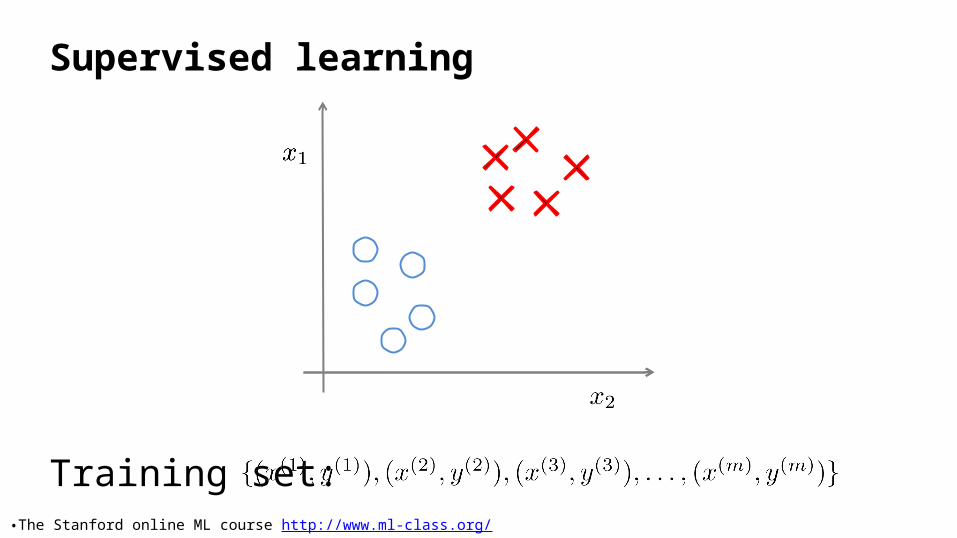
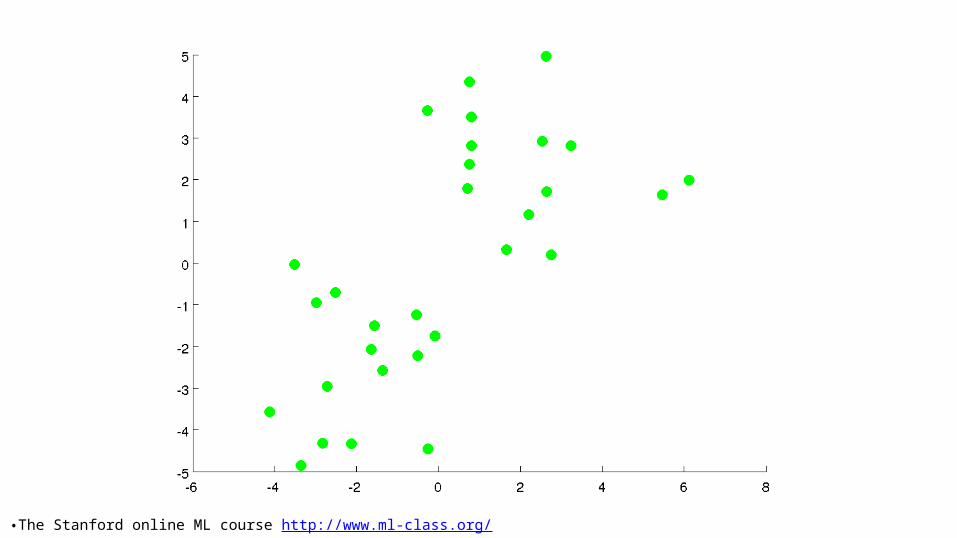
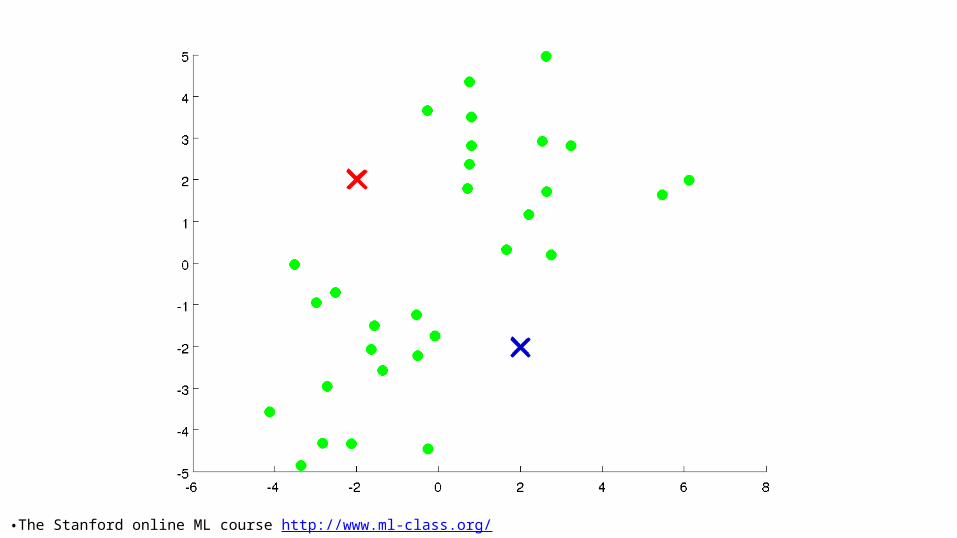
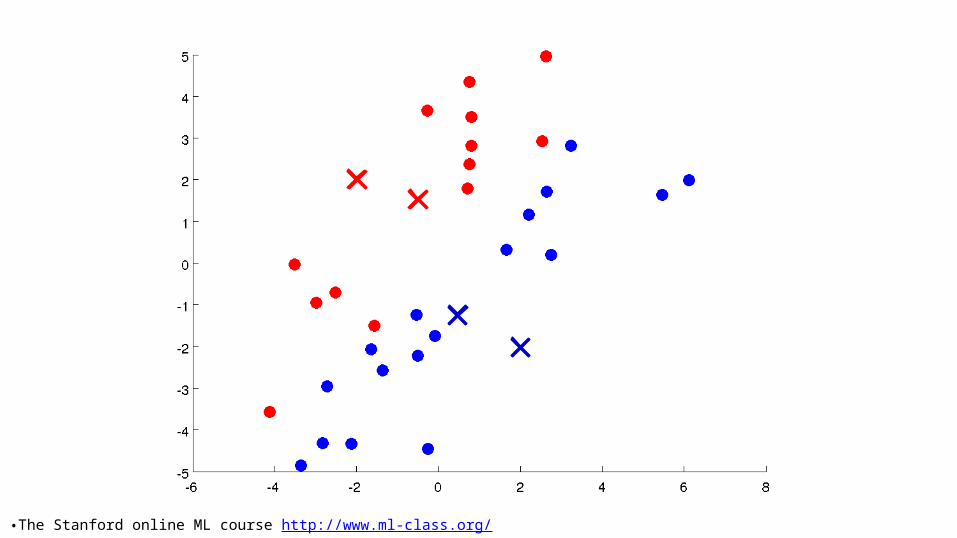
11: Unsupervised Learning - Clustering. CSC 4510 – Machine Learning. Dr. Mary-Angela Papalaskari Department of Computing Sciences Villanova University Course website: www.csc.villanova.edu /~map/4510/. Some of the slides in this presentation are adapted from: - PowerPoint PPT Presentation
CSC 4510 – Machine Learning Dr. Mary-Angela Papalaskari Department of Computing Sciences Villanova University Course website: www.csc.villanova.edu/~map/4510/ 11: Unsupervised Learning - Clustering 1 Some of the slides in this presentation are adapted from: • Prof. Frank Klassner’s ML class at Villanova • the University of Manchester ML course http://www.cs.manchester.ac.uk/ugt/COMP24111/ • The Stanford online ML course http://www.ml-class.org/
Transcript
CSC 4510 – Machine Learning
Dr. Mary-Angela PapalaskariDepartment of Computing SciencesVillanova University
Course website:www.csc.villanova.edu/~map/4510/
11: Unsupervised Learning - Clustering
1Some of the slides in this presentation are adapted from:• Prof. Frank Klassner’s ML class at Villanova• the University of Manchester ML course http://www.cs.manchester.ac.uk/ugt/COMP24111/• The Stanford online ML course http://www.ml-class.org/
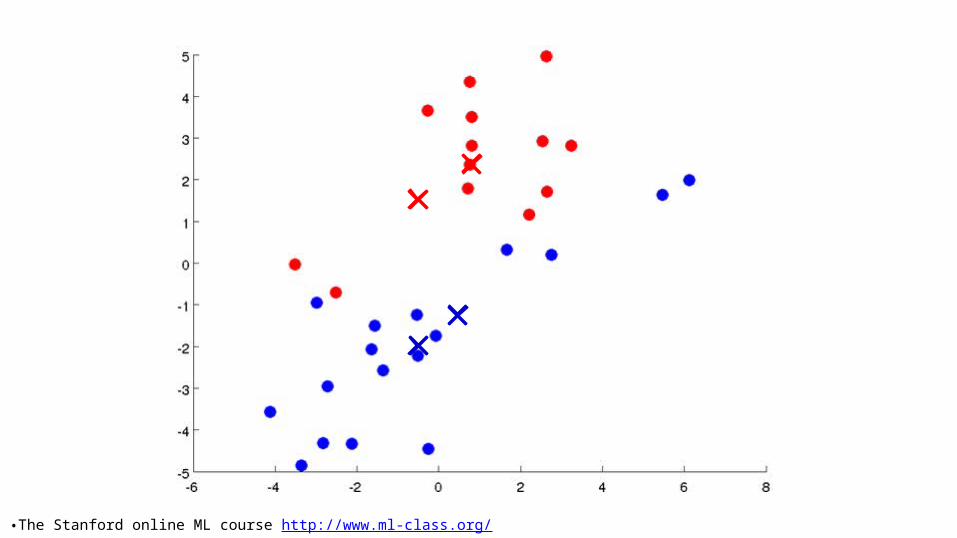
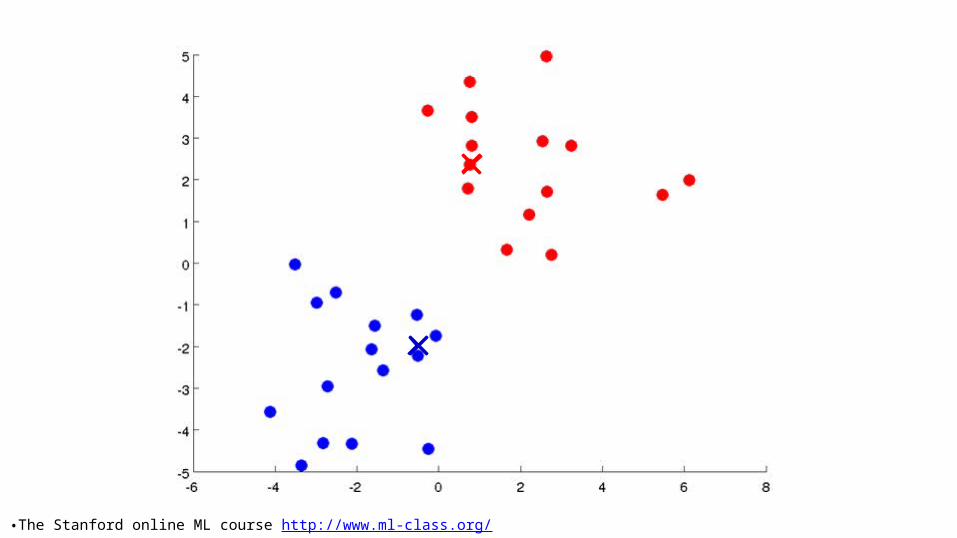
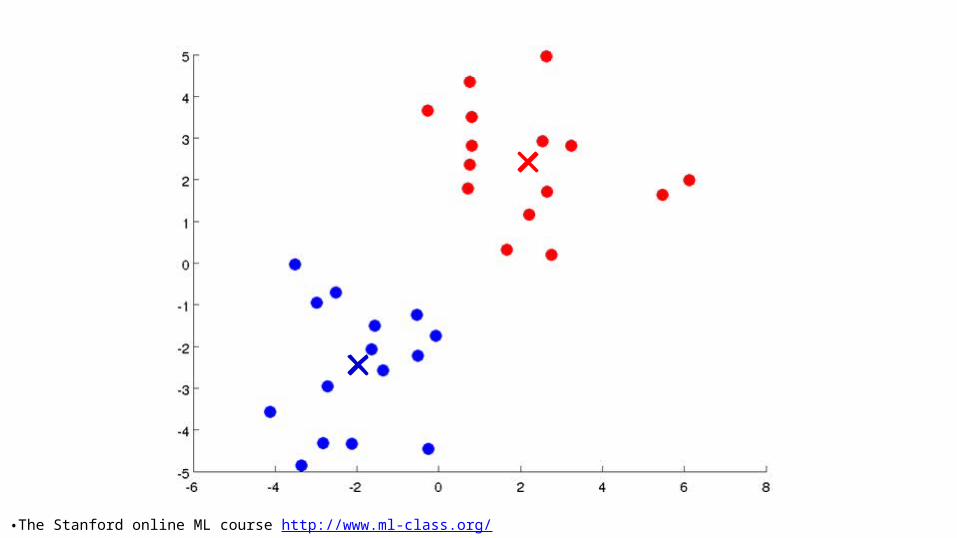
K-means intuition• Randomly choose k points as seeds, one per cluster. • Form initial clusters based on these seeds.• Iterate, repeatedly reallocating seeds and by re-
computing clusters to improve the overall clustering.• Stop when clustering converges or after a fixed
number of iterations.
Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.pptCSC 4510 - M.A. Papalaskari - Villanova University 8
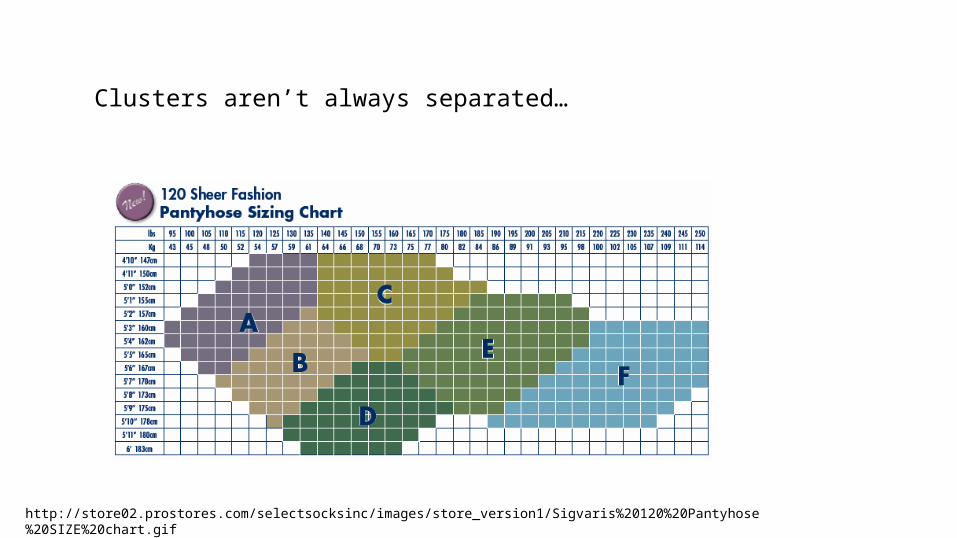
Weaknesses of k-means• The algorithm is only applicable to numeric data• The user needs to specify k.• The algorithm is sensitive to outliers– Outliers are data points that are very far away from
other data points. – Outliers could be errors in the data recording or
some special data points with very different values. www.cs.uic.edu/~liub/teach/cs583-fall-05/CS583-unsupervised-learning.pptCSC 4510 - M.A. Papalaskari - Villanova University 24
– Simple: easy to understand and to implement– Efficient: Time complexity: O(tkn), – where n is the number of data points, – k is the number of clusters, and – t is the number of iterations. – Since both k and t are small. k-means is considered a
linear algorithm. • K-means is the most popular clustering algorithm.
www.cs.uic.edu/~liub/teach/cs583-fall-05/CS583-unsupervised-learning.pptCSC 4510 - M.A. Papalaskari - Villanova University 25