41
| Date post: | 14-Jul-2015 |
| Category: |
Technology |
| Upload: | panagiotis-papadopoulos |
| View: | 180 times |
| Download: | 1 times |

Some Prominent Users
This very moment, Cassandra has surpassed
SQLite to become the 8th most popular
database, close behind Microsoft Access.
Source: http://db-engines.com/en/ranking

How it all begun
A. Lakshman (coauthor of Amazon's Dynamo) and P. Malik: “Cassandra - A Decentralized Structured Storage System”, SIGOPS, 2010

First Implementation
• Cassandra was first designed to fulfill the storage needs of the Facebook’s Inbox Search problem.
• Inbox Search: the feature to search through Facebook Inbox -> a very high write throughput, billions of writes per day -> scale with the number of users.

Goals
• Cassandra uses a synthesis of well known techniques to achieve scalability and availability.
• Designed to run on cheap commodity hardware and handle high write throughput without sacrificing read efficiency

Data Model and
Storage Architecture
Distribution Model

Basic features
1. Decentralized:
– every node has the same role (every node can service any request)
– no single point of failure
– data distribution (each node contains different data)
2. Fault-tolerant: Data is replicated to multiple nodes.

Basic features (cont.)
3. Tunable consistency: from "writes never fail" to "block for all replicas to be readable".
4. Scalability: Read and write throughput increase linearly as new machines are added

Scalability Winner
In this NoSQL study, the researchers concluded that: "In terms of scalability, there is a clear winner throughout our experiments. Cassandra achieves the highest throughput for the maximum number of nodes in all experiments although this comes at the price of high write and read latencies.”
Rabl Tilmann, Sadoghi Mohammad, Jacobsen Hans-Arno, Villamor Sergio Gomez, Mulero Victor Muntes, Mankovskii Serge , "Solving Big Data Challenges for Enterprise Application Performance Management". VLDB 2012

Cassandra’s Distribution Model
Put request

Cassandra’s Distribution Model
Put request
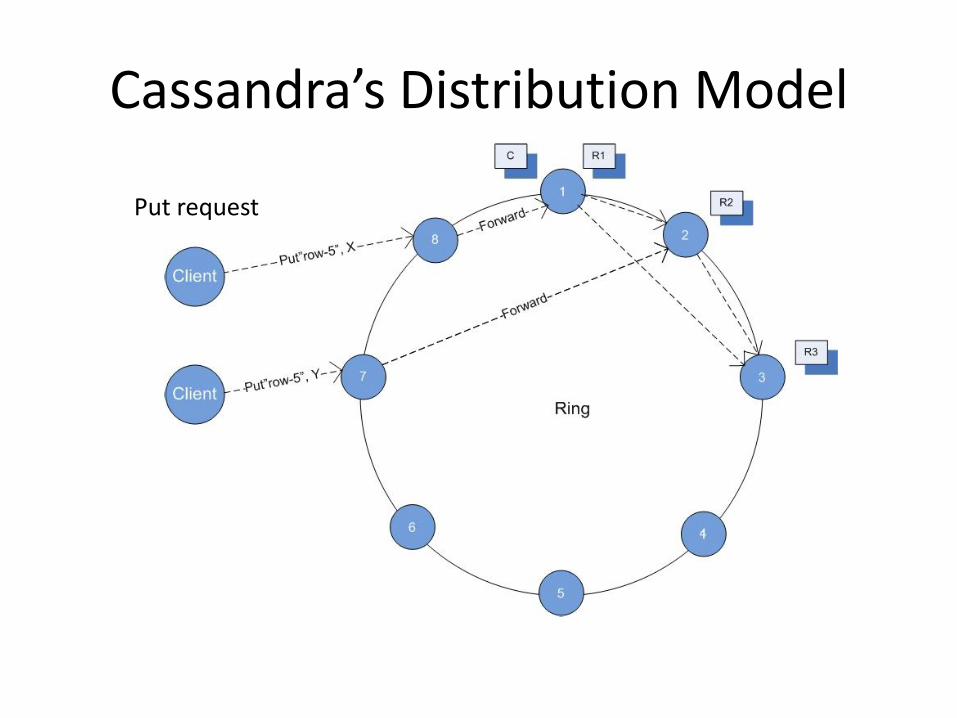
Cassandra’s Distribution Model
Put request

Cassandra’s Distribution Model
2/3 Responses: {X,Y}
Need for reconciliation!
Get request

Log-Structured Merge-Trees
LSM tree is a data structure with performance characteristics
that provide indexed access to files with high insert volume, such
as transactional log data. LSM trees provide far better write throughput than traditional B+ trees through sequentially writes
More about LSM trees: http://www.benstopford.com/2015/02/14/log-structured-merge-trees/
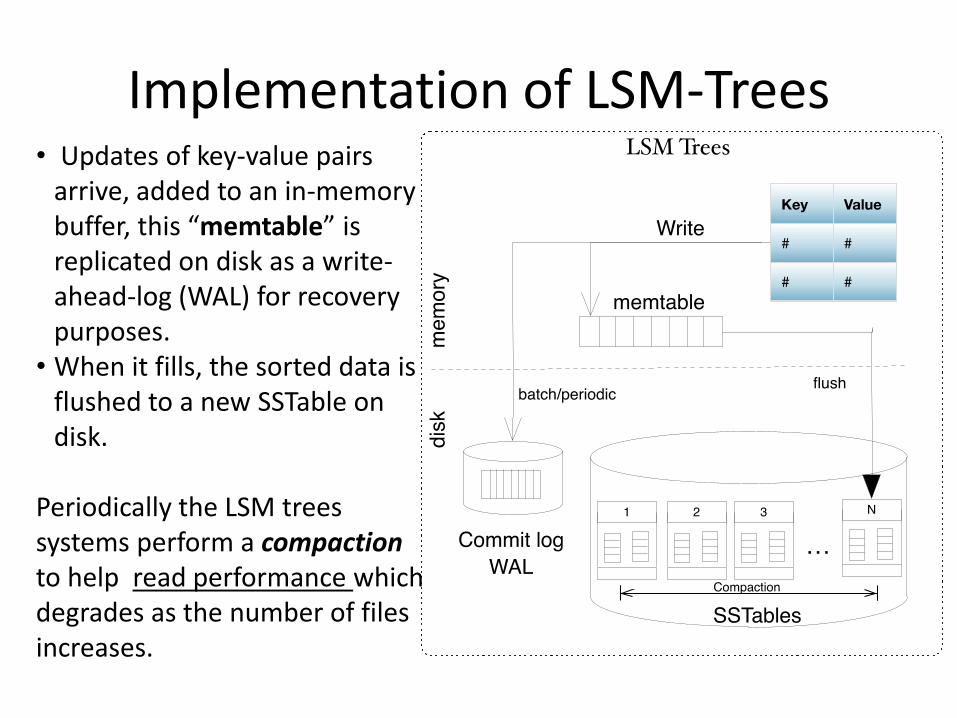
Implementation of LSM-Trees • Updates of key-value pairs
arrive, added to an in-memory buffer, this “memtable” is replicated on disk as a write-ahead-log (WAL) for recovery purposes.
• When it fills, the sorted data is flushed to a new SSTable on disk.
Periodically the LSM trees systems perform a compaction to help read performance which degrades as the number of files increases.
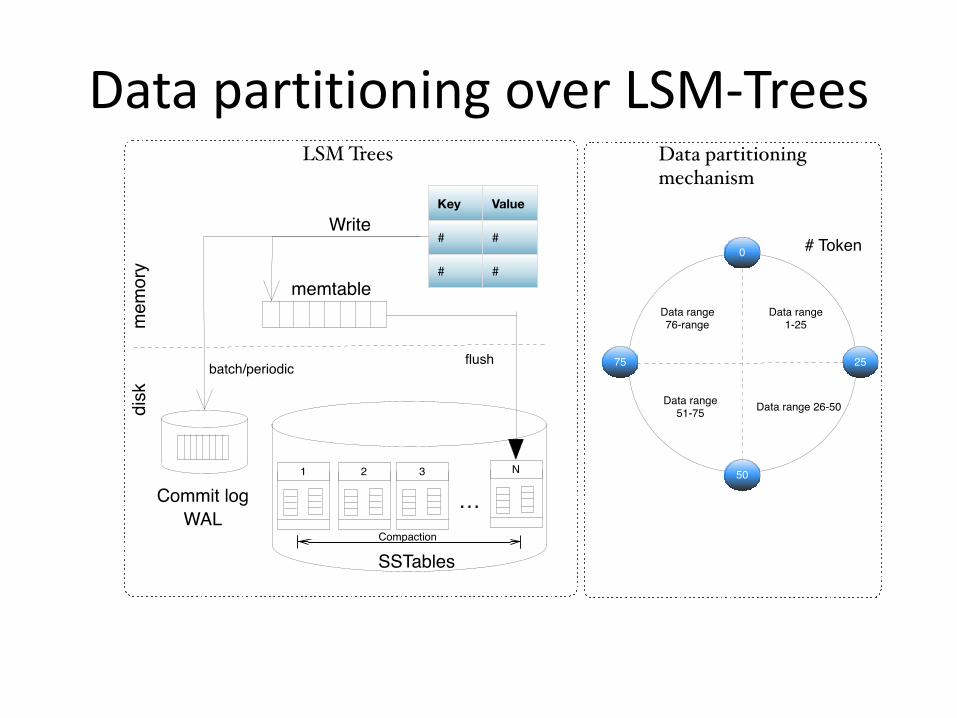
Data partitioning over LSM-Trees

Consistency

What is Consistency?

What is Consistency?
According to ACID Consistency is defined as the guarantee that :
any transactions started in the future necessarily see the effects of other transactions committed in the past
Database constraints are not violated, particularly once a transaction commits
Operations in transactions are performed accurately, correctly, and with validity, with respect to application semantics.
According to CAP
Atomic Consistency (or just Consistency) refers to a property of a single request/response operation sequence.

Consistency models
Consistency models define the guarantees the database provides about when concurrent writes become visible to readers. Strong consistency: after the update completes, any subsequent access
will return the updated value.
Weak consistency: a number of conditions need to be met before the updated value will be returned. Inconsistency window: the period between the update and the moment when it is guaranteed that any observer will always see the updated value. Eventual consistency: a specific form of weak consistency; if no new updates are made to the object, eventually all accesses will return the last updated value.

Consistency Limitations
Traditional replicated relational database systems focus on the problem of guaranteeing strong consistency of replicated data. Strong consistency provides the application writer a convenient programming model -> But: these systems are usually limited in scalability and availability. NoSQL databases provide eventual consistency

Consistency Vs Availability
Werner Vogels, the CTO of Amazon.com wrote[1] that "data inconsistency in large-scale reliable distributed systems has to be tolerated" to obtain the needed performance and availability.
[1] http://queue.acm.org/detail.cfm?id=1466448

Consistency Vs Performance
A consistency level involves determining requirements for consistent results:
i.e. always reading the most recently written data
Vs read or write latency:
the time it takes for the requested data to be returned or for the write to succeed.

Tunable Consistency
Cassandra extends the concept of eventual consistency by offering tunable consistency:
for any given read or write operation, the client decides consistency level of the requested data.
on a per-query basis, depending on users’ requirements for response time versus data accuracy.

Consistency in Cassandra
• Write Consistency
specifies on how many replicas the write must succeed before returning an ack to the client application.
• Read Consistency
specifies how many replicas must respond before a result is returned to the client application.
Strongest consistency level:
(nodes_written + nodes_read) > replication_factor

Linearizable Consistency
Cassandra v2.0 provides a linearizable consistency mode using an extension of the Paxos protocol to reach consensus at each insert or update request.
See more: http://www.datastax.com/dev/blog/lightweight-transactions-in-cassandra-2-0
As is validated by our experiments, this implementation (Cassandra Serial) incurs a significant performance penalty in write-intensive workloads.

So…
• Cassandra works perfect with applications that share its relaxed semantics! (i.e. shopping carts in online stores)
• But, what about traditional applications that require strong consistency guarantees?

How can we guarantee Strong
Consistency?

Our approach:
Combine LSM-Trees with a strongly-consistent primary-backup (PB) replication scheme
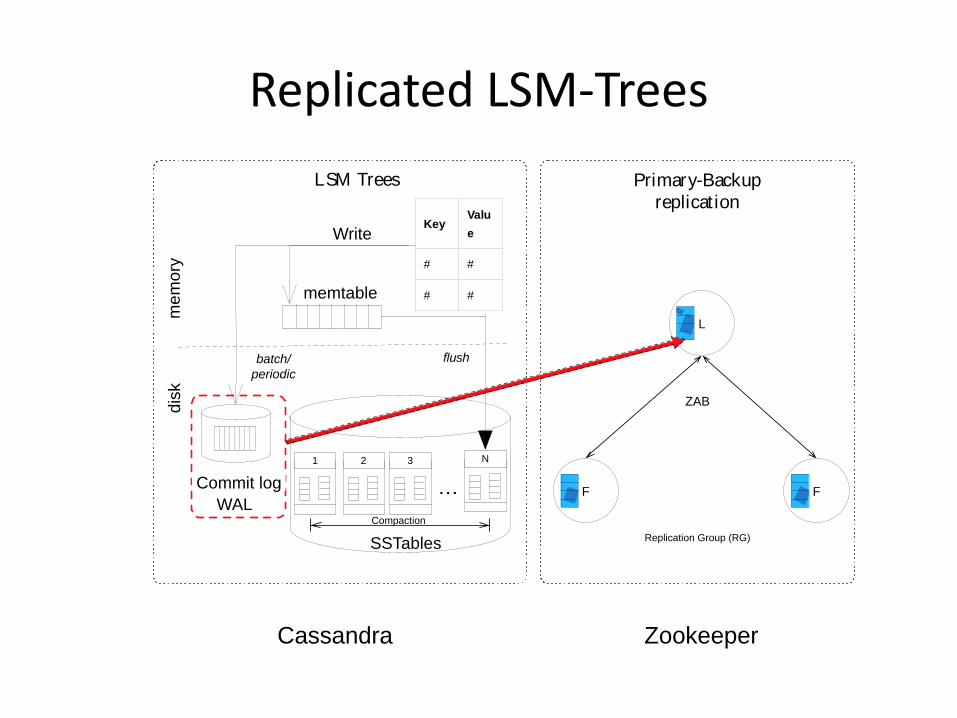
Replicated LSM-Trees
Primary-Backup
replicat ion
L
F F
ZAB
Replication Group (RG)SSTables
Write
#
Valu
e
#
#
Key
#
memtable
me
mo
ryd
isk
1 N2 3
…Commit log
flush
Compaction
LSM Trees
batch/
periodic
WAL
Cassandra Zookeeper

RG Architecture
ZooKeeper Atomic Broadcast (ZAB): Two-phase primary-backup atomic broadcast

Old Ring Architecture
Ring 2
3
1
4

New Ring Architecture
Ring 2
3
1
B
B
P
B B
P
B B
P
B
B
P
Replication Group 2
Replication Group 3
Replication Group 4
Replication Group 1
ZAB
ZAB
ZAB
ZAB
Each node is a
WAL Replica
with LSM tree

What about performance?
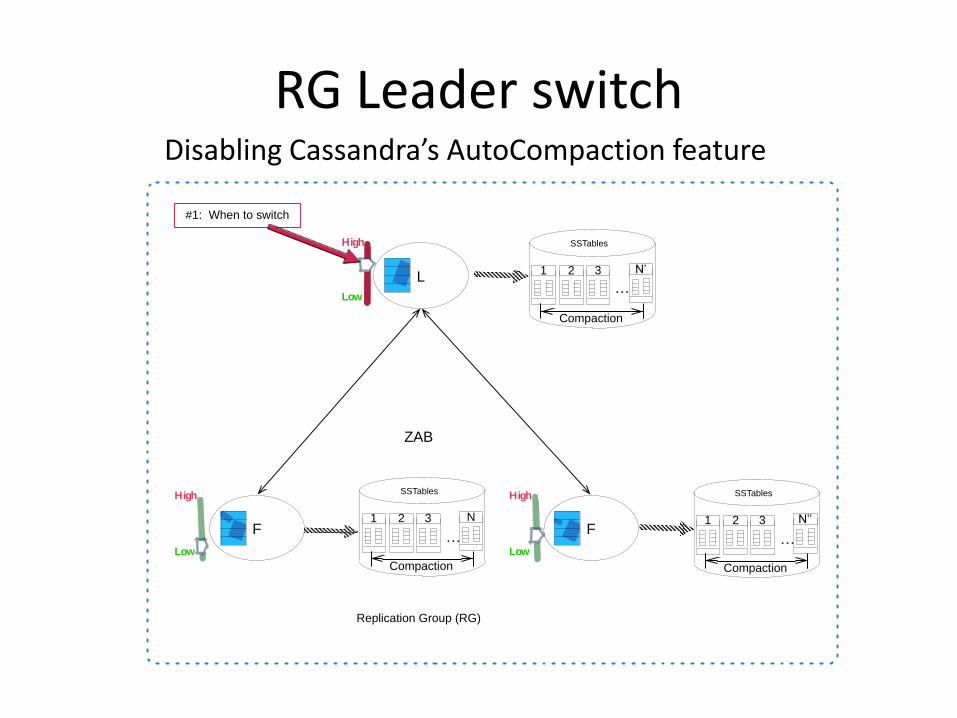
Primary-backup scheme requires read and write operations to go through a single master of the RG When LSM trees needs to be compacted it will hamper performance

Our approach:
Gain the control of LSM tree compactions
RG Leader switch
SSTables
1 N’2 3
…
Compaction
ACaZoo
L
F F
ZAB
Replication Group (RG)
SSTables
1 N’’2 3
Compaction
…
SSTables
1 N2 3
Compaction
…
High
Low
High
Low
#1: When to switch
High
Low
Disabling Cassandra’s AutoCompaction feature

RG leader switch policies
SSTables
1 N’2 3
…
Compaction
ACaZoo
L
F F
ZAB
Replication Group (RG)
SSTables
1 N’’2 3
Compaction
…
SSTables
1 N2 3
Compaction
…
High
Low
High
Low
#1: When to switch
High
Low
Weighted Votes
#2: Whom to elect
Compaction Vs new Leader Election
0
500
1000
1500
2000
2500
0 25 50 75 100 125 150 175 200
Wri
te T
hro
ugh
put
(op
s/1
00
ms)
Time (sec)
Smoothed Average Throughput
0
500
1000
1500
2000
2500
0 25 50 75 100 125 150 175 200
Wri
te T
hro
ugh
put
(op
s/1
00
ms)
Time (sec)
Smoothed Average Throughput
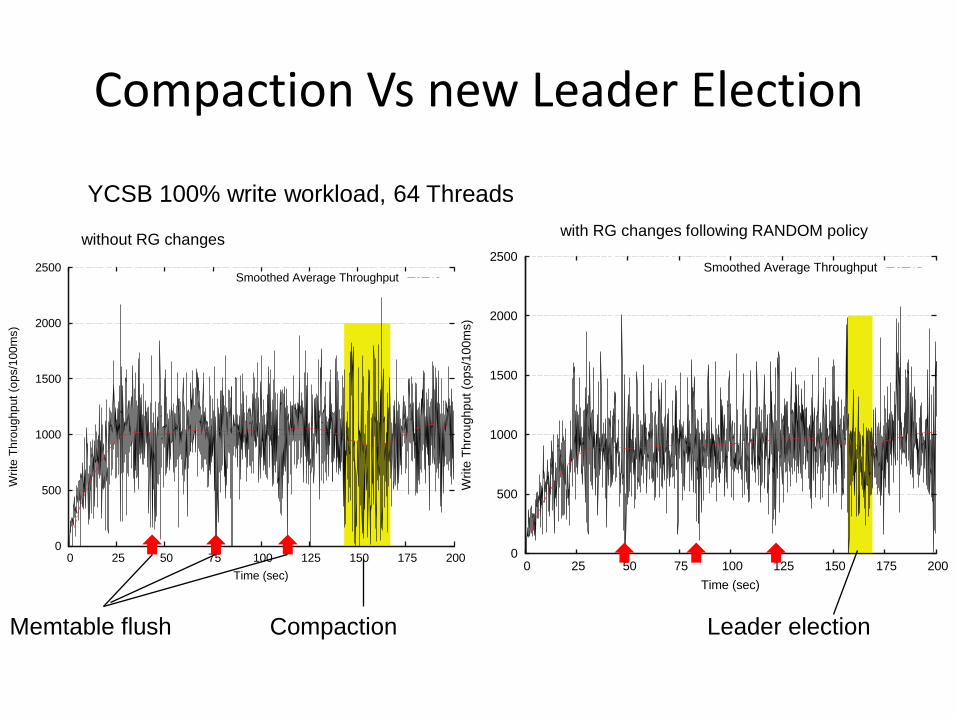
YCSB 100% write workload, 64 Threads
without RG changes with RG changes following RANDOM policy
Memtable flush Leader election Compaction

A deeper look into background activity
Count (#) Longest (sec) Average (sec) Total (sec)
Compaction (RA) 11 78.44 17.96 197.64
Memtable flush (RA) 53 - - -
Garbage Collection (RA) 197 0.91 0.148 29.33
Compaction (RR) 12 72.65 15.94 191.39
Memtable flush (RR) 52 - - -
Garbage Collection (RR) 192 0.85 0.147 27.84
YCSB 20min 100% write workload, 256 Threads RA : RG change random policy RR : RG round robin policy

3 Node RG
40%
25%
Consistent
Cassandra
Consistent
Cassandra -
RG Changes
Cassandra
Quorum
Oracle
NoSQL
Consistent
Cassandra
Consistent
Cassandra -
RG Changes
Cassandra
Serial
Cassandra
Quorum
Oracle
NoSQL
Consistent
Cassandra
Consistent
Cassandra -
RG Changes
Cassandra
Serial
Cassandra
Quorum
Oracle
NoSQL

Conclusions
• We were able to guarantee strong Consistency in Cassandra: – By combining the ZAB protocol with its implementation of LSM-Trees
– Key point: Replication of LSM-Tree WAL
• A novel technique that reduces the impact of LSM-Tree compactions on write performance – Changing leader prior heavy compactions: up to 40% higher throughput
For more details: Panagiotis Garefalakis, Panagiotis Papadopoulos and Kostas Magoutis ACaZoo: A Distributed Key-Value Store based on Replicated LSM-Trees. In Proceedings of 33rd IEEE Symposium on Reliable Distributed Systems (SRDS). October 2014, Nara, Japan.











![Abstract - School of Computing · In general, Internet services must make tradeoffs between performance, consistency, and availability to meet application requirements [8]. Thus,](https://static.documents.pub/doc/80x56/603877c1f4dbee5ff9072307/abstract-school-of-computing-in-general-internet-services-must-make-tradeoffs.jpg)






