Indian Journal of Chemi stry Vo l. 45A, January 2006, pp. 77-92 Carbohydrate-based drug design: Recognition fingerprints and their use in lead identification J Rajan Prabu", Vetri se lvi Rangannan h & Nagasuilla Chandra'" '" "Mo lecular Biophysics Unit and hB ioinformaties Ccntre & Supercomp ut er Education and Rese:lrch Centre, Indian Institute of Science. Bangalore 560 012. India Email : nchandra @s erc.ii sc .ern et.in Receil'ed 3 Decel/lber 2004; revised / 7 Novell/ber 2005 Carbohydrate-based therapeutics is a rapi dl y developing theme. resulting directly from th e rece nt increase in interest in th e biological ro les of carbohydrates. A fundamental requirement for succcssfu l drug design is a dctailed understanding of protein-carbohydrate interaction s. Thi s article reports a st ru ctural bioinformatics st ud y of several carbohydrate binding pro- teins to identify com mon minimum principles requir ed for th e recognition of mannose. gluco se and ga lactose. whic h ind eed form much o r th e basis for recognition of hi gher sugars. The st ud y identities all aspartic acid - 04 sugar hydroxyl inte ra ction to be hi ghl y conserve d, whi ch appears to be cr uci al for recognition of a ll three sugars. Other int eractions are specific to par- ticular sugars. leading to indi vi dual fin gerprints. These fingerprints ha ve th en been used in the id entifica ti on of lead com- pounds. us ing fragment-based design approaches. The results obtai ned by such gu id ed des ign protocols are found to be more focused than tho se obtained from comparable aiJ-illilio design protocols. These studies. apart from providing c lu es about the usable pharl1l acophore space for th ese structures. al so PI"OVC that the use of fin gerprints in a fra gment-based li ga nd des ign. leads to th e design of a sugar-like li gand. mimicking th e nJtural carbohydl"ate li ga nd in each of th e eight examples studied. Carbohydrates occupy a s ignificant place in th e st udy of biological s ystems and th ei r multiple and crucial roles in various cellular events, both in health and in di sease , are now well recognized 1 -3 . For example, car- bohydrates located on the cell surfaces serve as re- cepto rs to bind with bacteria, viruses, toxin s, and ho rmone s. The first ste ps of adhesion in the initiation of infections are the refore often mediated through carbohydrate-lectin interactions 4 - 6 . Understandably, a direct application of such knowledge has been of in - terest in the development of carbohydrate-based drug s, targeted to inte ract with various carbohydrate binding protein s 7 A review of current literature indi- cates the use of severa l carbohydrate-based drug s for treating many diseases such as bacterial infec ti o ns, gastric ulcers. ep ilepsy and many more being actively re sea rched for cancer , diabetes and AIDSs -ll . How - ever, the mechani sm of action especiall y at the str uc- tural level remain s poorly under stood in most cas es, even when th ey are being use d ro utinely in clinical practice 7 A c1 etailed understandi ng of cell-surface ca rbohydrate -lectin interactions is required for fo- cu se d. rational drug design of carbohy drat e-based therapeutics to de velop. Crystal structures of a number of protein-carbo- hydrate complexes , many of which are plant lectins. have been det e rmined in the pa st two decades l2 . U It is of great interest to understand the se quence and strLI C- tural features responsible for generating sugar reco g- nition capa bility in different protein molecules. Avail- ability of a large numb er of structures makes it feasible to carry out a bioinfonnatics analysis to understand the recogniti on principles and to identify any patterns that may be pre se nt in the binding sites of various proteins that may define such recognition. This paper de scri be s the study of recognition of three common sugars viz., man nose, glucose and ga lactose, which are often found on various cell surfaces. Although there has been tremendous progress in the development of algorithms to address various as- pect s of structure-based drug design in the recent years 1 4, there is still a nee d for improvement in meth- odology. For example, methods developed for frag- ment-b ased ligand design methods to bind at a given protein binding site lS has e nabled ab-initio ligand d e- sign, but do not hav e th e intrinsic ability to pick out and su itably weight the crucial interactions . As a re- sult, li gands designed with this approach do not al- ways exhibit the intended phamlacological profiles. Herein. we describe the use of reco gnitio n finger- prints deriv ed in thi s study. to ca rry OUL gu id ed frag- ment-ba se d design or lea d c ompound s targeted at the binding sites of chosen examp les of man nose . galac- tose and glucose bindin g proteins. Results obtai ned from this approach hav e been show n to be superior to tho se fr om s tandard ah-illitio design protocols.
Transcript
Indian Journal of Chemi stry Vol. 45A, January 2006, pp. 77-92
Carbohydrate-based drug design: Recognition fingerprints and their use in lead identification
J Rajan Prabu", Vetri se lvi Rangannan h & Nagasuilla Chandra'" '"
"Mo lecular Biophysics Unit and hB ioinformaties Ccntre & Supercomputer Education and Rese:lrch Centre, Indian Institute of Science. Bangalore 560 012. India
Carbohydrate-based therapeutics is a rapi dl y developing theme. resulting direct ly from the rece nt increase in interest in the biological ro les of carbohydrates. A fundamental requirement for succcssfu l drug design is a dctailed understanding of protein-carbohydrate interactions. Thi s article reports a st ructural bioinformatics study of several carbohydrate binding proteins to identify com mon minimum princ iples required for the recognition of mannose. glucose and ga lactose. which indeed form much or the basis for recognition of higher sugars. The study identities all aspartic acid - 04 sugar hydroxyl interaction to be hi ghl y conserved, whi ch appears to be cruci al for recognition of all three sugars. Other interaction s are specific to particular sugars. leading to indi vidual fingerprints. These fingerprints ha ve then been used in the identificati on of lead compounds. using fragment-based design approaches. The results obtai ned by such gu ided design protocols are found to be more focused than those obtained from comparable aiJ-illilio design protocols. These studies. apart from providing clues about the usable pharl1lacophore space for these structures. al so PI"OVC that the use of fin gerprints in a fragment-based liga nd des ign. leads to the design of a sugar-like li gand. mimicking the nJtural carbohydl"ate li ga nd in each of the eight examples studi ed.
Carbohydrates occupy a significant place in the study of biological systems and thei r multiple and crucial roles in various cellular events, both in health and in di sease, are now well recognized 1-3 . For example, carbohydrates located on the cell surfaces serve as receptors to bind with bacteria, viruses, toxins, and hormones. The first steps of adhesion in the initiation of infections are therefore often mediated through carbohydrate-lectin interactions4
-6
. Understandably, a direct application of such knowledge has been of interest in the development of carbohydrate-based drugs, targeted to interact with various carbohydrate binding proteins7 A review of current literature indicates the use of several carbohydrate-based drugs for treating many diseases such as bacterial infec tio ns, gas tric ulcers. ep ilepsy and many more being actively researched for cancer, diabetes and AIDSs-ll . However, the mechani sm of action especially at the structural level remain s poorly understood in most cases, even when th ey are being used routinely in clinical practice 7 A c1 eta i led understandi ng of cell-surface carbohydrate- lectin interactions is required for focused. rational drug design of carbohydrate-based therapeutics to deve lop.
C rysta l structures of a number of protein-carbohydrate complexes, many of which are plant lec tin s. have been dete rmined in the past two decades l2. U It is of great interes t to understand the sequence and strLIC-
tural features responsible for generating sugar recognition capability in different protein molecules. Availability of a large number of structures makes it feasible to carry out a bioinfonnatics analysis to understand the recogniti on principles and to identify any patterns that may be present in the binding sites of various proteins that may define such recognition. This paper describes the study of recognition of three common sugars viz., man nose, glucose and galactose, which are often found on various cell surfaces.
Although there has been tremendous progress in the development of algorithms to address various aspects of structure-based drug design in the recent years 14, there is still a need for improvement in methodology. For example, methods developed for fragment-based ligand des ign methods to bind at a given protein binding site lS has enabled ab-initio ligand des ign , but do not have the intrinsic ability to pick out and su itably weight the c rucial interactions . As a result, li gands designed with this approach do not always exhibit the intended phamlacological profiles. Herein . we describe the use of recognition fingerprints derived in thi s study. to carry OUL gu ided fragment-based design or lead compounds targeted at the binding s ites of chosen examp les of man nose. galactose and glucose binding pro teins. Res ults obtai ned from this approach have been show n to be supe rior to those from standard ah-illitio design protocols.
78 lNDlAN J CHEM. SEC A. JANUARY 2006
Methodology
Dataset prepanltion
Proteins, which are bound to man nose, galactose and glucose, were derived from the Protein Databank by parsing the HETATM cards using the known three-letter codes (MAN, MMA, GAL, AMG, MGA, GLC, MGL) for each of the three sugars. Redundancy was removed from the first lists thu s prepared, by iterations of all vs. all Blastp lO searches within the first lists and parsing the Blast outputs, so as to eliminate the lower resolution entries that exhibit s imilarity greater than 95 %, for a length of at least 90% (as judged by the Blosum62 substitution matrix) to that of the query sequence in every pair. This was done to ensure that, in the fin , ~ dataset no two sequences were greater than 95 % similar to each other. From the nonredundant lists obtained for each sugar, entries containing covalently bound sugars were removed by manual inspection of the atom connectivities within the sugars . The remaining entries containing only non-covalently bound sugars were further classified into those containing monosaccharides, disaccharides and higher oligosaccharides. From these, three further lists were prepared that contained entries bound to monosachharides and used for further analysis . To these lists, entries containing di saccharides were added, if conesponding close homologues containing monosaccharides were not available, to obtain the final datasets in all the three cases. Appropriate perl scripts and C-programs were written for variou s needs of file handling and extracting required information as well as for appropriate representation.
Fingerprint derivation
Insight-II software suite (Accelrys Inc., http ://www.accelrys .com) was used to visualize, overlay and analyse various structures. Binding site subsets were prepared to obtain spheres of 6 A around all sugar atoms in each structure from the final datasets and protein-sugar interactions were th en computed within these subsets, using the LPC l 7 program set. Binding sites from different proteins were first overlaid by superimposing the ring atoms of the sugars. Interaction fingerprints were derived by identifying common protein residues in different proteins in a given dataset that were involved in hydrogen bonding, stacking interactions and van der Waals contacts with the individual sugar atoms by using home-grown scripts that parsed and interpreted the LPC outputs. Hydrogen bonds were considered to be common
between two structures if they involved the same atom sets of the same res idue types in different prote ins and were within 3.6 A of any the same sugar hydroxyls. The polar atoms of the main chain and the side chains were regarded as two different atoms sets for this purpose. Van der Waals interactions between any non-polar atoms of the same resi due type in different proteins with the same carbon atom of the sugar (within a di stance of 4.5 A) were considered to be equivalent. Similarly, alignment of any aromatic res idue in different structures with the corresponding sugar rings with their centroids at a distance of less than 4.5 A apart and their planes maki ng an angle of greater than 150°, were considered as common stacking interactions . Further, commonalties in interactions within the proteins themselves were derived using previously developed HBPRINT algorithm l 8
and used for analyzing the proximity of the required res idues in deriving the final fingerprints. Where required, manual re-orientation of the binding sites (containing the sugars) were made so as to maximi ze the similarities in the binding site residue types and positions among different structures. This was carried out by a systematic rotation of all binding sites within each dataset, about the centroids of their respective sugars, with respect to anyone chosen reference from each set. The structural superpositions thus derived have been used to obtain structure-based sequence alignments. Sequ,::nce alignments have then been
I d . I '9 ana yse uSlllg sequence ogos' .
Lead design Structure-based lead design was carried out using
Luofo available through Cerius2 (Accelrys Inc., 2004; http://www.accelrys.com). Crystal structures of garlic lectin (lBWU) and concanavalin-A (SCNA) were chosen as examples of proteins recognizing man nose to carry out the structure-based design . Similarly, peanut lectin (2TEP), galactosidase (1 UAS) and a c-type lectin (1 TLG) were chosen as examples of galactose recognizing proteins whereas hexokinase (I BOG) and pea lectin (2BQP) were chosen as examples of glucose recognizing proteins. Each of these had sugars bound to them non-covalently as their native ligands. The structures were then set up for ah-initio LUOI searches as follows: (a) removal of all heteroatoms (water, substrates), (b) addition of all essential hydrogen atoms followed by a force-field assignment of potential types and partial charges based on the CVFF forcefield, (c) definition of the center of the active site (in all cases the center of mass
RAJ AN PRABU e/ (Ii.: RECOGNITION FINGERPRI NTS IN CARBOHYDRATE-BASED DRUG DESIGN 79
of the sugar bound to each of the respecti ve crystal structures was taken as the search center using a potenti al interactio n sphere of 12 A around it) and, (d) ass ignment of specific input parameters such as the hydrophilic and hydrophobic interacti on sites to be generated by LUDT- (aliphatic/aromatic flag (on) , densL (25), den sP (25), and rInsd (0.5A)). Th e tunicate c-type lectin structure was taken as a third example of galatcose binding proteins, since it differed from the other two exampl es by containing a calcium ion in direct co-ordination with the sugar. This protein was set up for the LUDI search, both with and without the calcium atom in the search zone. The empirical scoring function deve loped by Bohm (1998), as implemented in LUDT , was used for evaluating binding strengths. The LUDI fragment library used contained 1053 fragments belonging to many different c lasses. The guided-design protocol s were al so carri ed out using LUDI with the same fragment library and similar input parameters, but with addi tional interaction constraint(s) derived from the interaction fin gerprints for the respective fa milies.
Results and Disclission Datasets
The procedure described in the Methodology secti on resulted in identifying first li sts of 630, 3 16 and 39 1 protei n structures for man nose, galactose and g lucose respecti vely. Further f iltering to remove redundancy gave ri se to second li sts of 136, 82 and 106 for man nose, galactose and g lucose respectively . Of these, 17, 1 and 3 structures respecti vely contained covalent complexes of the three sugars which were excluded and thi s resulted in further short-lists of 116, 8 1 and 103 structures that contained non-covalent sugars for mannose. galactose and g lucose respectively . Of these, only 12, 15 and 32 structures respectively contained mo nosacch arides and were taken as the core datasets. To these li sts, structures containing disaccharides were added where corresponding monosaccharide entries were not avai labl e, which resu lted in final li sts of 13,26 and 3 1 structures for man nose, ga lactose and glucose sets respec tively, and has been used for a ll furth er analysis in this study. The li sts of such prote ins are g iven in Tables 1-3 .
Table I- Dataset to study mannose recognition . A non-redu ndant li st of proteins which bind ma nnose non-cova lently. where structures of protein-mannose complexes are known
S. No. Protein PDB ID Resolution SCOP fami ly Fold and cha in (A)
2
3
4
5
6
7
8
9
10
I l
12
13
Rat mannose binding prote in A
Mannose binding protein C
Human fibrin
Lamprey fibrinogen
Mannose binding protein , Fril
Pea lect in
Lectin (legume isolectin I) complex with MMA
Concanvalin A
Capsid pro tein of Pbcv- I VP54
Artocarpin
identifi er
IKWU:C
lRDL: I
IFZC: B
ILWU : H
IQMO :A
lRIN: A
lLOB :G
5CNA: A
IM3Y: D
IJ4U : D
Fimh ad hesin-fimc chaperone I KLF : P co mpl ex with D-mannose
Man nnse spec ifi c aggl uti- IBW U: A nin(lectin from gar li c) bulbs co m-plex with Ci- D-mannose
Mannose spec ifi c agg lutinin from I MS A : D snow drop bu lb
1.95
!.7
2.3
2.80
3.5
2.6
2.0
2.0
2
2.9
2.79
2.20
2.29
C-Typc lectin domai n
Fibrinogen Cterminal domainlike
Leg ume lect ins
Major capsid protein VP54
C-Type lect in-like
Fibrinogen C-terminal domain-li ke
Co ncanavalin A-like lectin s/giucanases
Nuc ieopiasmi n-ii kelV P (v iral coat and capsid proteins)
Mannose binding ~'::' rri s Jll I lect ins
Pilus subun its Common fo ld of diphlheria tox in/tran sc ripti on fac -torslcytoc hrollle f
u-D-Mannose spe- ~- Pri sm II c ifi c plant !t::ctins
80 INDl f\ N J CHEM . SEC A. JANUARY 2006
Table 2--])ataset to study ga lactose rccogni ti on. A non-rcd undant list of proteins wh ich bind galac tose non-cova lcn tl y, where structures of protein-ga lactose complexes are known
S.No. Protein name PDB ID: Reso luti on SCOP fa mil y Fold chain (A)
identiri er
Galactosc mutarotase rrom INSX:B 1.75 A Idose I-epi merase Supersa nd wich Lactococcus lacti s mutant (muta rorase) H 170N complex with galactose
2 Ri ce-a. -galactosidase IUAS: A 1.5 Amylase. catalytic TIM ~/a.-ba rre l
3 Thennus Thermophilus A4 ~- lKWK: A 2.2 domain
galac tosidase in complex with galactose
4 Heat labile en terotox in B pen- LDJR: D 1.3 Bacterial AB5 tox- OB-fold tamer complexed with M- ins, B-subunits carbox yphen y I-a. -D-gal actose
5 Tetanus toxi n complex with LDIW: A 2.0 Clostridium neuro- ~-Tre foil galactose tox ins, C-terminal
domain
6 Tunicate-C-type lecti n com- ITLG : A 2.2 C-type lectin do- C-type lect in -like pl exed with D-galctose malll
7 Mannose binding protein -A lA FA: 1 :2
8 Lamprey fibrinogen complex ILWU : K 2.8 Fibrinogen C- Fibrinogen C-tcrmin al with peptide GL Y -HlS-ARG- terminal domain- domain-like PRO-Amide like
9 Sialidase or Neuraminidase IEUU 2.5 Ga lactose binding Galactose-binding do-domain main-like
10 Human galact in -3 IA3K 2. 1 Galectin (animal S- Concanavalin A-like
II Lactose-liga nded Congerin I JCIL: A 1.5 lectin ) lec ti ns/gl ucanases
12 Complex of toad ovary g:l l:lctin lGAN: A 2.23 with N-acetyl galctose
13 S-lectin JSLT: A 1.9
14 Lectin complexed with lac tose IHLC: A 2.9
15 Human galctin-7 in compl ex 4GAL: B 1.95 with lac tose
16 Galactose/Glucose binding pro- IGCA 1.7 L-arabinose binding Peripl asmi c binding tein complex with ga lactose protein-like protein-like I
18 Peanut lectin :2TEP: A 2.5 lecti ns/g lucanases
19 Lectin UAE-Il complex with lDZQ:A 2.85 galactose
20 Winged bean lectin co mpl exed IWBL: A 2.5 with methyl-a.-D-g:l lactose
21 Winged bean acidic lectin com- IF9K : A 3 plex with methyl-D-galactose
22 Jacalin . a moraceae plant lectin IJ AC: A 2.43 Mannose-bind ing [:I-Prism [ with [:I-pri sm lectins
23 Ri cin 2AAI: B 2.5 Ricin B-like ~-Trefo il
24 Mistletoe lectin 1 from ViSCI/1I1 JOQL:B 1.0 albl/ l11 complex with galactose
25 Ebulin , orthorombic LHWM:B 2.8
26 Xylanase from Srreplolllyces IISZ: B 2.0 Olivaceovirides E-86 complex with galactose
RAJAN PRABU et al.: RECOGNITION FINGERPRINTS IN CARBOHYDRATE-BASED DRUG DESIGN 81
Table 3-Dataset to study glucose recognition. A non-redundant list of proteins which bind glucose non-covalently, where structures of protein-glucose complexes are known
S. No. Protein PDBID Resolution SCOP family Fold and chain (A) identifier
N-acetyllactosamide a - IGWW: B 1.8 a -I ,3-galactosyl- Nucleotide-diphospho-sugar 1,3 - galactose transferase transferase-like transferases
2 a - amylase IMXD:A 2.0 u -Amylases, C-terminal Glycosyl hydrolase domain ~-sheet domain
3 Amylosucrose IJG9: A 1.66 Amylase, catalytic domain TIM ~I a -barrel 4 Maltodextrin glycosyl IGJW: A 2.1
transferase 5 Bacteriorhodopsin lKME: B 2.0 Bacteriorhodopsin - like Family A G protein-coupled
26 Lactose synthase complex INF5 : D 2.0 ~-14 Galactosyltransferase N ucIeotide-di phospho-sugar with glucose transferases
27 ~ - D-glucan exohydro- IEXI : A 2.2 ~-D-glucan exohydrolase, TIM ~-barrel lase isoenzyme EXOI N-terminal domain
28 Endo-I ,4- ~ - xylanase lHIZ: A 2.4 ~-G I ycanases TIM ~-barrel 29 ADP - ribose pyrophos- lQ33: A 1.81 ND
phatese 30 Iswi protein IOFC: X 1.9 31 4-a-Glucano transferase IKIW: A 2.8
82 L~DIAN J CHEM, SEC A, JANUARY 2006
Deriving fingerprints of recognition for mannose and galactose
It is obvious from the three tables that proteins that bind to the sugars in all the three cases are indeed quite diverse, belonging to different structural and functional families and without any significant se-
quence similarities among them. Yet, they all share a common feature of the capability to recognize the same sugar - mannose, glucose or galactose - in each of the three datasets. An obvious question that is raised from this observation is what brings about these recognition capabilities? To address this question,
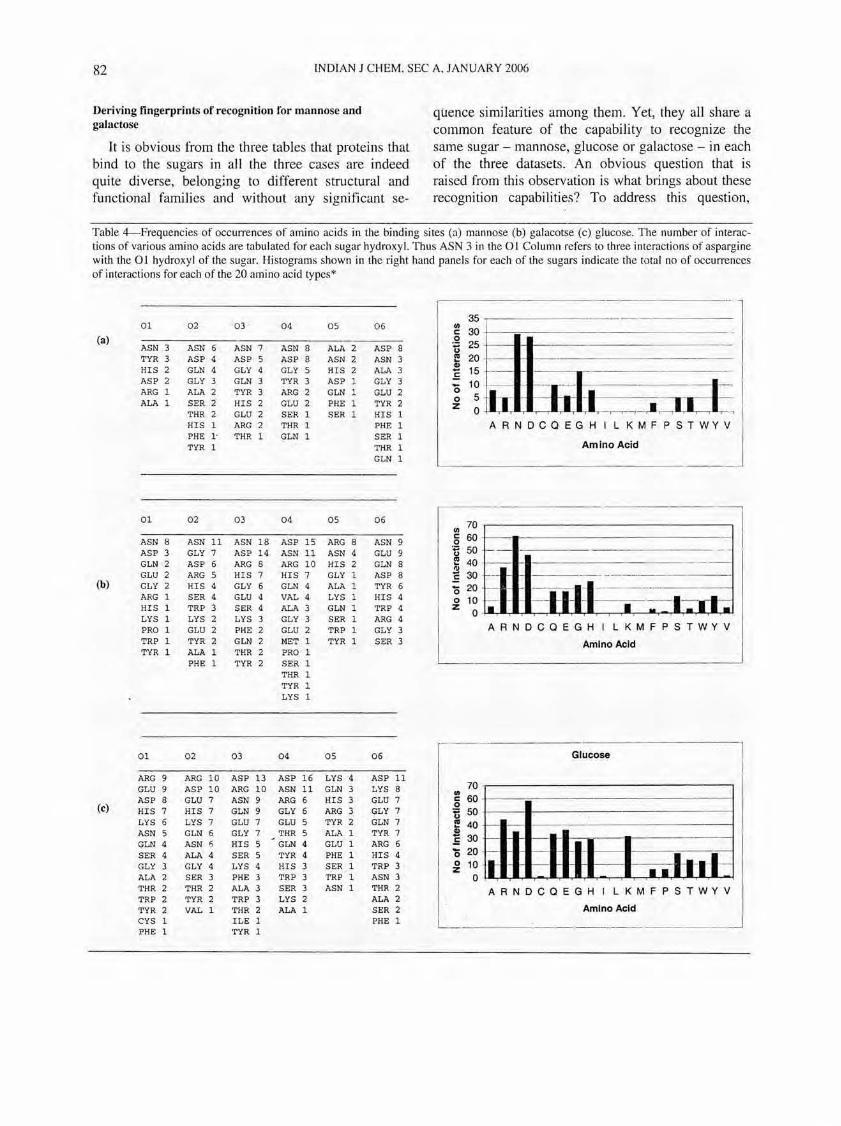
Table 4-Frequencies of occurrences of amino acids in the binding sites (a) man nose (b) galacotse (c) glucose. The number of interactions of various amino acids are tabulated for each sugar hydroxyl. Thus ASN 3 in the 01 Column refers to three interactions of aspargine with the 01 hydroxyl of the sugar. Histograms shown in the right hand panels for each of the sugars indicate the total no of occurrences of interactions for each of the 20 amino acid types*
(a)
(b)
(e)
01
ASN 3 TYR 3 HIS 2 ASP 2 ARG 1 ALA 1
01
ASN 8 ASP 3 GLN 2 GLU 2 GLY 2 ARG 1 HIS 1 LYS 1 PRO 1 TRP 1 TYR 1
01
ARG 9 GLU 9 ASP 8 HIS 7 LYS 6 ASN 5 GLN 4 SER 4 GLY 3 ALA 2 THR 2 TRP 2 TYR 2 CYS 1 PHE 1
02
ASN 6 ASP 4 GLN 4 GLY 3 ALA 2 SER 2'
THR 2 HIS 1 PHE l' TYR 1
02
ASN 11 GLY 7 ASP 6 ARG 5 HIS 4 SER 4 TRP 3 LYS 2 GLU 2 TYR 2 ALA 1 PHE 1
02
ARG 10 ASP 10 GLU 7 HIS 7 LYS 7 GLN 6 ASN ALA 4 GLY 4 SER 3 THR 2 TYR 2 VAL 1
0 3
ASN 7 ASP 5 GLY 4 GLN 3 TYR 3 HIS 2 GLU 2 ARG 2 THR 1
03
ASN 18 ASP 14 ARG 8 HIS 7 GLY 6 GLU 4 SER 4 LYS 3 PHE 2 GLN 2 THR 2 TYR 2
03
ASP 13 ARG 10 ASN 9 GLN 9 GLU 7 GLY 7 HIS 5 SER 5 LYS 4 PHE 3 ALA 3 TRP 3 THR 2 ILE 1 TYR 1
04
ASN 8 ASP 8 GLY 5 TYR 3 ARG 2 GLU 2 SER 1 THR 1 GLN 1
04
ASP 15 ASN 11 ARG 10 HIS 7 GLN 4 VAL 4 ALA 3 GLY 3 GLU 2 MET 1 PRO 1 SER 1 THR 1 TYR 1 LYS 1
04
ASP 16 ASN 11 ARG 6 GLY 6 GLU 5 THR 5 GLN 4 TYR 4 HIS 3 TRP 3 SER 3 LYS 2 ALA 1
05
ALA 2 ASN 2 HIS 2 ASP 1 GLN 1 PHE 1 SER 1
05
ARG 8 ASN 4 HIS 2 GLY 1 ALA 1 LYS 1 GLN 1 SER 1 TRP 1 TYR 1
05
LYS 4 GLN 3 HIS 3 ARG 3 TYR 2 ALA. 1 GLU 1 PHE 1 SER 1 TRP 1 ASN 1
06
ASP 8 ASN 3 ALA GLY GLU 2 TYR 2 HIS 1 PHE 1 SER 1 THR 1 GLN 1
06
ASN 9 GLU 9 GLN 8 ASP 8 TYR 6 HIS 4 TRP 4 ARG 4 GLY 3 SER 3
06
ASP 11 LYS 8 GLU 7 GLY 7 GLN 7 TYR 7 ARG 6 HIS 4 TRP 3 ASN 3 THR 2 ALA 2 SER 2 PHE 1
35 III c:: 30
.S! 25 U E 20 III .E 15 '0 10 o 5 Z 0
---=-~~=----~-=----'l ---- ---- - . -
-----!
- '--1-' i o:J:~ I -I. I • -•• • ,--,--r-,I r--r
ARNOCOEGHILKMFPSTWYV I Amino Acid J
~~-T----------------------~---l r c:: 60+--_.- - --- --------- - --- I'
IB - - - -.. __ ... __ ... _--- - -
I ~ 20
I ~ ': f-_A----IRI--1Nl--IIo C 0 E G H ILK M F PST W Y V I Amino Acid ~
- ---------------
70 ~ 60 o ti 50
. E 40 .l!! .E 30 '0 20 ~ 10
o -l
Glucose
------
I • •
.~-----------"
----
--------------
• ••• • •••••
I i 1
.
I ARNOCOEGH I LKMFPSTWYV I I . . J Amino Acid . L ____ ~.~._. _______ , ______ . ______ _
RAJAN PRABU et al.: RECOGNITION FINGERPRINTS IN CARBOHYDRATE-BASED DRUG DESIGN 83
(a) Mannose (b) Galactose (c) Glucose
lbwu A lklf P lqmo_A lrin A lkwu C llob G lmsa D ... lj4u_D Scna A lrdl 1
. ...;.
ljac-':'A laxl
. 2t.ep~A
. la3k . lcil ' A
, 19an...:A lslt:.....,:A: lhlc A 4gal_B ltlg_A 2aai B ldjr_D lwbl A H9kl
~. ~hwm B leuu luas A 19ca_ lnsx B ldiw A lisz B ikwkA laz~A loql_B '
lbdg_ lcza N leul A lqs9_H ligz_A
.1_k3i_A 2bqp_A liSa A 2gbp_ ljg9_A 19ww_B 19ic_B ln30 B lloa G lhiz A ljsw_A 2bvw B 1ge9_H lmxd A lkiw A lexl A ljx2_A lhSu_A., lkme AB lofc X Ha9 A lisy_B lq33_A lnfS CD 19jw_A lcql_B
Fig. 1 - Structure-based sequence alignment of the binding sites in the three datasets obtained from the super positions in their re-oriented frameworks (see text). Residues forming the core fingerprints are highlighted gray. Sequences shown not necessarily sequential in number, since they are derived from structural equivalences in each set. Hyphens represent gaps in the alignment imply lack of structural equivalences at that position.
the binding sites of each of the structures in each dataset were overlaid by superimposing the corresponding sugar ring atoms. Residues directly interacting with the sugars through polar contacts were first computed and analysed with respect to each sugar atom. Residues were then ranked based on their frequencies of occurrence for all the structures in a given set. Table 4 lists these rankings for different residues. Some preferences of residue types emerge from this study, although a clear-cut fingerprint could not be derived. For example, an aspartic acid/ asparagine is found to interact 26 times with the 04 atom of galactose, but as many as 39 other interactions from other residues were also found to interact with the same 04 atom. Further, the frequency of occurrence
of aspartic acid/asparagine to interact with the 03 atom of galactose was also significantly higher (32) than that of any other single residue. The same trend was observed with glucose and mannose datasets as well. It was however observed that when the interactions of atoms were summed up, the frequency of interaction of certain residues such as aspartic acid and in many cases, also asparagines, were much higher than that of other residues (histograms in Table 4). This result, together with the observations of the binding site architectures and interactions by visual inspection through computer graphics, suggested that the ligand in its binding site may have re-oriented in, what may ultimately emerge as, essentially similar binding sites. To analyse this further, the binding sites
84 INDIAN J CHEM, SEC A, JANUARY 2006
(a)
xg-• -0 - - .. N "
N .. .. .. .. C
7 & 5 .. 3 2 , o
801 .02 003004 mas CJC6
II I II III 111111 II 1111
HII 1111 I III IUIIIII II
2 3 45. 7 I 9 ~ " n u
D ---~ It If:
• 0 ., $ , II 1 . ... .
.. C i 0 J.I .4hI1 n .. _ -Ih .. 001 n." 2 3 7 8 t 4
- . -----,-.~ 2 II 0 .. (Of ., • .. .. .. .. .. c 0 .JAI1I,JLL...,.,.I1I ..... ...I'JUWr,El...,IIWI.,..JJL,-.M,ILIIj
2 S " , ! 6 7 8 9 10 11 12 13 14
Poila'1ln tngelJ)llri
Fig. 2 - Sequence logos of structure-based sequence alignments for (a) man nose, (b) galactose and (c) glucose datasets. The numbers in the X-axes correspond to the sequential numbering of the structurally conserved atoms in the binding sites forming the finger-prints, in the order shown in Fig. 1. Greater the height and size of the letter, the higher is its extent of conservation . Histograms shown in the righthand panels for all the three datasets indicate the number of hydrogen bonds formed by each of the amino acid residues in the fingerprint, (shown in the sequence logos) with sugar hydroxyls. The six hydroxy Is are coloured differently as indicated in the top of the figure. The same colouring scheme is maintained for all three datasets. The numbers in the X-axes here too, correspond to the position numbers of the fingerprint, similar to that used in the sequence logos.
were rotated about the centroids of the sugar molecules with respect to each other. Typically, the subset of the binding site from one structure would be considered as the reference and the subsets of the binding sites from other molecules would be rotated, so as to get the maximum overlap in their corresponding interacting residues. Analysis of the structures, overlaid in the re-oriented frameworks in all the three cases, led to the derivation of common patterns in the occurrences of amino acid residues as well as in their relative spatial distributions within each data set. Fig. 1 illustrates a structure-based sequence alignment derived from the re-oriented superpositions of different structures in all the three cases. The high conservation of certain residues. for example aspartic acids, at structurally equivalent positions are obvious from this figure for all the three datasets. Fig. 2 shows the frequency of occurrence of each residue type depicted as
sequence logos. Also shown are the frequencies in their interactions with individual sugar atoms. The most conserved of the residues (mannose: positions 4, 5 and 6; galactose: 2, 3, 8 and 10; glucose 1, 5, 6, 7 and 11) shown in the respective sequence logos, are not only conserved in their sequence types, but also conserved in their relative spatial distributions. The clustering of such residues after re-prientation, clearly emerges due t~ their structural equivalences (Fig. 3) and can therefore be considered to form the core fingerprint. Fig. 3 (a, b & c) also illustrates that hidden patterns existed in the binding sites. These were not obvious by simple superpositions of the sugar molecules, but became apparent after viewing them in their re-oriented frameworks.
A fingerprint for mannose recognition was derived III an earlier ~tudy, based on an analysis of six unique mannose-protein complexes available at that time21
•
RAJ AN PRABU ef al.: RECOG NITION FINGERPRINTS IN CARBOHYDRATE-BASED DRUG DESIGN 8'5
(a)Mannote (e)GJuto.e
(i i)
Fig. 3 - Superpositions of binding sites of protei ns in the datasets of (a) man nose (b) galactose and (c) glucose. Two types of superposi tions shown are (i) simple superpositions of the sugar rings alone and (ii) starting from the fLfSt superpositions, re-orientation of the binding sites with respect to a reference structure in the set, about the centroids of the sugars, so as to obtain maximum superpositions of the different binding sites in each set. The same colouring scheme is used for both the cases. In the mannose dataset, all the residues falling in position 4 of the fingerprint are coloured red, while residues falling in position 5 are in yellow and residues falling in position 6 are in . blue. Similarly residues in positions 2, 3, 8 and 10 in the galactose dataset are coloured blue, yellow, red and pink respectively. In the glucose dataset, residues in positions 1,5, 6,7 and 11 are coloured pink, cyan, yellow, red and blue respectively. The sugars in all of them are coloured grey. The predominant residue types along with their position numbers in the corresponding sequence logos are indicated.
The fingerprint derived from the previous study is upheld in the present study as well, although the present dataset includes seven more unique proteins, making a total of 13 different structures'. The sequence logo (Fig. 2a) for mannose binding sites indicates a consensus occurrence of Asp, Asn and Ala/Val. The 04 hydroxyl was predominantly found to interact with an aspartic acid/asparagine side chain. In addition, one or more of the 02 to 04 hydroxyl~ were in most cases found to interact with an additional Asnl Asp. The alanine or valine found in the fingerprint was also conserved with a favourab le van
der Waals interaction with one of the sugar carbons. Apart from these three residues, a high preponderance of a threonine' and a glycine with van der Waals inte'actions with the sugar carbons was also observed. The number of occurrences of each interaction is also quantitati vely illustrated in the histogram shown in Fig. 2a. These fingerprints , having been derived at the structural level, contain two components (a) conservation of the same residue type(s) in the binding site, and, (b) and also conservation in their relative spatial distributions. Fig. 3a(ii) illustrates the conservation in their spatial arrangements. The strategies to derive
86 INDIAN J CHEM, SEC A, JANUARY 2006
these fingerprints or structural motifs appears to have varied from protein to protein, suggesting they may have evolved independently since they do not exhibit similarities in their sequence distribution.
The fingerprint for galactose recognition, shown in Figs 1 b, 2b and 3b, again reveals a high prepon~erance of an aspartic acid/asparagine hydrogen bondmg with one of the 04 or 03 hydroxyls. Apart from a predominant Asp - 04 hydroxyl interaction seen as in the case of mannose, a high frequency of 03 hydroxyl with the main chain of glycine and 06 hydroxyl with an asparagine were also observed in the galactose set (Fig. 3b). Besides, there is also a high preference of one to two glycines and an aromatic residue, typically a tryptophan, the latter making a stacking interaction . The crucial roles played by many of these residues, including the highly conserved glycine in galactose recoGnition has been described recently in jacalin like
b .
lectins23. The structurally equivalent residues (aspartIc acid, asparagines, glycine, valine and a tryptophan ; refelTing to predominant residue types in the sequence logo) conserved in the dataset (Fig. 3b), can be described here as the core fingerprint. The individual families forming the galactose-binding proteins in the dataset, exhibit much more conservation of residue types among themselves. For example, the galactosebinding members of the jacalin family show high conservation of the tryptophan that stacks with the galactose sugar. Substitutions across families, however are conservative in nature, allowing common p3tterns to be recognized from the full dataset. An analysis of the galactose binding proteins reported recentl/ 4
, describes the lack of any identifiable patterns at the sequence or structural levels, but have shown that distance matrices computed for different galactose bindinG sites have some similarities and can be used b
to identify galactose binding proteins in general. Our results agree with the lack of identifiable sequence or structural patterns when they are viewed by simple superimposition of their respective sugars . However, the fact that distance matrices have some features in common, imply that they carry the information that define the binding site. This issue gets resolved by the identification of sequence and structural patterns that we have reported here, made possible by viewing the different structures in their re-oriented frameworks.
The fingerprint for glucose, shown in Figs 1 c, 2c ' and 3c, also shows a very high preponderance of aspartic acid, which is predominantly hydrogen-bonded with the 04 and 06 hydroxyls of glucose. Apart from
this interaction, additional asparagines are seen to make hydrogen bonds with one of the sugar hydroxy Is also (Fig. 2c). A predominant interaction of a glycine with the 03 hydroxyl is also seen. Fig. 3c shows the conservation of structurally equivalent aspartic acid, asparagines, glycine/leucine, that can be considered as the core fingerprint.
Lead identification
A total of eight protein structures from mannose, Glucose and galactose binding proteins were chosen as ;xample for carrying out ab-initio lead design studies. The centre of mass of the bound sugar in the crystallographically determined binding sites of each ~f
these structures were used as the search centres m each case. The results of ab-initio design as well as the guided-design are summarized in Table 5. The abinitio design considered only a defined sphere around the identified ligand binding site to place the fragments in the search for a lead compound. The same fragment-based search using the same search sphere at the same site, but by considering constraints, defined based on interactions deemed to be important for recognizing the native ligands, is referred to as the guided design. Very often, conserved interactions that would form the finger-print are also biologically significant and any change in them could lead to loss of function. It would, therefore, be more beneficial to apply constraints based on such interactions. Each interacting atom from the protein, derived to be part of the core finger-prints were used to define constraints, either individually or in sets, to carry out the guided design . A systematic exercise with different sets of constraints indicated that some constraints proved to be useful by picking up more clustered hits (Fig. 4), whereas some other constraints did not identify any suitable lead at all. This procedure helped in ruling out usage of interactions which would overconstrain the search space and hence not identify any hits at all. Those interactions which proved to be useful in identifying hits , are summarized in Table 5. Figure 4 (a, b & c) indicates that the number of hits obtained from the ab-initio protocols are many more than those from the con'esponding guided design protocols in all the eight cases studied here. Table 5 indeed substantiates thi s observation. Apart from the simple reduction in the number of hits in each case, a significant improvement in the clustering of hits in the binding site is also observed with the guided design protocols in all cases, as evident from Fig. 4. This shows that the guided design helps greatly in obtain-
RAJAN PRABU el (II. : RECOGNITION FINGERPRINTS IN CARBOHYDRATE-BASED DRUG DESIGN 87
(a) Mannose
5cna:ab-initio
(b) Galactose
2tep:ab-initio
I t1g(with Ca) :ab-initio
(c) Glucose
I bdg: ab-initio
5cna:guided
2tep:guided
I tIg(with Ca): guided
I bdg:guided
I bwu: ab-initio I bwu;guided
I uas:ab-initio 1 uas:guided
I t1g(without Ca): ab-initio I tIg (without Ca): guided
2bqp: ab-initio 2bqp: guided
Fig. 4 - Superpositions of alllhe hits obtained by ab-initio and guided lead design protocols fo r each of the eight examples studied here in (a) mannose (b) galactose (c) glucose datasels. The number of hilS in each case are shown in Table 5. The corresponding PDB codes and lhe nature of the search are labeled for each protein.
88 INDIAN J CHEM, SEC A, JANUARY 2006
Table 5 - Number of leads designed from ab-illitio and guided design protocols to fit the binding si tes of chosen examp les of man nose, galactose and glucose binding proteins. The same fragment library and same input parameters were used in all cases. The number in each cell represents the number of hits obtained. The interacting atom of the protein used for guiding the search is listed wherever applicable. All other interactions of the fingerprint, that did not yield even a single hit, are not shown here.
2BQP 246 21 26 31 66 IS 7 7 OS1:00 OS 1:00 FI23:CE FI23:CO F123 :CZ FI23:CZ OSI:OO OS1:00
2 2 2 FI23:CE 2 Z FI23:CE OS1:00
2 2
5cna
... ·.f
RAJAN PRABU et al.: RECOG NITION FINGERPRINTS IN CARBOHYDRATE-BASED DRUG DESIGN 89
1bwu 2tep 1uas 1tlg (with Ca)
1tlg 1bdg 2bqp (without Ca)
Fig. 5 - Chemical nature of the top IO-LUDI hits obtained by guided lead design prot<;>co ls for each of the 8 examples. The corresponding PDB code is indicated on top of each column. Standard atom colours have been used. [Green - Carbon, Red - Oxygen , Blue - Nitrogen, White - Hydrogen, Yellow - Sulphur].
90 INDI AN ] CHEM , SEC A, JANUARY 2006
NtJO&·"·
5CNA Rank: 6. 35 Score: 401
Q~:"''''
~• ~ .. ~ ~!~"l
St, ::IIo:Al . • '~. ' •
4:" .
M~;&#" ~'~~'\'
2TEPRank: 4,28 Score: 350
I no (with Cal Rank: 1, 11 Score: 510
I BOO Rank: 5, 10 Score: 312
Mannose
1BWU Rank: 5, l) Score: 340
Galactose
1)-~,U( .. ~ !~ .;}'
1 no (without Ca) Rank: 6~ % Seale: 342
Glucose "'.,:)~ .
I'frn# .. I
" _iU ~ .,,; ' ......
« ~~~ 2BQP Rank: 5,82 Score: 318
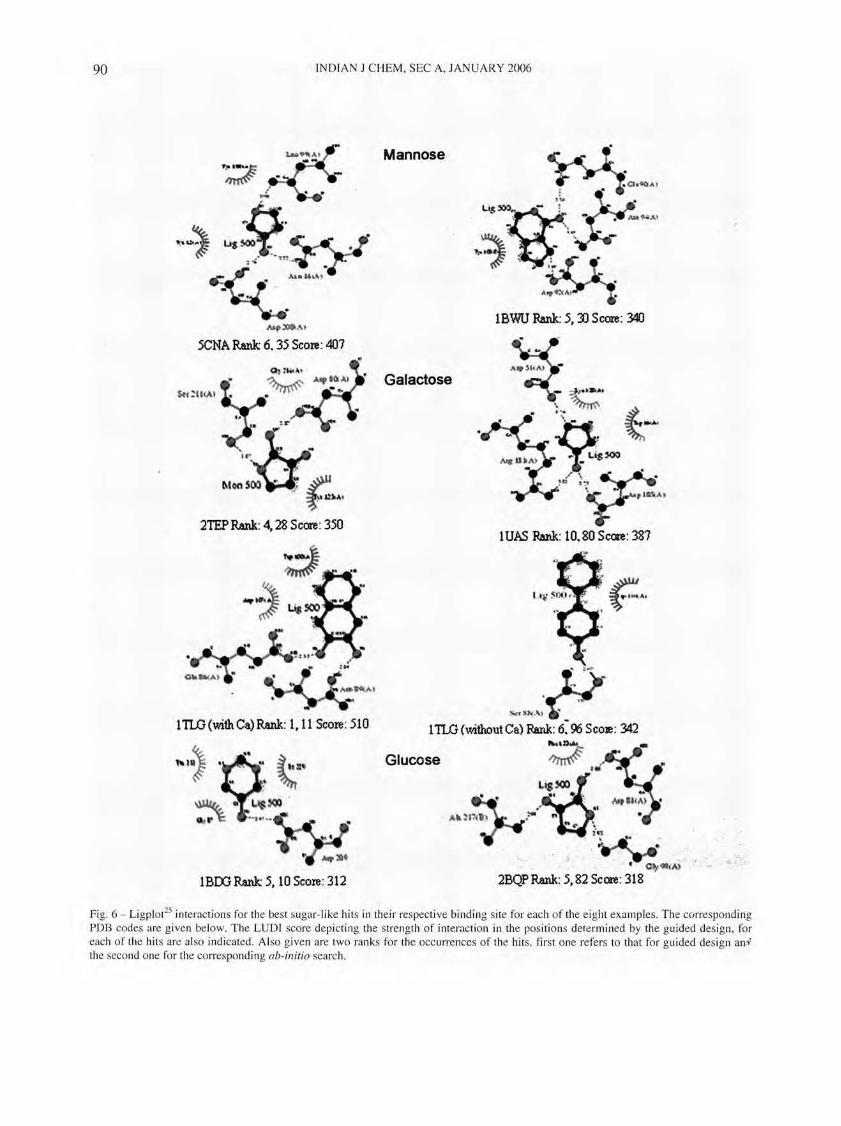
Fig. 6 - Ligplot25 interactions for the best sugar-like hits in their respective binding site for each of the e ight examples. The corresponding PDB codes are given below. The LUDr score depicting the stren gth of interaction in the positi ons determined by the guided des ign, for each of the hits are also indicated. Al so given are two ranks for the occurrences of the hits, first one refers to that for guided design an i the second one for the corresponding ab-initio search.
RAJAN PRABU et al.: RECOGNlTlON FINGERPRINTS IN CARBOHYDRATE-BASED DRUG DESIGN 91
ing a better definition of the useful interaction search space. The clustering of the hits in the guided design, in fact, overlaps to a significant extent with the positions of the native ligands, strongly suggesting that they are likely to be more biologically significant leads than those obtained by the ab-initio search. In the case of the tunicate galactose binding lectin, the presence of calcium further improved the definition of the interaction space and hence resulted in finer focusing of the hits, as compared to the corresponding structure in the absence of calcium. An analysis of the nature of the hits obtained in all the eight cases using both protocols, indicate that not only did the interaction space get better defi ned, but the nature of hi ts are al so better defined. Thi s was judged based on the similarities in interactions of the hits obtained, with those of the native tigands. Most of the top hits from the guided search were in fact molecules containing either five-membered or six-membered ring scaffolds with one or more hydroxyl or amino substituents, which are referred to here as sugar-like molecules for convenience. The hits from the ab-initio search on the other hand, were far more diverse in nature and did not contain any hydrogen bonding groups in many cases. The chemical structures of ten top hits from the guided search for all the eight examples are illu strated in Fig. 5. It is noteworthy that these hits were somewhere among the hundreds of hits, if at all identifi ed, in the ab-inirio searches. Thus, the guided searches also significantly help in clearly defining the pharmacophore space that is required to be searched during lead design . The ranks of some molecules that were identified as hits in both the protocols are shown in Fig. 6. It can be clearly seen that the hits rank higher in the guided design than in the ab-illitio protocols in all the eight cases. Even when the same molecules were identified by both protocol s, their positi ons in the binding sites were not identical in most of the cases. The interactions made by the hits from the guided design appeared to be specific since they involved many of the binding site res idues. On the other hand, the interactions made by the same hits from ab-initio des ign appeared to be non-specific, since they were not only fewer in number but also did not involve the binding site residues. Thus, many of the hits from guided des ign, retain binding modes in the protein binding si tes similar to those of the corresponding native ligands. A good lead-design operation is to be expected to result in the identification of the natural ligand (or its close analogues) itself, apart
from identification of interesting lead compounds. In view of this, the sugar-like molecules identified from the guided design protocols lend much credence to the methods and also serves as a self-validation exerCIse .
In summary, the guided design has been useful (a) to significantly improve the definition of the interaction search space, and, (b) to significantly improve the probabilities of identifying more native-like ligands, which has implications for identifying leads with better affinities and specificities in a drug-design exercise. Identifying leads from a guided search would also be useful in a database search by narrowing down on the pharmacophore space as well as the in leraction space to be searched. The fac t that the fingerprints identi fied in all the three cases, wheT'} used to guide the search protocols, resulted in identifying sugar-like molecules, also proves these motifs contain the information of sugar binding determinants in them.
Acknowledgements We thank Prof M Vijayan and Prof A Surolia
(Molecular Biophys ics Unit, Indian Institute of Science) for encouragement and many useful discussions. Financial support from DBT is gratefully acknowledged. Use of fac ilities at the Super Computer Education & Research Centre, Bioinformatics Centre, nsc, Bangalore, and Interactive Graphics faci lity supported by DBT is also acknowledged. Financial support from the DBT computational genomics initiative is gratefully acknowledged.
References I Axford J. Trends illlll'lUl1ol, 22 (2001 ) 237. 2 Brooks S A, Dwek M V & Schumacher U, FlIn ct ional
and Moleclliar GlvcoiJiology, (Bios Sc ie ntifi c Pu bli shers, Oxford) 2002, p 287.
3 Dwek R A. Chelll Rev. 28 ( 1996) 683. 4 Smith A E & He leniu s A, Science, 304 (2004) 237 . 5 Imbe rty A, Wimmerova M , Mitchell E P & Gilboa-Garber N,
Microbes illtect, 6 (2004 ) 22 1. 6 Courtney H S. Hasty D L & Dale J B, Alln Med, 34 (2002)
77. 7 Osborn H M, Evans P G, Gemmell N & Osborne S D. J
Pharm Pharmacal, 56 (2004) 69 1. 8 Hounsell E F, Young M & Davies M J. Ciin Sci, 93 (1997)
287. 9 Yarema K J & Bertozzi C R, ClI rr Opill Chem Bioi, 2 (1998)
49 . to Voge l P, Chill1ia, 55 (200 I) 359. II Mu sser J H, Carbohydrate-bused Th erapelltics ill Burger 's
Medicinal Chelllistry alld Drug Discovery, Vol. 2, ed ited by D J Abraham, 6th Edn, (John Wiley and Sons, New York)
92 INDIAN J CHEM, SEC A, 1ANUARY 2006
2003, P 203. 12 Berman H M, Westbrook 1, Feng Z, Gilliland G, Bhat TN,
Weissig H, Shindyalov r N & Bourne P E, Nucleic Acids Res, . 28 (2000) 235.
13 Bettler E, Loris R & Imberty A, (2004) 3D Lectin Database, 13 http://wwwcermavcnrsfr/databankllectine. 14 Anderson A C, Chem Bioi, 10 (2003) 787. 15 Honma T, Med Res Rev, 23 (2003) 606. 16 Altschul S F, Gish W, Miller W, Myers E W & Lipman 01,
.J Mol Bioi, 215 (1990) 403. 17 Sobolev Y, Sorokine A, Prilusky J, Abola E E & Edelman
M, Bioinjormatics, 15 (1999) 327.
18 Prasad T, Prathima M N & Chandra N R, Bioinjormatics 19 (2003) 167.
19 Schneider T 0 & Stephens R M, Nucleic Acids Res, 18 (1990) 6097.
20 Bohm H J, J COIllPUt Aided Mol Des, 6 (1992) 61. 21 Bohm H J, J Compul Aided Mol Des, 12 (1998) 309. 22 Ramachandraiah G & Chandra N R, Proteins, 39 (2000) 358. 23 Raval S, Gowda S B, Singh 0 0 & Chandra N R, GlycobioL-
ogy 14 (2004) 1247 . 24 Sujatha M S & Balaji P Y, Proteins, 55 (2004) 44. 25 Wallace A C, Laskowski R A & Thornton J M, Prot Eng, 8