17
CAP6938 Neuroevolution and Developmental Encoding Neural Network Weight Optimization Dr. Kenneth Stanley September 6, 2006
| Date post: | 01-Jan-2016 |
| Category: |
Documents |
| Upload: | kennedy-ramos |
| View: | 42 times |
| Download: | 3 times |

CAP6938Neuroevolution and
Developmental Encoding
Neural Network Weight Optimization
Dr. Kenneth Stanley
September 6, 2006

Review
• Remember, the values of the weights and the topology determine the functionality
• Given a topology, how are weights optimized?• Weights are just parameters on a structure
? ??
??
??
??
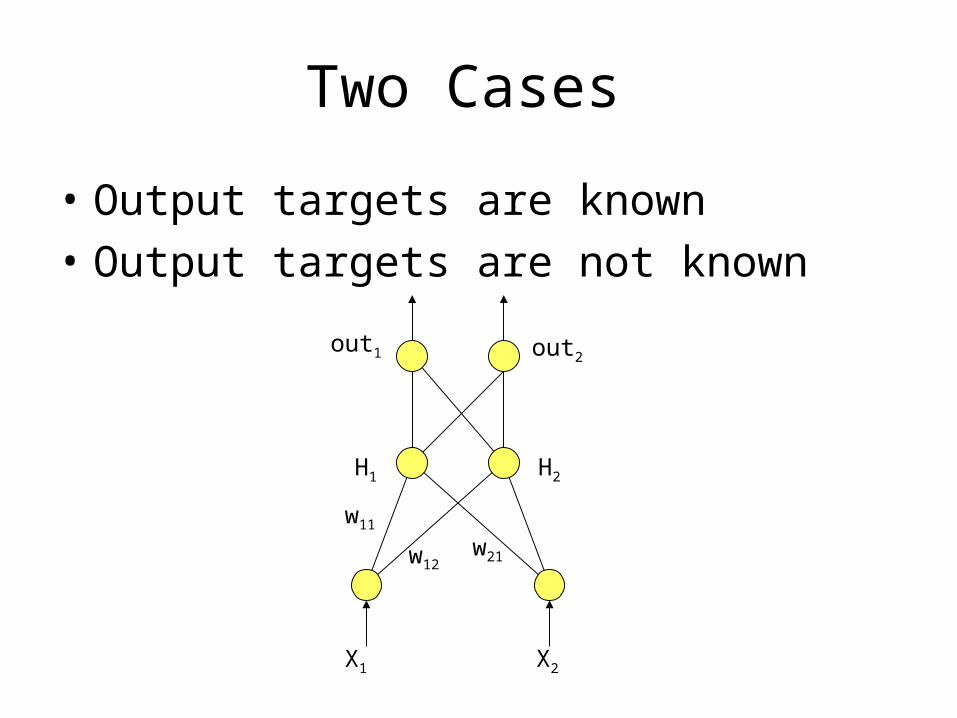
Two Cases
• Output targets are known
• Output targets are not known
X1 X2
H1 H2
out1 out2
w11
w21w12
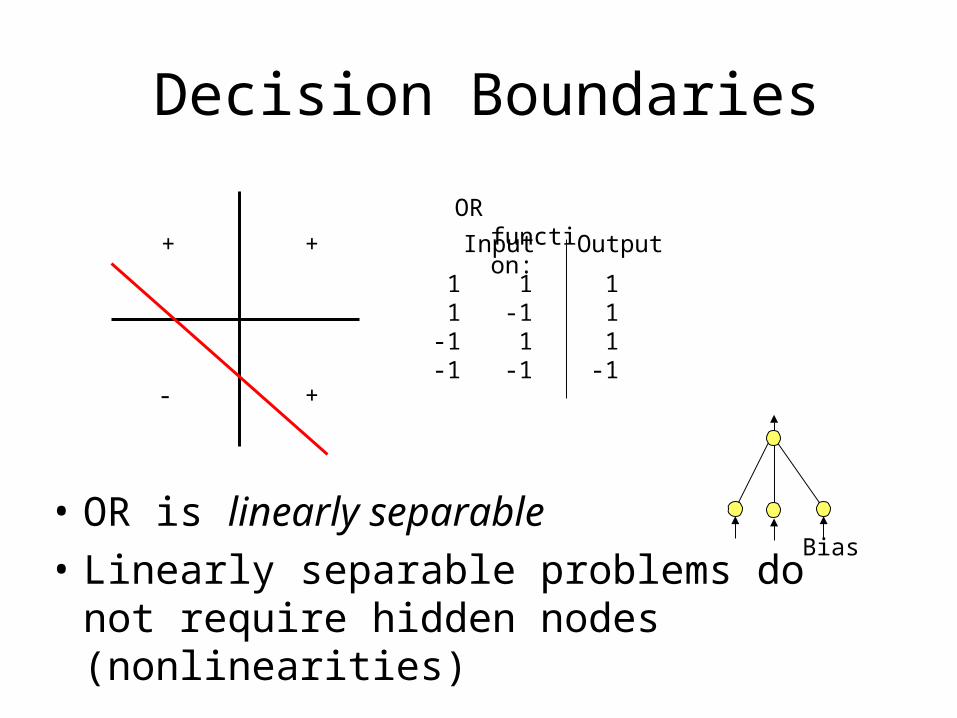
Decision Boundaries
++
- +
OR function:
1 1 1 1 -1 1 -1 1 1-1 -1 -1
Input Output
• OR is linearly separable
• Linearly separable problems do not require hidden nodes (nonlinearities)
Bias

Decision Boundaries
• XOR is not linearly separable
• Requires at least one hidden node
-+
- +
XOR function:
1 1 -1 1 -1 1 -1 1 1-1 -1 -1
Input Output
Bias

Hebbian Learning
• Change weights based on correlation of connected neurons
• Learning rules are local• Simple Hebb Rule: • Works best when relevance of inputs to
outputs is independent• Simple Hebb Rule grows weights unbounded• Can be made incremental:
yxww iii )old(new)(
yxw ii

More Complex Local Learning Rules
• Hebbian Learning with a maximum magnitude:– Excitatory: – Inhibitory:
• Second terms are decay terms: forgetting– Happens when presynaptic node does not affect
postsynaptic node
• Other rules are possible• Videos: watch the connections change
)01 21 . Wx(yη(W-w)xyw )0.1( 21 y(W-w)x(W-w)xyw
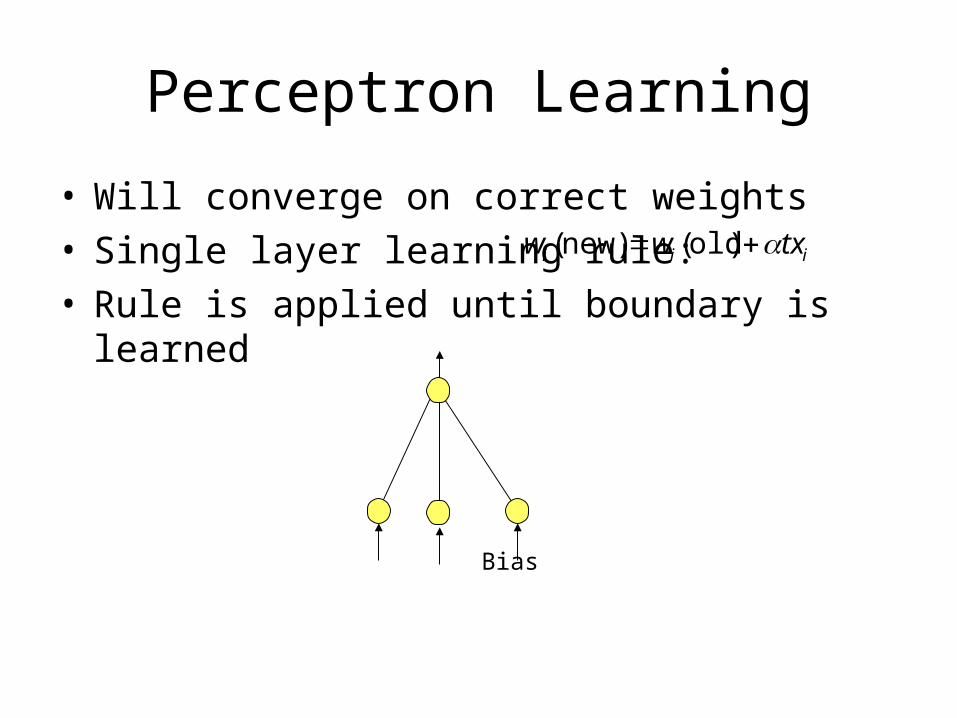
Perceptron Learning
• Will converge on correct weights• Single layer learning rule:• Rule is applied until boundary is learned
Bias
iii txww )old(new)(
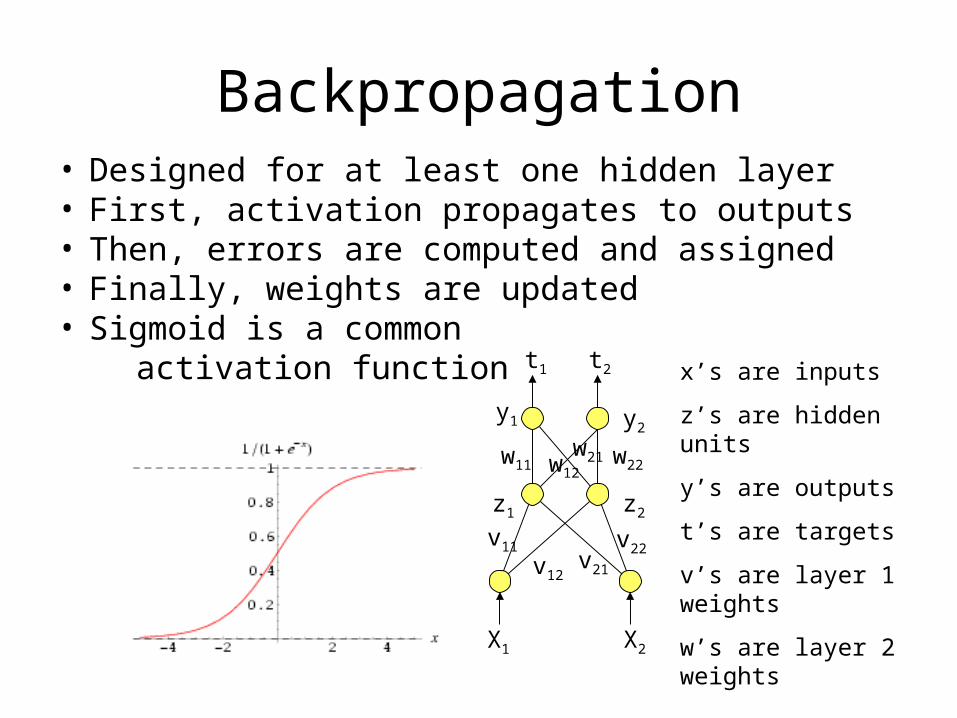
Backpropagation• Designed for at least one hidden layer• First, activation propagates to outputs• Then, errors are computed and assigned• Finally, weights are updated• Sigmoid is a common activation function
X1 X2
z1 z2
y1 y2
v11v21v12
v22
w11w21w12
w22
t1 t2 x’s are inputs
z’s are hidden units
y’s are outputs
t’s are targets
v’s are layer 1 weights
w’s are layer 2 weights

Backpropagation Algorithm
1) Initialize weights
2) While stopping condition is false, for each training pair1) Compute outputs by forward activation
2) Backpropagate error:1) For each output unit, error
2) Weight correction
3) Send error back to hidden units
4) Calculate error contribution for each hidden unit:
5) Weight correction
3) Adjust weights by adding weight corrections
)()( kkkk yinfyt (target minus output times slope)
jkjk zw (Learning rate times error times hidden output)
)(1
j
m
kjkkj zinfw
ijij xv

Example Applications
• Anything with a set of examples and known targets
• XOR
• Character recognition
• NETtalk: reading English aloud
• Failure predicition
• Disadvantages: trapped in local optima

Output Targets Often Not Available
(Stone, Sutton, and Kuhlmann 2005)

One Approach: Value Function Reinforcement Learning
• Divide the world into states and actions
• Assign values to states
• Gradually learn the most promising states and actions
Start
Goal0 0 0 0 0 0 0 1
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0

Learning to Navigate
Start
Goal0 0 0 0 0 0 0 1
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0Start
Goal0 0 0 0 0 0 0 1
0 0 0 0 0 0 0 0.5
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
Start
Goal0 0 0 0 0 0 0 1
0 0 0 0 0 0 0 1
0 0 0 0 0 0 0 1
0 0 0 0 0 0 0 1
0 0 0 0 0 0 0 1
0 0 0 0 0 0 0.9 1Start
Goal0 0 0 0 0 0 0 1
0 0 0 0 0 0 0 1
0 0 0 0 0 0 0 1
0 0 0 0 0 0 0 1
0 0 0 0 0 0 0 1
1 1 1 1 1 1 1 1
T=1 T=56
T=350 T=703

How to Update State/Action Values
• Q learning rule:
• Exploration increases Q-values’ accuracy• The best actions to take in different states
become known• Works only in Markovian domains
),(),(),( allactionsnextstateQMaxactionstateRactionstateQ

Backprop In RL
• The state/action table can be estimated by a neural network
• The target learned by the network is the Q-value:
NNAction State_description
Value

Next Week: Evolutionary Computation
For 9/11: Mitchell ch.1 (pp. 1-31) and ch.2 (pp. 35-80) Note Section 2.3 is "Evolving Neural Networks"
• EC does not require targets
• EC can be a kind of RL
• EC is policy search
• EC is more than RL

















