21
© 2018 IBM Corporation IBM Systems Group Concurrent High Performance Processor design: From Logic to PD in Parallel Leon Stok, VP EDA, IBM Systems Group

© 2018 IBM Corporation
IBM Systems Group
Concurrent High Performance Processor design: From Logic to PD in Parallel
Leon Stok, VP EDA, IBM Systems Group

© 2017 IBM Corporation
The mainframe is everywhere, making the world work better
Mainframes process
30 billion business transactions per day
Mainframes enable
$6 trillion in card payments annually
80 percent of the world’s corporate data resides or originates on mainframes
91 percent of CIOs said new customer-facing apps are accessing the mainframe

3 © 2018 IBM Corporation
IBM Z – Processor Roadmap
z1969/2010
zEC129/2012
z102/2008
z133/2015
Leadership Single Thread, Enhanced
Throughput
Improved out-of-order
Transactional Memory
Dynamic Optimization
2 GB page support
Step Function in System Capacity
Top Tier Single Thread Performance,System
Capacity
Accelerator Integration
Out of Order Execution
Water Cooling
PCIe I/O Fabric
RAIM
Enhanced Energy Management
Leadership System Capacity and Performance
Modularity & Scalability
Dynamic SMT
Supports two instruction threads
SIMD
PCIe attached accelerators
Business Analytics Optimized
Workload Consolidation and Integration Engine
for CPU Intensive Workloads
Decimal FP
Infiniband
64‐CP Image
Large Pages
Shared Memory
z149/2017
Pervasive encryption
Low latency I/O for acceleration of
transaction processing for DB2 on z/OS
Pause‐less garbage collection for enterprise scale JAVA applications
New SIMD instructions
Optimized pipeline and enhanced SMT
Virtual Flash Memory
65 nm
45 nm
32 nm
22 nm
14 nm

4 © 2018 IBM Corporation
z14 processor design summary
Micro-Architecture• 10 cores per CP-chip • 5.2GHz
• Cache Improvements:• 128KB I$ + 128KB D$• 2x larger L2 D$ (4MB)• 2x larger L3 Cache• symbol ECC
• New translation & TLB design• Logical-tagged L1 directory• Pipelined 2nd level TLB• Multiple translation engines
• Better Branch Prediction• 33% Larger BTB1 & BTB2• New Perceptron & Simple Call/Return Predictor
• Pipeline Optimizations• Improved instruction delivery• Faster branch wakeup• Improved store hazard avoidance• 2x double-precision FPU bandwidth• Optimized 2nd generation SMT2
Architecture• PauseLess Garbage Collection• Vector Single & Quad precision• Long-multiply support (RSA, ECC)• Register-to-register BCD arithmetic
Accelerators• Redesigned in-core crypto-accelerator
• Improved performance• New functions (GCM, TRNG, SHA3)
• Optimized in-core compression accelerator• Improved start/stop latency• Huffman encoding for better
compression ratio• Order-preserving compression
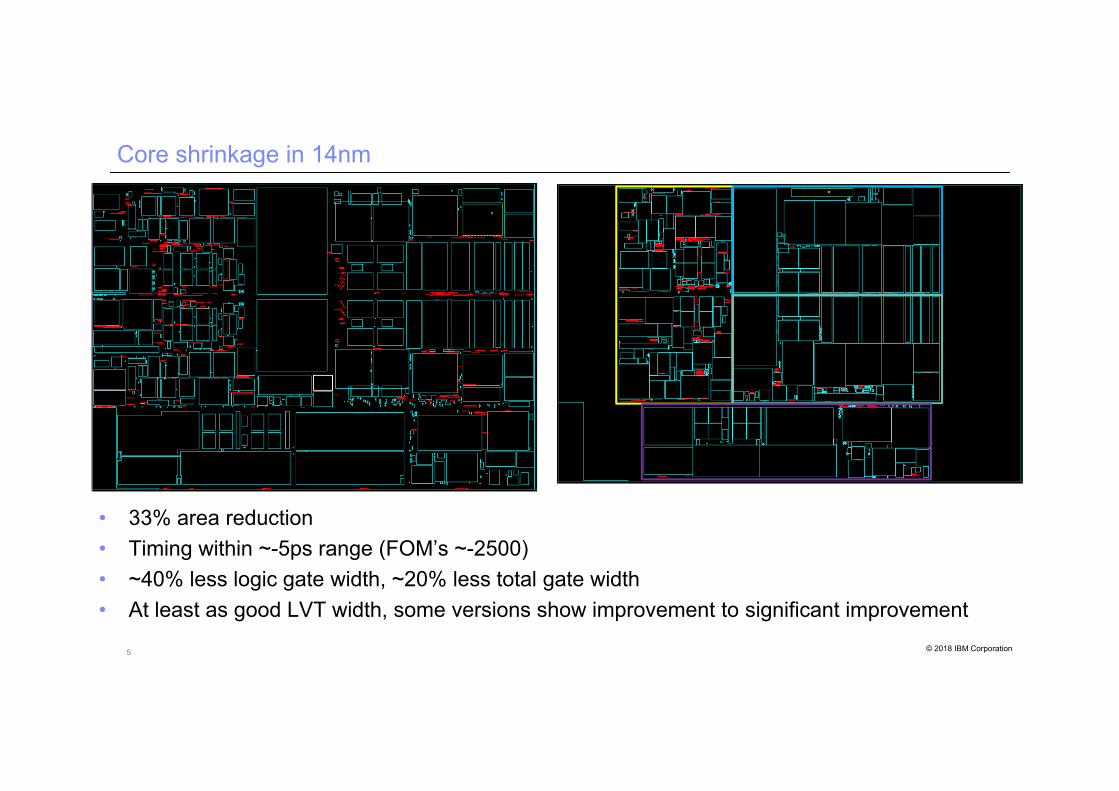
5 © 2018 IBM Corporation
Core shrinkage in 14nm
• 33% area reduction• Timing within ~-5ps range (FOM’s ~-2500)• ~40% less logic gate width, ~20% less total gate width• At least as good LVT width, some versions show improvement to significant improvement

6 © 2018 IBM Corporation6
Why was this so difficult ? – Logic designers from Venus, PD designers from Mars
Module A3Module A2
Module A1
Module B4
Module B3
Module B2
Module B1
Module C4
Module C3
Module C2
Module C1
Logical Organization Preference
Verification Focus
Logic Ownership
Functional Adjacency
Module A3Module A2Module A1
Module B4
Module B3
Module B2
Module B1
Module C4
Module C3
Module C2
Module C1
Physical Organization Preference
Implementation Focus
Physical Optimization
Geographic Adjacency
Combined Single Hierarchy
Iterative PD Annotation
High Coordination Effort
Less Efficient
Design QualityPerformance
PowerArea

7 © 2018 IBM Corporation
On-chip Bus/Interconnect
Hig
h Sp
eed
Link
Hig
h Sp
eed
Link
Hig
h Sp
eed
Link
Hig
h Sp
eed
Link
Hig
h Sp
eed
LinkMemory
ControllerMemory Controller
Perip
hera
lPe
riphe
ral
On-
chip
C
ontro
ller
Accelerator
Accelerator
Accelerator
Multi-core Chiplet
Multi-core Chiplet
Multi-core Chiplet
Multi-core Chiplet
Proc
esso
r C
ore
Proc
esso
r C
ore
Proc
esso
r C
ore
Proc
esso
r C
ore
An obvious benefit is to create a multi-core chiplet Create a multi-core chiplet entity and instantiate it multiple timesMove processor cores and bus
interface logic into their respective multi-core chiplet instances
Logic Designers View
[Alvan Ng, Automated Physical Hierarchy Generation: Tools and Methodology, DVCon2018]
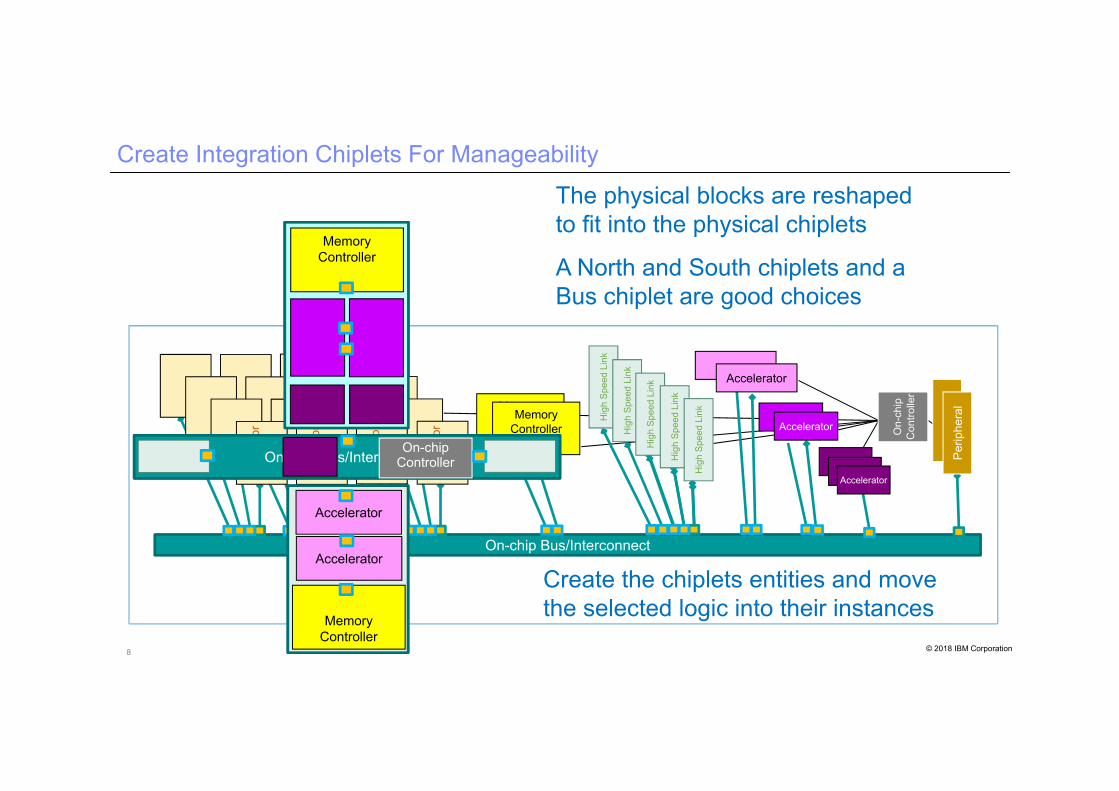
8 © 2018 IBM Corporation
Create Integration Chiplets For Manageability
On-chip Bus/InterconnectSouth Chiplet
North Chiplet
Memory ControllerMemory
ControllerPr
oces
sor
Cor
e
Proc
esso
r C
ore
Proc
esso
r C
ore
Proc
esso
r C
ore
Bus Chiplet
Perip
hera
lPe
riphe
ral
Accelerator
Accelerator
Accelerator
On-
chip
Con
trolle
r
A North and South chiplets and a Bus chiplet are good choices
Create the chiplets entities and move the selected logic into their instances
The physical blocks are reshaped to fit into the physical chiplets
Hig
h Sp
eed
Link
Hig
h Sp
eed
Link
Hig
h Sp
eed
Link
Hig
h Sp
eed
Link
Hig
h Sp
eed
Link
Memory Controller
Accelerator
Accelerator
On-chip Bus/InterconnectOn-chip
Controller
Memory Controller
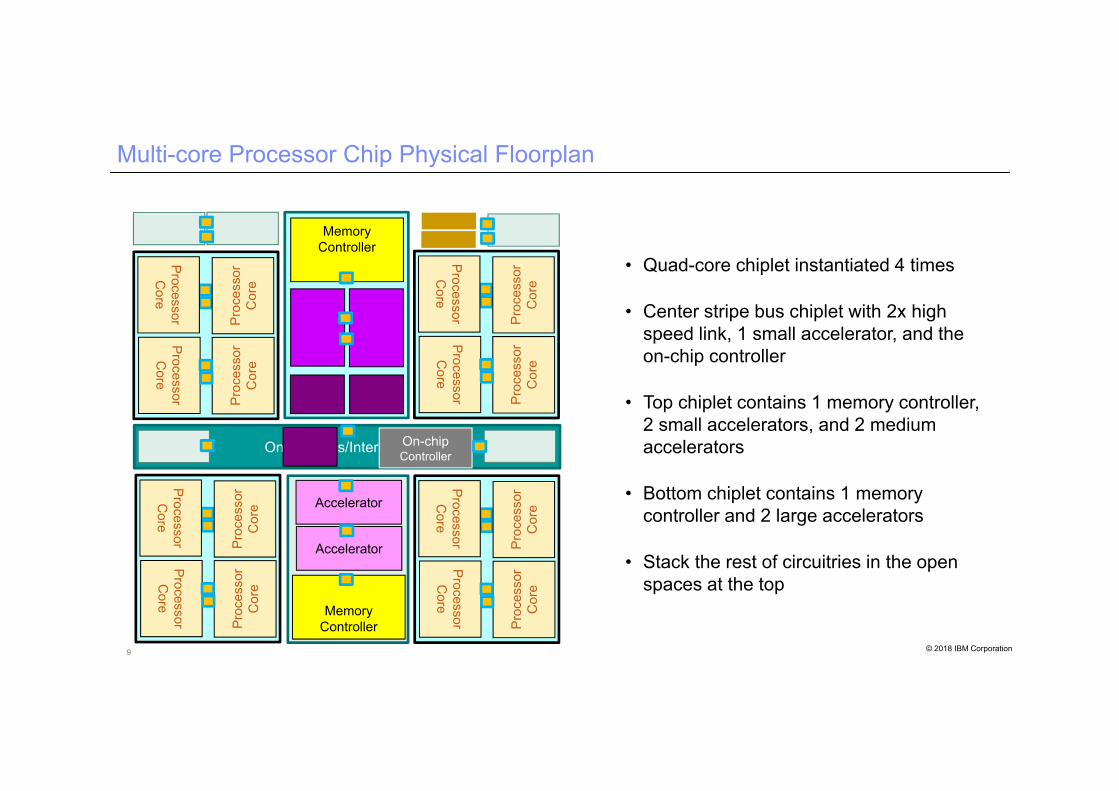
9 © 2018 IBM Corporation
Multi-core Processor Chip Physical Floorplan
• Quad-core chiplet instantiated 4 times
• Center stripe bus chiplet with 2x high speed link, 1 small accelerator, and the on-chip controller
• Top chiplet contains 1 memory controller, 2 small accelerators, and 2 medium accelerators
• Bottom chiplet contains 1 memory controller and 2 large accelerators
• Stack the rest of circuitries in the open spaces at the top
Proc
esso
r C
ore
Processor C
oreProcessor
Core
Proc
esso
r C
ore
Proc
esso
r C
ore
Processor C
oreProcessor
Core
Proc
esso
r C
ore
Proc
esso
r C
ore
Processor C
oreProcessor
Core
Proc
esso
r C
ore
Memory Controller
Accelerator
Accelerator
On-chip Bus/InterconnectOn-chipController
Memory Controller
Proc
esso
r C
ore
Processor C
oreProcessor
Core
Proc
esso
r C
ore

10 © 2018 IBM Corporation
Alternative Chip Physical Floorplan
• Quad-core chiplet instantiated 4 times
• Center stripe bus chiplet contains 2x Memory-Peripheral combined unit, 3x small accelerator, and the on-chip controller
• One accelerator chiplet instantiated twice which contains a large and a medium accelerator
• Stack the High-Speed Links on the right
Proc
esso
r C
ore
Processor C
oreProcessor
Core
Proc
esso
r C
ore
Acce
lera
tor
Proc
esso
r C
ore
Processor C
oreProcessor
Core
Proc
esso
r C
ore
Proc
esso
r C
ore
Processor C
oreProcessor
Core
Proc
esso
r C
ore
Acce
lera
tor
Proc
esso
r C
ore
Processor C
oreProcessor
Core
Proc
esso
r C
ore
On-chip Bus/Interconnect MEM/IOOn-chip
Controller
MEM/IO
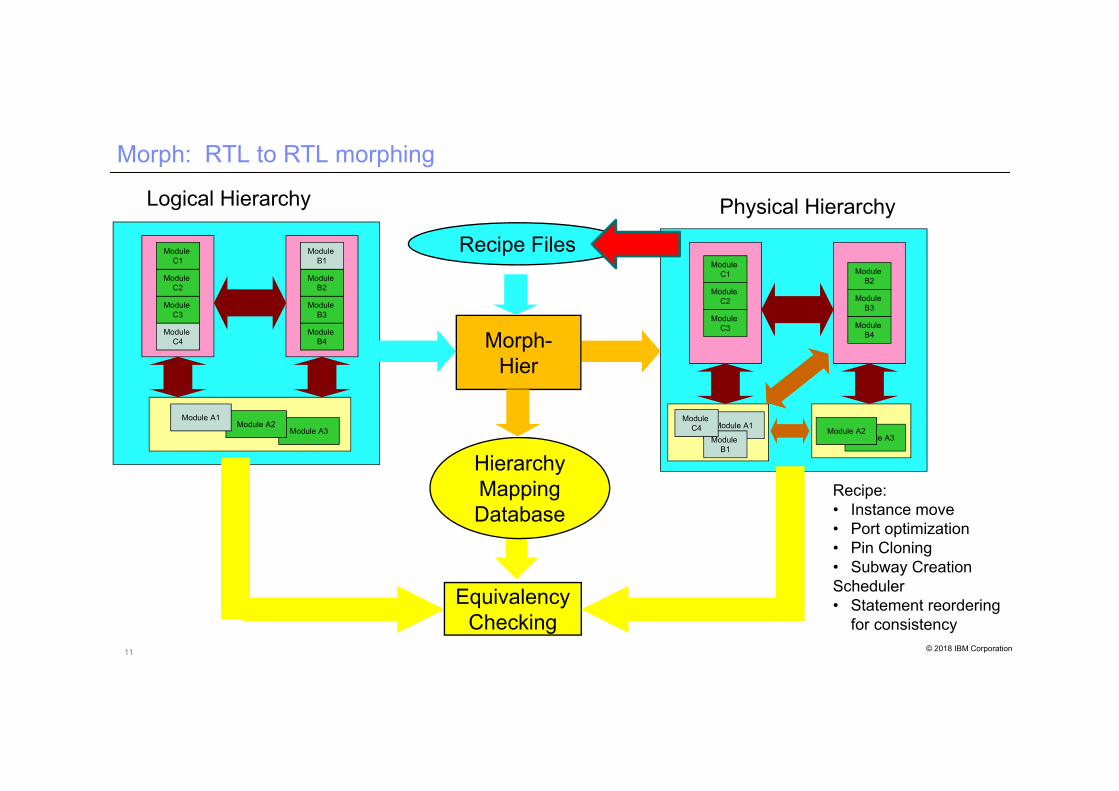
11 © 2018 IBM Corporation
Morph: RTL to RTL morphing
Module A3Module A2
Module A1
Module B4
Module B3
Module B2
Module B1
Module C4
Module C3
Module C2
Module C1
Module A3Module A2
Module A1
Module B4
Module B3
Module B2
Module B1
Module C4
Module C3
Module C2
Module C1
Logical Hierarchy Physical Hierarchy
Morph-Hier
EquivalencyChecking
HierarchyMapping Database
Recipe Files
Recipe:• Instance move• Port optimization• Pin Cloning• Subway CreationScheduler• Statement reordering
for consistency
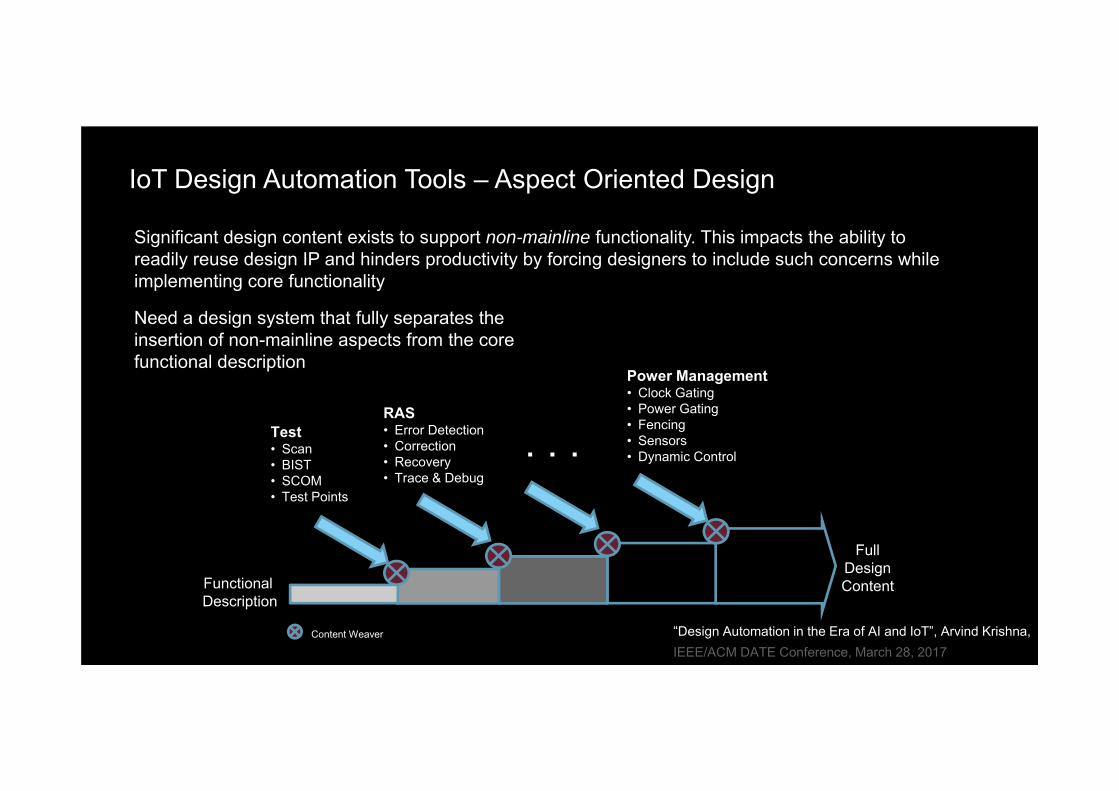
IoT Design Automation Tools – Aspect Oriented Design
Content Weaver
Functional Description
FullDesign Content
Significant design content exists to support non-mainline functionality. This impacts the ability to readily reuse design IP and hinders productivity by forcing designers to include such concerns while implementing core functionality
Need a design system that fully separates the insertion of non-mainline aspects from the core functional description
RAS • Error Detection• Correction• Recovery• Trace & Debug
Power Management• Clock Gating• Power Gating• Fencing• Sensors • Dynamic Control
Test• Scan• BIST• SCOM• Test Points
. . .
“Design Automation in the Era of AI and IoT”, Arvind Krishna, IEEE/ACM DATE Conference, March 28, 2017
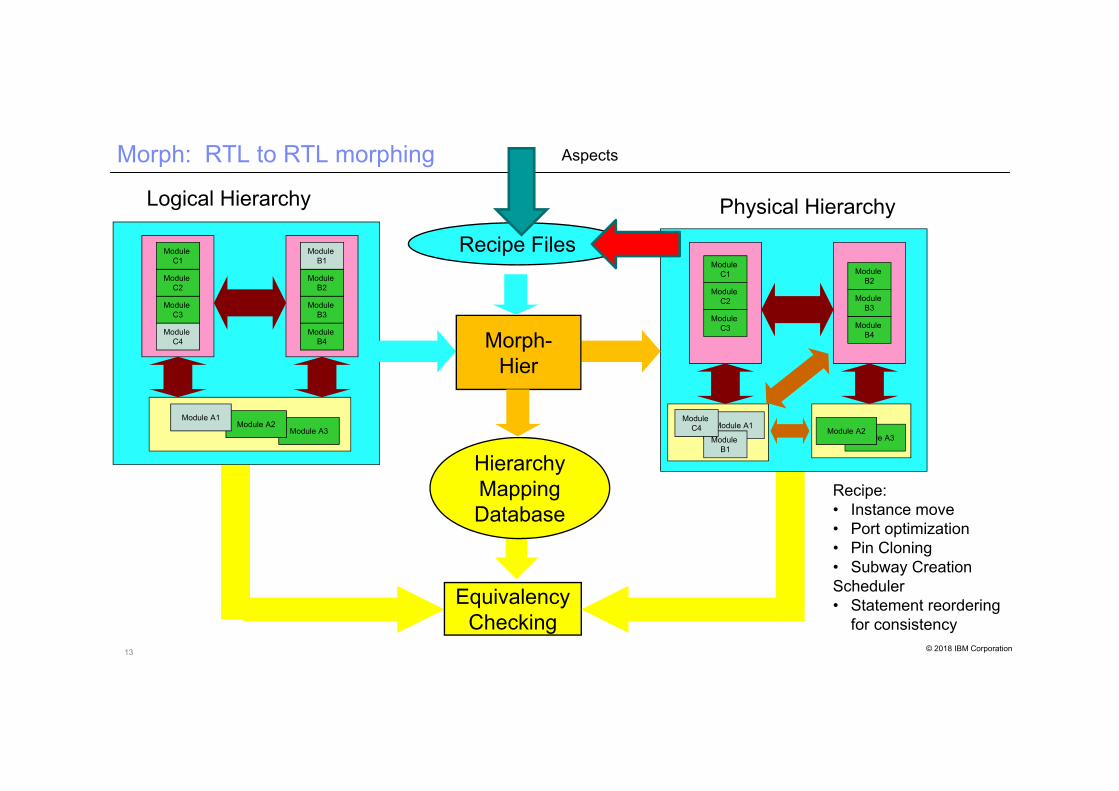
13 © 2018 IBM Corporation
Morph: RTL to RTL morphing
Module A3Module A2
Module A1
Module B4
Module B3
Module B2
Module B1
Module C4
Module C3
Module C2
Module C1
Module A3Module A2
Module A1
Module B4
Module B3
Module B2
Module B1
Module C4
Module C3
Module C2
Module C1
Logical Hierarchy Physical Hierarchy
EquivalencyChecking
Morph-Hier
HierarchyMapping Database
Recipe Files
Recipe:• Instance move• Port optimization• Pin Cloning• Subway CreationScheduler• Statement reordering
for consistency
Aspects

14 © 2018 IBM Corporation
Pervasive Logic Centralized VHDL Organization
Perip
hera
l
Accelerator
Accelerator
Accelerator
On-chip Bus/Interconnect
Hig
h Sp
eed
Link
Hig
h Sp
eed
Link
Hig
h Sp
eed
Link
Hig
h Sp
eed
Link
Hig
h Sp
eed
Link
Memory ControllerMemory
Controller
Proc
esso
r C
ore
Proc
esso
r C
ore
Proc
esso
r C
ore
Proc
esso
r C
ore
On-chip Controller Logic Test Logic Miscellaneous Circuitries

15 © 2018 IBM Corporation
Distribute Pervasive Logic Using Morph-Hier
Proc
esso
r C
ore
Processor C
oreProcessor
Core
Proc
esso
r C
ore
Proc
esso
r C
ore
Processor C
oreProcessor
Core
Proc
esso
r C
ore
Proc
esso
r C
ore
Processor C
oreProcessor
Core
Proc
esso
r C
ore
Memory Controller
Accelerator
Accelerator
On-chip Bus/InterconnectOn-chip Controller
Memory Controller
Proc
esso
r C
ore
Processor C
oreProcessor
Core
Proc
esso
r C
ore
Perip
hera
l
Accelerator
Accelerator
Accelerator
On-chip Bus/InterconnectH
igh
Spee
d Li
nkH
igh
Spee
d Li
nkH
igh
Spee
d Li
nk
Hig
h Sp
eed
Link
Hig
h Sp
eed
Link
Memory ControllerMemory
ControllerPr
oces
sor
Cor
e
Proc
esso
r C
ore
Proc
esso
r C
ore
Proc
esso
r C
ore
The Pervasive unit contains all the supporting logic for each functional unitEach red dot graphically map to a physical pervasive boundaryThe pervasive logic are push into the physical entities using Morph-Hier

16 © 2018 IBM Corporation
Centralized Pervasive Logic Distributed To Physical Units
Proc
esso
r Cor
e
Processor Core
Processor Core
Proc
esso
r Cor
ePr
oces
sor C
ore
Processor Core
Processor Core
Proc
esso
r Cor
e
Memory Controller
Accelerator
Accelerator
Proc
esso
r Cor
e
Processor Core
Processor Core
Proc
esso
r Cor
e
On-chip Bus/InterconnectOn-chip Controller
Memory Controller
Proc
esso
r Cor
e
Processor Core
Processor Core
Proc
esso
r Cor
e
Benefits:
Parallel logic design Concurrent with functional units
Verification Speedup Self contained unit
Design quality Lower bug rate

17 © 2018 IBM Corporation
z14 Pipeline
Deep high frequency pipeline• Async branch prediction ahead
of ifetch• 32B/cycle ifetch• 6 instruction / cycle parse &
decode• CISC instruction cracking• Unified OOO issue queue• 2 LSU, 4-cycle load-use• 4 FXU, 2 SIMD/FP/BCD• In-order completion & checkpoint

18 © 2018 IBM Corporation
Physical constraints on the pipeline
1
Chiplet C1LBS L1
RLM r1
h1
L2
r22
h2r2
L3
r3
h3
7
4
L4

19 © 2018 IBM Corporation
PD micro-architect allotment
1
Chiplet C1LBS L1
RLM r1
h1
L2
r22
h2r2
L3
r3
h3
1
3
L4
3
20 © 2018 IBM Corporation
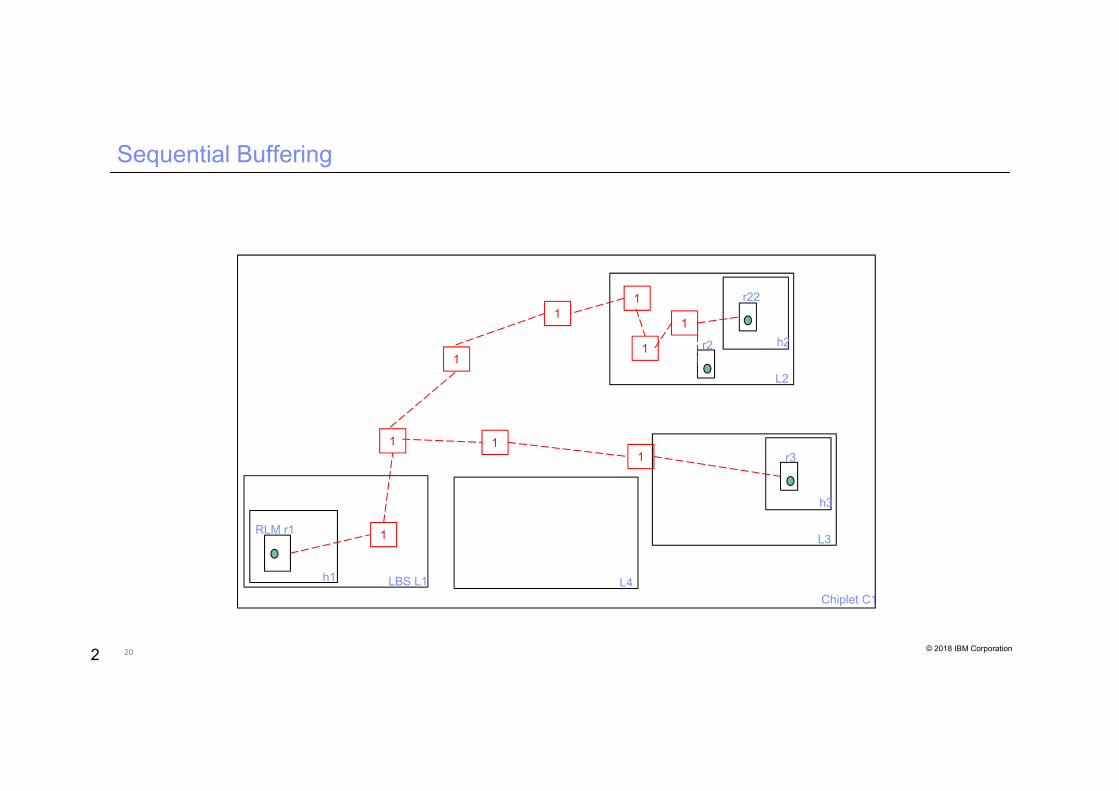
Sequential Buffering
2
Chiplet C1LBS L1
RLM r1
h1
L2
r22
h2r2
L3
r3
h3
1
L4
1
1
1
1
11
1
1

21 © 2018 IBM Corporation
Most innovation in micro-processors is nowadays coming from– Architecture, micro-architecture and accelerators– Physical design optimization at micro-architectural level– In place of
• Moore’s law technology progress and • ‘Fixed block’ level PPA optimization.
This is leading significantly more ‘new’ Logic being designed and modified, concurrently with the Physical Design Concurrent design of Logic and PD leads to
– interesting new problems to be explored with significantly larger potential pay-off due the micro-architectural / PD co-optimization design space.
Conclusions













![GCC internals intro y optimizationesnicolasw/Docencia/CP/gcc_int_intro.pdf · Optimizaciones Back-end Backend: – RTL tree + RTL language + RTL Engine + RTL Compiler [Middle-End]](https://static.documents.pub/doc/80x56/5f066be67e708231d417e97b/gcc-internals-intro-y-optimizationes-nicolaswdocenciacpgccintintropdf-optimizaciones.jpg)



