20
Challenges in developing names services Nicky Nicolson, RBG Kew @nickynicolson Research Data Alliance Plenary 5, San Diego 9-11 March 2015

Challenges in developing names services
Nicky Nicolson, RBG Kew
@nickynicolson
Research Data Alliance Plenary 5, San Diego 9-11 March 2015

How the data are assembled
- Dedicated, long running indexing effort
- Initiated by Darwin c 1885

Indexers scan journals (and books, and e-journals...)

Locate nomenclatural acts...


Extract and structure the data

Data are annotated immediately


Summary
• Created structured, standardised, annotated data
• Data can be the “fuel” for names services
• How to ensure that the creators / annotators get credit?
– Attribution
– Usage metrics
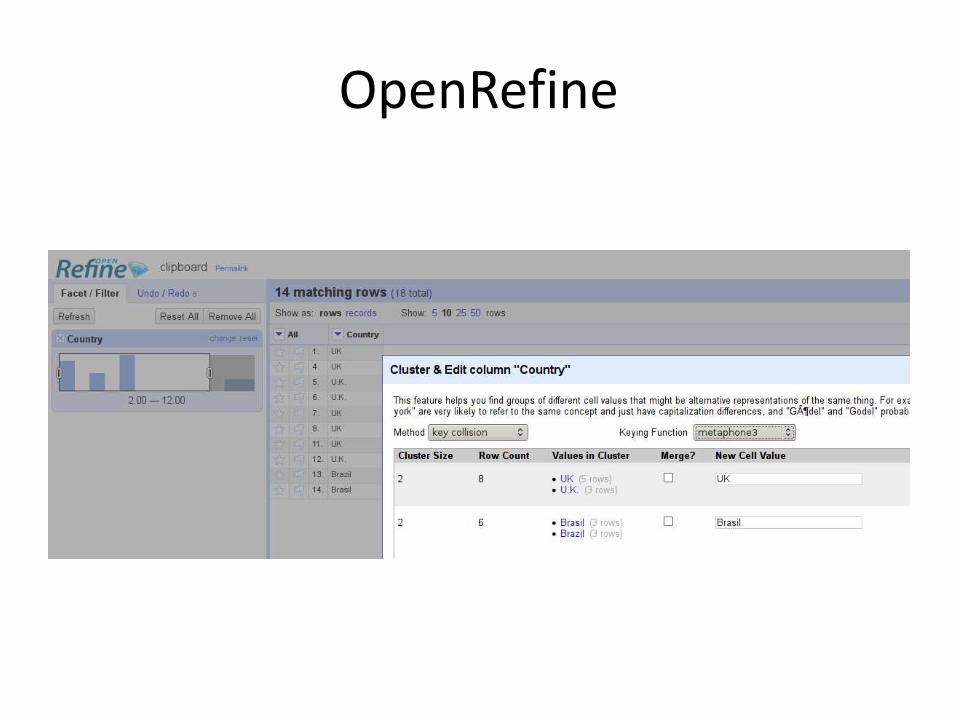
OpenRefine




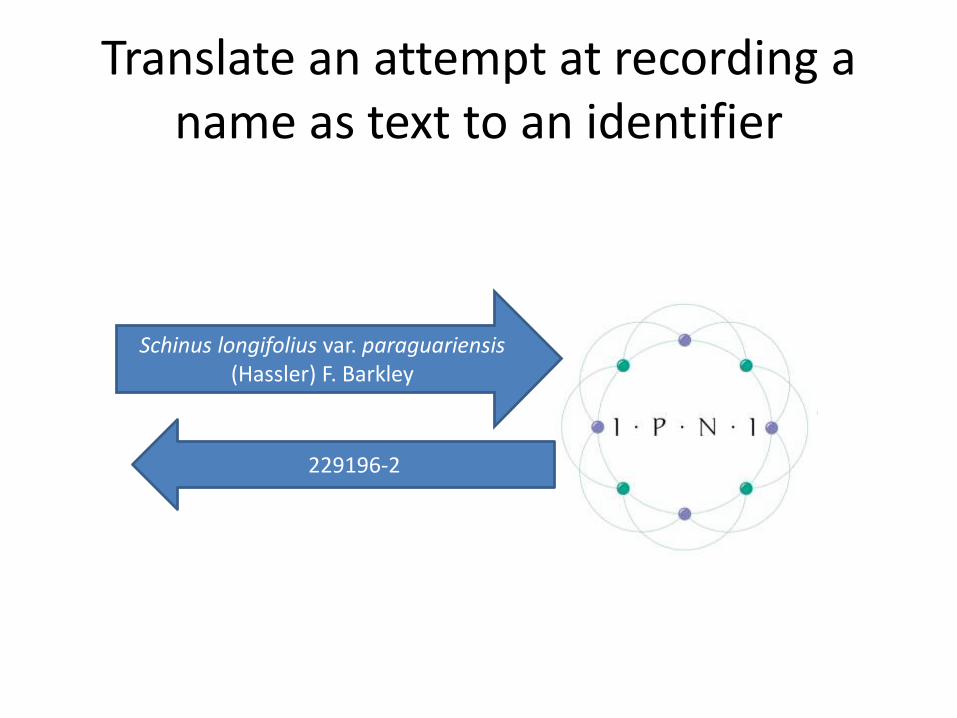
Translate an attempt at recording a name as text to an identifier
Schinus longifolius var. paraguariensis(Hassler) F. Barkley
229196-2
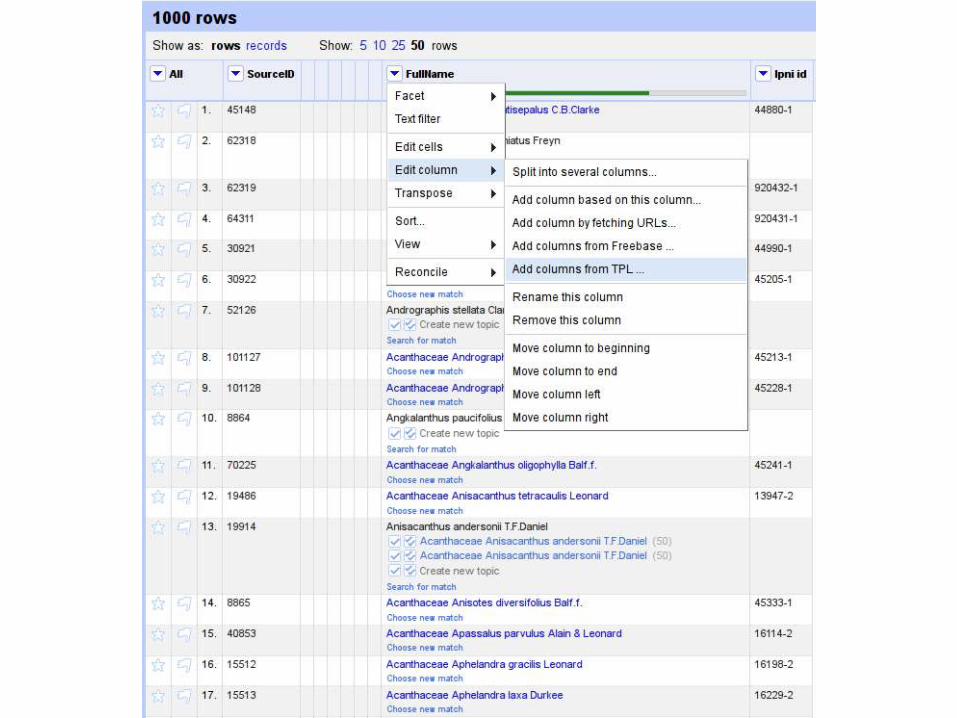

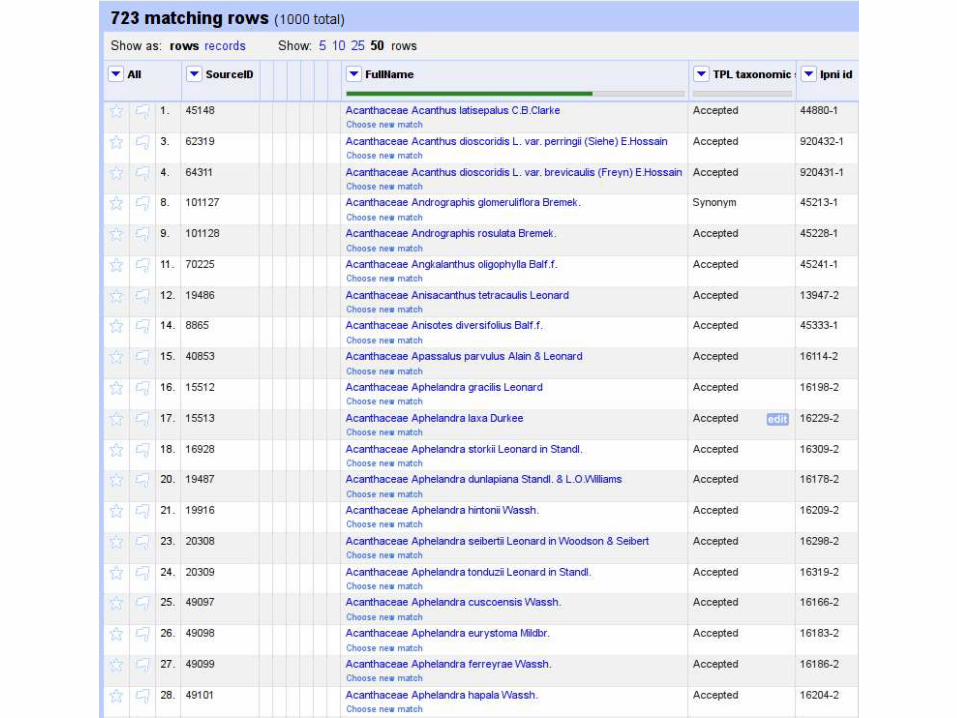

We need to know how the data are being used...
... To ensure the workers who scan, structure, annotate the data get credit for their work,
and metrics on its downstream use.
Google Analytics for services?


















