85
CUDA L-BFGS and MAP Superresolution Multi-core architectures and programming Oliver Taubmann & Jens Wetzl August 7, 2012

CUDA L-BFGS andMAP SuperresolutionMulti-core architectures and programming
Oliver Taubmann & Jens WetzlAugust 7, 2012

Outline
Two sub-projects:
� Library for unconstrained nonlinear optimization2 uses the L-BFGS method2 works with any differentiable cost function
� Super-resolution of a low quality image series2 employs nonlinear optimizer2 maximum-a-posteriori approach
Both were implemented on the GPU using CUDA.
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 2 / 54

Outline
CUDA L-BFGSAlgorithm & ImplementationOptimizationFramework
MAP SuperresolutionAlgorithm & ImplementationOptimizationEvaluation
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 3 / 54

Outline
CUDA L-BFGSAlgorithm & Implementation
OutlineInterface & CPU ImplementationAnalysis
OptimizationFramework
MAP SuperresolutionAlgorithm & ImplementationOptimizationEvaluation
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 4 / 54

Descent Methods
� Find local minima of a differentiable function� Iterative scheme:
Input: Function f , start point~x
while ‖∇f (~x)‖22 ≥ ε · ‖~x‖2
2 do . Convergence criterion
~z← FINDSEARCHDIRECTION(f ,~x) . Method-specifict← argmin
t≥0f (~x + t ·~z) . Line search
~x←~x + t ·~z . Update current solution
end while
Output: Final solution~x
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 5 / 54
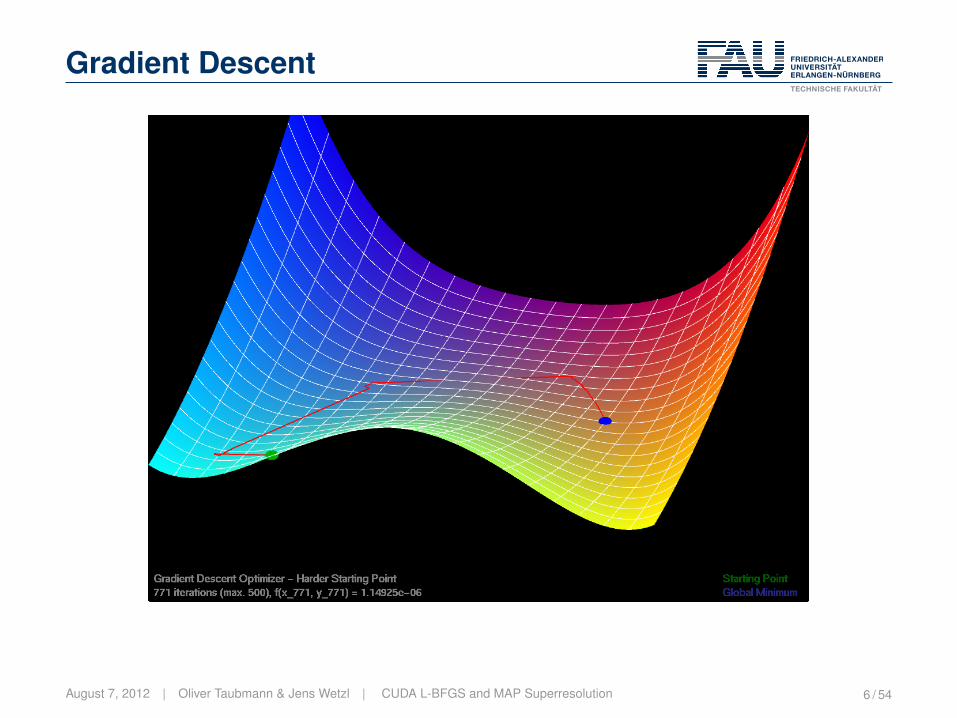
Gradient Descent
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 6 / 54

Quasi-Newton Methods
� Newton: Local, quadratic approximation
function FINDSEARCHDIRECTION(f ,~x)return −H−1
f (~x) · ∇f (~x)end function
Where H−1f is the inverse Hessian of f .
� Quasi-Newton:
2 Don’t compute H−1f directly
2 Estimate it using successive gradient vectors
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 7 / 54

Quasi-Newton Methods
� Newton: Local, quadratic approximation
function FINDSEARCHDIRECTION(f ,~x)return −H−1
f (~x) · ∇f (~x)end function
Where H−1f is the inverse Hessian of f .
� Quasi-Newton:
2 Don’t compute H−1f directly
2 Estimate it using successive gradient vectors
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 7 / 54
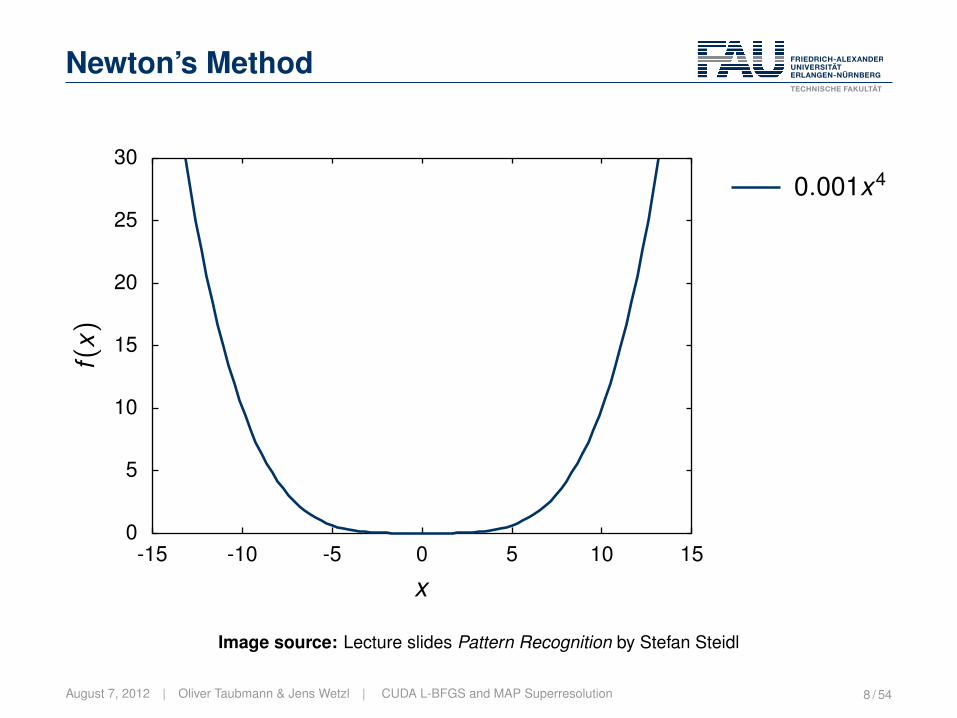
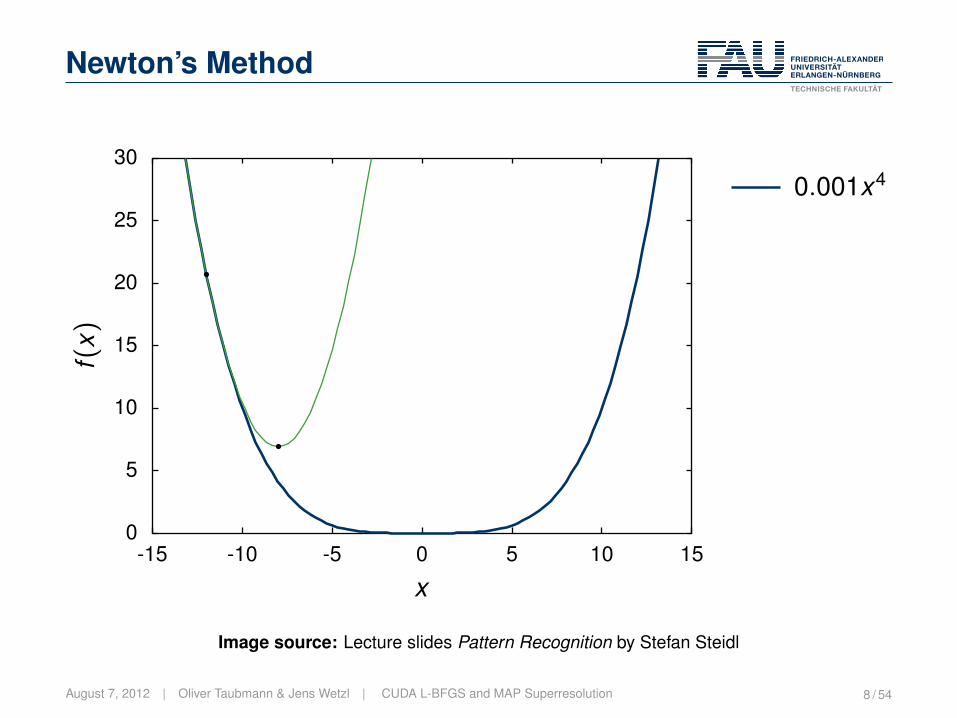
Newton’s Method
Newton’s Method
The idea:• Select a point.• Compute the minimum of the second order Taylor approximation.
x
5
10
15
20
25
30
0
f(x)
-15 -10 -5 15
0.001x4
5 100
Lecture Pattern Recognition | „ 2005-2012 Hornegger, Hahn, Steidl 11-29Image source: Lecture slides Pattern Recognition by Stefan Steidl
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 8 / 54
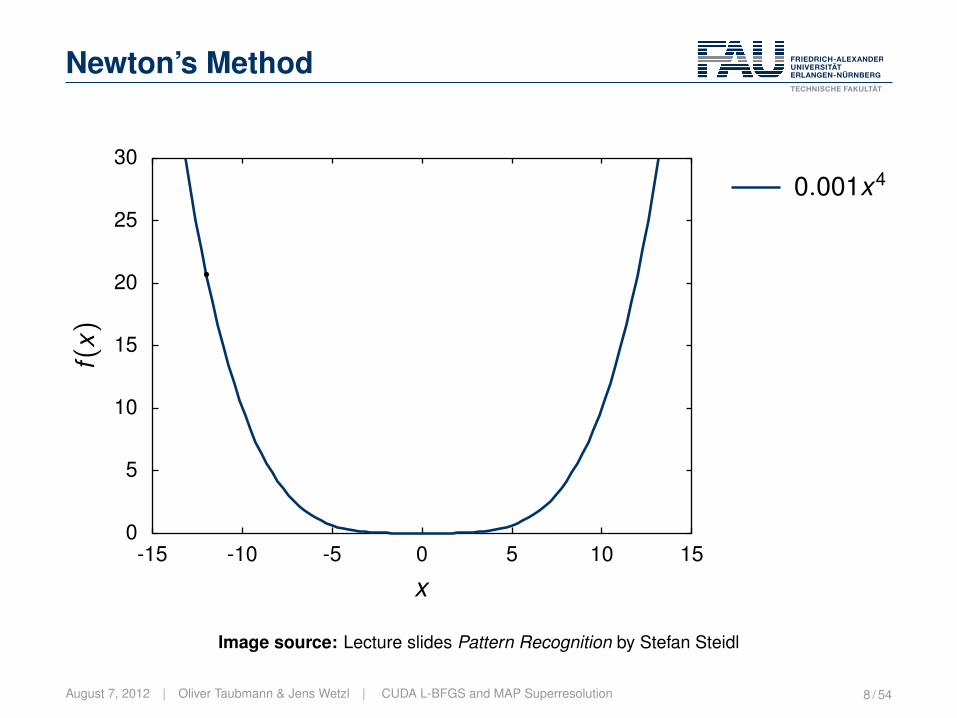
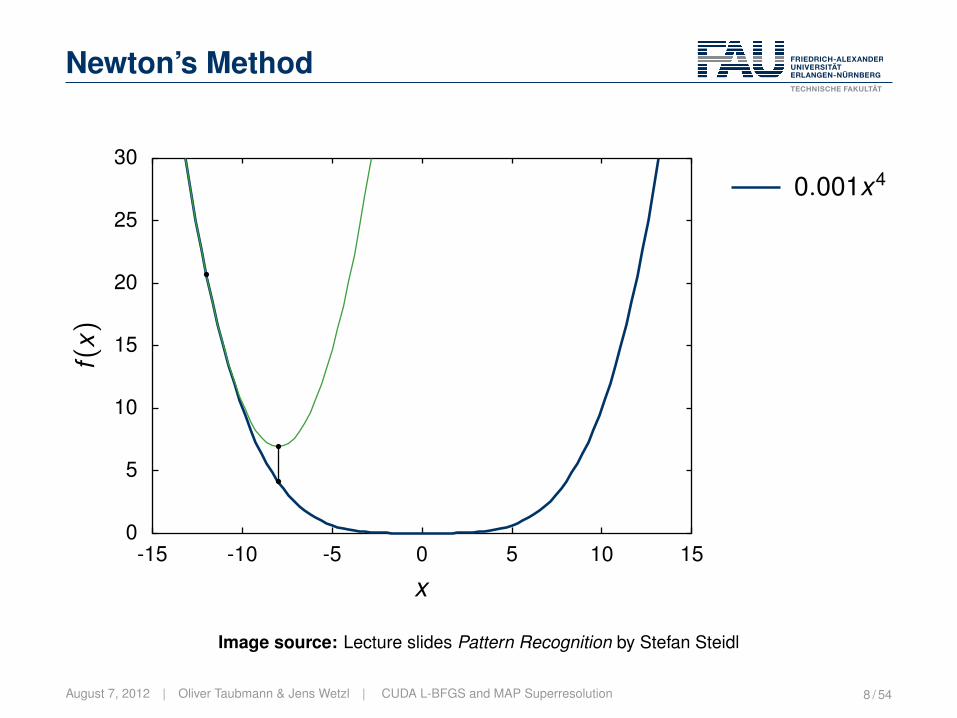
Newton’s Method
Newton’s Method
The idea:• Select a point.• Compute the minimum of the second order Taylor approximation.
x
5
10
15
20
25
30
0
f(x)
-15 -10 -5 15
0.001x4
5 100
Lecture Pattern Recognition | „ 2005-2012 Hornegger, Hahn, Steidl 11-29Image source: Lecture slides Pattern Recognition by Stefan Steidl
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 8 / 54
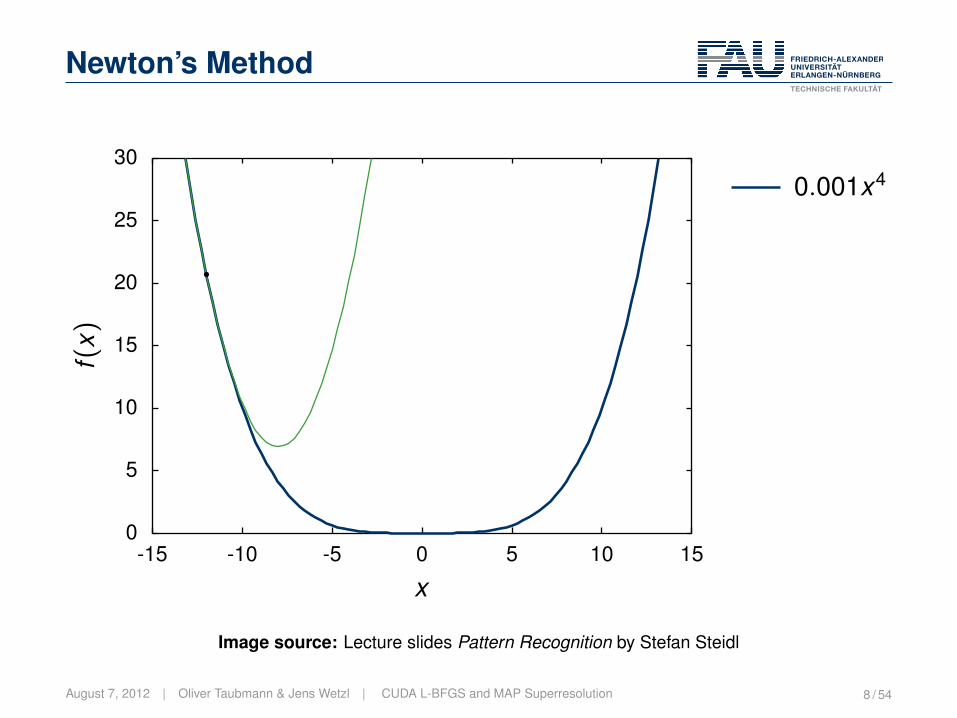
Newton’s Method
Newton’s Method
The idea:• Select a point.• Compute the minimum of the second order Taylor approximation.
x
5
10
15
20
25
30
0
f(x)
-15 -10 -5 15
0.001x4
5 100
Lecture Pattern Recognition | „ 2005-2012 Hornegger, Hahn, Steidl 11-29Image source: Lecture slides Pattern Recognition by Stefan Steidl
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 8 / 54
Newton’s Method
Newton’s Method
The idea:• Select a point.• Compute the minimum of the second order Taylor approximation.
x
5
10
15
20
25
30
0
f(x)
-15 -10 -5 15
0.001x4
5 100
Lecture Pattern Recognition | „ 2005-2012 Hornegger, Hahn, Steidl 11-29Image source: Lecture slides Pattern Recognition by Stefan Steidl
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 8 / 54
Newton’s Method
Newton’s Method
The idea:• Select a point.• Compute the minimum of the second order Taylor approximation.
x
5
10
15
20
25
30
0
f(x)
-15 -10 -5 15
0.001x4
5 100
Lecture Pattern Recognition | „ 2005-2012 Hornegger, Hahn, Steidl 11-29Image source: Lecture slides Pattern Recognition by Stefan Steidl
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 8 / 54
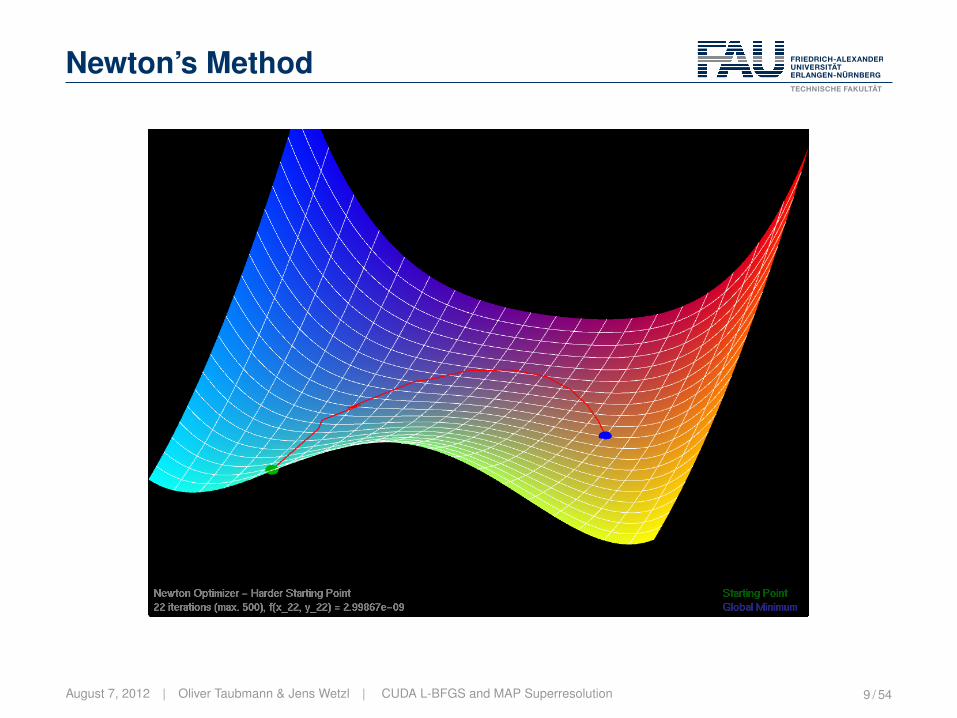
Newton’s Method
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 9 / 54

L-BFGS
� “Limited-memory Broyden-Fletcher-Goldfarb-Shanno”� Keeps a small history, typically 3 ≤ m ≤ 8, of the latest updates:
~sk = ~xk+1−~xk~yk = ∇f (xk+1)−∇f (xk)
� Plus some derived scalar values:
ρk =1
~yTk ·~sk
αk (see next slide)
� Needs an inital (diagonal or scalar) estimate of H−1f
2 With no prior knowledge, a scalar H0 is sufficient2 Initialized to H0 = 1, updated each iteration to H0 =
~yTk ·~sk‖~yk‖2
2
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 10 / 54

L-BFGS
� “Limited-memory Broyden-Fletcher-Goldfarb-Shanno”� Keeps a small history, typically 3 ≤ m ≤ 8, of the latest updates:
~sk = ~xk+1−~xk~yk = ∇f (xk+1)−∇f (xk)
� Plus some derived scalar values:
ρk =1
~yTk ·~sk
αk (see next slide)
� Needs an inital (diagonal or scalar) estimate of H−1f
2 With no prior knowledge, a scalar H0 is sufficient2 Initialized to H0 = 1, updated each iteration to H0 =
~yTk ·~sk‖~yk‖2
2
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 10 / 54

L-BFGS Pseudocode
function FINDSEARCHDIRECTION(f ,~x)~z← ∇f (~x)for i← k− 1, k− 2, . . . , k−m do
αi ← ρi ·~sTi ·~z . Store αi
~z←~z− αi ·~yiend for~z← H0 ·~zfor i← k−m, k−m + 1, . . . , k− 1 do
βi ← ρi ·~yTi ·~z
~z←~z +~si · (αi− βi)end forreturn −~z
end function
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 11 / 54

Interface
Minimizer:
class LBFGS_API lbfgs{public:lbfgs(cost_function& cf);~lbfgs();
status minimize(float *d_x);status minimize_with_host_x(float *h_x);
static std::string statusToString(status stat);
void setMaxIterations (size_t maxIter );void setMaxEvaluations (size_t maxEvals );void setGradientEpsilon(float gradientEps);
[...]
private:[...]
};
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 12 / 54

Interface (cont.)
Cost function:class LBFGS_API cost_function {public:cost_function(size_t numDimensions);virtual ~cost_function();
virtual void f_gradf(const float *d_x, float *d_f, float *d_gradf) = 0;size_t getNumberOfUnknowns() const;[...]
};
CPU cost function:class LBFGS_API cpu_cost_function : public cost_function {public:cpu_cost_function(size_t numDimensions);virtual ~cpu_cost_function();
virtual void cpu_f_gradf(const real *h_x, real *h_f, real *h_gradf) = 0;void f_gradf(const float *d_x, float *d_f, float *d_gradf);[...]
};
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 13 / 54

CPU Implementation
� First: Straight-forward implementation of pseudocode (using Eigen)� Repeatedly refined to mimick reference Fortran code in netlib
2 One big “work-array” for most of the data2 GOTOs everywhere for reverse communication2 → Lots and lots of time spent on comparing and debugging
DO 170 I=1,N170 W(I)=G(I)172 CONTINUE
CALL MCSRCH(N,X,F,G,W(ISPT+POINT*N+1),STP,FTOL,
* XTOL,MAXFEV,INFO,NFEV,DIAG)IF (INFO .EQ. -1) THENIFLAG=1RETURN
ENDIFIF (INFO .NE. 1) GO TO 190
� Finally ended up with an algorithmically “streamlined” implementation2 Store only as much as needed2 Minimize redundant computations
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 14 / 54

CPU Implementation
� First: Straight-forward implementation of pseudocode (using Eigen)� Repeatedly refined to mimick reference Fortran code in netlib
2 One big “work-array” for most of the data2 GOTOs everywhere for reverse communication2 → Lots and lots of time spent on comparing and debugging
DO 170 I=1,N170 W(I)=G(I)172 CONTINUE
CALL MCSRCH(N,X,F,G,W(ISPT+POINT*N+1),STP,FTOL,
* XTOL,MAXFEV,INFO,NFEV,DIAG)IF (INFO .EQ. -1) THENIFLAG=1RETURN
ENDIFIF (INFO .NE. 1) GO TO 190
� Finally ended up with an algorithmically “streamlined” implementation2 Store only as much as needed2 Minimize redundant computations
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 14 / 54

Analysis
function FINDSEARCHDIRECTION(f ,~x)~z← ∇f (~x)for i← k− 1, k− 2, . . . , k−m do
αi ← ρi ·~sTi ·~z . dot
~z←~z− αi ·~yi . axpyend for~z← H0 ·~z . scalefor i← k−m, k−m + 1, . . . , k− 1 do
βi ← ρi ·~yTi ·~z . dot
~z←~z +~si · (αi− βi) . axpyend forreturn −~z
end function
� 3 vector operation types that can be parallelized� Otherwise highly sequential (note read/write pattern of~z)� Dot products require global communication!
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 15 / 54

Analysis
What’s left?
� Line search: For each step length tried, we have2 1 axpy for backtracking2 1 function/gradient evaluation for checking conditions2 Arbitrarily complex scalar computations
� History updates:2 Solution difference: 1 scale (~xk−~xk−1 = t ·~z)2 Gradient difference: 1 axpy (∇f (~xk)−∇f (~xk−1))2 2 more dots for ρk =
1~yT
k ·~skand
H0 =~yT
k ·~sk
‖~yk‖22=
ρ−1k
~yTk ·~yk
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 16 / 54

Outline
CUDA L-BFGSAlgorithm & ImplementationOptimization
Naïve ApproachUsing cuBLASScalar Operations on the GPUAlgorithmic Optimization
Framework
MAP SuperresolutionAlgorithm & ImplementationOptimizationEvaluation
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 17 / 54

Naïve Approach
The obvious things to do:
� . . . after replacing all convenient abstractions provided by Eigen. . .� Keep all vectors in device memory – no copying of large chunks� Implement simple kernels for dot, scale and axpy
2 One element per thread for everything2 Two stage atomic additions for dot (first shared, then global)
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 18 / 54

Naïve Approach
The obvious things to do:
� . . . after replacing all convenient abstractions provided by Eigen. . .� Keep all vectors in device memory – no copying of large chunks� Implement simple kernels for dot, scale and axpy
2 One element per thread for everything2 Two stage atomic additions for dot (first shared, then global)
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 18 / 54

Using cuBLAS
� These functions are also offered by cuBLAS, so why not use them?� cuBLAS is a CUDA port of BLAS (Basic Linear Algebra Subprograms)� BLAS is highly optimized and widely used in HPC
� Example code for dispatching according to chosen implementation:
void lbfgs::dispatch_dot([...]) const{#if defined(LBFGS_IMPLEMENTATION_NAIVE)
[...]gpu_lbfgs::dot<<<gridDim, blockDim>>>(d_x, d_y, n, d_res);[...]
#elif defined(LBFGS_IMPLEMENTATION_CUBLAS)const cublasPointerMode_t mode = dstDevicePointer
? CUBLAS_POINTER_MODE_DEVICE: CUBLAS_POINTER_MODE_HOST;
CublasSafeCall(cublasSetPointerMode(m_cublasHandle, mode));CublasSafeCall(cublasSdot(m_cublasHandle, n, d_x, 1, d_y, 1, dst));
#endif}
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 19 / 54

Using cuBLAS
� These functions are also offered by cuBLAS, so why not use them?� cuBLAS is a CUDA port of BLAS (Basic Linear Algebra Subprograms)� BLAS is highly optimized and widely used in HPC
� Example code for dispatching according to chosen implementation:
void lbfgs::dispatch_dot([...]) const{#if defined(LBFGS_IMPLEMENTATION_NAIVE)
[...]gpu_lbfgs::dot<<<gridDim, blockDim>>>(d_x, d_y, n, d_res);[...]
#elif defined(LBFGS_IMPLEMENTATION_CUBLAS)const cublasPointerMode_t mode = dstDevicePointer
? CUBLAS_POINTER_MODE_DEVICE: CUBLAS_POINTER_MODE_HOST;
CublasSafeCall(cublasSetPointerMode(m_cublasHandle, mode));CublasSafeCall(cublasSdot(m_cublasHandle, n, d_x, 1, d_y, 1, dst));
#endif}
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 19 / 54
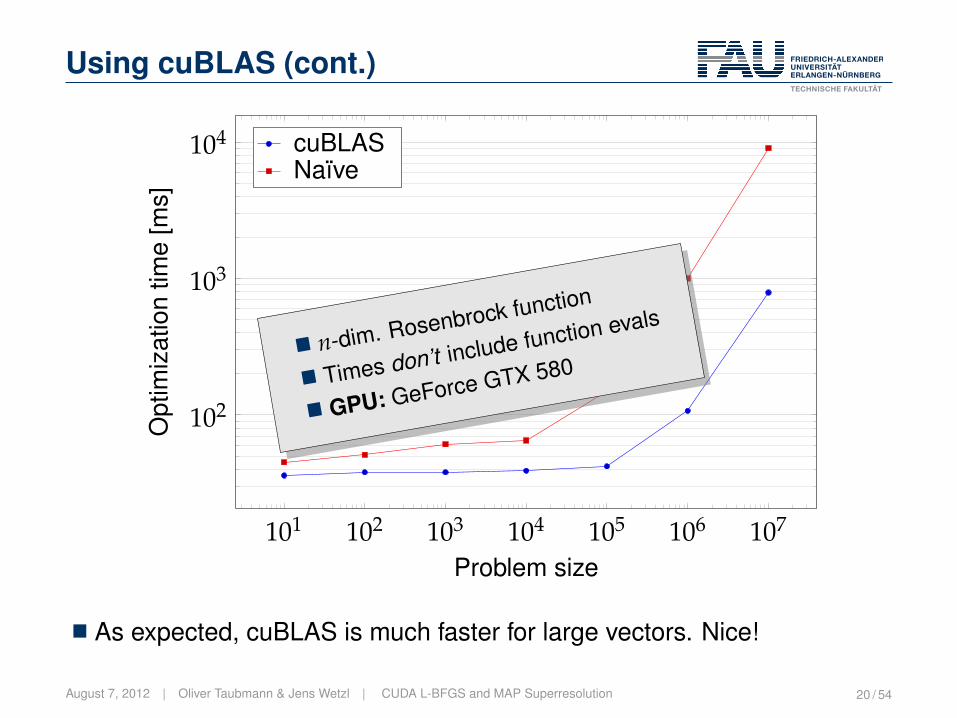
Using cuBLAS (cont.)
101 102 103 104 105 106 107
102
103
104
Problem size
Opt
imiz
atio
ntim
e[m
s]cuBLASNaïve
� n-dim. Rosenbrock function
� Times don’t include function evals
� GPU: GeForce GTX 580
� As expected, cuBLAS is much faster for large vectors. Nice!
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 20 / 54
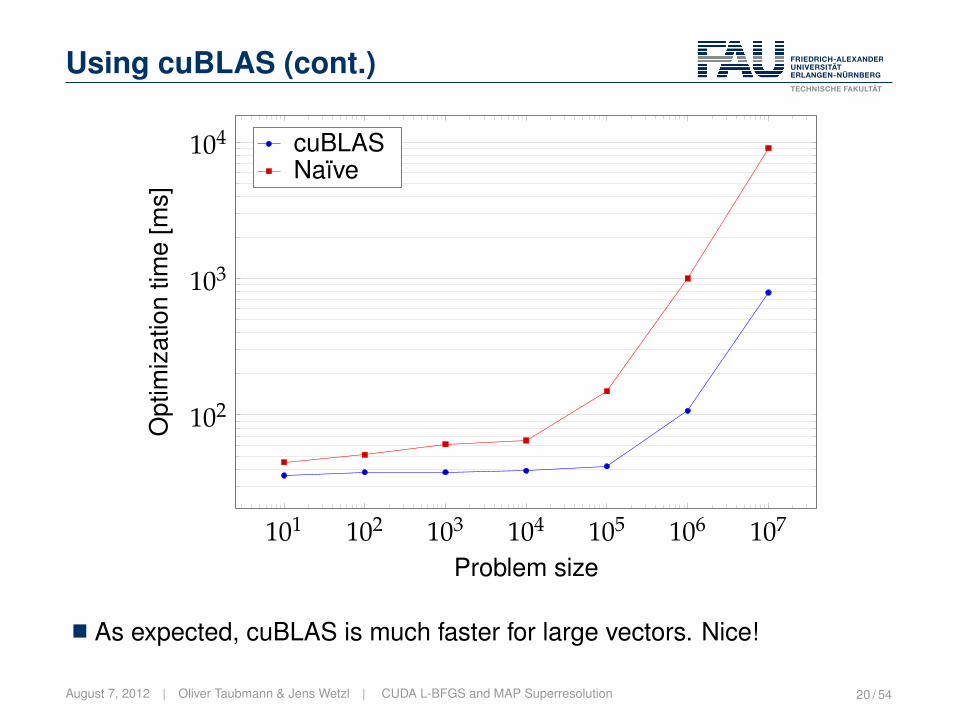
Using cuBLAS (cont.)
101 102 103 104 105 106 107
102
103
104
Problem size
Opt
imiz
atio
ntim
e[m
s]cuBLASNaïve
� As expected, cuBLAS is much faster for large vectors. Nice!
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 20 / 54

Scalar Operations on the GPU
� Up to now, all scalar calculations are still done on the CPU�→ scalar values (e.g. dot results) must still be copied frequently� Is it faster to avoid copying and let a single GPU thread do the work?
� Trying to combine as many steps as possible,we still ended up with several “sequential” kernels:
__global__ void update1 ([...]); // first update loop__global__ void update2 ([...]); // second update loop__global__ void update3 ([...]); // after line search__global__ void initStep ([...]);__global__ void lineSearch([...]);
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 21 / 54

Scalar Operations on the GPU
� Up to now, all scalar calculations are still done on the CPU�→ scalar values (e.g. dot results) must still be copied frequently� Is it faster to avoid copying and let a single GPU thread do the work?
� Trying to combine as many steps as possible,we still ended up with several “sequential” kernels:
__global__ void update1 ([...]); // first update loop__global__ void update2 ([...]); // second update loop__global__ void update3 ([...]); // after line search__global__ void initStep ([...]);__global__ void lineSearch([...]);
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 21 / 54
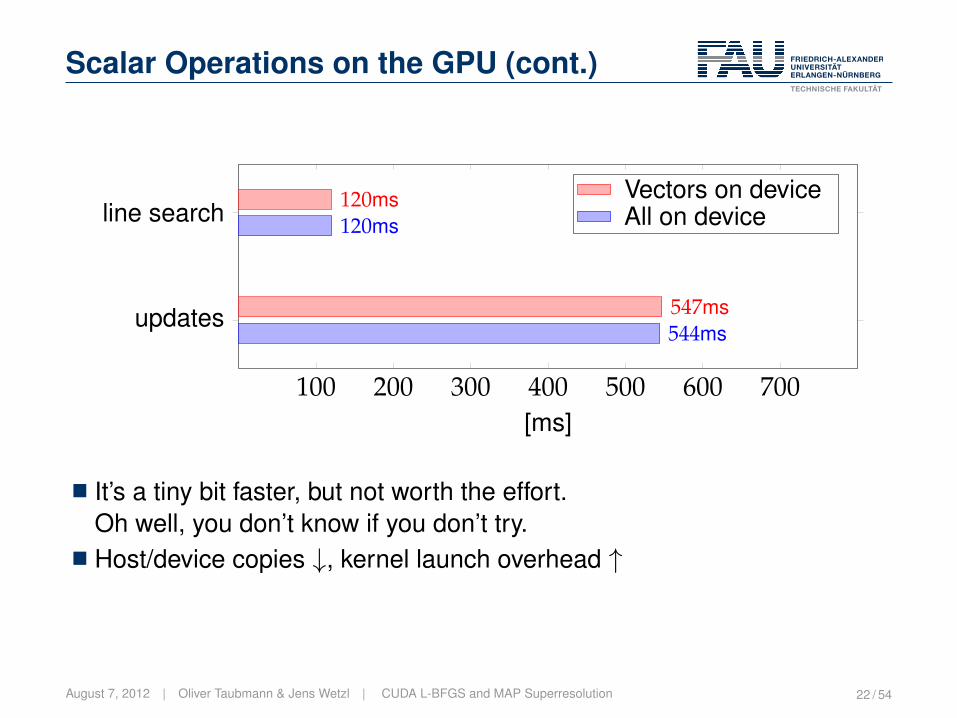
Scalar Operations on the GPU (cont.)
100 200 300 400 500 600 700
updates
line search
544ms
120ms
547ms
120ms
[ms]
Vectors on deviceAll on device
� It’s a tiny bit faster, but not worth the effort.Oh well, you don’t know if you don’t try.
� Host/device copies ↓, kernel launch overhead ↑
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 22 / 54

Line Search
� Code optimization is all good and well, but will only get us so far:2 Most of the time is usually spent in function/gradient evaluations2 L-BFGS is robust even when step lengths are chosen naïvely, but:2 A clever line search is crucial to minimize the number of evaluations
t0
f (~x + t ·~s)
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 23 / 54
Line Search
� Code optimization is all good and well, but will only get us so far:2 Most of the time is usually spent in function/gradient evaluations2 L-BFGS is robust even when step lengths are chosen naïvely, but:2 A clever line search is crucial to minimize the number of evaluations
t0
f (~x + t ·~s)
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 23 / 54
Line Search
� Code optimization is all good and well, but will only get us so far:2 Most of the time is usually spent in function/gradient evaluations2 L-BFGS is robust even when step lengths are chosen naïvely, but:2 A clever line search is crucial to minimize the number of evaluations
t0 t1
f (~x + t ·~s)
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 23 / 54
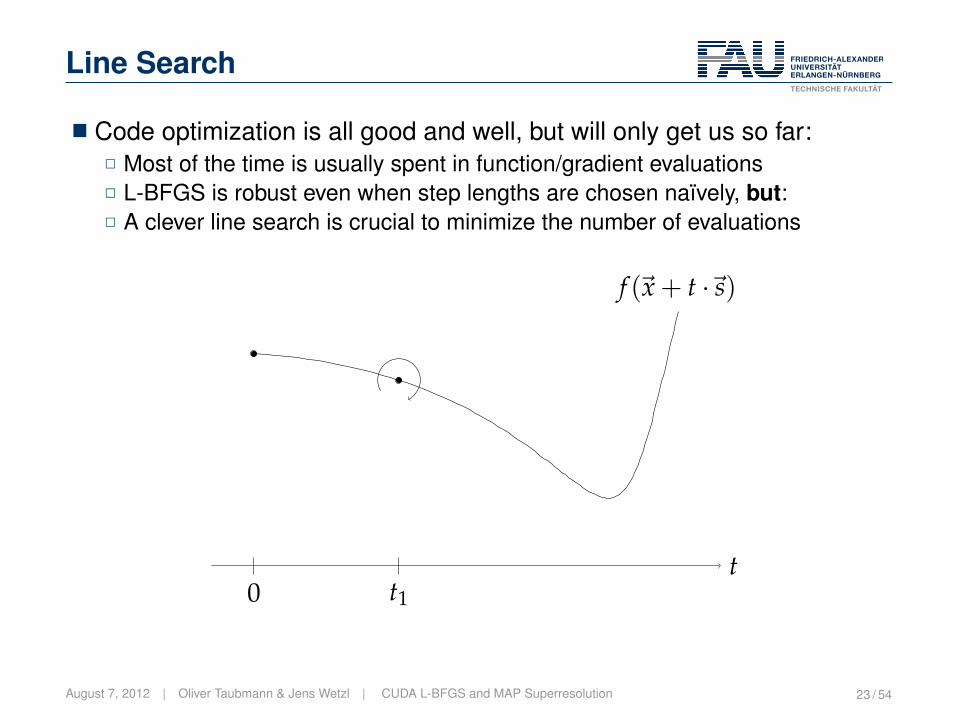
Line Search
� Code optimization is all good and well, but will only get us so far:2 Most of the time is usually spent in function/gradient evaluations2 L-BFGS is robust even when step lengths are chosen naïvely, but:2 A clever line search is crucial to minimize the number of evaluations
t0 t1
f (~x + t ·~s)
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 23 / 54
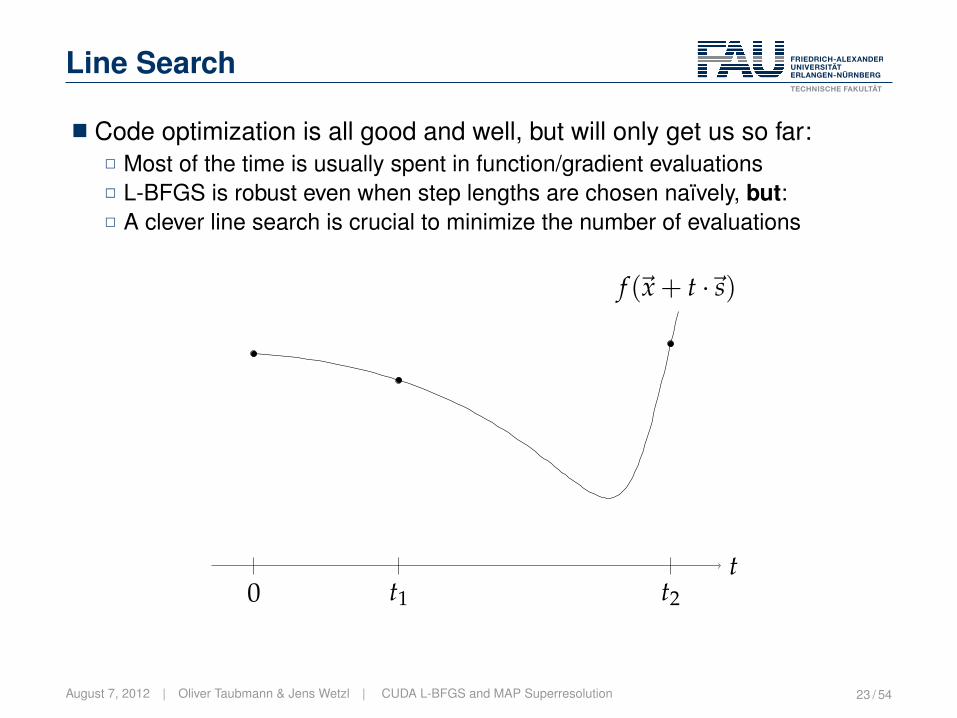
Line Search
� Code optimization is all good and well, but will only get us so far:2 Most of the time is usually spent in function/gradient evaluations2 L-BFGS is robust even when step lengths are chosen naïvely, but:2 A clever line search is crucial to minimize the number of evaluations
t0 t1 t2
f (~x + t ·~s)
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 23 / 54
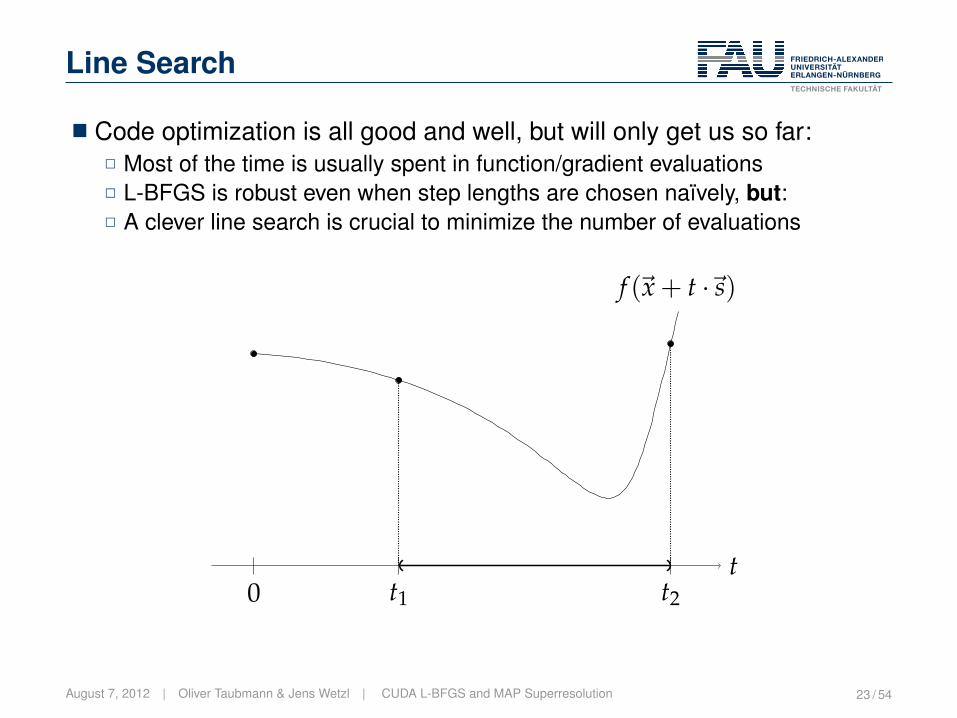
Line Search
� Code optimization is all good and well, but will only get us so far:2 Most of the time is usually spent in function/gradient evaluations2 L-BFGS is robust even when step lengths are chosen naïvely, but:2 A clever line search is crucial to minimize the number of evaluations
t0 t1 t2
f (~x + t ·~s)
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 23 / 54
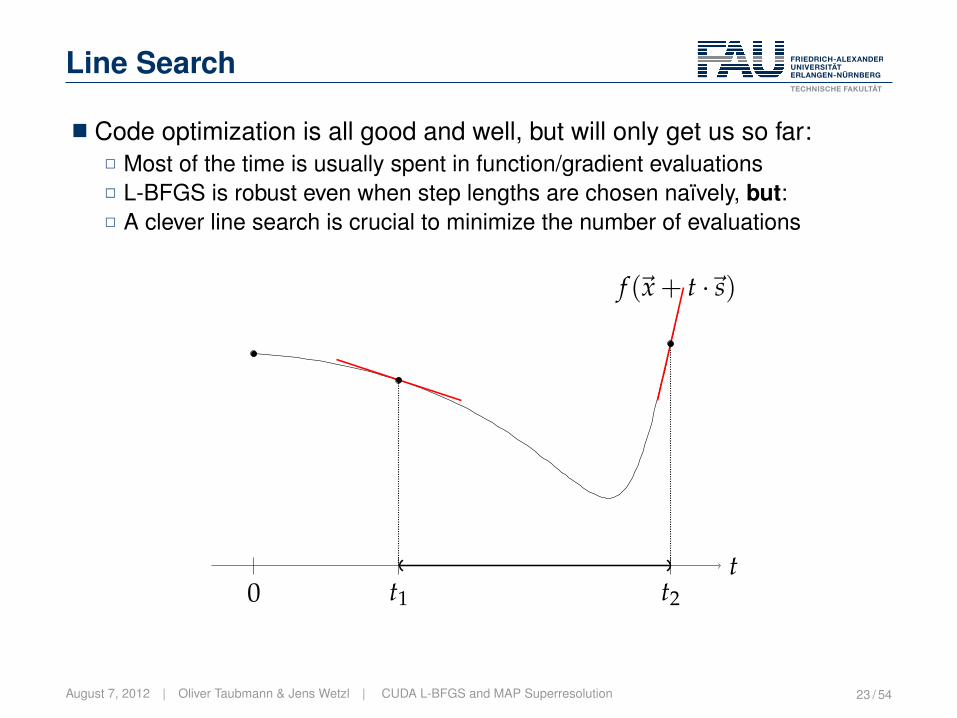
Line Search
� Code optimization is all good and well, but will only get us so far:2 Most of the time is usually spent in function/gradient evaluations2 L-BFGS is robust even when step lengths are chosen naïvely, but:2 A clever line search is crucial to minimize the number of evaluations
t0 t1 t2
f (~x + t ·~s)
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 23 / 54
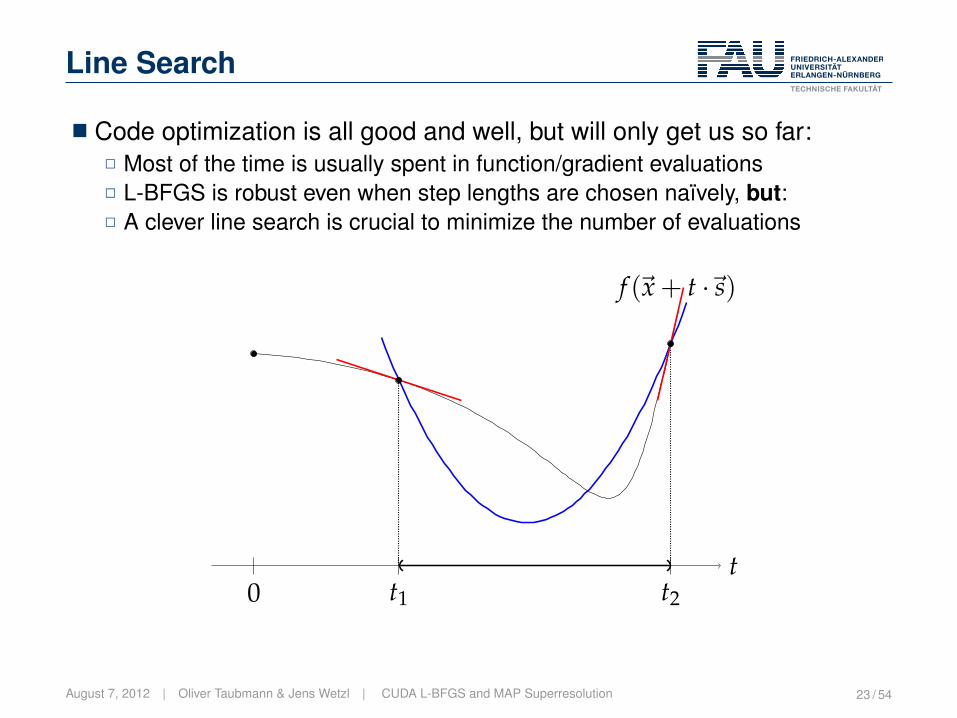
Line Search
� Code optimization is all good and well, but will only get us so far:2 Most of the time is usually spent in function/gradient evaluations2 L-BFGS is robust even when step lengths are chosen naïvely, but:2 A clever line search is crucial to minimize the number of evaluations
t0 t1 t2
f (~x + t ·~s)
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 23 / 54
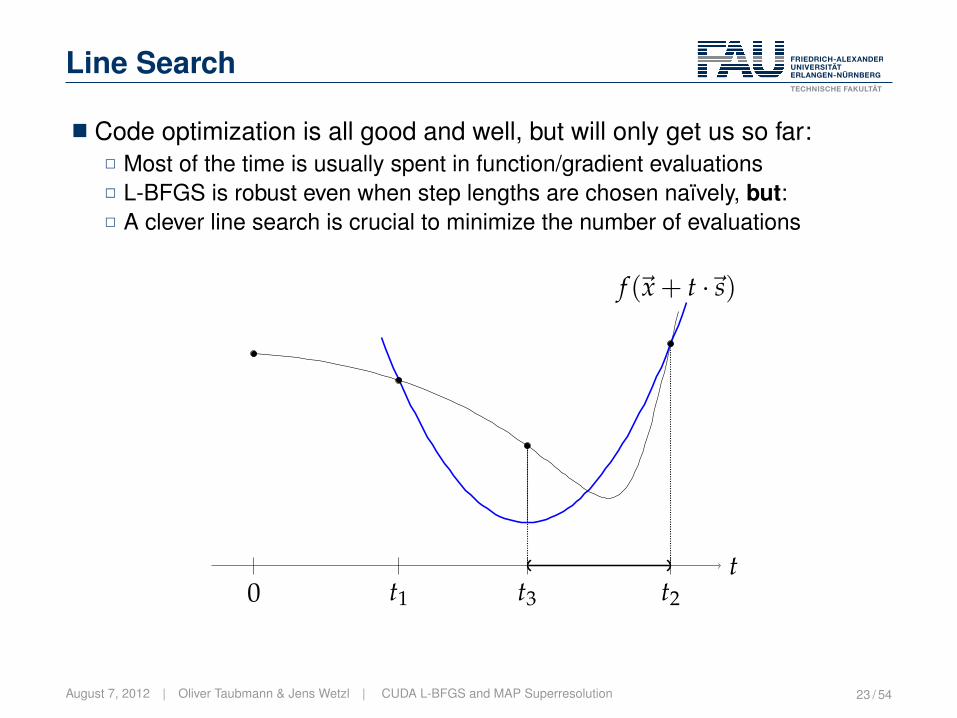
Line Search
� Code optimization is all good and well, but will only get us so far:2 Most of the time is usually spent in function/gradient evaluations2 L-BFGS is robust even when step lengths are chosen naïvely, but:2 A clever line search is crucial to minimize the number of evaluations
t0 t1 t2t3
f (~x + t ·~s)
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 23 / 54
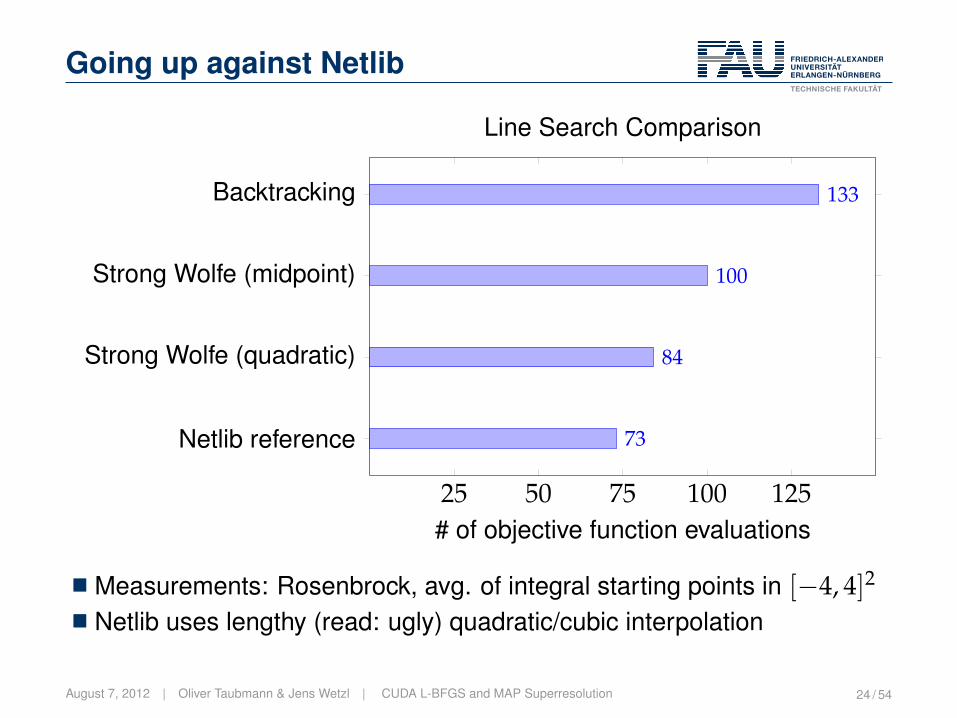
Going up against Netlib
25 50 75 100 125
Backtracking
Strong Wolfe (midpoint)
Strong Wolfe (quadratic)
Netlib reference
133
100
84
73
# of objective function evaluations
Line Search Comparison
� Measurements: Rosenbrock, avg. of integral starting points in [−4, 4]2
� Netlib uses lengthy (read: ugly) quadratic/cubic interpolation
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 24 / 54
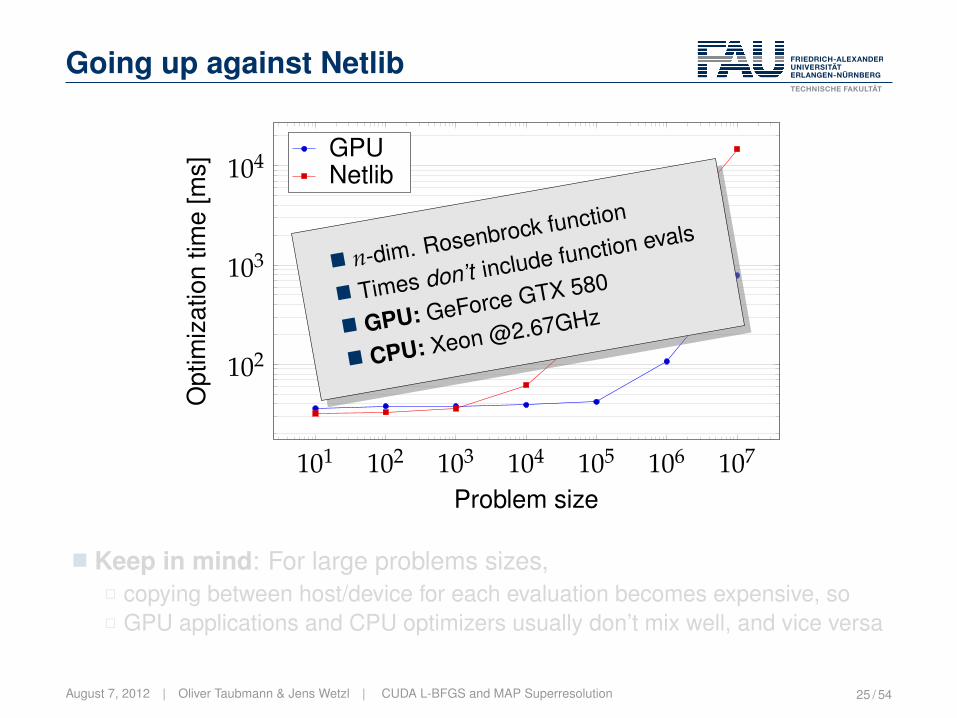
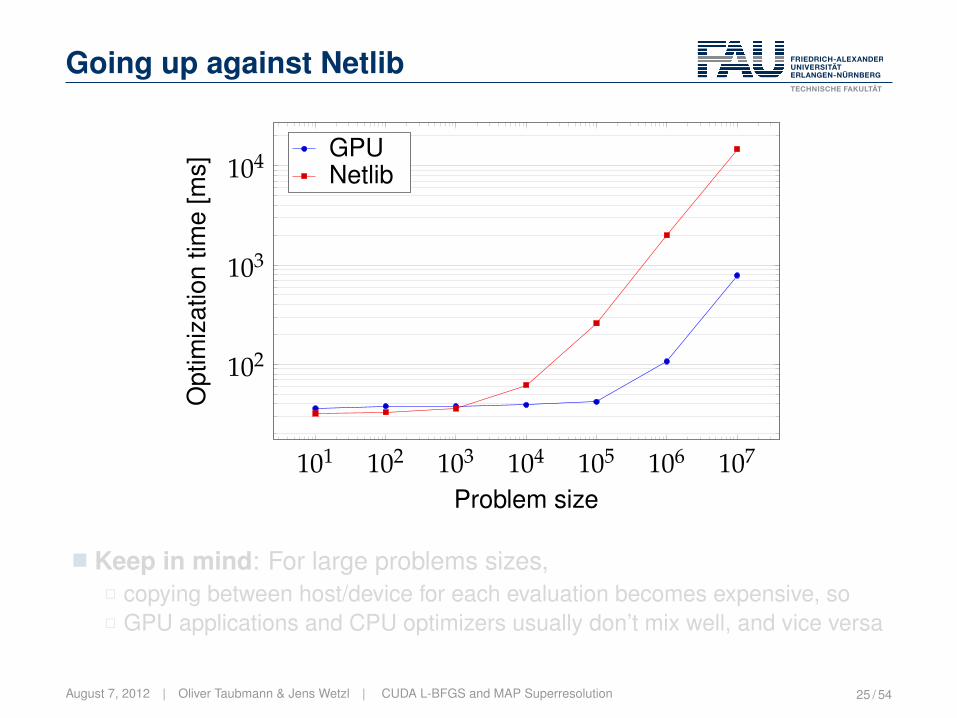
Going up against Netlib
101 102 103 104 105 106 107
102
103
104
Problem size
Opt
imiz
atio
ntim
e[m
s]
GPUNetlib
� n-dim. Rosenbrock function
� Times don’t include function evals
� GPU: GeForce GTX 580
� CPU: Xeon @2.67GHz
� Keep in mind: For large problems sizes,2 copying between host/device for each evaluation becomes expensive, so2 GPU applications and CPU optimizers usually don’t mix well, and vice versa
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 25 / 54
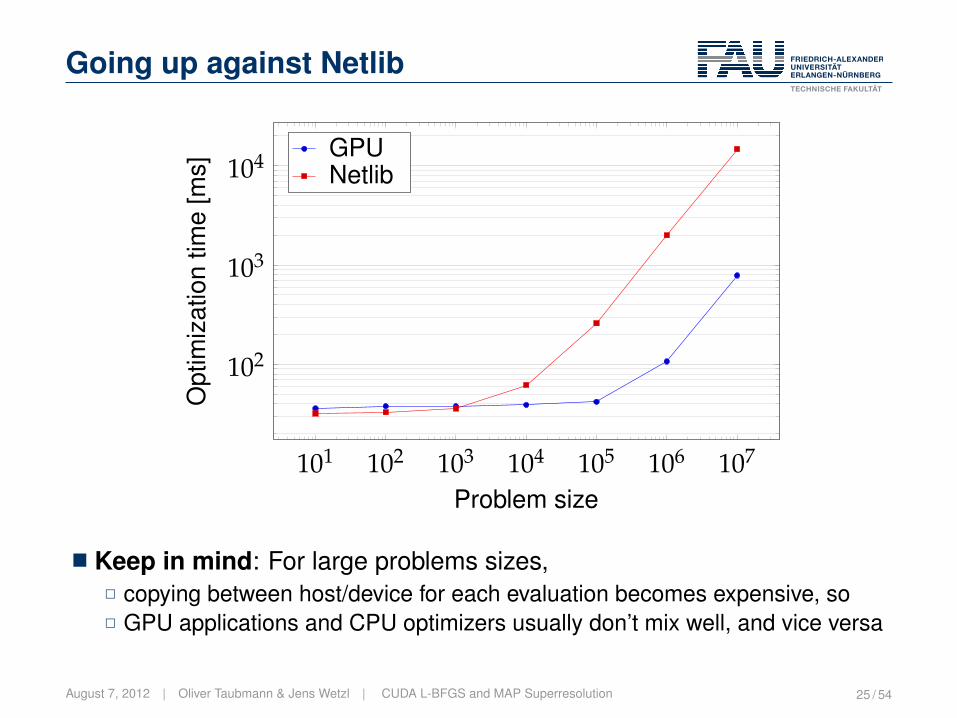
Going up against Netlib
101 102 103 104 105 106 107
102
103
104
Problem size
Opt
imiz
atio
ntim
e[m
s]
GPUNetlib
� Keep in mind: For large problems sizes,2 copying between host/device for each evaluation becomes expensive, so2 GPU applications and CPU optimizers usually don’t mix well, and vice versa
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 25 / 54
Going up against Netlib
101 102 103 104 105 106 107
102
103
104
Problem size
Opt
imiz
atio
ntim
e[m
s]
GPUNetlib
� Keep in mind: For large problems sizes,2 copying between host/device for each evaluation becomes expensive, so2 GPU applications and CPU optimizers usually don’t mix well, and vice versa
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 25 / 54

Outline
CUDA L-BFGSAlgorithm & ImplementationOptimizationFramework
MAP SuperresolutionAlgorithm & ImplementationOptimizationEvaluation
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 26 / 54

Testing
Functions used for testing:
� Quadratic functions: f (~x) =~xTA~x +~bT~x + c, ~x ∈ Rn
2 Convex if A is positive semidefinite⇒ unique, easy-to-find solution2 We randomly generate parameters up to matrix size 500×500
• Compute QR decomposition of a random matrix• A = QΛQT with Λ = diag(λi), λi ≥ 0 randomly chosen
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 27 / 54
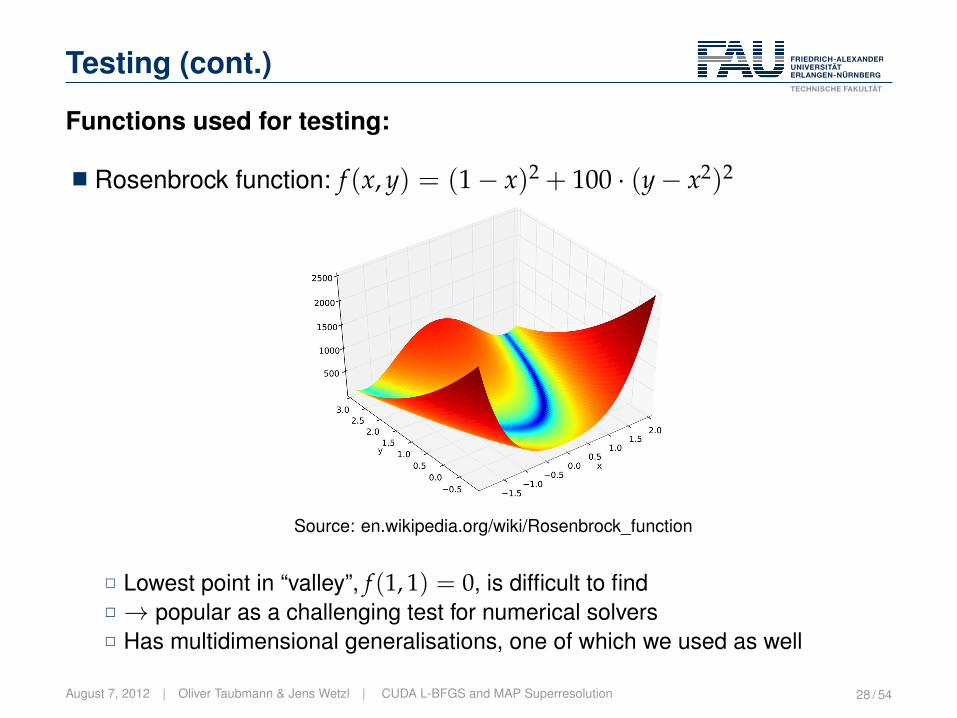
Testing (cont.)
Functions used for testing:
� Rosenbrock function: f (x, y) = (1− x)2 + 100 · (y− x2)2
Source: en.wikipedia.org/wiki/Rosenbrock_function
2 Lowest point in “valley”, f (1, 1) = 0, is difficult to find2 → popular as a challenging test for numerical solvers2 Has multidimensional generalisations, one of which we used as well
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 28 / 54

CMake Build System
� Builds (and installs) library, optional sample projects and test cases� Allows to comfortably. . .
2 switch on error checking, timing, verbose output, CPU double precision2 choose between all different implementations
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 29 / 54

Outline
CUDA L-BFGSAlgorithm & ImplementationOptimizationFramework
MAP SuperresolutionAlgorithm & ImplementationOptimizationEvaluation
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 30 / 54

Outline
CUDA L-BFGSAlgorithm & ImplementationOptimizationFramework
MAP SuperresolutionAlgorithm & Implementation
Problem ModelImplementation
OptimizationEvaluation
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 31 / 54

Problem
� Given:2 A series of low quality images, e.g. from a bad camera2 Motion (and camera) parameters, e.g. obtained from registration
� Wanted: A single high quality image2 reconstructed from the original images2 reasonably “smooth” at the same time
Effectively higher resolutions can be obtained due to sub-pixel motion
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 32 / 54
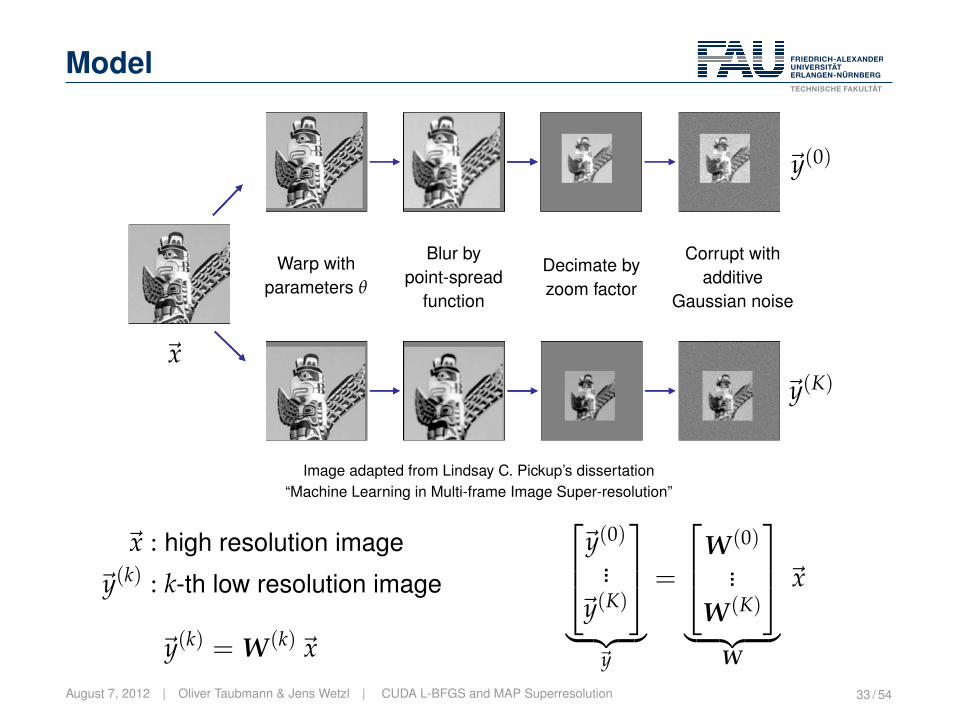
Model
~x
~y(0)
~y(K)
Warp withparameters θ
Blur bypoint-spread
function
Decimate byzoom factor
Corrupt withadditive
Gaussian noise
Image adapted from Lindsay C. Pickup’s dissertation“Machine Learning in Multi-frame Image Super-resolution”
~x : high resolution image
~y(k) : k-th low resolution image
~y(k) = W(k)~x
~y(0)...~y(K)
︸ ︷︷ ︸
~y
=
W(0)
...W(K)
︸ ︷︷ ︸
W
~x
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 33 / 54
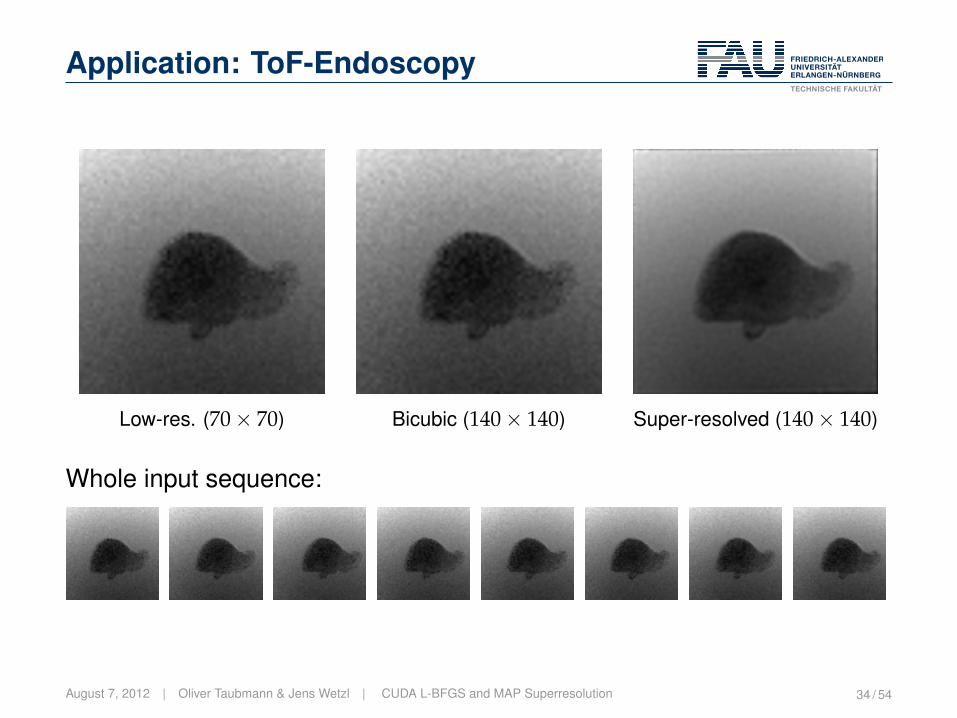
Application: ToF-Endoscopy
Low-res. (70× 70) Bicubic (140× 140) Super-resolved (140× 140)
Whole input sequence:
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 34 / 54

Algorithm
� Compose system matrix W from motion parameters andwidth of the point spread function (PSF)
� Compute average image as initial guess for optimization:
~x(0) = W̃T~y where W̃ is W with normalized columns
� Minimize the objective function
~x∗ = argmin~x
‖W ~x−~y‖22 + λ · ‖cHuber (LoG(~x)) ‖1
2 W ~x−~y is the residual2 LoG(~x) is the Laplacian-of-Gaussian-filtered image2 cHuber(·) is the pseudo-Huber loss function (applied element-wise)2 λ controls the strength of the prior, i.e. smoothness
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 35 / 54

Algorithm
� Compose system matrix W from motion parameters andwidth of the point spread function (PSF)
� Compute average image as initial guess for optimization:
~x(0) = W̃T~y where W̃ is W with normalized columns
� Minimize the objective function
~x∗ = argmin~x
‖W ~x−~y‖22 + λ · ‖cHuber (LoG(~x)) ‖1
2 W ~x−~y is the residual2 LoG(~x) is the Laplacian-of-Gaussian-filtered image2 cHuber(·) is the pseudo-Huber loss function (applied element-wise)2 λ controls the strength of the prior, i.e. smoothness
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 35 / 54

Algorithm in Codevoid MAPSuperResolution::superresolve(const LRImageStack &lrImages,const std::vector<MotionParams> &motionParams, SRImage &srImage, [...])
{// Compute system matrixSRSystemMatrix systemMatrix(motionParams, m_psfWidth, [...]);
// Initialize SR Imageswitch (init) {
case SR_INITIALIZATION_AVERAGE:srImage.initToAverageImage([...]); break;
case SR_INITIALIZATION_BLACK:srImage.setZero(); break;
}
// OptimizeSRCostFunction cf(srImage.getNumPixels(), systemMatrix, lrImages,
m_gpuHandles, m_prior);
lbfgs minimizer(cf);minimizer.setGradientEpsilon(m_gradientEps);
lbfgs::status stat = minimizer.minimize(srImage.getPixels());}
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 36 / 54

Implementation
First steps:
� Some framework functionality2 Reading motion parameters from file2 Reading and saving image files to/from device memory (using FreeImage)
� Parallelization of all steps mentioned above with CUDA2 System matrix and all images stay on the device throughout2 Uses our optimizer (combined evaluation of f (~x) and ∇f (~x) pays off here)2 Tested correctness against given Matlab implementation
� But: Matrix is still dense⇒ prohibitive for realistic problem sizes2 It’s
(#LR pixels · #LR images
)× #HR pixels elements
#LR images #LR pixels #HR pixels Required memory8 64× 64 128× 128 2 GB8 128× 128 256× 256 32 GB16 256× 256 1024× 1024 4 TB
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 37 / 54

Implementation
First steps:
� Some framework functionality2 Reading motion parameters from file2 Reading and saving image files to/from device memory (using FreeImage)
� Parallelization of all steps mentioned above with CUDA2 System matrix and all images stay on the device throughout2 Uses our optimizer (combined evaluation of f (~x) and ∇f (~x) pays off here)2 Tested correctness against given Matlab implementation
� But: Matrix is still dense⇒ prohibitive for realistic problem sizes2 It’s
(#LR pixels · #LR images
)× #HR pixels elements
#LR images #LR pixels #HR pixels Required memory8 64× 64 128× 128 2 GB8 128× 128 256× 256 32 GB16 256× 256 1024× 1024 4 TB
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 37 / 54

Outline
CUDA L-BFGSAlgorithm & ImplementationOptimizationFramework
MAP SuperresolutionAlgorithm & ImplementationOptimization
Sparse System MatrixComputational BottlenecksPrior
Evaluation
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 38 / 54

Building the Sparse Matrix
� 1 LR pixel is affected by only a small region in the HR image� PSF width determines the size of that region�→ Max. number of elements per row can be precomputed
� Using the CRS (compressed row storage) format:2 Positions of non-zero entries are not restricted2 We can build all matrix rows in parallel2 Efficient matrix-vector-multiplication is possible
� If a row has less than max. number of elements,we still need to generate valid CRS structure
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 39 / 54

Building the Sparse Matrix
� 1 LR pixel is affected by only a small region in the HR image� PSF width determines the size of that region�→ Max. number of elements per row can be precomputed
� Using the CRS (compressed row storage) format:2 Positions of non-zero entries are not restricted2 We can build all matrix rows in parallel2 Efficient matrix-vector-multiplication is possible
� If a row has less than max. number of elements,we still need to generate valid CRS structure
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 39 / 54

Using the Sparse Matrix
� For computing the residual,~r = W ~x−~y, we need multiplication� Straight-forward to implement, but there’s cuSPARSE, too:
2 Similar to cuBLAS, but for sparse matrices2 Offers CRS-matrix-vector-multiplication, which we use
� Problem: We also need transposed multiplication2 For the gradient: −2WT~r2 For the average image: W̃
T~y
� CRS it not well suited for that, but at least:� cuSPARSE offers a better-than-naïve implementation
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 40 / 54

Using the Sparse Matrix
� For computing the residual,~r = W ~x−~y, we need multiplication� Straight-forward to implement, but there’s cuSPARSE, too:
2 Similar to cuBLAS, but for sparse matrices2 Offers CRS-matrix-vector-multiplication, which we use
� Problem: We also need transposed multiplication2 For the gradient: −2WT~r2 For the average image: W̃
T~y
� CRS it not well suited for that, but at least:� cuSPARSE offers a better-than-naïve implementation
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 40 / 54

Enter CCS (compressed column storage)
� CCS is perfect for transposed multiplication�→ Added option to store both CRS and CCS representation
2 cuSPARSE even offers the conversion:
#ifdef SUPERRES_STORE_TRANSPOSEcusparseScsr2csc(
m_gpuHandles.cusparseHandle, m_height, m_width,m_d_values, m_d_rowPointers, m_d_colIndices, // CRSm_d_values_ccs, m_d_rowIndices_ccs, m_d_colPointers_ccs, // CCS1, CUSPARSE_INDEX_BASE_ZERO);
#endif
� Trade-off:(-) Needs twice the memory for the matrix(0) Precomputation time: Building ↑, average image ↓(+) Evaluations are much faster
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 41 / 54

Enter CCS (compressed column storage)
� CCS is perfect for transposed multiplication�→ Added option to store both CRS and CCS representation
2 cuSPARSE even offers the conversion:
#ifdef SUPERRES_STORE_TRANSPOSEcusparseScsr2csc(
m_gpuHandles.cusparseHandle, m_height, m_width,m_d_values, m_d_rowPointers, m_d_colIndices, // CRSm_d_values_ccs, m_d_rowIndices_ccs, m_d_colPointers_ccs, // CCS1, CUSPARSE_INDEX_BASE_ZERO);
#endif
� Trade-off:(-) Needs twice the memory for the matrix(0) Precomputation time: Building ↑, average image ↓(+) Evaluations are much faster
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 41 / 54
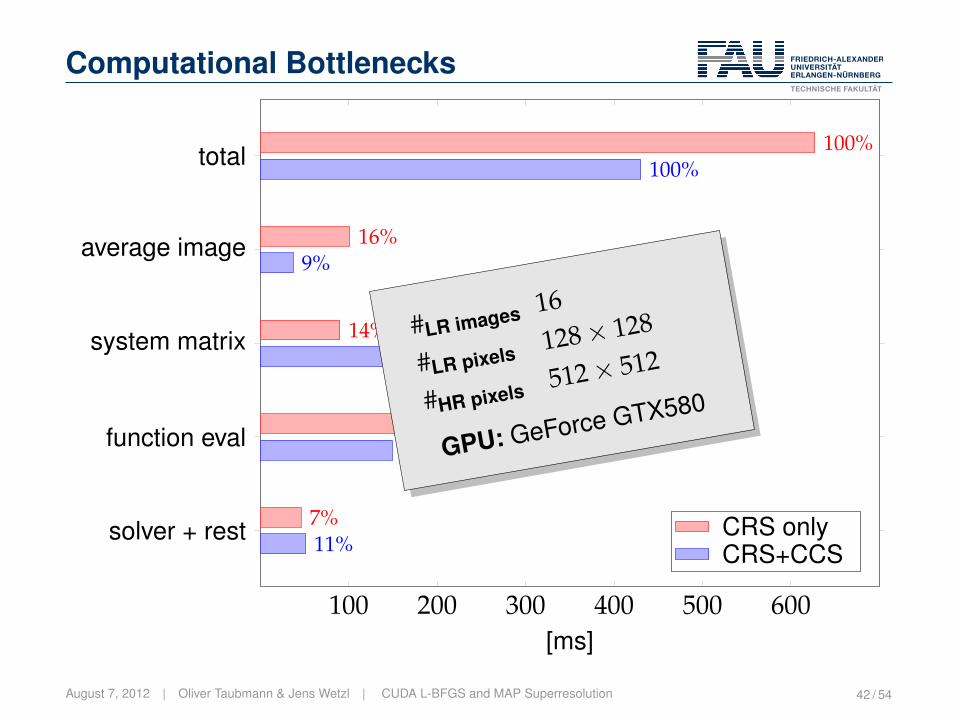
Computational Bottlenecks
100 200 300 400 500 600
average image
system matrix
function eval
solver + rest
total
9%
45%
35%
11%
100%
16%
14%
62%
7%
100%
[ms]
CRS onlyCRS+CCS
#LR images 16
#LR pixels128× 128
#HR pixels512× 512
GPU: GeForce GTX580
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 42 / 54
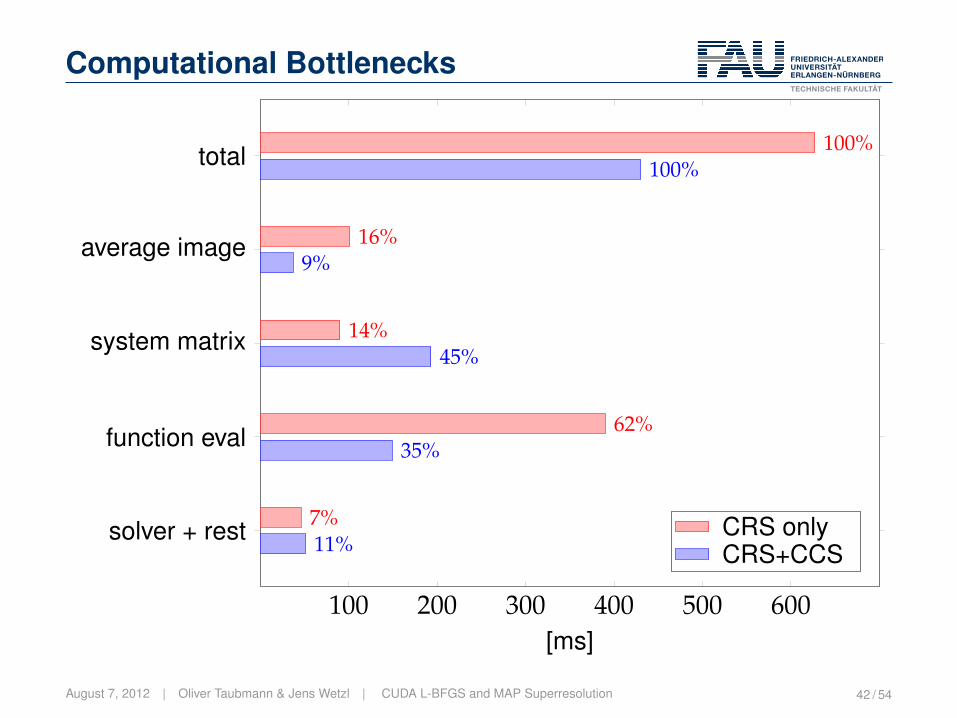
Computational Bottlenecks
100 200 300 400 500 600
average image
system matrix
function eval
solver + rest
total
9%
45%
35%
11%
100%
16%
14%
62%
7%
100%
[ms]
CRS onlyCRS+CCS
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 42 / 54
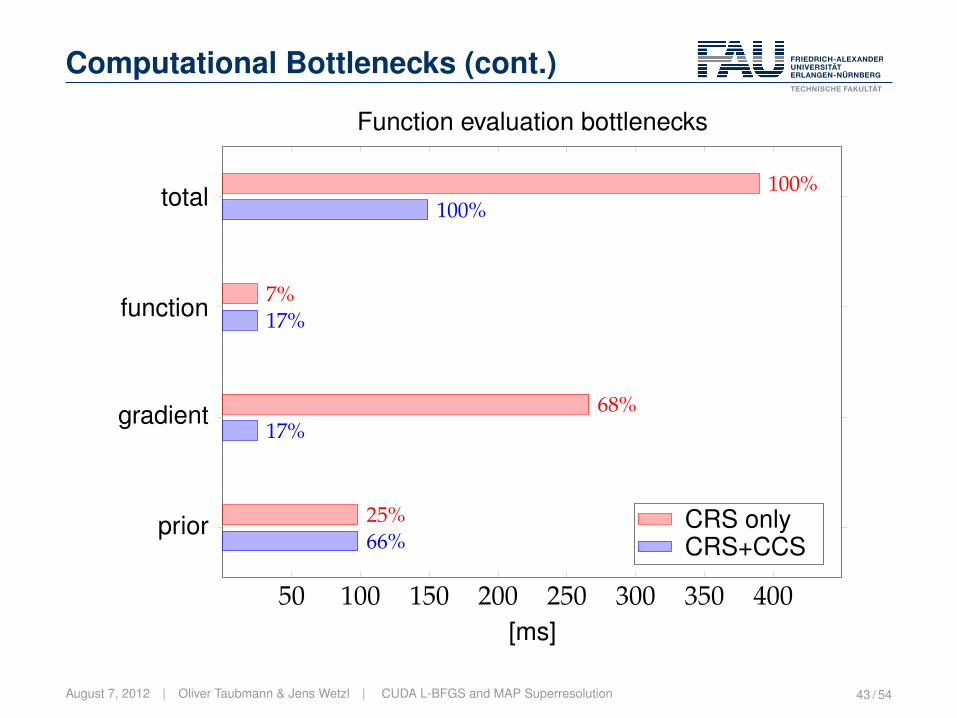
Computational Bottlenecks (cont.)
50 100 150 200 250 300 350 400
function
gradient
prior
total
17%
17%
66%
100%
7%
68%
25%
100%
[ms]
Function evaluation bottlenecks
CRS onlyCRS+CCS
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 43 / 54
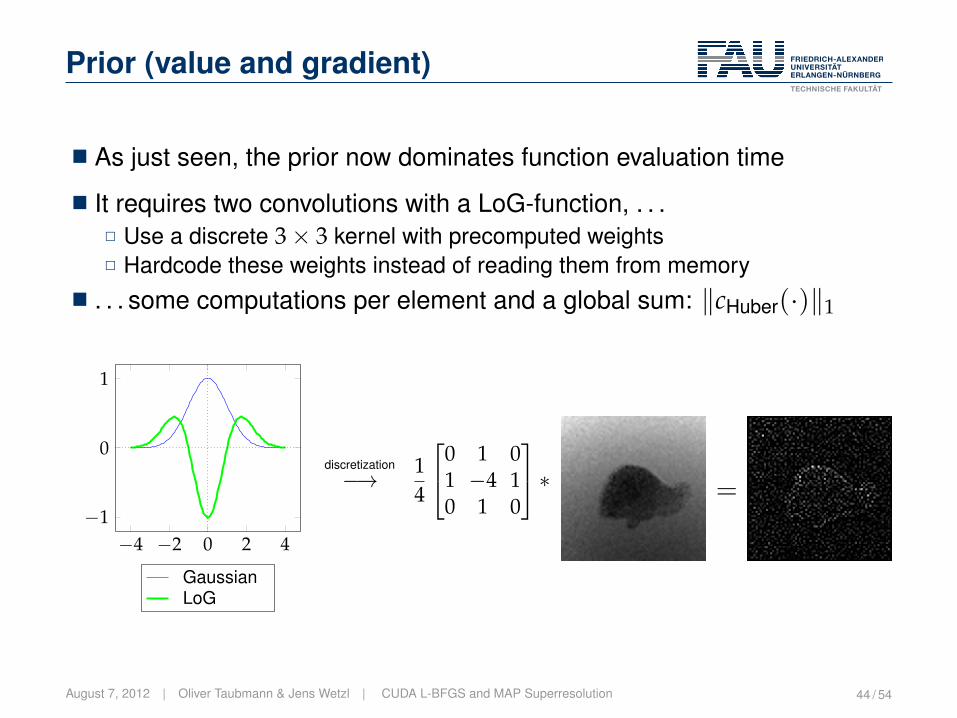
Prior (value and gradient)
� As just seen, the prior now dominates function evaluation time
� It requires two convolutions with a LoG-function, . . .2 Use a discrete 3× 3 kernel with precomputed weights2 Hardcode these weights instead of reading them from memory
� . . . some computations per element and a global sum: ‖cHuber(·)‖1
−4 −2 0 2 4−1
0
1
GaussianLoG
discretization−→ 1
4
0 1 01 −4 10 1 0
∗ =
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 44 / 54
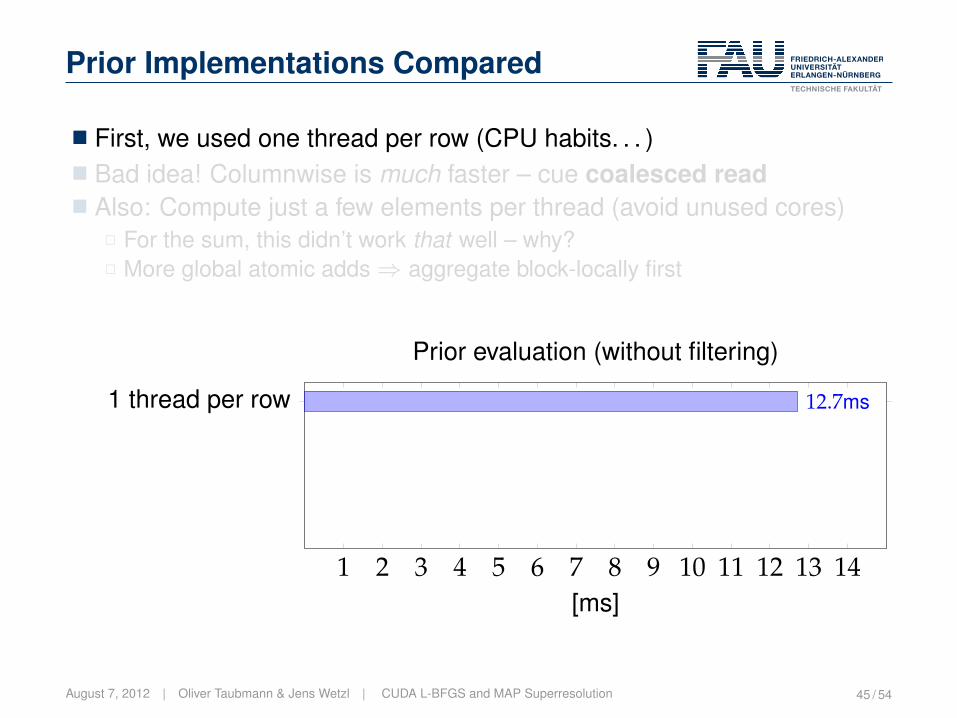
Prior Implementations Compared
� First, we used one thread per row (CPU habits. . . )� Bad idea! Columnwise is much faster – cue coalesced read� Also: Compute just a few elements per thread (avoid unused cores)
2 For the sum, this didn’t work that well – why?2 More global atomic adds⇒ aggregate block-locally first
1 2 3 4 5 6 7 8 9 10 11 12 13 14
1 thread per row 12.7ms
[ms]
Prior evaluation (without filtering)
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 45 / 54
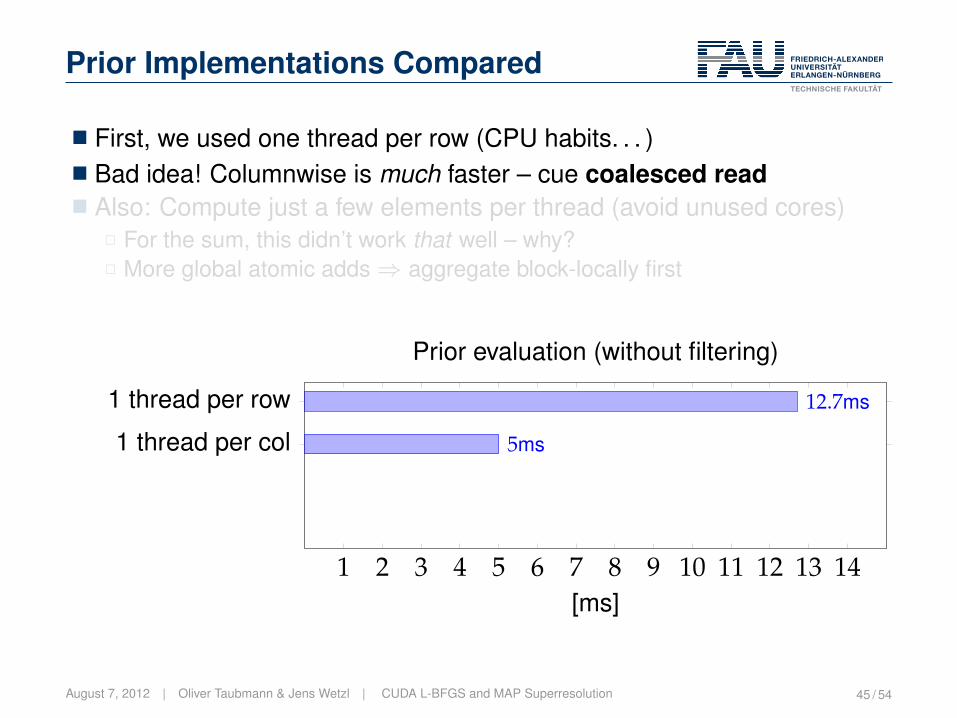
Prior Implementations Compared
� First, we used one thread per row (CPU habits. . . )� Bad idea! Columnwise is much faster – cue coalesced read� Also: Compute just a few elements per thread (avoid unused cores)
2 For the sum, this didn’t work that well – why?2 More global atomic adds⇒ aggregate block-locally first
1 2 3 4 5 6 7 8 9 10 11 12 13 14
1 thread per col
1 thread per row
5ms
12.7ms
[ms]
Prior evaluation (without filtering)
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 45 / 54
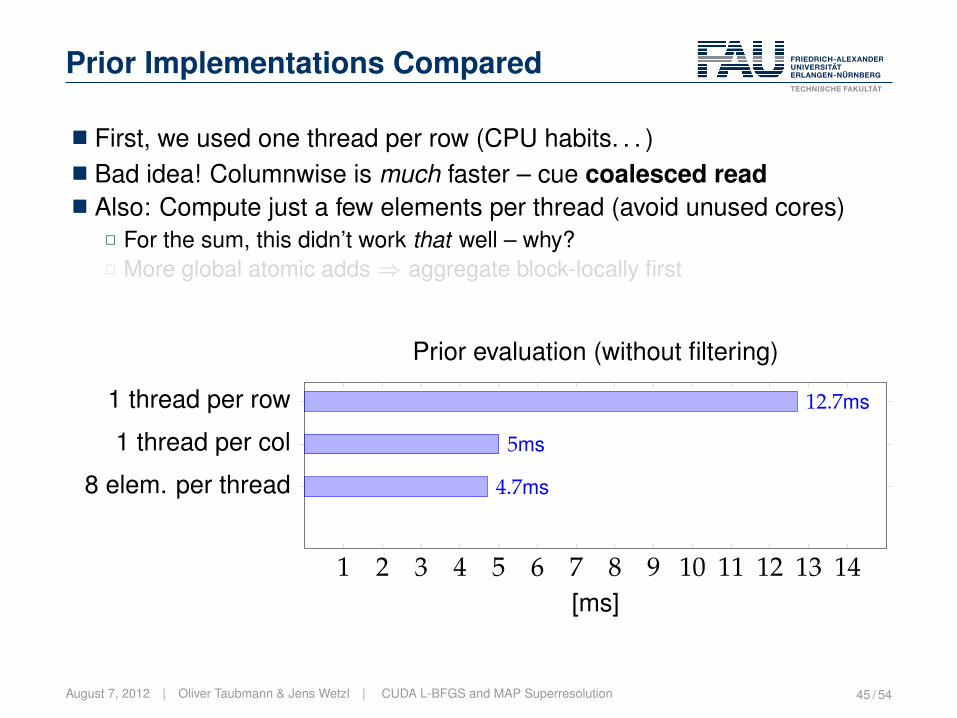
Prior Implementations Compared
� First, we used one thread per row (CPU habits. . . )� Bad idea! Columnwise is much faster – cue coalesced read� Also: Compute just a few elements per thread (avoid unused cores)
2 For the sum, this didn’t work that well – why?2 More global atomic adds⇒ aggregate block-locally first
1 2 3 4 5 6 7 8 9 10 11 12 13 14
8 elem. per thread
1 thread per col
1 thread per row
4.7ms
5ms
12.7ms
[ms]
Prior evaluation (without filtering)
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 45 / 54
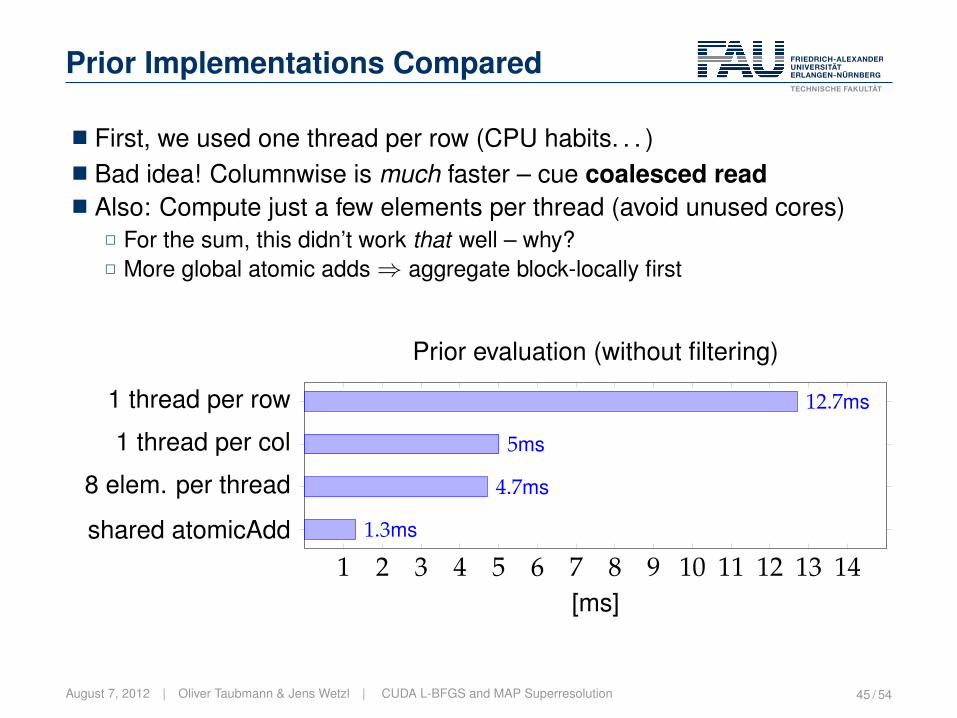
Prior Implementations Compared
� First, we used one thread per row (CPU habits. . . )� Bad idea! Columnwise is much faster – cue coalesced read� Also: Compute just a few elements per thread (avoid unused cores)
2 For the sum, this didn’t work that well – why?2 More global atomic adds⇒ aggregate block-locally first
1 2 3 4 5 6 7 8 9 10 11 12 13 14shared atomicAdd
8 elem. per thread
1 thread per col
1 thread per row
1.3ms
4.7ms
5ms
12.7ms
[ms]
Prior evaluation (without filtering)
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 45 / 54
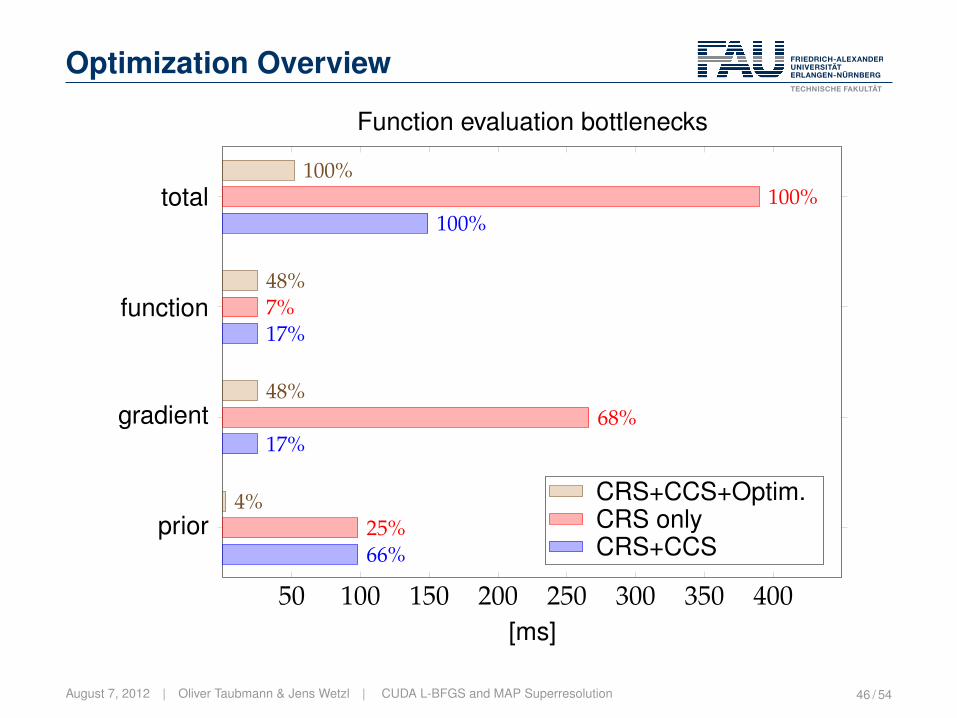
Optimization Overview
50 100 150 200 250 300 350 400
function
gradient
prior
total
17%
17%
66%
100%
7%
68%
25%
100%
48%
48%
4%
100%
[ms]
Function evaluation bottlenecks
CRS+CCS+Optim.CRS onlyCRS+CCS
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 46 / 54

Outline
CUDA L-BFGSAlgorithm & ImplementationOptimizationFramework
MAP SuperresolutionAlgorithm & ImplementationOptimizationEvaluation
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 47 / 54
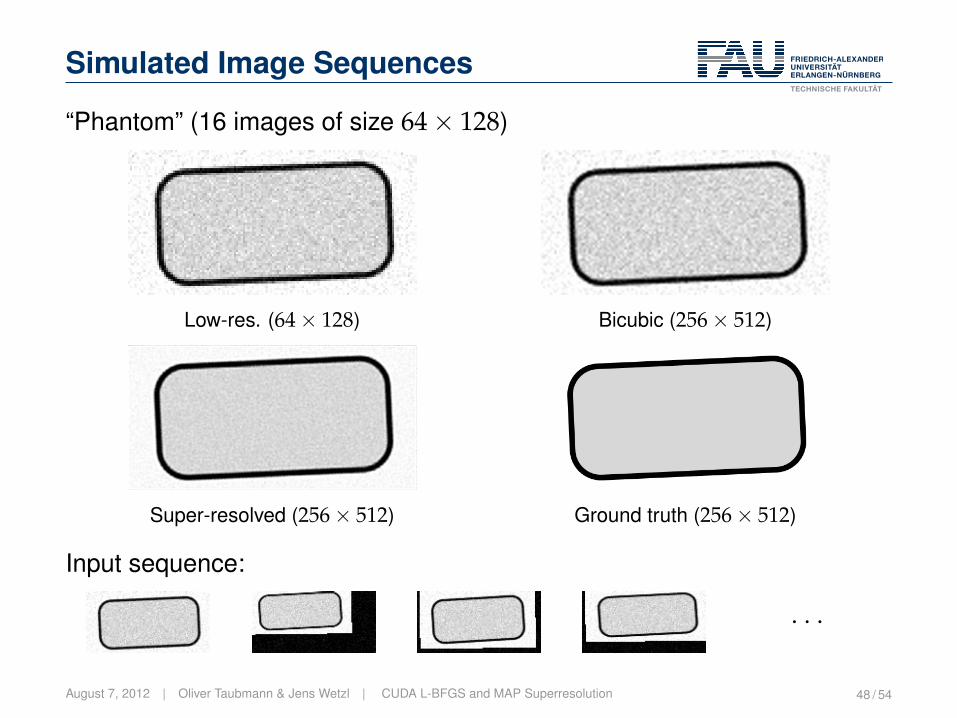
Simulated Image Sequences
“Phantom” (16 images of size 64× 128)
Low-res. (64× 128) Bicubic (256× 512)
Super-resolved (256× 512) Ground truth (256× 512)
Input sequence:
· · ·
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 48 / 54

Simulated Image Sequences (cont.)
“Aerial” (16 images of size 128× 128)
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 49 / 54

Simulated Image Sequences (cont.)
Low-res. (128× 128) Bicubic (256× 256)
Super-resolved (256× 256) Ground truth (256× 256)
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 50 / 54
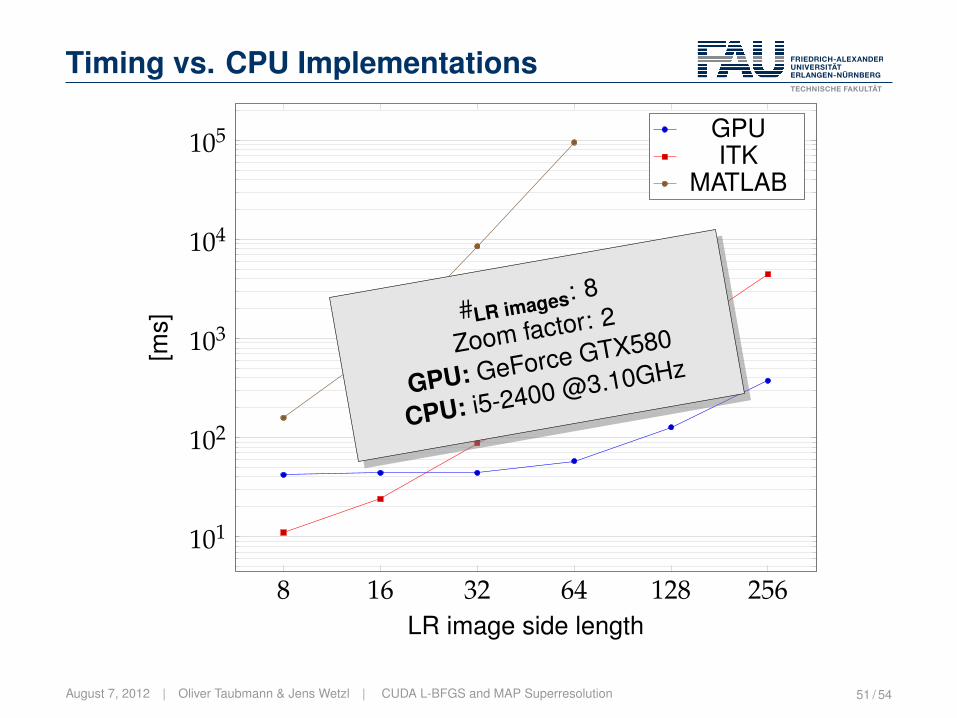
Timing vs. CPU Implementations
8 16 32 64 128 256
101
102
103
104
105
LR image side length
[ms]
GPUITK
MATLAB
#LR images: 8
Zoom factor: 2
GPU: GeForce GTX580
CPU: i5-2400 @3.10GHz
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 51 / 54
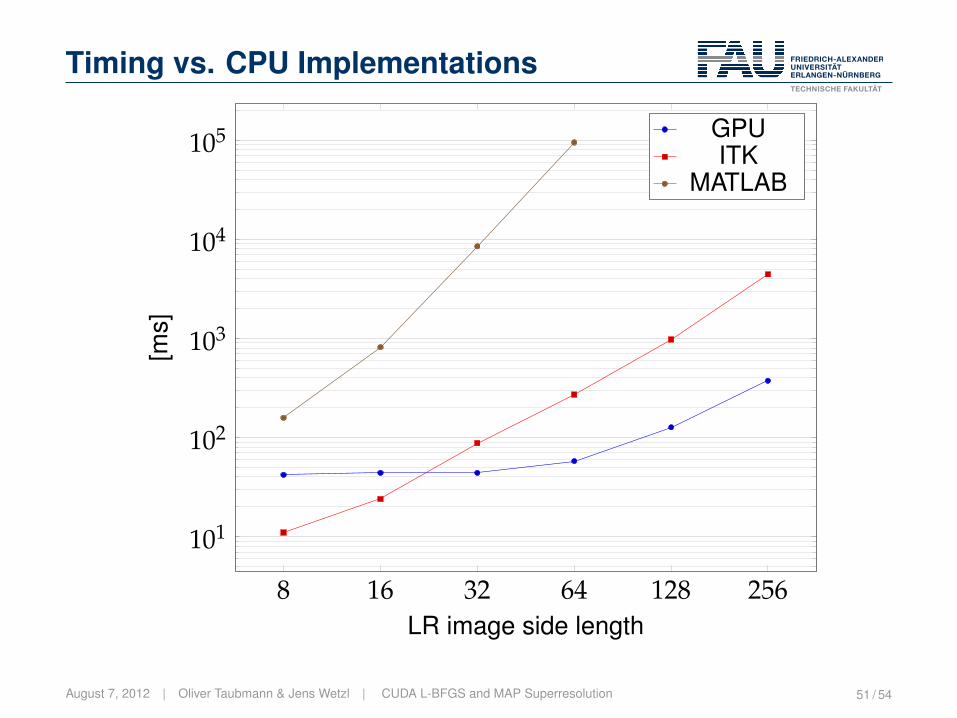
Timing vs. CPU Implementations
8 16 32 64 128 256
101
102
103
104
105
LR image side length
[ms]
GPUITK
MATLAB
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 51 / 54
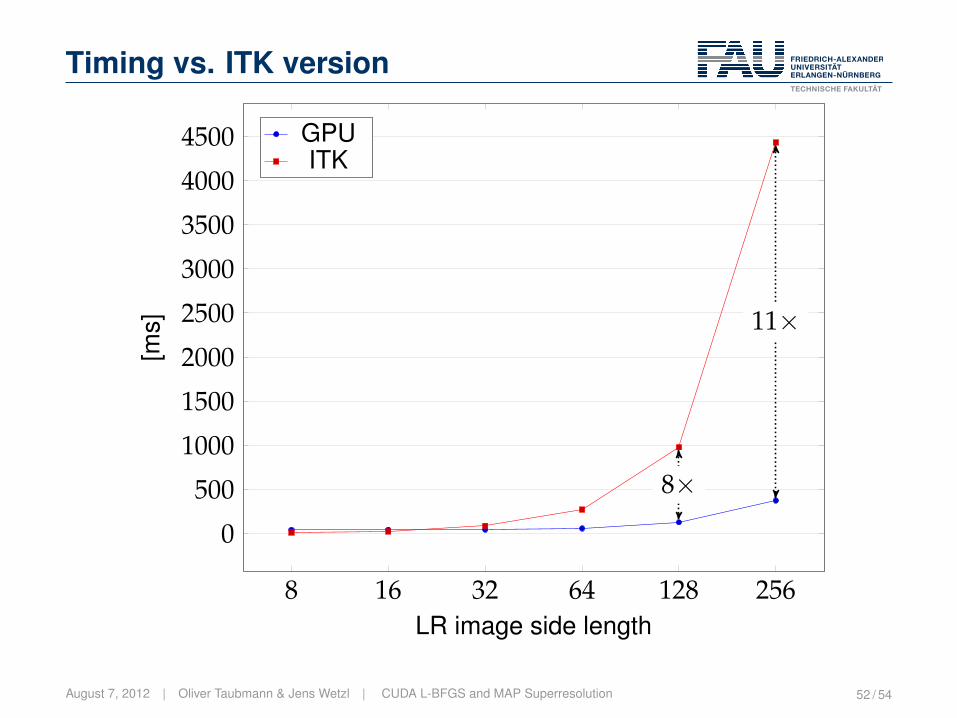
Timing vs. ITK version
8 16 32 64 128 256
0
500
1000
1500
2000
2500
3000
3500
4000
4500
8×
11×
LR image side length
[ms]
GPUITK
August 7, 2012 | Oliver Taubmann & Jens Wetzl | CUDA L-BFGS and MAP Superresolution 52 / 54

Questions?

Thanks for listening!

















