40
Chapter 15 Learning from Categorical Data Created by Kathy Fritz
| Date post: | 30-Dec-2015 |
| Category: |
Documents |
| Upload: | honorato-pearson |
| View: | 25 times |
| Download: | 0 times |

Chapter 15
Learning from Categorical Data
Created by Kathy Fritz

Chi-Square Tests for Univariate Categorical Data

Univariate Categorical Data
Univariate categorical data arise in a variety of settings.
The number of different categories, k, are the possible values for the categorical variable.
Univariate categorical data are usually summarized in a one-way frequency table, displayed either horizontally or vertically.
For example, each person in a sample of 100 registered voters in a particular city might be
asked which of five city council members he or she favors for mayor. The variable of interest
is the favored candidate and it has 5 categories.

Notation
k = number of categories of a categorical variablep1 = population proportion for Category 1
p2 = population proportion for Category 2
pk = population proportion for Category k
Note:p1 + p2 + + pk = 1
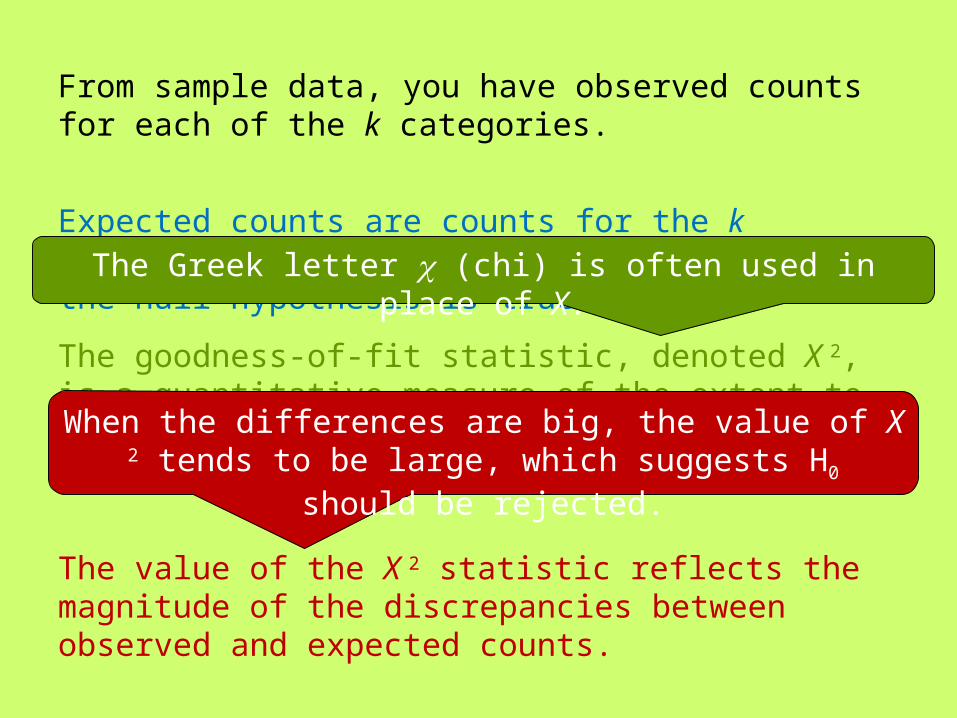
From sample data, you have observed counts for each of the k categories.
Expected counts are counts for the k categories that you would expect to have, if the null hypothesis is true.
The goodness-of-fit statistic, denoted X 2, is a quantitative measure of the extent to which the observed counts differ from those expected when H0 is true.
The value of the X 2 statistic reflects the magnitude of the discrepancies between observed and expected counts.
The Greek letter c (chi) is often used in place of X.
When the differences are big, the value of X 2 tends to be large, which suggests H0 should be rejected.

There are many different chi-square distributions. Each one has a different number of degrees of freedom.
A chi-square distribution curve is not symmetric, with a longer tail on the right. It has no area associated with negative values.
Chi-Square Distributions
Df = 3
Df = 5
Df = 10

For a test procedure based on X 2, the associated P-value is the area under the appropriate chi-square curve and to the right of the computed X 2 value.
For example, for a chi-square distribution with df = 4, the area to the right of X 2 = 8.18 is 0.085.
Chi-Square Distributions
The area to the right of a X 2 value can be found in Table 5. It can also be found using a statistical
software package or a graphing calculator.

Chi-Square Goodness-of-Fit TestAppropriate when the following conditions are
met:1. Observed cell counts are based on a random
sample or a sample that is representative of the population
When these conditions are met, the following test statistic can be used:
When the null hypothesis is true, the X 2 statistic has a chi-square distribution with df = k – 1, where k is the number of category proportions specified in the null hypothesis.
2. The sample size is large. The sample size is large enough for the chi-square goodness-of-fit test to be appropriate if every expected cell count is at least 5.
Expected count = n (hypothesized proportion for category)

Hypotheses H0: p1 = hypothesized proportion for Category 1
p2 = hypothesized proportion for Category 2
pk = hypothesized proportion for Category k
Ha: H0 is not true. At least one of the population category proportions differs from the corresponding hypothesized value.
Associated P-valuesThe P-value is the area to the right of X 2 under the chi-square curve with df = k – 1.
Chi-Square Goodness-of-Fit Test

A study investigated whether people can tell the difference between dog food, pâté (a spread made of finely chopped liver, meat, or fish), and processed meats (such as Spam and liverwurst).
Researchers used a food processor to make spreads that had the same texture and consistency as pâté from Newman’s own brand dog food and from the processed meats. Each participant in the study tasted the five spreads (duck liver pâté, Spam, dog food, pork liver pâté, and liverwurst). After tasting all five spreads, each participant was asked to choose the one that they thought was the dog food. The data are summarized in the one-way table below.
Spread Chosen as Dog Food
Duck Liver Pâté Spam Dog Food Pork Liver
Pâté Liverwurst
Frequency 3 11 8 6 22
You can use these data to test the hypothesis that the five different spreads are chosen equally often when people who have tasted all five spreads are asked to identify the one they think is dog food.

p1 = proportion al all people who would choose duck liver pâté as the dog food
p2 = proportion al all people who would choose Spam as the dog food
p3 = proportion al all people who would choose dog food as the dog food
p4 = proportion al all people who would choose pork liver pâté as the dog food
p5 = proportion al all people who would choose liverwurst as the dog food
Step 1 (Hypotheses):The population category proportions are defined as
Hypotheses:H0: p1 = p2 = p3 = p4 = p5 = 0.20Ha: At least one of the population proportions is not 0.20Step 2: (Method):Because the answers to the four key questions are 1) hypothesis testing, 2) sample data, 3) one categorical variable with more than 2 categories, and 4) one sample, a chi-square goodness-of-fit test is considered. When the null hypothesis is true, this statistic has approximately a chi-square distribution with df = 4. A significance level of a = 0.05 will be used for this test.

Step 3 (Check):• You must be willing to assume that the participants in
this study can be regarded as a random or representative sample.
Step 4: (Calculate):Test Statistic:
• Because the sample size is 50, all expected counts are 50(0.20) = 10. All expected counts are at least 5,so the sample size is large enough.
If this assumption is not reasonable, you should be very careful generalizing results from this
analysis to any larger population.
Degrees of freedom: k – 1 = 5 – 1 = 4
Associated P-Value:P-value = area under chi-square curve to the right of 21.4 < 0.001

Step 5 (Communicate Results):
Because the P-value is less than the selected significance level, the null hypothesis is rejected.
Based on these data, there is convincing evidence that the proportion identifying a spread as dog food is not the same for all five spreads.
So, although you reject H0, it is not because people were actually able to identify which one was really dog food.
Here, it is interesting to note that the large differences between observed counts and the counts that would have been expected if the null hypothesis of equal proportions were true are in duck liver pâté and the liverwurst categories, indicating that fewer than expected chose the duck liver and many more than expected chose liverwurst.
From this plot, it is easy to see the
two categories that differ the most from the
expected amount.

Tests for Homogeneity and Independence in a Two-Way Table

Bivariate categorical data results from observations made on two different categorical variables in a single sample.Suppose a researcher wishes to know whether there is any relationship between political philosophy (liberal, moderate, or conservative) and preferred news network for people who regularly watch the national news.Bivariate categorical data are usually summarized in a two-way frequency table.
There is a cell in the table for each possible combination of the category values.
The number times each particular combination occurs in the data set is entered in the corresponding cell of the table. These are called observed counts.
There are two categorical variables – political philosophy and preferred new network.
Two values (one for each variable) would be recorded for each person in the study.
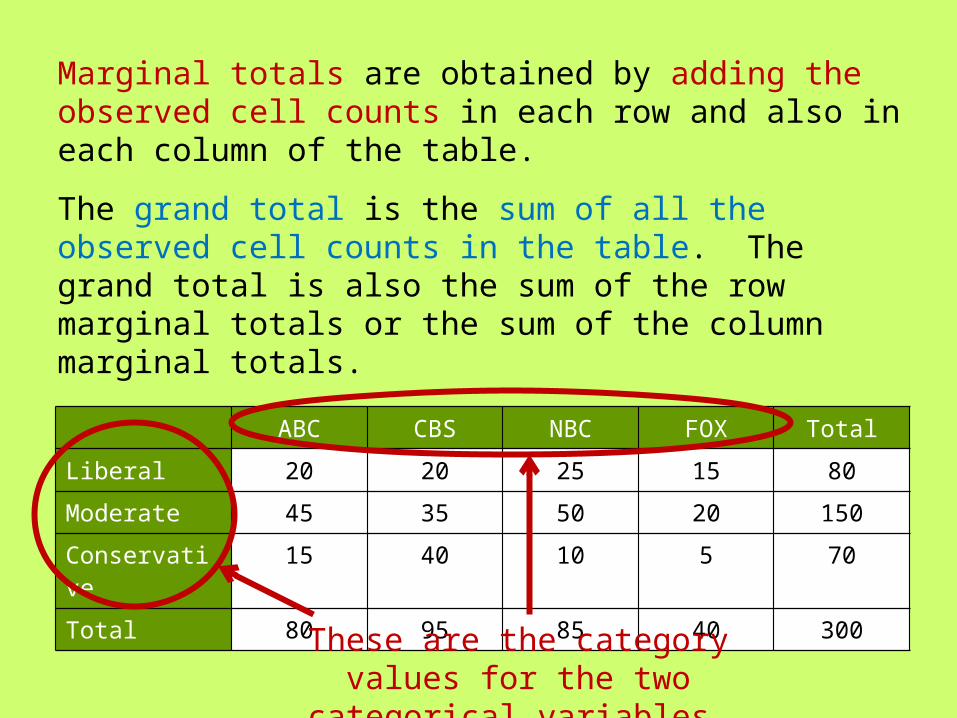
Marginal totals are obtained by adding the observed cell counts in each row and also in each column of the table.
ABC CBS NBC FOX Total
Liberal 20 20 25 15 80
Moderate 45 35 50 20 150
Conservative
15 40 10 5 70
Total 80 95 85 40 300
The grand total is the sum of all the observed cell counts in the table. The grand total is also the sum of the row marginal totals or the sum of the column marginal totals.
These are the category values for the two categorical variables.
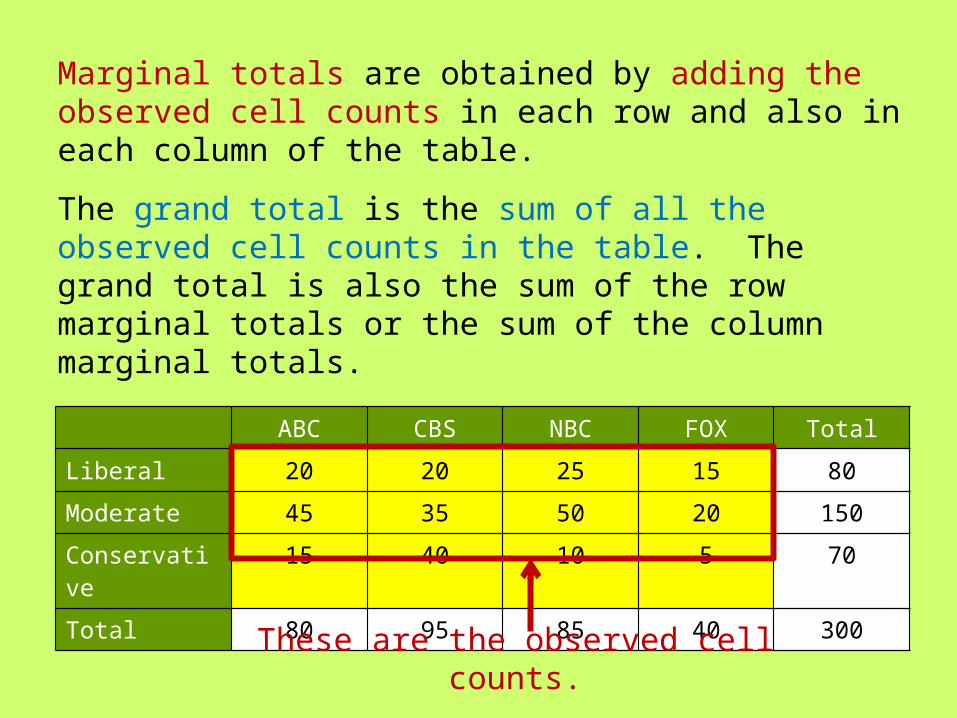
Marginal totals are obtained by adding the observed cell counts in each row and also in each column of the table.
ABC CBS NBC FOX Total
Liberal 20 20 25 15 80
Moderate 45 35 50 20 150
Conservative
15 40 10 5 70
Total 80 95 85 40 300
The grand total is the sum of all the observed cell counts in the table. The grand total is also the sum of the row marginal totals or the sum of the column marginal totals.
These are the observed cell counts.

Marginal totals are obtained by adding the observed cell counts in each row and also in each column of the table.
ABC CBS NBC FOX Total
Liberal 20 20 25 15 80
Moderate 45 35 50 20 150
Conservative
15 40 10 5 70
Total 80 95 85 40 300
The grand total is the sum of all the observed cell counts in the table. The grand total is also the sum of the row marginal totals or the sum of the column marginal totals.
These are the marginal totals.

Marginal totals are obtained by adding the observed cell counts in each row and also in each column of the table.
ABC CBS NBC FOX Total
Liberal 20 20 25 15 80
Moderate 45 35 50 20 150
Conservative
15 40 10 5 70
Total 80 95 85 40 300
The grand total is the sum of all the observed cell counts in the table. The grand total is also the sum of the row marginal totals or the sum of the column marginal totals.
This is the grand total.

Two-way tables are also used when data are collected to compare two or more populations or treatments on the basis of a single categorical variable.
Sample of 200 students
Sample of 100 faculty
Sample of 150 staff
In this situation, independent samples are selected from each population or treatment.
For example, data could be collected at a university to compare students, faculty, and staff on the basis of primary mode of transportation to campus (car, bicycle, motorcycle, bus, or by foot).
For each individual in the three independent samples, ONLY one value is recorded – mode of transportation to
campus.

Chi-Square Test for Homogeneity
Appropriate when the following conditions are met:
1. Observed counts are from independently selected random samples or subjects in an experiment are randomly assigned to treatment groups.
2. The sample sizes are large. The sample size is large enough for the chi-square test for homogeneity if every expected count is at least 5.
If some expected counts are less than 5, rows or columns of the table may be combined to achieve a table with satisfactory expected counts.

When these conditions are met, the following test statistic can be used:
Chi-Square Test for Homogeneity
The expected cell counts are estimated from the sample data using the formula
When the conditions above are met and the null hypothesis is true, the X 2 statistic has a chi-square distribution with
df = (number of rows – 1)(number of columns – 1)

Associated P-value: The P-value associated with the computed test statistic value is the area to the right of X 2 under the chi-square curve with
df = (number of rows – 1)(number of columns – 1)
Hypothesis:
H0: the population (or treatment) category proportions are the same for all the populations or treatments
Ha: the population (or treatment) category proportions are not all the same for all the populations or treatments
Chi-Square Test for Homogeneity

A study was conducted to determine if collegiate soccer players had in increased risk of concussions over other athletes or students. The two-way frequency table below displays the number of previous concussions for students in independently selected random samples of 91 soccer players, 96 non-soccer athletes, and 53 non-athletes.Number of Concussions
0 1 2 3 or more
Total
Soccer Players 45 25 11 10 91
Non-Soccer Players 68 15 8 5 96
Non-Athletes 45 5 3 0 53
Total 158 45 22 15 240
This is univariate categorical data - number of concussions - from 3
independent samples.

A study was conducted to determine if collegiate soccer players had in increased risk of concussions over other athletes or students. The two-way frequency table below displays the number of previous concussions for students in independently selected random samples of 91 soccer players, 96 non-soccer athletes, and 53 non-athletes.Number of Concussions
0 1 2 3 or more Total
Soccer Players 45 (59.9) 25 (17.1) 11 (8.3) 10 (5.7) 91
Non-Soccer Players 68 (63.2) 15 (18.0) 8 (8.8) 5 (6.0) 96
Non-Athletes 45 (34.9) 5 (10.0) 3 (4.9) 0 (3.3) 53
Total 158 45 22 15 240
The expected counts are shown in parentheses. Notice that two of the
expected counts are less than 5.
Combine the category values “2 concussions” and “3 or more concussions” to create the category value “2 or more
concussions)

Risky Soccer Continued . . .Number of Concussions
0 1 2 or more
Total
Soccer Players 45 (59.9) 25 (17.1) 21 (14.0) 91
Non-Soccer Players 68 (63.2) 15 (18.0) 13 (14.8) 96
Non-Athletes 45 (34.9) 5 (10.0) 3 (8.2) 53
Total 158 45 37 240
Step 1 (Hypotheses):
H0: Proportions in each head injury category are the same for all three groups.
Ha: The head injury category proportions are not all the same for all three groups.

Risky Soccer Continued . . .
Step 2 (Method):
This is a hypothesis testing problem. Random samples from three different populations were independently selected. The response is categorical. In this situation, you should consider a chi-square test of homogeneity.
A significance level of 0.05 will be used in this example.Step 3 (Check):
Because the samples were independent random samples and the expected counts are all at least 5, the chi-square of homogeneity is appropriate.

Risky Soccer Continued . . .
Step 4 (Calculate):
Step 5 (Check):Because the P-value is less than 0.05, H0 is rejected.
There is strong evidence that the proportions in the head injury categories are not the same for the three groups compared.
Df = (number of rows – 1)(number of columns – 1) = (3 – 1)(3 – 1) = 4P-value: The P-value is the area to the right of 20.6 under the chi-square curve with df = 4. P-value < 0.001
The largest differences between the observed and expected frequencies occur in the response
categories for soccer players and for non-athletes, with soccer players having higher than expected
proportions in the one and two or more head injuries categories.

Chi-Square Test for IndependenceAppropriate when the following conditions are
met:
1. Observed counts are from a random sample.2. The sample size is large. The sample size is large
enough for the chi-square test for independence if every expected count is at least 5.
If some expected counts are less than 5, rows or columns of the table may be combined to achieve a table with satisfactory expected counts.

When these conditions are met, the following test statistic can be used:
Chi-Square Test for Independence
The expected cell counts are estimated from the sample data using the formula
When the conditions above are met and the null hypothesis is true, the X 2 statistic has a chi-square distribution with
df = (number of rows – 1)(number of columns – 1)

Associated P-value: The P-value associated with the computed test statistic value is the area to the right of X 2 under the chi-square curve with
df = (number of rows – 1)(number of columns – 1)
Hypothesis:
H0: the two variables are independent
Ha: the two variables are not independent
Chi-Square Test for Independence
The main difference between the chi-square test of homogeneity and the chi-square test of
independence is the hypotheses.The hypotheses of the homogeneity test is to
determine if the populations’ proportions are the same, while the hypotheses of the independence test
is to determine if a relationship exists between the two variables.

A paper examined the relationship between a nurse’s assessment of a patient’s facial expression and the patient’s self-reported level of pain.
Because patients with dementia do not always give a verbal indication that they are in pain, the authors of the paper were interested in determining if there is an association between facial expression that reflects pain and self-reported pain.
Data for 89 patients are summarized in the table below.
Self-Report
Facial Expression No Pain Pain
No Pain 17 40
Pain 3 29

Step 1 (Hypotheses):
H0: Facial expression and self-reported pain are independent
Ha: Facial expression and self-reported pain are not independent
Step 2 (Method):
You should consider a chi-square test of independence because the answers to the four key questions are hypothesis testing, sampling data, two categorical variables, and one sample.
df = (2 – 1)(2 – 1) = 1
A significance level of 0.05 will be used for this test.
Dementia Patients Continued . . .

Step 3 (Check):
The expected counts are shown below.
Self-Report
Facial Expression No Pain Pain
No Pain 17 (12.81) 40 (44.19)
Pain 3 (7.19) 29 (24.81)
• All of the expected counts are greater than 5, so the sample size is large enough.
• Although the participants in the study were not randomly selected, they were thought to be representative of the population of nursing home patients with dementia.
Dementia Patients Continued . . .

Dementia Patients Continued . . .
Step 4 (Calculate):
Step 5 (Check):Because the P-value is less than 0.05, H0 isrejected. There is convincing evidence of an association between a nurse’s assessment of facial expression and self-reported pain.
P-value: The P-value is the area to the right of 4.92 under the chi-square curve with df = 1. P-value ≈ 0.025

Avoid These Common Mistakes

Avoid These Common Mistakes
1. Don’t confuse tests for homogeneity with tests for independence. The hypotheses and conclusions are different for the two types of test.
Tests for homogeneity are used when the individuals in each of two or more independent samples are classified according to a single categorical variable.
Tests for independence are used when individuals in a single sample are classified according to two categorical variables.

Avoid These Common Mistakes
2. Remember that a hypothesis test can never show strong support for the null hypothesis.
For example, if you do not reject the null hypothesis in a chi-square test for independence, you cannot conclude that there is convincing evidence that the variables are independent. You can only say that you were not convinced that there is an association between the variables.

Avoid These Common Mistakes
3. Be sure that the conditions for the chi-square test are met.
P-values based on the chi-square distribution are only approximate, and if the large sample condition is not met, the actual P-value may be quite different from the approximate one based on the chi-square distribution.
Also, for the chi-square test of homogeneity, the assumption of independent samples is particularly important.

Avoid These Common Mistakes
4. Don’t jump to conclusions about causation. Just as a strong correlation between two numerical variables does not mean that there is a cause-and-effect relationship between them, an association between two categorical variables does not imply a causal relationship.

















