24
110 CHAPTER-5 ENTROPY APPROACH TO DATA ANALYSIS

110
CHAPTER-5
ENTROPY APPROACH TO DATA ANALYSIS

111
5.1 Introduction
Nonlinear dynamical analysis is a powerful approach to understanding
financial systems. The calculations, however usually require very long data
sets that can be difficult or impossible to obtain. Pincus devised the theory and
method for a measure of regularity closely related to the kolmogorov entropy,
the rate of generation of new information that can be applied to the typically
short and noisy time series of clinical data. This family of statistics, named
approximate entropy (ApEn) [4] is rooted in the work of Grassberger and
Procaccia and Eckmann and Ruelle and has been widely applied in clinical
cardiovascular studies.
The method examines time series for similar epochs: more frequent and
more similar epochs lead to lower values of ApEn . Informally, given N points,
the family of statistics ApEn (m , r , N) is approximately equal to negative
average natural logarithm of the conditional probability that the two sequences
that are similar for m points remains similar , that is within a tolerance r [3] ,
the next point. Thus a low value of ApEn reflects a high degree of regularty.
Importantly, the ApEn algorithm counts each sequence as matching itself, a
practice carried over from the work of Eckmann and Ruelle [5] to avoid the
occurrence of ln(0) in the calculations. This step has led to discussion of the
bias of ApEn. In practice, it is found that this bias causes ApEn to lack two
important expected properties. First, ApEn is heavily dependent on the record
length and is uniformly lower than expected for short records. Second, it lacks
relative consistency. That is, if ApEn of one data set is higher than that of
another, it should, but does not, remain higher for all conditions tested. This
shortcoming is particularly important, because ApEn has been repeatedly
recommended as a relative measure for comparing data sets [6].

112
The terminology and notation of Grassberger and Procaccia, Eckmann
and Ruelle, and Pincus can be employed in
describing techniques for
estimating the Kolmogorov entropy [21, 22] of a process represented by a time
series and the related statistics ApEn and SampEn. The parameters N, m, and r
must be fixed for each calculation. N is the length of the time series, m is the
length of sequences to be compared, and r is the tolerance for accepting
matches. It is convenient to set the tolerance as r × SD, the standard deviation
of the data set, allowing measurements on data sets with different amplitudes
to be compared. Throughout this work, all time series have been normalized to
have SD = 1.
Sample Entropy is a statistical measure proposed by Richman and
Moorman (2000) [18] which quantifies the variability of time-series by
comparing sequences of consecutive data points [17, 19, 20]. It provides a
measure of the regularity or predictability of a time-series (high sample
entropy is related to low predictability / high complexity)
Sample entropy is derived from the conditional probability that a
sequence of data points is within a certain tolerance range r for m steps. This
tolerance r is usually measured in units of the standard deviation (SD) of the
series. Hence sample entropy depends on the length of the data series N, the
length m of sequences to be compared and the tolerance range r to be
specified. However SampEn can‟t be used to distinguish between signals of
similar form but different frequency. A signal contains noise and has a certain
period is no more complex than the same quantity of data but with a different
periodicity. SampEn calculation was applied to methane (CH4) for a model
run of the chemistry-climate model (CCM).
SampEn statistics is developed to be free of the bias caused by self-
matching. The name refers to the applicability to time series data sampled from

113
a continuous process. In addition, the algorithm suggests ways to employ
sample statistics to evaluate the results, as explained
below.
There are two major differences between SampEn and ApEn statistics.
First, SampEn does not count self-matches. Discounting self-matches are
justified on the grounds that entropy is conceived as a measure of the rate of
information production, and in this context comparing data with themselves is
meaningless. Furthermore, self-matches are explicitly dismissed in the later
work of Grassberger and co-workers. Second,
SampEn does not use a
template-wise approach when estimating conditional probabilities. To be
defined, SampEn requires only that one template find a match of length m +
1.
Grassberger and Procaccia ,defined
Cm(r) = (N - m + 1)
- 1
1
1
mN
i
Cm
i(r),
(6.1)
the average of the C
mi(r) defined above. This
differs from
m(r) only in that
m(r) is the average of the natural logarithms of the C
mi(r).
They suggest
approximating the Kolmogorov entropy of a process represented by a time
series by
limr 0 limn limN - ln [C
m + 1(r)/ C
m(r)]
(6.2)
In this form, however, the limits render it unsuitable for the analysis of finite
time series with noise. Therefore two alterations are made to adapt it to this
purpose. First, it is followed their later practice in calculating correlation
integrals and did not consider self-matches when computing Cm(r). Second,

114
only the first N - m vectors of length m are considered, ensuring that, for
1 i N - m, xm(i) and xm + 1(i) are
defined.
It is defined Bm
i(r) as (N - m - 1)- 1
times the number of vectors xm( j) within r
of xm(i), where j ranges from 1 to N - m, and j
i to exclude self-matches. It is
then defined
Bm(r) = (N - m)
- 1
mN
i 1
Bm
i(r). (6.3)
Similarly, Am
i(r) may be defined as (N - m - 1)- 1
times the number of vectors
xm + 1( j) within r of xm + 1(i),
where j ranges from 1 to N - m ( j i), and set
Am(r) = (N - m)
- 1
mN
i 1
Am
i(r). (6.4)
Bm(r) is then the probability that two sequences will match for
m points,
whereas Am(r) is the probability that two sequences will match for
m + 1 points.
We then defined the parameter
SampEn(m, r) = limN {-ln [A
m(r)/ B
m(r)]},
(6.5)
which is estimated by the statistics
SampEn(m, r, N ) = -ln [A
m(r)/B
m(r)]. (6.6)
Where there is no confusion about the parameter r and the length m of
the template vector, we set
B = {[(N - m - 1)(N - m)]/2} B
m(r) (6.7)

115
and
A = {[(N - m - 1)(N - m)]/2} Am(r), (6.8)
so that B is the total number of template matches of length m and A is the total
number of forward matches of length m + 1. It noted that A/B = [A
m(r)]/B
m(r)],
so SampEn(m, r, N ) can be expressed as -ln (A/B).
The quantity A/B is precisely the conditional probability that two
sequences within a tolerance r for m points remain within r of each other at the
next point. In contrast to ApEn(m, r, N ), which calculates probabilities in a
template-wise fashion, SampEn(m, r, N ) calculates the negative logarithm of a
probability associated with the time series as a whole. SampEn(m, r, N ) is
defined except when B = 0, in which case no regularity has been detected, or
when A = 0, which corresponds to a conditional probability of 0 and an infinite
value of SampEn(m, r, N ). The lowest nonzero conditional probability that
this algorithm can
report is 2[(N - m - 1)(N - m)]-1
. Thus, the statistic
SampEn(m, r, N ) has ln (N - m) + ln (N - m - 1) - ln (2) as an upper bound,
nearly doubling ln (N - m), the dynamic range of ApEn(m, r, N).
SampEn is not defined unless template and forward matches occur and
is not necessarily reliable for small numbers of matches. The calculation of
SampEn(m, r, N ) has been reviewed as a process of sampling information
about regularity in the time series and used sample statistics to inform about
the reliability of the calculated result. For operational purposes,
it is assumed
that the sample averages follow a Student's td distribution, where d is the
number of degrees of freedom. It is obvious that the "true" average conditional
probability of the process is within SDt(B 1,0.975)/ of the sample average,
where SD is the sample standard deviation and tB 1,0.975 is the upper 2.5th
percentile of a t distribution with B - 1 degrees of freedom. The
size of the

116
confidence intervals depends on the number B and the number of forward
matches. Informally, large confidence intervals around SampEn(m, r, N )
indicate that there are insufficient data to estimate the conditional probability
with confidence for that choice of m and r. In addition, confidence intervals
allow standard statistical tests of the significance of differences between data
sets.
Because of the logarithms inside the summation, m(r)(v u) will not
generally be equal to m(r)(u v). Thus cross-ApEn(m, r, N )(v u) and its
direction conjugate cross-ApEn(m, r, N )(u v) are unequal in most
cases.
In defining cross-SampEn, it is convenient to set Bm
i(r)(v u) as (N- m)-1
times the number of vectors ym( j) within r of xm(i), where j ranges from 1 to
N - m.
It is then defined
Bm(r)(v u) = (N - m)
- 1
mN
i 1
B
mi(r)(v u). (6.9)
Similarly, it is set A
mi(r)(v u) as (N
- m)
- 1 times the number of vectors ym + 1(
j) within r of xm + 1(i), where j ranges from 1 to N - m.
It is then defined
Am(r)(v u) = (N - m)
-1
mN
i 1
Am
i(r)(v u). (6.10)
Finally, SampEn can be expressed in the form
SampEn(m, r, N )(v u) = -ln {[Am(r)(v u)]/ [B
m(r)(v u)]}.
(6.11)

117
Examining this definition for direction dependence, it is found that (N -
m) Bm
i(r)(v u) is the number of vectors from v within r of the ith template of
the series u. Summing over the templates, it is found that
mN
i 1
(N - m) Bm
i(r)(v
u) simply counts the number of pairs of vectors from the two series that
match within r. The number of pairs that match is clearly independent of which
series is the template and which is the target. Because the last summation is
equal to (N - m)2 B
m(r)(v u), it follows that B
m(r)(v u) is also direction
independent, implying that cross-SampEn(m,
r, N )(v u) = cross-
SampEn(m, r, N )(u v). It should be noted that cross-SampEn will be defined
provided that Am(r)(v u) 0. Cross-SampEn, on the other hand, requires only
that one pair of vectors in the two series match for m + 1
points.
It is obvious that SampEn statistics appear to be relatively consistent
over the family of processes, whereas ApEn statistics are not. Although we
believe that relative consistency should be preserved for processes for which
probabilistic character is understood, we see no general reason why ApEn or
SampEn statistics should remain relatively consistent for all time series and all
choices of parameters.
It is proposed as a general, but by no means exhaustive, explanation for
this phenomenon. SampEn is, in essence, an event-counting statistic, where the
events are instances of vectors being similar to one another. When these events
are sparse, the statistics are expected to be unstable, which might lead to a lack
of relative consistency. The value of SampEn(m, r, N ) is less than or equal
to
ln (B), the natural logarithm of the number of template matches.
If
SampEn(m, r, N )(S) < SampEn(m, r, N ) (T ) and the number of T's template
matches, BT, is less than the number of S's template matches, BS, which would
be consistent with T displaying less order than S. Provided that AT
and AS, the

118
number of forward matches, are relatively large, both SampEn statistics will be
considerably lower than their upper bounds. As r decreases, BT and AT
are
expected to decrease more rapidly than BS and AS. Thus, as BT becomes very
small, SampEn(m, r, N )(T ) will begin to decrease, approaching the value
ln (BT), and could cross over a graph of SampEn(m, r, N )(S), where or
while
BS is still relatively large. Furthermore, as the number of template matches
decreases, small changes in the number of forward matches can have a large
effect on the observed conditional probability. Thus the discrete nature of the
SampEn probability estimation could lead to small degrees of crossover and
intermittent failure of relative consistency, and it cannot be said that SampEn
will always be relatively consistent. It is obvious, however, that SampEn is
relatively consistent for conditions where ApEn is not, and it is not observed
any circumstance where ApEn maintains relative consistency and SampEn
does not.
5.2 Method for the calculation of SampEn
Consider a time series with many matching points (data) of length N.
Two data points are considered to be in matching if they are within the
tolerance window „r‟. Now the sequences of data points are matched. The
sequence length is „m‟. For m=2, the match of two data points is considered.
The total number of matches for a particular pair is counted & the process is
repeated for all the possible pairs.
Now the total number of two component matches from the series is added.
The first data point from the series is omitted i.e. now number of data points
are (N-m+1) where m=2. Then the above procedure is repeated. At last add the
total number of pairs of two components to the previous. Say it is „B‟.

119
Similarly pair of 3-components (m=3) by using above procedure is obtained.
Then all the possible 3-component pairs are added. Say it is „A‟.
Sample entropy is defined as the negative natural logarithm of the ratio of A &
B. So mathematically SampEn can be written as
SampEn (m , r , N) = -ln(A/B) (6.12)
5.3 Multi-Scale Entropy Analysis
MSE method is dependent of coarse-graining procedure. It incorporates two
steps.
Consider a given time series nix,........,x,x,xx
321
The length of the series is N. Then we construct consecutive coarse-grained
time series by averaging a successively increasing number of data points in
non-overlapping windows. Figure 5.1 shows a schematic illustration of the
coarse-graining procedure for scale 2 and 3. Each element of the coarse-
grained time series, is calculated accordingly to the equation
j
1)1j(i
i
)(
jx
1y
(6.13)
Where, τ represents the scale the factor and i ≤ j ≤ The length of each
coarse-grained time-series is N/τ. For scale one, the time series { y(1)
} is
simply the original time-series.
Finally, sample entropy (Samp En) is calculated for each coarse-grained time-
series, and then SampEn is plotted as a function of the scale-factor. Let
1mi1iimx...,,.........x,x)i(u 1 ≤i N-m
(6.14)

120
be vectors of length m. Let nim(r) represent the number of vectors Um(i) .
Within distance r of Um(i) where j range from 1 to (N-m) and j≠ 1 to exclude
self matches.
1mN
)r(n)r(c
imm
i
(6.15)
Is probability that any vector Um (i) is within tolerance range r of Um (i). We
then define
)r(clnmN
1)r(u
mN
1i
m
ii
m
(6.16)
The parameter Sample entropy (SampEn) is defined as
)(
)(ln),(
1
limru
rurmSampEn
m
m
N
(6.17)
For a Time Series of finite length (N), the sample entropy is estimated by
statistics,
)r(u
)r(uln)N,r,m(SampEn
m
1m
(6.18)

121
Sample entropy is the natural logarithm of the ratio of the total number of two
components templates matches to the total number of three components
templates matches.
For scale one, the value of entropy is higher for the white noise time series in
comparison to the 1/f noise.
This result explains the facts that the 1/f noise contains complex structures
across multiple scales in contrast to the white noise.

122
Scale 1: x1 x2 x3 x4 x5 x6 …..xi
xi+1
Scale 2: x1 x2 x3 x4 x5 x6 ……..xi xi+1
Y1 Y2 Y3 Yj =
Scale 3: x1 x2 x3 x4 x5 x6 ………… ..… xi xi+1 xi+2
Y1 Y2 Yj =
[Fig 5.1 Coarse graining procedure for time series data]

123
[Fig 5.2 Procedure for calculating sample entropy (SampEn) for the case in which the
pattern length, m, is 2, and the similarity criterion, r, is 20]

124
5.4 Data Analysis and Results
The data base of various sectoral indices of National Stock Exchange of India
from tt5 (Advance) of India Infoline Securities pvt. Limited. Daily closing
values of indices are taken from 17th
june 2003 to 9th feb 2010. Total no of data
points are taken to be 1623.
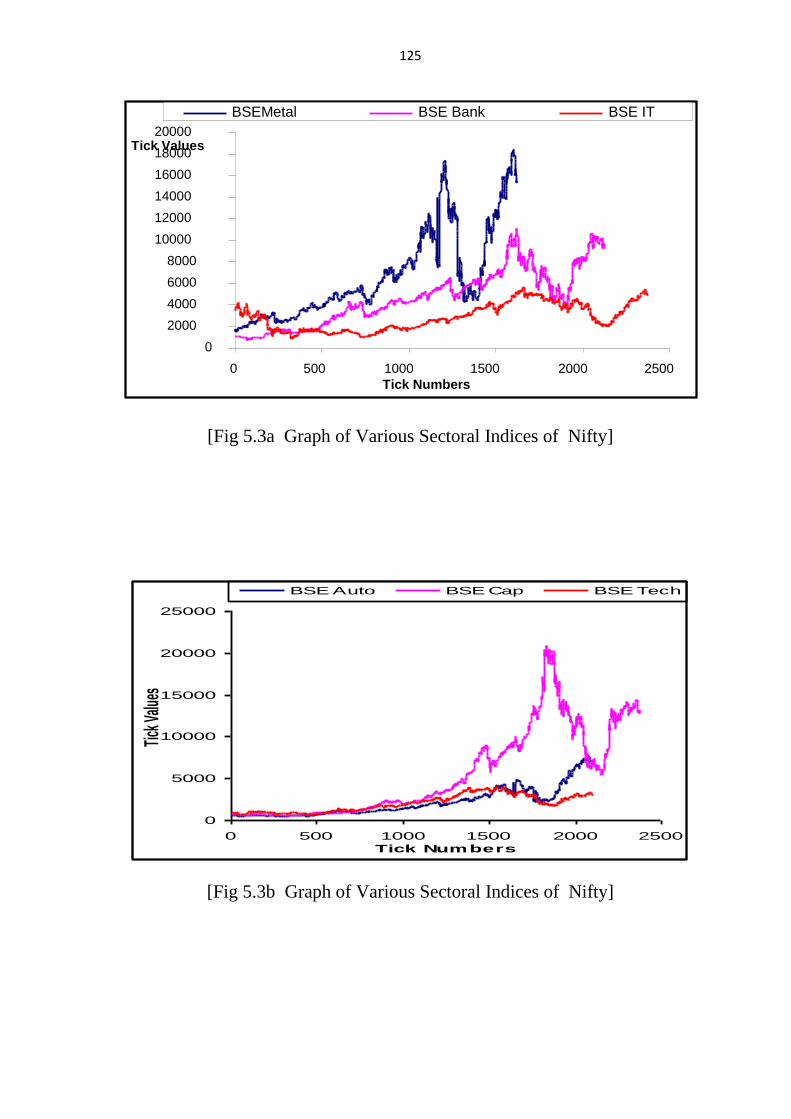
Figure 5.3(a) and 5.3(b) show the Graph of variation inVarious Sectoral
Indices of Nifty. Figure 5.4(a) and 5.4(b) show corresponding MSE Profile of
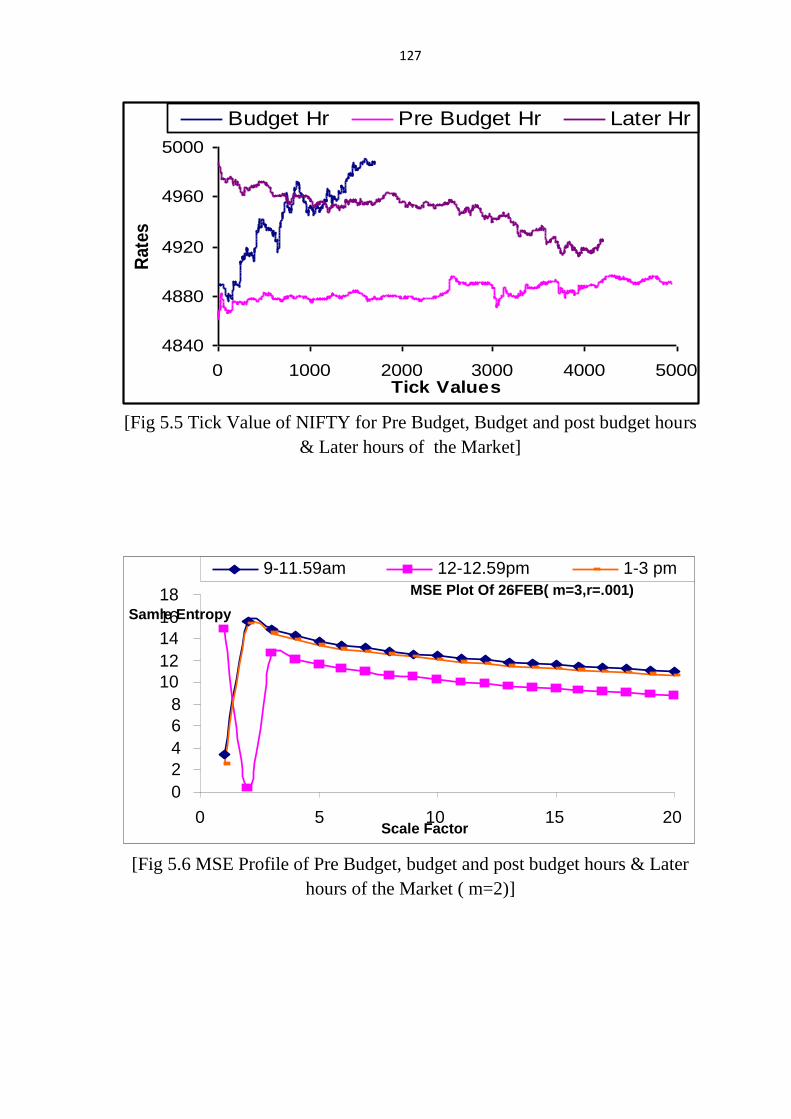
same Sectoral Indices. Fig 5.5 shows the variation of tick value of NIFTY for
pre budget hours, just after the budget announcement and at later hours of the
market. Figures 5.6 and 5.7 show the corresponding MSE profiles for m=2 and
m=3 values respectively. Figure 5.8 shows the variation in the tick value of
NIFTY for 24th
feb 2010 to 2 march 2010, in which there are two days of pre-
budget days, budget day, and one post- budget day. Fig 5.9(a) and 5.9(b) are
MSE Profiles of Pre Budget, Budget and post budget hours & Later hours of
the Market.
125
[Fig 5.3a Graph of Various Sectoral Indices of Nifty]
[Fig 5.3b Graph of Various Sectoral Indices of Nifty]
0
5000
10000
15000
20000
25000
0 500 1000 1500 2000 2500
Tick Numbers
Tick
Valu
es
BSE Auto BSE Cap BSE Tech
0
2000
4000
6000
8000
10000
12000
14000
16000
18000
20000
0 500 1000 1500 2000 2500 Tick Numbers
Tick Values
BSEMetal BSE Bank BSE IT

126
[Fig 5.4a MSE Profile of Sectoral Indices of BSE]
[Fig 5.4b MSE Profile of Sectoral Indices of BSE]
m=2 , r=0
6
8
10
12
14
16
0 10 20 30 40 50Scale Factor
Sam
ple
entro
py
BSE M BANKEX BSEIT
m=2, r=0
7
9
11
13
15
0 10 20 30 40 50Scale Factor
Sam
ple
Ent
ropy
BseAuto BseTech BsePsu BseCap.Goods
127
[Fig 5.5 Tick Value of NIFTY for Pre Budget, Budget and post budget hours
& Later hours of the Market]
[Fig 5.6 MSE Profile of Pre Budget, budget and post budget hours & Later
hours of the Market ( m=2)]
4840
4880
4920
4960
5000
0 1000 2000 3000 4000 5000Tick Values
Rate
sBudget Hr Pre Budget Hr Later Hr
MSE Plot Of 26FEB( m=3,r=.001)
0
2
4
6
8
10
12
14
16
18
0 5 10 15 20 Scale Factor
Samle Entropy
9-11.59am 12-12.59pm 1-3 pm

128
[Fig 5.7 MSE Profile of Pre Budget, Budget and post budget hours & Later
hours of the Market ( m=3)]
[Fig 5.8 Variation in the Tick value of NIFTY for 24th feb 2010 to 2 march
2010]
MSE Plot of 26 FEB (m=2,r=.001)
0
2
4
6
8
10
12
14
16
0 5 10 15 20Scale Factor
Sam
ple
Ent
ropy
9-11.59am 12-12.59pm 1-3 pm
4800
4850
4900
4950
5000
5050
0 2000 4000 6000 8000 10000 12000Tick Values
Rat
es
24-Feb 25-Feb 26-Feb 2-Mar

129
[Fig 5.9a MSE Profile of Tick value of NIFTY from 24th
feb 2010 to 2 march
2010]
[Fig 5.9b MSE Profile of Tick value of NIFTY from 24th
feb 2010 to 2
march 2010]
m=2,r= .001
0
2
4
6
8
10
12
14
16
18
0 5 10 15 20Scale Factor
Sam
ple
Ent
ropy
24-Feb 25-Feb 26-Feb 2-Mar
m=3, r= .001
0
2
4
6
8
10
12
14
16
18
0 5 10 15 20Scale Factor
Sam
ple
Entr
py
24-Feb 25-Feb 26-Feb 2-Mar

130
5.4 Discussion
Studies of the MSE profile of daily variations of different indices show
that the BSE Metal Index exhibit lower MSE pattern as compared to other
sectoral indices. This is due to the cyclical nature of the constituents of the
index. Thus a pattern emerging out of the cyclical nature gives rise to a lower
MSE pattern at all scales. All other indices show identical MSE pattern
indicating equivalent complexity levels of daily data. Similarly NIFTY tick
values [34, 35] are studied for pre budget hours, just after budget, and later
hours of market timing on the budget day. The MSE profile shows that the
entropy of market is the maximum at pre budge hours. The higher entropy
profile indicates higher entropy of the data. The index value of the budget and
post budget hours shows lower MSE profile showing low complexity, i.e.
higher degree of order. As the provisions of the budget were made public
market started interacting with the information showing lower MSE profile
indicating higher degree of order (low complexity).
Data of later hours again shows higher entropy profile [32] but still
having lower values of entropies at different scales than the pre budget hours.
However the same study performed on the NIFTY tick values for the period
from 24th
feb 2010 to 2nd
march 2010 in which there are two days of pre
budget, budget day and one post budget day, indicates that the difference
among their MSE profile disappear and their profiles converge showing the
identical behavior. This indicates that the market responds to receive
information with a higher degree of order and adjusts itself interacting with the
information. As the information has been received, the market behaves like an
isolated system with higher entropy. Multiscale entropy measurements could
be an effective alternative nonlinear approach for analyzing the stock market
data [33].

131
Limitations
The long-standing problem of deriving useful measures of time series
complexity is important for the analysis of financial, physical and biological
systems. MSE is based on the observation that the outputs of complex systems
are far from the extrema of perfect regularity and complete randomness.
Instead, they generally reveal structures with long-range correlations on
multiple spatial and temporal scales. These multiscale features, ignored by
conventional entropy calculations, are explicitly addressed by the MSE
method.
The complexity [31] is associated with the ability of financial systems to
adjust to an ever-changing environment, which requires integrative multiscale
functionality. In contrast, under free-running conditions, a sustained decrease
in complexity reflects a reduced ability of system to function in certain
dynamical regimes possibly due to decoupling or degradation of control
mechanisms. The MSE method requires an adequate length of data to provide
reliable statistics for the entropy measure on each scale. The minimum number
of data points required to apply the MSE method depends on the level of
accepted uncertainty. Another important consideration is related to
nonstationarity. To calculate SampEn , one has to fix the value of a parameter
that depends on the time series SD. Therefore, the results may be significantly
affected by nonstationarities , outliers , and artifacts. In contrast, attempts to
remove nonlocal nonstationarities , e.g.,trends , will most likely modify the
structure of the time series over multiple time scales. Thus, given the temporal
complexity of data on multiple scales, a novel technique, multiscale entropy,is
a robust measure of complexity [17].

132
5.5 References:
[1]. F.Takens, in Dynamical system and turbulence, edited by D.A.Rand and
L.S.Young. Lecture Notes in Mathematics vol.898, p.366, Springer,
Berlin(1981).
[2]. J.P. Eckmann and D. Ruelle, Rev.Mod.Phys. 57,617 (1985).
[3]. J.Theiler, S. Eubank, A. Longtin, B. Galdrikian, and J.D.Farmer,
Physica D 58, 77 (1992).
[4]. S. M. Pincus, Ann. N.Y. Acad. Sci. 954, 245 (2001), and references
therein.
[5]. P. Grassberger in Information Dynamics, edited by H.Atmanspacher and
H. Scheingraber , p. 15,Plenum, New York(1991).
[6]. B. Y. Yaneer, Dynamics of Complex System, Addison-Wesley,
Reading, Massachusetts(1997).
[7]. M.Costa, A. L.Goldberger, and C.-K. Peng, Phys. Rev. Lett. 89,
068102(2002).
[8]. M. Costa, A.L.Goldberger, and C.-K. Peng, Comput. Cardiol. 29, 137
(2002).
[9]. M. Costa and J. A. Healey, Comput. Cardiol. 30, 705 (2003).
[10]. M.Costa, A. L.Goldberger, and C.-K. Peng, Phys. Rev. Lett .92, 089804
(2004).
[11]. M. Costa, C.K. Peng, A.L. Goldberger, and J.M. Hausdorff, Physica A
330,53(2003).
[12]. C.E.Shannon, Bell Syst. Tech. j. 27, 379 (1948).
[13]. R. Shaw, Z. Naturforsch. A 36, 80 (1981).
[14]. D.E. Lake and R.J. Moorman ( private communication )
[15]. D.E. Lake, J.S. Richman, M.P. Griffin, and J.R. Moorman, Am. J.
Physiol. 283, R789 (2002).

133
[16]. J.E Mietus, C.K. Peng, I.Henry, R.L. Goldsmith, and A.L. Goldberger,
Heart 88, 378 (2002).
[17]. C.K. Peng, S.V. Buldyrev, A.L. Goldberger, S.Havlin, R.N. Mantegna,
M.E. Masta, C.K. Peng, M. Simons, and H.E. Stanley, Phys.Rev. E 51
, 5084 (1995).
[18]. P.Grassberger , T. Schreiber, and C. Schaffrath, Int.J.Bifurcation Chaos
Appl. Sci. Eng. 1, 521 (1991).
[19]. A.L. Goldberger, C.-K. Peng, and L. A. Lipsitz, Neurobiol. Aging 23,
23 (2002).
[20]. S.M. Pincus, I.M. Gladstone, and R.A. Ehrenkranz, J.Clin. Monit.
7,335(1991).
[21]. V.V.Nikulin and T. Brismar, Phys. Rev. Lett. 92, 089803(2004).
[22]. K.K.L.Ho, G.B. Moody, C.-K. Peng, J.E. Mietus, M.G. Larson, D.
Levy, and A.L. Goldberger, Circulation 96, 842(1997).
[23]. B.Audit, C. Thermes, C.Vaillant, Y.d‟Aubenton-Carafa, J.F. Muzy, and
A.Arnendo, Phys.Rev.Lett. 86, 2471 (2001).
[24]. L.A.Lettice et al., Proc. Natl. Acad. Sci. U.S.A. 99, 7548(2002).
[25]. M.A. Nobrega, I. Ovcharenco, V. Afzal, and E.M. Rubin, Science 302,
413 (2003).
[26]. J.S. Mattick, BioEssays 25, 930 (2003).
[27]. J.S. Mattick, EMBO Rep. 2, 986(2001).
[28]. (28) D.P. Feldman and J.P.Crutchfield , Phys. Lett. A 238, 244 (1998)
[29]. H.C. Fogedby, J.Stat. Phys. 69, 411(1992).
[30]. M.P. Paulus, M.A. Geyer, L.H. Gold, and A.J. Mandell, Proc.
Nalt. Acad. Sci. U.S.A. 87, 723 (1990).

















