There are growing interests in applying sparse techniques tomachine learning and image processing:
SVM can be done in compressed domain [CJS09];Multi-label prediction via CS [HKLZ09];Bayesian inference for reconstruction [HC09, DWB08] [IMD06];Bayesian inference for image denoising, inpainting...
This work and take-away message: pick an interestingproblem to showcase compressed measurements are as goodas complete measurements as long as you have enoughmeasurements.
Yuejie Chi ICIP 2010: Compressive BSS
BackgroundsBayesian Probabilistic Inference
Numerical ResultsConclusions and Future Work
MotivationsBackground
Bridging Compressive Sensing and Machine Learning
There are growing interests in applying sparse techniques tomachine learning and image processing:
SVM can be done in compressed domain [CJS09];Multi-label prediction via CS [HKLZ09];Bayesian inference for reconstruction [HC09, DWB08] [IMD06];Bayesian inference for image denoising, inpainting...
This work and take-away message: pick an interestingproblem to showcase compressed measurements are as goodas complete measurements as long as you have enoughmeasurements.
Yuejie Chi ICIP 2010: Compressive BSS
BackgroundsBayesian Probabilistic Inference
Numerical ResultsConclusions and Future Work
MotivationsBackground
Motivations
Blind Source Separation (BSS) from conventional mixtures
Important in many areas: speech recognition, MIMOcommunications, etc.
In many cases, measurements are expensive:
Body Area Networks (BAN): sensors are power hungry andneed to last a few days to a few weeks.Recent developments in Compressive Sensing (CS) provide anintriguing solution.
Our work: recover mixtures from small measurements:
Conventional methods like PCA and ICA may fail due toreduced dimensionality.
Yuejie Chi ICIP 2010: Compressive BSS
BackgroundsBayesian Probabilistic Inference
Numerical ResultsConclusions and Future Work
MotivationsBackground
Motivations
Blind Source Separation (BSS) from conventional mixtures
Important in many areas: speech recognition, MIMOcommunications, etc.
In many cases, measurements are expensive:
Body Area Networks (BAN): sensors are power hungry andneed to last a few days to a few weeks.Recent developments in Compressive Sensing (CS) provide anintriguing solution.
Our work: recover mixtures from small measurements:
Conventional methods like PCA and ICA may fail due toreduced dimensionality.
Yuejie Chi ICIP 2010: Compressive BSS
BackgroundsBayesian Probabilistic Inference
Numerical ResultsConclusions and Future Work
MotivationsBackground
Motivations
Blind Source Separation (BSS) from conventional mixtures
Important in many areas: speech recognition, MIMOcommunications, etc.
In many cases, measurements are expensive:
Body Area Networks (BAN): sensors are power hungry andneed to last a few days to a few weeks.Recent developments in Compressive Sensing (CS) provide anintriguing solution.
Our work: recover mixtures from small measurements:
Conventional methods like PCA and ICA may fail due toreduced dimensionality.
Yuejie Chi ICIP 2010: Compressive BSS
BackgroundsBayesian Probabilistic Inference
Numerical ResultsConclusions and Future Work
MotivationsBackground
Background: Compressive Sensing
Recovery of a sparse or compressible signal from a smallnumber of linear measurements [Don06, CT05].
y = Φx + n, Φ ∈ CM×N , M � N
Many classes of reconstruction algorithms available now:
Theoretical performance gaurantee is usually given byRestricted Isometry Property (RIP) of measurement matrixsatisfied by random matrices with high probability.
Yuejie Chi ICIP 2010: Compressive BSS
BackgroundsBayesian Probabilistic Inference
Numerical ResultsConclusions and Future Work
MotivationsBackground
Background: Compressive Sensing
Recovery of a sparse or compressible signal from a smallnumber of linear measurements [Don06, CT05].
y = Φx + n, Φ ∈ CM×N , M � N
Many classes of reconstruction algorithms available now:
Theoretical performance gaurantee is usually given byRestricted Isometry Property (RIP) of measurement matrixsatisfied by random matrices with high probability.
Yuejie Chi ICIP 2010: Compressive BSS
BackgroundsBayesian Probabilistic Inference
Numerical ResultsConclusions and Future Work
MotivationsBackground
Background: Compressive Sensing
Recovery of a sparse or compressible signal from a smallnumber of linear measurements [Don06, CT05].
y = Φx + n, Φ ∈ CM×N , M � N
Many classes of reconstruction algorithms available now:
Theoretical performance gaurantee is usually given byRestricted Isometry Property (RIP) of measurement matrixsatisfied by random matrices with high probability.
Yuejie Chi ICIP 2010: Compressive BSS
BackgroundsBayesian Probabilistic Inference
Numerical ResultsConclusions and Future Work
MotivationsBackground
Background: Blind Source Separation
Goal: to recover T independent sources from L observedmixture of sources, possibly corrupted by noise.
X = ΘA + ε
where
X ∈ CN×L is the matrix of observations;Θ ∈ CN×T is the matrix of sources;ε ∈ CN×L is the noise;A ∈ CT×L is the mixing matrix.
Without loss of generality, we let all representations lie in thewavelet domain.
particularly fit for image applications.
Yuejie Chi ICIP 2010: Compressive BSS
BackgroundsBayesian Probabilistic Inference
Numerical ResultsConclusions and Future Work
MotivationsBackground
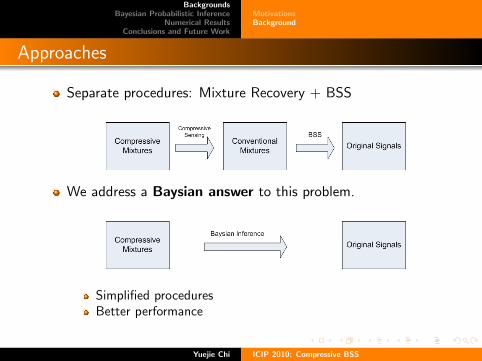
Approaches
Separate procedures: Mixture Recovery + BSS
We address a Baysian answer to this problem.
Simplified proceduresBetter performance
Yuejie Chi ICIP 2010: Compressive BSS
BackgroundsBayesian Probabilistic Inference
Numerical ResultsConclusions and Future Work
Problem FormulationPrior DistributionMarkov Chain Monte Carlo
Problem Formulation
Compressed measurements of mixtures of the sources:
Y = ΦΘA + N,
sop(Yk |Φ,Θ,A, αN
k ) ∼ N (ΦΘAk , (αNk )−1I),
where Yk and Ak are the kth columns of Y and A..
To maximize the posterior distribution:
p(Θ,A,N|Y,Φ)
∝ p(Y|Φ,Θ,A, αN)π(N|αN)π(A|αA)π(Θ|αΘ)
where α = [αN, αA, αΘ] is the set of the hyper parameters.
Yuejie Chi ICIP 2010: Compressive BSS
BackgroundsBayesian Probabilistic Inference
Numerical ResultsConclusions and Future Work
Problem FormulationPrior DistributionMarkov Chain Monte Carlo
Hidden Markov Tree Model
Model the statistical dependencies between wavelet-domaincoefficients. [CNB98]
Persistence:Parent node large/small
h.p.−→ Child node large/small
A node large/smallh.p.−→ Adjacent nodes large/small
Mixed Gaussian Model:
θs,i ∼ (1− πs,i )δ0
+πs,iN (0, (αs)−1)
Yuejie Chi ICIP 2010: Compressive BSS
BackgroundsBayesian Probabilistic Inference
Numerical ResultsConclusions and Future Work
Problem FormulationPrior DistributionMarkov Chain Monte Carlo
Prior Distributions
Prior distribution of noise variance:
αNk ∼ Gamma(a0, b0)
Prior distribution of A = {aij}:
aij ∼ N (µij , α−1ij ), 1 ≤ i ≤ T , 1 ≤ j ≤ L
Prior distributions of Θ:
θs,i ∼ (1− πs,i )δ0 + πs,iN (0, (αs)−1)
with πs,i =
πr ∼ Beta(er0, f
r0 ), if s = 1
πs0 ∼ Beta(es00 , f
s00 ), if 2 ≤ s ≤ S , θp(s,i) = 0
πs1 ∼ Beta(es10 , f
s10 ), if 2 ≤ s ≤ S , θp(s,i) 6= 0
αs ∼ Gamma(c0, d0)
Yuejie Chi ICIP 2010: Compressive BSS
BackgroundsBayesian Probabilistic Inference
Numerical ResultsConclusions and Future Work
Problem FormulationPrior DistributionMarkov Chain Monte Carlo
MCMC
The Gibbs sampler samples from the following conditionaldistributions at iteration t,