Compression •Word document: 1 page is about 2 to 4kB •Raster Image of 1 page at 600 dpi is about 35MB •Compression Ratio, CR = , where is the number of bits •Compression techniques take advantage of: • Sparse coverage • Repetitive scan lines • Large smooth gray areas • ASCII code, always 8 bits per character • Long words frequently used comp orig
Transcript
Compression
•Word document: 1 page is about 2 to 4kB
•Raster Image of 1 page at 600 dpi is about 35MB
•Compression Ratio, CR = , where is the number of bits
•Compression techniques take advantage of:
• Sparse coverage
• Repetitive scan lines
• Large smooth gray areas
• ASCII code, always 8 bits per character
• Long words frequently used
comp
orig
i
N
ii ppsH 2
1
log)(
Entropy
•Entropy is a quantitative term used for amount of information in a string
0.0 0.2 0.4 0.6 0.8 1.0
1.00
0.80
0.60
0.40
0.20
0.00
H(1)+H(0)
H(1)
H(0)
)(log)()(1
2
N
iii lplpsH
For N clusters, where li is the length of the ith cluster
)(/max sHlCR
Binary Image Compression Techniques
•Packing: 8 pixels per byte
•Run Length Encoding: Assume 100 dpi, 850 bits per line
• encode only the white bits as they are long runs
• Top part of a page could be 0(200)111110(3)111110(3) ….
•Huffman Coding: use short length codes for frequent messages
Message Probability
A 0.30
B 0.25
C 0.20
D 0.10
E 0.15
A .30 .30 .45 .55
B .25 .25 .30 .45
C .20 .25 .25
E .15 .20
D .10
A 00
.30
00 .30
1 .45
0
.55
B 01.25
01.25
00.30
1.45
C 11.20
10.25
01.25
E 100.15
11.20
D 10110
Encode Decode
Huffman Encoding0
(2,7) (13,2) 0
(2,7) (13,2) 0
(2,7) (13,2) 0
(2,2) (7,2) (13,2) 0
(2,2) (7,2) (13,2) 0
(2,7) (13,2) 0
(2,2)(7,2)(13,2) 0
(2,2)(7,2)(13,2) 0
0
Bit map: 160 bits
50 numbers in range 0-15
Use 4 bits per number: 200 bits
2 bits per symbol: 100 bits
HC: 1.84 x 50 = 92 bits
84.116.0316.0320.0248.01)( ii
iaverage sPlL
Predictive Coding
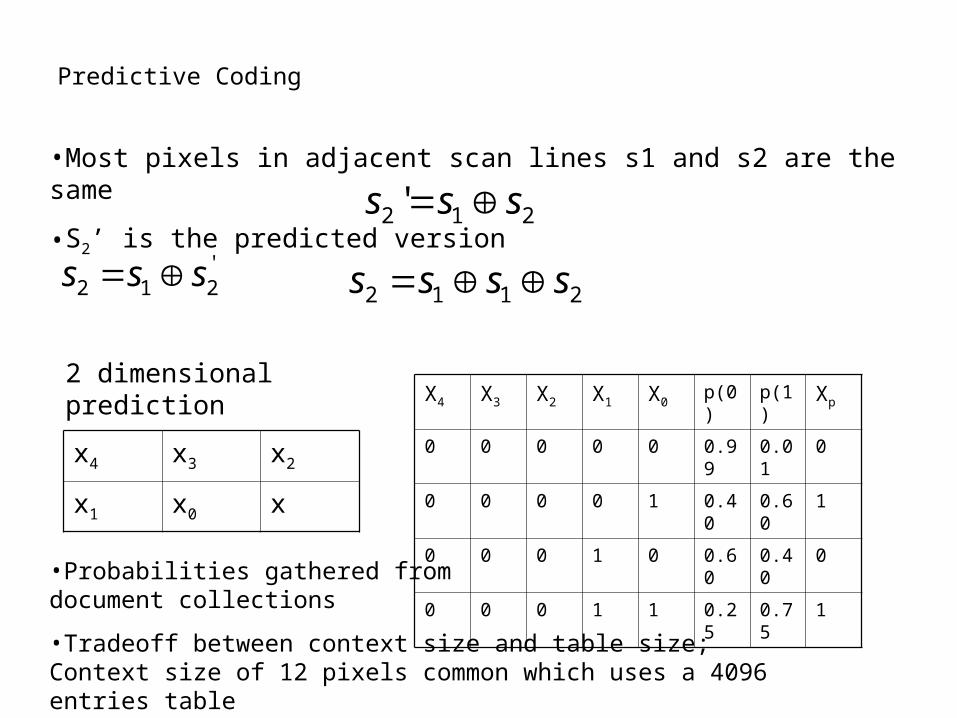
•Most pixels in adjacent scan lines s1 and s2 are the same
•Tradeoff between context size and table size; Context size of 12 pixels common which uses a 4096 entries table
Group III Fax
•White runs and black runs alternate
•All lines begin with a white run (possibly length zero)
•There are 1728 pixels in a scan line
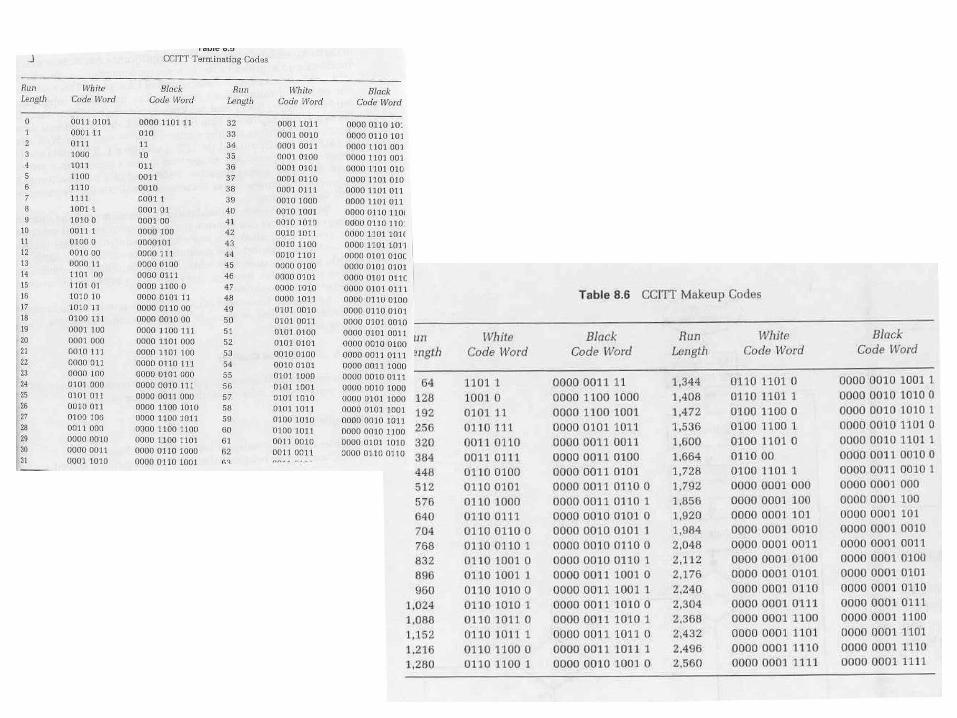
•Makeup codes encode a multiple of 64 bits
•Terminating codes encode the remainder (0 to 63)
•EOL for each line
•CCITT lookup tables
•Example,
• White run of 500 pixels would be encoded as
• 500 = 7x 64 + 52
• Makeup code for 7x 64 is 0110 0100
• Terminating code for 52 is 0101 0101
• Complete code is 0110 0100 0101 0101
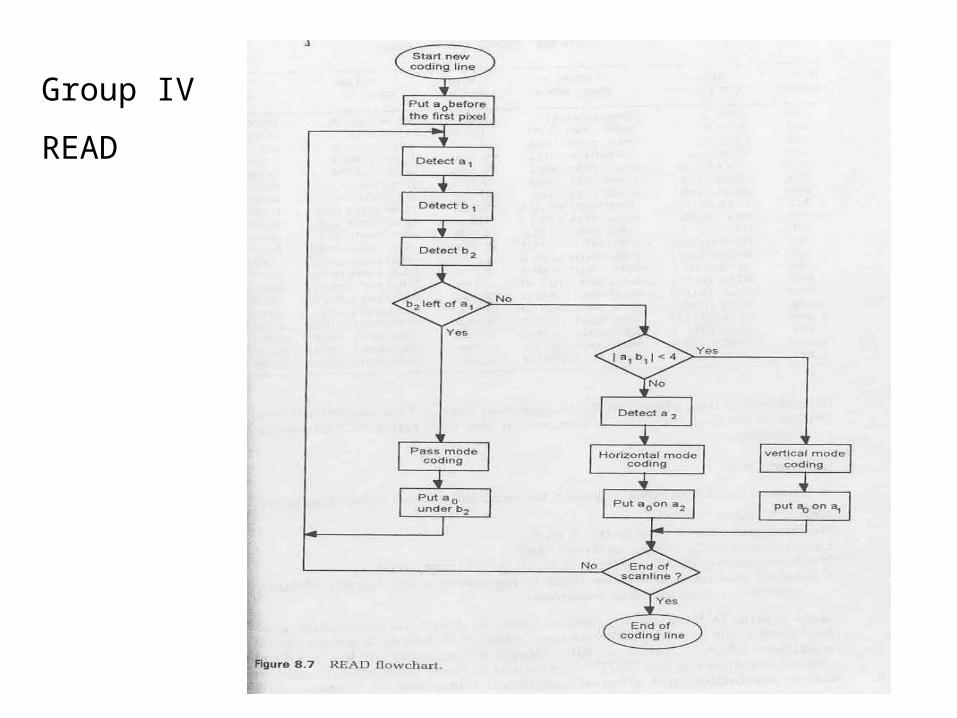
Group IV READ
1 1 1 1 0 0 0 0 1 1 1 0 0 0 0
1 1 0 0 0 0 1 1 1 1 1 1 0 0 0
Reference
Coding
a0
b1
a2a1
b2
•a0 is the reference changing pixel; a1 is the next changing pixel after a0; and a2 is the next changing pixel after a1.
•b1 is the first changing pixel on the reference line after a0 and is of opposite color to a0; b2 is the next changing pixel after b1.
•To start, a0 is located at an imaginary white pixel point immediately to the left of the coding line.
•Follow READ algorithm chart
Group IV
READ
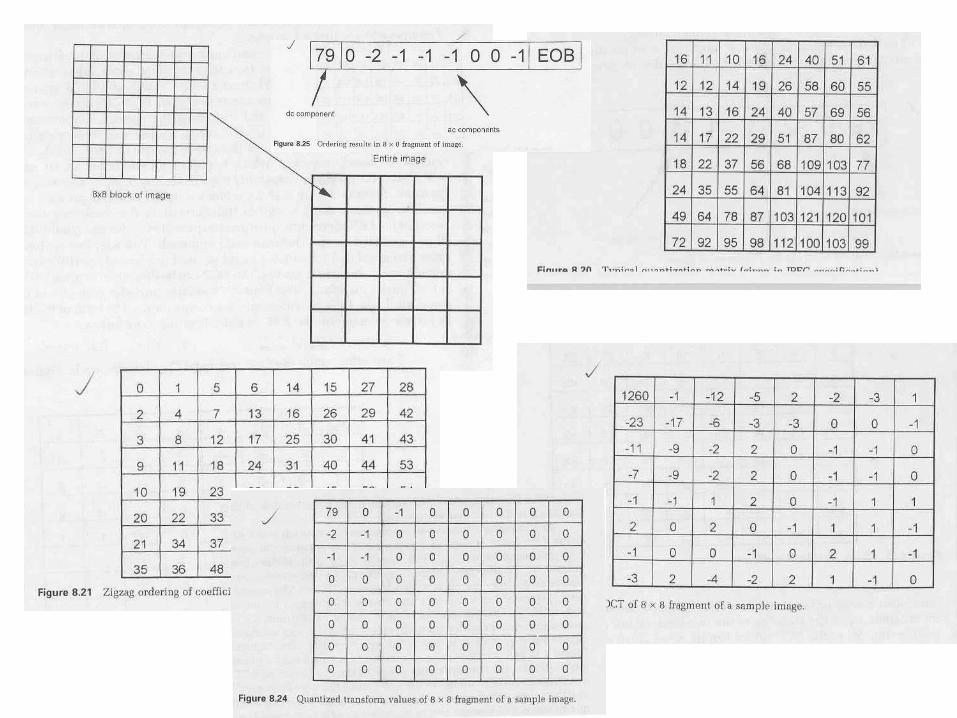
Grayscale Compression- JPEG
16
)12(cos
16
)12(cos),(
4
)()(),(
vkujkjf
vCuCvuF
16
)12(cos
16
)12(cos),()()(
4
1),(
7
0
7
0
vjuivuFvCuCjif
u v
7
0 16
)12(cos),(
2
)(),(
j
ujvjg
uCvuF
16
)12(cos),(
2
)(),(
7
0
vkkjf
vCvjg
k
Information Retrieval (Typed text documents)•IR goal is to represent a collection of documents were a single document is the smallest unit of information
•Typify document content and present information upon request
Requests DocumentsSimilarity Measure
1. OCR translates images of text to computer readable form and IR extracts the text upon request
2. Inverted Index: Transpose the document-term relationship to a term-document relationship
3. Remove Stopwords: the, and, to, a, in, that, through, but, etc.
4. Word Stemming: Remove prefixes and suffixes and normalize
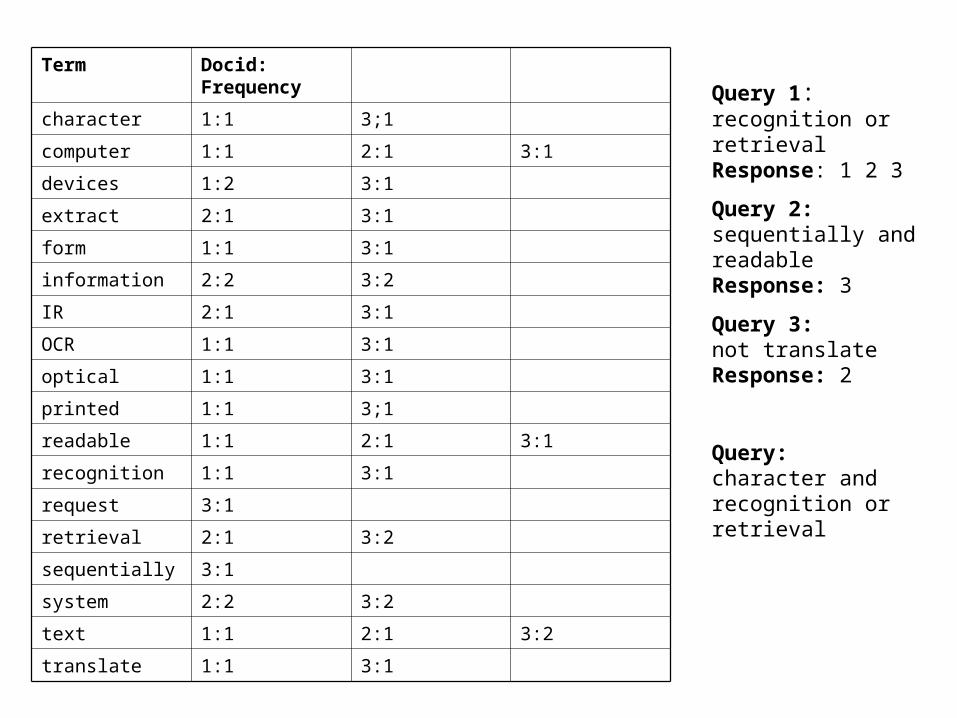
Term Docid: Frequency
character 1:1 3;1
computer 1:1 2:1 3:1
devices 1:2 3:1
extract 2:1 3:1
form 1:1 3:1
information 2:2 3:2
IR 2:1 3:1
OCR 1:1 3:1
optical 1:1 3:1
printed 1:1 3;1
readable 1:1 2:1 3:1
recognition 1:1 3:1
request 3:1
retrieval 2:1 3:2
sequentially 3:1
system 2:2 3:2
text 1:1 2:1 3:2
translate 1:1 3:1
Query 1: recognition or retrievalResponse: 1 2 3
Query 2:sequentially and readableResponse: 3
Query 3: not translateResponse: 2
Query:character and recognition or retrieval
Vector Space Model
•Each document is denoted by a vector of concepts (index terms)
•If the term is present in the document 1 is placed in the vector