Page 1
PDM CSE 1/189
CSE-423F
Distributed Operating System
Mrs. Jyoti Arora
A.P. (CSE)
PDMCE
[email protected]
CSE-423 F DISTRIBUTED OPERATING SYSTEM
L T P Class Work: 50
3 1 - Exam:100
Total: 150
Duration of Exam: 3 Hrs.
NOTE: For setting up the question paper, question no 1 will be set up from all the four sections which will be compulsory and of short
answer type. Two questions will be set from each of the four sections. The students have to attempt first common question, which is
compulsory, and one question from each of the four sections. Thus students will have to attempt 5 questions out of 9 questions.
Section A
Introduction: Introduction to Distributed System, Goals of Distributed system, Hardware and Software concepts, Design issues, Communication
in distributed system: Layered protocols, ATM networks, Client – Server model, Remote Procedure Calls and Group Communication.
Middleware and Distributed Operating Systems.
Section B
Synchronization in Distributed System: Clock synchronization, Mutual exclusion, Election algorithm, the Bully algorithm, Ring algorithm,
Atomic Transactions, Deadlock in Distributed Systems, Distributed Deadlock Prevention, Distributed Deadlock Detection.
Section C
Processes and Processors in distributed systems: Threads, System models, Processors Allocation, Scheduling in Distributed System, Real Time
Distributed Systems. Distributed file systems: Distributed file system Design, Distributed file system Implementation, Trends in Distributed FS.
Section D
Distributed Shared Memory: What is shared memory, Consistency models, Page based distributed shared memory, shared variables distributed
shared memory.
Case study MACH: Introduction to MACH, process management in MACH, communication in MACH, UNIX emulation in MACH.
Text Book:
1. Distributed Operating System – Andrew S. Tanenbaum, PHI.
2. Operating System Concepts, P.S.Gill, Firewall Media
PDM CSE 2/189
Page 2
References
• Distributed Operating System
– Andrew S. Tanenbaum, PHI.
• Operating System Concepts
- P.S.Gill, Firewall Media
• Distributed Operating Systems Concepts & Design
- P.K.Sinha
• http://www.cs.pitt.edu/~mosse/cs2510/class-notes/clocks.pdf
• http://web.info.uvt.ro/~petcu/distrib/SD6.pdf
PDM CSE 3/189
Background History
• Students should have knowledge of Operating system concepts like Basics
of operating system, scheduling, deadlocks, file system, mutual exclusion
PDM CSE 4/189
Page 3
Section-A
PDM CSE 5/189
Section-A
• Introduction to Distributed System
• Goals of Distributed system
• Hardware and Software concepts
• Design issues
• Communication in distributed system: Layered protocols
• ATM networks
• Client – Server model
• Remote Procedure Calls
• Group Communication
• Middleware and Distributed Operating Systems
PDM CSE 6/189
Page 4
PDM CSE 7
Distributed Operating System
• A distributed system is a collection of independent computers that appear
to the users of the system as a single computer. This definition has two
aspects. The first one deal with hardware: the machines are autonomous.
The second one deal with software: the users think of the system as a single
computer.
• Example of Distributed system- A large bank with hundreds of branch
offices all over the world. Each office has a master computer to store local
accounts and handle local transactions. In addition, each computer has the
ability to talk to all other branch computers and with a central computer at
headquarters. If transactions can be done without regard to where a
customer or account is, and the users do not notice any difference between
this system and the old centralized mainframe that it replaced, it too would
be considered a distributed system.
Goals of Distributed System
• Advantages of Distributed System over Centralized System
Ø Economic-Microprocessors offer a better price/performance than
mainframes.
Ø Speed-A distributed system may have more total computing power
than a mainframe.
Ø Inherently Distribution- Some Applications involve spatially
separated machines.
Ø Reliability- If one machine crashes, the system as a whole can still
survive
Ø Incremental Growth-Computing power can be added in small
increments.
PDM CSE 8
Page 5
Distributed System Goals
(contd.)
• Advantages of Distributed System over Independent PC’s
Ø Data sharing- Allow many users access to a common data base
Ø Device Sharing -Allow many users to share expensive peripherals like
color printers
Ø Communication- Make human-to-human communication easier, for
example, by electronic mail.
Ø Flexibility- Spread the workload over the available machines in the most
cost effective way
PDM CSE 9
Disadvantages of Distributed
System
• Disadvantages of Distributed Systems
Ø Software- Little software exist at present for distributed system. What
kinds of operating systems, programming languages, and applications are
appropriate for these systems? How much should the users know about the
distribution? How much should the system do and how much should the
users do?
Ø Networking- The network can saturate or cause other problems. It can
lose messages, which requires special software to be able to recover, and it
can become overloaded. When the network saturates, it must either be
replaced or a second one must be added.
Ø Security- Easy access also applies to secret data. For data that must be kept
secret at all costs, it is often preferable to have a dedicated, isolated
personal computer that has no network connections to any other machines,
and is kept in a locked room with a secure safe in which all the floppy disks
are stored
PDM CSE 10
Page 6
Distributed Programming
Architectures/Categories
• Client -Server
• 3-tier Architecture
• N-tier Architecture
• Tightly coupled
• Peer to Peer
Ø Client-Server- Small Clients code contacts the server for data then formats
& displays it to the user. Input at the client is committed back to server
when it represents a permanent change
Ø 3-tier Architecture- 3-tier system move the client intelligence to a middle
tier so that stateless clients can be used. This simplifies application
deployment. Most web applications are 3-tier.
PDM CSE 11
Distributed Programming
Architectures/Categories(contd..)
Ø N-tier Architecture- The web application which further forward their
request to other enterprise services. This type of applications is the one
most responsible foe the success of applications servers.
Ø Tightly coupled- It refers to a set of highly integrated machine that run the
same process in parallel subdividing the task in parts that are made
individually by each one & then put back together to make the final result.
Ø Peer to peer-An architecture where there is no special machine that
provide a service or manage the network resources. Instead all
responsibilities are uniformly divided among all machines known as peers.
Peers can serve both clients & servers.
PDM CSE 12
Page 7
Characteristics of Distributed
System
Ø Autonomous – the machines are autonomous in distributed system
Ø Single system view- the users think that they are dealing with single
system
Ø Heterogeneous computer & network- the workstations in distributed
system may differ from each other & also in way they communicate
(network)
Ø Interaction- Interactions of computers are hidden from users
Ø Scalable- Distributed system should be scalable
Ø Middleware- Distributed system may be organized as a means of layer of
software & placed between higher layer & underneath layer
PDM CSE 13
Hardware concepts
• Multiple CPU’s are connected in distributed system. To connect multiple
computers various classifications schemes are possible-in terms of how
they are connected & how they communicate.
• Flynn’s classification based on number of instructions stream & number of
data stream-
Ø SISD
Ø SIMD
Ø MISD
Ø MIMD
PDM CSE 14
Page 8
Hardware Concepts(contd..)
• Taxonomy of parallel and distributed computer systems.
PDM CSE 15
Hardware concepts(contd..)
• Multiprocessor- Single virtual address space shared by all cpu’s. Works as
parallel computers
Ø Also known as tightly coupled system
Ø Delay of sending of messages from one computer to another is short
Ø Data rate is high (i.e. number of bits per second that can transfer is large)
Ø Works on a single problem that problem is divided into sub problems &
these sub problems given to Parallel system & after that their work will be
combined
Ø Types of Multiprocessors
§ Bus Based Multiprocessor
§ Switched based multiprocessor
PDM CSE 16
Page 9
Hardware Concepts
(contd…)
• Bus-Based Multiprocessors – A number of CPUs connected to a common
bus, along with a memory module. e.g. Cable T.V. network the cable
company runs a wire down per street & all the subscribers/users share that
cable
• Problems with Cache Memory
Ø Write through cache- Whenever a word is written to the cache it is written
through to memory as well
Ø Snoopy cache- A cache that is always snooping or eavesdropping on the
bus
PDM CSE 17
Hardware concepts(contd..)
PDM CSE 18
• Switched Multiprocessors- Divide the memory up into modules and
connect them to the CPUs with a crossbar switch.
Page 10
Hardware concepts(contd..)
• Multicomputer – Every machine has its own private memory
Ø Inter machine message delay is large
Ø Data rate is low (i.e. number of bits per second that can be transferred is
large)
Ø Used as distributed system
Ø Works on many unrelated problems
Ø Types of Multicomputer
§ Bus based multicomputer
§ Switched based multicomputer
PDM CSE 19
Hardware Concepts
(contd..)
• Bus-Based Multicomputer-A collection of workstations on a LAN Each
CPU has its own local memory. Each CPU has a direct connection to its
own local memory
• Switched Multicomputer-Two topologies are used Grid & Hypercube
(a) Grid – Grids are 2-D in nature in form of rows & columns such as graph
theory. Grids are easy to understand. CPU’s connected in a grid form.
PDM CSE 20
Page 11
Hardware concepts(contd..)
• (b) Hypercube- A hypercube is a n-dimensional cube each vertex is a
cpu.so edge connection between cpu is made by connecting every
corresponding vertex in first cube to every corresponding vertex in second
cube
PDM CSE 21
Software Concepts
• Network Operating Systems
• True Distributed Systems
• Multiprocessor Timesharing Systems
Ø Network Operating Systems- A number of workstations connected by a
LAN. The file server accepts requests from user program running on the
other (nonserver) machine called clients to read & write files. Each
incoming request is examined & executed & the reply is sent back
PDM CSE 22
Page 12
Software Concepts
(contd.)
Ø True Distributed Systems-The goal of such a system is to create the
illusion in the minds of the users that the entire network of computers is a
single timesharing system, rather than a collection of distinct machines.
Ø Multiprocessor Timesharing Systems- Multiprocessors operated as a
UNIX timesharing system with multiple CPUs
PDM CSE 23
Design Issues
• Transparency-Transparency can be achieved by hiding the distribution
from the users.
Ø Location transparency-Users cannot tell where hardware and software
resources such as CPUs, printers, files, and data bases are located.
Ø Migration transparency-Resources must be free to move from one
location to another without having their names change.
Ø Replication transparency-The operating system is free to make additional
copies of files and other resources on its own without the users noticing.
Ø Concurrency transparency-To lock a resource automatically once
someone had started to use it, unlocking it only when the access was
finished.
Ø Parallelism transparency- Parallelism transparency can be regarded as the
Holy Grail for distributed systems designers. When that has been achieved,
the work will have been completed, and it will be time to move on to new
fields.
PDM CSE 24
Page 13
Design Issues (contd…)
• Flexibility-System should be flexible. There are two types of kernel,
known as the monolithic kernel and microkernel.
(a)The monolithic kernel is basically today's centralized operating system
augmented with networking facilities and the integration of remote
services. Most system calls are made by trapping to the kernel, having the
work performed there, and having the kernel return the desired result to the
user process. With this approach, most machines have disks and manage
their own local file systems.
(b) The microkernel approach is more flexible. It provides services:
1. An inter process communication mechanism.
2. Some memory management.
3. A small amount of low-level process management and scheduling.
4. Low-level input/output.
PDM CSE 25
Design Issues(contd..)
PDM CSE 26
•Reliability-If a machine goes down, some other machine takes over the job.
ØAvailability- It refers to the fraction of time that the system is usable. A highly
reliable system must be highly available.
ØSecurity Files and other resources must be protected from unauthorized
usage.
ØFault tolerance-Suppose that a server crashes and then quickly reboots. what
happens? Does the server crash bring users down with it?
Page 14
Design Issues
(contd.)
• Performance-Various Performance issues are Response time, throughput,
system utilization, and amount of network capacity consumed. Pay
considerable attention to the grain size of all computations. Jobs that
involve a large number of small computations, especially ones that interact
highly with one another, may cause trouble on a distributed system with
relatively slow communication. Such jobs are said to exhibit fine-grained
parallelism. On the other hand, jobs that involve large computations, low
interaction rates, and little data, that is, coarse-grained parallelism, may be
a better fit.
PDM CSE 27
Layered Protocol
OSI MODEL
• Open Systems Interconnection Reference Model (Day and Zimmerman,
1983), usually abbreviated as ISO OSI or sometimes just the OSI model.
• OSI model is designed to allow open systems to communicate. An open
system is one that is prepared to communicate with any other open system
by using standard rules that govern the format, contents, and meaning of
the messages sent and received.
• Protocol-Agreement between communicating parties on how
communication is to proceed. Types of protocols-
§ Connection-oriented protocols- Before exchanging data, the sender and
receiver first explicitly establish a connection. When they are done, they
must release (terminate) the connection. E.g. telephone
§ Connectionless protocols- No setup in advance is needed. The sender just
transmits the first message when it is ready. Dropping a letter in a mailbox
is an example of connectionless communication.
PDM CSE 28
Page 15
Layered Protocol
OSI MODEL (contd..)
• Interfaces-Set of operations that together define the service the layer is
prepared to offer its users
• Seven Layers of OSI Model , Functions & Protocols of each Layer
Ø Physical Layer
§ Bit Timings
§ Connection Establishment & Termination
§ Types of Topology
§ Deals with Media
§ Protocols- Token Ring, ISDN
PDM CSE 29
OSI MODEL
(contd.)
Ø Data Link Layer
§ Define Frame Boundaries
§ Error Control
§ Flow Control
§ Piggybacking
§ Protocols-HDLC,PPP
Ø Network Layer
§ Control Subnet Operations
§ Congestion Control
§ Switching
§ Create Virtual Circuit
§ Protocols-IP
PDM CSE 30
Page 16
OSI MODEL
(contd.)
Ø Transport Layer
§ Segmentation & Reassembly
§ Multiplexing & Demultiplexing
§ Flow Control
§ Provide end to end delivery
§ Protocols-TCP, UDP
Ø Session Layer
§ Establish Sessions
§ Token Management
§ Synchronization
§ Graceful close
§ Protocols- SIP ,RPC
PDM CSE 31
OSI MODEL
(contd.)
Ø Presentation Layer
§ Deals with syntax & semantics
§ Encoding Decoding
§ Compression decompression
§ Protocols-JPG,ZIP
Ø Application Layer
§ File Transfer Protocol
§ Email services
§ Telnet
§ Protocols-NNTP,SMTP
PDM CSE 32
Page 17
OSI MODEL
(contd.)
PDM CSE 33
Asynchronous Transfer Mode
• ATM networks are connection oriented. It transmits all information in
small, fixes size packets called cells.
• Advantages of ATM scheme
Ø A single network can now be used to transport an arbitrary mix of voice,
data broadcast television etc.
Ø New services like video conferencing for businesses will also use it
• Most common speed for ATM network are 155mbps & 622mbps.
• All cells follow the same route to the destination. Cell delivery is not
guaranteed but their order is.
• ATM Reference Model
Ø ATM Physical Layer
Ø ATM Layer
Ø ATM Adaptation Layer
PDM CSE 34
Page 18
Asynchronous Transfer
Mode(contd.)
• ATM Physical Layer
Ø Deals with physical medium : voltage, bit timings
• ATM Layer
Ø Deals with cell & cell transport
Ø Congestion control
Ø Establishment & release of virtual circuits
• ATM Adaptation Layer
Ø Segmentation & Reassembly
PDM CSE 35
ATM Switching
PDM CSE 36
(a) An ATM switching network. (b) Inside one switch.
Page 19
The Client-Server Model
• Clients- A process that request Specific services from server process
• Servers- A process that provides requested services for the clients
PDM CSE 37
Client –Server Model
Client- Server Model
(contd..)
• Operations of client
Ø Managing user interface
Ø Accepts & checks the syntax of user inputs
Ø Processes application logic
Ø Generates Database request & transmits to server
• Operations of server
Ø Accepts & process database requests from client
Ø Checks authorization
Ø Ensures that integrity constraints are not violated
Ø Maintains system catalogue
Ø Provide recovery control
Ø Perform Query/update processing & transmits responses to client
PDM CSE 38
Page 20
Client –Server Model
(contd.)
• Client-Server Topologies
Ø Single Client, Single Server- One client is directly connected to one
server
Ø Multiple Client, Single Server- Several clients are directly connected to
only one server
Ø Multiple Client, Multiple Server- Several clients are connected to
several servers
• Types of servers
Ø File server
Ø Database server
Ø Transaction server
Ø Object server
Ø Web server
PDM CSE 39
Client- Server Model
(contd..)
• Classification of Client-Server System
Ø 2-tier Client–Server Model- The client being the first tier & the server
being the second. The client requests services directly from server i.e.
client communicate directly with the server without the help of another
server
Ø 3-tier Client–Server Model- In this system the client request are
handled by intermediate servers which coordinate the execution of
client request with subordinate servers
Ø N-tier Client–Server Model- It allows better utilization of hardware &
platform resources & enhanced security level.
PDM CSE 40
Page 21
Advantages of Client-Server Model
• Advantages of Client Server Model
Ø Performance & Reduced workload
Ø Workstation Independence
Ø System Interoperability
Ø Scalability
Ø Data Integrity
Ø Data Accessibility
Ø System Administration
Ø Reduced Operating costs
Ø Reduced Hardware costs
Ø Communication costs are reduced
PDM CSE 41
Disadvantages of Client-Server
Model
• Disadvantages of Client-Server Model
Ø Maintenance Cost
Ø Training Cost
Ø Hardware Cost
Ø Software Cost
Ø Complexity
• Packets Exchange for Client Server communication
PDM CSE 42
Page 22
Remote Procedure Call
• When a process on machine A calls a procedure on machine B, the calling process
on A is suspended, and execution of the called procedure takes place on B.
Information can be transported from the caller to the callee in the parameters and
can come back in the procedure result. No message passing or I/O at all is visible to
the programmer. This method is known as remote procedure call (RPC)
PDM CSE 43
Remote Procedure Call(contd..)
• A remote procedure call occurs in the following steps:
Ø The client procedure calls the client stub in the normal way.
Ø The client stub builds a message and traps to the kernel.
Ø The kernel sends the message to the remote kernel.
Ø The remote kernel gives the message to the server stub.
Ø The server stub unpacks the parameters and calls the server.
Ø The server does the work and returns the result to the stub.
Ø The server stub packs it in a message and traps to the kernel.
Ø The remote kernel sends the message to the client's kernel.
Ø The client's kernel gives the message to the client stub.
Ø The stub unpacks the result and returns to the client.
PDM CSE 44
Page 23
Remote Procedure Call
(contd..)
• Acknowledgements
Ø Stop-and-wait protocol- In this client send packet 0 with the first 1K,
then wait for an acknowledgement from the server. Then the client
sends the second 1K, waits for another acknowledgement, and so on.
Ø Blast protocol- The client send all the packets as fast as it can. With
this method, the server acknowledges the entire message when all the
packets have been received, not one by one
Ø (a) A 4K message. (b) A stop-and-wait protocol. (c) A blast protocol
PDM CSE 45
Remote Procedure Call(contd..)
• Critical Path-The sequence of instructions that is executed on every RPC
is called the critical path, it starts when the client calls the client stub,
proceeds through the trap to the kernel, the message transmission, the
interrupt on the server side, the server stub, and finally arrives at the server,
which does the work and sends the reply back the other way.
PDM CSE 46
Page 24
Group Communication
• Group- A group is a collection of processes that act together in some system or
user-specified way.
• Types of Groups:
Ø Point-to-point communication is from one sender to one receiver
Ø One-to-many communication is from one sender to multiple receivers.
PDM CSE 47
Group Communication
(contd..)
• Groups are dynamic in nature. New groups can be created & old groups
can be destroyed.
• A process can join the group or leave one. A process can be a member of
several groups at same time. e.g. a person might be a member of a book
club, a tennis club & an environmental organization.
• Multicasting-Create a special network address to which multiple machines
can listen.
• Broadcasting- Packets containing a certain address are delivered to all
machines.
• Unicasting- Sending of a message from a single sender to a single receiver
PDM CSE 48
Page 25
Design Issues of Group
communication
• Closed Groups vs. Open group
• Peer vs. Hierarchical Group
• Group Membership
• Group addressing
• Send and Receive Primitives
• Atomicity
PDM CSE 49
Design Issues of Group
communication (contd..)
• Closed Groups vs. Open group- closed groups, in which only the
members of the group can send to the group. Outsiders cannot send
messages to the group as a whole. open groups, any process in the system
can send to any group.
PDM CSE 50
Page 26
Design Issues of Group
communication (contd..)
• Peer vs. Hierarchical Group-In peer groups, all the processes are equal.
No one is boss and all decisions are made collectively. In Hierarchical
groups, some kind of hierarchy exists. For example, one process is the
coordinator and all the others are workers.
PDM CSE 51
Design Issues of Group
communication (contd..)
• Group Membership – The method needed for creating and deleting
groups, as well as for allowing processes to join and leave groups.
Ø Centralized Approach(Group server) - The group server maintain a
complete data base of all the groups and their exact membership.
Ø Distributed approach-In an open group, an outsider can send a message to
all group members announcing its presence. In a closed group, something
similar is needed (in effect, even closed groups have to be open with
respect to joining). To leave a group, a member just sends a goodbye
message to everyone.
PDM CSE 52
Page 27
Design Issues of Group
communication(contd..)
• Group addressing- Groups need to be addressed, just as processes do. One
way is to give each group a unique address, much like a process address.
Ø Multicasting
Ø Broadcasting
Ø Point-to-point
Ø Predicate Addressing
• Send and Receive Primitives- To send a message, one of the parameters
of send indicates the destination. If it is a process address, a single message
is sent to that one process. If it is a group address (or a pointer to a list of
destinations), a message is sent to all members of the group. A second
parameter to send points to the message. Similarly, receive indicates a
willingness to accept a message, and possibly blocks until one is available
PDM CSE 53
Design Issues of Group
communication(contd..)
• Atomicity-The property of all-or-nothing delivery is called atomicity or
atomic broadcast. An algorithm that demonstrates atomic broadcast is at
least possible. The sender starts out by sending a message to all members of
the group. Timers are set and retransmissions sent where necessary. When
a process receives a message, if it has not yet seen this particular message,
it, too, sends the message to all members of the group (again with timers
and retransmissions if necessary). If it has already seen the message, this
step is not necessary and the message is discarded. No matter how many
machines crash or how many packets are lost, eventually all the surviving
processes will get the message.
PDM CSE 54
Page 28
Middleware
• Middleware is an software glue between Client & server which helps the
communication between client & server
• Forms of Middleware
Ø Transaction Processing Monitor
Ø Remote Procedure Call
Ø Message Oriented Middleware
Ø Object Request Broker
PDM CSE 55
Section-B
PDM CSE 56
Page 29
Section-B
• Clock Synchronization
• Mutual Exclusion
• Election Algorithm
• Bully Algorithm
• Ring Algorithm
• Atomic Transactions
• Deadlock in Distributed Systems
• Distributed Deadlock Prevention
• Distributed Deadlock Detection
PDM CSE 57
Clock Synchronization
• Logical Clocks
Ø Quartz crystal –It oscillates at a well defined frequency
Ø Counter Register- It is used to keep track of the oscillations of the quartz
crystal
Ø Constant register- It is used to store a constant value that is decided based
on the frequency of oscillations of the quartz crystal.
Ø Clock tick- When the value of counter register becomes zero an interrupt is
generated & its value is reinitialized to the value in the constant register.
Each interrupt is called a clock tick.
Ø Clock skew-The difference in time values in two clocks is called clock
skew.
PDM CSE 58
Page 30
Clock Synchronization
(contd..)
Ø Lamport Logical Clock-If a & b are two events & c is the timestamp of
event
• If a happens before b in the same process, C(a)<C(b).
• If a and b represent the sending and receiving of a message, C(a)<C(b).
• For all events a and b, C(a)≠C(b).
Ø Physical Clocks
• Transit of the sun-The event of the sun's reaching its highest apparent
point in the sky is called the transit of the sun. This event occurs at about
noon each day.
• Solar Day-The interval between two consecutive transits of the sun is
called the solar day.
PDM CSE 59
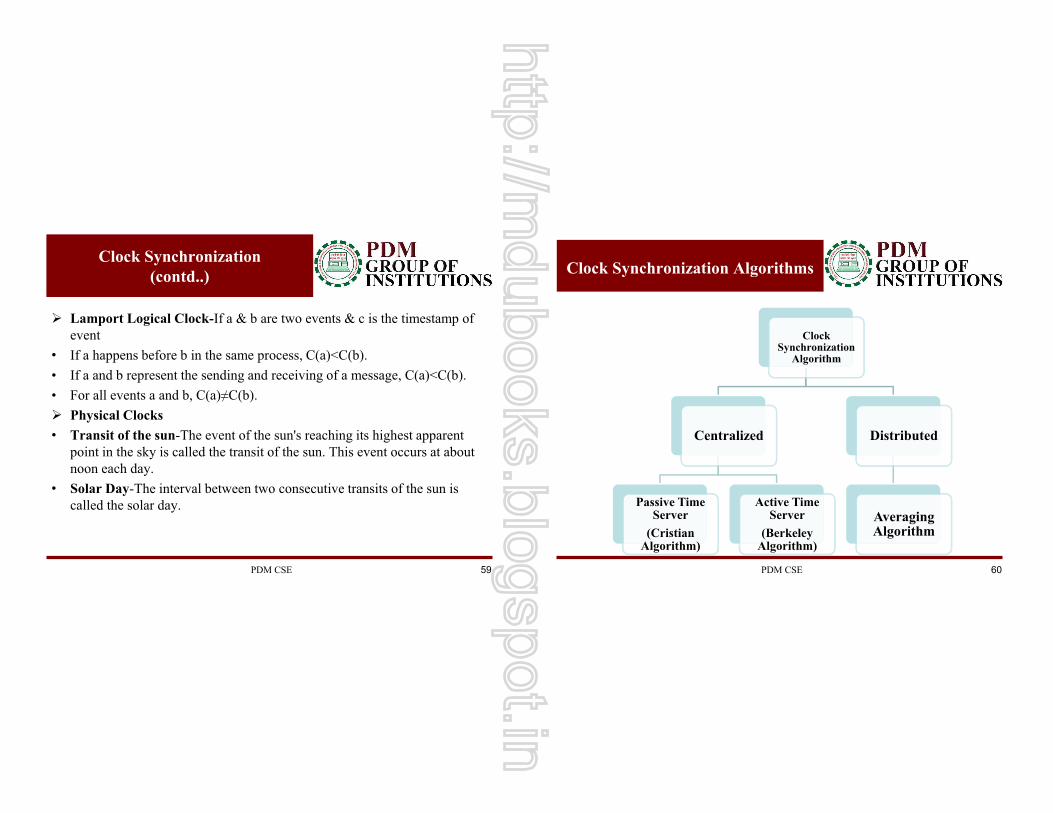
Clock Synchronization Algorithms
Clock Synchronization
Algorithm
Centralized
Passive Time Server
(Cristian Algorithm)
Active Time Server
(Berkeley Algorithm)
Distributed
Averaging Algorithm
PDM CSE 60
Page 31
Clock Synchronization Algorithms
(contd..)
• Cristian's Algorithm- This algorithm has a WWV receiver or timeserver
& the goal is to have all the other machines stay synchronized with it., each
machine sends a message to the time server asking it for the current time.
That machine responds as fast as it can with a message containing its
current time, CUTC
Problems of this algorithm (a) time must never run backward. If the
sender's clock is fast, CUTC will be smaller than the sender's current value of
C. (b) it takes a nonzero amount of time for the time server's reply to get
back to the sender.
The sender record accurately the interval between sending the request to the
time server and the arrival of the reply. Both the starting time, T0, and the
ending time, T1, are measured using the same clock, so the interval will be
relatively accurate, even if the sender's clock is off from UTC by a
substantial amount.
PDM CSE 61
Clock Synchronization Algorithms
(contd..)
• In the absence of any other information, the best estimate of the message
propagation time is (T1–T0)/2. This estimate can be improved if it is known
approximately how long it takes the time server to handle the interrupt and
process the incoming message. Let us call the interrupt handling time I.
Then the amount of the interval from T0 to T1 that was devoted to message
propagation is T1-T0-I, so the best estimate of the one-way propagation time
is half this.
• The Berkeley Algorithm- In this algorithm, the time server is active.
polling every machine periodically to ask what time it is there. Based on
the answers, it computes an average time and tells all the other machines to
advance their clocks to the new time or slow their clocks down until some
specified reduction has been achieved. This method is suitable for a system
in which no machine has a WWV receiver. The time daemon's time must
be set manually by the operator periodically.
PDM CSE 62
Page 32
Clock Synchronization Algorithms
(contd..)
• Averaging Algorithms- It is a decentralized clock synchronization
algorithms works by dividing time into fixed-length resynchronization
intervals. The ith interval starts at T0+iR and runs until T0+(i+1)R, where
T0 is an agreed upon moment in the past, and R is a system parameter. At
the beginning of each interval, every machine broadcasts the current time
according to its clock.
After a machine broadcasts its time, it starts a local timer to collect all other
broadcasts that arrive during some interval 5. When all the broadcasts
arrive, an algorithm is run to compute a new time from them. The simplest
algorithm is just to average the values from all the other machines. A slight
variation on this theme is first to discard the m highest and m lowest
values, and average the rest. Discarding the extreme values can be regarded
as self defense against up to m faulty clocks sending out nonsense.
.
PDM CSE 63
Mutual Exclusion
• Mutual exclusion refers to the problem of ensuring that no two processes
can be in their critical section at the same time.
• Requirements of Mutual Exclusion Algorithm
Ø Freedom from Deadlocks
Ø Freedom from starvation
Ø Fairness
• Performance of mutual exclusion algorithm is measured by
Ø No. of messages
Ø Synchronization delay
Ø Response time
Ø System throughput
PDM CSE 64
Page 33
Mutual Exclusion (contd..)
• Mutual Exclusion Algorithm
Ø A Centralized Algorithm
Ø A Distributed Algorithm
Ø A Token Ring Algorithm
• A Centralized Algorithm One process is elected as the coordinator (e.g.,
the one running on the machine with the highest network address).
Whenever a process wants to enter a critical region, it sends a request
message to the coordinator stating which critical region it wants to enter
and asking for permission.
PDM CSE 65
Centralized Algorithm
PDM CSE 66
(a) Process 1 asks the coordinator for permission to enter a critical region.
Permission is granted
(b) Process 2 then asks permission to enter the same critical region. The
coordinator does not reply.
(c) When process 1 exits the critical region, it tells the coordinator, which then
replies to 2 [2]
Page 34
Centralized algorithm
(contd..)
• Advantages of Centralized algorithm
Ø Guarantees mutual exclusion
Ø Easy to implement & requires only three messages per use of a critical
section(request, grant, release)
• Disadvantages of Centralized algorithm
Ø The coordinator is a single point of failure
Ø Confusion between no reply & permission denied
Ø A single coordinator can become a performance bottleneck
PDM CSE 67
Distributed Algorithm
• When a process wants to enter a critical region, it builds a message
containing the name of the critical region it wants to enter, its process
number, and the current time. It then sends the message to all other
processes, conceptually including itself.
• When a process receives a request message from another process, the
action it takes depends on its state with respect to the critical region named
in the message. Three cases have to be distinguished:
Ø If the receiver is not in the critical region and does not want to enter it, it
sends back an OK message to the sender.
Ø If the receiver is already in the critical region, it does not reply. Instead, it
queues the request.
PDM CSE 68
Page 35
Distributed Algorithm
(contd..)
Ø If the receiver wants to enter the critical region but has not yet done so, it
compares the timestamp in the incoming message with the one contained in
the message that it has sent everyone. The lowest one wins. If the incoming
message is lower, the receiver sends back an OK message. If its own
message has a lower timestamp, the receiver queues the incoming request
and sends nothing.
Ø After sending out requests asking permission to enter a critical region, a
process sits back and waits until everyone else has given permission. As
soon as all the permissions are in, it may enter the critical region. When it
exits the critical region, it sends OK messages to all processes on its queue
and deletes them all from the queue.
PDM CSE 69
Distributed Algorithm (contd..)
PDM CSE 70
a) Two processes want to enter the same critical region at the same moment.
b) Process 0 has the lowest timestamp, so it wins. c) When process 0 is done, it sends an OK also, so 2 can now enter the
critical region.
Page 36
Distributed Algorithm
(contd..)
• Advantages of Distributed algorithm
Ø No single point of failure exits
Ø Number of messages are 2(n-1)messages (n-1) request & (n-1) reply
messages
Ø No starvation, total ordering of messages
Ø Deadlock free
Ø Mutual exclusion guaranteed
• Disadvantages of Distributed algorithm
Ø Slower
Ø More complicated more expensive & less robust than centralized one
PDM CSE 71
Token Ring
• A logical ring is constructed in which each process is assigned a position in
the ring. The ring positions may be allocated in numerical order of network
addresses or some other means. When the ring is initialized, process 0 is
given a token. The token circulates around the ring. it is passed from
process k to process k+1 (modulo the ring size) in point-to-point messages.
When a process acquires the token from its neighbor, it checks to see if it is
attempting to enter a critical region. If so, the process enters the region,
does all the work it needs to, and leaves the region. After it has exited, it
passes the token along the ring. It is not permitted to enter a second critical
region using the same token.
• If a process is handed the token by its neighbor and is not interested in
entering a critical region, it just passes it along. As a consequence, when no
processes want to enter any critical regions, the token just circulates at high
speed around the ring.
PDM CSE 72
Page 37
Token Ring (contd..)
PDM CSE 73
a) An unordered group of processes on a network. b) A logical ring constructed in software.
Comparison of Mutual Exclusion
Algorithms
PDM CSE 74
Page 38
Election Algorithm
• Election algorithms attempt to locate the process with the highest process
number and designate it as coordinator.
Ø The Bully Algorithm
Ø The Ring Algorithm
• The Bully Algorithm When a process notices that the coordinator is no
longer responding to requests, it initiates an election. A process, P, holds an
election as follows:
a. P sends an ELECTION message to all processes with higher numbers.
b. If no one responds, P wins the election and becomes coordinator.
c. If one of the higher-ups answers, it takes over. P's job is done.
PDM CSE 75
Bully Algorithm
• The group consists of 8 processes. Previously process 7 was the
coordinator, but it has just crashed. Process 4 is the first one to notice this,
so it sends ELECTION messages to all the processes higher than it, namely
5, 6, and 7
• Processes 5 and 6 both respond with OK, Upon getting the first of these
responses, 4 knows that its job is over. It just sits back and waits to see who
the winner will be.
• both 5 and 6 hold elections, each one only sending messages to those
processes higher than itself.
• process 6 tells 5 that it will take over. At this point 6 knows that 7 is dead
and that it (6) is the winner. When it is ready to take over, 6 announces this
by sending a COORDINATOR message to all running processes.
PDM CSE 76
Page 39
Bully Algorithm (contd..)
• When 4 gets this message, it can now continue with the operation it was
trying to do when it discovered that 7 was dead, but using 6 as the
coordinator this time. In this way the failure of 7 is handled and the work
can continue.
• If process 7 is ever restarted, it will just send all the others a
COORDINATOR message and bully them into submission.
PDM CSE 77
Bully Algorithm(contd..)
PDM CSE 78
The bully election algorithm. (a) Process 4 holds an election. (b) Processes 5
and 6 respond, telling 4 to stop. (c) Now 5 and 6 each hold an election. (d)
Process 6 tells 5 to stop. (e) Process 6 wins and tells everyone.
Page 40
Ring Algorithm
• In Ring algorithm if any process notices that the current coordinator has
failed, it starts an election by sending message to the first neighbor on the
ring.
• The election message contains the node’s process identifier and is
forwarded on around the ring.
• Each process adds its own identifier to the message.
• When the election message reaches the originator, the election is complete.
• Coordinator is chosen based on the highest numbered process.
PDM CSE 79
Ring Algorithm (contd..)
Election Algorithm using a Ring
PDM CSE 80
Page 41
Atomic Transaction
• A transaction that happens completely or not at all (No Partial results)
e.g.
ØCash machine hands you cash and deducts amount from your account
ØAirline confirms your reservation and
– Reduces number of free seats
– Charges your credit card
• Fundamental principles – A C I D
Ø Atomicity – to outside world, transaction happens indivisibly
Ø Consistency – transaction preserves system invariants
Ø Isolated – transactions do not interfere with each other
Ø Durable – once a transaction “commits,” the changes are permanent
PDM CSE 81
Tools for Implementing Atomic
Transaction
• Stable storage
Ø write to disk “atomically”
• Log file
Ø record actions in a log before “committing” them
Ø Log in stable storage
• Locking protocols
Ø Serialize Read and Write operations of same data by separate transactions
• Begin transaction
Ø Place a begin entry in log
• Write
Ø Write updated data to log
PDM CSE 82
Page 42
Tools for Implementing Atomic
Transaction (contd..)
• Abort transaction
Ø Place abort entry in log
• End transaction (commit)
Ø Place commit entry in log
Ø Copy logged data to files
Ø Place done entry in log
PDM CSE 83
Concurrency Control in Atomic
Transactions
• Locking-When a process needs to read or write a file as part of a
transaction it first locks the file. If a read lock is set on a file other read
locks are permitted. When a file is locked for writing no other locks of any
kind are permitted. Read locks are shared, but write locks must be
exclusive.
• Two Phase Locking Protocol-In this the process first acquire all the locks
it needs during the growing phase then releasing them during the shrinking
phase.
• Granularity of Locking-The issue of how large an item to lock is called
granularity of locking. The finer the granularity ,the most precise the lock
can be & more parallelism can be achieved.
PDM CSE 84
Page 43
Concurrency Control
(contd.)
• Optimistic Concurrency Control- The idea is just go ahead & do
whatever you want to, without paying attention to what anybody else is
doing. Optimistic concurrency control is deadlock free & allows maximum
parallelism because no process ever has to wait for a lock.
• Timestamps-Assign each transaction a timestamp at the moment it does
BEGIN_TRANSACTION. Every file in the system has a read & write
timestamp associated with it, telling which committed transaction last read
& wrote it.
PDM CSE 85
Deadlocks in Distributed System
• Distributed Deadlocks
Ø Communication Deadlocks- A communication deadlock occurs, for
example, when process A is trying to send a message to process B,
which in turn is trying to send one to process C, which is trying to send
one to A.
Ø Resource Deadlocks -A resource deadlock occurs when processes are
fighting over exclusive access to I/O devices, files, locks, or other
resources.
• Strategies are used to handle deadlocks
Ø The ostrich algorithm (ignore the problem)
Ø Detection (let deadlocks occur, detect them, and try to recover)
Ø Prevention (statically make deadlocks structurally impossible)
Ø Avoidance (avoid deadlocks by allocating resources carefully)
PDM CSE 86
Page 44
Distributed Deadlock Detection
• Centralized Deadlock Detection
• Distributed Deadlock Detection
Ø Centralized Deadlock Detection - Each machine maintains the resource
graph for its own processes and resources, a central coordinator maintains the
resource graph for the entire system (the union of all the individual graphs).
When the coordinator detects a cycle, it kills off one process to break the
deadlock.
§ False Deadlock- Detecting a nonexistent deadlock in distributed systems
has been referred to as false deadlock detection. False deadlock wi1l never
occur in a system of two-phase locking transactions & the coordinator
conclude incorrectly that a deadlock exist and kills some process.
PDM CSE 87
False Deadlock
PDM CSE 88
(a) Initial resource graph for machine 0(b) Initial resource graph for machine 1
(c) The coordinator's view of the world. (d) The situation after the delayed
message.
Page 45
Distributed Deadlock Detection
Ø Distributed Deadlock Detection- a special probe message is generated
and sent to the process (or processes) holding the needed resources. The
message consists of three numbers: the process that just blocked, the
process sending the message, and the process to whom it is being sent. The
initial message from 0 to 1 contains the triple (0, 0, 1).
Probe Message
PDM CSE 89
Distributed Deadlock Prevention
• Distributed Deadlock Prevention
Ø Wait-die-An old process wants a resource held by a young process. A
young process wants a resource held by an old process. In one case we
should allow the process to wait; in the other we should kill it. e.g. if
(a) dies and (b) wait. Then killing off an old process trying to use a
resource held by a young process, which is inefficient. This algorithm
is called wait-die.
PDM CSE 90
Page 46
Distributed Deadlock Prevention
(contd..)
PDM CSE 91
Ø Wound wait Algorithm- One transaction is supposedly wounded (it is
actually killed) and the other waits. If an old process wants a resource
held by a young process the old process preempts the young one whose
transaction is then killed. The young one probably starts up again
immediately & tries to acquire the resource forcing it to wait
Section - C
PDM CSE 92
Page 47
Section - C
• Threads
• System models
• Processors Allocation
• Real Time Distributed Systems
• Distributed file system Design
• Distributed file system Implementation
• Trends in Distributed file systems
PDM CSE 93
Thread
• A thread is a Light weight process .Threads are like little mini-processes.
• Threads can create child threads and can block waiting for system calls to
complete, just like regular processes.
• Each Process has its own Program counter, its own stack, its own register
set& its own address space
(a) Three processes with one thread each. (b) One process with three threads.
PDM CSE 94
Page 48
Thread (contd..)
• Thread states
Ø Running-A running thread currently has the CPU & is active
Ø Blocked-A blocked thread is waiting for another thread to unblock it
Ø Ready- A ready thread is scheduled to run & will as soon as its turn comes
up
Ø Terminated – A terminated thread is one that has exited
• Per Thread items-Program counter, Stack, register set, Child thread, State
• Per Process items-Open files, Child processes, Global variables, Timers,
Signals, Semaphores
PDM CSE 95
Thread Organizations in a process
• Dispatcher/worker Model
• Team Model
• Pipeline Model
PDM CSE 96
Page 49
Thread organization in a process
(contd..)
• Dispatcher/worker Model-The Dispatcher thread reads incoming requests
for work from the system mailbox & chooses an idle worker thread &
hands it the request. Each worker thread works on a different client request.
• Team Model- All threads behave as equal, there is no master slave
relationship between threads. Each thread gets & processes client’s request
on its own.
• Pipeline Model- In this model, output data generated by one part of
application is used as input for another part of application. The threads of a
process are organized as a pipeline so that the output data generated by first
thread is used for processing by second thread, the output of second thread
is used for processing by the third thread & so on.
PDM CSE 97
Design Issues for Threads Packages
§ Threads Package -A set of primitives available to the user relating to
threads.
Ø Threads Creation-Threads can be created either statically or dynamically.
In static approach the number of threads of a process is decided at the time
of writing the program. In Dynamic approach the number of threads of a
process keeps changing dynamically.
Ø Threads Termination- A thread may either destroy itself when it finishes
its job by making an exit call or be killed from outside by using kill
command.
Ø Threads Synchronization- Execution of critical section in which the same
data is accessed by the threads must be mutually exclusive in time. Mutex
variable & condition variable are used to provide mutual exclusion
Ø Threads Scheduling- Scheduling based on Priority assignment Facility &
Handoff scheduling
PDM CSE 98
Page 50
Implementing a Threads Package
• Implementing Threads in User Space
• Implementing Threads in Kernel Space
• (a) A user-level threads package. (b) A threads packaged managed by the
kernel.
PDM CSE 99
Implementing a Threads Package
(Contd..)
• User Level Thread Approach-
Ø Put the thread package entirely in user space.
Ø Kernel knows nothing about them.
Ø Run time system (RTS) maintains status information table of threads,
threads states, threads priority, context switching.
• Kernel Level Thread Approach-
Ø No Run time System is used
Ø Threads managed by Kernel
Ø Implementation of blocking system call is straightforward
PDM CSE 100
Page 51
System Models
• Workstation Model
• Processor pool Model
Ø Workstation Model-A network of personal workstations, each with a local
file system. The system consists of workstations scattered throughout a
building or campus and connected by a high-speed LAN.
PDM CSE 101
Workstation Model
• Advantages of Workstation Model
Ø Workstation Models are manifold and clear.
Ø Easy to understand.
Ø Users have a fixed amount of dedicated computing power, and thus
guaranteed response time.
Ø Sophisticated graphics programs can be very fast, since they can have
direct access to the screen.
Ø Each user has a large degree of autonomy and can allocate his workstation's
resources as he sees fit.
• Disadvantages of Workstation Model-
Ø Much of the time users are not using their workstations, which are idle,
while other users may need extra computing capacity and cannot get it.
PDM CSE 102
Page 52
System Models (contd.)
• Processor Pool Model- A rack full of cpu’s in the machine room, which
can be dynamically allocated to users on demand.
• Advantages of Processor pool model-
Ø It allows better utilization of available processing power
Ø Provides grater flexibility than workstation model
• Disadvantages of Processor pool model-
Ø Unsuitable for high performance interactive applications
PDM CSE 103
Processor Allocation
• Allocation Models
Ø Non-migratory Allocation Algorithm-When a process is created, a
decision is made about where to put it. Once placed on a machine, the
process stays there until it terminates. It may not move, no matter how
badly overloaded its machine becomes and no matter how many other
machines are idle.
Ø Migratory Allocation Algorithm-A process can be moved even if it has
already started execution.
• Maximize CPU utilization
• Minimizing Mean response time
• Minimizing response ratio
PDM CSE 104
Page 53
Design Issues for Processor
Allocation Algorithms
• Deterministic versus heuristic algorithms-Deterministic algorithms are
appropriate when everything about process behavior is known in advance.
At the other extreme are systems where the load is completely
unpredictable. Requests for work depend on who's doing what, and can
change dramatically from hour to hour, or even from minute to minute.
• Centralized versus distributed algorithms-Collecting all the information
in one place allows a better decision to be made, but is less robust and can
put a heavy load on the central machine. Decentralized algorithms are those
in which information is in scattered form.
• Optimal versus suboptimal algorithms - Optimal solutions can be
obtained in both centralized and decentralized systems. They involve
collecting more information and processing it more thoroughly.
PDM CSE 105
Design Issues for Processor
Allocation (contd.)
• Local & Global algorithm-When a process is about to be created, a
decision has to be made whether or not it can be run on the machine where
it is being generated. If that machine is too busy, the new process must be
transferred somewhere else.
• Sender-initiated versus receiver-initiated algorithms-Once the transfer
policy has decided to get rid of a process, the location policy has to figure
out where to send it. In one method, the senders start the information
exchange. In another, it is the receivers that take the initiative.
PDM CSE 106
Page 54
Implementation Issues for
Processor Allocation Algorithms
• All the algorithms assume that machines know their own load, so they can
tell if they are under loaded or overloaded, and can tell other machines
about their state.
• Count the number of processes on each machine and use that number as the
load.
• Count only processes that are running or ready.
• Count the fraction of time the CPU is busy.
• Take into account the CPU time, memory usage, and network bandwidth
consumed by the processor allocation algorithm itself.
PDM CSE 107
Processor Allocation Algorithms
• Graph-Theoretic Deterministic Algorithm-The system can be
represented as a weighted graph, with each node being a process and each
arc representing the flow of messages between two processes. Arcs that go
from one sub graph to another represent network traffic. The goal is then to
find the partitioning that minimizes the network traffic while meeting all
the constraints.
Ø Two ways of allocating nine processes to three processors.
PDM CSE 108
Page 55
Centralized Processor Allocation
Algorithms
• Centralized Algorithm- A coordinator maintains a usage table with one entry
per personal workstation, initially zero. when significant events happen,
messages are sent to the coordinator to update the table. Allocation decisions
are based on the table.
Ø This algorithm, called up-down, is centralized in the sense that a coordinator
maintains a usage table with one entry per personal workstation, initially zero.
when significant events happen, messages are sent to the coordinator to update
the table. Allocation decisions are based on the table. These decisions are made
when scheduling events happen: a processor is being requested, a processor has
become free, or the clock has ticked.
Ø Usage table entries can be positive, zero, or negative. A positive score indicates
that the workstation is a net user of system resources, whereas a negative score
means that it needs resources. A zero score is neutral.
PDM CSE 109
Hierarchical Processor Allocation
Algorithms
PDM CSE 110
• Hierarchical Algorithm- A collection of processors is organize in a logical
hierarchy independent of the physical structure of the network. For each group of
k workers, one manager machine is assigned the task of keeping track of who is
busy and who is idle. What happens when a department head, or worse yet, a big
cheese, stops functioning (crashes)? One answer is to promote one of the direct
subordinates of the faulty manager to fill in for the boss. The choice of which can
be made by the subordinates themselves, by the deceased's peers, or in a more
autocratic system, by the sick manager's boss.
A processor hierarchy can be modeled as an organizational hierarchy.
Page 56
Sender & Receiver Initiated
Processor Allocation Algorithms
• A Sender-Initiated Distributed Heuristic Algorithm- when a process is
created, the machine on which it originates sends probe messages to a
randomly-chosen machine, asking if its load is below some threshold value.
If so, the process is sent there. If not, another machine is chosen for
probing. Probing does not go on forever. If no suitable host is found within
N probes, the algorithm terminates and the process runs on the originating
machine.
• A Receiver-Initiated Distributed Heuristic Algorithm- whenever a
process finishes, the system checks to see if it has enough work. If not, it
picks some machine at random and asks it for work. If that machine has
nothing to offer, a second, and then a third machine is asked. If no work is
found with N probes, the receiver temporarily stops asking, does any work
it has queued up, and tries again when the next process finishes. If no work
is available, the machine goes idle. After some fixed time interval, it begins
probing again.
PDM CSE 111
Bidding Processor Allocation
Algorithms
• A Bidding Algorithm- Each processor advertises its approximate price by
putting it in a publicly readable file. Different processors may have different
prices, depending on their speed, memory size, presence of floating-point
hardware, and other features. expected response time, can also be published.
Ø When a process wants to start up a child process, it goes around and checks out
who is currently offering the service that it needs. It then determines the set of
processors whose services it can afford. From this set, it computes the best
candidate, where "best" may mean cheapest, fastest, or best price/performance,
depending on the application. It then generates a bid and sends the bid to its
first choice. The bid may be higher or lower than the advertised price.
Ø Processors collect all the bids sent to them, and make a choice, presumably by
picking the highest one. The winners and losers are informed, and the winning
process is executed. The published price of the server is then updated to reflect
the new going rate.
PDM CSE 112
Page 57
Real Time Distributed System
• Real time System- A real-time systems interact with the external world in
a way that involves time. E.g. an audio compact disk player consists of a
CPU that takes the bits arriving from the disk and processes them to
generate music.
• Types of Real time System
Ø Soft Real Time System
Ø Hard Real Time System
• Soft real-time-Where a critical real time task gets priority over other tasks
& retains that priority until it completes
• Hard Real time-Guarantees that critical tasks be completed on time
PDM CSE 113
Design Issues of Real Time
Distributed System
• Design Issues of Real Time Distributed System
Ø Clock Synchronization- With multiple computers, each having its own
local clock, keeping the clocks in synchrony is a key issue.
Ø Event-Triggered versus Time-Triggered Systems-An event-triggered
real-time system, when a significant event in the outside world happens, it
is detected by some sensor, which then causes the attached CPU to get an
interrupt. Event-triggered systems are thus interrupt driven. The time-
triggered real-time system, a clock interrupt occurs every ∆T milliseconds.
At each clock tick (selected) sensors are sampled and (certain) actuators are
driven. No interrupts occur other than clock ticks.
Ø Predictability-At design time the system can meet all of its deadlines,
even at peak load.
PDM CSE 114
Page 58
Design Issues of Real Time
Distributed System
Real Time Distributed
System(contd..)
Ø Fault Tolerance-Some real-time systems have the property that they can
be stopped cold when a serious failure occurs. For instance, when a railroad
signaling system unexpectedly blacks out, it may be possible for the control
system to tell every train to stop immediately. If the system design always
spaces trains far enough apart and all trains start braking more-or-less
simultaneously, it will be possible to avert disaster and the system can
recover gradually when the power comes back on. A system that can halt
operation like this without danger is said to be fail-safe.
Ø Language Support-Real-time systems and applications are programmed in
general-purpose languages such as C. The language cannot support general
while loops. Iteration must be done using for loops with constant
parameters. Recursion cannot be tolerated.
PDM CSE 115
Real-time scheduling algorithms
characteristics
• Hard real time versus soft real time- Hard real-time algorithms must
guarantee that all deadlines are met. Soft real time algorithms can live with
a best efforts approach.
• Preemptive versus non-preemptive scheduling- Preemptive scheduling
allows a task to be suspended temporarily when a higher-priority task
arrives, resuming it later when no higher-priority tasks are available to run.
Non preemptive scheduling runs each task to completion. Once a task is
started, it continues to hold its processor until it is done.
• Dynamic versus static-Dynamic algorithms make their scheduling
decisions during execution. In Static algorithms, the scheduling decisions,
whether preemptive or not, are made in advance, before execution.
• Centralized versus decentralized- In centralized, one machine collecting
all the information and making all the decisions, in decentralized, each
processor making its own decisions.
PDM CSE 116
Page 59
Real Time System
PDM CSE 117
• Dynamic Scheduling-An algorithms that decide during program
execution which task to run next.
•Three approaches of dynamic scheduling
ØRate monotonic algorithm- In this each task is assigned a priority equal
to its execution frequency. At run time, the scheduler always selects the
highest priority task to run, preempting the current task if need be.
ØEarliest deadline first- Whenever an event is detected, the scheduler
adds it to the list of waiting tasks. This list is always keep sorted by
deadline, closest deadline first. The scheduler then just chooses the first
task on the list, the one closest to its deadline.
ØLeast Laxity- It computes for each task the amount of time it has to
spare, called the laxity (slack). For a task that must finish in 200 msec but
has another 150 msec to run, the laxity is 50 msec. This algorithm, called
least laxity, chooses the task with the least laxity, that is, the one with the
least breathing room.
Real Time System (contd..)
• Static Scheduling- Static scheduling is done before the system starts
operating. The input consists of a list of all the tasks and the times that each
must run. The goal is to find an assignment of tasks to processors and for
each processor, a static schedule giving the order in which the tasks are to
be run.
PDM CSE
118
Page 60
Distributed File system(DFS)
Design
• Distributed File System Design has two parts:
Ø File service Interface(operations on files - read, write, append)
Ø Directory service Interface (mkdir, rmdir, file creation and deletion)
• The File Service Interface
Ø File Properties
Ø File Service model
§ File Properties
• Byte sequence vs. data structure- A file can be structured as a sequence
of records. The operating system either maintains the file as a B-tree or
other suitable data structure, or uses hash tables to locate records quickly.
• Attributes (owner, creation/modified date, size, permissions)- A files
can have attributes, which are pieces of information about the file Typical
attributes are the owner, size, creation date, and access permissions.
PDM CSE 119
Distributed File system Design
(contd..)
PDM CSE 120
• Immutable vs. mutable files-Once a file has been created, it cannot be
changed. Such a file is said to be immutable. Having files be immutable
makes it much easier to support file caching and replication because it
eliminates all the problems associated with having to update all copies of a
file whenever it changes.
• Protection via Capabilities vs. Protection via Access Control Lists-
Protection in distributed systems uses : capabilities and access control lists.
With capabilities, each user has a kind of ticket, called a capability for each
object to which it has access. The capability specifies which kinds of accesses
are permitted (e.g., reading is allowed but writing is not). All access control
list schemes associate with each file a list of users who may access the file
and how. The UNIX scheme, with bits for controlling reading, writing, and
executing each file separately for the owner, the owner's group, and everyone
else is a simplified access control list.
Page 61
File Service Model in DFS
§ The File Service Model
• (a) Upload/download model- In the upload/download model, the file
service provides only two major operations: read file and write file. The
read file operation transfers an entire file from one of the file servers to the
requesting client. The write file operation transfers an entire file the other
way, from client to server
• Advantage
Ø Simple
• Problems
Ø Wasteful: what if client needs small piece?
Ø Problematic: what if client doesn’t have enough space?
Ø Consistency: what if others need to modify the same file?
PDM CSE 121
File Service Model in DFS
(contd..)
(b) Remote access model- In this model, the file service provides a large
number of operations for opening and closing files, reading and writing
parts of files, moving around within files, examining and changing file
attributes, and so on.
• Advantages:
Ø Client gets only what’s needed
Ø Server can manage coherent view of file system
• Problem:
Ø Possible server and network congestion
Ø Servers are accessed for duration of file access
Ø Same data may be requested repeatedly
PDM CSE 122
Page 62
File Service Model (contd..)
PDM CSE 123
a) The remote access model.
b) The upload/download model
Directory Server Interface in DFS
Design
• The Directory Server Interface
(a) A directory tree contained on one machine.
(b) A directory graph on two machines.
PDM CSE 124
Page 63
Directory Server Interface in DFS
Design (contd..)
• Defines how user-attributed file names can be composed
• Naming Transparency
Ø Location Transparency
– No clue as to where server is located
Ø Location Independence
– Files can be moved without changing their names
• Two-Level Naming
Ø Symbolic Names vs. Binary Names
Ø Symbolic Links
PDM CSE 125
Directory Server Interface in DFS
Design (contd..)
Ø UNIX semantics -Every operation on a file is instantly visible to all
processes Read returns result of last write
• Easily achieved if Only one server & Clients do not cache data but
Performance problems if no cache
Ø Session semantics- No changes are visible to other processes until the file
is closed. Changes to an open file are initially visible only to the process (or
machine) that modified it.
Ø Immutable files -No updates are possible, simplifies sharing and
replication .It does not help with detecting modification
Ø Transactions -All changes have the all-or-nothing property. Each file
access is an atomic transaction
PDM CSE 126
• Semantics of File Sharing
Page 64
DFS Implementation
• File usage
• System Structure
• Caching
• Replication
• Update Protocols
• Sun's Network File System
§ File usage
Ø Most files are <10 Kbytes
Ø Feasible to transfer entire files (simpler)
Ø Still have to support long files
Ø Most files have short lifetimes( keep them local)
Ø Few files are shared
PDM CSE 127
System Structure in DFS
Implementation
§ System structure
• Stateful Server
Ø Server maintains client-specific state
Ø Shorter requests
Ø Better performance in processing requests
Ø Cache coherence is possible
Ø Server can know who’s accessing what
Ø File locking is possible
PDM CSE 128
Page 65
System Structure in DFS
Implementation(contd..)
§ Stateless
Ø Server maintain no information on client accesses
Ø Each request must identify file and offsets
Ø Server can crash and recover (No state to lose)
Ø Client can crash and recover (No open/close needed)
Ø No server space used for state
Ø No limits on number of open files
Ø No problems if a client crashes
PDM CSE 129
Caching in DFS
Implementation
§ Caching
Ø Caching Location- It refers to the place where the cached data is stored.
Whether it is server’s main memory or client disk or client’s main memory.
Four different places of cache location
• Server’s disk
• Server’s buffer cache
• Client’s buffer cache
• Client’s disk
• Approaches to caching
o Write-through-What if another client reads its own (out-of-date) cached
copy? All accesses will require checking with server, server maintains state
and sends invalidations
PDM CSE 130
Page 66
Caching in DFS Implementation
o Delayed writes (write-behind)-Data can be buffered locally. Remote files
updated periodically. One bulk write is more efficient than lots of little
writes.
o Write on close-Matches session semantics.
o Centralized control- Keep track of who has what open and cached on each
node. Stateful file system with signaling traffic.
PDM CSE 131
Replication in DFS Implementation
• Replication Transparency-multiple copies of selected files are
maintained, with each copy on a separate file server. The reasons for
offering such a service are:
Ø To increase reliability by having independent backups of each file. If one
server goes down, or is even lost permanently, no data are lost. For many
applications, this property is extremely desirable.
Ø To allow file access to occur even if one file server is down. The motto
here is: The show must go on. A server crash should not bring the entire
system down until the server can be rebooted.
Ø To split the workload over multiple servers. As the system grows in size,
having all the files on one server can become a performance bottleneck. By
having files replicated on two or more servers, the least heavily loaded one
can be used.
PDM CSE 132
Page 67
Replication in DFS Implementation
(contd..)
• Three ways of replication
Ø Explicit File Replication-In this approach programmer control the entire
process. When a process makes a file, it does so on one specific server.
Then it can make additional copies on other servers, if desired. If the
directory server permits multiple copies of a file, the network addresses of
all copies can then be associated with the file name, so that when the name
is looked up, all copies will be found.
Ø Lazy replication- In this approach only one copy of each file is created, on
some server. Later, the server itself makes replicas on other servers
automatically, without the programmer's knowledge.
Ø Group communication- In this all write system calls are simultaneously
transmitted to all the servers, so extra copies are made at the same time the
original is made.
PDM CSE 133
Replication in DFS Implementation
(contd..)
(a) Explicit file replication. (b) Lazy file replication. (c) File replication using a
group.
• Two important issues related to replication transparency-Naming of
Replicas & replication control
PDM CSE 134
Page 68
Update Protocols in DFS
Implementation
• Update Protocols-the problem of how replicated files can be modified.
Various algorithms are used like:
Ø Primary copy replication-When it is used, one server is designated as the
primary. All the others are secondary's. When a replicated file is to be
updated, the change is sent to the primary server, which makes the change
locally and then sends commands to the secondary's, ordering them to
change, too. Reads can be done from any copy, primary or secondary.
Ø Voting-The basic idea is to require clients to request and acquire the
permission of multiple servers before either reading or writing a replicated
file. A file is replicated on N servers & to update a file, a client must first
contact at least half the servers plus 1 (a majority) and get them to agree to
do the update. Once they have agreed, the file is changed and a new version
number is associated with the new file. The version number is used to
identify the version of the file and is the same for all the newly updated
files.
PDM CSE 135
Network File System in DFS
Implementation
• NFS Architecture-NFS is to allow an arbitrary collection of clients and
servers to share a common file system.
• NFS Protocols-A protocol is a set of requests sent by clients to servers,
along with the corresponding replies sent by the servers back to the clients.
Ø NFS protocol handles mounting.
Ø NFS method makes it difficult to achieve the exact UNIX file semantics.
NFS needs a separate, additional mechanism to handle locking.
Ø NFS uses the UNIX protection mechanism, with the rwx bits for the owner,
group, and others.
Ø All the keys used for the authentication, as well as other information are
maintained by the NIS (Network Information Service). The NIS was
formerly known as the yellow pages. Its function is to store (key, value)
pairs. when a key is provided, it returns the corresponding value.
PDM CSE 136
Page 69
Trends in Distributed File System
• WORM (Write Once Read Many)-It is a data storage device where
information once written cannot be modified. It permits unlimited reading
of data once written. It is useful in archiving information when users want
the security of knowing it has not been modified since the initial write.
• Scalability- Algorithms that work well for systems with 100 machines may
also work well for systems with 1000 machines. Partition the system into
smaller units and try to make each one relatively independent of the others.
Having one server per unit scales much better than a single server.
• Fault tolerance -Distributed systems will need considerable redundancy in
hardware, communication infrastructure, in software and especially in data.
Systems will also have to be designed that manage to function when only
partial data are available, since insisting that all the data be available all the
time does not lead to fault tolerance.
PDM CSE 137
Trends in Distributed File System
(contd.)
• Multimedia-New applications, especially those involving real-time video
or multimedia will have a large impact on future distributed file systems.
Text files are rarely more than a few megabytes long, but video files can
easily exceed a gigabyte. To handle applications such as video-on-demand,
completely different file systems will be needed.
• Distributed Shared Memory-For communication in multiprocessors, one
process just writes data to memory, to be read by all the others. For
synchronization, critical regions can be used, with semaphores or monitors
providing the necessary mutual exclusion. Communication generally has to
use message passing, making input/output the central abstraction.
PDM CSE 138
Page 70
Section-D
PDM CSE 139
Section -D
• Shared Memory
• Consistency Models
• Page based distributed shared memory
• Shared variables distributed shared memory
• Introduction to MACH
• Process Management in MACH
• Communication in MACH
• UNIX Emulation in MACH
PDM CSE 140
Page 71
Shared Memory
• On-Chip Memory-Some computers have an external memory, self-
contained chips containing a CPU and all the memory also exist. Such
chips are used in cars, appliances, and even toys. In this, the CPU portion
of the chip has address and data lines that directly connect to the memory
portion.
(a)A single-chip computer(b)A hypothetical shared-memory multiprocessor.
PDM CSE 141
Bus based Multiprocessors in
Shared Memory
• Bus-Based Multiprocessors-A collection of parallel wires, holding the
address the CPU is called a bus. A system with three CPUs and a memory
shared among all of them. When any of the CPUs wants to read a word
from the memory, it puts the address of the word it wants on the bus and
asserts (puts a signal on) a bus control line indicating that it wants to do a
read. When the memory has fetched the requested word, it puts the word on
the bus and asserts another control line to announce that it is ready. The
CPU then reads in the word. Writes work in an analogous way.
• (a) A multiprocessor. (b) A multiprocessor with caching.
PDM CSE 142
Page 72
Bus based Multiprocessors in
Shared Memory (contd..)
• Write through Protocol- When a CPU first reads a word from memory,
that word is fetched over the bus and is stored in the cache of the CPU
making the request.
• write-through cache consistency protocol
Ø Read miss Fetch data from memory & store in cache
Ø Read hit Fetch data from local cache
Ø Write miss update data in memory & store in cache
Ø Write hit update memory & cache
• cache consistency protocol has three important properties:
Ø Consistency is achieved by having all the caches do bus snooping.
Ø The protocol is built into the memory management unit.
Ø The entire algorithm is performed in well under a memory cycle.
PDM CSE 143
Ring based Multiprocessors in
Shared Memory
• Ring-Based Multiprocessors- Memnet is a ring-based multiprocessors,
In Memnet, a single address space is divided into a private part and a
shared part. The private part is divided up into regions so that each machine
has a piece for its stacks and other unshared data and code. The shared part
is common to all machines The machines in a ring-based multiprocessor
can be much more loosely coupled
• All the machines in Memnet are connected together in a modified token-
passing ring. The ring consists of 20 parallel wires, which together allow
16 data bits and 4 control bits to be sent every 100 nsec, for a data rate of
160 Mbps.
PDM CSE 144
Page 73
Ring based Multiprocessors in
Shared Memory (contd..)
• (a) The Memnet ring. (b) A single machine. (c) The block table.
PDM CSE 145
Switched Multiprocessors in
Shared Memory (contd..)
• Switched Multiprocessors-Build the system as multiple clusters and
connect the clusters using an inter cluster bus. As long as most CPUs
communicate primarily within their own cluster, there will be relatively
little inter cluster traffic. If one inter cluster bus proves to be inadequate,
add a second inter cluster bus, or arrange the clusters in a tree or grid. If
still more bandwidth is needed, collect a bus, tree, or grid of clusters
together into a super-cluster, and break the system into multiple super
clusters. The super clusters can be connected by a bus, tree, or grid shows a
system with three levels of buses.
PDM CSE 146
Page 74
Switched Multiprocessors in
Shared Memory (contd..)
• (a) Three clusters connected by an inter cluster bus to form one super
cluster. (b) Two super clusters connected by a super cluster bus.
PDM CSE 147
Shared Memory (contd..)
• Directories-Each cluster has a directory that keeps track of which clusters
currently have copies of its blocks. Since each cluster owns 1M memory
blocks, it has 1M entries in its directory, one per block. Each entry holds a
bit map with one bit per cluster telling whether or not that cluster has the
block currently cached. The entry also has a 2-bit field telling the state of
the block.
• Caching-Caching is done on two levels: a first-level cache and a larger
second-level cache. Each cache block can be in one of the following three
states:
Ø UNCACHED — the only copy of the block is in this memory.
Ø CLEAN — Memory is up-to-date; the block may be in several caches.
Ø DIRTY — Memory is incorrect; only one cache holds the block.
PDM CSE 148
Page 75
NUMA Multiprocessor in Shared
Memory (contd..)
• NUMA(Non Uniform Memory Access) multiprocessor- A NUMA
machine has a single virtual address space that is visible to all CPUs. On a
NUMA machine, access to a remote memory is much slower than access to
a local memory. The ratio of a remote access to a local access is typically
10:1.
• Properties of NUMA Multiprocessors-NUMA machines have three key
properties that are of concern to us:
Ø Access to remote memory is possible.
Ø Accessing remote memory is slower than accessing local memory.
Ø Remote access times are not hidden by caching.
PDM CSE 149
Spectrum of shared memory
machines
Spectrum of shared memory machines
PDM CSE 150
Page 76
Consistency Models
• Consistency model - a contract between the software and the memory.
Types of Consistency Models
Ø Strict Consistency -Any read to a memory location x returns the value
stored by the most recent write operation to x.
Ø Sequential Consistency-The result of any execution is the same as if the
operations of all processors were executed in some sequential order, and
the operations of each individual processor appear in this sequence in the
order specified by its program.
Ø Causal Consistency-The causal consistency model represents a weakening
of sequential consistency in that it makes a distinction between events that
are potentially causally related and those that are not.
PDM CSE 151
Consistency Models (contd.)
Ø PRAM Consistency and Processor Consistency-PRAM consistency
(Pipelined RAM), which means: Writes done by a single process are
received by all other processes in the order in which they were issued, but
writes from different processes may be seen in a different order by different
processes.
Ø Release Consistency-Release consistency provides these two kinds.
Acquire accesses are used to tell the memory system that a critical region
is about to be entered. Release accesses say that a critical region has just
been exited.
Ø Entry consistency requires the programmer (or compiler) to use acquire
and release at the start and end of each critical section, respectively.
PDM CSE 152
Page 77
Page based distributed shared
memory
• Basic design
• Replication
• Granularity
• Finding the owner
• Finding the copies
• Page replacement
• Synchronization
PDM CSE 153
Page Based Distributed
Shared Memory (contd..)
• Basic Design-Distributed Shared Memory emulate the cache of a
multiprocessor using the MMU and operating system software. In a DSM
system, the address space is divided up into chunks, with the chunks being
spread over all the processors in the system. When a processor references
an address that is not local, a trap occurs, and the DSM software fetches the
chunk containing the address and restarts the faulting instruction, which
now completes successfully.
• Replication-To replicate chunks that are read only, for example, program
text, read only constants, or other read-only data structures.
PDM CSE 154
Page 78
(a) Chunks of address space distributed among
four machines.
(b) Situation after CPU 1 references chunk 10.
(c) Situation if chunk 10 is read only and replication is used.
PDM CSE 155
Page Based Distributed
Shared Memory (contd.)
• Granularity-Granularity means how big should the chunk be? Possibilities
are the word, block (a few words), page, or segment (multiple pages).
• It effective page size is too large it introduces a new problem, called false
sharing, it is defined as a page containing two unrelated shared variables,
A and B. Processor 1 makes heavy use of A, reading and writing it.
Similarly, process 2 uses B. Under these circumstances, the page containing
both variables will constantly be traveling back and forth between the two
machines.
False sharing of a page containing two unrelated variables.
PDM CSE 156
Page 79
False Sharing (contd..)
• The problem of false sharing is that although the variables are unrelated,
since they appear by accident on the same page, when a process uses one of
them, it also gets the other. The larger the effective page size, the more
often false sharing will occur, and conversely, the smaller the effective
page size, the less often it will occur.
• Clever compilers that understand the problem and place variables in the
address space accordingly can help reduce false sharing and improve
performance.
PDM CSE 157
Page Based Distributed
Shared Memory (contd..)
• Finding the owner- how to find the owner of the page.
Ø First solution is by doing a broadcast, asking for the owner of the specified
page to respond.
Ø Second solution is that, one process is designated as the page manager. It is
the job of the manager to keep track of who owns each page. When a
process, P, wants to read a page it does not have or wants to write a page it
does not own, it sends a message to the page manager telling which
operation it wants to perform and on which page. The manager then sends
back a message telling who the owner is. P now contacts the owner to get
the page and/or the ownership, as required.
Ø Two approaches to find ownership location using four message protocol &
using three message protocol
PDM CSE 158
Page 80
Page Based Distributed
Shared Memory (contd..)
(a) Four-message protocol. (b) Three-message protocol.
Ø Here the page manager forwards the request directly to the owner, which
then replies directly back to P, saving one message. A problem with this
protocol is the potentially heavy load on the page manager, handling all the
incoming requests.
PDM CSE 159
Page Based Distributed
Shared Memory (contd.)
• Finding the Copies-The detail of how all the copies are found when they
must be invalidated. Two possibilities present. one is to broadcast a
message giving the page number and ask all processors holding the page to
invalidate it. This approach works only if broadcast messages are totally
reliable and can never be lost. Second possibility is to have the owner or
page manager maintain a list or copyset telling which processors hold
which pages, here page 4, for example, is owned by a process on CPU 1.
• When a page must be invalidated, the old owner, new owner, or page
manager sends a message to each processor holding the page and waits for
an acknowledgement. When each message has been acknowledged, the
invalidation is complete.
PDM CSE 160
Page 81
Page Based Distributed
Shared Memory (contd..)
• Page Replacement-In a DSM system, it can happen that a page is needed
but that there is no free page frame in memory to hold it. When this
situation occurs, a page must be evicted from memory to make room for the
needed page. Two sub problems immediately arise: which page to evict and
where to put it.
• Different approaches are there-
Ø Use least recently used (LRU) algorithm.
Ø a replicated page that another process owns is always a prime candidate to
evict because it is known that another copy exists.
Ø If no replicated pages are suitable candidates, a non replicated page must be
chosen, two possibilities for non replicated pages
§ First is to write it to a disk, if present.
§ The other is to hand it off to another processor.
PDM CSE 161
Page Based Distributed
Shared Memory (contd..)
• Synchronization-In a DSM system, processes often need to synchronize
their actions. E.g. mutual exclusion, in which only one process at a time
may execute a certain part of the code. In a multiprocessor, the TEST-
AND-SET-LOCK (TSL) instruction is often used to implement mutual
exclusion. A variable is set to 0 when no process is in the critical section
and to 1 when one process is.
• If one process, A, is inside the critical region and another process, B, (on a
different machine) wants to enter it, B will sit in a tight loop testing the
variable, waiting for it to go to zero. Use synchronization manager (or
managers) that accept messages asking to enter and leave critical regions,
lock and unlock variables, and so on, sending back replies when the work is
done. When a region cannot be entered or a variable cannot be locked, no
reply is sent back immediately, causing the sender to block. When the
region becomes available or the variable can be locked, a message is sent
back.
PDM CSE 162
Page 82
Shared variable Distributed
Shared Memory
• Munin- Munin is a DSM system that is fundamentally based on software
objects. The goal of the Munin project is to take existing multiprocessor
programs, make minor changes to them, and have them run efficiently on
multicomputer systems using a form of DSM. Synchronization for mutual
exclusion is handled in a special way. Lock variables may be declared, and
library procedures are provided for locking and unlocking them. Barriers,
condition variables, and other synchronization variables are also supported.
• Release Consistency-Writes to shared variables must occur inside critical
regions; reads can occur inside or outside. While a process is active inside a
critical region, the system gives no guarantees about the consistency of
shared variables, but when a critical region is exited, the shared variables
modified since the last release are brought up to date on all machines.
PDM CSE 163
Shared variable Distributed
Shared Memory (contd..)
• Operation of Munin's release consistency- Three cooperating processes,
each running on a different machine. At a certain moment, process 1 wants
to enter a critical region of code protected by the lock L (all critical regions
must be protected by some synchronization variable). The lock statement
makes sure that no other well-behaved process is currently executing this
critical region. Then the three shared variables, a, b, and c, are accessed
using normal machine instructions. Finally, unlock is called and the results
are propagated to all other machines which maintain copies of a, b, or c.
These changes are packed into a minimal number of messages.
PDM CSE 164
Page 83
Shared variable Distributed
Shared Memory
• Multiple Protocols-Munin also uses other techniques for improving
performance. Declaration of shared variable by one of four categories:
Ø Read-only- Read-only variables are easiest. When a reference to a read-
only variable causes a page fault, Munin looks up the variable in the
variable directory, finds out who owns it, and asks the owner for a copy of
the required page.
Ø Migratory-Migratory shared variables use the acquire/release protocol.
They are used inside critical regions and must be protected by
synchronization variables. The idea is that these variables migrate from
machine to machine as critical regions are entered and exited.
Ø Write-shared-A write-shared variable is used when the programmer has
indicated that it is safe for two or more processes to write on it at the same
time, for example, an array in which different processes can concurrently
access different sub arrays.
PDM CSE 165
Shared variable Distributed
Shared Memory (contd..)
• Directories-Munin uses directories to locate pages containing shared
variables. When a fault occurs on a reference to a shared variable, Munin
hashes the virtual address that caused the fault to find the variable's entry in
the shared variable directory.
• Synchronization-Munin maintains a second directory for synchronization
variables. When a process wants to acquire a lock, it first checks to see if it
owns the lock itself. If it does and the lock is free, the request is granted. If
the lock is not local, it is located using the synchronization directory, which
keeps track of the probable owner. If the lock is free, it is granted. If it is
not free, the requester is added to the tail of the queue.
PDM CSE 166
Page 84
Shared variable Distributed
Shared Memory
• Midway-Midway is a distributed shared memory system that is based on
sharing individual data structures. Its goal was to allow existing and new
multiprocessor programs to run efficiently on multi computers with only
small changes to the code. Midway programs use the Mach C-threads
package for expressing parallelism.
• Entry Consistency-Consistency is maintained by requiring all accesses to
shared variables and data structures to be done inside a specific kind of
critical section known to the Midway runtime system. To make the entry
consistency work, three characteristics that multiprocessor programs do not
have:
Ø Shared variables must be declared using the new keyword shared.
Ø Each shared variable must be associated with a lock or barrier.
Ø Shared variables may only be accessed inside critical sections.
PDM CSE 167
Introduction to MACH
§ Goals of Mach
§ The Mach Microkernel
§ The Mach BSD UNIX Server
• Goals of Mach
Ø Providing a base for building other operating systems
Ø Supporting large sparse address spaces.
Ø Allowing transparent access to network resources.
Ø Exploiting parallelism in both the system and the applications.
Ø Making Mach portable to a larger collection of machines.
• The Mach Microkernel-The kernel manages five principal abstractions:
Ø Processes -A process is basically an environment in which execution can
take place. It has an address space holding the program text and data, and
usually one or more stacks. The process is the basic unit for resource
allocation.
PDM CSE 168
Page 85
Introduction to MACH
(Contd.)
Ø Threads-A thread in Mach is an executable entity. It has a program counter
and a set of registers associated with it. Each thread is part of exactly one
process.
Ø Memory objects-Memory object, is a data structure that can be mapped
into a process address space. Memory objects occupy one or more pages
and form the basis of the Mach virtual memory system. When a process
attempts to reference a memory object that is not presently in physical main
memory, it gets a page fault. As in all operating systems, the kernel catches
the page fault.
Ø Ports-Inter process communication in Mach is based on message passing.
To receive messages, a user process asks the kernel to create a kind of
protected mailbox, called a port, for it. The port is stored inside the kernel,
and has the ability to queue an ordered list of messages.
PDM CSE 169
Introduction to MACH
(contd.)
Ø Messages-A process can give the ability to send to (or receive from) one of
its ports to another process. This permission takes the form of a capability,
and includes not only a pointer to the port, but also a list of rights that the
other process has with respect to the port (e.g., SEND right). Once this
permission has been granted, the other process can send messages to the
port, which the first process can then read.
The abstract model for UNIX emulation using Mach.
PDM CSE 170
Page 86
The Mach BSD UNIX Server
• The Mach BSD UNIX Server-The Mach BSD UNIX server has a number
of advantages over a monolithic kernel.
Ø First, by breaking the system up into a part that handles the resource
management and a part that handles the system calls, both pieces become
simpler and easier to maintain.
Ø Second, by putting UNIX in user space, it can be made extremely machine
independent, enhancing its portability to a wide variety of computers.
Ø Third, multiple operating systems can run simultaneously. On a 386, for
example, Mach can run a UNIX program and an MS-DOS program at the
same time.
Ø Fourth, real-time operation can be added to the system
Ø Finally, this arrangement can be used to provide better security between
processes, if need be.
PDM CSE 171
Process Management in MACH
Process Management in MACH includes
§ Processes
§ Threads
§ Scheduling
• Processes- A process in Mach is a passive entity. A process in Mach
consists primarily of an address space and a collection of threads that
execute in that address space.
• A Mach process.
PDM CSE 172
Page 87
Process Management in MACH
(contd.)
• A Mach process has some ports and other properties.
Ø Process port is used to communicate with the kernel.
Ø Bootstrap port is used for initialization when a process starts up.
Ø Exception port is used to report exceptions caused by the process. Typical
exceptions are division by zero and illegal instruction executed.
Ø Registered ports are normally used to provide a way for the process to
communicate with standard system servers.
• Process Management Primitives
Ø Create- create a new process, inheriting certain properties
Ø Terminate- kill a specified process
Ø Suspend- increment suspend counter
Ø Resume- decrement suspend counter if it is zero unlock the process
Ø Thread- return a list of Process’s threads
PDM CSE 173
Threads in Process Management in
MACH
• Threads-The active entities in Mach are the threads. They execute
instructions and manipulate their registers and address spaces. Each thread
belongs to exactly one process. All the threads in a process share the
address space and all the process-wide resources. Threads also have private
per-thread resources. Each thread has its own thread port, which it uses to
invoke thread-specific kernel services.
• C threads call for thread management
Ø Fork-Create a new thread running the same code as the parent thread
Ø Exit-Terminate the calling thread
Ø Join-Suspend the caller until a specified thread exits
Ø Detach-Announce that the thread will never be jointed (waited for)
Ø Yield-Give up the CPU voluntarily
Ø Self-Return the calling thread's identity to it
PDM CSE 174
Page 88
Threads in Process Management in
MACH (contd..)
• Implementation of C thread in MACH (a) All C threads use one kernel
thread. (b) Each C thread has its own kernel thread. (c) Each C thread has
its own single-threaded process. (d) Arbitrary mapping of user threads to
kernel threads.
PDM CSE 175
Scheduling in Process Management
in MACH
• Scheduling-Thread scheduling in Mach is based on priorities. Priorities are
integers from 0 to some maximum (usually 31 or 127), with 0 being the
highest priority and 31 or 127 being the lowest priority. This priority
reversal comes from UNIX. Each thread has three priorities assigned to it.
The first priority is a base priority, which the thread can set itself, within
certain limits. The second priority is the lowest numerical value that the
thread may set its base priority to.
• Associated with each processor set is an array of run queues, the array has
32 queues, corresponding to threads currently at priorities 0 through 31.
When a thread at priority n becomes runnable, it is put at the end of queue
n. A thread that is not runnable is not present on any run queue.
PDM CSE 176
Page 89
• Each run queue has three variables attached to it.
Ø Mutex- Make sure that only one CPU at a time is manipulating the queues.
Ø Count- Count the number of threads on all the queues combined.
Ø Hint- Where to find the highest-priority thread.
The global run queues for a system with two processor sets
PDM CSE 177
Communication in MACH
• The goal of communication in Mach is to support a variety of styles of
communication in a reliable and flexible way. It can handle asynchronous
message passing, RPC, byte streams, and other forms as well.
• Communication in MACH includes
§ Ports
§ Message Passing
§ Network Message server
• Ports-The basis of all communication in Mach is a kernel data structure
called a port. A port is essentially a protected mailbox. When a thread in
one process wants to communicate with a thread in another process, the
sending thread writes the message to the port and the receiving thread takes
it out. Ports support unidirectional communication, like pipes in UNIX. A
port that can be used to send a request from a client to a server cannot also
be used to send the reply back from the server to the client. A second port
is needed for the reply. Ports support reliable, sequenced, message streams.
PDM CSE 178
Page 90
Port in MACH Communication
(Contd.)
• A MACH Port
PDM CSE 179
Message passing in MACH
communication
• Message Passing via a Port-Two processes, A and B, each have access to
the same port. A has just sent a message to the port, and B has just read the
message. The header and body of the message are physically copied from A
to the port and later from the port to B.
PDM CSE 180
Page 91
Message passing in MACH
communication(contd..)
• Capabilities- Each process has exactly one capability list. When a thread
asks the kernel to create a port for it, the kernel does so and enters a
capability for it in the capability list for the process to which the thread
belongs. Each capability consists not only of a pointer to a port, but also a
rights field telling what access the holder of the capability has to the port.
Three rights exist: RECEIVE, SEND, and SEND-ONCE.
• Capability List
PDM CSE 181
Message passing in MACH
communication(contd..)
• Message Formats-A message body can be either simple or complex,
controlled by a header bit. A complex message body consists of a sequence
of (descriptor, data field) pairs. Each descriptor tells what is in the data
field immediately following it. A data field is a capability.
• MACH Message Format
PDM CSE 182
Page 92
Network Message Server in MACH
communication
• The Network Message Server- Communication over the network is
handled by user-level servers called network message servers. Every
machine in a Mach distributed system runs a network message server.
• A network message server is a multithreaded process that performs a
variety of functions-
Ø Interfacing with local threads
Ø Forwarding messages over the network
Ø Translating data types from one machine's representation to another's
Ø Managing capabilities in a secure way
Ø Doing remote notification
Ø Providing a simple network-wide name lookup service
Ø Handling authentication of other network message servers
PDM CSE 183
Network Message Server in MACH
communication (contd..)
• Inter machine communication in MACH proceeds in five steps-
Ø First, the client sends a message to the server's proxy port.
Ø Second, the network message server gets this message. Since this message
is strictly local, out-of-line data may be sent to it and copy-on-write works
in the usual way.
Ø Third, the network message server looks up the local port, 4 in this
example, in a table that maps proxy ports onto network ports. Once the
network port is known, the network message server looks up its location in
other tables. It then constructs a network message containing the local
message, plus any out-of-line data and sends it over the LAN to the
network message server on the server's machine. In some cases, traffic
between the network message servers has to be encrypted for security.
When the remote network message server gets the message, it looks up the
network port number contained in it and maps it onto a local port number.
PDM CSE 184
Page 93
Network Message Server in MACH
communication (contd..)
Ø In fourth step, it writes the message to the local port just looked up.
Ø Finally, the server reads the message from the local port and carries out the
request. The reply follows the same path in the reverse direction.
PDM CSE 185
UNIX Emulation in MACH
• Mach has various servers that run on top of it. A program that contains a
large amount of Berkeley UNIX inside itself. This server is the main UNIX
emulator.
• The implementation of UNIX emulation on Mach consists of two pieces-
Ø UNIX server-Contains a large amount of UNIX code, has the routines
corresponding to the UNIX system calls. It is implemented as a collection
of C threads
Ø System call emulation library-It is linked as a region into every process
emulating a UNIX process. This region is inherited from /etc/init by all
UNIX processes when they are forked off.
PDM CSE 186
Page 94
UNIX Emulation in MACH
(contd.)
• Various steps of UNIX emulation in MACH
Ø Trap to the kernel
Ø UNIX emulation library gets control
Ø RPC to the UNIX server
Ø System call performed
Ø Reply returned
Ø Control given back to the user program part of UNIX process
PDM CSE 187
UNIX Emulation in MACH
(contd..)
UNIX emulation in Mach uses the trampoline mechanism.
PDM CSE 188
Page 95
TH
E E
ND
PD
M C
SE
189