28
CS 203A Computer Architecture Lecture 10: Multimedia and Multithreading Instructor: L.N. Bhuyan
| Date post: | 19-Dec-2015 |
| Category: |
Documents |
| View: | 225 times |
| Download: | 2 times |

CS 203A Computer Architecture Lecture 10: Multimedia and
Multithreading
Instructor: L.N. Bhuyan

Approaches to Mediaprocessing
Multimedia
Processing
General-purpose
processors with
SIMD extensions
Vector Processors
VLIW with SIMD extensions
(aka mediaprocessors)
DSPs ASICs/FPGAs

What is Multimedia Processing?• Desktop:
– 3D graphics (games)
– Speech recognition (voice input)
– Video/audio decoding (mpeg-mp3 playback)
• Servers:
– Video/audio encoding (video servers, IP telephony)
– Digital libraries and media mining (video servers)
– Computer animation, 3D modeling & rendering (movies)
• Embedded:
– 3D graphics (game consoles)
– Video/audio decoding & encoding (set top boxes)
– Image processing (digital cameras)
– Signal processing (cellular phones)

Characteristics of Multimedia Apps (1)• Requirement for real-time response
– “Incorrect” result often preferred to slow result
– Unpredictability can be bad (e.g. dynamic execution)
• Narrow data-types
– Typical width of data in memory: 8 to 16 bits
– Typical width of data during computation: 16 to 32 bits
– 64-bit data types rarely needed
– Fixed-point arithmetic often replaces floating-point
• Fine-grain (data) parallelism
– Identical operation applied on streams of input data
– Branches have high predictability
– High instruction locality in small loops or kernels

Characteristics of Multimedia Apps (2)
• Coarse-grain parallelism
– Most apps organized as a pipeline of functions
– Multiple threads of execution can be used
• Memory requirements
– High bandwidth requirements but can tolerate high latency
– High spatial locality (predictable pattern) but low temporal locality
– Cache bypassing and prefetching can be crucial

SIMD Extensions for GPP• Motivation
– Low media-processing performance of GPPs– Cost and lack of flexibility of specialized ASICs for
graphics/video– Underutilized datapaths and registers
• Basic idea: sub-word parallelism– Treat a 64-bit register as a vector of 2 32-bit or 4 16-bit
or 8 8-bit values (short vectors)– Partition 64-bit datapaths to handle multiple narrow
operations in parallel• Initial constraints
– No additional architecture state (registers)– No additional exceptions– Minimum area overhead
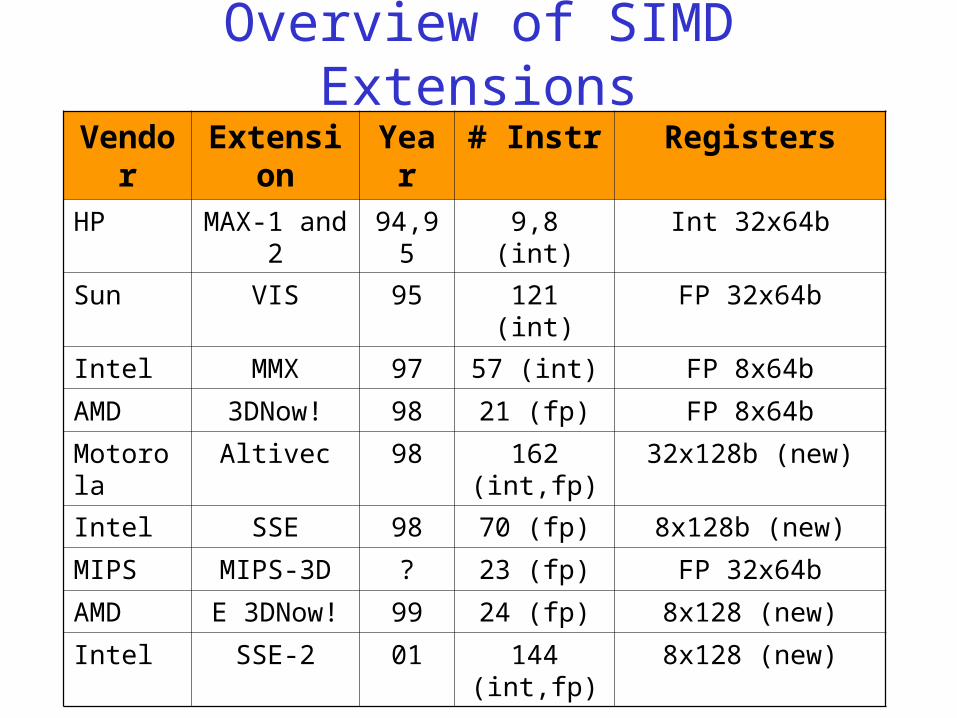
Overview of SIMD Extensions
Vendor Extension Year # Instr Registers
HP MAX-1 and 2
94,95 9,8 (int) Int 32x64b
Sun VIS 95 121 (int) FP 32x64b
Intel MMX 97 57 (int) FP 8x64b
AMD 3DNow! 98 21 (fp) FP 8x64b
Motorola Altivec 98 162 (int,fp) 32x128b (new)
Intel SSE 98 70 (fp) 8x128b (new)
MIPS MIPS-3D ? 23 (fp) FP 32x64b
AMD E 3DNow! 99 24 (fp) 8x128 (new)
Intel SSE-2 01 144 (int,fp) 8x128 (new)

Intel MMX Piipeline

Performance Improvement in MMX Architecture

SIMD Performance
0
2
4
6
8
Athlon Alpha21264
P entium III P owerP CG4
UltraSparcIIi
Sp
ee
du
p o
ve
r B
as
e
Arch
ite
ctu
re
fo
r B
erk
ele
y
Me
dia
Be
nch
mark
s
Arithmetic Mean Geometic Mean
Limitations• Memory bandwidth• Overhead of handling alignment and data width
adjustments

Other Features for Multimedia• Support for fixed-point arithmetic
– Saturation, rounding-modes etc
• Permutation instructions of vector registers
– For reductions and FFTs
– Not general permutations (too expensive)
• Example: permutation for reductions
– Move 2nd half a a vector register into another one
– Repeatedly use with vadd to execute reduction
– Vector length halved after each step
0 15
16
63 V0
0 15
16
63 V1

Multithreading
Consider the following sequence of instructions through a pipeline
LW r1, 0(r2)
LW r5, 12(r1)
ADDI r5, r5, #12
SW 12(r1), r5

Multithreading• How can we guarantee no dependencies between
instructions in a pipeline?– One way is to interleave execution of instructions from
different program threads on same pipeline – Micro context switching
Interleave 4 threads, T1-T4, on non-bypassed 5-stage pipe
T1: LW r1, 0(r2)T2: ADD r7, r1, r4T3: XORI r5, r4, #12T4: SW 0(r7), r5T1: LW r5, 12(r1)

Avoiding Memory Latency• General processors switch to another context on
I/O operation => Multithreading, Multiprogramming, etc. An O/S function. Large overhead! Why?
• Why not context switch on a cache miss? => Hardware multithreading.
• Can we afford that overhead now? => Need changes in architecture to avoid stack operations. How to achieve it?
• Have many contexts CPU resident (not memory resident) by having separate PCs and registers for each thread. No need to store them in stack on context switching.

Simple Multithreaded Pipeline
• Have to carry thread select down pipeline to ensure correct state bits read/written at each pipe stage

Multithreading Costs• Appears to software (including OS) as
multiple slower CPUs• Each thread requires its own user state
– GPRs– PC
• Also, needs own OS control state– virtual memory page table base register– exception handling registers
• Other costs?

What “Grain” Multithreading?
• So far assumed fine-grained multithreading– CPU switches every cycle to a different thread– When does this make sense?
• Coarse-grained multithreading– CPU switches every few cycles to a different
thread– When does this make sense (Ex - Memory
Access? – NPs)?

Superscalar Machine Efficiency
• Why horizontal waste?• Why vertical waste?

Vertical Multithreading
• Cycle-by-cycle interleaving of second thread removes vertical waste

Ideal Multithreading for Superscalar
• Interleave multiple threads to multiple issue slots with no restrictions

Simultaneous Multithreading
• Add multiple contexts and fetch engines to wide out-of-order superscalar processor– [Tullsen, Eggers, Levy, UW, 1995]
• OOO instruction window already has most of the circuitry required to schedule from multiple threads
• Any single thread can utilize whole machine

Comparison of Issue CapabilitiesCourtesy of Susan Eggers; Used with Permission

From Superscalar to SMT
• Small items– per-thread program counters– per-thread return stacks– per-thread bookkeeping for instruction
retirement, trap & instruction dispatch queue flush
– thread identifiers, e.g., with BTB & TLB entries

Simultaneous Multithreaded Processor

Intel Pentium-4 Xeon Processor• Hyperthreading == SMT• Dual physical processors, each 2-way SMT• Logical processors share nearly all resources of the
physical processor– Caches, execution units, branch predictors
• Die area overhead of hyperthreading ~5 %• When one logical processor is stalled, the other can
make progress– No logical processor can use all entries in queues
when two threads are active• A processor running only one active software thread to
run at the same speed with or without hyperthreading
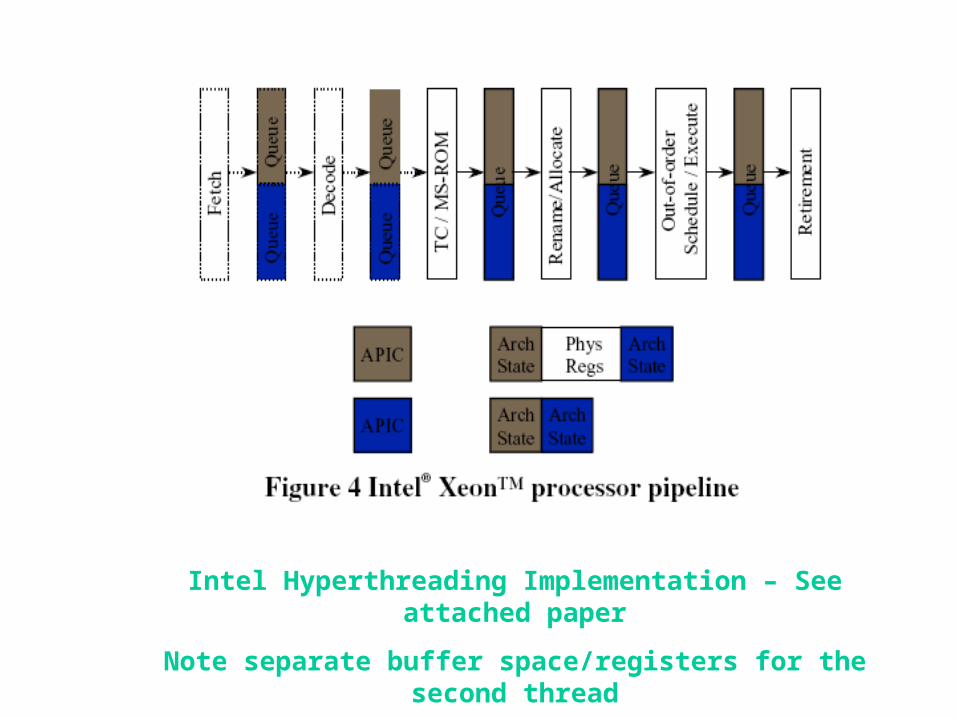
Intel Hyperthreading Implementation – See attached paper
Note separate buffer space/registers for the second thread


Intel Xeon Performance

















