Page 1
Concurrent Data Structures in Architectures with
Limited Shared Memory Support
Ivan WalulyaYiannis NikolakopoulosMarina Papatriantafilou
Philippas Tsigas
Distributed Computing and SystemsChalmers University of TechnologyGothenburg, Sweden
Page 2
Yiannis Nikolakopoulos [email protected]
2
Concurrent Data Structures• Parallel/Concurrent programming:– Share data among threads/processes,
sharing a uniform address space (shared memory)
• Inter-process/thread communication and synchronization– Both a tool and a goal
Page 3
Yiannis Nikolakopoulos [email protected]
3
Concurrent Data Structures:Implementations
• Coarse grained locking– Easy but slow...
• Fine grained locking– Fast/scalable but: error-prone, deadlocks
• Non-blocking– Atomic hardware primitives (e.g. TAS, CAS)– Good progress guarantees (lock/wait-freedom)– Scalable
Page 4
Yiannis Nikolakopoulos [email protected]
4
What’s happening in hardware?• Multi-cores many-cores– “Cache coherency wall”
[Kumar et al 2011]– Shared address space
will not scale– Universal atomic primitives (CAS, LL/SC) harder to
implement• Shared memory message passing
Cache Cache
IA Core
Shared Local
Page 5
Yiannis Nikolakopoulos [email protected]
5
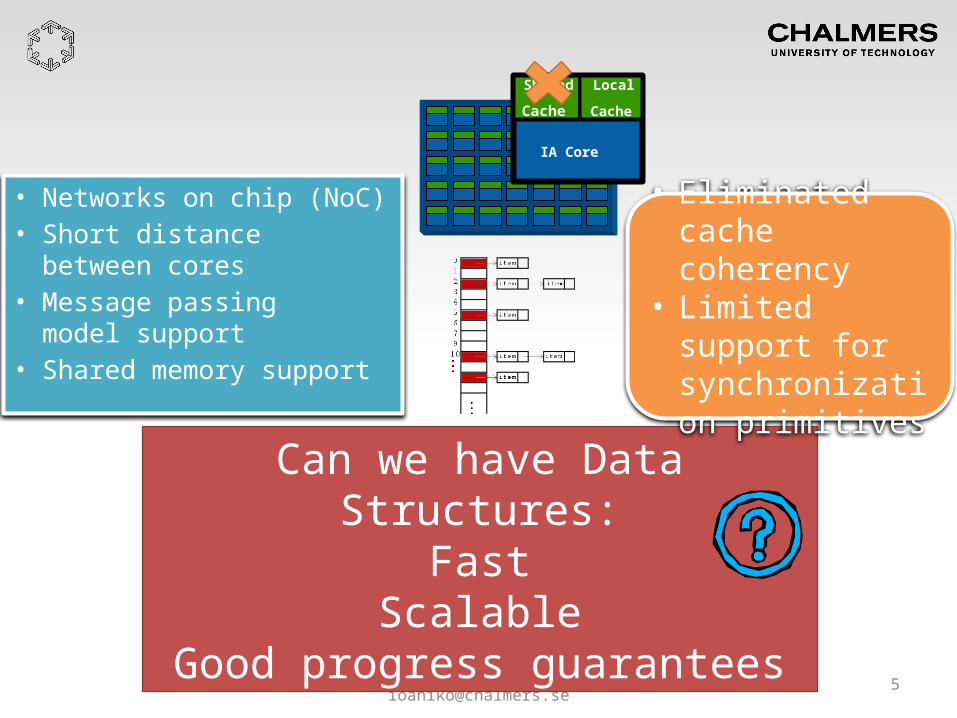
• Networks on chip (NoC)• Short distance
between cores• Message passing
model support• Shared memory support
Can we have Data Structures:Fast
ScalableGood progress guarantees
Cache Cache
IA Core
Shared Local
• Eliminatedcache coherency
• Limited support for synchronization primitives
Page 6
Yiannis Nikolakopoulos [email protected]
6
Outline• Concurrent Data Structures• Many-core architectures• Intel’s SCC• Concurrent FIFO Queues• Evaluation• Conclusion
Page 7
Yiannis Nikolakopoulos [email protected]
7
Single-chip Cloud Computer (SCC)• Experimental processor by Intel• 48 independent x86 cores arranged on 24 tiles• NoC connects all tiles• TestAndSet register
per core
Page 8
Yiannis Nikolakopoulos [email protected]
8
SCC: Architecture Overview
Memory Controllers:to private & shared
main memory
Message Passing
Buffer (MPB) 16Kb
Page 9
Yiannis Nikolakopoulos [email protected]
9
Programming Challenges in SCC• Message Passing but…– MPB small for
large data transfers– Data Replication is difficult
• No universal atomic primitives (CAS); no wait-free implementations [Herlihy91]
Page 10
Yiannis Nikolakopoulos [email protected]
10
Outline• Concurrent Data Structures• Many-core architectures• Intel’s SCC• Concurrent FIFO Queues• Evaluation• Conclusion
Page 11
Yiannis Nikolakopoulos [email protected]
11
Concurrent FIFO Queues• Main idea:– Data are stored in shared off-chip memory– Message passing for communication/coordination
• 2 design methodologies:– Lock-based synchronization (2-lock Queue)– Message passing-based synchronization
(MP-Queue, MP-Acks)
Page 12
Yiannis Nikolakopoulos [email protected]
12
2-lock Queue• Array based, in shared off-chip memory (SHM)• Head/Tail pointers in MPBs• 1 lock for each pointer [Michael&Scott96]• TAS based locks on 2 cores
Page 13
Yiannis Nikolakopoulos [email protected]
13
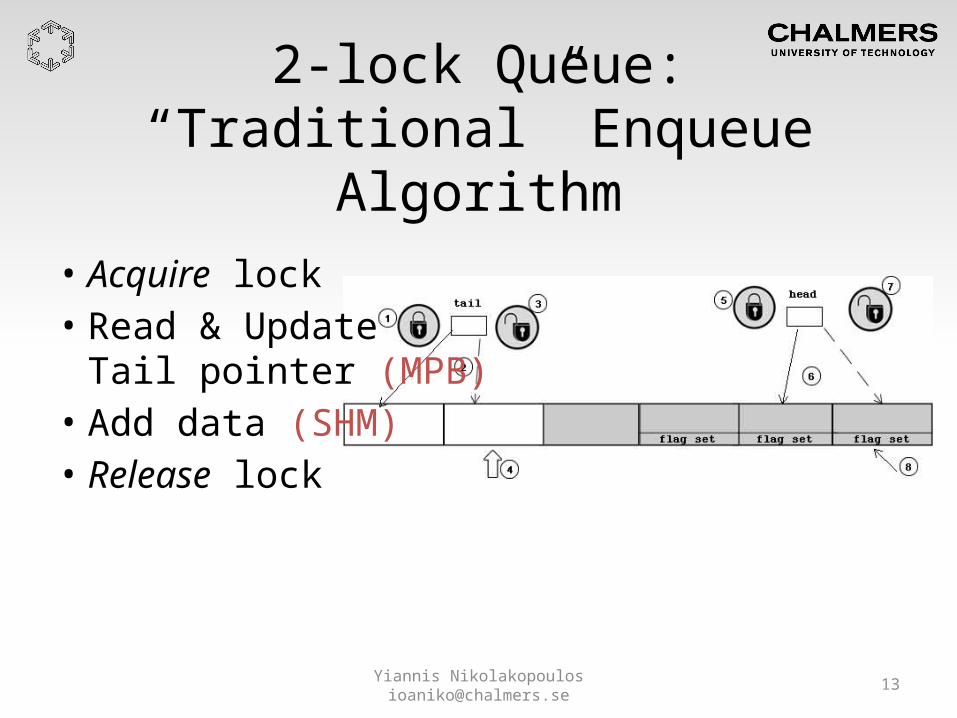
2-lock Queue:“Traditional” Enqueue Algorithm
• Acquire lock• Read & Update
Tail pointer (MPB)• Add data (SHM)• Release lock
Page 14
Yiannis Nikolakopoulos [email protected]
14
2-lock Queue:Optimized Enqueue Algorithm
• Acquire lock• Read & Update
Tail pointer (MPB)• Release lock• Add data to node SHM• Set memory flag to dirty Why?
No Cache Coherency!
Page 15
Yiannis Nikolakopoulos [email protected]
15
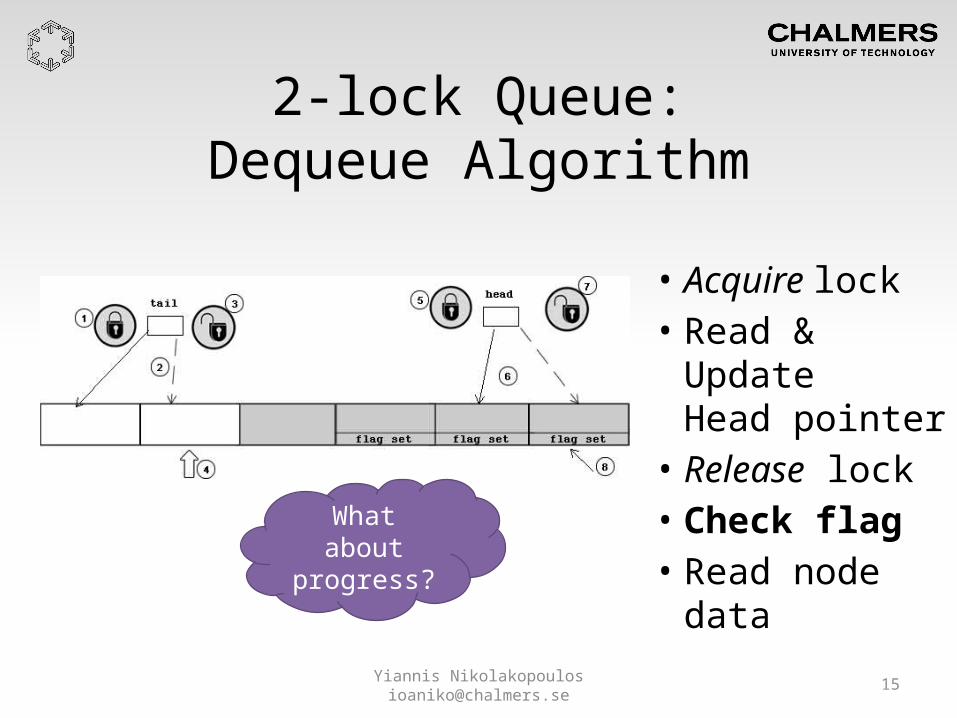
2-lock Queue:Dequeue Algorithm
• Acquire lock• Read & Update
Head pointer• Release lock• Check flag• Read node dataWhat about
progress?
Page 16
Yiannis Nikolakopoulos [email protected]
16
2-lock Queue:Implementation
Head/TailPointers (MPB)
Data nodes
Locks?On which tile(s)?
Page 17
Yiannis Nikolakopoulos [email protected]
17
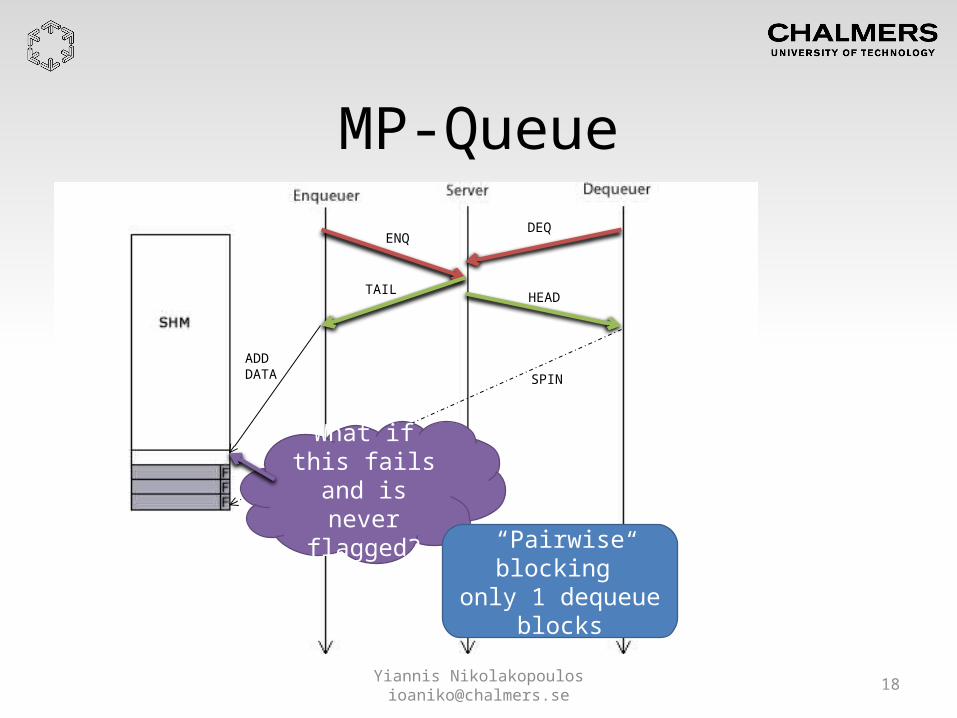
Message Passing-based Queue• Data nodes in SHM• Access coordinated by a Server node who
keeps Head/Tail pointers• Enqueuers/Dequeuers request access through
dedicated slots in MPB• Successfully enqueued data are flagged with
dirty bit
Page 18
Yiannis Nikolakopoulos [email protected]
18
MP-Queue
ENQ
TAIL
DEQ
HEAD
SPIN
What if this fails and is
never flagged?“Pairwise blocking”
only 1 dequeue blocks
ADDDATA
Page 19
Yiannis Nikolakopoulos [email protected]
19
Adding Acknowledgements• No more flags!
Enqueue sends ACK when done• Server maintains in SHM a private queue of
pointers• On ACK:
Server adds data location to its private queue• On Dequeue:
Server returns only ACKed locations
Page 20
Yiannis Nikolakopoulos [email protected]
20
MP-Acks
ENQ
TAIL
ACK
DEQ
HEAD
No blocking between
enqueues/dequeues
Page 21
Yiannis Nikolakopoulos [email protected]
21
Outline• Concurrent Data Structures• Many-core architectures• Intel’s SCC• Concurrent FIFO Queues• Evaluation• Conclusion
Page 22
Yiannis Nikolakopoulos [email protected]
22
Evaluation
Benchmark:• Each core performs Enq/Deq at random• High/Low contention
• Perfomance? Scalability?• Is it the same for all cores?
Page 23
23
• Throughput:Data structure operations completed per time unit.
[Cederman et al 2013]
Measures
Yiannis [email protected]
Operations by core i
Average operations per
core
Page 24
Yiannis Nikolakopoulos [email protected]
24
Throughput – High Contention
Page 25
Yiannis Nikolakopoulos [email protected]
25
Fairness – High Contention
Page 26
Yiannis Nikolakopoulos [email protected]
26
Throughput VS Lock Location
Page 27
Yiannis Nikolakopoulos [email protected]
27
Throughput VS Lock Location
Page 28
Yiannis Nikolakopoulos [email protected]
28
Conclusion• Lock based queue– High throughput– Less fair– Sensitive to lock locations, NoC performance
• MP based queues– Lower throughput– Fairer– Better liveness properties– Promising scalability
Page 29
Yiannis Nikolakopoulos [email protected]
29
Thank you!
[email protected] @chalmers.se
Page 30
Yiannis Nikolakopoulos [email protected]
30
BACKUP SLIDES
Page 31
Yiannis Nikolakopoulos [email protected]
31
Experimental Setup• 533MHz cores, 800MHz mesh, 800MHz DDR3 • Randomized Enq/Deq operations• High/Low contention• One thread per core• 600ms per execution • Averaged over 12 runs
Page 32
Yiannis Nikolakopoulos [email protected]
32
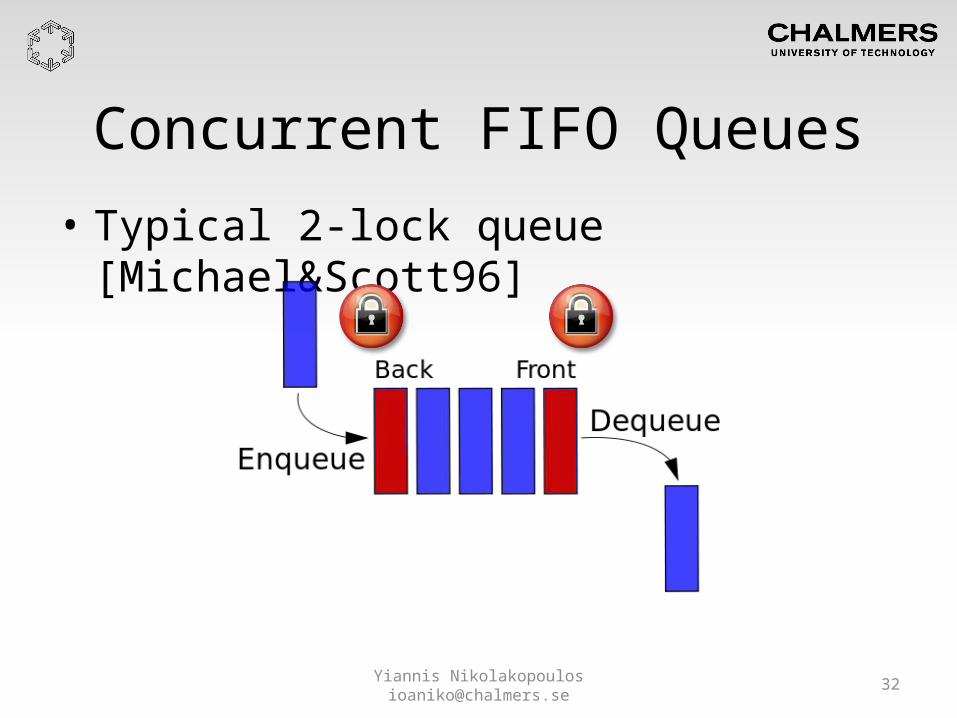
Concurrent FIFO Queues• Typical 2-lock queue [Michael&Scott96]