28
Compact Data Structures and Applications Gil Einziger and Roy Friedman Technion, Haifa
| Date post: | 31-Dec-2015 |
| Category: |
Documents |
| Upload: | adelia-preston |
| View: | 222 times |
| Download: | 1 times |

Compact Data Structures and Applications
Gil Einziger and Roy Friedman
Technion, Haifa

Approximate Set Membership• The problem:
– Maintain enough state to approximately answer set membership queries. (add/query).
• Things to consider:– False positive probability. – No false negatives! – A tradeoff between space and the false positive probability.
Bloom filters are the classical example.
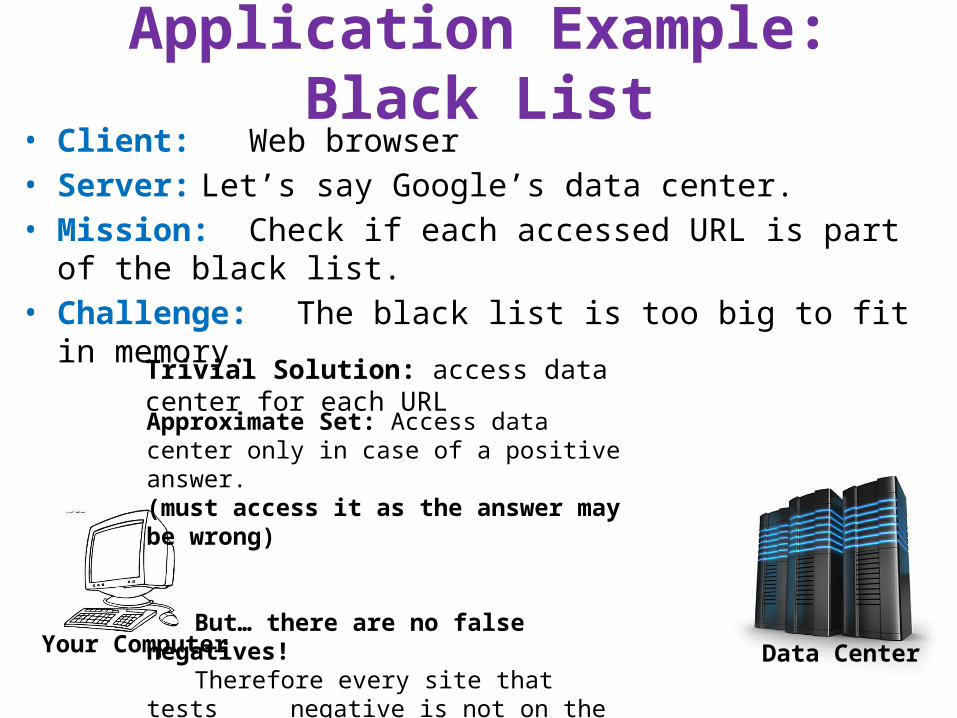
Application Example: Black List
Your Computer
• Client: Web browser • Server:Let’s say Google’s data center. • Mission: Check if each accessed URL is part of the black list. • Challenge: The black list is too big to fit in memory.
Data Center
Trivial Solution: access data center for each URL
Approximate Set: Access data center only in case of a positive answer.(must access it as the answer may be wrong)
But… there are no false negatives! Therefore every site that tests
negative is not on the list and we do not have to contact the datacenter.

Bloom Filters• An array BF of m bits and k hash functions {h1,…,hk} over the domain [0,
…,m-1]• Adding an object obj to the Bloom filter is done by computing h1(obj),
…, hk(obj) and setting the corresponding bits in the Bloom filter.• Checking for set membership for an object cand is done by computing
h1(cand),…, hk(cand) and verifying that all corresponding bits are set
m=11, k=3,
1 11
h1(o1)=0, h2(o1)=7, h3(o1)=5
BF=
h1(o2)=0, h2(o2)=7, h3(o2)=4
√
×

Approximate Counting
• Multiset: Instead of a query – ‘estimate’ operation
“How many times the item was added before?”
• Things to consider:– False positives– No false negatives
• we only get over approximation!
– A tradeoff between space and accuracyTypically solved with Bloom filter extensions – like Spectral Bloom filter, Count Min Sketch, Multi Stage Filters and many more.

Counting with Bloom Filter
• A vector of counters (instead of bits)• A counting Bloom filter supports the operations:
– Increment• Increment by 1 all entries that correspond to the results of the k hash
functions
– Decrement• Decrement by 1 all entries that correspond to the results of the k hash
functions
– Estimate (instead of get)• Return the minimal value of all corresponding entries
m=11
3 68
k=3, h1(o1)=0, h2(o1)=7, h3(o1)=5
CBF=
Estimate(o1)=4
4 9 7

Some Applications
• Google Chrome• Google BigTable• Apache Hadoop• Facebook’s) Apache) Casandra• Venti (archive system)• Cache Admission Policy– And many more…

Approximate Set with Hash Tables
17 12
• We use a bitwise array• The function: P assigns each item a place in the array. • The function: F assigns each item a fingerprint.
– The add operation writes f(o), in the location p(o).– The query operation compares p(o) with the content of f(o)
For example:
Only works when there are no collisions…
× p(o1)=3, h (o1)=7 p(o2)=5, h (o2)=12√

• Chain based hash table ? A single pointer is 64 bits – so most of the space is simply for pointers!
• Array ? Linear Probing?Can we do anything that is more space efficient than an array?
Handling Collisions

Bucket Chain Tag (fingerprint)
Inferred from place in table Only tag bits are stored.
TinyTable Overview

Chain Index (1 bit per chain)
Array
A
Is Last? ( 1 bit per item)
B C
Chain 2 is not empty
Second item is last in chain
First Item is not last
Chain 7 is empty
Encoding of a Single Bucket

Chain Index
Array ( 6 items of fixed size)
Is Last?
Logical View
Add B to chain 5:
A
A
B
B

Chain Index
Array ( 6 items of fixed size)
Is Last?
Logical View
Add C to chain 0:
A
A
B
B
A BC
C

Chain Index
Array ( 6 items of fixed size)
Is Last?
Logical View
Add D to chain 2:
A B
B
A BC
C
BD
D
A

Handling Overflows
“When a bucket overflows … ‘steal’ space from a neighboring bucket. “
Bucket 2
Items: 2Capacity: 5
Bucket 1
Items: 4Capacity: 5
Bucket 0
Items: 4Capacity: 5
Bucket 0
Items: 5Capacity: 5
Bucket 0
Items: 6Capacity: 6
Bucket 1
Items: 4Capacity: 4
Bucket 0
Items: 7Capacity: 7
Bucket 1
Items: 4Capacity: 4
Bucket 2
Items: 2Capacity: 4

Performance Tradeoff
• Denote:
– TinyTable works for every ;
when is close to 1 – update performance suffers.
𝜶=𝑨𝒍𝒍𝒐𝒄𝒂𝒕𝒆𝒅𝑺𝒑𝒂𝒄𝒆𝐑𝐞𝒒𝒖𝒊𝒓𝒆𝒅𝑺𝒑𝒂𝒄𝒆
𝜶>𝟏
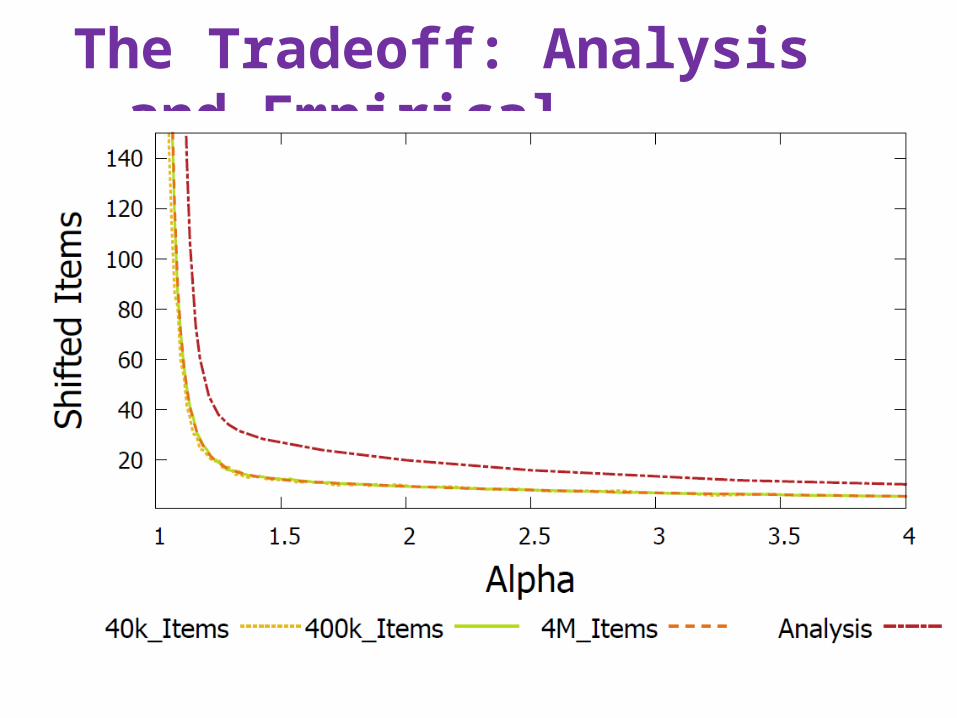
The Tradeoff: Analysis and Empirical

Time for 1 million operations (seconds)
Alpha = 1.2Alpha = 1.1Alpha = 1.025
Query is over 10 times faster than in Bloom filter, regardless of alpha.
Update Speed depends on alpha – and can be similar to that of Bloom filters.
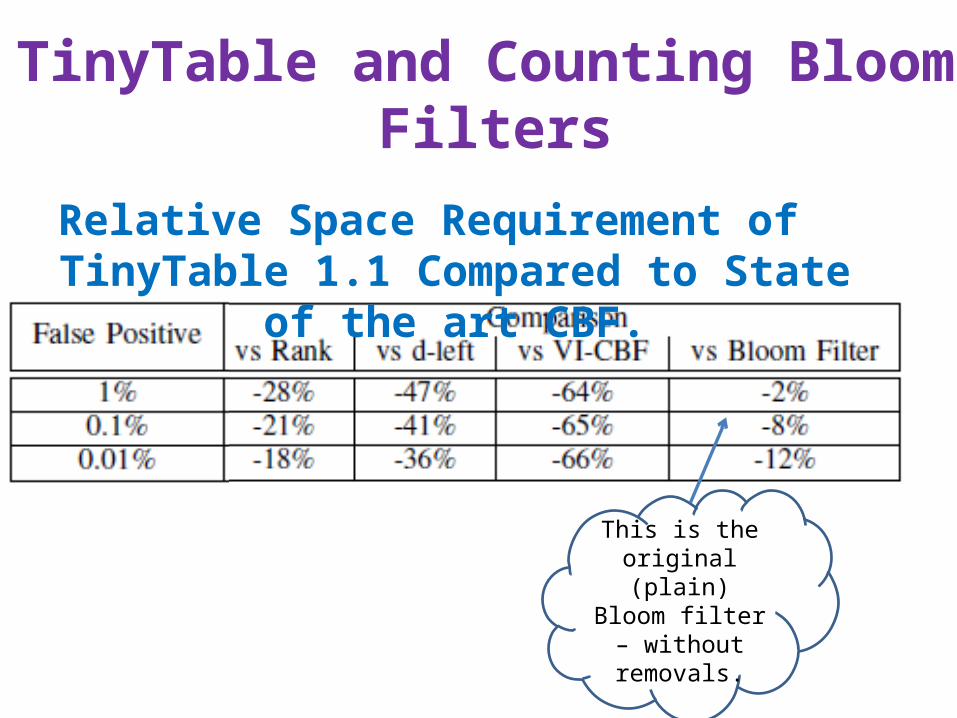
TinyTable and Counting Bloom Filters
This is the original (plain) Bloom filter –
without removals.
Relative Space Requirement of TinyTable 1.1 Compared to State of the art CBF.

TinyTable vs Table Based CBF
Alpha = 1.2Alpha = 1.1
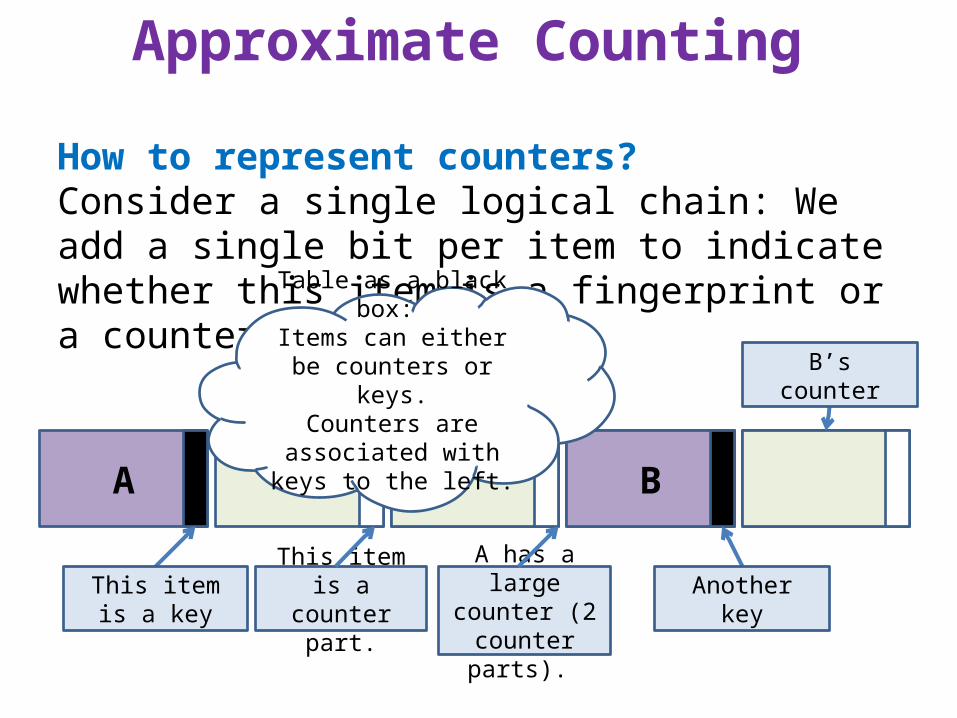
Approximate Counting
How to represent counters?Consider a single logical chain: We add a single bit per item to indicate whether this item is a fingerprint or a counter part.
A
This item is a key This item is a counter part.
A has a large counter (2
counter parts).
B
Another key
B’s counter
Table as a black box: Items can either be
counters or keys.Counters are associated
with keys to the left.

Summery: TinyTable • Query is always very fast. It is based on efficient
bitwise operations and very memory local.
• Update time depends on memory density, denser table = slower update.
• Full support of additions, removals and counting.
• Many attractive configurations! Can be made smaller than Bloom filters with reasonable (better) performance.

TinyTable (Alpha =1.2) vs Approximate Counting

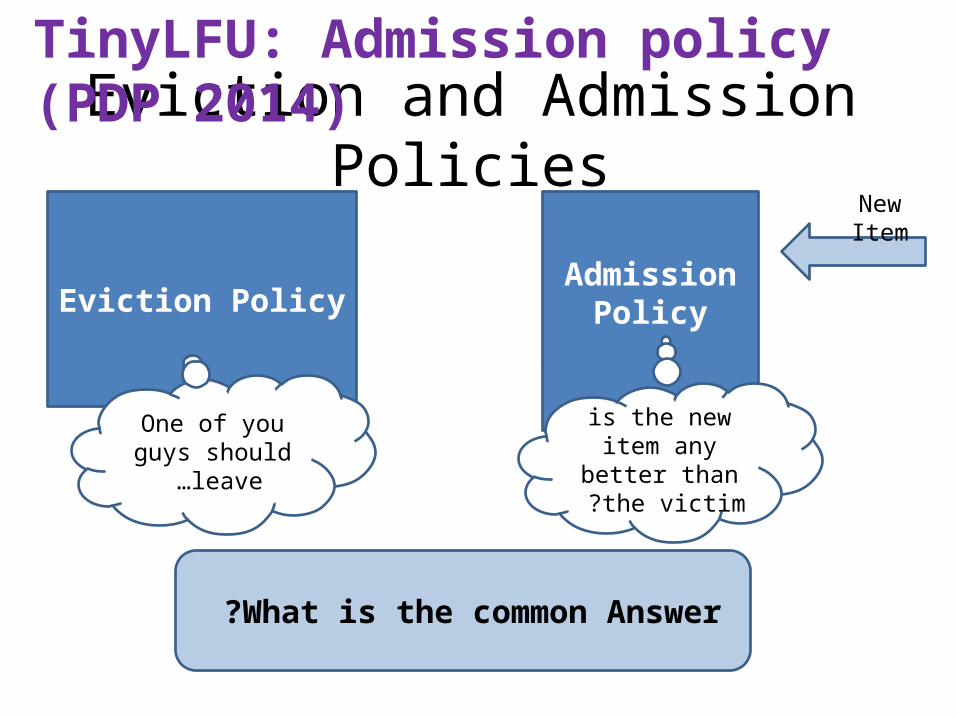
TinyLFU: Admission policy (PDP 2014)
It is not always beneficial to add a new item at the expense of cache victim.
Freq
uenc
y
Rank
Long Heavy Tail For example~(50% of the weight)
A small number of very popular itemsFor example~(50% of the weight)
Cache Victim
Winner
Eviction and Admission Policies
Eviction PolicyAdmission
Policy
New Item
One of you guys should leave …
is the new item any better than
the victim ?
What is the common Answer ?
TinyLFU: Admission policy (PDP 2014)

TinyLFU: (PDP 2014)
TinyTable
Use a sample of recent events to manage cache.(alternative implementation)

TinyLFU: Admission policy results
1. Low metadata overhead less than 8 bytes per cache line.2. Higher cache hit rate3. Faster cache operation (Query is faster than update)

TinyTable is soon to be released as an open source project. TinyLFU was released as the Shades open source project.
I believe there are many other applications!
Thank you for your Time!(and use my hash table – it is awesome)

















