electronics and Design(ISLPED’05), pages 239–244, San Diego, CA, August 8-10 2005.
[9] N. H. Abdul Ghani and F. N. Najm. Handling inductance in early power gridverification. In IEEE/ACM International Conference on Computer-Aided Design(ICCAD’06), pages 127–134, San Jose, CA, November 5-9 2006.
[10] M. Benoit, S. Taylor, D. Overhauser, and S. Rochel. Power distribution in high-performance design. In ACM/IEEE International Symposium on Low PowerElectronics and Design (ISLPED’98), pages 274–278, Monterey, CA, August 10-12 1998.
[11] L. C. Tsai. A 1 GHz PA-RISC processor. In IEEE International Solid-StateCircuits Conference, pages 322–323, San Francisco, CA, February 4-8 2001.
71
6 References
[12] C. J. Anderson, J. Petrovick, J. M. Keaty, J. Warnock, G. Nussbaum, J. M.Tendier, C. Carter, S. Chu, J. Clabes, and J. DiLullo. Physical design of afourth-generation POWER GHz microprocessor. In IEEE International Solid-State Circuits Conference, pages 232–233, San Francisco, CA, February 4-8 2001.
[13] C. Ho, A. E. Ruehli, and P. A. Brennan. The modified nodal approach to networkanalysis. IEEE Transactions on Circuits and Systems, 22(6):504–509, June 1975.
[14] J. N. Kozhaya, S. R. Nassif, and F. N. Najm. A multigrid-like technique for powergrid analysis. IEEE Transactions on Computer-Aided Design, 21(10):1148–1160,October 2002.
[15] Z. Zhu, B. Yao, and C. Cheng. Power network analysis using an adaptivealgebraic multigrid approach. In IEEE/ACM Design Automation Conference(DAC’03), pages 105–108, Anaheim, CA, June 2-6 2003.
[16] K. Wang and M. Marek-Sadowska. On-chip power supply network optimizationusing multigrid-based technique. In IEEE/ACM Design Automation Conference(DAC’03), pages 113–118, Anaheim, CA, June 2-6 2003.
[17] H. Su, E. Acar, and S. R. Nassif. Power grid reduction based on algebraicmultigrid principles. In IEEE/ACM Design Automation Conference (DAC’03),pages 109–112, Anaheim, CA, June 2-6 2003.
[18] S. R. Nassif and J. N. Kozhaya. Fast power grid simulation. In ACM/IEEE De-sign Automation Conference (DAC’00), pages 156–161, Los Angeles, CA, August2-4 2000.
[19] D. Kouroussis, I. A. Ferzli, and F. N. Najm. Incremental partitioning-basedvectorless power grid verification. In IEEE/ACM International Conference onComputer-Aided Design (ICCAD’05), pages 358–364, San Jose, CA, November6-10 2005.
[20] I. A. Ferzli, F. N. Najm, and L. Kruse. A geometric approach for early power gridverification using current constraints. In ACM/IEEE International Conferenceon Computer-Aided Design (ICCAD’07), pages 40–47, San Jose, CA, November5-8 2007.
[21] N. H. Abdul Ghani and F. N. Najm. Fast vectorless power grid verificationusing an approximate inverse technique. In ACM/IEEE Design AutomationConference (DAC’09), pages 184–189, San Francisco, CA, July 26-31 2009.
[22] M. Avci and F. N. Najm. Early p/g grid voltage integrity verification. InIEEE/ACM International Conference on Computer-Aided Design (ICCAD’10),San Jose, CA, November 7-11 2010.
[23] F. N. Najm. Circuit simulation. John Wiley & Sons, Hoboken, NJ, 2010.
72
6 References
[24] J. D. Lambert. Numerical methods for ordinary differential systems: the initialvalue problem. Jon Wiley & Sons Ltd., Chichester, UK, 1991.
[25] Y. Saad. Iterative methods for sparse linear systems. SIAM, Philadelphia, PA,2003.
[26] N. J. Higham. Accuracy and stability of numerical algorithms. SIAM, Philadel-phia, PA, 1996.
[27] N. H. Abdul Ghani and F. N. Najm. Fast vectorless power grid verification underan RLC model. Submitted to. IEEE Transactions on Computer-Aided Design ofIntegrated Circuits and Systems.
[28] S. Lang. Algebra. Addison-Wesley, Menlo Park, CA, 1993.
[29] S. Demko, W. F. Moss, and P. W. Smith. Decay rates for inverses of bandmatrices. Mathematics of Computation, 43(168):491–499, October 1984.
[30] M. J. Grote and T. Huckle. Parallel preconditioning with sparse approximateinverses. SIAM Journal on Scientific Computing, 18(3):838–853, May 1997.
[31] M. Benzi, C. D. Meyer, and M. Tuma. A sparse approximate inverse precondi-tioner for the conjugate gradient method. SIAM Journal on Scientific Comput-ing, 17(5):1135–1149, September 1996.
[32] G. H. Golub and C. F. Van Loan. Matrix computations (3rd ed.). Johns HopkinsUniversity Press, Baltimore, MD, 1996.
[33] J. Zhang. A sparse approximate inverse preconditioner for parallel precon-ditioning of general sparse matrices. Applied Mathematics and Computation,130(11):63–85, July 2002.
[34] M. Benzi and M. Tuma. A comparative study of sparse approximate inversepreconditioners. Applied Numerical Mathematics, 30(2-3):305–340, June 1999.
[35] R. K. Ahuja, T. L. Magnanti, and J. B. Orlin. Network flows: theory, algorithmsand applications. Prentice Hall, Englewood Cliffs, New Jersey, 1993.
[36] G. Sierksma. Linear and integer programming: theory and practice. MarcelDekker, New York, NY, 2001.
[37] A. Frangioni and A. Manca. A computational study of cost reoptimization formin-cost flow problems. INFORMS Journal on Computing, 18(1):61–70, 2003.
[38] Mosek: http://www.mosek.com.
[39] B. Faaland. A weighted selection algorithm for certain tree-structured linearprograms. Operations Research Journal, 32(2):405–422, March-April 1984.
73
6 References
[40] T. H. Cormen, C. E. Leiserson, R. L. Rivest, and C. Stein. Introduction ToAlgorithms. The MIT Press, Cambridge, MA, 2nd edition, 2001.
[41] R. K. Martin. Large scale linear and integer optimization: a unified approach.Kluwer Academic Publishers, Boston, MA, 1998.
[42] S. P. Bradley, A. C. Hax, and T. L. Magnanti. Applied Mathematical Program-ming. Addison-Wesley, Menlo Park, CA, 1977.
[43] C. A. R. Hoare. Quicksort. The Computer Journal, 5(1):10–16, 1962.
[44] S. S. Erenguc. An algorithm for solving a structured class of linear programmingproblems. Operations Research Letters, 4(6):293–299, April 1986.























































































![The Albanian Question - Mehmet Konitza [Mehmet Konica] (1818)](https://static.documents.pub/doc/80x56/55284d4f5503467f588b4727/the-albanian-question-mehmet-konitza-mehmet-konica-1818.jpg)









