31
Current Situation and Future Plans Abdelrahman Al-Ogail & Omar Enayet October - 2010 Real-Time Strategy Artificial Intelligence Research
| Date post: | 28-Dec-2015 |
| Category: |
Documents |
| Upload: | clementine-chase |
| View: | 217 times |
| Download: | 0 times |

Current Situation and Future Plans
Abdelrahman Al-Ogail & Omar Enayet
October - 2010
Real-Time Strategy Artificial Intelligence
Research

What do we do.What did we achieve till now.The Engine.The Paper.The Future.
Short Term Goals.Long Term Goals.
Agenda

What do we do

AI Learning
Make the machine learn.
AI Planning
Plan then re-plan according to new
givens.
Knowledge
SharingLet everyone know instantly what you
knew through experience.
PROJECT RESEARCH AREA

Experience Loss Static Scripts
Computer AI relies on static scripting
techniques.
The Absence of sharing experience costs a lot
PROBLEM DEFINITION

Adaptive A.I.
Making the Computer Opponent adapt to
changes like human do.
Mobile Experience
Import/Export your experience !
OBJECTIVES

RTS GamesReal-Time Strategy Games.
Severe Time Constraints – Real-Time AI – Many Objects – Imperfect Information – Micro-Actions
PROJECT DOMAIN

Robotics
For interest for military which uses
battle simulations in training programs.
War Simulation
For the corporation of robots.
Experimental Relevance
They constitute well-defined environments
to conduct experiments.
MOTIVATIONS
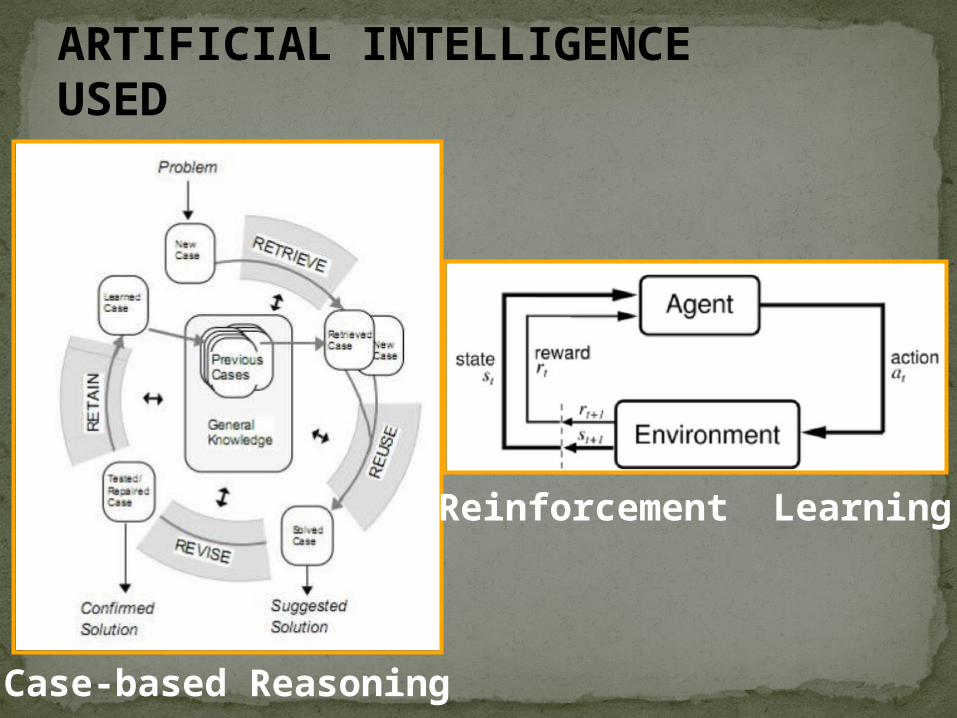
ARTIFICIAL INTELLIGENCE USED
Case-based Reasoning
Reinforcement Learning

What did we achieve till now

Developed the engine with its basic stuff.Graduation Project, Excellent Degree.Participated with a booth in ICT’10 with the GP.Project was funded by ITIDA.Another graduation project & more than a
master thesis are being done to extend our work in Ain-Shams University.
Published a paper in ISDA’10Had Contact with researchers on this field all
over the world.
What did we achieve till now

Maintaining the project bloghttp://rtsairesearch.wordpress.com/
Maintaining the project repository:Our research stuff repository: http://rtsairesearch.googlecode.com/
I-Strategizer (Engine’s code): http://istrategizer.googlecode.com/
Maintaining our own blogs:
OmarsBrain.wordpress.com (Omar Enayet)
AbdelrahmanOgail.wordpress.com (Abdelrahman Al-Ogail)
What did we achieve till now (Cont’d)

The Future

Adding new theory in the area of “Simulation of Human Behavior”.
Developing a commercial AI Engine for RTS Games specifically and games in general. We already started and we have quite experience in game development.
Participate in related contests around the world for AI Engines in RTS Games (As Robocup, AAAI Starcraft Competition, ORTS Competition).
Initializing a major research group in Egypt in this field and become pioneers in it world wide.
The Future – Long-term Goals

Enhancing current engine which will efficiently be able to plan and learn when playing against static AI
Use it as a test-bed to publish a number of papers: 1- Introducing the whole Agent model and theory in AI related
conference.2- Introducing the whole AI Game Engine from a game industry point of view in a game-industry conference.3- More Details & Testing concerning the hybridization of Online Case based Planning and Reinforcement Learning ( the topic of our last paper)4- Knowledge representation for plans and experience in RTS games.5- Enhancing agent’s situation assessment algorithm.
Publishing a paper concerning : Comparing Case-Based Reasoning to Reinforcement Learning.
The Future – Short-term Goals

Include different planning algorithms/systems and let agent use them and make an intensive comparison between these panning systems.
Include different learning algorithms/systems and let agent use them and make an intensive comparison between these learning systems.
Multi-Agent AI : machine collaboration with other machines, or machine collaboration with human players.
Knowledge (Gaming Experience) Sharing.Opponent Modeling.
The Future – Long-term Papers’ Topics

The Engine

Named “I-Strategizer”.Based on an open-source RTS game engine
called “Stratagus”.Currently tailored to serve an open source
game Wargus .(clone of an old popular game called Warcraft 2 )
Still needs a lot of research and development for simulating human behavior and making it generic for strategy games.
Coded in C++ and LUA scripts.
The Engine
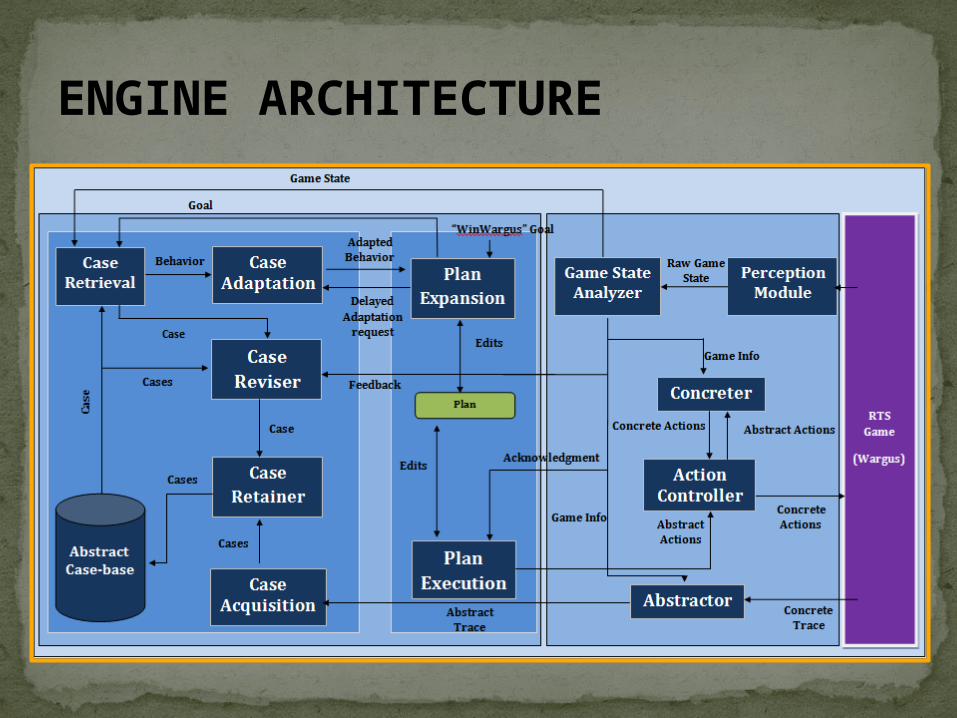
ENGINE ARCHITECTURE

The Paper

Abstract—Research in learning and planning in real-time strategy (RTS) games is very interesting in several industries such as military industry, robotics, and most importantly game industry. A recent published work on online case-based planning in RTS Games does not include the capability of online learning from experience, so the knowledge certainty remains constant, which leads to inefficient decisions. In this paper, an intelligent agent model based on both online case- based planning (OLCBP) and reinforcement learning (RL) techniques is proposed. In addition, the proposed model has been evaluated using empirical simulation on Wargus (an open-source clone of the well known RTS game Warcraft 2). This evaluation shows that the proposed model increases the certainty of the case base by learning from experience, and hence the process of decision making for selecting more efficient, effective and successful plans.
Keywords- Case-based Reasoning; Reinforcement Learning; Online Case-based Planning; Real-Time Strategy Games; Sarsa (λ) Learning; Eligibility Traces; Intelligent Agent.
The Paper -Abstract

The Problem :Learning from human then no learning from experience.Our Solution :Learning from experience is maintained through Reinforcement Learning (RL) .
Old Approach :Online Case-Based Planning (OLCBP)Our Approach :Hybridizing OLCBP with RL .
The Paper -Introduction

OLCBP ?Other approaches done to hybrid CBR with
RL.
The Paper -Background

The Paper –Intelligent OLCBP Model

We used an RL Temporal-difference learning approach: SARSA(λ) Learning
According to certain rules, SARSA(λ) Learning and interactions from the environment, the certainty value of cases in the case-base change -> Thus Learning from experience occurs.
The Paper –The Hybridization

The Paper –The Test-Case

The Paper –The Results

Agent has learnt that building a smaller heavy army in that specific situation (the existence of a towers defense) is more preferable than building a larger light army. Similarly, the agent can evaluate the entire case base and learn the right choices.
The Paper –The Results (Cont’d)

Online case-based planning was hybridized with reinforcement learning in order to introduce an intelligent agent capable of planning and learning online using temporal difference with eligibility traces: Sarsa (λ) algorithm. The empirical evaluation has shown that the proposed model –unlike Darmok System - increases the certainty of the case base by learning from experience, and hence the process of decision making for selecting more efficient, effective and successful plans.
The Paper –Conclusion

Implementing a prototype based on the proposed model.
Developing a strategy/case base visualization tool capable of visualizing agent’s preferred playing strategy according to its learning history. This will help in tracking the learning curve of the agent.
Finally, designing and developing a multi-agent system where agents are able to share their experiences together.
The Paper –Future Work

Thank you !

















