Computational evolution of decision-making strategies Peter Kvam Center for Adaptive Rationality, Max Planck Institute for Human Development Department of Psychology, Michigan State University Joseph Cesario Department of Psychology, Michigan State University Jory Schossau Department of Computer Science and Engineering, Michigan State University Heather Eisthen Department of Integrative Biology, Michigan State University Arend Hintze Department of Integrative Biology, Michigan State University
Transcript
Computational evolution of
decision-making strategies
Peter KvamCenter for Adaptive Rationality, Max Planck Institute for Human Development
Department of Psychology, Michigan State University
Joseph CesarioDepartment of Psychology, Michigan State University
Jory SchossauDepartment of Computer Science and Engineering, Michigan State University
Heather EisthenDepartment of Integrative Biology, Michigan State University
Arend HintzeDepartment of Integrative Biology, Michigan State University
Introduction
• We often take a strategy-first approach when
constructing decision-making models
– Assume optimal, approximately optimal, specific heuristics,
utility-based, or other principled strategy
– Then see what practical limitations are and in what environments
it succeeds
– Success = strategy is adaptive
• This is a bit backwards
– In reality, strategies are adaptive because they arise from the
environment, not vice versa
– We instead take the opposite approach, examining strategies
that evolve in response to task environment
Introduction
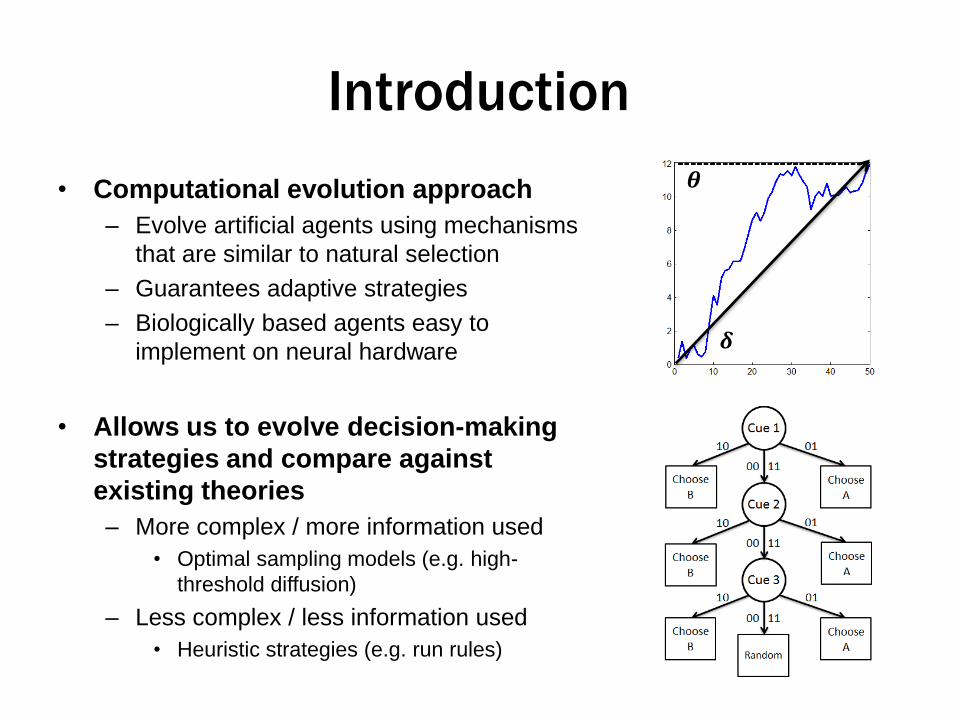
• Computational evolution approach
– Evolve artificial agents using mechanisms
that are similar to natural selection
– Guarantees adaptive strategies
– Biologically based agents easy to
implement on neural hardware
• Allows us to evolve decision-making
strategies and compare against
existing theories
– More complex / more information used
• Optimal sampling models (e.g. high-
threshold diffusion)
– Less complex / less information used
• Heuristic strategies (e.g. run rules)
𝜹
𝜽
Goals
• Examine a common task that animals in almost every ecological niche have to solve– Binary perceptual decision
• Incoming information is from source A or source B -- agent must determine which one
• e.g. predator / prey, edible / inedible, track A / B
– Optional stopping (agent terminates search)
• Examine strategies that they develop– Examine structure of their brains
– Behavioral accuracy, brain complexity, amount of information use
Methods
• Task
– Discriminate between sources of incoming information
– Comes from either majority [01] (right) or majority [10] (left)
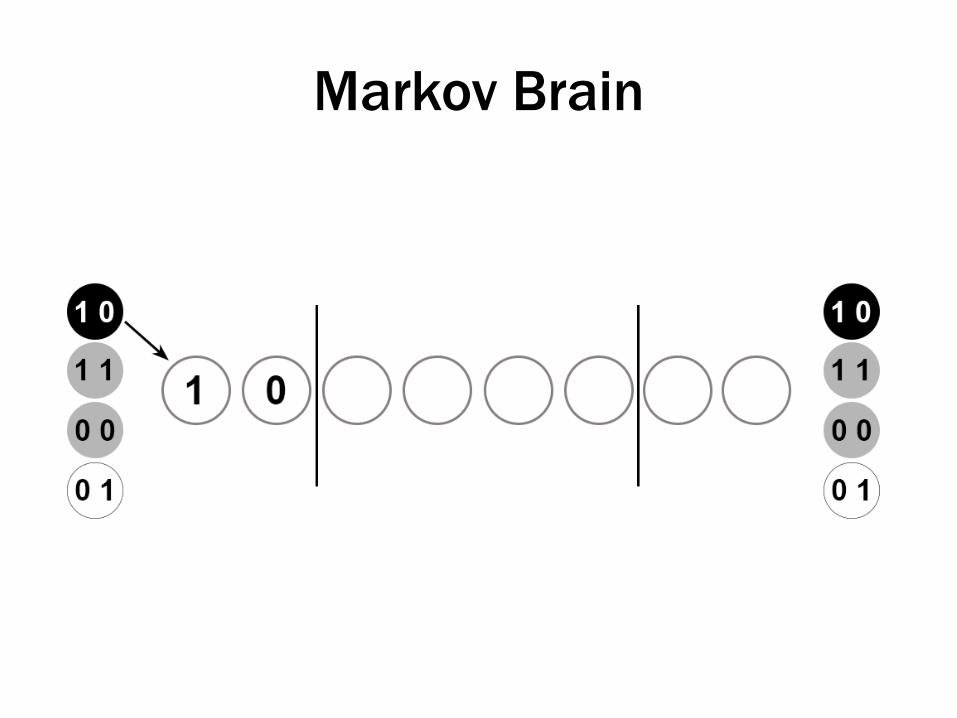
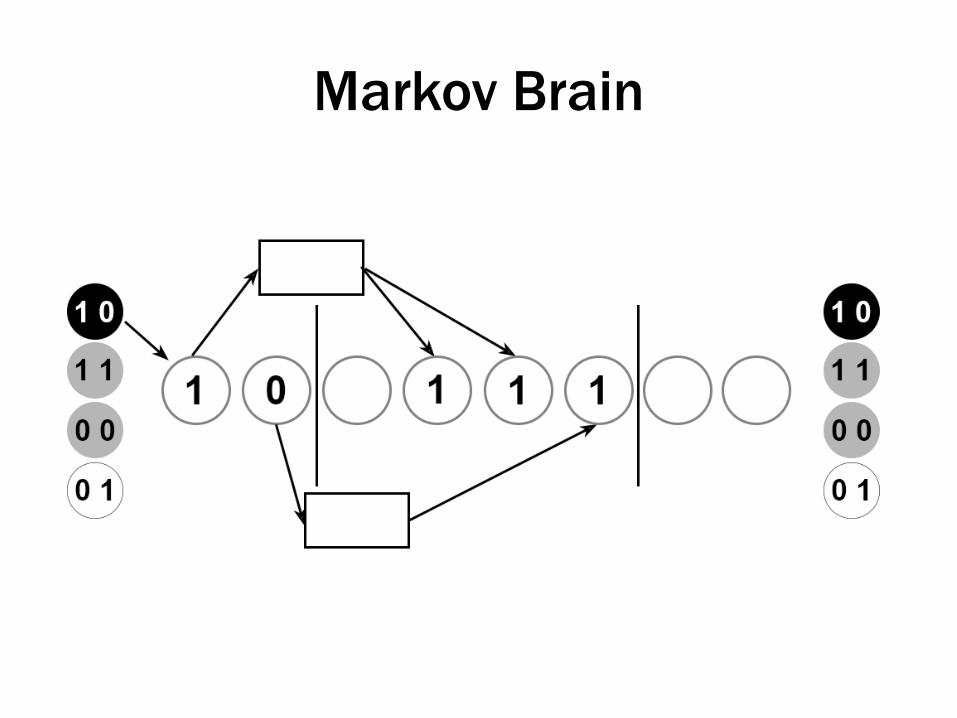
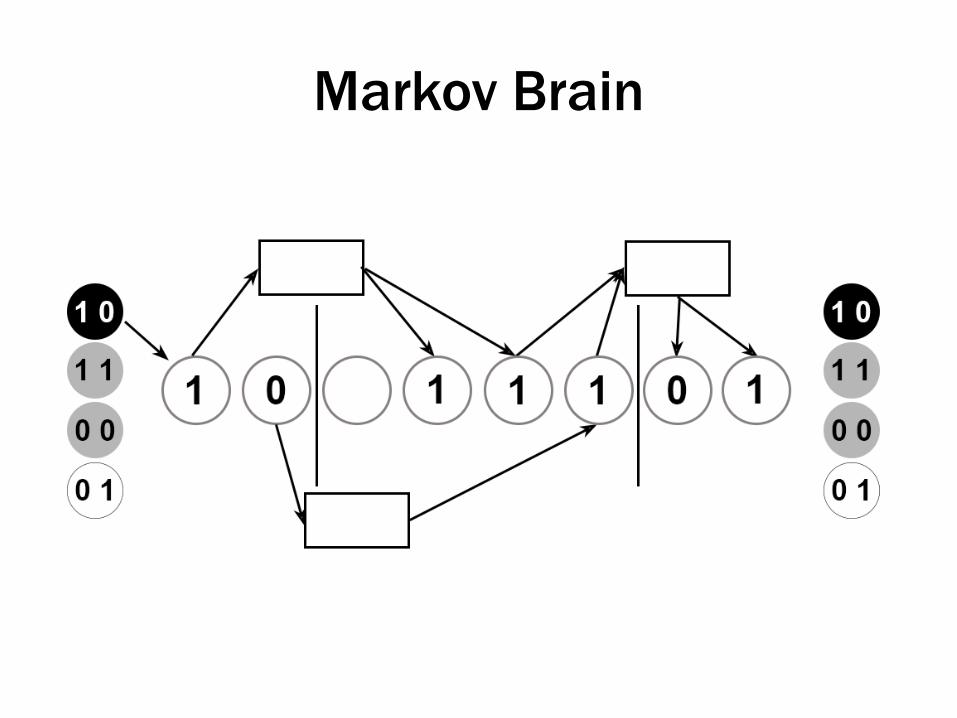
• Agents
– Markov brains (16-bit)
• Have 16 nodes, used for input, processing, output of information
• Nodes are causally connected via logic gates
• Genetic code gives rise to pattern of connections
Organism has to indicate which one using its output nodes
Markov Brain
Markov Brain
Markov Brain
Markov Brain
Markov Brain
Markov Brain
Setup
• 100 organisms per generation
– Each one has its own genome and node structure
• Each organism makes 100 left [10] / right [01] decisions
during its lifetime (actual direction is random)
– Gains points for every correct answer, loses points for incorrect
• Reproduction based on performance (roulette wheel)
– Offspring accumulate mutations in genome to set node structure
– Poor performers simply die off without reproducing
Data
• Focus on manipulations of difficulty
• Fitness – asymptotic performance of population
• Brain size - # of connections between nodes in the
artificial brains
• Strategy use – how much information do the agents
use, and how long do they gather it?
Fitness
90% 85% 80% 75%
70% 65% 60%
• Agents achieved near-
perfect accuracy in
most conditions except
most difficult
• Even then, worst
performance was
~80% accuracy
Strategies
• Simple heuristic strategies
– Should use very little information
– Terminate search early
– Small brains
• Complex evidence accumulation strategies
– Should use a large amount of information
– Gather information over a protracted period
– Large brains
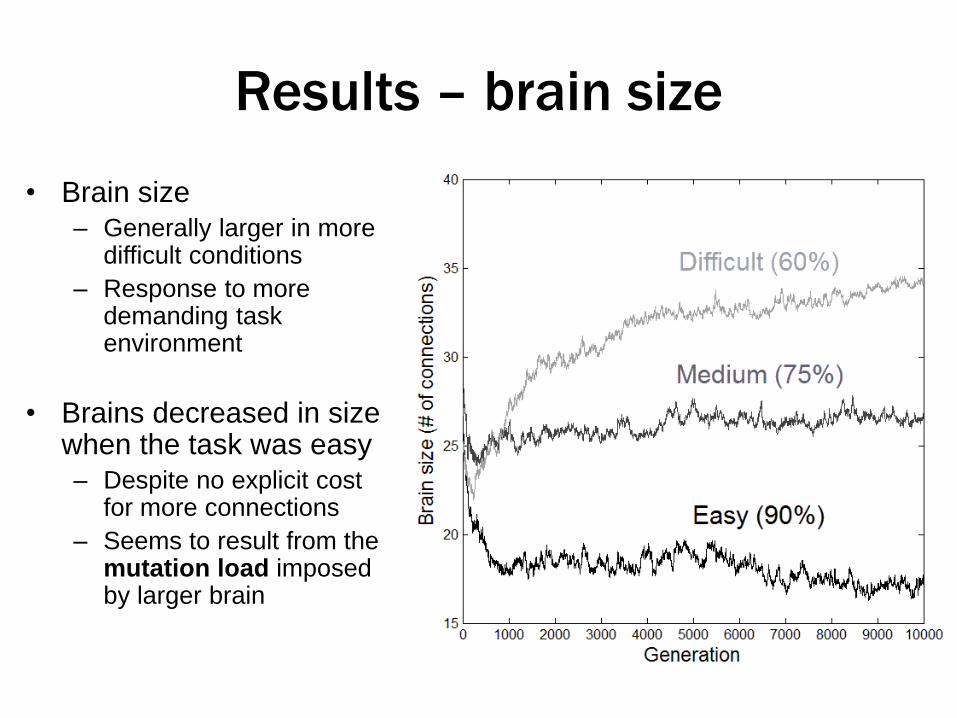
Results – brain size
• Brain size
– Generally larger in more difficult conditions
– Response to more demanding task environment
• Brains decreased in size when the task was easy
– Despite no explicit cost for more connections
– Seems to result from the mutation load imposed by larger brain
Results – strategy use
• More difficult conditions led to more information use– Agents also gathered information over a more protracted period
Conclusions
• Difficulty of task environment plays a huge role in evolutionary trajectory of artificial agents– Behavior scales based on environmental demands,
– Not strictly based on optimal decision strategies
• Agents in difficult conditions evolved large brains, integrated lots of information over a protracted period– Strategies resembled complex sequential sampling strategies
• Agents in easier conditions evolved smaller brains, used relatively little information– Brain size seems to be limited by mutation load