1 Confessions of an Accidental Benchmarker • Appendix B of the Linpack Users’ Guide • Designed to help users extrapolate execution time for Linpack software package • First benchmark report from 1977; • Cray 1 to DEC PDP-10 http://bit.ly/hpcg-benchmark Jack Dongarra & Piotr Luszczek University of Tennessee Oak Ridge National Laboratory Mike Heroux Sandia National Laboratory
Transcript
1 Confessions of an Accidental Benchmarker
• Appendix B of the Linpack Users’ Guide • Designed to help users extrapolate execution time for
Linpack software package • First benchmark report from 1977;
• Cray 1 to DEC PDP-10
http://bit.ly/hpcg-benchmark
Jack Dongarra & Piotr Luszczek University of Tennessee Oak Ridge National Laboratory Mike Heroux Sandia National Laboratory
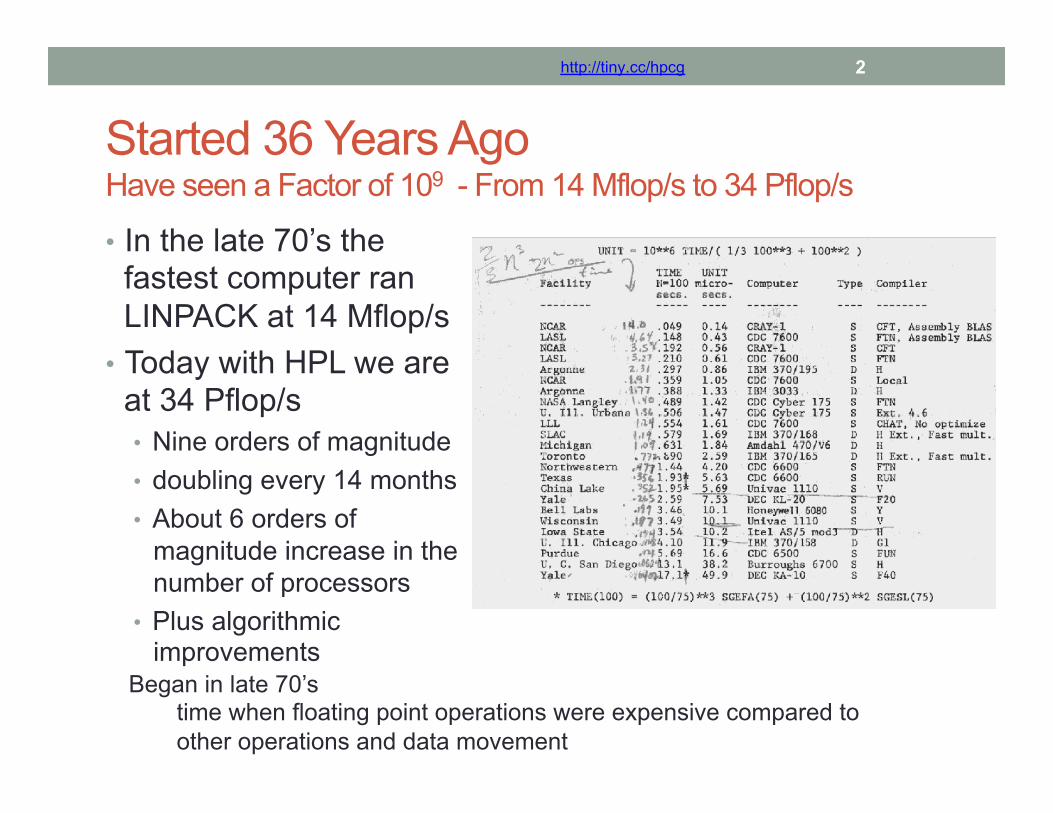
Started 36 Years Ago Have seen a Factor of 109 - From 14 Mflop/s to 34 Pflop/s
• In the late 70’s the fastest computer ran LINPACK at 14 Mflop/s
• Today with HPL we are at 34 Pflop/s • Nine orders of magnitude • doubling every 14 months • About 6 orders of
magnitude increase in the number of processors
• Plus algorithmic improvements
Began in late 70’s time when floating point operations were expensive compared to other operations and data movement
http://tiny.cc/hpcg 2
High Performance Linpack (HPL) • Is a widely recognized and discussed metric for ranking
high performance computing systems • When HPL gained prominence as a performance metric in
the early 1990s there was a strong correlation between its predictions of system rankings and the ranking that full-scale applications would realize.
• Computer system vendors pursued designs that would increase their HPL performance, which would in turn improve overall application performance.
• Today HPL remains valuable as a measure of historical trends, and as a stress test, especially for leadership class systems that are pushing the boundaries of current technology.
http://tiny.cc/hpcg 3
The Problem • HPL performance of computer systems are no longer so
strongly correlated to real application performance, especially for the broad set of HPC applications governed by partial differential equations.
• Designing a system for good HPL performance can
actually lead to design choices that are wrong for the real application mix, or add unnecessary components or complexity to the system.
http://bit.ly/hpcg-benchmark 4
Concerns • The gap between HPL predictions and real application
performance will increase in the future. • A computer system with the potential to run HPL at 1
Exaflops is a design that may be very unattractive for real applications.
• Future architectures targeted toward good HPL performance will not be a good match for most applications.
• This leads us to a think about a different metric
http://bit.ly/hpcg-benchmark 5
HPL - Good Things • Easy to run • Easy to understand • Easy to check results • Stresses certain parts of the system • Historical database of performance information • Good community outreach tool • “Understandable” to the outside world • If your computer doesn’t perform well on the LINPACK
Benchmark, you will probably be disappointed with the performance of your application on the computer.
http://bit.ly/hpcg-benchmark 6
HPL - Bad Things • LINPACK Benchmark is 36 years old
• Top500 (HPL) is 21 years old
• Floating point-intensive performs O(n3) floating point operations and moves O(n2) data.
• No longer so strongly correlated to real apps. • Reports Peak Flops (although hybrid systems see only 1/2 to 2/3 of Peak) • Encourages poor choices in architectural features • Overall usability of a system is not measured • Used as a marketing tool • Decisions on acquisition made on one number • Benchmarking for days wastes a valuable resource
http://tiny.cc/hpcg 7
Running HPL • In the beginning to run HPL on the number 1 system
was under an hour. • On Livermore’s Sequoia IBM BG/Q the HPL run took
about a day to run. • They ran a size of n=12.7 x 106 (1.28 PB)
• 16.3 PFlop/s requires about 23 hours to run!!
• 23 hours at 7.8 MW that the equivalent of 100 barrels of oil or about $8600 for that one run.
• The longest run was 60.5 hours • JAXA machine
• Fujitsu FX1, Quadcore SPARC64 VII 2.52 GHz • A matrix of size n = 3.3 x 106
• .11 Pflop/s #160 today
http://bit.ly/hpcg-benchmark 8
0%#
10%#
20%#
30%#
40%#
50%#
60%#
70%#
80%#
90%#
100%#
6/1/93#
10/1/93#
2/1/94#
6/1/94#
10/1/94#
2/1/95#
6/1/95#
10/1/95#
2/1/96#
6/1/96#
10/1/96#
2/1/97#
6/1/97#
10/1/97#
2/1/98#
6/1/98#
10/1/98#
2/1/99#
6/1/99#
10/1/99#
2/1/00#
6/1/00#
10/1/00#
2/1/01#
6/1/01#
10/1/01#
2/1/02#
6/1/02#
10/1/02#
2/1/03#
6/1/03#
10/1/03#
2/1/04#
6/1/04#
10/1/04#
2/1/05#
6/1/05#
10/1/05#
2/1/06#
6/1/06#
10/1/06#
2/1/07#
6/1/07#
10/1/07#
2/1/08#
6/1/08#
10/1/08#
2/1/09#
6/1/09#
10/1/09#
2/1/10#
6/1/10#
10/1/10#
2/1/11#
6/1/11#
10/1/11#
2/1/12#
6/1/12#
10/1/12#
2/1/13#
6/1/13#
61#hours#
30#hours#
20#hours#
12#hours#
11#hours#
10#hours#
9#hours#
8#hours#
7#hours#
6#hours#
5#hours#
4#hours#
3#hours#
2#hours#
1#hour#
Run Times for HPL on Top500 Systems http://bit.ly/hpcg-benchmark 9
#1 System on the Top500 Over the Past 20 Years (16 machines in that club)
Proposal: HPCG • High Performance Conjugate Gradient (HPCG). • Solves Ax=b, A large, sparse, b known, x computed. • An optimized implementation of PCG contains essential
computational and communication patterns that are prevalent in a variety of methods for discretization and numerical solution of PDEs
• Patterns:
• Dense and sparse computations. • Dense and sparse collective. • Data-driven parallelism (unstructured sparse triangular solves).
• Strong verification and validation properties (via spectral properties of CG).
http://bit.ly/hpcg-benchmark 13
What about the NAS Parallel CG Benchmark?
• NAS CG is flawed from the perspective of modeling the design choices of real science and engineering codes.
• The matrix truly random and make the placement of entries random means that, for distributed memory machines, a 2-dimensional matrix decomposition is most effective, which is fundamentally different that the 1D processor decomposition that spatial locality in PDEs needs.
• Random also meant that the natural spatial and temporal locality properties of real sparse matrices were not present, so caches were much less useful in the benchmark than in real life.
• Finally, NAS CG has no preconditioner, so it is essentially a fast sparse MV benchmark for an atypical sparse matrix.
http://bit.ly/hpcg-benchmark 14
Problem Setup • Synthetic symmetric positive definite problem
• Matrix, rhs, and initial guess • Perhaps with several sparsity patterns using compressed row
storage • User can change the matrix format and cost will be reported. • Matrix pattern may be regular but user cannot use this information
LA = tril(A); UA = triu(A); DA = diag(diag(A)); x = LA\y; x1 = y - LA*x + DA*x; % Subtract off extra diagonal contribution x = UA\x1;
http://bit.ly/hpcg-benchmark 16
Iteration • We will perform some number of iterations, repeated k
times, using the same initial guess each time, where k is sufficiently large to test system uptime, at least 5 hours.
• By doing this we can compare the numerical results for “correctness/reproducibility” at the end of each iteration phase.
• If the result is not bit-wise identical across successive
iteration phases, we can report the deviation. • Cache will be flushed between each of the k times the
iterations are performed to report fair timing data for averaging.
http://bit.ly/hpcg-benchmark 17
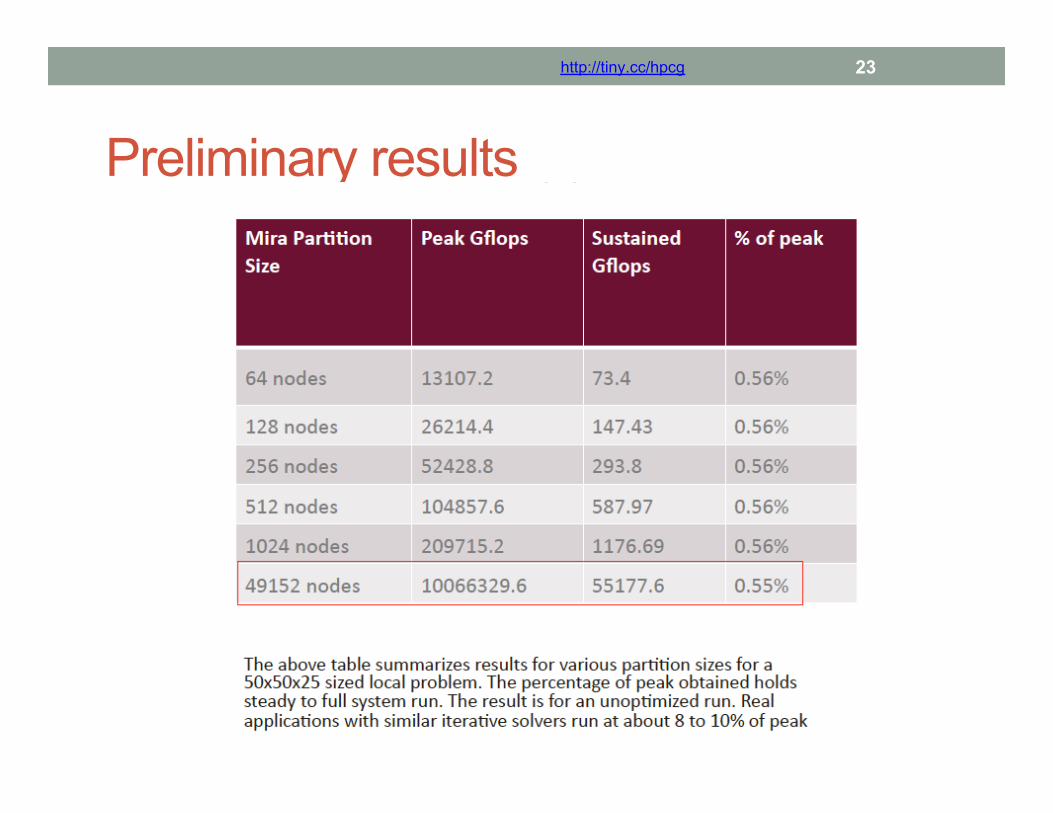
Post-processing and reporting • Collect numbers and provide an alternate to listing Top500 • V&V numbers are reported • Timing and execution rates are reported • Also reported will be the number of nodes, total storage, processors,
accelerators, precision used, compiler version, optimization level, compiler directives used, flop count, power used, cache effects, loads and stores, etc.
http://bit.ly/hpcg-benchmark 18
Key Computation Data Patterns • Domain decomposition:
• SPMD (MPI): Across domains. • Thread/vector (OpenMP, compiler): Within domains.