Page 1
Architectural Specialization forInter-Iteration Loop Dependence Patterns
Christopher Batten
Computer Systems LaboratorySchool of Electrical and Computer Engineering
Cornell University
Spring 2015
Page 2
• Research Overview • XLOOPS: Explicit Loop Specialization PyMTL: Productive Hardware Modeling
Motivating Trends in Computer Architecture
Transistors(Thousands)
Frequency(MHz)
TypicalPower (W)
MIPSR2K
IntelP4
DECAlpha 21264
Data collected by M. Horowitz, F. Labonte, O. Shacham, K. Olukotun, L. Hammond, C. Batten
1975 1980 1985 1990 1995 2000 2005 2010 2015
100
101
102
103
104
105
106
SPECintPerformance
107
Numberof Cores
Intel 48-CorePrototype
AMD 4-CoreOpteron
• Data-Parallelism via
GPGPUs and Vector
• Fine-Grain Task-Level
Parallelism
• Instruction Set
Specialization
• Subgraph
Specialization
• Application-Specific
Accelerators
• Domain-Specific
Accelerators
• Coarse-Grain
Reconfig Arrays
• Field-Programmable
Gate Arrays
Specialization
Cornell University Christopher Batten 2 / 66
Page 3
• Research Overview • XLOOPS: Explicit Loop Specialization PyMTL: Productive Hardware Modeling
Performance (Tasks per Second)
En
erg
y E
ffic
ien
cy (
Ta
sks p
er
Joule
)
SimpleProcessor
Design PowerConstraint
High-PerformanceArchitectures
EmbeddedArchitectures
DesignPerformanceConstraint
Flexibility vs
. Spe
cializat
ion
CustomASIC
Less FlexibleAccelerator
More FlexibleAccelerator
Cornell University Christopher Batten 3 / 66
Page 4
• Research Overview • XLOOPS: Explicit Loop Specialization PyMTL: Productive Hardware Modeling
Vertically Integrated Research Methodology
Our research involves reconsidering all aspects of the computing stackincluding applications, programming frameworks, compiler optimizations,runtime systems, instruction set design, microarchitecture design, VLSI
implementation, and hardware design methodologies
CrossCompiler
FunctionalSimulator
Binary
Applications
Functional-LevelModel
Cycle-LevelSimulator
Cycle-LevelModel
Layout
Register-Transfer-Level Model
RTLSimulator
Gate-Level Model
Gate-LevelSimulator
Switching Activity
PowerAnalysis
SynthesisPlace&Route
Key Metrics: Cycle Count, Cycle Time, Area, Energy
Experimenting with full-chiplayout, FPGA prototypes, andtest chips is a key part of our
research methodology
Cornell University Christopher Batten 4 / 66
Page 5
• Research Overview • XLOOPS: Explicit Loop Specialization PyMTL: Productive Hardware Modeling
Projects Within the Batten Research Group
Apps
Algos
PL
ISA
uArch
RTL
VLSI
Circuits
Tech
Compiler
GPGPU
Architecture[ISCA'13]
[MICRO'14a]
Integrated
Voltage
Regulation[MICRO'14b]
XLOOPS
Explicit Loop
Specialization[MICRO'14c]
Polymorphic
Hardware
Specialization
Accelerating
Dynamic
Prog Langs
PyMTL/Pydgin
Frameworks[MICRO'14d]
[ISPASS'15]
PyMTL/Pydgin
Frameworks
XLOOPS
Explicit Loop
Specialization
PyMTL/Pydgin
Frameworks[MICRO'14d]
[ISPASS'15][MICRO'14c]
Cornell University Christopher Batten 5 / 66
Page 6
Research Overview • XLOOPS: Explicit Loop Specialization • PyMTL: Productive Hardware Modeling
XLOOPS: Architectural Specialization forInter-Iteration Loop Dependence Patterns
Shreesha Srinath, Berkin Ilbeyi, Mingxing Tan, Gai Liu,Zhiru Zhang, and Christopher Batten
47th ACM/IEEE Int’l Symp. on Microarchitecture (MICRO)Cambridge, UK, Dec. 2014
Cornell University Christopher Batten 6 / 66
Page 7
Research Overview • XLOOPS: Explicit Loop Specialization • PyMTL: Productive Hardware Modeling
Loop Dependence Pattern Specialization
Iteration0
inst0inst1inst2inst3...branch
Iteration1
inst0inst1inst2inst3...branch
inst0inst1inst2inst3...branch
Iteration2
inst0inst1inst2inst3...branch
Iteration3
inst0inst1inst2inst3...branch
Iterationn-1
Intra-IterationMicro-op Fusion,
ASIPs, CCA, BERET
Inter-IterationVector, GPU,HELIX-RC
BothDySER, C-Cores,
Qs-Cores
Key Challenge: Creating HW/SW abstractions that are flexibleand enable performance-portable execution
Cornell University Christopher Batten 7 / 66
Page 8
Research Overview • XLOOPS: Explicit Loop Specialization • PyMTL: Productive Hardware Modeling
Explicit Loop Specialization (XLOOPS)
Key Idea 1: Expose fine-grained parallelism by elegantly encodinginter-iteration loop dependence patterns in the ISA
Key Idea 2: Single-ISA hetereogenous architecture with a new executionparadigm supporting traditional, specialized, and adaptive execution
GPP
L1 Data Cache
Lanes
Lane Manager
Mem XBar
I Traditional Execution
I Specialized Execution
I Adaptive Execution
Cornell University Christopher Batten 8 / 66
Page 9
Research Overview • XLOOPS: Explicit Loop Specialization • PyMTL: Productive Hardware Modeling
3. XLOOPS Microarchitecture 4. Evaluation
1. XLOOPS Instruction Setloop:
lw r2, 0(rA)
lw r3, 0(rB)
...
addiu.xi rA, 4
addiu.xi rB, 4
addiu r1, r1, 1
xloop.uc r1, rN, loop
2. XLOOPS Compiler
#pragma xloops ordered
for(i = 0; i < N i++)
A[i] = A[i] * A[i-K];
#pragma xloops atomic
for(i = 0; i < N; i++)
B[ A[i] ]++;
D[ C[i] ]++;
OoO GPP
L1 Data Cache
Lanes
Lane Manager
Mem XBar
Cornell University Christopher Batten 9 / 66
Page 10
Research Overview XLOOPS : { • Instruction Set • Compiler Microarchitecture Evaluation } PyMTL
3. XLOOPS Microarchitecture 4. Evaluation
1. XLOOPS Instruction Setloop:
lw r2, 0(rA)
lw r3, 0(rB)
...
addiu.xi rA, 4
addiu.xi rB, 4
addiu r1, r1, 1
xloop.uc r1, rN, loop
2. XLOOPS Compiler
#pragma xloops ordered
for(i = 0; i < N i++)
A[i] = A[i] * A[i-K];
#pragma xloops atomic
for(i = 0; i < N; i++)
B[ A[i] ]++;
D[ C[i] ]++;
OoO GPP
L1 Data Cache
Lanes
Lane Manager
Mem XBar
Cornell University Christopher Batten 10 / 66
Page 11
Research Overview XLOOPS : { • Instruction Set • Compiler Microarchitecture Evaluation } PyMTL
XLOOPS Instruction Set Extensions
xloop.{d}.{c} rI, rN, L
Data
Dependence
Control
Dependence
Induction
Variable
Loop
Bound
Loop
Label
XLOOP Instruction
Unordered Concurrent Fixed Bound
xloop.uc.fb r2, r3, 0x8000
Cross-Iteration Instructions
addiu.xi rX, imm
addu.xi rX, rT
Variables that can be computed as linear functions of the induction variable
Cornell University Christopher Batten 11 / 66
Page 12
Research Overview XLOOPS : { • Instruction Set • Compiler Microarchitecture Evaluation } PyMTL
XLOOPS Instruction Set: Unordered Concurrent
Iteration 0
inst0inst1inst2inst3...xloop.uc
Iteration 1
inst0inst1inst2inst3...xloop.uc
Iteration 2
inst0inst1inst2inst3...xloop.uc
Iteration 3
inst0inst1inst2inst3...xloop.uc
loop:
lw r2, 0(rA)
lw r3, 0(rB)
mul r4, r2, r3
sw r4, 0(rC)
addiu.xi rA, 4
addiu.xi rB, 4
addiu.xi rC, 4
addiu r1, r1, 1
xloop.uc r1, rN, loop
for ( i=0; i<N; i++ )
C[i] = A[i] * B[i]
Element-wise Vector
Multiplication
Instructions in loop cannot
write live-in registers
Live-out values must be stored
to memory
Data-races are possible
Cornell University Christopher Batten 12 / 66
Page 13
Research Overview XLOOPS : { • Instruction Set • Compiler Microarchitecture Evaluation } PyMTL
XLOOPS Instruction Set: Unordered Atomic
loop:
lw r6, 0(rA)
lw r7, 0(r6)
addiu r7, r7, 1
sw r7, 0(r6)
addiu.xi rA, 4
...
addiu r1, r1, 1
xloop.ua r1, rN, loop
for ( i=0; i<N; i++ )
B[A[i]]++; D[C[i]]++;
Histogram
Updates
Iterations execute atomically
No race conditions
Iteration 0
inst0inst1inst2inst3...xloop.ua
Iteration 1
inst0inst1inst2inst3...xloop.ua
Iteration 2
inst0inst1inst2inst3...xloop.ua
Iteration 3
inst0inst1inst2inst3...xloop.ua
Results can be non-deterministic
Inspired by Transactional Memory
Cornell University Christopher Batten 13 / 66
Page 14
Research Overview XLOOPS : { • Instruction Set • Compiler Microarchitecture Evaluation } PyMTL
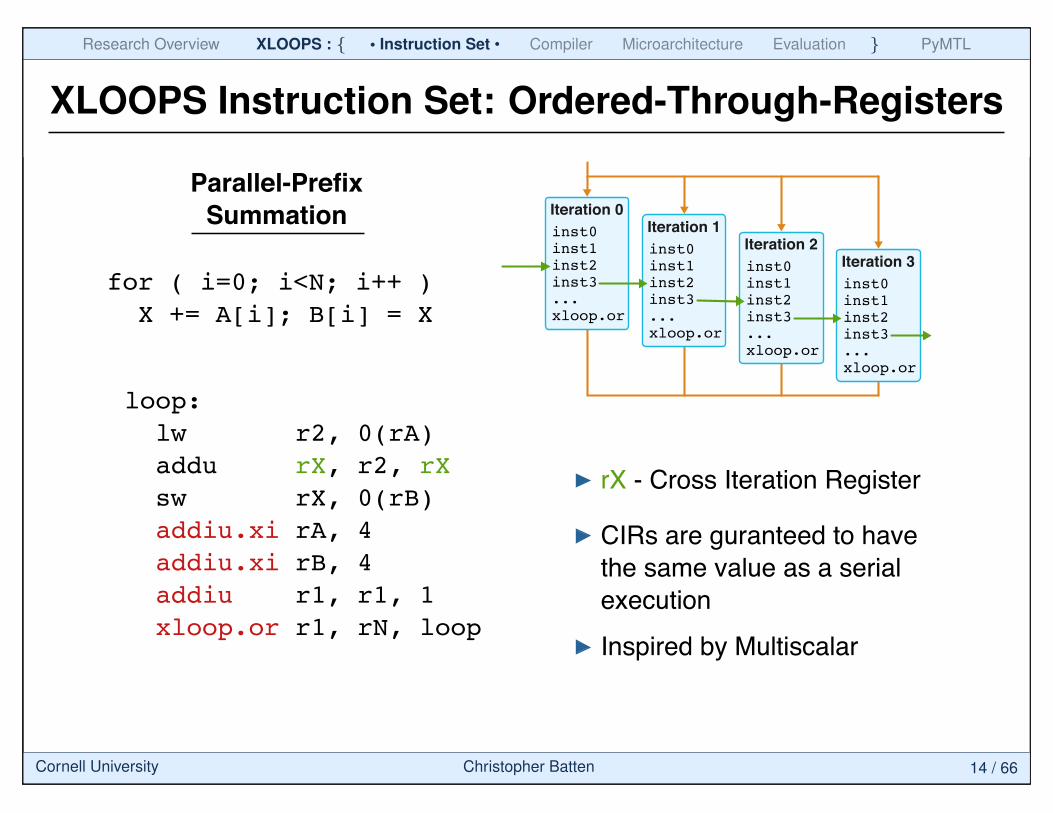
XLOOPS Instruction Set: Ordered-Through-Registers
loop:
lw r2, 0(rA)
addu rX, r2, rX
sw rX, 0(rB)
addiu.xi rA, 4
addiu.xi rB, 4
addiu r1, r1, 1
xloop.or r1, rN, loop
for ( i=0; i<N; i++ )
X += A[i]; B[i] = X
Parallel-Prefix
Summation
rX - Cross Iteration Register
CIRs are guranteed to have
the same value as a serial
execution
Inspired by Multiscalar
Iteration 0
inst0inst1inst2inst3...xloop.or
Iteration 1
inst0inst1inst2inst3...xloop.or
Iteration 2
inst0inst1inst2inst3...xloop.or
Iteration 3
inst0inst1inst2inst3...xloop.or
Cornell University Christopher Batten 14 / 66
Page 15
Research Overview XLOOPS : { • Instruction Set • Compiler Microarchitecture Evaluation } PyMTL
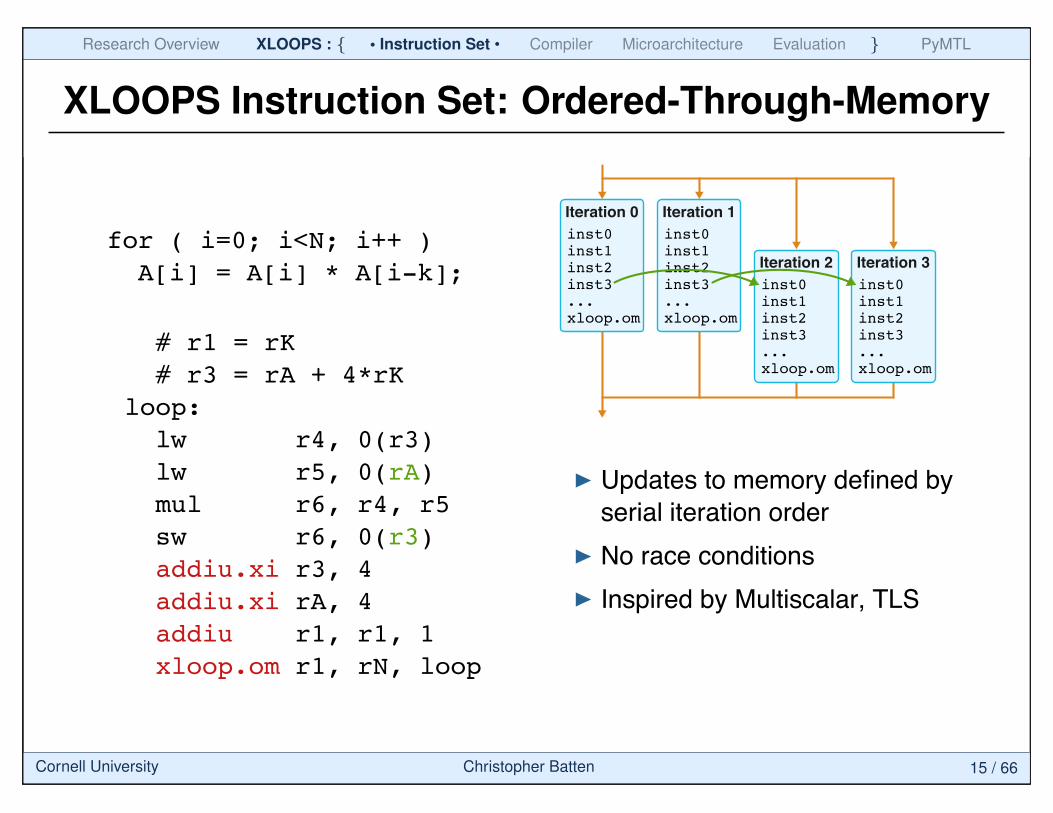
XLOOPS Instruction Set: Ordered-Through-Memory
# r1 = rK
# r3 = rA + 4*rK
loop:
lw r4, 0(r3)
lw r5, 0(rA)
mul r6, r4, r5
sw r6, 0(r3)
addiu.xi r3, 4
addiu.xi rA, 4
addiu r1, r1, 1
xloop.om r1, rN, loop
for ( i=0; i<N; i++ )
A[i] = A[i] * A[i-k];
Updates to memory defined by
serial iteration order
No race conditions
Iteration 0
inst0inst1inst2inst3...xloop.om
Iteration 1
inst0inst1inst2inst3...xloop.om
Iteration 2
inst0inst1inst2inst3...xloop.om
Iteration 3
inst0inst1inst2inst3...xloop.om
Inspired by Multiscalar, TLS
Cornell University Christopher Batten 15 / 66
Page 16
Research Overview XLOOPS : { • Instruction Set • Compiler Microarchitecture Evaluation } PyMTL
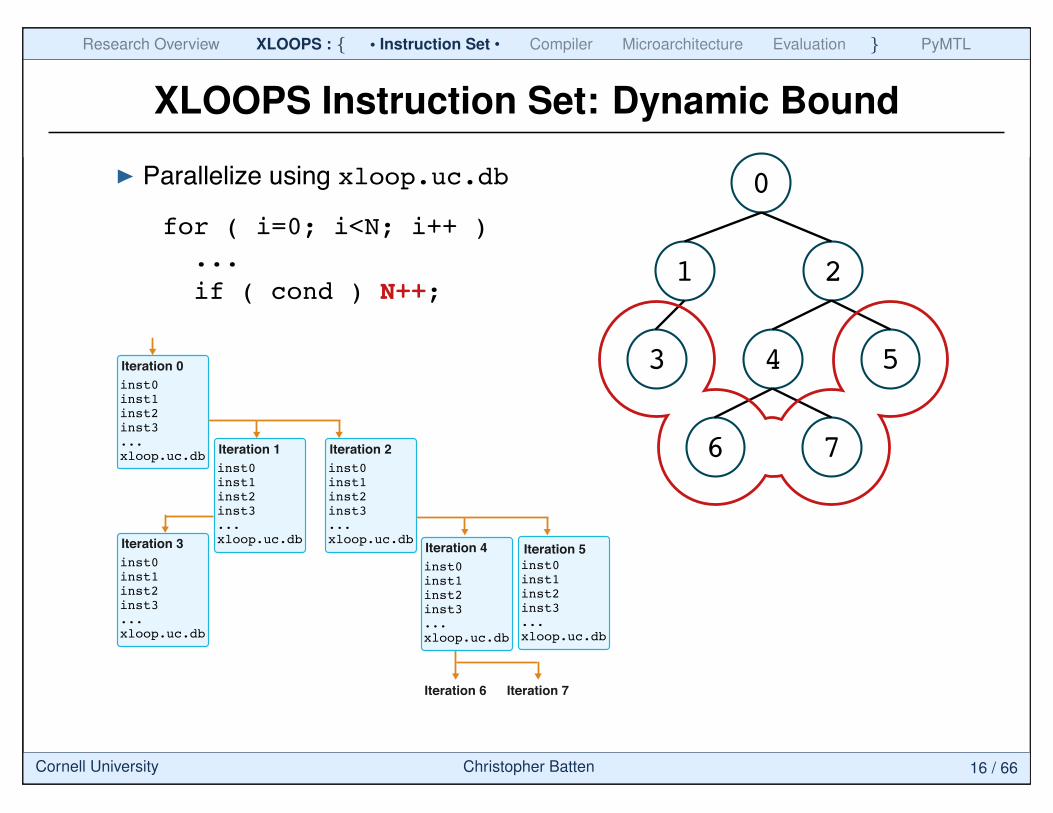
XLOOPS Instruction Set: Dynamic Bound
Iteration 0
inst0inst1inst2inst3...xloop.uc.db
Iteration 6 Iteration 7
Iteration 1
inst0inst1inst2inst3...xloop.uc.db
Iteration 2
inst0inst1inst2inst3...xloop.uc.dbIteration 3
inst0inst1inst2inst3...xloop.uc.db
Iteration 4
inst0inst1inst2inst3...xloop.uc.db
Iteration 5inst0inst1inst2inst3...xloop.uc.db
Parallelize using xloop.uc.db 0
1 2
3 4 5
6 7
for ( i=0; i<N; i++ )
...
if ( cond ) N++;
Cornell University Christopher Batten 16 / 66
Page 17
Research Overview XLOOPS : { Instruction Set • Compiler • Microarchitecture Evaluation } PyMTL
3. XLOOPS Microarchitecture 4. Evaluation
1. XLOOPS Instruction Setloop:
lw r2, 0(rA)
lw r3, 0(rB)
...
addiu.xi rA, 4
addiu.xi rB, 4
addiu r1, r1, 1
xloop.uc r1, rN, loop
2. XLOOPS Compiler
#pragma xloops ordered
for(i = 0; i < N i++)
A[i] = A[i] * A[i-K];
#pragma xloops atomic
for(i = 0; i < N; i++)
B[ A[i] ]++;
D[ C[i] ]++;
OoO GPP
L1 Data Cache
Lanes
Lane Manager
Mem XBar
Cornell University Christopher Batten 17 / 66
Page 18
Research Overview XLOOPS : { Instruction Set • Compiler • Microarchitecture Evaluation } PyMTL
XLOOPS Compiler
Kernel implementing Floyd-Warshall shortest path algorithm
for ( int k = 0; k < n; k++ )
#pragma xloops ordered
for ( int i = 0; i < n; i++ )
#pragma xloops unordered
for ( int j = 0; j < n; j++ )
path[i][j] = min( path[i][j], path[i][k] + path[k][j] );
Cornell University Christopher Batten 18 / 66
Page 19
Research Overview XLOOPS : { Instruction Set • Compiler • Microarchitecture Evaluation } PyMTL
Mid-Level Optimization Passes
XLOOPSData-Dependence
Analysis Pass
XLOOPSControl-Dependence
Analysis Pass
Code Generation
C++ Appw/ Pragmas
ModifiedLSR Pass
XLOOPSBinary
I Programmer annotations. unordered: no data-dependences. ordered: preserve data-dependences. atomic: atomic memory updates
I Loop strength reduction pass encodesMIVs as xi instructions
I XLOOPS data-dependence analysis pass. Register-dependence: analysing use-definition
chains through PHI nodes. Memory-dependence: well known
dependence analysis techniques
I Detect updates to the loop bound to encodedynamic-bound control-dependence pattern
Cornell University Christopher Batten 19 / 66
Page 20
Research Overview XLOOPS : { Instruction Set Compiler • Microarchitecture • Evaluation } PyMTL
3. XLOOPS Microarchitecture 4. Evaluation
1. XLOOPS Instruction Setloop:
lw r2, 0(rA)
lw r3, 0(rB)
...
addiu.xi rA, 4
addiu.xi rB, 4
addiu r1, r1, 1
xloop.uc r1, rN, loop
2. XLOOPS Compiler
#pragma xloops ordered
for(i = 0; i < N i++)
A[i] = A[i] * A[i-K];
#pragma xloops atomic
for(i = 0; i < N; i++)
B[ A[i] ]++;
D[ C[i] ]++;
OoO GPP
L1 Data Cache
Lanes
Lane Manager
Mem XBar
Cornell University Christopher Batten 20 / 66
Page 21
Research Overview XLOOPS : { Instruction Set Compiler • Microarchitecture • Evaluation } PyMTL
Traditional Execution
GPR RF32 × 32b
2r2w
GPP
LLFU
D$ Request/Response Crossbar
L1 I$ 16 KB
L2 Request and Response Crossbars
L1 D$ 16 KB
SLFU
Minimal changes to ageneral-purpose processor (GPP)
I xloop → bne
I addiu.xi→ addiu
I addu.xi → addu
Efficient traditional execution
I Enables gradual adoptionI Enables adaptive execution to
migrate an xloop instruction
Cornell University Christopher Batten 21 / 66
Page 22
Research Overview XLOOPS : { Instruction Set Compiler • Microarchitecture • Evaluation } PyMTL
Specialized Execution – xloop.uc
GPR RF32 × 32b
2r2w
GPP
LLFU
D$ Request/Response Crossbar
L1 I$ 16 KB
L2 Request and Response Crossbars
L1 D$ 16 KB
SLFU
Lane3
Lane1
Lane RF24 × 32b
2r2w
Inst Buf128×
Lane RF24 × 32b
2r2w
Inst Buf128×
Lane RF24 × 32b
2r2w
Inst Buf128×
Lane0
SLFU SLFU SLFU
IDQ
Lane Management Unit
IDQ IDQ
Loop Pattern Specialization Unit
I Lane Management Unit (LMU)I Four decoupled in-order lanesI Lanes contain instruction buffers
and index queuesI Lanes and the GPP arbitrate for
data-memory port andlong-latency functional unit
Specialized execution
I Scan phaseI Specialized execution phase
Cornell University Christopher Batten 22 / 66
Page 23
Research Overview XLOOPS : { Instruction Set Compiler • Microarchitecture • Evaluation } PyMTL
lwIteration 2
Iteration 3lw
dispatchdispatch
swaddiu.xiaddiu.xi
opaddiu.xiaddiuxloop
swaddiu.xiaddiu.xi
opaddiu.xiaddiuxloop
GPP LMU Lane0 Lane1 LLFUloop: lw r2, 0(rA) lw r3, 0(rB) mul r4, r2, r3 sw r4, 0(rC) addiu.xi rA, 4 addiu.xi rB, 4 addiu.xi rC, 4 addiu r1, r1, 1 xloop.uc r1, rN, loop
opop
Tim
e
xloop
Sc
an
Ph
as
e
rename
op
lwlw
mulsw
addiu.xiaddiu.xi
opaddiu.xiaddiuxloop
op
renamerenamerenamerenamerenamerenamerenamerename
writewritewritewritewritewritewritewritewrite
op
writewritewritewritewritewritewritewritewrite
Sp
ec
ialize
d E
xe
cu
tio
n P
ha
se
lwIteration 0
dispatch
lw lwIteration 1
dispatch
mul
X
lwmul
X
Cornell University Christopher Batten 23 / 66
Page 24
Research Overview XLOOPS : { Instruction Set Compiler • Microarchitecture • Evaluation } PyMTL
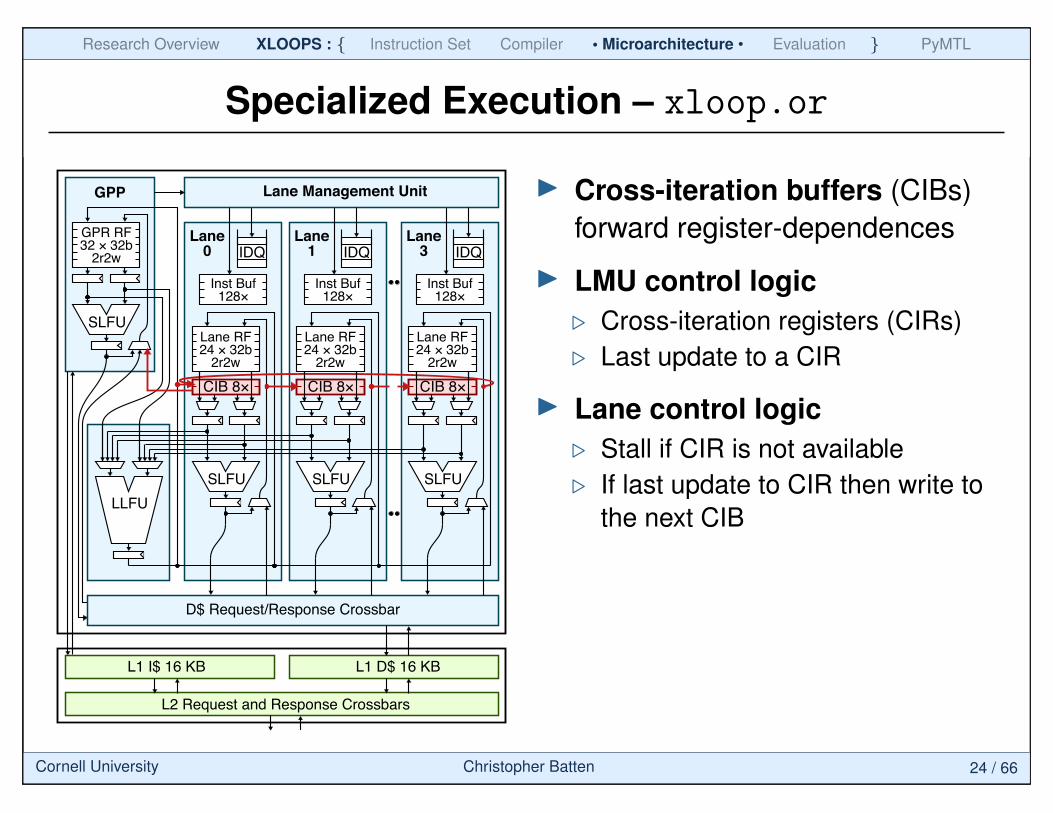
Specialized Execution – xloop.or
GPR RF32 × 32b
2r2w
GPP
LLFU
D$ Request/Response Crossbar
L1 I$ 16 KB
L2 Request and Response Crossbars
L1 D$ 16 KB
SLFU
Lane3
Lane1
Lane RF24 × 32b
2r2w
Inst Buf128×
Lane RF24 × 32b
2r2w
Inst Buf128×
Lane RF24 × 32b
2r2w
Inst Buf128×
Lane0
SLFU SLFU SLFU
IDQ
Lane Management Unit
IDQ IDQ
CIB 8×CIB 8×CIB 8×
I Cross-iteration buffers (CIBs)forward register-dependences
I LMU control logic. Cross-iteration registers (CIRs). Last update to a CIR
I Lane control logic. Stall if CIR is not available. If last update to CIR then write to
the next CIB
Cornell University Christopher Batten 24 / 66
Page 25
Research Overview XLOOPS : { Instruction Set Compiler • Microarchitecture • Evaluation } PyMTL
addiu.xiopaddiu.xi
addiuxloop
GPP LMU Lane0 Lane1 LLFUloop: lw r2, 0(rA) addu rX, r2, rX sw rX, 0(rB) addiu.xi rA, 4 addiu.xi rB, 4 addiu r1, r1, 1 xloop.or r1, rN, loop
opop
Tim
e
xloop
Sc
an
Ph
as
e rename
op
lwaddusw
addiu.xiopaddiu.xi
addiuxloop
op
renamerenamerenamerenamerenamerename
writewritewritewritewritewritewrite
op
writewritewritewritewritewritewrite
Sp
ec
ialize
d E
xe
cu
tio
n P
ha
se
lwIteration 0
dispatch
addusw
addiu.xiopaddiu.xi
addiuxloop
lwIteration 1
dispatch
addusw
addiu.xiopaddiu.xi
addiuxloop
addiu.xiopaddiu.xi
addiuxloop
lwIteration 2
dispatch
addu lwIteration 3
dispatch
sw addusw
Iteration 4
dispatchdispatch
Cornell University Christopher Batten 25 / 66
Page 26
Research Overview XLOOPS : { Instruction Set Compiler • Microarchitecture • Evaluation } PyMTL
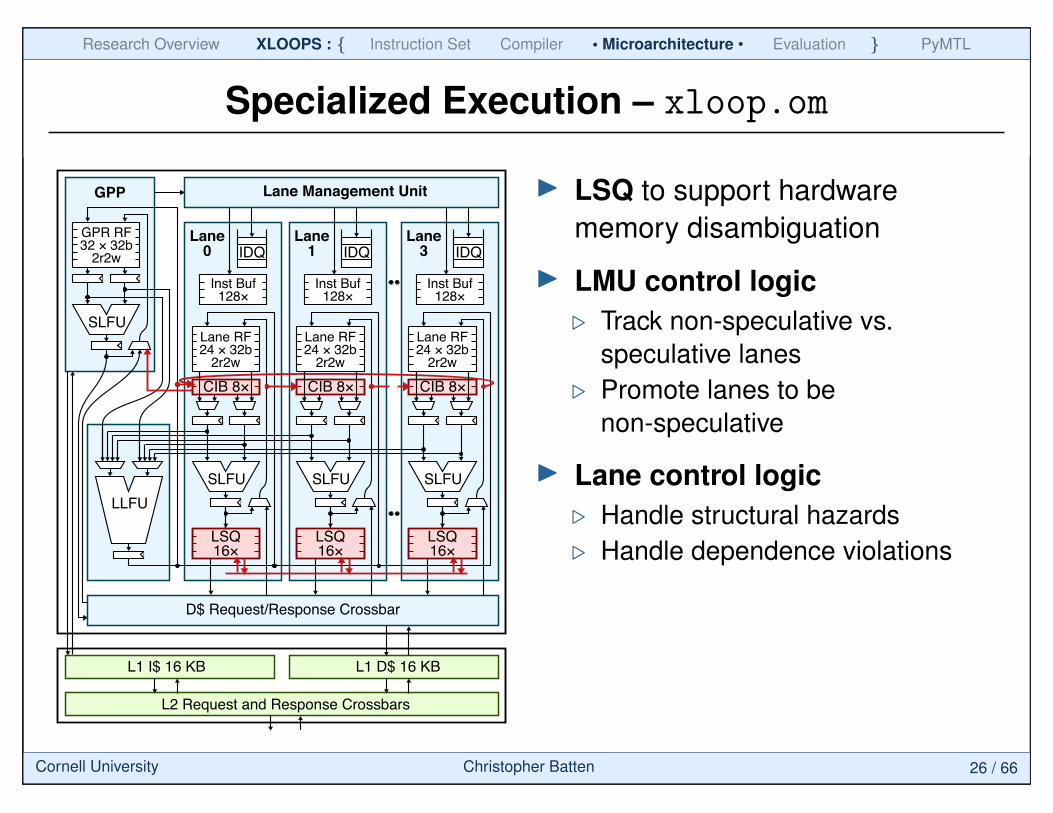
Specialized Execution – xloop.om
GPR RF32 × 32b
2r2w
GPP
LLFU
D$ Request/Response Crossbar
L1 I$ 16 KB
L2 Request and Response Crossbars
L1 D$ 16 KB
SLFU
Lane3
Lane1
Lane RF24 × 32b
2r2w
Inst Buf128×
Lane RF24 × 32b
2r2w
Inst Buf128×
Lane RF24 × 32b
2r2w
Inst Buf128×
Lane0
SLFU SLFU SLFU
IDQ
Lane Management Unit
IDQ IDQ
CIB 8×CIB 8×CIB 8×
LSQ16×
LSQ16×
LSQ16×
I LSQ to support hardwarememory disambiguation
I LMU control logic. Track non-speculative vs.
speculative lanes. Promote lanes to be
non-speculative
I Lane control logic. Handle structural hazards. Handle dependence violations
Cornell University Christopher Batten 26 / 66
Page 27
Research Overview XLOOPS : { Instruction Set Compiler • Microarchitecture • Evaluation } PyMTL
GPP LMU Lane0 Lane1 LLFU
opop
Tim
e
xloop
lwlw
xloopsw
. . .
rename
. . .
write
. . .
renamerename
writerename
writewritewrite
write
. . .
write
writewritewrite
loop: lw r4, 0(r3) lw r5, 0(rA) ... ... sw r6, 0(r7) addiu r1, r1, 1 xloop.om r1, rN, loop
Sc
an
Ph
as
e
Iteration 0
dispatch
Sp
ec
ialize
d E
xe
cu
tio
n P
ha
se
dispatch
Iteration 1lwlw
xloopsw
. . .
lwlw
check
Iteration 1
lwlw
xloopsw
. . .
Iteration 2
lwlw
sw
. . .
xloopdispatch
Iteration 3
X
check
dispatch
Cornell University Christopher Batten 27 / 66
Page 28
Research Overview XLOOPS : { Instruction Set Compiler • Microarchitecture • Evaluation } PyMTL
Supporting other patterns
GPR RF32 × 32b
2r2w
GPP
LLFU
D$ Request/Response Crossbar
L1 I$ 16 KB
L2 Request and Response Crossbars
L1 D$ 16 KB
SLFU
Lane3
Lane1
Lane RF24 × 32b
2r2w
Inst Buf128×
Lane RF24 × 32b
2r2w
Inst Buf128×
Lane RF24 × 32b
2r2w
Inst Buf128×
Lane0
SLFU SLFU SLFU
IDQ
Lane Management Unit
IDQ IDQ
CIB 8×CIB 8×CIB 8×
LSQ16×
LSQ16×
LSQ16×
DBN
Lane Management Unit I xloop.ua – Using xloop.om
mechanisms
I xloop.orm – Combine xloop.or
and xloop.om mechanisms
I xloop.*.db
. Lanes communicate updates toloop bound
. LMU tracks maximum bound andgenerates additional work
Cornell University Christopher Batten 28 / 66
Page 29
Research Overview XLOOPS : { Instruction Set Compiler • Microarchitecture • Evaluation } PyMTL
Adaptive Execution
GPP
L1 Data Cache
Lanes
Lane Manager
Mem XBar
I Some kernels have higherperformance on LPSU (e.g.,significant inter-iteration parallelism)
I Some kernels have higherperformance on GPP (e.g., limitedinter-iteration parallelism, significantintra-iteration parallelism)
I Approach #1: Move to more complicated superscalar or out-of-orderlanes to better exploit both inter- and intra-iteration parallelism
I Approach #2: Adaptively migrate between traditional and specializedexecution to achieve best performance
Cornell University Christopher Batten 29 / 66
Page 30
Research Overview XLOOPS : { Instruction Set Compiler • Microarchitecture • Evaluation } PyMTL
GPP LMU Lane0 Lane1 LLFU
Tim
e
OoO GPP
L1 Data Cache
Lanes
Lane Manager
Mem XBar
GP
P P
rofi
lin
gT
rad
itio
na
l E
xe
cu
tio
nL
PS
U P
rofi
lin
gI Migrating loop oniteration boundariesis very cheap andusually only requiressending the nextiteration index
I An adaptive profilingtable in GPP recordsprofiling progress forsmall number ofrecently seen xloop
instructions
Cornell University Christopher Batten 30 / 66
Page 31
Research Overview XLOOPS : { Instruction Set Compiler Microarchitecture • Evaluation • } PyMTL
3. XLOOPS Microarchitecture 4. Evaluation
1. XLOOPS Instruction Setloop:
lw r2, 0(rA)
lw r3, 0(rB)
...
addiu.xi rA, 4
addiu.xi rB, 4
addiu r1, r1, 1
xloop.uc r1, rN, loop
2. XLOOPS Compiler
#pragma xloops ordered
for(i = 0; i < N i++)
A[i] = A[i] * A[i-K];
#pragma xloops atomic
for(i = 0; i < N; i++)
B[ A[i] ]++;
D[ C[i] ]++;
OoO GPP
L1 Data Cache
Lanes
Lane Manager
Mem XBar
Cornell University Christopher Batten 31 / 66
Page 32
Research Overview XLOOPS : { Instruction Set Compiler Microarchitecture • Evaluation • } PyMTL
Application Kernelsxloop.uc
Color space conversionDense matrix-multiply
String search algorithmSymmetric matrix-multiplyViterbi decoding algorithm
Floyd-Warshall shortest path
xloop.or
ADPCM decoderCovriance computation
Floyd-Steinberg ditheringK-Means clustering
SHA-1 encryption kernelSymmetric matrix-multiply
xloop.om
Dynamic-programmingK-Nearest neighbors
Knapsack kernelFloyd-Warshall shortest path
xloop.orm, xloop.ua
Greedy maximal-matching2D Stencil computationBinary tree constructionHeap-sort computationHuffman entropy coding
Radix sort algorithmxloop.uc.db
Breadth-first searchQuick-sort algorithm
25 Kernels: MiBench,PolyBench, PBBS, custom
Cornell University Christopher Batten 32 / 66
Page 33
Research Overview XLOOPS : { Instruction Set Compiler Microarchitecture • Evaluation • } PyMTL
Cycle-Level Evaluation Methodology
PyMTL
I LLVM-3.1 based compiler framework
I gem5 – in-order and out-of-order processors
I PyMTL – LPSU models
I McPAT-1.0 – 45nm energy models
Cornell University Christopher Batten 33 / 66
Page 34
Research Overview XLOOPS : { Instruction Set Compiler Microarchitecture • Evaluation • } PyMTL
XLOOPS Cycle-Level Performance Results
rgb2
cmyk
-uc
sgem
m-u
c
ssea
rch-
uc
sym
m-u
c
vite
rbi-u
c
war
-uc
adpc
m-o
r
cova
r-or
dith
er-o
r
kmea
ns-o
r
sha-
or
sym
m-o
r
dynp
rog-
om
knn-
om
ksac
k-sm
-om
ksac
k-lg-o
m
war
-om
mm
-orm
sten
cil-o
rm
btre
e-ua
hsor
t-ua
huffm
an-u
a
rsor
t-ua
bfs-
uc-d
b
qsor
t-uc-
db
1.0
1.5
2.0
2.5
3.0
3.5
4.0
Sp
ee
du
p N
orm
aliz
ed
to
S
imp
le R
ISC
Co
re
OOO 2-Way OOO 4-Way OOO 2-Way with LPSU
xloop.uc xloop.or xloop.{om,orm} xloop.ua xloop.*.db
I XLOOPS vs. Simple Core : Always higher performanceI XLOOPS vs. OOO 2-way : Generally competitive or higher performanceI XLOOPS vs. OOO 4-way : Mixed results
Cornell University Christopher Batten 34 / 66
Page 35
Research Overview XLOOPS : { Instruction Set Compiler Microarchitecture • Evaluation • } PyMTL
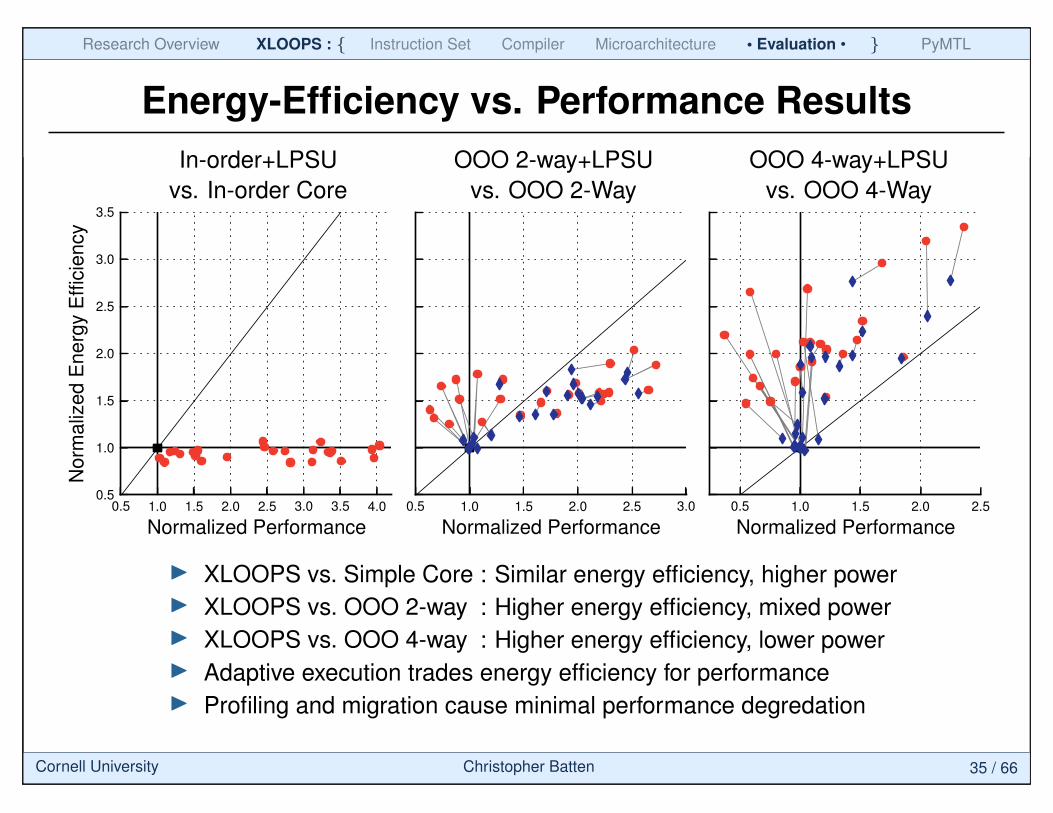
Energy-Efficiency vs. Performance ResultsIn-order+LPSU
vs. In-order CoreOOO 2-way+LPSU
vs. OOO 2-WayOOO 4-way+LPSU
vs. OOO 4-Way
0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0
Normalized Performance
0.5
1.0
1.5
2.0
2.5
3.0
3.5
Norm
aliz
ed E
nerg
y E
ffic
iency
0.5 1.0 1.5 2.0 2.5 3.0
Normalized Performance0.5 1.0 1.5 2.0 2.5
Normalized Performance
I XLOOPS vs. Simple Core : Similar energy efficiency, higher powerI XLOOPS vs. OOO 2-way : Higher energy efficiency, mixed powerI XLOOPS vs. OOO 4-way : Higher energy efficiency, lower powerI Adaptive execution trades energy efficiency for performanceI Profiling and migration cause minimal performance degredation
Cornell University Christopher Batten 35 / 66
Page 36
Research Overview XLOOPS : { Instruction Set Compiler Microarchitecture • Evaluation • } PyMTL
DCache16KB SRAM for Cache Lines
DCacheTags
ICacheTags
ICache16KB SRAM for Cache Lines
L0Instr
Buffer
L0Instr
Buffer
L0Instr
Buffer
L0Instr
Buffer
Loop PatternSpecialization Unit
ScalarProcessor
32b IEEEFloating Point Unit
32b IntegerMul/Div Unit
VLSIImplementation
I TSMC 40 nmstandard-cell-basedimplementation
I RISC scalarprocessor with4-lane LPSU
I Supports xloop.uc
I ≈40% extra areacompared to simpleRISC processor
Cornell University Christopher Batten 36 / 66
Page 37
Research Overview XLOOPS : { Instruction Set Compiler Microarchitecture • Evaluation • } PyMTL
loop:
lw r2, 0(rA)
lw r3, 0(rB)
...
addiu.xi rA, 4
addiu.xi rB, 4
addiu r1, r1, 1
xloop.uc r1, rN, loop
OoO GPP
L1 Data Cache
Lanes
Lane Manager
Mem XBar
#pragma xloops ordered
for(i = 0; i < N i++)
A[i] = A[i] * A[i-K];
#pragma xloops atomic
for(i = 0; i < N; i++)
B[ A[i] ]++;
D[ C[i] ]++;
XLOOPS Take-Away Points
I XLOOPS is an elegant new abstraction thatenables performance-portable execution of loops
I XLOOPS enables a single-ISA heterogeneousarchitecture with a new execution paradigm. Traditional Execution. Specialized Execution. Adaptive Execution
This work was supported in part by the National ScienceFoundation (NSF), the Defense Advanced Research ProjectsAgency (DARPA), and donations from Intel Corporation,Synopsys, Inc., and Xilinx, Inc.
Cornell University Christopher Batten 37 / 66
Page 38
Research Overview XLOOPS: Explicit Loop Specialization • PyMTL: Productive Hardware Modeling •
PyMTL: A Unified Framework for VerticallyIntegrated Computer Architecture Research
Derek Lockhart, Gary Zibrat, and Christopher Batten
47th ACM/IEEE Int’l Symp. on Microarchitecture (MICRO)Cambridge, UK, Dec. 2014
Cornell University Christopher Batten 38 / 66
Page 39
Research Overview XLOOPS: Explicit Loop Specialization • PyMTL: Productive Hardware Modeling •
PyMTL OutlineOutline(
1'/'39'PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
The'Computer'Architecture'Research'Methodology'Gap'
The'PerformanceFProducGvity'Gap'
PyMTL'
SimJIT'
Cornell University Christopher Batten 39 / 66
Page 40
Research Overview XLOOPS PyMTL : { • Methodology Gap • Framework Perf/Productivity Gap SimJIT }
Managing Increasing Design ComplexityManaging(Increasing(Design(Complexity(
3'/'39'
• AbstracGons'
''' • Methodologies'
''' • Pa>erns,'Languages,'Tools'
PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
Cornell University Christopher Batten 40 / 66
Page 41
Research Overview XLOOPS PyMTL : { • Methodology Gap • Framework Perf/Productivity Gap SimJIT }
Computer Architecture Research AbstractionsComputer(Architecture(Research(Abstractions(
4'/'39''
Algorithms'
InstrucGon'Set'Architecture'
Microarchitecture'
VLSI'
Compilers'Academic'Research'
'A'Few''
Researchers'
Industry'Development'
'Hundreds'of'Engineers'
Sea'of'Transistors'
ApplicaGons'
PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
Cornell University Christopher Batten 41 / 66
Page 42
Research Overview XLOOPS PyMTL : { • Methodology Gap • Framework Perf/Productivity Gap SimJIT }
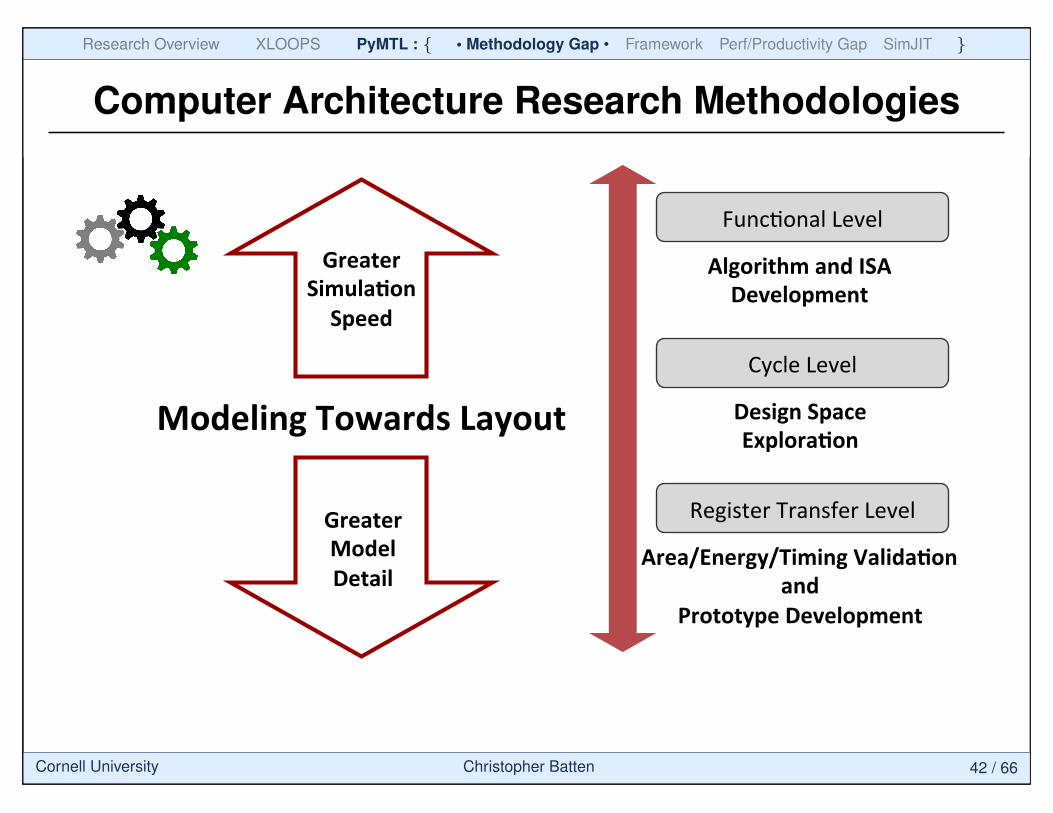
Computer Architecture Research Methodologies
InstrucGon'Set'Architecture'
Algorithms'
Compilers'
Computer(Architecture(Research(Methodologies(
6'/'39'
Cycle'Level'
• Behavior'• Timing'
Microarchitecture'
FuncGonal'Level'
• Behavior'
VLSI'
Register'Transfer'Level'
• Behavior'• Timing'• Physical'Resources'Sea'of'Transistors'
ApplicaGons'
PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
Cornell University Christopher Batten 42 / 66
Page 43
Research Overview XLOOPS PyMTL : { • Methodology Gap • Framework Perf/Productivity Gap SimJIT }
Computer Architecture Research MethodologiesComputer(Architecture(Research(Methodologies(
7'/'39'PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
FuncGonal'Level'
Cycle'Level'
Register'Transfer'Level'
Algorithm'and'ISA'Development'
Design'Space'Explora8on'
Area/Energy/Timing'Valida8on'and'
Prototype'Development'
Modeling'Towards'Layout
Greater''Simula8on'Speed'
Greater''Model'Detail'
Cornell University Christopher Batten 42 / 66
Page 44
Research Overview XLOOPS PyMTL : { • Methodology Gap • Framework Perf/Productivity Gap SimJIT }
Computer Architecture Research FrameworksComputer(Architecture(Research(Frameworks(
8'/'100''
• AbstracGons'
''' • Methodologies'
''' • Pa>erns,'Languages,'Tools'
PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
Cornell University Christopher Batten 43 / 66
Page 45
Research Overview XLOOPS PyMTL : { • Methodology Gap • Framework Perf/Productivity Gap SimJIT }
Computer Architecture Research FrameworksComputer(Architecture(Research(Frameworks(
9'/'100''
FuncGonal'Level'
Cycle'Level'
Register'Transfer'Level'
Algorithm'and'ISA'Development'
Design'Space'Explora8on'
Area/Energy/Timing'Valida8on'and'
Prototype'Development'
MATLAB/Python'Algorithm'or'C++'InstrucGon'Set'Simulator'
C++'Computer'Architecture''SimulaGon'Framework'(ObjectFOriented)'
Verilog'or'VHDL'Design'with'EDA'Toolflow'(ConcurrentFStructural)'
PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
Cornell University Christopher Batten 43 / 66
Page 46
Research Overview XLOOPS PyMTL : { • Methodology Gap • Framework Perf/Productivity Gap SimJIT }
Computer Architecture Research FrameworksComputer(Architecture(Research(Frameworks(
9'/'100''
FuncGonal'Level'
Cycle'Level'
Register'Transfer'Level'
Algorithm'and'ISA'Development'
Design'Space'Explora8on'
Area/Energy/Timing'Valida8on'and'
Prototype'Development'
Different'languages,''pa>erns,'and'tools!
The'Computer'Architecture'Research'Methodology'Gap
PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
Cornell University Christopher Batten 43 / 66
Page 47
Research Overview XLOOPS PyMTL : { • Methodology Gap • Framework Perf/Productivity Gap SimJIT }
Great Ideas From Prior WorkGreat(Ideas(From(Prior(Work(
10'/'100''PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
• ConcurrentVStructural'Modeling'(Liberty,'Cascade,'SystemC)!!
• Unified'Modeling'Languages'(SystemC)''
• Hardware'Genera8on'Languages'(Chisel,'Genesis2,'BlueSpec,'MyHDL)''
• HDLVIntegrated'Simula8on'Frameworks'(Cascade)!!
• LatencyVInsensi8ve'Interfaces'(Liberty,'BlueSpec)'
Consistent'interfaces'across'abstracGons'''Unified'design'environment'for'FL,'CL,'RTL'''ProducGve'RTL'design'space'exploraGon'''ProducGve'RTL'validaGon'and'cosimulaGon'''Component'and'test'bench'reuse'
Cornell University Christopher Batten 44 / 66
Page 48
Research Overview XLOOPS PyMTL : { Methodology Gap • Framework • Perf/Productivity Gap SimJIT }
PyMTL OutlineOutline(
11'/'39'PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
The'Computer'Architecture'Research'Methodology'Gap'
The'PerformanceFProducGvity'Gap'
PyMTL'
SimJIT'
Cornell University Christopher Batten 45 / 66
Page 49
Research Overview XLOOPS PyMTL : { Methodology Gap • Framework • Perf/Productivity Gap SimJIT }
What is PyMTL?What(is(PyMTL?(
12'/'39'
'• A'Python'DSEL'for'concurrentFstructural'hardware'modeling'• A'Python'API'for'analyzing'models'described'in'the'PyMTL'DSEL'• A'Python'tool'for'simulaGng'PyMTL'FL,'CL,'and'RTL'models'• A'Python'tool'for'translaGng'PyMTL'RTL'models'into'Verilog'• A'Python'tesGng'framework'for'model'validaGon'
PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
API'
SimulaGon'Tool'
TranslaGon'Tool'
Model'DSEL'
TesGng'Framework'
Cornell University Christopher Batten 46 / 66
Page 50
Research Overview XLOOPS PyMTL : { Methodology Gap • Framework • Perf/Productivity Gap SimJIT }
What Does PyMTL Enable?What(Does(PyMTL(Enable?(
14'/'39'
• Incremental'refinement'from'algorithm'to'accelerator'implementaGon'• Automated'tesGng'and'integraGon'of'PyMTLFgenerated'Verilog'
FL'Model'
Test'Harness'
CL'Model'
Test'Harness'
RTL'Model'
Test'Harness'
Verilog'RTL'
Model'
Verilog'RTL'
Model'
Test'Harness'
PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
Cornell University Christopher Batten 47 / 66
Page 51
Research Overview XLOOPS PyMTL : { Methodology Gap • Framework • Perf/Productivity Gap SimJIT }
What Does PyMTL Enable?What(Does(PyMTL(Enable?(
15'/'39'
'• Incremental'refinement'from'algorithm'to'accelerator'implementaGon'• Automated'tesGng'and'integraGon'of'PyMTLFgenerated'Verilog'• MulGFlevel'coFsimulaGon'of'FL,'CL,'and'RTL'models'
FL'Model'
CL'Model'
RTL'Model'
PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
Cornell University Christopher Batten 47 / 66
Page 52
Research Overview XLOOPS PyMTL : { Methodology Gap • Framework • Perf/Productivity Gap SimJIT }
What Does PyMTL Enable?What(Does(PyMTL(Enable?(
16'/'39'
'• Incremental'refinement'from'algorithm'to'accelerator'implementaGon'• Automated'tesGng'and'integraGon'of'PyMTLFgenerated'Verilog'• MulGFlevel'coFsimulaGon'of'FL,'CL,'and'RTL'models'• ConstrucGon'of'highlyFparameterized'RTL'chip'generators'
Verilog'RTL'
Model'
PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
Cornell University Christopher Batten 47 / 66
Page 53
Research Overview XLOOPS PyMTL : { Methodology Gap • Framework • Perf/Productivity Gap SimJIT }
What Does PyMTL Enable?What(Does(PyMTL(Enable?(
18'/'39'
'• Incremental'refinement'from'algorithm'to'accelerator'implementaGon'• Automated'tesGng'and'integraGon'of'PyMTLFgenerated'Verilog'• MulGFlevel'coFsimulaGon'of'FL,'CL,'and'RTL'models'• ConstrucGon'of'highlyFparameterized'RTL'chip'generators'• Embedding'within'C++'frameworks'&'integraGon'of'C++/Verilog'models'(see!Srinath!et.!al.!in!MICRO247,!Session!6B!)!
PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
'gem5'
PyMTL'
C++'Model' PyMTL' Verilog'
Model'
(Used to implement CL model for XLOOPS LPSU)
Cornell University Christopher Batten 48 / 66
Page 54
Research Overview XLOOPS PyMTL : { Methodology Gap • Framework • Perf/Productivity Gap SimJIT }
The PyMTL FrameworkThe(PyMTL(Framework(
19'/'39'PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
Model'
Config'
Test'&'Sim'Harness'
Verilog'
Traces'&'VCD'
User'Tool'Output'
Elaborator'
SimulaGon'Tool'
TranslaGon'Tool'
User'Tool'
Model'Instance'
EDA'Toolflow'
Specifica8on' Tools' Output'
VisualizaGon' StaGc'Analysis'
Dynamic'Checking'
FPGA'SimulaGon'
High'Level'Synthesis'
Cornell University Christopher Batten 49 / 66
Page 55
Research Overview XLOOPS PyMTL : { Methodology Gap • Framework • Perf/Productivity Gap SimJIT }
The PyMTL DSEL: FL ModelsThe(PyMTL(DSEL(
21'/'39'
def sorter_network( input ): ! return sorted( input ) !!class SorterNetworkFL( Model ) ! def __init__( s, nbits, nports ): !! s.in_ = InPort [nports](nbits) ! s.out = OutPort[nports](nbits) !!! @s.tick_fl! def logic(): ! for i, v in enumerate( sorted( s.in_ ) ): ! s.out[i].next = v'
PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
f(x)'
['3,'1,'2,'0']' ['0,'1,'2,'3']'f(x)'
Cornell University Christopher Batten 50 / 66
Page 56
Research Overview XLOOPS PyMTL : { Methodology Gap • Framework • Perf/Productivity Gap SimJIT }
The PyMTL DSEL: CL ModelsThe(PyMTL(DSEL(
22'/'39'
def sorter_network( input ): ! return sorted( input ) !!class SorterNetworkCL( Model ) ! def __init__( s, nbits, nports, delay=3 ): !! s.in_ = InPort [nports](nbits) ! s.out = OutPort[nports](nbits) ! s.pipe = Pipeline( delay ) !! @s.tick_cl! def logic(): ! s.pipe.xtick() ! s.pipe.push( sorted( s.in_ ) ) !! if s.pipe.ready(): ! for i, v in enumerate( s.pipe.pop() ): ! s.out[i].next = v !! '
PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
f(x)'
['3,'1,'2,'0']' ['0,'1,'2,'3']'f(x)'
Cornell University Christopher Batten 51 / 66
Page 57
Research Overview XLOOPS PyMTL : { Methodology Gap • Framework • Perf/Productivity Gap SimJIT }
The PyMTL DSEL: RTL ModelsThe(PyMTL(DSEL(
23'/'39'
def sorter_network( input ): ! return sorted( input ) !!class SorterNetworkRTL( Model ) ! def __init__( s, nbits ): !! s.in_ = InPort [4](nbits) ! s.out = OutPort[4](nbits) !! s.m = m = MinMaxRTL[5](nbits) !! s.connect( s.in_[0], m[0].in_[0] ) ! s.connect( s.in_[1], m[0].in_[1] ) ! s.connect( s.in_[2], m[1].in_[0] ) ! s.connect( s.in_[3], m[2].in_[1] ) !! . . . ! '
PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
['3,'1,'2,'0']' ['0,'1,'2,'3']'f(x)'
Cornell University Christopher Batten 52 / 66
Page 58
Research Overview XLOOPS PyMTL : { Methodology Gap • Framework • Perf/Productivity Gap SimJIT }
The PyMTL DSEL: RTL ModelsThe(PyMTL(DSEL(
24'/'39'
class MinMaxRTL( Model ) ! def __init__( s, nbits ): ! s.in_ = InPort [2](nbits) ! s.out = OutPort[2](nbits) ! @s.combinational! def logic(): ! swap = s.in_[0] > s.in_[1] ! s.out[0].value = s.in[1] if swap else s.in[0] ! s.out[1].value = s.in[0] if swap else s.in[1] !!class RegRTL( Model ) ! def __init__( s, nbits ): ! s.in_ = InPort (nbits) ! s.out = OutPort(nbits) ! @s.tick_rtl! def logic(): ! s.out.next = s.in_ ! '
PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
Cornell University Christopher Batten 52 / 66
Page 59
Research Overview XLOOPS PyMTL : { Methodology Gap • Framework • Perf/Productivity Gap SimJIT }
PyMTL Accelerator Case Study
L1 DCache
L1 ICache
Arbitration
DotProduct
AcceleratorProcessor
Experimented with FL, CL, and RTLmodels of a pipelined processor, blockingcache, and dot-product accelerator
Rela
tive S
imula
tor
Perf
orm
an
ce
Level of Detail (FL = 1, CL = 2, RTL = 3)
1 2 3 4 5 6 7 8 9
Pure FL Model SimJIT+PyPyCPython
27 different compositions that trade-offsimulator performance vs. accuracy
Cornell University Christopher Batten 53 / 66
Page 60
Research Overview XLOOPS PyMTL : { Methodology Gap • Framework • Perf/Productivity Gap SimJIT }
Why Python?Why(Python?(
26'/'39'
Benefits:''• Modern'language'features'enable'rapid'prototyping'(dynamicFtyping,'reflecGon,'metaprogramming)'• Lightweight,'pseudocodeFlike'syntax'• BuiltFin'support'for'integraGng'C/C++'code'• Large,'acGve'developer'and'support'community''Drawbacks:''• Performance'
PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
Cornell University Christopher Batten 54 / 66
Page 61
Research Overview XLOOPS PyMTL : { Methodology Gap Framework • Perf/Productivity Gap • SimJIT }
PyMTL OutlineOutline(
27'/'39'PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
The'Computer'Architecture'Research'Methodology'Gap'
The'PerformanceFProducGvity'Gap'
PyMTL'
SimJIT'
Cornell University Christopher Batten 55 / 66
Page 62
Research Overview XLOOPS PyMTL : { Methodology Gap Framework • Perf/Productivity Gap • SimJIT }
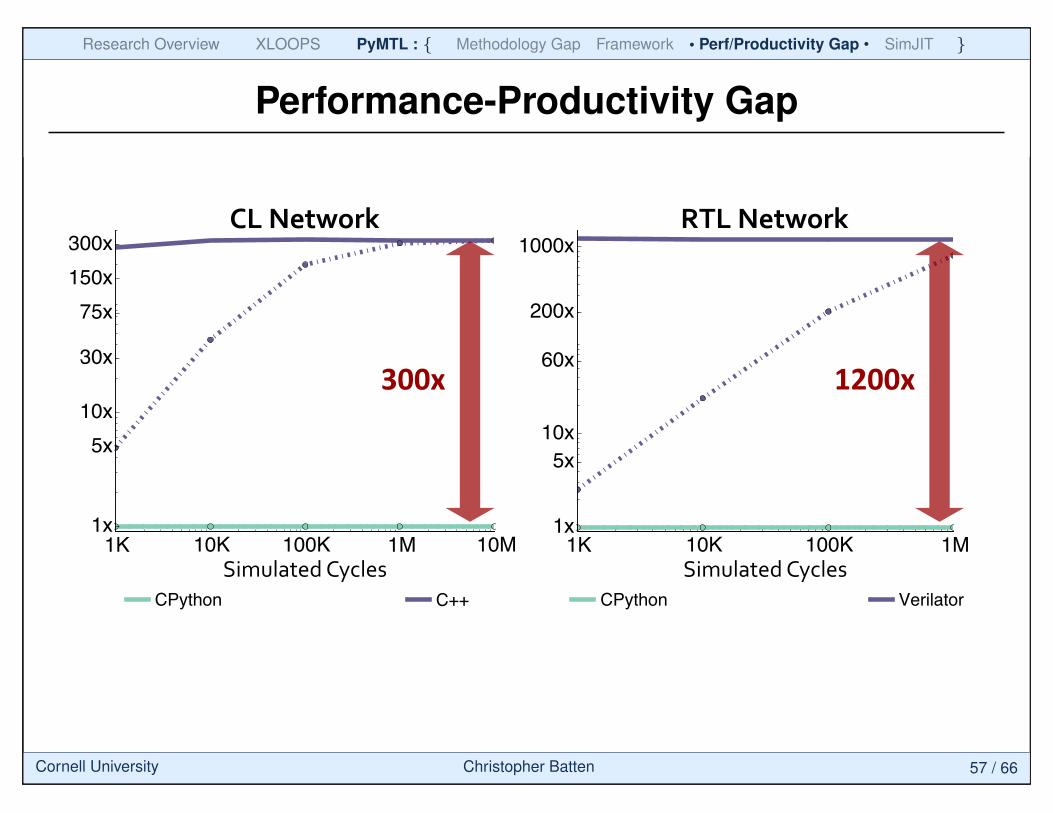
Performance-Productivity GapPerformanceHProductivity(Gap(
28'/'39'
Experiment:''• Simple'8x8'Mesh'Network'Model''• CycleFPrecise'CL'Model:'• PyMTL'Model'Simulated'with'the'CPython'Interpreter'• HandFWri>en'C++'Model'and'Simulator'
• BitFAccurate'RTL'Model:'• PyMTL'Model'Simulated'with'CPython'Interpreter'• HandFWri>en'Verilog'RTL'Simulated'with'Verilator'
PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
Cornell University Christopher Batten 56 / 66
Page 63
Research Overview XLOOPS PyMTL : { Methodology Gap Framework • Perf/Productivity Gap • SimJIT }
Performance-Productivity Gap
RTL�NetworkCL�Network
Simulated�CyclesSimulated�Cycles1K 10K 100K 1M10M
1x
5x10x
30x
75x150x300x
60x
200x
1000x
CPython VerilatorC++
1K10K 100K 1M
10x5x
1x
CPython
PerformanceHProductivity(Gap(
29'/'39'PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
300x' 1200x'
Cornell University Christopher Batten 57 / 66
Page 64
Research Overview XLOOPS PyMTL : { Methodology Gap Framework • Perf/Productivity Gap • SimJIT }
Performance-Productivity GapPerformanceHProductivity(Gap(
30'/'39'
Python'is'growing'in'popularity'in'many'domains'of'scienGfic'and'highFperformance'compuGng.''How'do'they'close'this'gap?'
PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
• PythonVWrapped'C/C++'Libraries'(NumPy,!CVXOPT,!NLPy,!pythonOCC,!GEM5)''
• Numerical'JustVInVTime'Compilers'(Numba,!Parakeet)!!
• JustVInVTime'Compiled'Interpreters'(PyPy,!Pyston)!
• Selec8ve'Embedded'JustVInVTime'Specializa8on'(SEJITS)!
Cornell University Christopher Batten 58 / 66
Page 65
Research Overview XLOOPS PyMTL : { Methodology Gap Framework • Perf/Productivity Gap • SimJIT }
Performance-Productivity Gap
RTL�NetworkCL�Network
Simulated�CyclesSimulated�Cycles1K 10K 100K 1M10M
1x
5x10x
30x
75x150x300x
60x
200x
1000x
CPython PyPy VerilatorC++
1K10K 100K 1M
10x5x
1x
CPython PyPy
PerformanceHProductivity(Gap(
31'/'39'PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
30x'240x'
Cornell University Christopher Batten 59 / 66
Page 66
Research Overview XLOOPS PyMTL : { Methodology Gap Framework Perf/Productivity Gap • SimJIT • }
PyMTL OutlineOutline(
32'/'39'PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
The'Computer'Architecture'Research'Methodology'Gap'
The'PerformanceFProducGvity'Gap'
PyMTL'
SimJIT'
Cornell University Christopher Batten 60 / 66
Page 67
Research Overview XLOOPS PyMTL : { Methodology Gap Framework Perf/Productivity Gap • SimJIT • }
PyMTL SimJIT-RTL ArchitecturePyMTL(SimJIT(Architecture(
PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
PyMTL'RTL'Model'Instance'
TranslaGon'
Verilator'
LLVM/GCC' Wrapper'Gen'
Verilog'Source'
PyMTL'CFFI'Model'Instance'
RTL'C++'Source'
C'Interface'Source'
C'Shared'Library'
TranslaGon'Cache'
SimJITFRTL'Tool'
33'/'39'
Fairly'robust,'ready'for'use'in'research!'
Cornell University Christopher Batten 61 / 66
Page 68
Research Overview XLOOPS PyMTL : { Methodology Gap Framework Perf/Productivity Gap • SimJIT • }
PyMTL SimJIT-CL ArchitecturePyMTL(SimJIT(Architecture(
PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research' 34'/'39'
PyMTL'CL'Model'Instance'
TranslaGon' LLVM/GCC' Wrapper'Gen'
PyMTL'CFFI'Model'Instance'
CL'C++'Source'
C'Interface'Source'
C'Shared'Library'
SimJITFCL'Tool'
Just'a'prototype!'
Cornell University Christopher Batten 62 / 66
Page 69
Research Overview XLOOPS PyMTL : { Methodology Gap Framework Perf/Productivity Gap • SimJIT • }
Performance-Productivity Gap
RTL�NetworkCL�Network
Simulated�CyclesSimulated�Cycles1K 10K 100K 1M10M
1x
5x10x
30x
75x150x300x
60x
200x
1000x
CPython PyPy VerilatorC++
1K10K 100K 1M
10x5x
1x
CPython PyPy
PerformanceHProductivity(Gap(
PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
30x'240x'
35'/'39'
Cornell University Christopher Batten 63 / 66
Page 70
Research Overview XLOOPS PyMTL : { Methodology Gap Framework Perf/Productivity Gap • SimJIT • }
PyMTL SimJIT Performance
RTL�NetworkCL�Network
Simulated�CyclesSimulated�Cycles1K 10K 100K 1M10M
1x
5x10x
30x
75x150x300x
60x
200x
1000x
CPython PyPySimJIT-CL SimJIT-RTLSimJIT-CL+PyPy SimJIT-RTL+PyPy
VerilatorC++
1K10K 100K 1M
10x5x
1x
CPython PyPy
PyMTL(SimJIT(Performance(
36'/'39'PyMTL:'A'Unified'Framework'for'Ver8cally'Integrated'Computer'Architecture'Research'
4.5x' 6x'
Cornell University Christopher Batten 64 / 66
Page 71
Research Overview XLOOPS PyMTL : { Methodology Gap Framework Perf/Productivity Gap • SimJIT • }
f(x)
f(x)
PyMTL Take-Away Points
I PyMTL is a productive Python framework for FL,CL, and RTL modeling and hardware design
I SimJIT is a strong first step towards closing theperformance-productivity gap between Pythonand C++ simulation
I An alpha version of PyMTL is open source andavailable for researchers to experiment with
https://github.com/cornell-brg/pymtl
This work was supported in part by the National ScienceFoundation (NSF), the Defense Advanced Research ProjectsAgency (DARPA), and donations from Intel Corporation andSynopsys, Inc.
Cornell University Christopher Batten 65 / 66
Page 72
Research Overview XLOOPS: Explicit Loop Specialization PyMTL: Productive Hardware Modeling
f(x)
f(x)
Batten Research Group
Exploring cross-layer hardwarespecialization using a vertically
integrated researchmethodology
Performance (Tasks per Second)
En
erg
y E
ffic
ien
cy (
Ta
sks p
er
Joule
)
SimpleProcessor
Design PowerConstraint
High-PerformanceArchitectures
EmbeddedArchitectures
DesignPerformanceConstraint
Flexibility vs
. Spe
cializat
ion
CustomASIC
Less FlexibleAccelerator
More FlexibleAccelerator
loop:
lw r2, 0(rA)
lw r3, 0(rB)
...
addiu.xi rA, 4
addiu.xi rB, 4
addiu r1, r1, 1
xloop.uc r1, rN, loop
OoO GPP
L1 Data Cache
Lanes
Lane Manager
Mem XBar
#pragma xloops ordered
for(i = 0; i < N i++)
A[i] = A[i] * A[i-K];
#pragma xloops atomic
for(i = 0; i < N; i++)
B[ A[i] ]++;
D[ C[i] ]++;
Cornell University Christopher Batten 66 / 66