19
CSCI 765 Big Data and Infinite Storage
| Date post: | 03-Jan-2016 |
| Category: |
Documents |
| Upload: | madeline-blankenship |
| View: | 222 times |
| Download: | 0 times |

CSCI 765
Big Data and
Infinite Storage

One new idea introduced in this course is the emerging idea of structuring data into vertical structures and processing across those vertical structures.
This is in contrast to the traditional method of structuring data into horizontal structures and processing down those horizontal structures (horizontal structures are often called records, e.g., an employee file containing horizontal employee records which are made up of fields such as Name, Address, Salary, Phone, etc.)
Thus, horizontal processing of vertical data (HPVD) will be introduced as an alternative to the traditional vertical processing of horizontal data (VPHD).
Why do we need to structure and process data differently than we have in the past?
What has changed?
Data (digital data) has gotten really BIG!!
How big is BIG DATA these days and how big will it get?

An Example: The US Library of Congress is storing EVERY tweet sent since Twitter launched in 2006.
Each tweet record contains fifty fields.
Let's assume each of those horizontal tweet records is about 1000 bits wide.
Let's estimate approximately 1 trillion tweets from 1 billion tweeters, to 1 billion tweetees over 10 years of tweeting?
As a full data file that's 1030 data items (1012 *109 * 109)

That's BIG! Is it going to get even bigger?Yes.
Let’s look at how the definition of “big data” has evolved just over my work lifetime.
My first job in this industry was as THE technician at the St. John’s University IBM 1620 Computer Center. I did the following:
1. I turned the 1620 switch on. 2. I waited for the ready light bulb to come on (~15 minutes) 3. I put the Op/Sys punch card stack on the card reader (~4 inches high)4. I put the FORTRAN compiler card stack on the reader (~3 inches)5. I put the FORTRAN program card stack on the reader (~2 inches)6. The 1620 produced an object code stack which I read in (~1 inch)7. I read in the object stack and a 1964 BIG DATA stack (~40 inches)
The 1st FORTRAN upgrade allowed for a “continue” card so that the data stack could be read in segments (and I could sit down).

How high would a 2013 BIG DATA STACK reach today if it were put on punch cards?
Let's be conservative and assume an exabyte (218 bytes) of data on cards
How high is an exabyte punch card stack? Take a guess.................?
Keep in mind that we're being conservative because the US LoC tweet database may be ~1030 bytes or more soon (if it's fully losslessly stored).

That exabyte stack of
punch cards would reach to
JUPITER!
So, in my work lifetime, BIG DATA has gone from 40 inches high all the way to Jupiter!
What will happen to BIG DATA over your work lifetime?

I must deal with a data file that would reach Jupiter as a punch card stack, but I can replace it losslessly by 1000 extendable vertical pTrees and write programs to process across those 1000 vertical structures horizontally.
You may have to deal with a data file that would reach the end of space (if on cards), but you can replace it losslessly by 1000 extendable vertical pTrees and write programs to process across those 1000 vertical structures horizontally.
The next generation may have to deal with a data file that creates new space, but can replace it losslessly by 1000 extendable vertical pTrees and write programs to process across those 1000 vertical structures horizontally.
You will be able to use my code! The next generation will be able to use my code too!
It seems clear that DATA WILL HAVE TO BE COMPRESSED and that data will have to be VERTICALLY structured.
Let's take a quick look at how one might organize and compressed vertical data (more on that later too).
But it's pure0 so this branch ends
0 0 0 0 1
P11
4. Left half of rt half ? false0 00 0 0
2. Left half pure1? false 0
00 0
1. Whole thing pure1? false 0
5. Rt half of right half? true1
00 0 0 1
R11 0 0 0 0 0 0 1 1
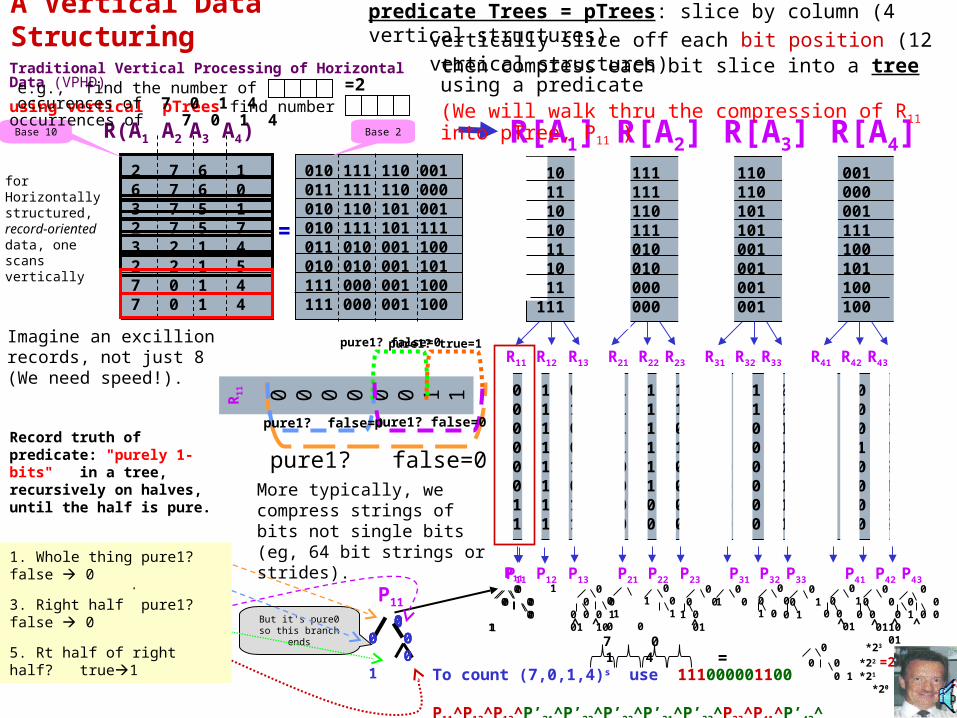
predicate Trees = pTrees: slice by column (4 vertical structures).
Record truth of predicate: "purely 1-bits" in a tree, recursively on halves, until the half is pure.
3. Right half pure1? false 0 00 0
0 1 0 1 1 1 1 1 0 0 0 10 1 1 1 1 1 1 1 0 0 0 00 1 0 1 1 0 1 0 1 0 0 10 1 0 1 1 1 1 0 1 1 1 10 1 1 0 1 0 0 0 1 1 0 00 1 0 0 1 0 0 0 1 1 0 11 1 1 0 0 0 0 0 1 1 0 01 1 1 0 0 0 0 0 1 1 0 0
R11 R12 R13 R21 R22 R23 R31 R32 R33 R41 R42 R43
R[A1] R[A2] R[A3] R[A4] 010 111 110 001011 111 110 000010 110 101 001010 111 101 111011 010 001 100010 010 001 101111 000 001 100111 000 001 100
vertically slice off each bit position (12 vertical structures)then compress each bit slice into a tree using a predicate(We will walk thru the compression of R11 into pTree, P11 )
P11
pure1? false=0
pure1? false=0
pure1? false=0pure1? true=1
pure1? false=0
Traditional Vertical Processing of Horizontal Data (VPHD)
R(A1 A2 A3 A4)
2 7 6 16 7 6 03 7 5 12 7 5 73 2 1 42 2 1 57 0 1 47 0 1 4
for Horizontally structured,record-oriented data, one scans vertically
010 111 110 001011 111 110 000010 110 101 001010 111 101 111011 010 001 100010 010 001 101111 000 001 100111 000 001 100
=
Base 10 Base 2
P11 P12 P13 P21 P22 P23 P31 P32 P33 P41 P42 P43 0 0 0 0 1
1
0 0 00 0 0 1 01 10
0 1 0
0 1 0 1 0
0 0 01 0 01
0 1 0
0 0 0 1 0
0 0 10 1
0 0 10 0 01
0 0 00 0 01
0 0 0 0 1 0 010 01^ ^ ^ ^ ^ ^ ^
=2
To count (7,0,1,4)s use 111000001100 P11^P12^P13^P’21^P’22^P’23^P’31^P’32^P33^P41^P’42^P’43
7 0 1 4
0 *23
0 0 *22 =2 0 1 *21
*20
=
A Vertical Data Structuring
using vertical pTrees find number occurrences of 7 0 1 4e.g., find the number of occurences of 7 0 1 4
Imagine an excillion records, not just 8 (We need speed!).
More typically, we compress strings of bits not single bits (eg, 64 bit strings or strides).

The age of Big Data is upon us
and so is the age of
Infinite Storage.
Many of us have enough money in our pockets right now to buy all the storage we will be able to fill for the next 5 years.
So having adequate storage capacity is no longer much of a problem.
Managing our storage is a problem (especially managing BIG DATA storage).
How much data is there?
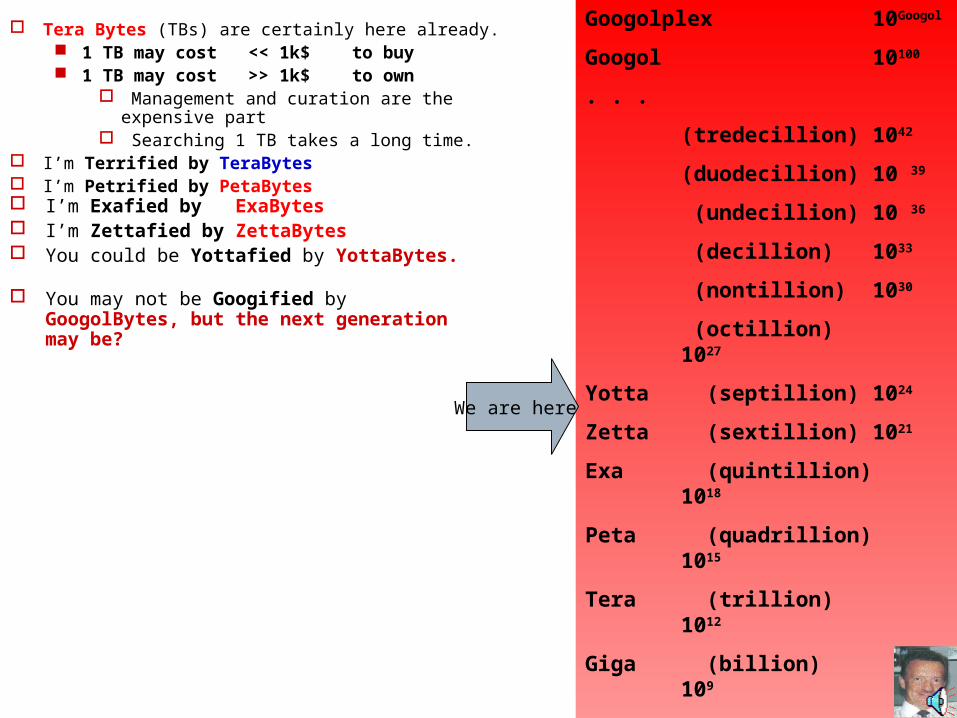
Tera Bytes (TBs) are certainly here already. 1 TB may cost << 1k$ to buy 1 TB may cost >> 1k$ to own
Management and curation are the expensive part Searching 1 TB takes a long time.
I’m Terrified by TeraBytes I’m Petrified by PetaBytes
Googolplex 10Googol
Googol 10100
. . .
(tredecillion) 1042
(duodecillion) 10 39
(undecillion) 10 36
(decillion) 1033
(nontillion) 1030
(octillion) 1027
Yotta (septillion) 1024
Zetta (sextillion) 1021
Exa (quintillion) 1018
Peta (quadrillion) 1015
Tera (trillion) 1012
Giga (billion) 109
Mega (million) 106
Kilo (thousand) 103
We are here
I’m Exafied by ExaBytes I’m Zettafied by ZettaBytes You could be Yottafied by YottaBytes.
You may not be Googified by GoogolBytes, but the next generation may be?

How much information is there?
Soon everything may be recorded.
Most of it will never be seen by humans.
Data summarization, Vertical Structuring, Compression, trend detection, anomaly detection, data mining, are key technologies
Yotta
Zetta
Exa
Peta
Tera
Giga
Mega
KiloA BookA Book
.Movie
All books (words)
All Books MultiMedia
Everything!Recorded
A PhotoA Photo
10-24 Yocto, 10-21 zepto, 10-18 atto, 10-15 femto, 10-12 pico, 10-9 nano, 10-6 micro, 10-3 milli

First Disk, in 1956 IBM 305 RAMAC
4 MB
50 24” disks
1200 rpm (revolutions per minute)
100 milli-seconds (ms) access time
35k$/year to rent
Included computer & accounting software(tubes not transistors)
7th Grade
C.S. lab Tech.

10 years later1.
6 m
eter
s 30 MB
Disk EvolutionKilo
Mega
Giga
Tera
Peta
Exa
Zetta
Yotta

MemexAs We May Think, Vannevar Bush, 1945
“A memex is a device in which an individual stores all his books, records, and communications, and which is mechanized so that it may be consulted with exceeding speed and flexibility”
“yet if the user inserted 5000 pages of material a day it would take him hundreds of years to fill the repository, so that he can enter material freely”

Can you fill a terabyte in a year?
Item Items/TB Items/day
a 300 KB JPEG image 3 M 10,000
a 1 MB Document 1 M 3,000
a 1 hour, 256 kb/s MP3 audio file
10 K 26
a 1 hour video 300 0.8

On a Personal Terabyte, how Will We Find Anything?
Need Queries, Indexing, Vertical Structuring?, Compression, Data Mining, Scalability, Replication…
If you don’t use a DBMS, you will implement one of your own!
Need for Data Mining, Machine Learning is more important then ever!
Of the digital data in existence today,
80% is personal/individual
20% is Corporate/Governmental
DBMSDBMS

Parkinson’s Law (for data) Data expands to fill available storage
Disk-storage version of Moore’s Law
Available storage doubles every 9 months!
How do we get the information we need from the massive volumes of data we will have? Vertical Structuring and Compression Querying (for the information we know is there) Data mining (for answers to questions we don't know to ask
preciselyMoore’s Law with respect to processor performance seems to be
over (processor performance doubles every x months…). Note that the processors we find in our computers today are the same as the ones we found a few years ago. That’s because that technology seems to have reached a limit (minaturizing). Now the direction is to put multiple processor on the same chip or die and to use other types of processor to increase performance.

Thank you.

















