Remote Accessibility to Diabetes Management and Therapy in Operational healthcare Networks. REACTION (FP7 248590) D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture Date 2012-03-05 Version 2.0 Dissemination Level: Public Legal Notice The information in this document is subject to change without notice. The Members of the REACTION Consortium make no warranty of any kind with regard to this document, including, but not limited to, the implied warranties of merchantability and fitness for a particular purpose. The Members of the REACTION Consortium shall not be held liable for errors contained herein or direct, indirect, special, incidental or consequential damages in connection with the furnishing, performance, or use of this material. Possible inaccuracies of information are under the responsibility of the project. This report reflects solely the views of its authors. The European Commission is not liable for any use that may be made of the information contained therein.
Transcript
Remote Accessibility to Diabetes Management and Therapy in Operational healthcare Networks.
REACTION (FP7 248590)
D4-1 State of the Art: Concepts and Technology for a unified data fusion
architecture
Date 2012-03-05
Version 2.0
Dissemination Level: Public
Legal Notice The information in this document is subject to change without notice. The Members of the REACTION Consortium make no warranty of any kind with regard to this document, including, but not limited to, the implied warranties of merchantability and fitness for a particular purpose. The Members of the REACTION Consortium shall not be held liable for errors contained herein or direct, indirect, special, incidental or consequential damages in connection with the furnishing, performance, or use of this material. Possible inaccuracies of information are under the responsibility of the project. This report reflects solely the views of its authors. The European Commission is not liable for any use that may be made of the information contained therein.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
3. Data fusion architecture ........................................................................................................12 3.1 Data fusion in REACTION .................................................................................................12
3.1.1 Terms and reference................................................................................................13 3.1.2 How to define data fusion for the REACTION project .............................................13 3.1.3 The need of a formal data fusion framework ...........................................................14
3.2 Current approaches to data fusion and architecture .........................................................16 3.2.1 Architecture types ....................................................................................................16 3.2.2 Modelling an architecture with respect of REACTION .............................................17 3.2.3 Data fusion requirements .........................................................................................19 3.2.4 Processing of data in sensor networks ....................................................................19
3.3 Collecting physiological measurements from personal health devices .............................20 3.4 Collecting physiological measurements from body worn sensors .....................................21 3.5 Collecting contextual data ..................................................................................................23
3.6 Security and privacy ..........................................................................................................25 3.6.1 Security ....................................................................................................................26 3.6.2 Privacy .....................................................................................................................27 3.6.3 ISO 27799 ................................................................................................................28 3.6.4 ASTM F2761-09 .......................................................................................................28
4. Models, ontology and terminology.......................................................................................29 4.1 Introduction ........................................................................................................................29 4.2 Data modelling ...................................................................................................................29
4.2.1 Semantic annotation/tagging ...................................................................................30 4.2.2 Object oriented data models ....................................................................................31 4.2.3 RDF data model .......................................................................................................31
5. Standards relevant for data fusion .......................................................................................38 5.1 Health Level Seven international (HL7) .............................................................................40
5.1.1 IEEE 11073 ..............................................................................................................41 5.1.2 ISO/TC 215 ..............................................................................................................43 5.1.3 ISO/TC 251 WG IV ..................................................................................................44 5.1.4 ASTM E2182-84 Standards .....................................................................................45 5.1.5 Continua Health Alliance .........................................................................................45
5.2 In-hospital care and towards the EHR ...............................................................................46 5.2.1 CEN 13606 ..............................................................................................................46 5.2.2 HISA .........................................................................................................................47 5.2.3 Integrating the Healthcare Enterprise (IHE).............................................................48
6. Technologies for semantic management of data and services ........................................49 6.1 Semantic management in middleware ..............................................................................49
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 3 of 91 DATE 2012-03-05
6.1.2 Semantic interoperability .........................................................................................50 6.2 SOA ...................................................................................................................................50 6.3 Hydra Middleware ..............................................................................................................51 6.4 REACTION data and the cloud..........................................................................................53
7. Knowledge discovery and data mining ...............................................................................55 7.1 From data to knowledge ....................................................................................................55 7.2 The role of Data Quality .....................................................................................................56 7.3 Data mining tasks ..............................................................................................................57
7.4 The Knowledge Discovery process ...................................................................................58 7.5 Knowledge discovery for diabetes .....................................................................................62 7.6 Methods for data mining ....................................................................................................62
7.6.1 Exploratory data analysis .........................................................................................62 7.6.2 Statistical approaches to estimation and prediction ................................................63 7.6.3 The k-nearest neighbour algorithm ..........................................................................63 7.6.4 Decision trees ..........................................................................................................64 7.6.5 Neural networks .......................................................................................................64 7.6.6 Kohonen networks ...................................................................................................65 7.6.7 Hierarchical and k-means clustering ........................................................................65 7.6.8 Finding association rules .........................................................................................65 7.6.9 Patient rule induction ...............................................................................................66
7.7 Text mining /knowledge discovery from free text ..............................................................66
8. Conclusions: towards a unified data fusion architecture ..................................................71 8.1 EU projects ........................................................................................................................78
8.3 Libraries .............................................................................................................................89 8.3.1 Open Health Tools: ..................................................................................................89 8.3.2 Morfeo Project: .........................................................................................................90 8.3.3 The Open Healthcare Group ...................................................................................90 8.3.4 Zephyropen ..............................................................................................................90
8.4 Development tools and frameworks ..................................................................................90 8.4.1 .NET Micro Framework ............................................................................................90 8.4.2 Open Healthcare Framework (OHF) for Eclipse: .....................................................91 8.4.3 LinkEHR ...................................................................................................................91
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 4 of 91 DATE 2012-03-05
Figures and Tables
Figures
FIGURE 1 SHOWING THE REACTION PLATFORM WITH ITS ADJACENT SPHERES. ............................................................ 8 FIGURE 2 REACTION ABSTRACTION LEVELS AND FLOWS. ............................................................................................ 10 FIGURE 3 FIVE TYPES OF CLOSED-LOOP APPLICATIONS IN REACTION WHICH ALL INTERLACE THROUGH INFORMATION
EXCHANGE: 1) BAN 2) PAN 3) APPLICATIONS INVOLVED IN REACTION PLATFORM 4), INFORMAL CARES AND 5)
HIS BACKEND. .......................................................................................................................................................... 12 FIGURE 4 EXAMPLE OF THE REACTION PLATFORM SEEN FROM A FORMAL FRAMEWORK PERSPECTIVE IN A DATA
FUSION SYSTEM (MITCHELL 2007). ......................................................................................................................... 15 FIGURE 5 SHOWING HOW TO CONCEPTUALISE A DATA FUSION FRAMEWORK BY CLASSES IN A HEALTHCARE DOMAIN
SUCH AS REACTION. ............................................................................................................................................. 16 FIGURE 6 SHOWING THE THREE DIFFERENT DATA FUSION ARCHITECTURE TYPES. ........................................................ 17 FIGURE 7 A SCHEME OF THE AGC ALGORITHM IN REACTION. .................................................................................... 21 FIGURE 8 DEMONSTRATION OF THE DELTA EPATCH SENSOR. ....................................................................................... 22 FIGURE 9 THE FITBIT SENSOR MEASURING USER ACTIVITY. ........................................................................................... 24 FIGURE 10 FROM DATA TO KNOWLEDGE. ........................................................................................................................ 29 FIGURE 11 SEMANTIC MODEL OF PHYSIOLOGICAL MEASUREMENTS............................................................................... 30 FIGURE 12 SEMANTIC ANNOTATION WITH ONTOLOGY AS SEMANTIC REPOSITORY. ........................................................ 31 FIGURE 13 BLOOD GLUCOSE GRAPH. .............................................................................................................................. 32 FIGURE 14 A GENERIC EHEALTH PLATFORM THAT SHOWS THE INFORMATION FLOWS FROM FOUR PARTIES INCLUDING
SOME STANDARD SETTING INTERFACES. .................................................................................................................. 38 FIGURE 15 A SIMPLIFICATION OF THE REACTION PLATFORM CONCEPT SHOWING PRIMARY STANDARD PATHWAYS
WITH AIMED (BLUE AND RED) DELIVERY END POINTS. .............................................................................................. 39 FIGURE 16 RADIOLOGY DATA. ......................................................................................................................................... 41 FIGURE 17 PAN INTERFACE (FROM CONTINUA DESIGN GUIDELINES V1.5). ................................................................. 42 FIGURE 18 OBJECT MODEL FOR WEIGHING SCALE FOLLOWING IEEE 11073-10415:2008. ....................................... 43 FIGURE 19 SHOWING THE ISO/TC215 WORKGROUP DIAGRAM. ..................................................................................... 44 FIGURE 20 INCORPORATION OF DEVICES USING THE HYDRA MIDDLEWARE. .................................................................. 51 FIGURE 21 SHOWING AN EARLY EXAMPLE OF APPLIED REACTION HYDRA MIDDLEWARE SOLUTION BASED ON THE
CONTINUA AHD. ....................................................................................................................................................... 52 FIGURE 22 MICROSOFT HEALTHVAULT PLATFORM AND VARIOUS ONLINE SERVICES. ................................................... 54 FIGURE 23: FROM DATA TO KNOWLEDGE. ....................................................................................................................... 55 FIGURE 24: A SIX-STEP KDDM PROCESS MODEL. DASHED ARROWS ILLUSTRATE POSSIBLE ITERATIONS. .................. 61 FIGURE 25 STRUCTURE OF SIR. ..................................................................................................................................... 69 FIGURE 26: EXAMPLE OF AN ONTOLOGY CAPSULE. ........................................................................................................ 70 FIGURE 27 REACTION SOA MODEL WHERE DATA FUSION AT CLIENT SIDE SHAPES THE WAY DATA IS MANAGED BY
SERVICE ORCHESTRATION AT SERVER SIDE............................................................................................................. 72 FIGURE 28 SHOWING METABO PROCESSES AND HOW THE SYSTEM INTERPRETS THESE DATA ESTABLISHING
RELATIONSHIPS AMONG THE REPORTED ACTIVITIES AND THE METABOLIC STATUS OF THE USERS. ....................... 78 FIGURE 29 SHOWING THE DIADVISOR INFORMATION FLOWS. ......................................................................................... 79 FIGURE 30 THE TUNSTALL MOBILE ALARM DEVICE. ........................................................................................................ 80 FIGURE 31 SHOWING A SCHEME OVER THE HEARTCYCLE CONTEXT AGGREGATION. ..................................................... 82 FIGURE 32 TELEMEDIS SYSTEM LAYOUT. ....................................................................................................................... 84 FIGURE 33 SHOWING THE OPENEHR SERVICE ARCHITECTURE. ..................................................................................... 85 FIGURE 34 SHOWING THE COMMON PLATFORM COMPONENTS IN HEALTHDESIGN. ....................................................... 86 FIGURE 35 COBRA ARCHITECTURAL STRUCTURE FOR AGENTS AND SMART SPACES.................................................... 87 Tables TABLE 1 BLOOD GLUCOSE XML. ..................................................................................................................................... 32 TABLE 2 BLOOD GLUCOSE PLAIN TEXT. ........................................................................................................................... 32 TABLE 3 BLOOD GLUCOSE SPARQL QUERY. ................................................................................................................. 32 TABLE 4 DUAL LITERAL CLASS PROPERTIES OF BLOOD GLUCOSE. ................................................................................. 33 TABLE 5 OWL REPRESENTATION OF FORMER RDFS CLASS. ........................................................................................ 33 TABLE 6 IEEE 11073 PERSONAL HEALTH DEVICE STANDARDS.................................................................................... 43 TABLE 7 EXAMPLE OF WEIGHING SCALE IHE OBSERVATION REPORT. ............................................................................ 48
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
& Stephan Spat (FHG-SIT), Eugenio Mantovani (VUB) Verified and approved by
Work Package WP4
Fragment No
Distribution List All
Abstract
This report provides a state of the art description and analysis of the models, technologies and standards in the context of the REACTION Data Management requirements. It outlines the initial architecture for the data management subset of the REACTION platform.
Comments and modifications First internal version was delivered at month 6. Final version due M24.
Status
Draft
Task leader accepted
WP leader accepted
Technical supervisor accepted
Medical Engineering supervisor accepted
Medical supervisor accepted
Quality manager checked
Project Coordinator accepted
Action requested
to be revised by partners involved in the preparation of the deliverable
for approval of the task leader
for approval of the WP leader
for approval of the Technical Manager
for approval of the Medical Engineering Manager
for approval of the Medical Manager
for approval of the Quality Manager
for approval of the Project Coordinator Deadline for action: N/A
Keywords
References
Previous Versions
Version Notes
Version Author(s) Date Changes made
0.1 Stefan Asanin 2010-04-25 Initial version
0.5 Stefan Asanin 2010-06-22 First draft
0.9 Stefan Asanin 2010-08-15 Second draft
1.0 Stefan Asanin 2010-08-31 First internal version
1.1 Stefan Asanin 2010-10-11 Revised version
1.2 Peter Rosengren 2012-02-20 Restructuring document
2012-02-21 Adding chapter on knowledge discovery and data mining
1.4 Stefan Asanin 2012-02-29 Revised version
2.0 Stefan Asanin 2012-03-05 Final version submitted to the European Commission
Internal review history
Reviewed by Date Comments made
Manolis Spanakis (FORTH) 2012-03-05 Comments and suggestions
Antonis Miliarakis (FORTHNET) 2012-03-05 Minor corrections and comments
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 6 of 91 DATE 2012-03-05
1. Executive Summary
The aim of this document is to survey and evaluate the state of the art in models, technologies and standards in the context of the REACTION Data Management requirements and service architecture. It includes healthcare standards for messaging and health data representation as well as current approaches to and the adoption of the HISA (Health Informatics Service Architecture) standard across the EU. Further, investigations are undertaken into the work of the Continua Health Alliance working groups on architecture and interfaces as well as on the application of ontologies to medical terminology and HIS and CIS interoperability. The most important standards groupings in Health Informatics have been selected for future liaisons with the REACTION project.
The REACTION project aims to develop a technological platform and pilot applications to improve long term diabetes management in inpatient and outpatient environments. Features of the technology include continuous blood glucose monitoring, monitoring of significant events, monitoring and predicting risks and/or related disease indicators, decision on therapy and treatments, education on life style factors such as obesity and exercise and, ultimately, automated closed-loop delivery of insulin. For unified data fusion architecture this means taking into account the dispersed sources of knowledge and expertise but also the measurements gathered by each sensor and the environmental (context) data in order to give a meaningful interpretation by semantic management.
This deliverable's focus is therefore complemented by an evaluation of the relevant generic technologies for messaging protocols, data fusion and mediator architectures, service oriented architectures (SOA) and novel technologies for semantic management of data and services.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 7 of 91 DATE 2012-03-05
2. Introduction
This deliverable introduction will start by giving a brief background on diabetes and the concept of eHealth as a preamble for introducing the REACTION project. The introduction on the REACTION project will explain how data fusion could be adopted within the project platform and further discusses the different user and platform spheres and finally what roles they perform in the project. At the end of this section stating there is a state of the purpose, context and scope of the deliverable and the overall report outline.
2.1 Background
Diabetes
As diabetes is the fourth leading cause of death in Europe, as well as being a risk factor for other diseases, notably cardiovascular diseases, it makes the rapid increase in diabetes in Europe a major public health issue. The enlarging European Union provides a timely opportunity to examine the scale of the diabetes problem. Over 60 million people live with diabetes in Europe, many of these people unaware of their condition. This emphasises the need to place diabetes as a priority disease in both national health policy and at a European level. This is especially so given that the cost of diabetes complications accounts for 5-10% of total healthcare spending in several countries including Belgium, France, Germany, Italy, the Netherlands, Spain, Sweden and the UK.
Diabetes mellitus itself is a metabolic disorder characterised by hyperglycaemia (high blood sugar) resulting from defects in the production of or in the body's response to insulin. Disease management entails administration of insulin in combination with careful blood glucose monitoring. The overall health status of type 2 diabetics can be improved by adequate treatment of diabetes and of the associated risk factors. Self-management of diabetes in which the patient measures blood glucose several times a day and uses the resultant data to gauge the required insulin dosage is a promising modality. Tight Glucose control (TGC) requires almost continuous measurements and different sensors for continuous blood glucose measurement have been under development for the last two decades. Minimally invasive sensors able to measure glucose in interstitial fluid, and thus more suitable for self-monitoring, have also been developed. To date, however, none of these has delivered a level of performance sufficient for use in routine glucose monitoring. Robust, clinically acceptable devices are however widely expected to become available in the near future (International Diabetes Federation, 2004).
2.2 Introducing the REACTION project
The REACTION project will develop an integrated approach to improve long term management of diabetes, continuous blood glucose monitoring, clinical monitoring and intervention strategies, monitoring and predicting related disease indicators, complemented by education on life style factors such as obesity prevention and exercise and, ultimately, automated closed-loop delivery of insulin. REACTION project is about to utilize many partner’s expertises within the FP7 integrated research programme ranging from microelectronics, acoustics, optics, biomedical analysis, medical and nursing research, semantic technologies for content and knowledge management, health informatics, information security, etc. Therefore, the REACTION platform has the potential to become a Europe-wide eHealth service platform for improved glycaemic control of diabetes patients whether admitted to hospital, in an outpatient programme or just coping with their disease in their daily lives.
With previous subchapter in mind, the REACTION project has very clear objectives for overcoming the deployment obstacles inherent in previous programmes by taking a holistic view and pay proper consideration to all aspects of this complex issue. The REACTION project will demonstrate a stable yet technologically highly innovative platform by using the right blend of mainstream proven technologies (backend health information systems, wireless technologies), new innovative solutions based on proven research experience (PAN networking and interoperability) as well as state-of-the art technological solutions developed during the course of other projects (ePatch multi sensors, semantic web annotations, networked systems middleware). REACTION will seek to influence important standardisation work in bodies such as ISO TC215 WG 7 (Medical devices), CEN TC251 WG IV (interoperability), IEEE PHD (personal health data) interfaces and security (WWRI) as well as Continua Health Alliance working groups on architectures through its active partners in these bodies.
The REACTION platform, Figure 1, is conceived to support the needs of its users in each of the depicted spheres. It is therefore designed as a modular architecture in order to provide flexibility and expansion and, where possible, be interoperable with existing systems and support interoperability (according to the IEEE,
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 8 of 91 DATE 2012-03-05
interoperability is defined as the ability of two or more systems or components to exchange information and to use the information that has been exchanged (IEEE Dictionary of Standards 1990)) with forthcoming systems. The REACTION platform is to be designed to support the management of multiple diseases, as many patients have co-morbidities, and to be effective, REACTION will have the opportunity to monitor and support management of these diseases, in addition to diabetes. REACTION will therefore not develop all the sensors for use in the project; rather it will exploit existing sensors where available, and integrate these and the sensors developed within the REACTION project into the common platform. Where possible, sensors following standards will be used. This implies that the REACTION platform should be based on standards to support these sensors, and provide interoperability with external devices and systems. It further implies that sensors developed within the REACTION project should follow the same standards to create a homogeneous system.
Figure 1 showing the REACTION platform with its adjacent spheres.
Analysis of state of the art will therefore concentrate on the efforts to develop and integrate standards for the design of the overall system architecture, as well as standards for specific parts of the system. The main features of the REACTION platform are summarized as follows:
The Patients Sphere
In the Patient’s Sphere, physiological and environmental monitoring collects data that can be used to characterise the condition of the patient. Data will come from a variety of sensors able to measure physiological data on an episodic or continuous basis. Continuous measurement may be achieved through wearable medical sensors connected via a Body Area Network (BAN) for multi-parametric recording of vital physiological parameters and will include sensors for continuous monitoring of blood glucose. Episodic data will be collected from sensors using the same wireless infrastructure or be wired into the system as appropriate.
The REACTION platform
The REACTION platform provides the central production environment for the deployment of REACTION applications. It consists of five layers, each providing a key functionality to support the overall platform.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 9 of 91 DATE 2012-03-05
The Application layer provides the environment within which REACTION applications can be supported and developed. Applications are developed and deployed to execute complex tasks. Each application serves specific goals and is constructed from a series of standardised workflows. Applications are developed and stored in the form of conceptual domain models. The domain model describes the service, the objects involved (devices, users, rule sets, repositories, etc). A standard approach is required to describe the domain taxonomy (see more in chapter 4.4). The common domain model will be mapped to an operative data model, which is implemented in the Service Layer. It will provide an open SDK for model-driven development of applications that use the REACTION platform.
The Service layer provides functionality to translate applications into service components. Each workflow in the application consists of a series of services. The services are structured into an operative data model, which requires a standard method of representation, such as through XML schemas and data access interfaces, which might include a subset of HL7 or a set of Web Services. The service ontology presents high level concepts describing service related information, which will be used in both development and run-time processes. Since each device, person and repository is represented as an object that is accessible as a service, the service device ontology enables a developer to create new instances for any device type, which are filled with real data at run time. A set of services will be developed for monitoring, feedback, alarm handling, user interaction, etc.
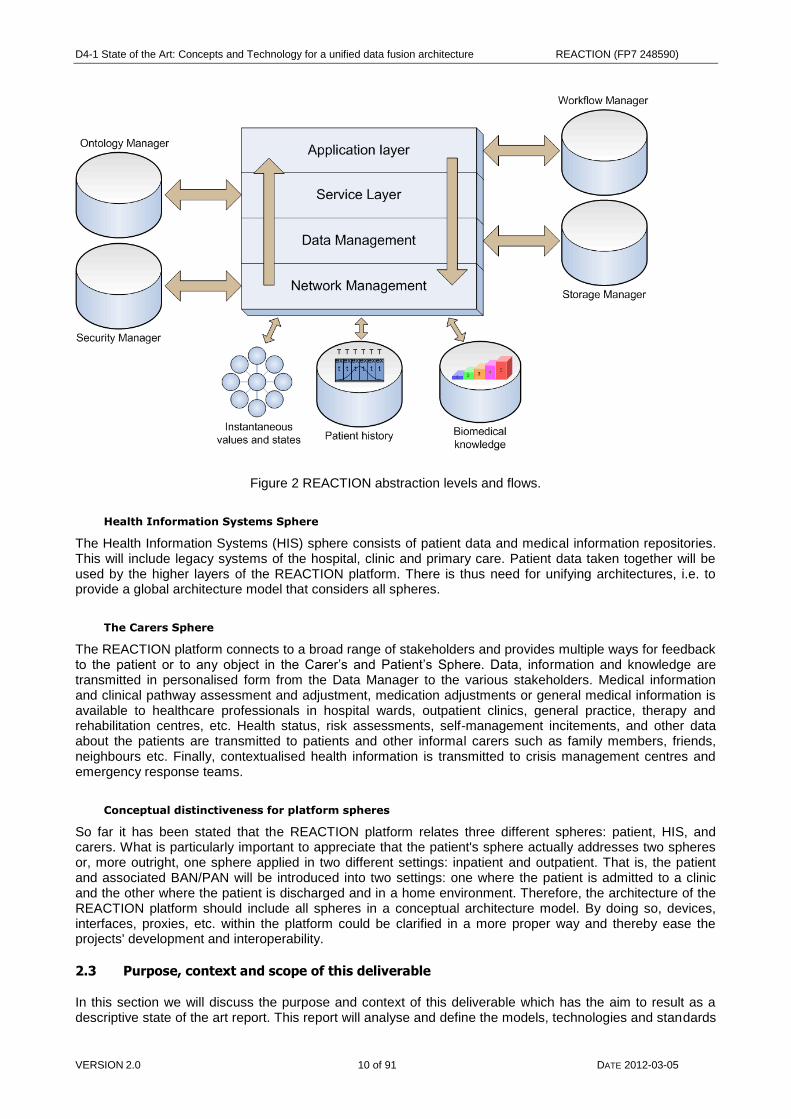
The Data Management layer is central to the high level functioning of applications and services deployed on the platform. It implements the model-driven architecture for application development and deployment, the service oriented architecture for core service functionalities, data manipulation, data fusion and event handling. It also manages data transfer to and from nodes and stakeholders in a REACTION environment. It will interact with the Health Information Systems sphere through standardised health data exchange interfaces. These interfaces constitute a Personal Area Network (PAN) that will connect the patient to loosely coupled ambient sensors. Communication protocols with built-in reflective properties (such as Bluetooth and ZigBee) will be preferred, but other communication protocols will be supported. The PAN node will then be used for data fusion and inference. Data will be combined with descriptive context data such as GPS data, ambient temperature, human activity indicators, etc. and fused to Data Management. Seamless integration will be achieved using a middleware developed in the FP6 project Hydra which will turn each device into a Web Service that proxy the functionality of the device. The Hydra middleware employs semantic technologies and automatically detects physical devices irrespective of their underlying communication protocol (it supports Bluetooth, ZigBee, RFID, RF, Wi-Fi, Serial port and many more). Through the use of device ontologies the middleware resolves the type of device that has been detected and automatically creates a web service interface that allows other devices and applications to use and control the device. Data manipulation may take the form of linearization, extrapolation, interpolation, extraction or contraction, reformatting etc. Translation between state domain and time domain is also performed here. The challenge is to identify, develop, and implement the computer algorithms needed to support the clinical workflows. Data Management may also invoke extended services for special tasks and services that query healthcare professionals for intervention and decisions. It also provides more advanced querying functionality hard coded in specific Web-Service methods. The queries are implemented in the SPARQL language. Context awareness is achieved through semantic annotation of patients' device data, data coming from the environment, and data from the patients' historical information in EPR repositories. The backend knowledge discovery processes will be implemented using Semantic Web Services to prove an automated environment for executing services and applications. Through its data management layer, the REACTION platform can support both distributed and centralised services for decision support. Distributed monitoring and decision support is typically used for monitoring of the patient health status at the point of care. Distributed decision support is essential in critical services such as event handling, when connectivity is not guaranteed. It is anchored in the Personal Area Network and can support decision making among patients and informal carers. Centralised decision support involves querying established biomedical knowledge and expertise to derive clinically relevant information and risk assessment based on the contextualized medical data and patient history. The centralised decision support is anchored in the Data Management subset. All in all, in the data management layer and its subsets, data fusion implementation is essential in order to achieve such effective and desired extraction of contextual and meaningful data. This layer is therefore to be main subject of this deliverable.
The Network Management layer is responsible for the physical communication between devices, persons and external repositories.
Security Management layer is implemented throughout all the layers and will perform mapping and brokering between security models, user and client devices, profiling management, semantic standards and generalisation ontologies development.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 10 of 91 DATE 2012-03-05
Figure 2 REACTION abstraction levels and flows.
Health Information Systems Sphere
The Health Information Systems (HIS) sphere consists of patient data and medical information repositories. This will include legacy systems of the hospital, clinic and primary care. Patient data taken together will be used by the higher layers of the REACTION platform. There is thus need for unifying architectures, i.e. to provide a global architecture model that considers all spheres.
The Carers Sphere
The REACTION platform connects to a broad range of stakeholders and provides multiple ways for feedback to the patient or to any object in the Carer’s and Patient’s Sphere. Data, information and knowledge are transmitted in personalised form from the Data Manager to the various stakeholders. Medical information and clinical pathway assessment and adjustment, medication adjustments or general medical information is available to healthcare professionals in hospital wards, outpatient clinics, general practice, therapy and rehabilitation centres, etc. Health status, risk assessments, self-management incitements, and other data about the patients are transmitted to patients and other informal carers such as family members, friends, neighbours etc. Finally, contextualised health information is transmitted to crisis management centres and emergency response teams.
Conceptual distinctiveness for platform spheres
So far it has been stated that the REACTION platform relates three different spheres: patient, HIS, and carers. What is particularly important to appreciate that the patient's sphere actually addresses two spheres or, more outright, one sphere applied in two different settings: inpatient and outpatient. That is, the patient and associated BAN/PAN will be introduced into two settings: one where the patient is admitted to a clinic and the other where the patient is discharged and in a home environment. Therefore, the architecture of the REACTION platform should include all spheres in a conceptual architecture model. By doing so, devices, interfaces, proxies, etc. within the platform could be clarified in a more proper way and thereby ease the projects' development and interoperability.
2.3 Purpose, context and scope of this deliverable
In this section we will discuss the purpose and context of this deliverable which has the aim to result as a descriptive state of the art report. This report will analyse and define the models, technologies and standards
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 11 of 91 DATE 2012-03-05
relevant in the context of the REACTION data management subsets and thereby assemble and outline the initial architecture for the data management of the REACTION platform.
2.3.1 Purpose and context
The purpose in this deliverable is to survey and evaluate the state of the art in models, technologies and standards in the context of the REACTION Data Management requirements and service architecture. The Data Management subset is basically a runtime environment that transforms data into information. It also performs data manipulation and conditioning, translation between state domain and real time domain, simple data analysis, queries, contextualisation of data, and fusion of data to the next node. Therefore, another purpose of this deliverable is to address, in the context of REACTION abstraction levels and nodes, how data manipulation and data fusion is to be most properly conceived from an implementation perspective. The work package 4 is thereby initiated by this state-of-the-art survey. The survey will also be used for input to the requirement engineering work and serve as a basis for the subsequent design and development tasks on other WP‟s.
2.3.2 Scope
Its scope includes healthcare standards for messaging and health data representation. Further investigations will be undertaken into the work of the Continua Health Alliance working groups on architecture and interfaces, the current approaches to and the adoption of the HISA (Health Informatics Service Architecture) standard across the EU, as well as on the application of ontologies to medical terminology and HIS and CIS interoperability. This healthcare focus is complemented by an evaluation the relevant generic technologies for messaging protocols, data fusion and mediator architectures, service oriented architectures (SOA) and novel technologies for semantic management of data and services. The work is carried out within Task 4.1. With all standards and messaging protocols reviewed and set as a background, data fusion and SOA models will be screened and put under a technical trial in order to finally be established as a global and interoperable REACTION platform of conformability.
2.4 Report outline
Chapter 3 describe how data fusion of various data sources can be modelled, developed and applied. Chapter 4 goes through the models, ontologies and terminology relevant to the project. Chapter 5 represent standards applicable in both in-hospital, out-patient and a transparent environment. Related projects within EU and outside will be reviewed in chapter 6. In order to be able to determine context out of sources and create a meaningful interpretation chapter 7 will go through the semantic data management used in data fusion. Chapter 8 outlines technical developments tools and resources usable in the REACTION platform. Chapter 9 concludes with a set of design principles for the REACTION data fusion approach and architecture, including initial architecture diagram sketches.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 12 of 91 DATE 2012-03-05
3. Data fusion architecture
Data fusion is an important component of applications for systems that use correlated data from multiple sources to determine the state of a system (Wald 2002). Though, as the state of the system is being monitored and available resources change. Also, it would be useful if the data fusion could dynamically. This change should be based on the current environment and available resources in the system (Carvalho 2003). To avoid this, one need to adopt a proper data fusion architecture which can be reconfigured according to the measured environment and availability of the sensing units or data sources, and thereby provide a graceful degradation in the view of the environment as resources change. The main issue in data fusion can therefore be seen as to provide higher accuracy and improved robustness against uncertainty and unreliable integration by expedient data fusion architecture.
The complexity of modelling and conceptualising a data fusion architecture is a key enabling mechanism where metadata pivot data fusion and govern the challenges mentioned above. Within the next generation of automated healthcare solutions, such the one in REACTION, the core architectural paradigm will be based on semantic data fusion of metadata (i.e. conceptual extraction of sensor parameters, values and contextual information). As metadata usually is stored and managed within individual system stacks, this has also imposed problems for healthcare as the fact that the community of medical knowledge is expanding exponentially and any attempts to centrally manage all types of medical knowledge in one system's metadata framework is bound to fail. The counteraction for this problem is to let the data fusion architecture have the ability to accommodate information that is not originally anticipated and hence provide information normalisation, estimation of parameters and dynamic optimisation. In order to also cover data pre-processing for extraction and any optimal algorithms, an integral part of such an architectural solution would be to offer healthcare interoperability that has the ability to expose the entire set of healthcare data to the holistic practice of medicine, i.e. delivering data where and when it is needed and at the correct level of detail. Once that data is delivered, it must also be placed in the proper context which also is the intention of the semantic data fusion in the REACTION platform. This is, for the REACTION system architecture and its spheres (Figure 1) and its multiple dynamic closed loops (Figure 3), important in order to achieve proper management of dynamic changes in the availability of resources and changes in the environment.
Figure 3 Five types of closed-loop applications in REACTION which all interlace through information
exchange: 1) BAN 2) PAN 3) applications involved in REACTION platform 4), informal cares and 5) HIS backend.
3.1 Data fusion in REACTION
A key objective in the REACTION project is to demonstrate the use of non-invasive and minimally invasive monitoring devices (composing BAN network) together with loosely coupled ambient sensors representing
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 13 of 91 DATE 2012-03-05
descriptive context data such as GPS data, ambient temperature, human activity indicators, etc. (composing a PAN network). Despite technological developments in sensing and monitoring devices, issues related to system integration, sensor miniaturization, low-power sensor interface circuitry design, wireless telemetric links and signal processing still have to be investigated. Moreover, issues related to quality of service, security, multi-sensor data fusion, and decision support are active research topics and presented throughout this deliverable.
An electronic patch is a small body sensor, which senses physiological signals and is embedded in a skin-friendly adhesive. An ePatch (Figure 8) looks like a normal plaster but contains various kinds of miniaturised body sensors for measuring physiological parameters, microelectronics for data analysis, a wireless radio module for communication and a battery power source. ePatch sensors have been developed for applications such as myographic recordings, skin temperature, and skin impedance. The monitoring can encompass multiple ePatches around the body for multi-parametric sensing. Wearable sensors will be connected through a patient centric Body Area Network (BAN). Decentralised decision support at the point-of-delivery (the patient) will be achieved with active nodes/gateways (PDA, Smart Phone operating personalised software bundles in an OSGi framework or Apples iPhone OS 4.2). Communication will be based on standards where possible. A Personal Area Network (PAN) will connect the patient to the coupled ambient sensors. Communication protocols with built-in reflective properties (such as Bluetooth and ZigBee) will be preferred, but other communication protocols will also be supported. The PAN node will be used for data fusion and inference. Data will be combined with descriptive context data such as GPS data, ambient temperature, human activity indicators, etc. and fused to Data Management. Data manipulation may take the form of linearization, extrapolation, interpolation, extraction or contraction, reformatting etc. Translation between state domain and time domain is also performed here. The challenge is to identify, develop, and implement the computer algorithms needed to support both clinical and outpatient workflows. Data Management in the REACTION platform is therefore central to the high level functioning of applications and services deployed on the platform as it will implement a model-driven architecture for application development and deployment, a service oriented architecture, core service functionalities, data manipulation, and data fusion and event handling. Data fusion in the REACTION platform can be seen as an underlying developmental structure that will collect different sensor variables and establish a highly interpretative potential for the data management layer. This layer will by that be enabled to design a device and network-based data fusion/diffusion model from this deliverables adjunct data fusion framework(s) and thereby also in the end be able to provide a semantic integration of a multitude of heterogeneous medical devices and media, information sources, services and communication.
3.1.1 Terms and reference
Before we deepen more into this chapter there is a need of clarifying some terms of definitions within data fusion. There is a working group (EARSeL & SEE) that have made some contributions on the behalf of this. Integration plays a role that more refer to concatenation than extraction of relevant data. Data assimilation comprises measured data into models of e.g. numerical analysis of system behaviour. Measurements are primarily sensor outputs are a sample of its elementary support. Any kind of raw information is treated as a signal. To model data fusion one uses classes. Class features are defined as in Object Oriented Language where attributes or features are an object with rules that define the relationships between objects and their states. Briefly, data fusion of some measurements often results into attributes and likewise attributes result into decisions. Therefore, an object in data fusion is defined by its properties. Data fusion here in this context is then about simulating measurements through a fusion process. By inference models the results derived are then not measurements per se but rather simulated data fusion class attributes. (Lucien 1999). In more simplified words: data fusion in REACTION will mirror the undivulged reality of bodily processes by modelling and object reference of data fusion.
3.1.2 How to define data fusion for the REACTION project
As data fusion is a component within the REACTION platform that use correlated data and represent them as one there is in this section as many definitions of the term data fusion as there are different mathematical tools to implement this process. The concept of process is rather easy to understand but its exact meaning varies among its interpreters and users so that words as merging, combination, synergy and integration can be discriminately heard. Many valid attempts have been made to define data fusion although it at the same time can connote a very wide domain of applicability. These attempts undermine the difficulty of providing a precise definition but some of these found that are in literature are close to complete the definition by heart, for example: data fusion is a set of methods, tools and means using data coming from various sources of different nature, in order to increase the quality of the requested information (Mangolini 1994), and data fusion techniques combine data from multiple sensors, and related information from associated databases,
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 14 of 91 DATE 2012-03-05
to achieve improved accuracy and more specific inferences that could be achieved by the use of a single sensor alone (Hall D 1997). On the other hand and maybe more simplistic, Harvey B. Mitchell, in his book "Multi-sensor data fusion: an introduction" defines data fusion as: the theory, techniques and tools which are used for combining sensor data, or data derived from sensory data, into a common representational format (Mitchell 2007). By his definition, an improvement of the quality of the information is said to be taking place and is better represented than would be possible if the data sources were represented individually.
What is though worthwhile to mention, is that there are two ways of extracting data information from noisy multi-dimensional measurements (i.e. from disperse sensor sources): The first one is called data integration and uses every set of data gathered by a single sensor, to obtain an optimal estimate of some desired state (e.g. a predefined search variable). As there are more sensors, and therefore more sets of data, one could use these to increase the knowledge of the state and to provide an improved estimate. Nevertheless, data integration ignores the possibility of merging data sets into a higher data set (such as proposed by Lee et al., in their Pervasive Healthcare Architecture (Lee 2008)) and processes every set of sensor data on its own. This concept of data processing does not provide optimal estimates because of the waste of the extra information in the additional measurements. In the REACTION platform this would, for example, be beneficial in a diagnosis context where the physician is not sure on what to look for, i.e. what symptoms could be derived from the raw values gathered. Thus, these applications only permit suboptimal performance and the need for optimal estimation finally leads to a more sophisticated concept called data fusion. The data fusion approach uses any obtainable values from additional measurements. This information may be partly redundant but certainly not by excess. The main strategy of data fusion is to, at once and at the present point of time, processes the multi-dimensional measurement data while given in the array of measurements and to find the optimal combination in order to produce the best possible state estimate. Therefore, one has to combine the measurements and the state variables due to physical laws, i.e. space, time and condition (Huadong 2003) (Nakamura et al. 2007). This often requires a sophisticated modelling of the state dynamics and observation mapping, because any error in modelling leads to a loss of information which in turn lead to suboptimal and inefficient estimates. An optimal estimator, however, extracts as much information as possible out of the available measurements to generate the best estimate. So a lot of care has to be taken about the exact modelling of the process.
In data fusion the main motivating principle is to improve the quality of the information output by a process known as synergy (not to be misinterpreted with the data fusion process itself). This does not require that one uses multiple sensors as the synergy of data gathered from an individual sensor can be obtained over time. However, employing more than one sensor may enhance the synergistic effect and thereby the system performance by the following: representation (a richer abstract and semantic meaning of individual data inputs), certainty (a linear probability of data sets before fusion), accuracy (standard deviation on data after fusion process is smaller than standard deviation by direct source), and completeness (bringing a complete view on the new informational situation gained by the current knowledge in that situation) (Mitchell 2007). For the REACTION project (Figure 5) this means that enhancing the synergetic effect in data fusion will enable a more clarified semantic model of disease management by taking into account individual sensor inputs, a better certainty of probabilistic anticipation in sensor values, failure overview, an accurate data fusion interpretation retrieved by comparing sensor values, and finally give a complete view of the REACTION platform by affirming the knowledge from different stakeholders and patients.
3.1.3 The need of a formal data fusion framework
Systems that make use of sensor data fusion are usually of such size and complexity that a formal framework is needed in order to organize all the knowledge issued within the system. Therefore, despite what framework to choose, preferably object modularity should be included as it decreases the complexity in designing the data fusion system and helps out in the construction and maintenance of an operational sensor data fusion system. When deploying a formal framework it is useful to divide the system into three domains: the physical (hardware) containing sensor modules each of which represents a sensor which physically interacts with the external environment which in turn partially can be modified by actuators, the informational (software) which is the heart of the data fusion system with operative blocks of data fusion, control/resource managements (i.e. the REACTION platforms many managers), and a human-machine interface (HMI). Finally, the last domain is the cognitive domain which constitutes the final arbiter and decision maker in a data fusion system, i.e. the user. Figure 4 shows a brief overview of such a system.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 15 of 91 DATE 2012-03-05
Figure 4 Example of the REACTION platform seen from a formal framework perspective in a data fusion
system (Mitchell 2007).
When having a system architecture at hand then it is fairly easier to model and conceptualise a data fusion framework. As a step one needs to distinguish the different domains, i.e. physical, informative and cognitive, and as a help there is the notion that any data fusion framework by some system architecture should explicitly define possible levels of data fusion including approaches to manage the data fusion process itself (Carvalho 2003). Breaking the system architecture down into classes and relationships will emphasize anticipatory data fusion process(es). Yet another beneficial result of this is that it introduces a taxonomy for data fusion classifications (i.e. data and variable attributes and definitions, see Figure 5 (Carvalho 2003)) which presumably have not been exposed earlier and thereby accelerates and enhances the modelling and conceptualisation of the data fusion architecture. There are two main issues that must be addressed in the next coming data fusion architecture design: the topological issue which concern the problem of spatial distribution of sensors, the communication network between the sensors and places of processing, if any decision making should take place with required bandwidth, information exchange and the availability and reliability of this information at the time of the data fusion. The other issue is the processing of data fusion and address the question of how to conduct the data fusion, i.e. measurements demands, fusion methods and internal communication architectures (i.e. standards etc.) (Pau 1988).
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 16 of 91 DATE 2012-03-05
Figure 5 showing how to conceptualise a data fusion framework by classes in a healthcare domain such as
REACTION.
As a summary for data fusion one can state that it itself is a formal framework used to express the convergence of data from different sources in which it is expressed as the means and tools for the uniting of data from different sources. That is, a formal framework in data fusion maps out and builds an integrated whole of a system. This is done by connecting to a cohesive support (manifested by object modularity such as classes, their attributes and relationships) and by bricks of information (i.e. data sources).
3.2 Current approaches to data fusion and architecture
The set of sources of information can be said to create a fusion architecture by the means of how these sources are assembled and how these are used. By that they are being able to perform a fusion operation (e.g. by the effects found in the data fusion engines in Hydra and REACTION) in the most suitable domain settings. When developing a system that uses data fusion then the architectural choice is often ambiguous in the sense that it depends on the information that is sought and involved. To solve this so called problem one can distinguish between three architecture types that all adapts to its purpose, i.e. solving the problem, but to different degree. These types are centralised, decentralised and a last one, hybrid, which is a combination of the first two (Wald 2002).
3.2.1 Architecture types
Centralised architecture
The centralised architecture exploits itself and its set of sources of information in a single location in both a simultaneous and non-simultaneous way. The advantage of a centralised architecture type is that is presumed to provide results that are aggregated in an optimal way by taking into account the whole knowledge that is locally available instead of when it is distributed. Since the original and local information is fused without diversions of attributes, states etc., it is regarded as a minimal information loss and therefore better represented if not provided by any autonomous source. Simultaneously, there is a risk when a source in that set makes an error or a fault value and whereby this source affects the whole data set. This risk creates a decreased quality in the whole set. Centralised architecture is preferred when data retrieved is supposed to be used at the scene of the set of source collection.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 17 of 91 DATE 2012-03-05
Decentralised architecture
Compared to the centralised architecture the decentralised architecture instead offers a large modularity and flexibility as it, by its analogue name of being autonomous, processes independently of each of its sources of information. This is true all the way until it fuses representation on a higher semantic level and at a later stage in the data fusion process, i.e. clustering of relevant data information into one. A decentralised architecture should be chosen when there is communication problems as small bandwidth, unsecured communications or if the acquisition rate of sources changes a lot and where an adoption of a decentralised architecture can avoid re-processing of all the sources. The drawback of a decentralised architecture compared to a centralised is that it has lower global quality and lower information content. Also, in a decentralised architecture, the databases or any retrieval from these are left completely separated and will only perform the data fusion when the use or user requires or needs the information. Consequently, data fusion only occurs locally (i.e. distributed) at each sensor node and on the basis of local observations including the information obtained from neighbouring nodes.
Hybrid/distributed architecture
The hybrid architecture is as shortly described earlier a combination of the two previous ones. The data fusion system (engine) combines the capacity to fuse at measure level or track level. The benefit of this architecture combines the ones of previous architectures. As advantages, the architecture features: high accuracy, systemic error robustness and the possible distribution of computational load. As possible disadvantages in the hybrid architecture there is a higher computational load because the measures are processed two times. This can be stripped down by a thoughtful data fusion architecture design.
Figure 6 showing the three different data fusion architecture types
1.
3.2.2 Modelling an architecture with respect of REACTION
For the stake of the REACTION project, choosing a data fusion architecture is highly arbitrary as it holds multiple stakeholders and patient scenarios (i.e. in-hospital and out-patient). One therefore needs to postulate the data management subsets as central to the high level functioning of applications and services deployed on the platform. By implementing a model-driven architecture for application development and deployment, a service oriented architecture for core service functionalities, data manipulation, data fusion and event handling, it should be possible to manage data transfer to and from nodes and stakeholders in the REACTION environment in a eligible way. The consensus is that there should be an operational data fusion
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 18 of 91 DATE 2012-03-05
engine per observation type. With this it is supposed that every patient observation is represented in different schemes where any value variation repress data fusion, e.g. fusion is not executable until certain sensor value is achieved. This will provide enhancement of performance as superfluous values are ignored, such as inconstant measurements gathered in heated sensor area from example: sweat, radiation from wireless communication, or power dissipation of sensors. All of these attributes together with observation type settings should be carefully predetermined and accordingly processed in the system (by algorithms, reliability check up (redundant sensors) and error detections). Lee et al., further differentiates observation types as relationships between sensor types in terms of distance between their locations and the position of the patient. According to their Pervasive Healthcare Monitoring System (PHMS) there are at least two more factors that are dependent for a correct interpretation of body sensors and environmental sensors. These are location and time. Location has to do with the spatial information of single or multiple persons and is an important factor to check a targeted person's condition in a health monitoring system. The system has to keep tracking the person's location, because depending on the location, a body condition of a body sensor worn person might be changed and by the factors mentioned earlier, the person might be exercising in a gym and where his or her heart rate and body temperature increases. These changes of body condition are normal but if the system is not location-aware, the system might falsely warn to e.g. a medical sphere in REACTION.
The most uncomplicated solution is that each patient uses a Global Positioning System (GPS) receiver together with a home gateway system that intercommunicates with the GPS receiver to track the person. Nonetheless, the GPS is an impractical solution due to its limited performance in indoor environment while system accuracy is not stable enough to be presented as part of a medical solution (e.g. ionospheric effects and satellite clock errors). Equipping every patient with GPS could also imply a matter of cost and therefore it might be required with a relative localization in the indoor healthcare area among the sensor nodes in a pre-specified space. A more convenient solution for REACTION indoor patients would be the use of home arrangement and furniture places available as part of a high accuracy network where the home gateway device maps the targeted person by predefined sensor location. With this approach (based on triangulation, trilateration or multilateration of data gathered from Infrared, pressure, acoustic, camera sensors, etc.) the system could retrieve spatial information based on the sensed data into the pre-specified space (Lee 2008). It is also possible to use active RFIDs such as Lionel et al., have done in their prototype system Landmarc, where they show that active RFID is a viable cost-effective candidate for indoor location sensing by improving the overall accuracy of locating objects by utilizing the concept of reference tags (M. Lionel et al 2003). An alternative, as presented in deliverable D5-1, is to use the 6LoWPAN protocol that involves intercommunication and localization among sensor nodes by the help of the neighbour discovery component (ND). The second factor dependent for proper reading of sensor data is time. As measured data need to be linked to a certain time of retrieval from sensor nodes, time can give the medical sphere in REACTION valuable temporal information to monitor patient data accordingly. That means that in order to generate correct context from sensors, each separate sensor (observation type) has to have a record function where the timestamp of each data packet in the sensed data is set. Consequently, timestamps by sensed data from different types of observational sensors play a crucial role in analyzing the measured physiological data as well as the context of a situation. Time can at the end be specified as the primary factor for contextualizing a particular situation by separate observation types such as location, activity and identity (Lee 2008).
Modelling architecture in a medical solution such as REACTION could therefore be said to involve correct time stamping and time retrieval of predefined sensor values measured and contextualized per observational type set by location and consent in the different spheres. As eHealth standards in major are a common feature in medical electronic applications these standards also usually include parameters or attribute that guide developers towards such an architecture model. For the REACTION stake and interest, the Continua Health Alliance (described in chapter 5.1.5) proposes an architecture with separate interface protocols that deals with for this chapter discussed factors. The Continua architecture is based on a “push”-model where data is being moved through the system in response to a predefined event. Although late information tell us that the Continua Alliance eventually also will support other models as well, it is for the moment excluding a "pull"-model (i.e. data is retrieved by command from the server side). The consequence for this complicates a medical architecture where a two-way communication is preferred. A countermeasure could be modelling a solution that bypass the push approach by a relative approach. Conclusively for this chapter is that the data management services in REACTION will have a two-way connectivity between health professionals in one end and sensors and patients in the other end, and by this it is said that a communication dynamic, factor covering and standard applicable architecture is necessary to be modelled.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 19 of 91 DATE 2012-03-05
3.2.3 Data fusion requirements
When reaching the point of having a comprehensive formal framework or similar such appropriate models of choice, it is the moment for reviewing what each individual data fusion modularity requires in terms of being able to provide a functionally integrated system. Within eHealth this often means that there are two subsets to consider: one addressing the medical devices and their standards, and one addressing more technical aspects such as transport layers, obtainable stacks, energy properties, etc. What also is crucial to comprehend is that these subsets also mirror the interdisciplinary approach that projects like the REACTION project have. The approach blends medicine, physicists, and care givers with technology, system architects, and developers. For all parties there is a more and more common feature in an eHealth system, which is providing wireless solutions. Wireless is a current topic in medical device industry and research and it has always exerted a fascination for the medical community through its ability to remove the cables which literally hinder the mobility of patient monitoring equipment. By that, there is also a more recent and greater interest in the ability to enable a new generation of mobile, personal healthcare devices. The aim of this is to increase the degree of personal health monitoring in order to cope with the pressures imposed by changing demographics and the increasing incidence of long term chronic conditions. Therefore, wireless technology can be seen as a key tool in moving that aim from being a concept to actual deployment. With such a requirement apparent, wireless groups are building capacity and trying to convince medical device manufacturers that their wireless standard is the best on the market. Of course, in an ideal world, there would be one wireless panacea but in the real world, physics intervenes and dictates that the conflicting requirements of different medical devices which in turn will need different solutions. This is also something that will highly affect the architecture of the REACTION platform. Some relevant issues concern how many sensors and how many different kind of sensors can be allowed in an environment without making the platform critically vulnerable and, in contrast, how many various sensor/observational types are necessary in order to provide sufficient information about a specific disease treatment? Aside the need for standards or rules, interoperability between devices (both medical and other) are critical if they are going to be deployed in hundreds, and eventually in thousands of homes, wards, etc. As a result, the wireless debate is being merged on a limited number of wireless specifications. These specifications often have the focus on interoperability and are being controlled by standards groups in conjunction with medical device manufacturers such as the Continua Health Alliance, ZigBee Health Care, the Bluetooth Medical Devices Working Group which covers Bluetooth and Wibree (also known as Ultra Low Power Bluetooth) and the IEEE 11073 Personal Health Devices Working Group. Scalability is therefore an architectural attribute that needs to be accomplished so that the project and REACTION as a product can be commercially prevalent.
3.2.4 Processing of data in sensor networks
Wireless sensor networks provide a challenging application area for signal processing as these networks are built by collections of small, battery-operated devices (i.e. sensor nodes) which are capable of sensing data, processing data with an onboard microprocessor, and sharing data with other nodes by forming wireless, multi-hop networks. Since it typically is so that communication power consumption in nodes dominates over sensing and processing power consumption, it is clearly more efficient to extract measured data in a distributed fashion within a network than it is to collect data in a centralized processing fashion by single location (Wagner 2007). Therefore, each node in the sensor network is and should be capable of completing three main tasks: collecting data by its sensor data input, processing data with a built in microprocessor, and sharing data with neighbouring nodes or gateway in the network using desirable communication protocols. By modelling a data fusion architecture the view of the system that is built could, in advance, easily be clarified in what considers the choice of sensors, standards, and meeting the terms of disease management arrogation. Further and deeper elaboration on each individual communication standard can be found in deliverable D-5.1.
Before looking at different application areas, it’s important to understand what happens to the data when it is transferred over a wireless link. As a cable is a pretty dumb component and limited to transferring data between two fixed points it is important to contemplate any wireless access as it typically can extend that wired transfer to a database or a UI at a remote location. As such, it allows data to be aggregated from any multiple devices while most cables are restricted to display data on a nearby monitoring device. As issued in chapter 2.1 there are some challenges within eHealth that emerges to be database compatibility and sensor network interoperability.
Therefore, the obvious choice for such applications is the set of 802.11 standards, also known as Wi-Fi or Wireless LAN. Many hospitals and clinics already contain the infrastructure for wireless LAN by the form of Wi-Fi access points. Private homes (i.e. patient sphere) also fall in to that category but probably with a higher diversity of communication standards as the private consumer market offer a greater variety of network devices that are not regulatory bound. Still, most Wi-Fi enabled products are likely to be seen within the
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 20 of 91 DATE 2012-03-05
clinical environment and in many ways, this also defines where medical wireless technology is today. Wireless standards really come into their own is by enabling the next generation of personal medical devices and for example, Wibree
2 is optimised for sending limited amount of data, as this ensures a long battery life
and Wibree has a range of several hundred metres that will allow it to be used for sensors around a typical house, making it equally applicable for personal devices and fixed, assisted living sensors. On the other hand, the Bluetooth Medical Devices Working Group is already incorporating Wibree into its work program to ensure a structured approach to the medical standards available. Surely, there are plenty of other wireless standards, but as mentioned, the market for medical devices demands interoperability. The set of 802.11 provides satisfaction for that and the infrastructure of it links complex products within the clinical environment to the need of being network enabled. The combination of Bluetooth and Wibree, or even ZigBee for that matter, together with the support of the medical device industry, organisations and/or alliances provide a complete set of wireless capabilities that can serve the personal healthcare market.
By assessing the requirements conducted in deliverable D2.5, there are some important key points by requirement types to consider. For this chapter, key points found in chapter 6.2 (requirements of WP4) that deals with data fusion and its architecture are the relevant ones. Nonetheless, all of these key points need to be mapped and reviewed by some fundamental issues. These are used when building a data fusion system for a certain solution and include the following question points (Hall D 1997):
1. For this solution, what algorithms and technological approaches are appropriate and foremost optimal;
2. Considering the processing information flow, where should the data be fused and what architecture type should be applied to achieve this;
3. Depending on the separate measured sensor data, how should it be processed in order to extract the maximum amount of information and how should this extracted information be further selected in order to be relevant for the solutions' purpose;
4. With the observation types apparent, what accuracy can realistically be achieved by the data fusion process;
5. When performing a data fusion, how can its process be optimized in a dynamic sense so that real time measurements are correctly represented;
6. How does any level of data fusion affect the actual sensor node processing;
7. Under what conditions does multisensory data fusion improve the system operation and when is it supposed to be preferred with single sensor retrieval?
3.3 Collecting physiological measurements from personal health devices
The REACTION platform will be based on seamless integration of wearable ePatch sensors and off-the-shelf medical devices, environmental sensors and actuators and therefore one of the projects' objectives is to develop a set of wearable and portable medical devices that can be coupled seamlessly with the platform. The reason behind this objective is to create a solution for multi-parametric monitoring and contextualisation of patient health status. The requirements for this objective will therefore focus on accurate measurements with minimally or non-invasive methods where sensors are said to be wearable and interconnected within BAN. These devices also hold communication technology that, through Web Services, represent the main procedure for communicating between devices in the REACTION architecture. These devices may be presented as UPnP devices but where the UPnP discovery information is usually restricted to Local Area Networks. Because of this, it is preferred with applications that use very loosely coupled devices that come and leave the platform, and where an assumed decentralised structure (and further functionalities for communication protection) has to be included in every single component.
The Data Management subset is basically a runtime environment that transforms data into information. It performs data manipulation and conditioning, translation between state domain and real time domain, simple data analysis, queries, contextualisation of data, and fusion of data to the next node, either upwards to the Service Layer or downwards to external devices or repositories. As REACTION deploys the Hydra Middleware for this purpose, the project will also be able to employ its semantic technologies and automatically to detect physical devices irrespective of their underlying communication protocol (it supports Bluetooth, ZigBee, RFID, RF, Wi-Fi, Serial port and many more). Through the use of device ontologies the Hydra Middleware resolves the type of device that has been detected and automatically creates a web service interface that allows other devices and applications to use and control the device. Nevertheless,
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 21 of 91 DATE 2012-03-05
REACTION will implement tools to promote physiological and context parameters to knowledge about the patient and the illness with the aim to provide a risk assessment based on her/his current health state and history. The tools will allow for integration between instantaneously measured data from sensors, historic data from EPR‟s, statistical data from stratification studies and statistical database and evidence based case management repositories. A continuous update and calibration with independent off-line measurements of relevant biomarkers and diagnostic tools has to be possible. In order to do so, the REACTION platform will need to integrate mechanistic physiology-based models of insulin and glucose kinetics, but also other relevant physiological measures, and use the physiological feedback loop of insulin and glucose kinetics with statistical models for prediction and risk assessment. One such model is the Automatic Glucose Control (AGC) which consists of an algorithm that has the purpose to calculate insulin delivery rate from available physiological data and deliver this via an insulin pump. The closed loop algorithm calculates the insulin delivery rate based on the continuous glucose monitoring via the CGM sensor, together with additional physiological parameters using the sensors in the e-patch platform. A general overview of the system is shown in Figure 7 that includes the direct feedback control from physiological measurements and the context from indirect information to support personalisation and safety interlock from user and carer verification.
Figure 7 A scheme of the AGC algorithm in REACTION.
In the figure it is also shown individual sensors within the patient’s sphere (including the ePatch) and the interoperability with these physiological but also contextual sensor data inputs gathered from the patients' personal health devices must be granted in the REACTION platform. Therefore, the concept of interoperability needs to apply to various sensors and devices in patient sphere and where multiple communication protocol connectivity needs to be supported. By this, the REACTION platform can collect physiological measurements both from standard based medical devices but also from other that are not based on medical standards but still useful by the contextual contribution found in a data fusion model.
3.4 Collecting physiological measurements from body worn sensors
A body worn sensor can be said to be part of a personal health device. Placing sensor devices on human bodies can be a delicate issue as these sensors need to be light, ambient and easily to get accustomed to, so that users are not interfered with more than necessary in their daily life. If not, the employment of a project might fail on that single point. Connecting the chapters 3.2.3 and 3.2.4 it is easy to notice that these light weighted wearable sensors need to include the sensor itself, some microprocessor to run it and a sending communication module, and all of this without imposing usage anomalies in the sector of its application.
It is also mentioned in previous chapter but is more suited to be explained in this one: the ePatch (Figure 8) is a sensor that is wearable and where diagnoses can become significantly more accurate, because they are based on monitored data recorded while the wearer is engaged in the kinds of normal day-to-day activities that trigger the symptoms. The ePatch platform does much more than just registers and transmits physiological data. Advanced microelectronics and customised algorithms enable the ePatch to intelligently process and filter data flows. This dramatically boosts the value of this data in providing alarm signals, as the basis of treatment decisions and for preventive action.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 22 of 91 DATE 2012-03-05
Figure 8 Demonstration of the Delta ePatch sensor
3.
The ePatch is a good example of wearable sensor that fulfils the requirements of being unobstructed for its users as the ePatches are supremely easy to apply and to use and users hardly even notice the ePatch is there. The effort in REACTION is on developing medical devices body sensors and especially focus is on developing capabilities for developing and supplying body sensors imbedded in skin friendly adhesives. This new ePatch technology will therefore be further developed in the REACTION project and is expected to be a platform for future development and supply of application specific ePatches as OEM products.
Kang et al., described back in 2006 that a ubiquitous healthcare service has to consist of a wearable system so that more continual measurements of biological signals of a user, which gives information of the user from wearable sensors, can be taken. In their paper they proposed a wearable context aware system for ubiquitous healthcare together with a systematic design process of a ubiquitous healthcare service. Their context aware framework is claimed to send information from wearable sensors to healthcare service entities as a middleware to solve the interoperability problem between sensor makers and healthcare service providers (DO Kang 2006) and by that it resembles very much the objectives in the REACTION project. Solving the problem of wearability in REACTION and at the same time affirming the work of Kang, would also be pleasing the challenge set by Lymberis in the European Commission article earlier in 2004: the possibility for minimally (or non) invasive biomedical measurement but also wearable sensing, processing and data communication is part of the latest developments within research and development and although the systems are being developed to satisfy specific user needs, a number of common critical issues have to be tackled to achieve reliable and acceptable smart health wearable applications e.g. biomedical sensors, user interface, clinical validation, data security and confidentiality, and user acceptance (Lymberis 2004). For example does Lymberis give a state of the art report on how smart fabrics and interactive textiles (SFIT) are fibrous, sensing, actuating, generating/storing power and/or communicating structures. Further, under the Information and Communication Programme of the European Commission, there is a cluster of R&D projects dealing with smart fabrics and interactive textile wearable systems. This includes projects aiming at personal health management through integration, validation, and use of smart clothing and other networked mobile devices as well as projects targeting the full integration of sensors/actuators, energy sources, processing and communication within the clothes to enable personal applications such as protection/safety, emergency and healthcare (Paradiso &. Lymberis 2008). Examples of these projects are:
Proetex; protection in e-textiles where micro-nanostructure fibre systems are applied for emergency-disaster wear
4.
Stella; stretchable electronics for applications in a large area5.
Biotex; biosensors in textiles that support health management6.
Context; contact less sensors for body monitoring by textiles7.
MyHeart; a cat suit that works as a textile platform that retrieves physiological data and prevents cardiovascular disease by a preventive lifestyle and early diagnosis
8.
Ofseth; optical fibre sensors that are embedded into technical textiles for the healthcare area9.
Mermoth; clothes with sensors that are used in a medical remote monitoring scenario10
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 23 of 91 DATE 2012-03-05
As the body is flexible and smooth so does the material (i.e. sensors) also need to be in order to keep the amalgamated sensation of a wearable system. For this, it is important to bridge the discrepancy between electronics and textiles, e.g. electronics are hard, dense and localized on a surface while textiles are soft and elastic, washable, and can be dislocated at the body. For a data fusion point of view in REACTION, all of these sensors need to 1) fulfil their partial requirements discussed so far in this subchapter, 2) provide a wireless or wired E2E information connectivity with a adaptable bandwidth by 3) compatible standards, and 4) by an on-body generic processing interconnect with other sensor devices as well as a receiving gateway, hub or server side. Ideally one also considers the mechanisms for closing the loop in data fusion by self activation or human intervention (CSEM 2010).
3.5 Collecting contextual data
Medical devices available on the market may not fulfil certain particular measure requirements. These can be both based on physiological inputs such as ECG or glucose values and on contextual inputs that are of matter for the overall medical judgement. For example, a body temperature sensor might render data that alert about a low temperature but without any contextual information the alarm staff or physician will omit the fact that e.g., the patient actually is exercising on a workout bicycle. A sensor revealing that the bicycle is activated by e.g. speedometer or power consumption calculation, could here add valuable contextual information to that scenario. A context is defined as a pattern of behaviour or relations among variables data that potentially affect user behaviour and system performance. A context could thereby be derived from the fused data in combination with a decision making policy (i.e. REACTION rule engine). Wireless sensor networks typically consist of a large number of sensor nodes embedded in a physical space and as we now know, such sensors are devices that are primarily used for monitoring several physical phenomena (e.g. potentially in remote environments). Spatial and temporal dependencies between the readings at these nodes highly exist in such scenarios as the workout bicycle. Statistical contextual information further on encodes these spatio-temporal dependencies and enables the sensors to locally predict their current readings based on their own past readings, and the current readings of their neighbours which here can be any particular medical or non-medical device.
The Hydra Middleware can implement such features in the REACTION platform as it already easily and securely integrates heterogeneous physical devices into interoperable distributed systems. These devices, i.e. sensors, connect through a wireless BAN to any available network infrastructure in the patient’s surroundings and other body and room sensors provide contextualisation. The BAN interconnects with other sensors in the environment that can record contextual information about the other vital parameters and the patients‟ activities (Personal Area Network – PAN). Additively, Hydra's semantic self-configuration tools for devices can enhance the medical (and contextual) devices with semantics. Finally, context awareness in REACTION will be achieved through semantic annotation of patients' device data, data coming from the environment, and data from the patients' historical information in EPR repositories.
Examples of non-medical sensors that model the contextual information resource are listed below with an indication of potential use in the REACTION platform.
1. Acoustic, sound, vibration: A microphone is an acoustic-to-electric transducer or sensor that converts sound into an electrical signal. In the REACTION platform a PC, PDA or another suchlike gateway or host often carries an integrated microphone and thus can be used for communication, verbal note-taking or verbal system command by user or between patient and physician. If no such microphone is integrated an external microphone is easily adopted as a device and service in the Hydra Middleware.
2. Chemical: Smoke detector; most smoke detectors work either by optical detection (photoelectric) or by physical process (ionization), while others use both detection methods to increase sensitivity to smoke. Connecting a smoke detector to the Hydra Middleware would enhance the security aspects of the REACTION platform.
3. Electrical current, electrical potential, magnetic, radio: Most sensors that are to be used within an eHealth project or domain make use of these kinds of sensors. Electrical current and electrical potential are deployed in most electrophysiological measurements as the body's internal flow of information exchange occurs with the help of biopotentials. Magnetic sensors can be used to distinguish the proximity of sensor nodes or their position in an environment although radio sensors are more efficient here.
4. Position, angle, displacement, distance, speed, and accelerometer: An odometer (milometer) indicates distance travelled by a car or other vehicle. The device may be electronic, mechanical, or a
10
http://www.mermoth.org/
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 24 of 91 DATE 2012-03-05
combination of the two. As an extraction from the odometer and relevant for the REACTION project there is the pedometer which can be a motivation tool for people wanting to increase their physical activity. Pedometers have been shown in clinical studies to increase physical activity, and reduce blood pressure levels and Body Mass Index, and are anticipatory for diabetes management.
Figure 9 The Fitbit sensor measuring user activity.
An accelerometer is a device that measures proper acceleration, the acceleration experienced relative to freefall. Single- and multi-axis models are available to detect magnitude and direction of the acceleration as a vector quantity, and can be used to sense orientation, acceleration, vibration shock, and falling. This kind of sensor could be useful in those cases where the patient sphere consists of elderly people and would serve as an additional alarm service, i.e. fall detection.
5. Optical, light, imaging: Infrared radiation (IR radiation) is electromagnetic radiation with a wavelength between 0.7 and 300 micrometres. Infrared imaging is used extensively for military and civilian purposes. Military applications include target acquisition, surveillance, night vision, homing and tracking. Non-military uses include thermal efficiency analysis, remote temperature sensing, short-ranged wireless communication, spectroscopy, and weather forecasting. IR spectroscopy for example, is a technique that is used for glucose monitoring. Infrared spectroscopy exploits the fact that molecules absorb specific frequencies that are characteristic of their structure. These absorptions are resonant frequencies, i.e. the frequency of the absorbed radiation matches the frequency of the bond or group that vibrates. The energies are determined by the shape of the molecular potential energy surfaces, the masses of the atoms, and the associated vibronic coupling. In glucose monitoring the influence of glucose on light propagation will make more glucose result in less scattering, consequently shorter optical paths, and therefore less absorption by the IR photons.
6. Pressure: The term tactile sensor usually refers to a transducer that is sensitive to touch, force, or pressure. Tactile sensors are employed where ever interactions between a contact surface and the environment are to be measured and registered. Tactile sensors are useful in a wide variety of applications for robotics and computer hardware. A sensor's sensitivity indicates how much the sensor's output changes when the measured quantity changes. Depending on the interaction in the REACTION platform this way of communicating could be giving an augmented sensation of an interface panel.
7. Thermal, heat, temperature: Thermometer is a device that measures temperature or temperature gradient using a variety of different principles. A thermometer has two important elements: the temperature sensor (e.g. the bulb on a mercury thermometer) in which some physical change occurs with temperature, plus some means of converting this physical change into a value (e.g. the scale on a mercury thermometer). Thermometers increasingly use electronic means to provide a digital display or input to a computer. For a medical solution such as the REACTION platform a thermometer could serve two purposes: one measuring body temperature by a particular sensor and one measuring temperature in room giving a contextual data resource.
8. Proximity, presence: Motion detector; an electronic motion detector contains a motion sensor that transforms the detection of motion into an electric signal. This can be achieved by measuring optical or acoustical changes in the field of view. This could be used to detect whether or not the patient is at home and further also more spatially delimit user location. Similarly, a Passive Infrared sensor (PIR sensor) is an electronic device that measures infrared (IR) light radiating from objects in its field of view. PIR sensors are often used in the construction of PIR-based motion detectors. Apparent motion is detected when an infrared source with one temperature, such as a human, passes in front of an infrared source with another temperature, such as a wall.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 25 of 91 DATE 2012-03-05
Supplying a disease management system such as the REACTION platform with only medical sensor data is sufficient enough to be able to make management decisions but when the disease itself, diabetes, is of dynamic and multilateral in the sense that it depends on more inputs than just physiological data, one also must do analysis on what external or better pictured in what contextual setting the disease is best managed. That is, a blood value together with a pulse rate is insignificant if there is no contextual information supporting why those measures are high or low. Maybe the patient is running or sleeping. Applying contextual data is momentous for a successful interpretation of and subsequently management of diabetes. In REACTION, a context-awareness framework will be developed (WP4 task 4.4) that takes existing approaches to context-management into consideration. The framework will include a REACTION-specific model of context and the required components for the management of that model. A candidate starting point is the approach to context management developed in the Hydra project. The Hydra framework defines a multi-level context model relating providers and consumers of context, to different levels for context sensing, context provision and context linking. Context management architecture will therefore specify the necessary functional components in REACTION.
3.5.1 Environmental sensing
PAN network technology for integration of heterogeneous sensors in the REACTION environment will provide context awareness to the multi-parametric medical sensors. Other parameters that will be measured are the ones related to environmental conditions (the temperature and humidity of the environment around the patient (some of its sensors are already described in chapter 3.5)) that could give an indicator of the reliability of the primary and secondary sensor signal. The body automatically shorts down or minimise the blood perfusion at the skin surface when the person is freezing and therefore the sensors on the skin surface may measure correctly, but the physiologic parameters measured in tissue near skin surface may not be in correlation with the conditions of the patient. Environmental sensing in REACTION will 1) conduce to current physiological sensor readings, 2) build up the contextual data repository, and 3) enhance the way the carer sphere creates and manages the disease management and workflows.
3.5.2 Patient entered data
A straight forward medical system that takes whatever sensor values measured and sends these into an AHD from where messaging protocols are further sent to various spheres and EHRs are not sufficient to fulfil the wide range of contextual information available in REACTION. What is necessary to do is to take into account those factors that play a role in determining the complementary aspects and validity of those represented measurements in the system. In order to do so, one need an “integrative risk assessment” such the one that will be implemented in the REACTION platform as a synthesis of several components. Multi-parametric data about patient health status (from real-time observations and direct patient inputs regarding e.g. exercise status) and health history (from data storages and EHR repositories) will be combined with user preferences (from patients and healthcare professional) in order to create the patients “Health Status Profile”. Prior knowledge about healthy physiology and patho-physiological conditions common to diabetic patients will be used to set-up mechanistic models that support and structure the modelling and data analysis process. The REACTION data fusion will, by these parameters, be able to generate a “patient footprint” which then can be used to investigate various risk assessment models and services.
A central activity in the REACTION data fusion is derived from the knowledge discovery which has the aim of analysing the collected data (e.g., qualitative and quantitative data such as data from real-time observations, health history and especially the direct patient inputs). Even if the knowledge discovery of patient inputs should preferably by Matthew I Kim et al., rely on a guided entry of data elements that can be abstracted from a specific primary source (i.e. as they promote a more accurate entry of information (Matthew Kim 2004)), the REACTION platform and foremost the data fusion algorithms within must be capable of dealing with any adaptive interfaces and thereby different configurations of data elements. Adaptive interfaces are generated during run-time by applying a set of transformation algorithms to different types of device models and by strict data fusion architecture this would probably mean that the REACTION platform loses access of the originally anticipated contextual data sets. A dynamic data fusion architecture or a layered model where a transaction level interface module (i.e. transacting the adaptive interface algorithms to something recognisable for the REACTION platform) can presumably prevent the loss of valuable contextual data.
3.6 Security and privacy
The issues of security, confidentiality and liability are crucial elements of eHealth development and are some of the major challenges of eHealth. The document e-Health - making healthcare better for European citizens:
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 26 of 91 DATE 2012-03-05
An action plan for a European e-Health Area11
defines several security issues. Because health information, products, and services have the potential both to improve health and to do harm, organisations and individuals that receive and provide health information remotely have obligations to be trustworthy, provide high quality content, protect users‟ privacy, and adhere to best practices for online professional services in healthcare.
Requirements for security, privacy and trust have to be determined not only in terms of the global regulatory framework and security and privacy objectives for healthcare services but also in terms of the technology enhanced context-aware security features that suit the particular security models involved in any distributed healthcare environment.
3.6.1 Security
When physical boundaries are eroding, security depends on the ability to appropriately manage logical boundaries. Existing healthcare solutions, however, are mostly integrated in a traditional security framework focusing on perimeter security, e.g. intrusion protection, repudiation and authentication. The distributed nature of REACTION platform greatly increases the vulnerabilities against malicious conduct. Virtualisation of devices is thus an important method to protect devices from attacks and balance users' security risks and ensure damage control. Both devices and users can operate with virtual identities. Two devices with respective users can thus connect based on semantic security description according to the security model.
To manage security in the REACTION platform and empower users with privacy enhancing tools, a trust concept will be defined based on a definition of “trust” as the human way of balancing risk and benefit of a transaction in a subjective way (Cahill2003). Trust requires adapting policies dynamically to changing requirements. The security and privacy chain as well as important trust concerns will therefore be identified and ranked so that secure identity management can be implemented throughout the platform. Hence the REACTION project aims to provide a visible and controllable distributed security and privacy model, which is based on the concept of trust as a multilateral relation between stakeholders in a community of patients, informal carers and healthcare professionals and providers.
Safety plays an important role in any closed-loop system, but for healthcare applications, the safety aspects become paramount. The device risk assessment will be undertaken using existing risk management methodologies and frameworks. Where possible it will include existing standards and industry best practice.
The P2P architecture of Hydra will be extended to include BAN and PAN. REACTION applies a novel approach to large-scale SOA and envisions arbitrary pairs of peer application entities communicating and providing services directly to and with each other. In a peer-to-peer SOA, none of the participant hosts is required to be always on; moreover, a participating host may change its IP address each time it comes on.
In terms of security and safety, it should be verifiable that multiple sensory data, presumably relating to the same person, are actually received from the same person's devices. In other words, data that is supposed to come from the same person should be authenticated by some mechanism that allows verifying the link between the person and the received data. If this cannot be guaranteed, sensory data from the patient's own devices could be mixed up with data from devices not belonging to the patient in question and this may lead to false conclusions in the data fusion process. Of course, in the same way false/forged data could be deliberately injected by an attacker.
Depending on the type of sensory data being transmitted, it could also be necessary to ensure confidentiality and privacy. For instance, it might not be necessary to use encryption in order to protect certain ambient sensory data from eavesdropping, e.g., the room temperature, but other sensor data, e.g., GPS coordinates, though also ambient data might be considered private. Other data, such as the patient's heart rate, can be considered personal and intimate in the first place and thus such data, if not transmitted confidentially, might disclose a disease, such as a heart problem, to anyone overhearing the data transmission.
Another aspect of privacy, mainly relating to centralised data fusion architecture, is accumulation of personal data. As outlined before, it surely is necessary to relate data of the same person, but this could be done in a way that does not disclose the person's real world identity, e.g., a pseudonym could be used instead of the person's real name. Even more, if it is not necessary for some 'data fusion provider' to relate current data with past data, privacy could be improved by allowing different pseudonyms for each batch of related sensory data. That is, the provider would be able to distinguish different batches of data but, per se, he would not know if two batches relate to the same person. Of course, certain physiological data is 'reasonably unique' in the sense that it is unlikely that the same data pattern occurs with two different persons and thus, such data might relate two batches of data to the same person. Still, such inferences would be subject to
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 27 of 91 DATE 2012-03-05
processing, which is different from having a built-in mechanism aiming at recognising discriminating persons per se.
Regarding decentralised vs. centralised architecture and error propagation, local nodes might better know how to deal with false sensor data, and possibly even be able to correct them. However, this assumes that the nodes have some way of distinguishing (injected) false data from correct data. One way would be to employ security mechanisms. Another advantage of having a decentralised data fusion architecture might be that it could be harder to compromise the system as a whole, as it might be more challenging to compromise many (or all) data fusion nodes instead of a single centralised one. The downside of having a decentralised infrastructure might be increased security management, as each node would probably need a set of security keys.
3.6.2 Privacy
Privacy is one of the key enablers for various scenarios in the eHealth domain. Concerns regarding privacy legislation, standardisation and implementation are upcoming at the same time as the introduction of Electronic Health Records or the digital patient18. Establishing trust in this area could be the enabler for various applications as healthcare as itself is a multidisciplinary scientific challenge.
In general, in REACTION there can be see an issue of liability, rather than privacy. In short, it misses the point to concentrate on finding out which privacy issues arise when an ICT component (i.e. by the data fusion level) or a security mechanism malfunction or incur in errors in communication, which always is a key element of privacy protection. Based on the general premise which says “errors occur that put informational privacy at risk”, there is choice and flexibility about the technological solution that a developer adopts. Therefore, it seems better to concentrate on the issue of liability. Still, this choice should go hand in hand with responsibility. When errors occur in data fusion, there is a duty to notify, to react, and to compensate.
1. The general premise is that the possibility that technology makes errors is accepted. Acceptance means that the statement ‘technology or the use of it is open to errors’ holds true, both if we adopt the perspective of users, and also if we look at the technology from the developers’ perspective.
If we take this premise seriously, that errors are accepted, then the means that can reduce security risks are plural. This means that there is choice, on the developers’ side, about the technology solution to reduce errors (Phantom routing could be one of the means to re-balance the accepted premise, that there might be errors.) Now, choice of the technology is the outcome of reflection and deliberative processes, economic actors, lawyers, ICT people, social services, doctors etc…. The solution adopted is justified, checked, confronted, and supported and argued about.
A part of such deliberative process based on “choice” includes, or should include, responsibility. Responsibility means that when I (developers) choose a technology component to stem errors, I should, not only devote attention to the falls or possible malfunctions of the technology solution, identify them and prepare plans on how to address them, but also “assume” the responsibility that there might be errors that I can’t prevent or I can’t foresee.
2. This is where liability kicks in and can be explained by the following:
We see first a duty to inform expressed through “Security breach notification” mechanism. Security breach notification should ensure that users concerned are promptly and fully informed about the breach and about the action taken to stem malfunctions and their consequences. Security breach notification should be a legally binding mechanism of security components in Reaction.
Second, the technological security component should react, e.g., by re-routing or phantom routing.
Third, provide redress through compensation. There should not only be reaction to errors, but also compensation. Compensation concerns business models, liability clauses, etc…Compensatory measures can be flexible too, say, take into account that users can disconnect causing errors, foresee different compensation schemes, in tune with the technology solution that has been chosen. There is flexibility, but compensatory measures should be clearly stated and have legal force, be legally binding. The user should not be forced to collect evidence, find the responsible persons, and start up complex proceedings to advance his or her claims. The user is better off when he or she is compensated by the service provider, i.e. when the application finds out an error has occurred re. his or her personal data, it automatically compensates him or her.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 28 of 91 DATE 2012-03-05
With this in mind, one should go into the details of the technology solution and see how it could be related to the triangular ethical matrix
12 to notify, to react, and to compensate. One way is to map out plausible security
standards that can be of use for this approach.
3.6.3 ISO 27799
The ISO 27000 series of standards have been specifically reserved by ISO for information security matters. This of course, aligns with a number of other topics, including ISO 9000 (quality management) and ISO 14000 (environmental management). The health sector standard, ISO 27799 has now reached 'FDIS ballot' stage within its development cycle (Technical Committee ISO/TC 215). Its publication is therefore well on track, with a proposed title of 'Health Informatics - Security management in health using ISO/IEC 17799'. The standard itself provides guidance to health organizations and other holders of personal health information on how to protect such information via implementation of ISO17799/ISO27002. It specifically covers the security management needs in this sector, with respect to the particular nature of the data involved. The standard takes account of the range of models of service delivery within the healthcare sector, and provides additional explanation with respect to those control objectives within 17799/27002 which require it. A number of additional requirements are also listed. It is envisaged that adoption of ISO 27999 will assist interoperation, and better enable the adoption of new collaborative technologies in health care delivery.
ISO is also developing a health sector standard relating to audit trails for electronic health records. This has been provisionally numbered ISO 27789 / ISO27789. The content sections of ISO 27799 are: Scope, References (Normative), Terminology, Symbols, Health information security (Goals; Security within information governance; Health information to be protected; Threats and vulnerabilities), Practical Action Plan for Implementing ISO 17799/27002 (Taxonomy; Management commitment; Establishing, operating, maintaining and improving an ISMS; Planning; Doing; Checking, Auditing), Healthcare Implications if ISO 17799/27002 (Information security policy; Organization; Asset management; HR; Physical; Communications; Access; Acquisition; Incident Management; BCM; Compliance), Threats, Tasks and documentation of the ISMS, Potential benefits and tool attributes, and Related standards (The ISO 27000 Directory (security) 2008).
3.6.4 ASTM F2761-09
This standard specifies general requirements, a model and framework for integrating equipment to create an Integrated Clinical Environment (ICE). This standard specifies the characteristics necessary for the safe integration of medical devices and other equipment, via an electronic interface, from different manufacturers into a single medical system for the care of a single high acuity patient. This standard establishes requirements for a medical system that is intended to have greater error resistance and improved patient safety, treatment efficacy and workflow efficiency than can be achieved with independently used medical devices. This series of standards establishes requirements for design, verification, and validation processes of a model based integration system for ICE. This series of standards also is intended to define the requirements essential for safety and thereby facilitate regulatory acceptance. These requirements were therefore derived to support the clinical scenarios or clinical concepts of operations (ASTM International (safety) 2010).
12
Provides a means of examining the ethical positions of all interest groups and ensuring equality of treatment (justice/fairness).
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 29 of 91 DATE 2012-03-05
4. Models, ontology and terminology
This chapter will make a walkthrough of models, ontology and terminology that are used in information/computer science in order to create formal and semantic representations of the knowledge. These semantics are foreseen to play an important role in the REACTION data fusion model.
4.1 Introduction
In the REACTION platform, a number of components and systems will communicate with each other, therefore interoperability is a fundamental question. There are several levels of interoperability, including:
Functional interoperability: two or more systems are able to exchange data (human readable by the receiver)
Semantic interoperability: the ability to automatically interpret the exchanged data
Functional interoperability requires a common data model, or at least the mapping of the data structures used in the communicating systems. Semantic interoperability requires moreover a common terminology. An important objective of the REACTION project is to achieve semantic interoperability. The SemanticHEALTH project (Semantic Health 2009) developed a roadmap focusing on semantic interoperability issues of e-Health systems and infrastructures. It may be useful to build on its results.
Interpretation is needed to transform data into information. Knowledge can be derived from the information by learning and reasoning. The prior knowledge influences the whole process, for instance it contains the models for interpretation (see Figure 10).
DataKnowledge
Information
Learning
Reasoning Interpretation
Models
Figure 10 From data to knowledge.
Several methods are available to represent data, information and knowledge in a (medical) information system:
Data models are necessary to define a common data structure to enable data exchange among systems
Ontologies provide a way to represent the concepts and their relationships in a specific domain
Taxonomies define a common terminology to ensure that each actor understands the same concept on a certain term
Clinical guidelines define standardized processes based on the domain knowledge to improve quality and effectiveness and provide decision support
These methods will be introduced in this chapter.
4.2 Data modelling
The objective of data modelling is to design a data structure to represent the entities of a relevant real (or abstract) world (Bekke 2010). There are three abstraction forms for data modelling:
Classification to model “instance_of” relations
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 30 of 91 DATE 2012-03-05
Aggregation to model “has_a” relations
Generalization to model “is_a” relations
Some modelling methods such as relational data models have limited modelling capabilities as they do not support each abstraction type. Semantic data modelling enables the use of all three methods. Figure 11 illustrates part of a possible model of physiological measurements. It contains generalization (blood glucose measurement is an abstract measurement) and aggregation (to model the attributes of blood glucose measurement).
Blood glucose
measurement
unit
valuedate
time
patient
measurement
has_a
is_a
Figure 11 Semantic model of physiological measurements.
If the data is interpreted in a semantic way, it can be manipulated based on its meaning. Moreover it has the benefit to manage the domain knowledge together with the data. The semantic management of data can provide solution for problems where other technologies are ineffective or even inappropriate.
Different approaches can be used for semantic interpretation and data modelling, some will be described in the following sections.
4.2.1 Semantic annotation/tagging
A “tag” is a keyword which is assigned to some data item, for example a document or web page. If each tag we use is associated with a uniquely defined concept, we can speak about semantic tagging or semantic annotation. This association can be achieved for example by the use of controlled vocabularies or ontologies as semantic repository (see Figure 12). An example is the social bookmarking tool “Faviki” which uses the articles of Wikipedia as a controlled vocabulary (Miličić 2009). The use of ontologies has the advantage that it contains the relationships of the concepts as well. As a result e.g. the data items referencing to cities can be queried from the sample, because the repository contains the information which terms refer to cities. Semantic tagging has the restriction that only those terms can be used, which are defined in the repository, but this eliminates problems of synonyms or homonyms, e.g. a different concept is required for each meaning of a term. Semantic annotation is mostly used to provide meta-data to some text, usually the named entities in it (Atanas Kiryakov 2004). A named entity could be e.g. a person, an organization, a location. The words referring to universals can also be annotated with their formal definition of meaning in the specific context.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 31 of 91 DATE 2012-03-05
Patient XY was born in Budapest. He was admitted to the
University Hospital Graz with the diagnosis diabetes mellitus. ...
Budapest
Graz
City
Hungary
Austria
Country
type
type
partOf
partOf
type
type
UH Graz
Diabetes
mellitus
disease
type
locatedIn
Semantic repository
Figure 12 Semantic annotation with ontology as semantic repository.
Semantic annotation is used to annotate documents on the Web to be part of the Semantic Web. Full automatic annotation is not available yet, but there are a number of tools for semi-automatic annotation (Lawrence Reeve 2005). They can use pattern-based or machine learning-based methods.
4.2.2 Object oriented data models
Object oriented data modelling is a commonly used semantic modelling method. In this case the entities of the word are modelled as objects. An object may have attributes, which describe its properties. Relationships between the objects can be defined as well. The similar objects which have the same attributes can be grouped into classes. A class is similar to an abstract data type. The classes can be arranged into a hierarchy where the subclasses inherit the properties of their super class.
The object oriented data model is the most often used data model in recent information systems. There are a number of standards in the field of healthcare which define an object oriented data model: HL7 RIM (Reference Information Model), CEN 13606 and HISA (CEN 12967) found in chapters 5.1, 5.2.1 and 5.2.2.
4.2.3 RDF data model
RDF is initially designed to represent metadata about Web resources, but it can be considered as a semantic data model as well. It can also be used as a representation tool for more complex languages. RDF can describe static facts in form of triplets (subject – predicate – object) (Graham Klyne, et al 2004). RDF uses URIs (Unified Resource Identifiers) to uniquely identify the entities. The triplets can be combined to form larger graphs. There are various methods to store RDF graphs in a computable way, including XML-based and plain text representation.
In the following three representation methods are shown for the same data (a blood glucose measurement resulting 5.3 mmol/l): graph, XML and plain text (N-triplets).
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
Data stored in RDF can be queried just like a relational database. A query is a graph pattern which is matched against the RDF graph. The pattern may contain literals and variables. To this purpose special RDF-query languages exist (Peter Haase 2004). SPARQL has recently become a W3C recommendation, but other alternatives exist as well. They have slightly different features and syntax (e.g. most are SQL-like while others are inspired by rule languages) (W3C SPARQL 2008).
There are several frameworks for different platforms to support the storage and query of RDF data. They implement different query languages, although SPARQL has an increasing support: the early versions of SeSAME had a custom query language SeSQL while the recent version supports SPARQL as well. ARC designed extensions to support aggregation functions and insert/update/delete called SPARQL+ and a script language (Nowack 2008).
A SPARQL query to select all blood glucose measurements which are higher than 5 mmol/l looks like the following in Table 3:
To define an abstract model, RDF Schema (RDFS) (Dan Brickley, et al 2004) is required. It is able to model class hierarchy, properties and to define some constrains. RDFS also has a basic support for reasoning and inference.
A class definition for the former example is shown in the following Table 4. It defines “blood glucose” as a subclass of “measurement” and presents two literal properties (value and unit).
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
Table 4 Dual literal class properties of blood glucose.
4.3 Ontologies
Ontology can be defined as “the formal specification of shared conceptualization”. This means that it describes the concepts and their relationships in a specific domain, facilitating interoperability both for machines and people. It consists of an object oriented data model and logic. It is able to model the generic knowledge and to create specific data instances (individuals) as well. In some cases the same concept can be modelled either as a class or as an individual: for example different protein types can be instances of the “Protein” class, or can be subclasses of that. The most suitable approach must be decided according to the specific needs of the application.
Ontologies can be used for semantic access to resources, or for meaning negotiation and explanation. In the first case, the meaning of the terms is more or less known in advance by the members. A “lightweight ontology” focusing on the relationships which are relevant for the query (often just taxonomic relationships) can be satisfactory for this purpose. In the other case, the explicit representation of axioms and explanations is necessary. These ontologies can be called “foundational ontologies” which are more expensive and complex to build and need more human expertise. There are also different representation formats of ontologies. The graphical representation (an ordered graph) is the most readable for human users. There are more formal representations which are computer interpretable: e.g. ontologies can be expressed in F-logic or in Ontology Web Language (OWL) format. The latter is a W3C recommendation (Deborah L McGuinness, Frank van Harmelen 2004). OWL is XML-based and builds on RDF/RDFS formats, and has support for more constrains, relationship types, set operators etc. OWL has three sublanguages, in increasing complexity: OWL Lite, OWL DL (description logics) and OWL Full. An OWL representation of the former RDFS class is shown in the following. It defines a constrain on the unit property: it must be exactly one from the listed values (mmol/l or mg/dl).
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 34 of 91 DATE 2012-03-05
In 2009 the W3C published OWL2, which adds some new features to OWL, e.g. property chains, keys, new data types (W3C OWL Working Group 2009). It introduces also a new syntax called Manchester Syntax.
To generate new knowledge from the existing information, inferences can be drawn through the relationships between the objects.
Ontologies are “common and shared” by definition. A growing number of ontologies exist, and it is easy to use pieces of them to build one for a specific purpose. On the other hand, building an ontology is difficult and expensive, so reuse helps to reduce the efforts.
The Open Biological and Biomedical Ontologies (OBO) is a repository of open-source ontologies (OBO 2006). They have to satisfy some requirements, for example:
Common shared syntax (OBO syntax or OWL)
Orthogonal to other ontologies
Include textual definitions
Use the relations defined in the OBO Relation Ontology
Another repository is the BioPortal of National Centers for Biomedical Computing (NCBO Website 2010). It contains almost 200 ontologies in different formats (mainly OWL and OBO format). It is wider than OBO, but does not define strict requirements, e.g. some of the ontologies are closed-source. Most of the ontologies can be browsed on the website.
4.4 Taxonomies
To achieve semantic interoperability, a common “language” is necessary furthermore. Clinicians in different countries or even in different hospitals may use different terms and abbreviations for the same concepts. For a human reader they may mean the same, but for a computer program each are different. Therefore a unified terminology or coding system is essential.
Taxonomy is a classification of concepts. It is usually arranged in a hierarchical structure. Taxonomies are considered narrower than ontologies since the latter may define several types of relationships. Several taxonomies exist also in different medical domains. Most of these are restricted to a narrow domain: the International Classification of Diseases (ICD) is for instance a disease taxonomy. In fact, it is slightly broader than a taxonomy as it contains some cross-references as well. A common problem when creating taxonomies is that the terms can often be classified by more than one aspect. For example, a disease can be classified either by etiology (i.e. its cause) or by the affected tract. The ICD uses a mixture of these two aspects: e.g. infectious diseases are classified by etiology but most diseases are grouped by organs. Sometimes it is difficult to find a single aspect which is suitable for every term. A possible solution could be the introduction of multiple inheritance.
4.4.1 SNOMED
SNOMED (Systematized Nomenclature of Medicine) is a healthcare terminology managed by International Health Terminology Standards Development Organisation (IHTSDO) (IHTSDO 2010). Its recent version is SNOMED CT (Clinical Terms). Its aim is to serve as a comprehensive, multilingual terminology system to achieve semantic interoperability. Unlike to other classification systems such as ICD, the objective of SNOMED is to describe the detailed health state of individual patients.
SNOMED CT consists of over a million medical concepts, which have a unique identifier. They are arranged into an “is_a” hierarchy. Concepts are either primitives or defined from other concepts based on description logic. One or more terms or names called descriptions may be assigned to the concepts to describe synonyms. SNOMED concepts are often referred to by an information model such as HL7. If concepts are referred to directly by an information model then they are considered to be 'pre-coordinated'. The logic may be extended in the near future to include General Concept Inclusion Axioms.
SNOMED may contain redundancy as there could be semantically duplicate concepts. Some primitives could be transformed to defined concepts. To use SNOMED, a licence is needed from IHTSDO or from one of its National Release Centres. Research projects meeting some criteria may obtain a free licence. SNOMED is sometimes referred as an ontology, but it contains several ontological errors (Gergely Héja 2008).
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 35 of 91 DATE 2012-03-05
4.4.2 LOINC
Logical Observation Identifiers Names and Codes (LOINC) are a set of universal identifiers that encode laboratory data and other clinical observations. It contains codes among others for haematology, serology, microbiology, cell counts, vital signs, ECG, several imaging methods and even some score systems.
LOINC has been developed as a response to the demand for electronic movement of clinical data from laboratories to hospitals, physician's offices, and payers who all would use the data for clinical care and management purposes. It results in a LOINC database that facilitates the exchange and pooling of results for clinical care, vital signs, outcomes management, and research. Today, in order to electronically send report results, most laboratories and clinical services use HL7 but where its messages are interlinked with their internal code values. As a consequence, the clinical system in use will not be fully capable to comprehend its content and properly file the results it receives. Two countermeasures can be to either adopt the producer's laboratory codes (which becomes hard when receiving data from multiple sources), or to resolve each result producer's code system and map it to their internal code system. Both ways are over-sized and adapting LOINC codes as universal identifiers for laboratory and other clinical observations in the clinical system can solve this problem (LOINC 2010). By referral and as simulated above, LOINC can be recapped as an option to HL7 but the essential and subsequent question is whether the REACTION project will amount data on such a deep level as laboratory codes. Coincidently, receiving results from multiple sources lines up on the interoperating device model layers that in turn will carry a set of data management annotations. This creates an inhomogeneous demand magnitude within the HL7 if stated insufficient.
4.4.3 UCUM
UCUM (Unified Code for Units of Measure) is a code system that has the intention to include all units of measures being contemporarily used (including international science, engineering, and business). The purpose of UCUM is to facilitate a unequivocal electronic communication in a set of values together with their units. The electronic communication is under focus and is antagonistic to the communication between humans. EDI protocols (Electronic Data Interchange) are typical part of a application of UCUM although others can be used. UCUM is inspired by and based on ISO 2955-1983, ANSI X3.50-1986, and HL7's extensions called ISO+. There are several projects within UCUM but the relevant one is one that works with figuring out how procedure defined units fit into UCUM's semantic framework. Eclipse OHF also has an implementation available in Java and should be processed for possible involvement in the REACTION project (UCUM 2009).
4.4.4 OpenGALEN
The aim of the GALEN (Generalized Architecture for Languages, Encyclopaedias and Nomenclatures in medicine) project was to develop a new approach for the computerization of medical terminology. OpenGALEN is a non-profit organisation formed to support the adoption of the results of the project.
The name GALEN lies behind a technology that is designed to represent clinical information in a new way. It is intended to put the clinical data into the clinical workstation by producing a computer-based multilingual coding system for medicine and using a qualitatively different approach from those used in the past. GALEN is attempting to meet five challenges:
To reconcile diversity of needs for terminology with the requirement to share information
To avoid exponentially rising costs for harmonisation of variants
To facilitate clinical applications
To bridge the gap between the details required for patient care and the abstractions required for statistical, management, and research purposes.
To provide multilingual systems which preserve the underlying meaning and representation
To do so, GALEN advocates five fundamental paradigm shifts to resolve the fundamental dilemmas that face traditional terminologies, coding, and classification systems.
1. In the user interface, to shift from selecting codes to describing conditions. Interfaces using GALEN technology allow a central concept to be described through simple forms. If required, a precise code for reporting can be generated later automatically.
2. In the structure, to shift from enumerated codes to composite descriptions. Correspondingly, GALEN handles terminology internally analogously to a dictionary and a grammar
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 36 of 91 DATE 2012-03-05
so that indefinitely many descriptions can be composed from a manageable number of base concepts. Traditional coding systems are more like a phrase book; each sentence must be listed separately. No one would think of trying to list all the possible sentences in any natural language in a phrase book; listing all possible disease or procedure terms in a coding system is equally fruitless.
3. In establishing standards, to shift from a standard coding system to a standard reference model. Existing coding and classifications differ because they are used for different purposes. Finding a single fixed set of codes for all diseases, procedures, etc. which will serve all purposes is a chimera. The GALEN Common Reference Model provides a common means of representing coding and classification systems so that they can be inter-related - a common dictionary and grammar. The project’s slogan is ‘coherence without uniformity’.
4. In delivery, to shift from static coding systems as data to dynamic terminology services as software. Terminology is now at the heart of clinical software. GALEN originated the idea of a terminology server and is participating actively in the CorbaMed effort at standardising the software interface.
5. In presentation, to shift from translations of monolingual terminologies to multilingual terminologies. GALEN separates the underlying concepts from the surface natural language that presents them.
The GALEN CORE Model for representation of the Common Reference Model for Procedures contains the building blocks for defining procedures - the anatomy, surgical deeds, diseases, and their modifiers used in the definitions of surgical procedures. This document describes the structure the CORE model and gives a detailed account of its high level schemata followed by a detailed example of the use of the ontology for a portion of the model of the cardiovascular system and diseases.
The ontology for the GALEN CORE model is designed to be re-usable and application independent. It is intended to serve not only for the classification of surgical procedures but also for a wide variety of other applications - electronic healthcare records (EHCRs), clinical user interfaces, decision support systems, knowledge access systems, and natural language processing. The ontology is constructed according to carefully selected principles so that the reasons for classification are always explicit within the model and therefore available for processing and analysis by each application. This leads to an ontology in which most information lies in the descriptions and definitions. The hierarchies are built bottom-up automatically based on these definitions.
GALEN aims to produce an application-independent model by identifying two features of many existing ontologies that in turn will reduce application independence. Galen has designed means for avoiding them which are all summarised under the principle of separating taxonomies (A. Rector 1997) (A. Rector 2001). The fundamental principle is that when something has been classified in the way it has been, it should always be explicit in the model. Further, if a concept has been classified along several axes, then the information should be sufficient for an application to choose which axes are relevant to that application. This is achieved by the following two principles:
The subsumption (kind-of) relation is carefully distinguished from other transitive relations, such as partial (part-of) or causative (caused-by). A special mechanism, refinement is used to manage the interaction between subsumption and other transitive relations.
The taxonomy of elementary concepts is analysed into pure hierarchies in which each elementary concept has only a single elementary parent. The principle for specialisation for this primary taxonomy of elementary concepts for each part of this taxonomy is carefully chosen and uniform. All other classification is performed automatically on the basis of the descriptions and definitions of the concepts. For example the asserted taxonomy of elementary concepts for chemicals is based on their structure. There is a second, pure hierarchy of chemical functions which exists separately from the hierarchy of the chemicals themselves. Testosterone is asserted into the chemical hierarchy as being, structurally, a steroid but is then additionally described as having the function of a male sex hormone. It is therefore classified under both headings - chemical by structure and chemical by function - but the two hierarchies remain distinct and can be used for different purposes as required. The choice of principle for the taxonomy of elementary entities is necessarily arbitrary and is often made on the basis of convenience and efficiency. There are a few necessary exceptions to the rule that elementary concepts have only a single elementary parent, but they account for less than 5% of cases and occur for specific reasons (OpenGALEN.org 2010).
GALEN’s approach can therefore be stated to include:
Instead of enumeration all terms: definition of base concepts and a grammar to build composite descriptions
Separate concepts from terms, support multilingual terminology
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 37 of 91 DATE 2012-03-05
GALEN also defines a formal representation language called GRAIL which uses description logic. It is used for the Common Reference Model, a reusable, application- and language independent model of medical concepts, i.e. a set of building blocks and constrains. It can be extended for specific applications if necessary. The model is available in GRAIL and OWL-RDF translation (OpenGALEN.org 2010).
4.4.5 IHTSDO
The International Health Terminology Standards Development Organisation (IHTSDO) is an international non-profit organization that acquires, owns and administers the rights to SNOMED CT and other health terminologies and related standards. The purpose is to develop, maintain, promote and enable the uptake and correct use of its terminology products in health systems, services and products around the world, and undertake any or all activities incidental and conducive to achieving the purpose of the association for the benefits of its members. The IHTSDO focus is to enable the implementation of semantically accurate health records that are interoperable and to give support to its members by education, development resources and licensees on a global perspective.
4.5 HIS/CIS interoperability
The information flows and interaction between the health information systems (HIS), Clinical Information Systems (CIS) and the REACTION platform provide the knowledge management capabilities of REACTION applications. The data are promoted to information by context awareness in the data management subset. And information can be promoted to knowledge by querying HIS. Information about the patient's actual health parameters needs to be placed in the context of the patient's medical history, which is obtained from the HIS Electronic Patient Record. Evidence based case management requires access to knowledge bases where carers can correlate medical knowledge to the case in question. Knowledge bases can be automatically updated with randomised case information for improved case management. Also health information from outside the REACTION platform is accessible. Comprehensive physiological models can be accessed via web interfaces and the result fed back to the physician responsible for the case. General medical and clinical information in the open internet can be semantically queried and the results put together in a comprehensive report on risk assessment, which will be personalised and presented to the patient in the self-management scheme. Also information to assist in crisis management is available via web services, such as route planning, resource planning, i.e. where is the nearest qualified nurse and how long time will it take to get to the patient? Therefore, the whole chapter 4 have so far described the methodology behind the semantics in knowledge bases and provide sufficient understanding on both conceptual as modelling functionalities. As HIS will be integrated in REACTION applications in form of services, services need to be simple query services or data storage services. In all cases, these services will subsequently be orchestrated in functional workflows by the service orchestration subset (i.e. a data fusion management) which in turn is based on the semantic interoperability and concatenated standards reviewed here.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 38 of 91 DATE 2012-03-05
5. Standards relevant for data fusion
In order to fully understand what standards are and why they should be applied in the development of health information systems [HIS] one have to review the background facts as well as the definitions of those systems. This chapter presents selected HIS standards and their relationships.
Health informatics is the intersection of information science, computer science and health care. It deals with the resources, devices and methods, required to optimize the acquisition, storage, retrieval and use of information in health and biomedicine. Health informatics tools include not only computers but also clinical guidelines, formal medical terminologies, and information and communication systems. A subsection of health informatics is eHealth. eHealth is more targeted towards those electronic processes and communications that take place in between the patient, the system and the career. For this reason it is important from a medical and technological perspective, to understand how the information flow occur and transform in order to reliably and successfully develop the REACTION platform as whole. Although the REACTION project spans over the entire definition of health informatics, e.g. interoperability towards EHR, EPR and other HIS, it is important to understand why particularly standards should be applied at this eHealth sublevel. One reason is that this sublevel relates to the relevant generic technologies for messaging protocols, data fusion and mediator architectures, SOA and novel technologies for semantic management of data and services found in the project.
Figure 14 A generic eHealth platform that shows the information flows from four parties including some
standard setting interfaces13
.
In 2004 the EC issued its communication: COM(2004) 356 final: “e-Health – making healthcare better for European citizens: An action plan for a European e-Health Area” which sets out specific targets for the use of eHealth in several areas, including boosting the deployment of health informatics networks (2004-2008) and especially for this deliverable, interoperability standards for EHR and messaging. All of these will be greatly impacted by the availability of the REACTION platform.
The REACTION project will therefore focus on and validate the REACTION platform in two operational healthcare domains 1) professional decision support in hospital environments for diabetic patients admitted to the general wards, and 2) control and management of outpatients in clinically diabetes schemes, including therapy compliance and support for self-management. All applications will include closed-loop feedback mechanisms in a variety of forms.
In the first application domain of REACTION, the platform will connect to healthcare professional, medical expert knowledge systems and legacy healthcare systems and offer closed-loop feedback in hospital environments to carers at the point of care. In the second application domain, the REACTION environment will target the outpatient regime and facilitate personalised feedback to clinicians and patients, including medium term risk assessment for patient education and life-style change support. In a third and final
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 39 of 91 DATE 2012-03-05
application domain, the project aims to demonstrate and evaluate closed-loop glycaemic control schemes with autonomous regulation of insulin dose through a closed-loop approach, which will include some predictive insulin assumptions. REACTION will be based on the concept of trust as a multilateral relation between stakeholders in a community of patients, informal carers and professional healthcare providers. Hence, the platform will include mapping and brokering between security models, and user and device profiling management. The REACTION privacy model will also have support for virtualisation of devices and users for secure connectivity and delegation of services, as well as user empowered authentication and authorisation.
Figure 15 A simplification of the REACTION platform concept showing primary standard pathways with
aimed (blue and red) delivery end points.
According to the Description of Work (DoW) for the REACTION project, the platform should favourably be operable in two different spheres (where one of these are the already mentioned operational healthcare domains) followed by each two different sub-spheres representing different use and scenarios. The initial gathering of requirements made in work package 2 and its deliverables D2.1 and D2.5 confirm the need of these. Figure 15 shows a simplified version of the very first figure found in the DoW, the REACTION platform concept, but where electronic pathways and end-points of user visualisations are marked by the double edged arrows. The exception is the blue arrow resembling the directed communication between the primary care and the out-patient and the red arrow resembling the internally strived communication between the clinic and the admitted/in-patient. Nonetheless, both primary care and the clinic fall under the same umbrella in REACTION, i.e. the communication is routed through same paths but with different approach of responsibilities. The rest of the arrows can be said to represent one or other communication standard matching that technological, medical, and security based setting. The data fusion in REACTION sub-consequently needs to be able to deal with any standard present in each of its sphere or domain whether it concerns authenticity, accessibility, closed loop feedback, etc. between actuators and functionalities in the REACTION platform.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 40 of 91 DATE 2012-03-05
5.1 Health Level Seven international (HL7)
Interoperability for IEEE is the ability of two or more systems or components to exchange information and to use the information that has been exchanged. In the world of information system the most diffuse standard in order to assure interoperability is HL7 (http://www.hl7.org) v2.x or v3 and Clinical Document Architecture (CDA) for the exchange of clinical documents. The name comes from "Health Level 7", which refers to the top layer (Level 7) of the Open Systems Interconnection (OSI) layer protocol for the health environment.
Founded in 1987, Health Level Seven International (HL7) is a global authority for healthcare Information interoperability and standards with affiliates established in more than 30 countries.
HL7 is a non-profit, ANSI accredited standards development organization dedicated to providing a comprehensive framework and related standards for the exchange, integration, sharing, and retrieval of electronic health information that supports clinical practice and the management, delivery and evaluation of health services. HL7’s more than 2,300 members represent approximately 500 corporate members, which include more than 90 percent of the information systems vendors serving healthcare. HL7 collaborates with other standards developers and provider, payer, philanthropic and government agencies at the highest levels to ensure the development of comprehensive and reliable standards and successful interoperability efforts.
HL7 has a message-oriented architecture. It means that the application in which an event occurs will send a message to other applications rather than serving a request.
It provides standards for interoperability that improve care delivery, optimize workflow, reduce ambiguity and enhance knowledge transfer among all stakeholders (including healthcare providers, government agencies, the vendor community, fellow SDOs and patients). In addition HL7 has produced a family of standards for
Patient administration and demographics
Orders and results for Clinical Lab/Pathology, Imaging
Signs and symptoms, diagnosis and treatments
Pharmacy prescription dispensing and administration
Patient care messages
Claims and reimbursements
Scheduling and managing healthcare resources
Clinical research and public health/disease surveillance
where the information may be shared and re-used from many healthcare domains.
The messaging standard has been defined since version 2.x of the standard. The version 2 was widely accepted as the healthcare interoperability standard since the 90’s. In general version 2.x has the following characteristics:
Broad functional coverage
Highly adaptable
– IS environments differ
– System capabilities variation
Vocabulary independent
Least common denominator: technological base
– Not clear support for new technologies
Object technologies
XML and web technologies
– Not clear support for security operations
The most used version all over the world is 2.3.1. The messages are ASCII messages and they have a "human readable" form. The version 2 of the standard defines messages that are divided in one or more segments which content information is formatted by using delimitations characters, like circumflex accent (^), ampersand (&) and pipes (|), and uses the basic TCP/IP protocol for the transmission. The messages correspond to healthcare events that healthcare related applications exchange among some others.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 41 of 91 DATE 2012-03-05
An example of an HL7 message version 2 is shown in the figure below:
Figure 16 Radiology Data.
On the other hand the version 3 of HL7 is model based. The central Healthcare information model for HL7 Version 3 is called the Reference Information Model (RIM). This version of HL7 uses Object Oriented Design to facilitate Object Oriented methodology and information architecture, not ad hoc design and can be extended whenever new healthcare information need to be added. Additionally does not require changing what already exists and finally but not less important is a scalable and flexible version.
Main characteristics of version 3 are:
Design based on consensus RIM (Reference Information Model)
Adaptable to current and future technology bases
Vocabulary-level interoperability
Explicit conformance model
Built on strongly accepted industry base technologies
The messages are XML documents. Each message is a string of text with specific information enclosed by tags. Start and end tags have the same format as in html documents (start :< tag>, end :< /tag>). The tags in the document can be experienced by attributes, for instance <tag attribute="some value">. These tags and attributes are resulted from the HL7 Reference Information Model (RIM) and the HL7 Data Types. To end with, the structure of each message is defined in an XML schema, which specifies the tags and the attributes required or being acceptable in the message, their order and the number of times each may occur, along with comments unfolding how the tags must be used.
In the HL7 framework, the CDA (Clinical Document Architecture) is an HL7 standard for the representation and machine processing of clinical documents in a way which makes the documents both human readable and machine processed; the preservation of the content is guaranteed since it is an XML-based document mark-up standard that specifies the structure and semantics of clinical documents for the purpose of exchange.
CDA documents are complete and defined information objects that can include text, images, sounds, and other multimedia content. These documents are based on RIM and on
HL7 version 3 data types and have been created with the aim of standardizing the organization and structure of medical documents and easing the exchange of documents.
The benefit of using such a standard as HL7 is to improve efficiency, lower the cost and reduce the risk. A major decision that must be taken is the choice of the HL7 version that will be implemented in all the various sub-systems of the REACTION platform which is also the reason for describing it ahead of the two REACTION platform settings here below.
5.1.1 IEEE 11073
The IEEE, an association dedicated to advancing innovation and technological excellence for the benefit of human, is the world’s largest technical professional society. It is designed to serve professionals involved in all aspects of the electrical, electronic and computing fields and related areas of science and technology that
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 42 of 91 DATE 2012-03-05
underlie modern civilization. IEEE’s roots, however, go back to 1884 when electricity was just beginning to become a major force in society.
The formation of an ISO/IEEE 11073 (i.e. X73) personal health device data work group has enabled plug-and-play interoperability for personal health devices by developing new standards within the family of existing ISO/IEEE 11073 standards for medical device communications. These new standards address transport-independent application and information profiles between personal Telehealth devices and monitors. The reviewed standards give adequate descriptions on the postulated novel technologies within the REACTION project and should therefore be regarded as crucial for the REACTION platform and its discrete device implementation.
For the project cause, the selected IEEE standard is the one of 11073 that addresses Medical / Health Device Communication Standards in a family of ISO, IEEE, and CEN. These joint standards address the interoperability of medical devices. The ISO/IEEE 11073 standard family defines parts of a system, with which it is possible, to exchange and evaluate vital signs data between different medical devices, as well as remote control these devices.
Of specific interest to the REACTION platform are the set of standards defined for personal health devices. These are based on IEEE 11073-20601:2008 as the base standard, which defines an optimised exchange protocol. This standard supports a set of device specializations, each of which profiles a specific device, including the glucose meter (IEEE 11073-10417:2009) and insulin pump (IEEE P11073-10419).
The Personal Health Devices standards are built on IEEE 11073-10101 (standardised nomenclature) and IEEE 11073-10201:2005 (domain information model) and are optimised by using a simplified communication model and reduced hierarchical model. Its exchange protocol is optimised for low power and low bandwidth by being binary based and using an association based model, where common, unchanging data is transmitted only once, and only the attribute changes are transmitted.
IEEE 11073-20601:2008 is designed to be independent of the transport layer, defining generic characteristics that must be provided by any given transport layer. Industry consortia have defined versions of their technology to support IEEE 11073-20601:2008 in a standard way. This currently includes the ZigBee Health Care Profile (ZigBee Alliance 2009), the Bluetooth Health Device Profile (Bluetooth: SIG Press
Releases 2009) and the USB Personal Healthcare Device Class (USB Implementers Forum, Inc 2007).
Figure 17 PAN interface (from Continua Design Guidelines V1.5).
Currently standards for the devices in Figure 17 are defined for use, and these represent the devices perceived with the greatest level of interest for use. More standards for devices are being considered as interest grows. Devices which are commercially available following these specialisations and Continua compliant are listed in Table 1.
OPTIMIZED DATA EXCHANGE PROTOCOL LAYER
TRANSPORT LAYER
Bluetooth Health Device Profile USB Personal Healthcare Device
Class
ISO/IEEE Std 11073-20601
DEVICE SPECIALIZATION LAYER
Pulse Oximeter
Blood Pressure
Glucose Meter
Thermometer Weighing Scale
Independent Living Activity Hub
Cardiovascular Fitness & Activity
Strength & Fitness Activity
Lower Layer Protocols
Higher Layer Protocols
ZigBee Health Care Profile
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 43 of 91 DATE 2012-03-05
Specialisation Standard Status
Basic ECG (1 to 3 lead) IEEE P11073-10406 In development
Blood pressure IEEE 11073-10407:2008 Standard
Body composition analyzer IEEE P11073-10420 In development
Glucose meter IEEE 11073-10415:2009 Standard
Independent living activity hub IEEE 11073-10471:2008 Standard
INR IEEE P11073-10418 In development
Insulin pump IEEE P11073-10419 In development
Medication monitor IEEE 11073-10472:2010 Standard
Peak flow IEEE P11073-10421 In development
Pulse Oximeter IEEE 11073-10404:2008 Standard
Thermometer IEEE 11073-10408:2008 Standard
Weighing scales IEEE 11073-10415:2008 Standard
Table 6 IEEE 11073 Personal Health Device Standards.
IEEE 11073-20601:2008 provides a generalised object modelling methodology, which has been used to develop the existing device specialisations and may be used to model new devices such as may be developed as part of the REACTION project.
Take the weighing scale as an example, as shown in Figure 18.
class PHD-Weighing Scale
Weighing Scale
Body Weight
1..*
1
Body Height
0..*
Body Mass Index
0..*
Numeric NumericNumeric
1 1
MDS
class PHD-Weighing Scale
Weighing Scale
Body Weight
1..*
1
Body Height
0..*
Body Mass Index
0..*
Numeric NumericNumeric
1 1
MDS
Figure 18 Object model for Weighing Scale following IEEE 11073-10415:2008.
The approach of IEEE 11073-20601 is to use a two level hierarchy, with the top level being the MDS (Medical Device System) object. This object has predefined attributes that are used to specify the type of the device and aspects that are general to all devices (manufacturer, unique id).
Beneath the MDS are the objects that report observed values. These objects are predefined with attributes that take values to define the specifics of the observed value (type of data, units, etc).
The approach is generic, and so IEEE 11073-20601:2008 may be used to describe any simple medical device, such as is to be used in the REACTION platform. Furthermore, the existing specialisations can act as templates for different categories of device.
A further important aspect of the use of IEEE 11073-20601:2008 is that the object models form the basis of further messaging, such that the IHE-PCD01 message takes its structure directly from the object model of the device. In addition, the nomenclature of IEEE 11073-10101 is used directly for the IHE-PCD01 message.
5.1.2 ISO/TC 215
These ISO workgroups work with standardization in the field of information for health, and Health Information and Communications Technology (ICT) to achieve compatibility and interoperability between independent
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 44 of 91 DATE 2012-03-05
systems by ensuring compatibility of data for comparative statistical purposes (e.g. classifications), and by reducing duplication of effort and redundancies. As implied, ISO/TC 215 consists of several workgroups and these handle the following fields: Data structure, Messaging and communications, Health Concept Representation, Security, Health Cards, Pharmacy and Medication, Devices, and Business requirements for Electronic Health Records (see Figure 19).
Figure 19 showing the ISO/TC215 workgroup diagram
14.
Furthermore, the History of the Healthcare Information and Management Systems Society (HIMSS) works since 2003 together with American National Standards Institute (ANSI) in order to support the ISO/TC 215 secretariat (ISO 215 2010).
5.1.3 ISO/TC 251 WG IV
CEN/TC 251 (CEN Technical Committee 251) is a four part workgroup within the EU working on standardization in the field of Health Information and Communications Technology (ICT). The goal is similar to the ISO/TC 215 by trying to achieve compatibility and interoperability between independent systems and to enable modularity in Electronic Health Record systems. The aim of this WG (IV) is to develop and promote standards that enable the interoperability of devices and information systems in health informatics. The scope covers three main areas:
1. Intercommunication of data between devices and information systems.
2. Integration of data for multimedia representation.
3. Communication of such data between source departments and other legitimate users elsewhere in the healthcare sector, in order to facilitate electronic healthcare record provision.
The main concern of the WG IV is creating support to technology for interoperability and by addressing this, the issues of methodology, quality, security and architecture will require liaison with the other WGs in ISO/TC 251, and other standards. (Working Group IV: Technology for interoperability 2009).
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 45 of 91 DATE 2012-03-05
5.1.4 ASTM E2182-84 Standards
ASTM International, originally known as the American Society for Testing and Materials (ASTM) is one of the largest voluntary standards development organizations in the world. ASTM supply with a trusted source for technical standards for materials, products, systems, and services and they are widely known for their high technical quality and market relevancy, ASTM International standards (ASTM International 2010) therefore have an important role in the global information infrastructure that guides design, manufacturing and trade in the global eHealth sector. Relevant standards for this area are the following:
ASTM E2182 - 02 Standard Specification for Clinical XML DTDs in Healthcare
ASTM E2184 - 02 Standard Specification for Healthcare Document Formats
ASTM E2183 - 02 Standard Guide for XML DTD Design, Architecture and Implementation
The above lined up standards could be of interest for the REACTION project but with the risk of leaning towards standards originally conformed to American requirements and not to the EU domain.
5.1.5 Continua Health Alliance
The Continua Health Alliance (Continua Health Alliance 2010) was formed to establish an ecosystem of interoperable personal health systems that empower people and organizations to better manage their health and wellness. This goal was to be accomplished by ensuring interoperability between components, systems, and subsystems incorporated within these health systems. To achieve this aim, Continua established a Technical Working Group (TWG) to select the standards and specifications and define Design Guidelines to further clarify the standards and specifications to ensure interoperability might be achieved.
Continua Health Alliance is a non-profit, open industry coalition of healthcare and technology companies joining together in collaboration to improve the quality of personal healthcare. With more than 200 member companies around the world, Continua is dedicated to establishing a system of interoperable personal health solutions with the knowledge that extending those solutions into the home fosters independence, empowers individuals and provides the opportunity for truly personalized health and wellness management. The mission is to establish a system of interoperable personal Telehealth solutions that fosters independence and empowers people and organizations to better manage health and wellness. The Continua Health Alliance is comprised of technology, medical device and health care industry leaders dedicated to making personal Telehealth a reality. The objectives include:
Developing design guidelines that will enable vendors to build interoperable sensors, home networks, Telehealth platforms, and health and wellness services.
Establishing a product certification program with a consumer-recognizable logo signifying the promise of interoperability across certified products.
Collaborating with government regulatory agencies to provide methods for safe and effective management of diverse vendor solutions.
Working with leaders in the health care industries to develop new ways to address the costs of providing personal Telehealth systems.
In order to build trust and ensure customer peace of mind, Continua Health Alliance has created a product certification program with a recognizable logo signifying interoperability with other certified products. The Continua Health Alliance's Design Guidelines
15 contains references to the standards and specifications that
Continua selected for ensuring interoperability of devices. It also contains additional Design Guidelines for interoperability that further clarify these standards and specifications by reducing options in the underlying standard or specification or by adding a feature missing in the underlying standard or specification. These Continua Alliance guidelines focus on the following interfaces: PAN-IF - A common Interface to Personal Area Network health devices, xHRN-IF - An interface between Disease Management Services (DMS) WAN devices (i.e. xHR Senders) and Electronic Health Record (EHR) devices (i.e. xHR Receivers). These guidelines were specifically written for device manufacturers that intend to go through the Continua Certification process with their devices, companies that integrate Continua devices in systems and subsystems, and test labs that certify compliance to Continua specifications.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 46 of 91 DATE 2012-03-05
5.2 In-hospital care and towards the EHR
One of the major differences between inpatient and outpatient control of glycaemic levels is the fact that tight glycaemic control in hospitalised patients has to be provided by healthcare physicians and/or nurses. Achieving the goal of tight glycaemic targets requires extensive nursing efforts, including frequent bedside glucose monitoring, training to handle control algorithms or guidelines with intuitive decision taking and most importantly additional responsibility to prevent hypoglycaemic episodes. Therefore, one of the goals in REACTION is to facilitate a wide spread Tight Glucose Monitoring (TGM) in patients with diabetes, demonstrate closed-loop feedback involving special diabetes team and integration with workflow systems. Potential impact can extend to also preventing stress induced diabetes in normal patients. Still, it is important to bridge the IEEE11073 as a standard in the out-patients environment and make use of it, where applicable, in the out-patient settings. This means that the same protocols can be used but presumably among different devices. A common standard approach would here possibly improve the listed interoperability within REACTION.
5.2.1 CEN 13606
The CEN/ISO EN13606 is a European norm from the European Committee for Standardization (CEN). It is also approved as an international ISO standard as it is designed to achieve semantic interoperability in the electronic health record communication regardless device type.
The goals of the EN13606 norm are (excerpted from the EN13606 introduction): "The overall goal of this standard is to define a rigorous and stable information architecture for communicating part or all of the electronic health record (EHR) of a single subject of care (patient). This is to support the interoperability of systems and components that need to communicate (access, transfer, add or modify) EHR data via electronic messages or as distributed objects. The interoperability is made possible by preserving the original clinical meaning intended by the author and reflecting the confidentiality of that data as intended by the author and patient." (en13606 2010).
To achieve this objective, EN13606 follows a dual model architecture. This defines a clear separation between information and knowledge. Information is structured through a reference model that contains the basic entities for representing any information of the EHR. Knowledge is based on archetypes, which are a form of formal definitions of clinical concepts (e.g. discharge report, glucose measurement or family history). Knowledge thereby comes in the form of structured and constrained combinations of the entities of a reference model. It also provides a semantic meaning to a reference model structure. The interaction of the reference model (that stores data) and the archetype model (which semantically describes the data structures) provides an capability of an earlier unmarked evolution to information systems. Knowledge (archetypes) can and will change in the future while most data will remain untouched.
A reference model is an object oriented model. It is used to represent the generic and stable properties of health record information and comprises a small set of classes that define the generic building blocks to construct the EHRs. It specifies how health data should be aggregated to create more complex data structures. It also defines the context information that must accompany every piece of data in order to meet ethical and legal requirements. In sum, it encodes what it is meant, not how it is intended to be presented. Typically, a reference model contains:
1. A set of primitive types.
2. A set of classes that define the building blocks of EHRs. Possible annotations in an EHR (i.e. entities) must also be an instance of one of these classes.
3. A set of auxiliary classes that describe the context information to be attached to an EHR annotation including versioning information.
4. Finally it may involve classes that describe demographic data and that communicate with EHR fragments.
An archetype is a structured and constrained combination of entities of a reference model that represents a particular clinical concept and by which are composed of three main sections: header, definition and ontology. The header section basically contains metadata about the archetype, such as an identifier or authoring information while there in the definition section is where the clinical concept which the archetype represents is described. The third section is where the ontology section is defined by the entities which in the definition section are described and bound to terminologies. (en13606 2010).
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 47 of 91 DATE 2012-03-05
5.2.2 HISA
This EN 12967 standard has been developed by CEN and defines the essential elements of a Service Oriented Architecture (SOA) as well as a methodology for localization which together can become particularly useful for large healthcare organizations. HISA (Health Informatics Service Architecture) is based on the Open Distributed Processing (ODP) framework from ISO 10746. It contains the following three parts: 1) enterprise-, 2) information-, and 3) computational viewpoints. Being the starting point for the consideration for an International standard in ISO/TC 215, the basic principles of HISA are to provide a set of health specific middleware services as a common platform for various applications for regional health information systems, or large integrated hospital information systems. These are well established following a previous standard. These viewpoints are explained by the following general information brought from their online source (ISO 2010):
ISO 12967-1:2009 provides guidance for the initial description, planning and development of new systems, but also for the integration of existing information systems, both within one enterprise and across different healthcare organizations. This is made possible through an architecture integrating the common data and business logic into a specific architectural layer (i.e. the middleware) that is distinct from individual applications and accessible throughout the whole information system through services.
ISO 12967-2:2009 specifies the fundamental characteristics of the information model to be implemented by a specific architectural layer (i.e. the middleware) of the information system to provide a comprehensive and integrated storage of the common enterprise data and to support the fundamental business processes of the healthcare organization, as defined in ISO 12967-1. The information model is specified without any explicit or implicit assumption on the physical technologies, tools or solutions to be adopted for its physical implementation in the various target scenarios. The specification is nevertheless formal, complete and non-ambiguous enough to allow implementers to derive an efficient design of the system in the specific technological environment that will be selected for the physical implementation. This specification does not aim at representing a fixed, complete, specification of all possible data that can be necessary for any requirement of any healthcare enterprise. It specifies only a set of characteristics, in terms of overall organization and individual information objects, identified as fundamental and common to all healthcare organizations, and that is satisfied by the information model implemented by the middleware.
ISO 12967-3:2009 specifies the fundamental characteristics of the computational model to be implemented by a specific architectural layer of the information system (i.e. the middleware) to provide a comprehensive and integrated interface to the common enterprise information and to support the fundamental business processes of the healthcare organization, as defined in ISO 12967-1. The computational model is specified without any explicit or implicit assumption about the physical technologies, tools or solutions to be adopted for its physical implementation in the various target scenarios. The specification is nevertheless formal, complete and non-ambiguous enough to allow implementers to derive an efficient design of the system in the specific technological environment which will be selected for the physical implementation.
Current approaches to HISA in EU
Most healthcare organisational structures consist of centre networks that are distributed over a local or more global territory. These are characterised by a high degree of heterogeneity and diversity where the individual structure of one of each are evolving towards an integration of a set of specialised functional units. These units need to be able to share common information (e.g. data about a patient that visit several different units) and to by this operate according to the integrated workflows set by a primary model. This model is usually developed upon the concept of SOA. Therefore, HISA can conclusively be seen as a new standard that defines a healthcare SOA that in turn can secure openness and vendor-independence by identifying the general principles of healthcare systems service architecture. In Europe, today, there are a number of large healthcare organisations that are basing their healthcare planning on the HISA middleware principles by which various technical solutions are offered from different vendors. Examples are:
Uppsala, Kronoberg, Jönköping, Östergötland, Västmanland, Kalmar and Värmland County Councils (Sweden) handling approximately 200.000-500.000 inhabitants each and where the HISA implementations are based on a Java (J2EE) architecture with choice of application server and SQL database,
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 48 of 91 DATE 2012-03-05
The Università Cattolica del Sacro Cuore (Rome, Italy). Their system relies on a healthcare-specific middleware product from GESI
16 that has services allowing different applications to access the
common information heritage and to perform common business processes through a set of services. On top of the GESI middleware system there are several applications that give support to the user activities.
Copenhagen Hospital Corporation (H:S) (Denmark) including 10 hospitals and 1.6 million inhabitants, also uses GESI but their healthcare information exchange is not only done with the direct HISA interfaces but also by utilising the underlying HISA interfaces and thereby messaging with other standards such as HL7, XML and diagnostic equipment (ECG and imaging).
In sum, HISA principles say that A) information must be separated from specific applications and accessible through services and B) the logic of services must be independent from technological issues. But there is a problem that remains and that is that HISA in these cases is foremost locally or regionally implemented. HISA does also not work as an alternative but a complement to other standards for health informatics where HISA can manage specific messages that are developed by HL7 or a general communication standards from EHR (i.e. from CEN or openEHR) (Klein, Sottile and Endsleff 2006) (eHealth ERA 2007).
5.2.3 Integrating the Healthcare Enterprise (IHE)
Integrating the Healthcare Enterprise (IHE) is an organisation that is responsible for selecting standards and profiling standards to create an interoperable system within different health domains. IHE uses extensively HL7 as the basis of many of its profiles. Of specific interest is the work that is being undertaken on profiling personal care devices and the development of a standardised HL7 V2 protocol (IHE-PCD01) to support medical devices. This is designed to support equally medical devices built specifically on an IHE-PCD01 profile and IEEE 11073 PHD devices through a generic mapping. IHE-PCD01 is the message format of choice for Continua devices. It is transaction based, in contrast to IEEE 11073 PHD, and contains all the information. The following example (Table 7) shows a message reporting an observation from an IEEE 11073 PHD weighing scale device with body mass, body length, and BMI.
Table 7 Example of weighing scale IHE observation report.
16
http://www.gesi.it/gesi_en/prodotti.asp
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 49 of 91 DATE 2012-03-05
6. Technologies for semantic management of data and services
One of the objectives within the REACTION project is to research and develop a model-driven Data Management architecture. Data Management is a broad field of study, but essentially is the process of managing data as a resource that is valuable to an organization or business. Simplified, it can be said that data management is the process of developing data architectures, practices and procedures dealing with data and then executing these aspects on a regular basis. Deploying a model-driven architecture to data management involves a set of guidelines for the structuring of technical requirements specification. These are expressed as models that defines the system functionality which implements application development and deployment, the service oriented architecture (SOA) for core service functionalities, data manipulation, data fusion and event handling. Data manipulation and data fusion has been previously reviewed in chapter 3 and so is not focused here but focus will be on the semantic management which is part of the overall data management architecture.
6.1 Semantic management in middleware
Before we jump into the terms of semantic management it could be fruitful to review the underlying technology, i.e. the middleware. The primary role of a middleware is to manage the very high complex and heterogeneous characters of a distributed infrastructure. As it offers abstractions within programming (i.e. it simplifies the programming environment for distributed application developers) it also at the same time can support a very complex software infrastructure that implements these abstractions. Nonetheless, the middleware satisfies the need of integrating applications, most often within a single company although today one speaks more of application integration as from intra-enterprise application integration. The latest notion of middleware came therefore to be developed as to enable a B2B integration, a category where application servers and web services fall into. Both application servers and web services fed the evolution of the middleware and both middleware types can be used in the development of distributed applications.
In an application server the core functionality is based on Sun's J2EE and Microsoft's .NET where both are similar in their functionality. This will make an important implication which is that the presentation logic of the application (i.e. the co work of HTTP and the Web) will get a much more relevant role than in conventional middleware. An application server therefore might intend to support several types of clients connected to it such as mobile phones, applications, PDAs, Web browsers etc. A Web-based middleware will interact with these clients via its Web server which in turn delivers generated HTML pages both statically and dynamically. At the same time the client side (i.e. the user clients) can make HTTP requests where different kind of support for parsing and transforming XML documents will send what by then will be some kind of semantic data derived from a contextual source. In order to give full description of the contextual content one first need to have modelled an ontology (i.e. stated a common information exchange reference model) upon which the explicit specification of any conceptualisations found within the vicinity of the middleware's deployment (i.e. based on the environment it operates in) can be established (Gruber 1995).
As previously described in chapter 4.3, ontology "describes the concepts and their relationships in a specific domain". Therefore, an ontology practically constitutes a passive object that does not enable any semantics descriptions until an inference engine is executed. When executed querying and reasoning with the semantic component and service descriptions may occur and is usually based on logics (syntactic derivation rules). To be successful with this, one must choose a specific platform and an existing ontology tool suite (Oberle 2006). In our case this is described a little bit further down but let's first take a look on how data fusion may play a role in the interoperability between device measurements, context, environment and patient history.
Interoperability is a property referring to the ability of diverse systems and organizations to work together (inter-operate). Moreover, the IEEE defines interoperability as the ability of two or more systems or components to exchange information and to use the information that has been exchanged (Oberle 2006). Two interoperability types are defined here below:
6.1.1 Syntactic interoperability
When and if two or more systems are capable of communicating and exchanging data with each other it is said that they are exhibiting syntactic interoperability. Here the fundamental part are specified data formats, communication protocols and the like where in general, XML or SQL standards provide the syntactic interoperability. Important notice is that syntactical interoperability is required for any attempts of further interoperability.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 50 of 91 DATE 2012-03-05
6.1.2 Semantic interoperability
Semantic interoperability is the ability to automatically interpret that the information was exchanged meaningfully and accurately. This in order to produce useful results as defined by the end users of both systems and moreover, to achieve semantic interoperability, both sides must refer to a common information exchange reference model but where the content of the information exchange requests are unambiguously defined (i.e. what is sent is the same as what is understood).
The basis for semantic interoperability in REACTION will be the use of different ontologies. For example, there will be a Device ontology describing various aspects of devices, sensors and actuators and the services they offer. One or several domain ontologies will describe a particular domain such as healthcare (HL7)/diabetes.
The Ontologies support the evolution of vocabularies as they can define relations between the different concepts. An ontology based vocabulary of commonly used data exchange standards in healthcare such as Health Level 7 (HL7), which has categorized events in the healthcare domain by considering service functionality which also reflects the business logic, GEHR or CEN's ENV 13606 needs to be developed or adapted from projects. In the project eu-DOMAIN, HL7 was used to provide a domain model, which facilitated integration with legacy health systems
6.2 SOA
Web Services commonly provide a standard, simple and lightweight mechanism for exchanging both structured and typed information between distributed services. Traditionally, Service Oriented Architectures (SOAs) are based on a client and server architecture where a server application, hosted by an always-on end system provides services to many other client applications and this server has a fixed and well-known IP address so that client applications with ease can access it.
SOA defines how to integrate widely separated applications for a web based solution. The functionality of SOA-based distributed systems is to split itself into services instead of objects or components that are tightly coupled. Moreover, these services are autonomous and independent of each other as software building parts and in order to work more than in a local scale these need to be defined for service invocation, description, discovery, coordination and composition (Oberle 2006). Therefore, in the REACTION project, a SOA will be a collection of services that communicate with each other, i.e. devices and interface spheres. The aim is as such to have interoperable and loosely coupled services distributed in the network and where this is going to be realised by the Hydra Middleware. In this context, a service is a function that is well-defined, self-contained, and does not depend on the context or state of other services. Although the SOA term is not new, it is widely used nowadays thanks to the Web Services technology.
In the REACTION platform, each device will be enabled to offer Web Services that can be consumed by other devices, services or applications through an overlying mobile P2P network. Every service offered by a physical device is identified and invoked using SOAP messages that are transmitted over the P2P network to create a robust connection, and WSDL to define the interface of the services, no matter the implementation language used.
Monitoring and event handling are important aspects of REACTION services. Any REACTION applications will be able to react ubiquitously to change in the patients‟ health state and/or environment and perform pre-defined activities or alarm handling according to pre-programmed rules or through closed loops involving formal and informal carers. In order to provide fast, complex and robust event handling, the REACTION platform will develop an event handling framework based on the well known state machine concepts from the field of control theory. Monitoring will thus be based on mapping of data into “states”. In principle, all data are expressed in the time domain. Dynamic values change as function of time – also static value are function of time, although they change less often or never. These "states" presupposes a well functioning data fusion implementation that can derive measurements with the help of semantic- and context management and create meaningful representations of these. However the mechanism of event handling becomes much simpler when time resolved data are mapped into states. An event occurs when a transition (change of state) take place and alarm responses can be initiated by the occurrence and detection of events corresponding to a pre-defined scheme. The alarm handling can take the form of a simple, predefined feedback to the patient: “Your blood sugar level is slightly elevated. You need to adjust your insulin dose at next injection” or more complex medical feedback to healthcare professional. It can also involve physical actions in the Patients‟ Sphere (ringing a bell, turning on lights) and invoking professional emergency response teams with the inclusion of a complete medical history and contact information.
REACTION will apply a novel approach to large-scale SOA and envisions arbitrary pairs of peer application entities communicating and will by these means provide services directly to and with each other. In a peer-
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 51 of 91 DATE 2012-03-05
to-peer SOA, none of the participant hosts is required to be always on; moreover, a participating host may change its IP address each time it comes on. The design and implementation of the SOAP API is being carried out with the purpose to enable peer-to-peer sharing of XML-based Web Services that are programming language independent and can be developed in C# or Java.
6.3 Hydra Middleware
The dedicated and precedent EU project with the same name “Hydra”, is an EU FP6 Integrated Project that develops middleware for networked embedded systems which allows developers to rapidly create intelligent applications. System developers are provided with development tools for easily and securely integrating heterogeneous physical devices into interoperable distributed systems. Semantic self-configuration tools for devices, semantic resolution, knowledge discovery modules and basic security models will be integrated into the REACTION platform through the use of Hydra middleware (Hydra 2010). The Hydra project can also be seen to be concerned with ICT enabled medical devices which can be categorized as actuators, sensors, or processors that are installed and operated in the context of an ICT application.
The work will partly build on refined results from the HYDRA project by further extending the Hydra middleware and Semantic Model-driven Architecture (SeMDA) researched in this project.
The Hydra middleware incorporates support for self-discovery of devices. When a Hydra enabled device is introduced to the BAN or PAN, the middleware is able to discover and configure the device automatically. Here we see an example of a Hydra device network. Hydra distinguishes between two different devices. More powerful devices are capable of running the Hydra middleware natively and smaller devices that are too constrained or closed to run the middleware. For the latter devices, proxies are used. The proxies are embedded in the BAN or the PAN node, which presumably have more computing power than the device has. Once proxies are in place, all communication is based on the IP protocol. The figure below illustrates the two cases. On the right, the terminal can directly incorporate Hydra middleware and is able to establish communication with services on the REACTION platform. In the situation on the left, the devices cannot operate the Hydra middleware (because they are too resource constrained or have proprietary interfaces). In this case, proxies are created on the BAN or PAN node (in this case a mobile phone). The proxies virtualises the device vis-à-vis the REACTION platform. Any service will think it is communicating with the device, where in fact it is communicating with the proxy.
Figure 20 Incorporation of devices using the Hydra middleware.
The first objective of the Hydra project was to develop middleware based on SOA, to which the underlying communication layer is transparent. The middleware includes support for distributed as well as centralised architectures, security and trust, reflective properties and model-driven development of applications. The
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 52 of 91 DATE 2012-03-05
HYDRA middleware is deployable on both new and existing networks of distributed wireless and wired devices, which operate with limited resources in terms of computing power, energy and memory usage. It allows for secure, trustworthy, and fault tolerant applications through the use of distributed security and social trust components. The embedded and mobile Service-oriented Architecture provide interoperable access to data, information and knowledge across heterogeneous platforms, including web services, and support true ambient intelligence for ubiquitous networked devices. The second objective of the HYDRA project was to develop a Software Development Kit (SDK). The SDK will be used by developers to develop innovative Model-Driven systems such as the REACTION platform. Using Service Oriented Architecture (SOA) will enable the software architecture to start from the middleware Hydra which in turn will provide a Service-Oriented approach to networks of heterogeneous embedded devices. SOA will be adapted to include body area and personal area networks. The P2P architecture of Hydra will be extended to include BAN and PAN.
The Hydra middleware provides: 1) Discovery mechanism, 2) Low level protocols, 3) Service execution, 4) Virtualisation (IEEEx73) and 5) security and trust policies which can directly be used by the developer of REACTION applications. The work will result in a number of core software modules to be implemented in the REACTION architecture.
The REACTION platform, in summary, is based on seamless integration of wearable ePatch sensors and off-the-shelf medical devices, environmental sensors and actuators. A key objective in the REACTION project is to demonstrate the use of non-invasive and minimally invasive monitoring devices. Despite technological developments in sensing and monitoring devices, issues related to system integration, sensor miniaturization, low-power sensor interface circuitry design, wireless telemetric links and signal processing still have to be investigated. Moreover, issues related to quality of service, security, multi-sensor data fusion, and decision support are active research topics.
Figure 21 showing an early example of applied REACTION Hydra Middleware solution based on the
Continua AHD.
The Hydra middleware further allows developers to incorporate heterogeneous physical devices into their applications by offering easy-to-use web service interfaces for controlling any type of physical device irrespective of its network technology such as Bluetooth, RF, ZigBee, RFID, Wi-Fi, etc. Hydra incorporates means for Device and Service Discovery, Semantic Model Driven Architecture, P2P communication, and
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 53 of 91 DATE 2012-03-05
Diagnostics. Hydra enabled devices and services can be secure and trustworthy through distributed security and social trust components of the middleware.
6.4 REACTION data and the cloud
One beneficiary implementation would be to open up the REACTION platform for external applications and services such as Microsoft HealthVault
17. This could reinforce the scope of the project and unfold its
acknowledgement as well. Here, we next review what services these external applications give and briefly discuss their effective output within the REACTION project. By doing so the REACTION project will also comply with possibly the most important European strategic objectives in eHealth: to provide interoperability among healthcare information systems. The CEN/ISSS eHealth Standardisation Focus Group has identified five prominent strategic aims of healthcare informatics in Europe to be (CEN/ISSS 2004) and could work as a finger-post in the up-coming project iterations:
Improve access to clinical records.
Enable patient mobility and cross border access to healthcare.
Reduce clinical errors and improving safety.
Improve access to quality information on health for patients and professionals.
Improve efficiency of healthcare processes.
The interoperability of healthcare information systems is conclusively the key component in addressing these challenges and as we now know, a number of standardization efforts are addressing the same issue such as openEHR (8.2.2), HL7 Version 3 (5.1) and HISA (5.2.2). The Continua Alliance mentioned in chapter 5.1.5, is creating profiles for interoperability that stretch from the patient through to final report to the health care professional. As one of the most promising routes is based on semantic interoperability to support exchange of meaningful clinical information among healthcare systems, the utilisation of external services in REACTION would be publicly maximised. Since it is not realistic to expect all the healthcare institutes to yet conform to a single standard, there is a need to address the interoperability at the semantic level. Semantic interoperability therefore creates the ability for information shared by systems to be understood at the level of formally defined domain concepts so that the information is able to be processed in computers by the receiving system (ISO2007). HealthVault and Google Health are two major web-based solutions that go out for interconnecting people (e.g. patients) with the conception of medical concepts by their Online health services.
6.4.1 HealthVault
One way Online health services are put to real is by Microsoft HealthVault and the growing ecosystem of connected, patient-friendly applications. By HealthVault people can store copies of their health records obtained from several sources, upload information from health and fitness devices, provide their information to healthcare providers and access other products and services. In HealthVault, one easily accessible personal account, people can consolidate their health information and help them become more informed and active in managing their health.
17
www.healthvault.com
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 54 of 91 DATE 2012-03-05
Figure 22 Microsoft HealthVault platform and various Online services.
HealthVault can be said to offer a central repository for health information that people gather from across a wide spectrum of healthcare (see Figure 22). The HealthVault platform also supports the growing ecosystem of connected, user-friendly applications (e.g. REACTION to be), so people can keep a simple and comprehensive, up-to-date record of their health information in a way that is configurable by which they can view and share it with whomever they choose (Microsoft Health Vault 2010).
Microsoft HealthVault API
The HealthVault Platform gives a web-based API layer that provides data and infrastructure services upon which all HealthVault applications are built. It includes a web application that provides an explorer type UI for the HealthVault Platform as well as being the key middleman web based authentication. The API specification is bounded to the system description level and makes no claims related to the user interface or APIs that a system might implement. HealthVault Service communications occur via a schematized XML in the body of an HTTP request over a TLS Connection. The HTTP requests further must be submitted using the POST HTTP verb. The schemas for the XML body conform to W3C’s XML Schema 1.0 Standard.
7. Knowledge discovery and data mining
7.1 From data to knowledge
Across a wide variety of fields, including health care, data are being collected and accumulated at a dramatic pace. The true value is not in storing the data, but rather in our ability to extract useful reports and to find interesting trends and correlations, through the use of statistical analysis and inference, to support decisions and policies made by scientists and businesses. Thus there is an urgent need for a new generation of computational theories and tools to assist humans in extracting useful information and knowledge from the rapidly growing volumes of digital data. This section provides an overview of these theories and tools.
Before going into details, it is worth to start from the definition of data, information and knowledge as the proper handling of them is essential for all of the functionalities mentioned earlier. Data are the fundamental element of cognition, the common denominator on which all constructs are based, and are stored in information systems. Data pertain to facts and given attributes. Attaching meaning to data transforms them into semantic data, or information. Thus information is transformed from raw data by interpretation or data processing. Knowledge, at the next level, implies contextualized information, which is information interpreted by the receiver and from the perspective of the receiver. Knowledge can be derived from the information by learning and reasoning. The prior knowledge influences the whole process, for instance it contains the models for interpretation (see Figure 23). Moreover, inference methods can be used to generate new information from existing information by the use of available knowledge.
For example, if the knowledge base contains the condition of hypoglycaemia (IF blood glucose < 3 mmol/l THEN hypoglycaemia exists) and the information that the patient’s last blood glucose measurement resulted 2.8 mmol/l is known, it can be inferred that the patient is in hypoglycaemic state. This new information can trigger e.g. the alarm system to execute pre-defined actions. In this example, the raw data was the number “2.8” which came from the glucose meter. It was interpreted by assigning metadata being a blood glucose value and having the unit mmol/l.
Data
Information
Knowledge
Processing
Inference
Models
Interpretation
Learning
Reasoning
Figure 23: From data to knowledge.
Methods must be provided to process data and generate calculated data. This process can be also considered as interpretation as it associates meaning to the data thus generates information. Another way of interpretation is the annotation (addition of metadata). These metadata should be terms from a common terminology. Metadata help interpret and transform data into information. Sometimes, additional data elements must be considered together (for example, a patient’s name may be stored in three different data fields, as last name, first name, and middle name) before information can be derived from data. For healthcare enterprises, the complexities involved in accessing patient information across different software applications and across organizational boundaries are significant, yielding a potential for costly errors.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 56 of 91 DATE 2012-03-05
Data items (variables) can be categorized from several aspects. According to a commonly used classification, the data in a variable is classified as either categorical or numerical
18. Categorical variables are those that can
only be assigned to a number of distinct categories. These are sometimes called also qualitative data. An example is sex which is either male or female: that is each person belongs to one of two categories. Similarly blood type is a categorical variable with blood type being assigned to one of A, B, AB, or O. Categorical variables can be further divided into nominal or ordinal. Nominal variables are assigned a category with no natural ordering: sex is an example taking the named categories male and female. Ordinal variables have categories that are ordered. An example of ordinal data is pain: absent, mild, severe has a natural ordering.
Numerical variables (also known as quantitative data) are ones that take a numerical value. Age is one example, number of siblings is another. Numerical variables are also classified as of two types: discrete or continuous. A discrete variable only takes whole numerical values, such as -1, 0, 1, 2, 3 etc. The number of hospital episodes that a patient has experienced is a good example of a discrete variable. Continuous variables have no limitation on values. Weight can be 87.2345678 kg – there is no restriction here. Note however that continuous variables are not usually collected with such fine detail. It is possible that the weight will be recorded as 87 kg, but weight is still a continuous variable even though it may only be recorded in a whole number of kilograms. A similar example is age where the age last birthday, in years, might be recorded.
This distinction is important as different tools and methods can be used for different kinds of data.
The selection of the data items (parameters) and algorithms to be used requires care from the analysts. Especially with the availability of powerful, easy-to-use analysis software it is simple to perform any kind of data processing, but if it was not properly planned, it may result in misleading or invalid conclusions. For example, body mass index and waist circumference are usually good indicators of overweight, but for some people with strong muscles (e.g. athletes) it may be invalid. Thus the context and the relation between parameters should always be considered.
Many terms used in this field, often without clear definition or incorrectly. Therefore first we define the concepts used in the rest of this section.
Data analysis can be defined as the process of extracting, compiling, and modelling raw data for purposes of obtaining constructive information that can be applied to formulating conclusions, predicting outcomes or supporting decisions in business, scientific and social science settings
19. Data
analysis methods include statistical, self-organizing, logical and model-based methods.
Data mining is the process of discovering meaningful new correlations, patterns and trends by sifting through large amounts of data stored in repositories, using pattern recognition technologies as well as statistical and mathematical techniques. It often aims to make predictions based on the available data. Data mining methods significantly overlap with methods for data analysis. A common distinction is that data mining explores huge amounts of data such as stored in a data warehouse.
Knowledge discovery or knowledge acquisition seeks new knowledge in a data set. The extracted knowledge should be valid, novel, potentially useful, and ultimately understandable. Data mining is usually considered as one step in the knowledge discovery process. We should distinguish knowledge acquisition from free text (scientific articles, books, guidelines, textual patient records) because it requires different methods than knowledge discovery from structured data.
7.2 The role of Data Quality
Reliable conclusions or prediction can be made only from reliable data, thus the quality of the collected data is an important issue. As most research on data quality is related to database, the majority of the methods can be applied to structured data [Batín (2009)]. There is little research related to measures and methods to assess quality of unstructured (textual) data. A distinction can be made between abstract dimensions and concrete metrics. A dimension defines in general a quality aspect of information, whereas it can only be measured using one or more concrete metrics. Van der Zanden (2010) provides a comprehensive review of quality dimensions and examples of metrics used in the literature.
There are several studies examining data quality in medical records. They usually refer to two commonly used characteristics (i.e. dimensions) of data: (1) accuracy and (2) completeness. The accuracy of data generally refers to whether that a data element accurately represents a patient’s medical state or history. Completeness refers to whether an event is recorded in the patient’s record. The meta-analysis of Stein et al. (2000) of the
18
University of Leeds, School of Medicine Epidemiology and Critical Numbers e-Learning site (accessed: 06. 02. 2012) http://www.leeds.ac.uk/medicine/ceb/Biostatistics/E-Learning/key_skills/types_of_data.htm 19
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 57 of 91 DATE 2012-03-05
healthcare data quality literature indicates that the accuracy rates can be as low as 67% and completeness rates as low as 30.7%.
As a practical example, the uncertainty about the quality of data in medical records poses a significant problem for decision support systems. Trusting the accuracy of the guidance also requires us to trust the data used to generate it. We must assume that this data is flawless and complete. Unless these systems can effectively deal with the underlying data problems, it is unclear whether we can rely on the guidance provided by these systems can as a valid clinical decision-making aids.
Hasan (2007) suggests two naïve approaches for addressing the data quality problem. The first requires us to check each patient’s medical record for accuracy and completeness at the point-of-care, while the other would be to conduct pre-care data cleanup. In the context of a CDSS for drug dosing, the first approach could be undertaken by prompting the physician to check the active drug list for each patient at the time of encounter. This approach is clearly time consuming, possibly impractical and may lead to unintended consequences. For instance, two studies showed that the override rate, the times when the decision-maker chooses to dismiss or ignore clinical alerts, can be as high as 88% (Payne et al. 2002; Weingart et al. 2003). As a result, checks on data-quality must consider this dynamic so users do not entirely ignore alerts. The second solution is to invest in a data cleanup operation. This cleanup may include crosschecking a patient’s record with other data sources or calling the patient to confirm information in their medical record. The data cleanup approach also has several problems. It can be time consuming, expensive and still may not yield the desired level of completeness and accuracy. An alternative is to determine the data that is most critical to the decision-making context and check or clean accordingly. To do this we must derive an estimate of the “value” of each of these data elements as measured by how important each one is to the accuracy of the guidance produce by the system.
7.3 Data mining tasks
Data mining methods can be used for several tasks. Larose (2005) categorizes the most common applications according to the following list:
Description
Estimation
Prediction
Classification
Clustering
Association
In the following these tasks are shortly discussed. Examples of methods and algorithms will be provided later on.
7.3.1 Description
Sometimes, researchers and analysts are simply trying to find ways to describe patterns and trends lying within data. Descriptions of patterns and trends often suggest possible explanations for such patterns and trends. Data mining models should be as transparent as possible. That is, the results of the data mining model should describe clear patterns that are amenable to intuitive interpretation and explanation. Some data mining methods are more suited than others to transparent interpretation. For example, decision trees provide an intuitive and human-friendly explanation of their results. On the other hand, neural networks are comparatively opaque to non-specialists, due to the nonlinearity and complexity of the model. High-quality description can often be accomplished by exploratory data analysis, a graphical method of exploring data in search of patterns and trends.
7.3.2 Estimation
Estimation is similar to classification except that the target variable is numerical rather than categorical. Models are built using “complete” records, which provide the value of the target variable as well as the predictors. Then, for new observations, estimates of the value of the target variable are made, based on the values of the predictors. For example, we might be interested in estimating the systolic blood pressure reading of a hospital patient, based on the patient’s age, gender, body-mass index, and blood sodium levels. The
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 58 of 91 DATE 2012-03-05
relationship between systolic blood pressure and the predictor variables in the training set would provide us with an estimation model. We can then apply that model to new cases. The field of statistical analysis supplies several venerable and widely used estimation methods. These include point estimation and confidence interval estimations, simple linear regression and correlation, and multiple regression. Neural networks may also be used for estimation.
7.3.3 Prediction
Prediction is similar to classification and estimation, except that for prediction, the results lie in the future. Any of the methods and techniques used for classification and estimation may also be used, under appropriate circumstances, for prediction. These include the traditional statistical methods of point estimation and confidence interval estimations, simple linear regression and correlation, and multiple regression, as well as data mining and knowledge discovery methods such as neural network, decision tree, and k-nearest neighbour methods.
7.3.4 Classification
In classification, there is a target categorical variable, such as income bracket, which, for example, could be partitioned into three classes or categories: high income, middle income, and low income. The data mining model examines a large set of records, each record containing information on the target variable as well as a set of input or predictor variables. For example, in the medical field, suppose that we are interested in classifying the type of drug a patient should be prescribed, based on certain patient characteristics, such as the age of the patient and the patient’s sodium/potassium ratio. Graphs and plots are helpful for understanding two- and three-dimensional relationships in data. But sometimes classifications need to be based on many different predictors, requiring a many-dimensional plot. Therefore, we need to turn to more sophisticated models to perform our classification tasks. Common data mining methods used for classification are k-nearest neighbour, decision tree, and neural network.
7.3.5 Clustering
Clustering refers to the grouping of records, observations, or cases into classes of similar objects. A cluster is a collection of records that are similar to one another, and dissimilar to records in other clusters. Clustering differs from classification in that there is no target variable for clustering. The clustering task does not try to classify, estimate, or predict the value of a target variable. Instead, clustering algorithms seek to segment the entire data set into relatively homogeneous subgroups or clusters, where the similarity of the records within the cluster is maximized and the similarity to records outside the cluster is minimized. Clustering is often performed as a preliminary step in a data mining process, with the resulting clusters being used as further inputs into a different technique downstream, such as neural networks. Common clustering methods include hierarchical and k-means clustering and Kohonen networks.
7.3.6 Association
The association task for data mining is the job of finding which attributes “go together.” Most prevalent in the business world, where it is known as affinity analysis or market basket analysis, the task of association seeks to uncover rules for quantifying the relationship between two or more attributes. Association rules are of the form “If antecedent, then consequent,” together with a measure of the support and confidence associated with the rule. A priori algorithm and the GRI algorithm are two common algorithms for generating association rules.
7.4 The Knowledge Discovery process
There is a common confusion in understanding the terms of Data Mining (DM), Knowledge Discovery (KD) and Knowledge Discovery in Databases (KDD) [Kurgan and Musilek (2006)]. For many researchers the term DM is used as a synonym for KD besides being used to describe one of the steps of the KD process. The following formal definitions can be extracted from the literature:
Data Mining concerns application, under human control, of low-level DM methods, which in turn are defined as algorithms designed to analyze data, or to extract patterns in specific categories from.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 59 of 91 DATE 2012-03-05
Knowledge Discovery is a process that seeks new knowledge about an application domain. It consists of many steps, one of them being DM, each aimed at completion of a particular discovery task, and accomplished by the application of a discovery method.
Knowledge Discovery in Databases concerns the knowledge discovery process applied to databases
Knowledge Discovery and Data Mining concerns the KD process applied to any data source. The term KDDM has been proposed as the most appropriate name for the overall process of KD. This term will be used in the remaining of this document.
At an abstract level, the KDDM field is concerned with the development of methods and techniques for making sense of data. The basic problem addressed by the KDDM process is one of mapping low-level data (which are typically too voluminous to understand and digest easily) into other forms that might be more compact (for example, a short report), more abstract (for example, a descriptive approximation or model of the process that generated the data), or more useful (for example, a predictive model for estimating the value of future cases). At the core of the process is the application of specific data-mining methods for pattern discovery and extraction.
The traditional method of turning data into knowledge relies on manual analysis and interpretation. For example, in the health-care industry, it is common for specialists to periodically analyze current trends and changes in health-care data, say, on a quarterly basis. The specialists then provide a report detailing the analysis which becomes the basis for future decision making and planning for health-care management. This form of manual probing of a data set is slow, expensive, and highly subjective. In fact, as data volumes grow dramatically, this type of manual data analysis is becoming completely impractical in many domains. Databases are increasing in size in two ways: the number of records or objects in the database and the number of fields or attributes to an object.
Historically, the notion of finding useful patterns in data has been given a variety of names, including data mining, knowledge extraction, information discovery, information harvesting, data archaeology, and data pattern processing. The term data mining has mostly been used by statisticians, data analysts, and the management information systems (MIS) communities. It has also gained popularity in the database field. The phrase knowledge discovery in databases was coined at the first KDD workshop in 1989 [Piatetsky-Shapiro (1991)] to emphasize that knowledge is the end product of a data-driven discovery. KDDM refers to the overall process of discovering useful knowledge from data from various sources, and data mining refers to a particular step in this process. Data mining is the application of specific algorithms for extracting patterns from data. The additional steps in the KDDM process, such as data preparation, data selection, data cleaning, incorporation of appropriate prior knowledge, and proper interpretation of the results of mining are essential to ensure that useful knowledge is derived from the data. Blind application of data-mining methods (rightly criticized as data dredging in the statistical literature) can be a dangerous activity, easily leading to the discovery of meaningless and invalid patterns.
KDDM can be formally defined as the nontrivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data [Fayyad et al (1996)]. Here, data are a set of facts (for example, cases in a database), and pattern is an expression in some language describing a subset of the data or a model applicable to the subset. Hence, in our usage here, extracting a pattern also designates fitting a model to data; finding structure from data; or, in general, making any high-level description of a set of data. The term process implies that KDDM comprises many steps, which involve data preparation, search for patterns, knowledge evaluation, and refinement, all repeated in multiple iterations. By nontrivial, we mean that some search or inference is involved; that is, it is not a straightforward computation of predefined quantities like computing the average value of a set of numbers. The discovered patterns should be valid on new data with some degree of certainty. We also want patterns to be novel (at least to the system and preferably to the user) and potentially useful, that is, lead to some benefit to the user or task. Finally, the patterns should be understandable, if not immediately then after some postprocessing.
The previous discussion implies that we can define quantitative measures for evaluating extracted patterns. In many cases, it is possible to define measures of certainty (for example, estimated prediction accuracy on new data) or utility (for example, gain, perhaps in dollars saved because of better predictions or speedup in response time of a system). Notions such as novelty and understandability are much more subjective. In certain contexts, understandability can be estimated by simplicity (for example, the number of bits to describe a pattern). An important notion, called interestingness, is usually taken as an overall measure of pattern value, combining validity, novelty, usefulness, and simplicity. Interestingness functions can be defined explicitly or can be manifested implicitly through an ordering placed by the KDDM system on the discovered patterns or models.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 60 of 91 DATE 2012-03-05
The KDDM process is interactive and iterative, involving numerous steps with many decisions made by the user and it can involve significant iteration and can contain loops between any two steps. A KDDM process model consists of a set of processing steps to be followed by practitioners when executing KDDM projects. Such a model describes procedures that are performed in each of the steps, primarily used to plan, work through, and reduce the cost of any given project [Kurgan and Musilek (2006)]. The basic structure of the model was proposed by Fayyad et al. Since then, several different KDDM models have been developed in both academia and industry. All process models consist of multiple steps executed in a sequence, which often includes loops and iterations. Each subsequent step is initiated upon the successful completion of a previous step, and requires a result generated by the previous step as its inputs. Another common feature of the proposed models is the span of covered activities. It ranges from the task of understanding the project domain and data, through data preparation and analysis, to evaluation, understanding, and application of the generated results. All proposed models also emphasize the iterative nature of the model, in terms of many feedback loops and repetitions, which are triggered by a revision process
As an example, the six-step process model of Cios and Kurgan (2005) is described as follows (see also Figure 24):
1. Understanding the problem domain. In this step one works closely with domain experts to define the problem and determine the project goals, identify key people and learn about current solutions to the problem. It involves learning domain-specific terminology. A description of the problem including its restrictions is done. The project goals then need to be translated into the KDDM goals, and may include initial selection of potential DM tools.
2. Understanding the data. This step includes collection of sample data, and deciding which data will be needed including its format and size. If background knowledge does exist some attributes may be ranked as more important. Next, we need to verify usefulness of the data in respect to the KDDM goals. Data needs to be checked for completeness, redundancy, missing values, plausibility of attribute values, etc.
3. Preparation of the data. This is the key step upon which the success of the entire knowledge discovery process depends; it usually consumes about half of the entire project effort. In this step, we decide which data will be used as input for data mining tools of step 4. It may involve sampling of data, running correlation and significance tests, data cleaning like checking completeness of data records, removing or correcting for noise, etc. The cleaned data can be further processed by feature selection and extraction algorithms (to reduce dimensionality), by derivation of new attributes (say by discretization), and by summarization of data (data granularization). The result would be new data records, meeting specific input requirements for the planned to be used DM tools.
4. Data mining. This is another key step in the knowledge discovery process. Although it is the data mining tools that discover new information, their application usually takes less time than data preparation. This step involves usage of the planned data mining tools and selection of the new ones. Data mining tools include many types of algorithms, such as rough and fuzzy sets, Bayesian methods, evolutionary computing, machine learning, neural networks, clustering, preprocessing techniques, etc. Some popular methods will be discussed in the next section. This step involves the use of several DM tools on data prepared in step 3. First, the training and testing procedures are designed and the data model is constructed using one of the chosen DM tools; the generated data model is verified by using testing procedures. One of the major difficulties in this step is that many off-the-shelf tools may not be available to the user, or that the commonly used tools may not scale up to huge volume of data. The latter is a very important issue. Scalable DM tools are characterized by linear increase of their runtime with the increase of the number of data points within a fixed amount of available memory. Most of the DM tools are not scalable but there are examples of tools that scale well with the size of the input data.
5. Evaluation of the discovered knowledge. This step includes understanding the results, checking whether the new information is novel and interesting, interpretation of the results by domain experts, and checking the impact of the discovered knowledge. Only the approved models (results of applying many data mining tools) are retained. The entire KDDM process may be revisited to identify which alternative actions could have been taken to improve the results. A list of errors made in the process is prepared.
6. Using the discovered knowledge. This step is entirely in the hands of the owner of the database. It consists of planning where and how the discovered knowledge will be used. The application area in the current domain should be extended to other domains. A plan to monitor the implementation of the discovered knowledge should be created, and the entire project documented.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 61 of 91 DATE 2012-03-05
Figure 24: A six-step KDDM process model. Dashed arrows illustrate possible iterations.
The data-mining component of the KDDM process often involves repeated iterative application of particular data-mining methods. The knowledge discovery goals are defined by the intended use of the system. We can distinguish two types of goals: (1) verification and (2) discovery. With verification, the system is limited to verifying the user’s hypothesis. With discovery, the system autonomously finds new patterns. We further subdivide the discovery goal into prediction, where the system finds patterns for predicting the future behaviour of some entities, and description, where the system finds patterns for presentation to a user in a human-understandable form. Data mining involves fitting models to, or determining patterns from, observed data. The fitted models play the role of inferred knowledge: Whether the models reflect useful or interesting knowledge is part of the overall, interactive KDDM process where subjective human judgment is typically required. Two primary mathematical formalisms are used in model fitting: (1) statistical and (2) logical. The statistical approach allows for nondeterministic effects in the model, whereas a logical model is purely deterministic. The statistical approach tends to be the most widely used basis for practical data-mining applications given the typical presence of uncertainty in real-world data-generating processes.
Another categorization of data mining methods is supervised versus unsupervised methods. In unsupervised methods, no target variable is identified as such. Instead, the data mining algorithm searches for patterns and structure among all the variables. The most common unsupervised data mining method is clustering. Some data mining methods can be used in both supervised and unsupervised ways; association rule mining is an example to this. Searching for all possible associations may present a daunting task, due to the resulting combinatorial explosion. Nevertheless, certain algorithms, such as the a priori algorithm, attack this problem cleverly. Most data mining methods are supervised methods, however, meaning that (1) there is a particular pre-specified target variable, and (2) the algorithm is given many examples where the value of the target variable is provided, so that the algorithm may learn which values of the target variable are associated with which values of the predictor variables. For example, the regression methods are supervised methods. All of the classification methods are supervised methods, including decision trees, neural networks, and k-nearest neighbours.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 62 of 91 DATE 2012-03-05
Most supervised data mining methods apply the following methodology for building and evaluating a model. First, the algorithm is provided with a training set of data, which includes the pre-classified values of the target variable in addition to the predictor variables. A provisional data mining model is then constructed using the training samples provided in the training data set. The next step in supervised data mining methodology is to examine how the provisional data mining model performs on a test set of data. In the test set, a holdout data set, the values of the target variable are hidden temporarily from the provisional model, which then performs classification according to the patterns and structure it learned from the training set. The efficacy of the classifications is then evaluated by comparing them against the true values of the target variable. The provisional data mining model is then adjusted to minimize the error rate on the test set.
7.5 Knowledge discovery for diabetes
The diabetes domain seems particularly well suited to a knowledge discovery and data mining approach. First of all, thanks to the current availability of electronic health records, administrative health records, and monitoring facilities, including telemedicine programs, the sheer size of data accumulated and accessible to physicians, practitioners, and health care decision makers is huge. Second, because DM is a lifelong disease, even data available for an individual patient turn out to be massive and difficult to interpret. Moreover, because the treatment of DM is multifaceted, the need for taking into account many variables is becoming compelling. Finally, the capability of interpreting BG readings is important not only in DM but also when monitoring patients in intensive care units (ICU). In particular, hyperglycaemia is frequently encountered in critically ill patients, and evidence shows that normoglycaemia can decrease the morbidity and mortality of such patients. Examples will be provided when we discuss data mining methods later in this section.
Medical practitioners working with type 2 diabetes patients have long noticed the differential response that these patients display to the treatment with existing or novel diabetes therapies. This implies a great variety of biochemical, cellular, and molecular phenotypes in patients. Indeed, both biochemical and genetic data indicate that molecular phenotypes of patients with diabetes are substantially heterogeneous, suggesting that drivers of hyperglycaemia likely differ across individuals with the disease. (See: McCarthy (2010) for a recent review). In particular, more than 30 genes have been found to contribute to the risk of diabetes; yet, it is believed that these genes together still account for no more than 10% of the total genetic component of the disease. Unfortunately, at the moment, substantial gaps exist in our understanding of both the diversity of type 2 diabetes pathophysiology and the mechanisms associated with differential rates of disease progression. In addition, limited health care resources restrict the application of a wide range of technologies to generate molecular phenotypes for each and every patient. This justifies the so-called patient stratification approach, an approach that could separate groups of patients into large sectors of sub-phenotypes (with the occurrence of >10%) based on biochemical, cellular, and/or molecular phenotypes. It is anticipated that if implemented, the patient stratification approaches would provide diabetes patients with better choice of diabetes drugs: by improving their therapeutic efficacy and minimizing toxicity. This is a great challenge for research in the near future. Knowledge discovery and data mining technologies could be used to analyse case bases and derive associations and rules to differentiate patients based on this heterogeneity and to enable more personalized treatment.
7.6 Methods for data mining
A lot of various methods were developed to facilitate data analysis and data mining. The following, non-exhaustive discussion describes the methods based on the work of Larose (2005). Note that many algorithms can be applied to more than one data mining task. Examples from the diabetes domain will also be provided.
7.6.1 Exploratory data analysis
When approaching a data mining problem, a data mining analyst may already have some a priori hypotheses that he or she would like to test regarding the relationships between the variables. For this purpose, a myriad of statistical hypothesis testing procedures are available through the traditional statistical analysis literature. However, analysts do not always have a priori notions of the expected relationships among the variables. Especially when confronted with large unknown databases, analysts often prefer to use exploratory data analysis (EDA) or graphical data analysis. EDA allows the analyst to delve into the data set, examine the interrelationships among the attributes, identify interesting subsets of the observations and develop an initial idea of possible associations between the attributes and the target variable, if any. Simple (or not-so-simple) graphs, plots, and tables often uncover important relationships that could indicate fecund areas for further investigation. Thus EDA might be a first step of analysis, followed by other data mining models.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 63 of 91 DATE 2012-03-05
One important task is to inspect correlation between the variables. One should take care to avoid feeding correlated variables to one’s data mining and statistical models. At best, using correlated variables will overemphasize one data component; at worst, using correlated variables will cause the model to become unstable and deliver unreliable results. Other useful tools for EDA include histograms of the numeric variables, distributions of the categorical variables, numerical summary measures, including minimum and maximum; measures of centre, such as mean, median, and mode; and measures of variability, such as standard deviation. Two- and three-dimensional scatter plots may be useful to examine possible multivariate associations.
Bellazzi and Abu-Hanna (2009) provide an example of a more sophisticated data analysis method for interpreting self-monitoring data. They applied an artificial intelligence technique known as temporal abstractions (TAs) to self-monitoring data. The principle of TAs is to provide an interval-based representation of monitoring data: time-stamped data are aggregated into time intervals during which a certain event occurs. In the case of BG monitoring data it seems natural to apply three different kinds of TAs: state TAs (e.g., “high” BG values), trends TAs (e.g., “increasing” BG values), and complex TAs (e.g., a daily pattern: “high in the morning and low at dinner”). The combination of the three different pattern search mechanisms may be therefore used effectively to show a more complete picture of the behaviour of a certain patient over time.
7.6.2 Statistical approaches to estimation and prediction
Using statistics for estimation and prediction is a widespread and traditional approach. This is a significant overlap between data analysis and data mining as these methods can be considered for both.
In statistical analysis, estimation and prediction are elements of the field of statistical inference. Statistical inference consists of methods for estimating and testing hypotheses about population characteristics based on the information contained in the sample. A population is the collection of all elements (persons, items, or data) of interest in a particular study. A sample is simply a subset of the population, preferably a representative subset. If the sample is not representative of the population, that is, if the sample characteristics deviate systematically from the population characteristics, statistical inference should not be applied.
Univariate methods are used to analyse one variable at a time. These methods include point estimation and confidence interval estimation. Point estimation refers to the use of a single known value of a statistic to estimate the associated population parameter. The observed value of the statistic is called the point estimate. Since the sample is a subset of the population, inevitably the population contains more information than the sample about any given characteristic. Hence, unfortunately, our point estimates will nearly always “miss” the target parameter by a certain amount, and thus be in error by this amount, which is probably, though not necessarily, small. Therefore confidence interval estimations are used. A confidence interval estimate of a population parameter consists of an interval of numbers produced by a point estimate, together with an associated confidence level specifying the probability that the interval contains the parameter.
Bivariate methods are used to analyse the relationships of two variables, for example, using the value of one variable to estimate the value of a different variable. Linear regression is a commonly used method to this task which results in the equation of an estimated regression line. It can be used for extrapolation of unknown values; however it can be dangerous since we do not know the nature of the relationship between the response and predictor variables outside the range of the sample.
Data mining is usually applied to large data sets, containing even hundreds of variables. Multiple regression methods can be used to describe relationships between more than two variables. It usually improves the precision of estimates and predictions compared to uni- and bivariate methods.
King et al. (2010) examined the associations between psychosocial and social-environmental variables and diabetes self-management, and diabetes control using hierarchical multiple regression methods. Several questionnaires were applied to collect non-physiological data. Another example is the work of Hosoya et al. (2012). They examined the relationship between the severity of depressive symptoms and diabetes-related emotional distress in patients with type 2 diabetes using multiple regression.
7.6.3 The k-nearest neighbour algorithm
The k-nearest neighbour algorithm is most often used for classification, although it can also be used for estimation and prediction. k-Nearest neighbour is an example of instance-based learning, in which the training data set is stored, so that a classification for a new unclassified record may be found simply by comparing it to the most similar records in the training set. Before using this method, the following questions should be answered:
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 64 of 91 DATE 2012-03-05
How many neighbours should we consider? That is, what is k?
How do we measure distance?
How do we combine the information from more than one observation?
Similarity of records is measured by the distance function. Finding the most appropriate distance function might be challenges, e.g. if continuous and categorical variables are mixed. If k is greater than one, a combination function is necessary to provide a classification decision for new records. Voting may be unweighted or weighted.
Lee et al. (2011) developed a predictive model for type 2 diabetes based on genetic and clinical data. They compared several classification methods, including the k-nearest neighbour algorithm.
7.6.4 Decision trees
Decision trees are Tree-shaped structures that represent sets of decisions, which generate rules for the classification of a dataset. Decision tree learning is a method commonly used in data mining. The goal is to create a model that predicts the value of a target variable based on several input variables. Each interior node corresponds to one of the input variables; there are edges to children for each of the possible values of that input variable. Each leaf represents a value of the target variable given the values of the input variables represented by the path from the root to the leaf. A tree can be "learned" by splitting the source set into subsets based on an attribute value test. This process is repeated on each derived subset in a recursive manner called recursive partitioning. The recursion is completed when the subset at a node all has the same value of the target variable, or when splitting no longer adds value to the predictions. The target variable must be discrete.
There are several algorithms for building a decision tree. The classification and regression tree (CART) is a popular method. The decision trees produced by CART are strictly binary, containing exactly two branches for each decision node. CART recursively partitions the records in the training data set into subsets of records with similar values for the target attribute. C4.5 algorithm is another example which recursively visits each decision node, selecting the optimal split, until no further splits are possible. There are differences compared to the CART, e.g. it is not restricted to binary splits. The method for measuring node homogeneity is also quite different.
One of the most attractive aspects of decision trees lies in their interpretability, especially with respect to the construction of decision rules. Decision rules can be constructed from a decision tree simply by traversing any given path from the root node to any leaf. The complete set of decision rules generated by a decision tree is equivalent (for classification purposes) to the decision tree itself.
Decision tree is a widely used method also in the diabetes domain. Hische et al. (2010) for example used it to predict diabetes based on clinical and laboratory data. Nabil Barakat et al. (2005) compared two different decision tree building algorithms for the same problem.
7.6.5 Neural networks
The inspiration for neural networks was the recognition that complex learning systems in animal brains consisted of closely interconnected sets of neurons. Although a particular neuron may be relatively simple in structure, dense networks of interconnected neurons could perform complex learning tasks such as classification and pattern recognition. Artificial neural networks (hereafter, neural networks) represent an attempt at a very basic level to imitate the type of nonlinear learning that occurs in the networks of neurons found in nature. One of the advantages of using neural networks is that they are quite robust with respect to noisy data. Because the network contains many nodes (artificial neurons), with weights assigned to each connection, the network can learn to work around these uninformative (or even erroneous) examples in the data set. However, unlike decision trees, which produce intuitive rules that are understandable to non-specialists, neural networks are relatively opaque to human interpretation, as we shall see. Also, neural networks usually require longer training times than decision trees, often extending into several hours. Clearly, since neural networks produce continuous output, they may quite naturally be used for estimation and prediction.
A typical neural network consists of a layered, feedforward, completely connected network of artificial neurons, or nodes. The feedforward nature of the network restricts the network to a single direction of flow and does not allow looping or cycling. The neural network is composed of two or more layers, although most networks
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 65 of 91 DATE 2012-03-05
consist of three layers: an input layer, a hidden layer, and an output layer. There may be more than one hidden layer, although most networks contain only one, which is sufficient for most purposes. The number of hidden layers and the number of nodes in each hidden layer are both configurable by the user. The neural network is completely connected, meaning that every node in a given layer is connected to every node in the next layer, although not to other nodes in the same layer. Each connection between nodes has a weight associated with it. At initialization, these weights are randomly assigned to values between zero and 1. Neural networks represent a supervised learning method, requiring a large training set of complete records, including the target variable. As each observation from the training set is processed through the network, an output value is produced from the output node (assuming that we have only one output node). This output value is then compared to the actual value of the target variable for this training set observation, and the error (actual − output) is calculated. The problem is therefore to construct a set of model weights that will minimize the error.
Neural networks were used e.g. by Pappada et al. (2011) to predict blood glucose values in the short term or by Narasinga Rao et al. (2010) to predict measures of quality of life.
7.6.6 Kohonen networks
Kohonen networks represent a type of self-organizing map (SOM), which itself represents a special class of neural network. The goal of self-organizing maps is to convert a complex high-dimensional input signal into a simpler low-dimensional discrete map. Thus, SOMs are nicely appropriate for cluster analysis, where underlying hidden patterns among records and fields are sought. Self-organizing maps are based on competitive learning, where the output nodes compete among themselves to be the winning node (or neuron), the only node to be activated by a particular input observation. Like neural networks, SOMs are feedforward and completely connected, and each connection between nodes has a weight associated with it, which at initialization is assigned randomly to a value between zero and 1. Unlike most neural networks, however, SOMs have no hidden layer. Kohonen networks are self-organizing maps that exhibit Kohonen learning, developed by a Finnish researcher.
Wickramasinghe et al. (2011) SOMs to identify interesting patterns in diabetes data and assist diabetes related policy-making at different levels.
7.6.7 Hierarchical and k-means clustering
Clustering algorithms are either hierarchical or non-hierarchical. In hierarchical clustering, a treelike cluster structure (dendrogram) is created through recursive partitioning (divisive methods) or combining (agglomerative) of existing clusters. Agglomerative clustering methods initialize each observation to be a tiny cluster of its own. Then, in succeeding steps, the two closest clusters are aggregated into a new combined cluster. In this way, the number of clusters in the data set is reduced by one at each step. Eventually, all records are combined into a single huge cluster. Divisive clustering methods begin with all the records in one big cluster, with the most dissimilar records being split off recursively, into a separate cluster, until each record represents its own cluster. The distance between two clusters can be defined in several ways, for example the minimum or maximum distance between any records in the two clusters or the average distance between all of the records.
The k-means clustering algorithm is a straightforward and effective algorithm for finding clusters in data. K denotes the predefined number of clusters. The algorithms starts with a random assignment of one record to each cluster (initial cluster centres), than assigns each remaining record to the nearest cluster centre. For each of the k clusters, it finds the cluster centroid, and updates the location of each cluster centre to the new value of the centroid. The last steps are repeated until convergence or termination.
Guttula et al. (2010) used hierarchical clustering to analyze DNA microarray data in order to identify genes related to diabetic nephropathy.
7.6.8 Finding association rules
Association rules describe relationships between attributes. The daunting problem that awaits any algorithm for this problem is the curse of dimensionality: The number of possible association rules grows exponentially in the number of attributes. Association rules, while generally used for unsupervised learning, may also be applied for supervised learning for a classification task. The mining of association rules from large databases is a two-steps process:
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 66 of 91 DATE 2012-03-05
1. Find all frequent itemsets; that is, find all itemsets with frequency above threshold.
2. From the frequent itemsets, generate association rules satisfying the minimum support and confidence conditions.
The support for a particular association rule AB is the proportion of transactions that contain both A and B.
The confidence of the association rule AB is a measure of the accuracy of the rule, as determined by the percentage of transactions containing A that also contain B.
The a priori algorithm for mining association rules, however, takes advantage of structure within the rules themselves to reduce the search problem to a more manageable size. The a priori algorithm takes advantage of the a priori property to shrink the search space. The a priori property states that if an itemset Z is not frequent, then adding another item A to the itemset Z will not make Z more frequent.
The a priori algorithm is not well equipped to handle numeric attributes unless they are discretized during preprocessing. Of course, discretization can lead to a loss of information, so if the analyst has numerical inputs and prefers not to discretize them, he or she may choose to apply an alternative method for mining association rules: generalized rule induction (GRI). The GRI methodology can handle either categorical or numerical variables as inputs, but still requires categorical variables as outputs. GRI applies an information-theoretic approach to determining the “interestingness” of a candidate association rule.
Association rules need to be applied with care, since their results are sometimes deceptive. With association rules, one needs to keep in mind the prior probabilities involved as sometimes a random selection from the database would provide more efficacious results than applying the association rule.
Nabil Bakarat (2005) et al. compared the GRI method with decision trees for predicting diabetes.
7.6.9 Patient rule induction
Patient rule induction aims to identify subgroups in the data which are significantly different from the rest of the data. Bellazzi and Abu-Hanna (2009) applied this method for the following problem: Guidelines are based on evidence, however, they are not always beneficial to all patients at all times, and providing tools to investigate the effects of guideline-based therapy on clinical outcomes is an important contribution toward improving the guidelines. Knowledge discovery and data mining methods can be used to investigate issues related to intensive insulin therapy (IIT) in ICU. Although these guidelines have the potential to lower the mean blood glucose level of the patient population as a whole, hyperglycaemia is still often found in various critically ill patients. In addition, implementation of these IIT guidelines is nearly always associated with a significant increase in hypoglycaemia. One may be interested in knowing “which patients are at high risk of hyperglycaemia despite having an IIT guideline in place” and “which patients are at very high risk of severe hypoglycaemia because of these guidelines?” The researchers’ uncovered patterns for example, that low body temperature and low bicarbonate for medically admitted patients are associated with hyperglycaemia. This concords with expert knowledge, for example, intensive care specialists notice that patients with low body temperature do not react well to insulin therapy. It is important to note that such patterns are difficult to obtain from a traditional representation of the blood glucose values in the patient record.
7.7 Text mining /knowledge discovery from free text
Besides the structured databases like the EPR or monitoring databases, a lot of natural text documents exist. In the medical domain, these include for example literature (scientific articles for professionals and educational texts for patients), textual parts of electronic health records and medical documents like discharge letters. Information retrieval or knowledge discovery from these sources require different methods which are often referred as text mining. Text mining has been defined as the non-trivial discovery process for uncovering novel patterns in unstructured text. Text mining techniques have been advanced by using techniques and methods from information retrieval, natural language processing, data mining, machine learning, and statistics. However, some old methods are rarely used nowadays. For example, while Bayesian models and hierarchical clustering were widely used in the early days, more advanced machine learning methods, such as artificial neural networks, support vector machines, and semantic-based clustering algorithms, have been applied in recent years. The next section provides an overview of typical text mining applications based on the reviews of Spasic et al. (2005), Cohen and Hersh (2005) and Yoo and Song (2008).
A common text mining method is document clustering. Basically, document clustering is to group unlabeled documents into meaningful document clusters whose documents are similar to one another within the cluster, without any prior information about the document set. In order to measure similarities between documents, documents are often represented based on the vector space model. In this model, each document is
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 67 of 91 DATE 2012-03-05
represented as a high dimensional vector of words’/terms’ frequencies. A number of document clustering approaches have been developed over several decades. Most of these document clustering approaches are based on the vector space representation and apply various clustering algorithms to the representation. Many approaches can be categorized as hierarchical or partitional clustering. There are attempts to apply semantics to the clustering algorithm by mapping terms in documents to ontology concepts and then aggregating concepts based on the concept hierarchy.
Text classification is a technique to automatically determine the category that a document or part of a document belongs to based on the particular topics or characteristics of interest that a document contains. Accurate text classification systems can be especially valuable for example to database curators, who may have to review many documents to find a few that contain the kind of information they are collecting in their database. Classification methods primarily rely on supervised machine learning techniques. Features used for classification are not specified explicitly by the user; instead the user only provides a set of documents that contain the characteristics of interest, which is known as the positive training set, and another set that does not contain the characteristics, which is known as the negative training set.
The goal of a text classification system is to assign the class labels to the new unseen documents. Classification can be defined into two different phases, namely model construction or also widely known as the training phase and model usage also known as the prediction phase. In the training phase, given a set of positively labelled sample documents, the goal is to automatically extract features relevant to a given class. Hence, it would help distinguish the positive documents from the negative ones. Once such features have been identified then those features should be applied to the candidate documents using some kind of decision-making process. In the model usage phase, check the accuracy of the model and use to it classify new unseen data.
The huge volume of the biomedical literature provides a promising opportunity to induce novel knowledge by finding novel connections among logically-related medical concepts. For example, Swanson introduced Undiscovered Public Knowledge (UDPK) model to generate biomedical hypotheses from biomedical literature such as MEDLINE [Swanson 1986]. According to Swanson, UDPK is “a knowledge which can be public, yet undiscovered, if independently created fragments are logically related but never retrieved, brought together, and interpreted”. The UDPK model formalizes a procedure to discover novel knowledge from biomedical literature as follows: Consider two separate sets of biomedical literature, BC and AB, where the BC document set discusses biomedical concepts B and C and the AB document set discusses biomedical concepts B and A. However, none of the documents in the BC or AB sets primarily discusses biomedical concepts C and A together. The goal of the UDPK model is to discover some novel connections between a starting concept C (e.g., a disease) and target concepts A (e.g., possible medicine or treatments to the disease) by identifying biomedical concept B (called a bridge concept). For example, Swanson discovered that fish oils (as concept A) could be a potential medicine for Raynaud disease (as concept C) by identifying the bridge concept (as concept B) blood viscosity. Swanson’s UDPK model can be described as a process to induce “C implies A”, which is derived from both “C implies B” and “B implies A”; the derived knowledge or relationship “C implies A” is not conclusive but, rather, hypothetical. The goal is to uncover previously unrecognised relationships worthy of further investigation.
Another type of text mining is information extraction. In terms of what is to be extracted by the systems, most studies can be broken into the following three major areas: 1) named entity extraction (NER), named entities may include proteins or genes, 2) relation extraction whose main task is to extract relationships among entities, and 3) abbreviation extraction. Most of these studies adopt information extraction techniques, using a curated lexicon or natural language processing for identifying relevant tokens such as words or phrases in text.
Named entity recognition is a crucial step in extracting more complex types of information (i.e. facts and events). The idea is that recognising biological entities in text allows for further extraction of relationships and other information by identifying the key concepts of interest and allowing those concepts to be represented in some consistent, normalised form. This task has been challenging for several reasons. First, there does not exist a complete dictionary for most types of biological named entities, so simple text matching algorithms do not suffice. In addition, the same word or phrase can refer to a different thing depending upon context. Conversely, many biological entities have several names. Biological entities may also have multi-word names, so the problem is additionally complicated by the need to determine name boundaries and resolve overlap of candidate names. With the large amount of genomic information being generated by biomedical researchers, it should not be surprising that in the genomics era, much of the work in biomedical NER has focused on recognising gene and protein names in free text. The approaches generally fall into three categories: lexicon-based, rules-based and statistically based.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 68 of 91 DATE 2012-03-05
The goal of relationship extraction is to detect occurrences of a pre-specified type of relationship between a pair of entities of given types. While the type of the entities is usually very specific (e.g. genes, proteins or drugs), the type of relationship may be very general (e.g. any biochemical association) or very specific (e.g. a regulatory relationship). Several approaches to extracting relations of interest have been reported in the literature and are applicable to this work. Manually generated template-based methods use patterns (usually in the form of regular expressions) generated by domain experts to extract concepts connected by a specific relation from text. Automatic template methods create similar templates automatically by generalising patterns from text surrounding concept pairs known to have the relationship of interest. Statistical methods identify relationships by looking for concepts that are found with each other more often than would be predicted by chance. Finally, NLP-based methods perform a substantial amount of sentence parsing to decompose the text into a structure from which relationships can be readily extracted. In the current genomic era, most investigation of this type has centred on relationships between genes and proteins. It is thought that grouping genes by functional relationships could aid gene expression analysis and database annotation. Several researchers have investigated the extraction of general relationships between genes.
Paralleling the growth of the increase in biomedical literature is the growth in biomedical terminology. Because many biomedical entities have multiple names and abbreviations, it would be advantageous to have an automated means to collect these synonyms and abbreviations to aid users doing literature searches. Furthermore, other text-mining tasks could be done more efficiently if all of the synonyms and abbreviations for an entity could be mapped to a single term representing the concept. Most of the work in this type of extraction has focused on uncovering gene name synonyms and biomedical term abbreviations.
Van der Zanden (2010) applied information extraction methods to textual electronic patient records in order to evaluate their quality.
Information retrieval is extensively used by biomedical experts to locate relevant information (most often in the form of relevant publications) on the Internet. Apart from general-purpose search engines, many IR tools have been designed specifically to query the databases of biomedical publications such as PubMed. It is particularly important in biomedicine not to restrict IR to exact matching of query terms, because term ambiguity and variation phenomena may cause irrelevant information to be retrieved (low precision) and relevant information to be overlooked (low recall). Adding semantics would be particularly useful, e.g. the hierarchical organisation of ontologies and relations between the described concepts (and through them the corresponding terms) can be used to constrain or relax a search query and to navigate the user through huge volumes of published information.
Many current semantic information retrieval solutions use ontologies [see e.g. Vallet et al. (2005) and Styltsvig (2006)], but the construction of a comprehensive ontology even for a narrow domain requires much efforts. In the domain of diabetes there is no existing ontology which has the necessary scope and quality for semantic information retrieval purposes. ALL has developed an alternative technology which relies on the users' relevant background knowledge in the form of user-specified “ontology capsules”, and therefore does not require pre-built, domain-specific semantic resources (ontologies, semantic lexicons etc.) in order to achieve high precision values. With this approach queries can be specified via natural language expressions and sentences, and the system searches for text fragments in the document set that have approximately the same meaning (semantic content) as the query.
This technology opens up the possibility of developing efficient and comfortable search systems for repositories containing medical documents in natural languages, e.g. scientific papers or natural language text fragments entered in electronic patient records. It also enables search in medical data repositories containing large amounts of natural language documents, e.g. a repositories of hospital discharge letters.
The technology is capable of supporting multilingual search scenarios, since queries are transformed into language-independent semantic representations that can be matched with texts in different languages. In addition to IR, the approach can also be used for information extraction (IE), e.g. a search for medicines usable for the treatment of a certain set of symptoms will return the list of concrete medicines (that is, the list of the expressions by which they are referred to) found in the relevant documents.
Figure 25 provides an overview on the components of the SIR.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 69 of 91 DATE 2012-03-05
Figure 25 Structure of SIR.
The Parser creates a graph (DAG – directed acyclic graph) representation of the syntactic structure of the query and of segments of natural language texts. It consists of several modules as it is usual in natural language processing (NLP). Some of them are standard NLP programs; however, the most important components are made for the semantic search according to special requirements. Parsing the query or segments of documents is somewhat different, because the inputs are different. In the first case a pre-processed and structured version is the input, in the second case the input is the text itself. Therefore while in the first case the correctness of parsing is ensured, in the second case it is not. However, problems in the parsing of text segments do not cause failures in the search, because of the strategy built into the search engine.
The Semantic Lexicon stores the lexical units (words) with their semantic properties. It consists of several components. There are separate but connected storage for the predicative words (words expressing events, relations, mainly verbs) and for non-predicative ones. The reason is that different resources store them. The predicative words are obtained from FrameNet; however, the FrameNet corpus has to be completed substantially. WordNet is used for the non-predicative words. Above these stores of words there are ontology capsules acting as upper ontology segments. The medical terminology is obtained from MeSH. The words are grouped into synonym-sets (synsets). We use the notion of being synonym in a less strict way than it is used in linguistics: two words are synonym, if they refer to similar situation or item. This definition is adequate for information retrieval. With the predicative words their valence patterns are also represented, including semantic features (role relations) of the valence units. The role relations are connected to the relations defined in the ontology capsules.
The Generator of the Meaning Representation is responsible for building a meaning representation of the query from the result of the Parser.
The Pre-search Engine substantially reduces the amount of documents to be processed by a preliminary key-word based search. If data base of EPRs are searched, it executes the data base search based on numerical and coded data.
Finally, the Search Engine finds the phrases that may have similar meaning as the query (or its part) has.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 70 of 91 DATE 2012-03-05
endurant
activity
state
favourable
state
unfavourable
state
healing activity
organism
organ
par
tOf goal
negativeGoal
patient
patient
instrument processinstrument
perdurant
hasState
healing sub-activity step
next
pa
rtO
f
medication
locality
patient
initiator
patient
instrument
involvedIn
involves
Figure 26: Example of an ontology capsule.
We can identify three major conclusions from the above described trends as the result of this review for the REACTION project:
1. ICT is able to realize a unified information space which supplies every actor (including the health professionals and the patients themselves) with appropriate information. As a result the activities of the actors – which are performed in distributed activity spaces – will also be supported. An insulin dosing decision support application for example might use all the information available in the information space to provide advices to the patient. The activity, i.e. the actual insulin administration will be performed in the patient’s activity space. The insulin dose will be stored again in the information space as new information.
2. Several knowledge discovery and data mining methods are available to obtain new relationships from data which may reveal causalities. These might be used for example to predict the expected course of the disease, such as the development of complications. This could enable the development of a classification method which supports the identification of high-risk patients.
3. Information extraction from textual sources such as case bases or EPRs can be effectively realized by the use of text mining methods. A special semantic information retrieval method based on ontology capsules was proposed. This method has the advantage that in contrast to other semantic search solutions it does not require the development of a detailed domain ontology.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 71 of 91 DATE 2012-03-05
8. Conclusions: towards a unified data fusion architecture
From the analysis based on this state of the art report we conclude with a set of basic design principles with regards to the data fusion approach and the architecture of the REACTION platform. We also present an initial set of architecture diagram sketches for further elaboration Support input from different types of medical devices. The importance of the Continua Alliance in the medical device field is high and therefore REACTION needs to be able to interface and integrate with Continua compliant devices. However, it is also clear that for a foreseeable future many non-Continua compliant devices will be available in end-user organisations. Under this aspect, REACTION, needs to be inclusive and provide interoperability with both Continua and non-Continua devices. Follow the SOA principles from Hydra middleware. Since the REACTION platform needs to support different use cases in both out-patient and in-hospital scenarios, this implies that the REACTION platform needs to support both centralised and decentralised architectures. The SOA principles provide the necessary support for this. Providing device virtualisation using the IEEE11073 device data models for all medical devices. The platform needs to have its own internal model of specific devices. In order to overcome device software interface diversity it is recommended that the IEEE11073 standards are applied to model both Continua as well as non-Continua devices. Support different types of data flow scenarios. In many applications a simple end-to-end data push model from device to hospital will be required. However, REACTION also must open up for envisioned future applications or settings where personal health data is processed and refined in several steps, displayed locally for the patient as well as exported to external health services. Exporting medical data to different services. The main use of data captured will be in the hospital and clinical environments (using IHE-PCD01). However, the rapid growth of external cloud based health services such as MS HealthVault also requires REACTION to be able to export that particular data in different data formats. Patient specific data fusion. Each patient is unique and therefore clinicians must be able to configure and control the medical measurements and the context data required for each separate patient under monitoring. Device level data fusion. In order to capture relevant context data at the point of measurement it is necessary to be able to capture data values (time, temperature, location, etc.) from multiple devices and aggregate these into a single observation. A basic drawing of how the client (Patient’s sphere) can be mapped onto an AHD like the one offered by Continua is shown in Figure 27. The server is modelled composed of Application Development, HIS Interface Adapters, Data Managements, Network Management, Security Management, Service Orchestration and External Service Interface Adapters all show the essential modules designed with respect to a unified data fusion architecture.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 72 of 91 DATE 2012-03-05
APPLICATION DEVELOPMENTGENERIC
QUESTIONNAIRE DEV. COMPONENT
APPLICATION nSDK
HIS INTERFACE ADAPTERS
DATA MANAGEMENT
MEASUREMENTMANAGER
CONTEXT DATAMANAGER
SEMANTIC IR COMPONENT
DATA COLLECTION MANAGER
SERVICE ORCHESTRATION
EVENT MANAGER
RULE ENGINE
ORCHESTRATION
MANAGER
PATIENT FEEDBACK COMPILER
ALERT AND ALARM
MANAGER
NETWORK MANAGEMENT
EXTERNAL SERVICES
INTERFACE ADAPTERS
SECURITY MANAGEMENT
NETWORK MONITORING
CONFIGURATION
MANAGER
PERFORMANCE AND FAULT
MANAGEMENT
SECURITYMANAGER
IDENTITYMANAGER
P2PMANAGER
PATIENT’S SPHERE
DEVICECONNECTIVITY
P2PMANAGER
DATA FUSIONNETWORK
MONITORING
CARER’S SPHERE
P2PMANAGER
SHORT-TERMRISK MANAGER
LONG-TERMRISK MANAGER
TYPE 2DECISION SUPPORT
TYPE 1DECISION SUPPORT
RISK CLASSIFICATION
MANAGER
CARE PLAN
CONTEXT OBSERVATION
ONTOLOGY
HEALTH INFORMATION
SYSTEMSEXTERNAL
RESOURCES
ADAPTER 1
ADAPTER 2
ADAPTER n
ADAPTER 1
ADAPTER 2
ADAPTER n
PATIENT FEEDBACK FRONTEND
PERSONAL CLOUD SERVICE
MANAGER
GENERIC DSS DEV. COMPONENT
Figure 27 REACTION SOA model where data fusion at client side shapes the way data is managed by service
orchestration at server side.
APPENDIX: References
Aerotel Medical Systems (1). Home-CliniQ PC-Based Homecare Multi-Parameter Multi-User Medical Acquisition Center. 14 June 2010. http://www.aerotel.com/en/products-solutions/medical-parameters-monitoring/homecare-multi-user-multi-parameter-medical-acquisition-c.html.
Aerotel Medical Systems (2). Tele-CliniQ Personal Multi-Parameter Medical Acquisition Center for Homecare. 14 June 2010. http://www.aerotel.com/en/products-solutions/medical-parameters-monitoring/personal-multi-parameter-medical-acquisition-center-for-the.html.
Aerotel Medical Systems (3). MDKeeper Wristop Wireless Vital Signs Monitor. 14 June 2010. http://www.aerotel.com/en/products-solutions/lifecare-mobile-solutions/mdkeeper-innovative-wristop-vital-signs-mo.html.
AND Medical / LifeSource. CP-1THW Wireless Complete Health Monitoring System . 14 June 2010. http://lifesourceonline.com/and_med.nsf/html/CP-1THW.
ASTM International (safety). ASTM F2761 - 09. 11 June 2010. http://www.astm.org/Standards/F2761.htm.
ASTM International. Standards Worldwide. 14 June 2010. http://www.astm.org/.
Atanas Kiryakov, et al. “Semantic annotation, indexing, and retrieval.” Web Semantics: Science, Services and Agents on the World Wide Web, 2004: 49-79.
Bekke, Johan ter. J.H. ter Bekke tribute site: Semantic Data Modeling. 19 August 2010. http://www.jhterbekke.net/SemanticDataModeling.html.
Bluetooth: SIG Press Releases. BLUETOOTH TECHNOLOGY CHOSEN AS HEALTH DEVICE STANDARD . 8 June 2009. http://www.bluetooth.com/English/Press/Pages/PressReleasesDetail.aspx?ID=13.
Cambridge Consultants. “Wireless Technology for Personal Health and Fitness: Vena.” 6 January 2009. http://ftcc.co.uk/downloads/case_studies/wireless/vena-continua.pdf.
Carvalho, S Hervaldo, et al. ”A general data fusion architecture.” In International conference of information fusion. 2003. 1465-1472.
CEN. European Committee for Standardization: Healthcare. 14 June 2010. http://www.cen.eu/cen/Sectors/Sectors/Healthcare/Pages/default.aspx.
Cholestech. Cholestech LDX System. 10 February 2010. http://www.cholestech.com/products/ldx_overview.htm.
Continua Health Alliance. 14 June 2010. http://www.continuaalliance.org/index.html.
CSEM. Cluster of EC co-financed projects on Smart fabrics, interactive Textile. 20 February 2010. http://csnej106.csem.ch/sfit/default.htm.
Dan Brickley, et al. W3C RDF Vocabulary Description Language 1.0: RDF Schema. 10 February 2004. http://www.w3.org/TR/2004/REC-rdf-schema-20040210/.
Deborah L McGuinness, Frank van Harmelen. W3C OWL Web Ontology Language: Overview. 10 February 2004. http://www.w3.org/TR/2004/REC-owl-features-20040210/.
DO Kang, et al. “A wearable context aware system for ubiquitous healthcare.” IEEE Engineering in Medicine and Biology Society. 2006. 5192-95.
Eclipse Projects. Open Healthcare Framework (OHF) Project. 15 June 2010. http://www.eclipse.org/ohf/index.php.
eHealth ERA. eHealth - priorities and strategies in European countries. eHealth ERA report, Luxembourg: European Commission - Information Society and Media, 2007.
Elnahrawy, E., Nath, B., and Smets, P. “Assessing sensor reliability for multi-sensor data fusion within the tranferable belief model.” IEEE Trans. on Systems, Man and Cybermetics, Part B, 34 (1). 2004. 782-787.
en13606. The CEN/ISO EN13606 Information Site. 14 June 2010. http://www.en13606.eu/.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 74 of 91 DATE 2012-03-05
European Committee for Standardization. eHealth Focus Group. 14 June 2010. http://www.cen.eu/cen/Sectors/Sectors/ISSS/Activity/Pages/eHealth_FG.aspx.
Gergely Héja, György Surján, Péter Vargal. “Ontological analysis of SNOMED CT.” BMC Medical Informatics and Decision Making, 2008.
GLIF. The Guideline Interchange Format. 15 February 2010. http://www.openclinical.org/.
Google Health. Product Overview. 20 April 2010. http://www.google.com/intl/sv-SE/health/about/index.html.
Graham Klyne, et al. W3C Resource Description Framework (RDF): Concepts and Abstract Syntax. 10 February 2004. http://www.w3.org/TR/2004/REC-rdf-concepts-20040210/.
Gruber, Thomas. “Toward principles for the design of ontologies used for knowledge sharing.” International Journal of Human Computer Studies, 1995: 907-928.
Hall D, Llinas J. “An introduction to multisensor data fusion.” Proceedings of the IEEE 85, no. 1 (1997): 6-23.
Hall, D. Mathematical Techniques in Multisensor Data Fusion. ARTECH HOUSE Inc, 2004.
HealthFrontier - Remote Health Monitoring. ecg@home. 14 June 2010. http://www.healthfrontier.com/ecgathome.php.
HealthFrontier. ecgAnywhere. 14 June 2010. http://www.healthfrontier.com/ecganywhere.php.
HeartCycle. HeartCycle - Compliance and effectiveness in HF and CHD closed-loop management. 11 June 2010. http://heartcycle.med.auth.gr/index.php.
HL7. HL7 International - Unlocking the Power of Health Information. 14 June 2010. http://www.hl7.org/.
Huadong, Wu. Sensor Data Fusion for Context-Aware Computing Using Dempster-Shafer Theory . Doctoral thesis, Pittsburgh, Pennsylvania: The Robotics Institute Carnegie Mellon University, 2003.
Hydra. Middleware for networked devices. 11 June 2010. http://hydramiddleware.eu/news.php.
IEEE Dictionary of Standards. “Institute of Electrical and Electronics Engineers: Standard Computer Dictionary; A Compilation of IEEE Standard Computer Glossaries.” New York, 1990.
IHTSDO. SNOMED CT. 20 August 2010. http://www.ihtsdo.org/snomed-ct/.
Intelesens. “Vitalsens - wireless platform.” 18 November 2009. http://www.intelesens.com/pdf/intelesensbrochure2009.pdf.
International Diabetes Federation. “EU Workshop Proceedings.” DIABETES IN EUROPE - Towards a European framework for Diabetes Prevention and Care. 8 April 2004. http://www.idf.org/webdata/docs/DiabetesWorkshopProceedingsJune2004.pdf.
ISO 215. TC 215: Health informatics. 24 August 2010. http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_tc_browse.htm?commid=54960.
ISO12967. “ISO 12967-1:2009.” 14 June 2010. http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_detail.htm?csnumber=50500.
J.H. Hong, N.J Kim, E.J Cha, and Tae-Soo Lee. “Development of Zigbee-based Mobile Healthcare System.” World Congress on Medical Physics and Biomedical Engineering 2006 August 27 – September 1, 2006 COEX Seoul, Korea “Imaging the Future Medicine”. Seoul, Korea: IFMBE Proceedings, 2006. 4065-4075.
Jennic. Jennic Support - Technology for a changing world. 15 June 2010. http://www.jennic.com/support/.
Klein, Gunnar, Pier Angelo Sottile, and Frederik Endsleff. Another HISA - The new standard: Health Informatics - Service Architecture. European prestandard, European Commission, 2006.
Lawrence Reeve, Hyoil Han. “Survey of Semantic Annotation Platforms.” ACM Symposium on Applied Computing. Santa Fe, New Mexico, USA: ACM Special Interest Group on Applied Computing, 2005.
Lee, Hyun, et al. “Issues in data fusion for healthcare monitoring.” PETRA'08, July 15-19. Athens, Greece, 2008.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 75 of 91 DATE 2012-03-05
LinkEHR Normalization Platform. Bringing Data into Knowledge. 30 August 2010. http://www.linkehr.com/.
LOINC. LOINC: Logical Observation Identifiers Names and Codes. 20 August 2010. https://loinc.org/.
Lucien, Wald. “Some terms of reference in data fusion.” IEEE Transactions on Geosciences and Remote Sensing, 1999: 1190-1193.
Lymberis, Andreas. “Research and development of smart wearable health applications: the challenge ahead.” Studies in health technology and informatics, 2004: 155-61.
Lymberis, Paradiso &. “Smart fabrics and interactive textile enabling wearable personal applications: R&D state of the art and future challenges.” IEEE Engineering in Medicine and Biology Society. 2008. 5270-3.
M. Lionel et al. “LANDMARC: Indoor location sensing using active RFID.” Proceedings of the First IEEE International Conference on Pervasive Computing and Communications. 2003.
Mangolini, Marc. Apport de la fusion d'images satellitaires multicapeurs au niveau pixel en télédétection et photo-interprétation. Doctoral thesis, France: Université Nice - Sophia Antipolis, 1994.
Matthew Kim, Kevin B Johnsson. “Patient Entry of Information: Evaluation of User Interfaces.” Journal of Medical Internet Research 6, no. 2 (2004): 13.
medicaldevicenetwork.com. Connecting Healthcare with USB. 14 June 2010. http://www.medicaldevice-network.com/projects/connectinghealthcare/.
Microsoft .NET. Micro Framework. 14 June 2010. http://www.microsoft.com/netmf/default.mspx.
Microsoft Health Vault. The Healthcare Ecosystem. 14 June 2010. http://www.healthvault.com/Industry/index.aspx.
Miličić, Vuk. Semantic Web Use Cases and Case Studies: Case Study: Semantic tags by Faviki. 2 May 2009. http://www.w3.org/2001/sw/sweo/public/UseCases/Faviki/.
Mitchell, H.B. Multi-sensor data fusion: an introduction. New York: Springer-Verlag, 2007.
Morfeo. svn.forge.morfeo-project. 11 March 2010. https://svn.forge.morfeo-project.org/openhealth/sources/.
myglucometer. World's most advanced glucose meter. 15 June 2010. http://www.myglucometer.com/about-the-meter.
Nakamura et al. “Information Fusion for Wireless Sensor Networks: Methods, Models, and Classifications.” ACM Computing Surveys 39, no. 3 (August 2007): 1-9.
National Institute of Standards and Technology. “[USGV6] A Profile for IPv6 in the US Government.” 23 January 2008. https://spaces.internet2.edu/download/attachments/8961/rhcp_ipv6.pdf.
NCBO Website. BioPortal. 17 August 2010. http://bioportal.bioontology.org/.
Nowack, Benjamin. “SPARQL+, SPARQLScript, SPARQL Result Templates - SPARQL Extensions for the Mashup Developer.” Proceedings of International Semantic Web Conference (Posters Demos). 2008.
Oberle, Daniel. Semantic management of middleware. New York: Springer Science+Business Media, Inc, 2006.
OBO. The Open Biological and Biomedical Ontologies: OBO Foundry Principles . 24 April 2006. http://obofoundry.org/crit.shtml.
OHT. Open Health Tools. 2 March 2010. https://www.projects.openhealthtools.org/servlets/ProjectList?type=Projects.
openEHR. Enabling ICT to effectively support healthcare, medical research and related areas. 11 June 2010. http://www.openehr.org/home.html.
OpenGALEN.org. Mission Statement. 8 May 2010. http://www.opengalen.org/index.html.
Ortivus. CoroNet - Telemetry. 14 June 2010. http://www.ortivus.com/en-gb/Products/CoroNet/CoroNet--Telemetry/.
Ortivus Mobimed. MobiMed. 14 June 2010. http://www.ortivus.com/en-gb/Products/MobiMed/.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 76 of 91 DATE 2012-03-05
Pau, Louis-Francois. “Sensor data fusion.” Journal of Intelligent and Robotics Systems 1 (1988): 103-116.
Peter Haase, et al. “A Comparison of RDF Query Languages.” Proceedings of the Third Int'l Semantic Web Conference. Hiroshima, Japan, 2004. 502-517.
Project Hydra. Value-added Services from Smart Meters. 11 June 2010. http://projecthydra.info/.
Protégé . The Protégé Ontology Editor and Knowledge Acquisition System. 20 August 2010. http://protege.stanford.edu/.
Rector, A. “The GRAIL concept modelling language for medical terminology.” Artificial Intelligence in Medicine,, 1997: 139-171.
Rector, Alan. “Untangling Taxonomies and Relationships: Personal and Practical Problems in Loosely Coupled Development of Large Ontologies.” Proceedings of the First International Conference on Knowledge Capture. Victoria, BC, Canada: ACM, 2001. 139-146.
Samson W Tu, et al. “The SAGE Guideline Model: Achievements and Overview.” Journal of the American Medical Informatics Association 14, no. 5 (2007): 589-598.
Semantic Health. Semantic Interoperability: for Better Health and Safer Healthcare. Research and Deployment Roadmap for Europe, European Commission: Information Society and Media, 2009.
SmartPersonalHealth. SmartPersonalHealth: a European eHealth project. 29 April 2010. http://sph.continuaalliance.org/index.html.
Stanis, Jason. Consultant’s Guide to Google Health – Part I of IV – An Architecture View. 12 May 2009. http://healthtechsynthesis.wordpress.com/2009/05/12/consultant_guide_to_google_health_part_i_of_iv/.
Tanita - Monitoring your health. BC-590BT Bluetooth Wireless Body Composition Scale. 14 June 2010. http://www.tanita.com/en/bc590bt/.
The ISO 27000 Directory (security). An Introduction To ISO 27799 (ISO27799). 2 May 2008. http://www.27000.org/iso-27799.htm.
The ISO 27000 Directory. An Introduction To ISO 27799 (ISO27799). 8 May 2008. http://www.27000.org/iso-27799.htm.
The Open Healthcare Group. A Smarter Way for Better Healthcare . 12 November 2009. http://www.openhealth.org/ASTM/.
The RFID in Healthcare Consortium. The RFID in Healthcare Consortium. 21 May 2010. http://www.rfidinhealthcare.org/index.htm.
UCUM. The Unified Code for Units of Measure. 18 July 2009. http://www.unitsofmeasure.org/.
USB Implementers Forum. Universal Serial Bus. 14 June 2010. http://www.usb.org/.
USB Implementers Forum, Inc. “Universal Serial Bus; device class definition for Personal Healthcare Devices.” Vers. 1.0. 8 November 2007. http://www.usb.org/developers/devclass_docs/Personal_Healthcare_1.zip.
W3C OWL Working Group. W3C OWL 2 Web Ontology Language: Document Overview. 27 October 2009. http://www.w3.org/TR/2009/REC-owl2-overview-20091027/.
W3C SPARQL. SPARQL Query Language for RDF. 15 January 2008. http://www.w3.org/TR/rdf-sparql-query/.
Wagner, Raymond S. “Doctoral thesis: Distributed Multi-Scale Data Processing for Sensor Networks.” Rice University. April 2007. http://scholarship.rice.edu/bitstream/handle/1911/20662/3256758.PDF?sequence=1.
Wald, Lucien. Data fusion: Definitions and architectures - fusion of images of different spatial resolutions. Paris: École des Mines de Paris, 2002.
Working Group IV: Technology for interoperability. “CEN/TC 251.” 13 10 2009. http://cen.iso.org/livelink/livelink.exe/fetch/2000/7167/259826/259827/259617/WG_IV_information.pdf?nodeid=1313002&vernum=0.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 77 of 91 DATE 2012-03-05
Xbit Laboratories. USB Personal Healthcare Devices in Development. 4 March 2007. http://www.xbitlabs.com/news/other/display/20070403121551.html.
Zephyropen. Open source SDK for Health Monitoring Devices. 30 August 2010. http://code.google.com/p/zephyropen/.
ZigBee Alliance. ZigBee Health Care Overview. 14 June 2010. http://www.zigbee.org/Markets/ZigBeeHealthCare/Overview.aspx.
ZigBee Alliance. “ZigBee Alliance.” ZigBee selected by Continua Health Alliance for next generation guidelines. 9 June 2009. http://zigbee.org/imwp/idms/popups/pop_download.asp?contentID=16015.
ZigBee. Health Care Overview. 11 June 2010. http://www.zigbee.org/Markets/ZigBeeHealthCare/Overview.aspx.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 78 of 91 DATE 2012-03-05
APPENDIX: Related Projects In order to actively promote the project and its potential results, different activities will be undertaken in this project. One of these is to review relevant prior projects that can be of use to REACTION. As it will be important to establish liaisons with other relevant projects, standard organisations, and institutions that can be of benefit for the project, this chapter will contribute with a brief overview of some of these projects with respect to technology and concepts in data fusion.
8.1 EU projects
A large number of EU funded project have been active in the area of telemedicine and RPM and many of them within the Framework Programmes. Examples of funded projects in the area of telemedicine and RPM that have developed solutions similar or relevant to the REACTION project include:
8.1.1 METABO
The FP7 project METABO20
(Personal Health Systems for Monitoring and Point-of-Care Diagnostics – Personalised Monitoring) addresses, as REACTION does, the need of health practitioners to develop and implement more effective and adaptive monitoring and modelling processes of chronic diseases for clinical research purposes, as well as improving care provision, enhancing patients’ quality of life and lowering the costs. The main objective is to design an interoperable platform for the continuous effective monitoring of metabolic levels for the generation of predictive personalized models for diabetes patients.
Figure 28 showing METABO processes and how the system interprets these data establishing
relationships among the reported activities and the metabolic status of the users.
This platform will relate the clinical dimension of the patients with their daily life and reality through a multi-parametric monitoring system that will gather information of the metabolic status of patients and through a web application where physicians will access all these data together with all regular clinical parameters that are currently used. From a technical perspective, METABO addresses some challenges that are common to the REACTION platform: the use and integration of available sensors and medical devices to collect body and health parameters, environmental and contextual data, behavioural responses to stress and life situations to identify and detect the effects on personal metabolic process, the personalisation and adaptation of sensors and other equipment (cameras, electronic and mechanical components of cars, etc.) and of the underlying software to detect and record the necessary body and physical data, the design and implementation of a technical platform arranged for interoperability and data transfer among different monitoring devices, based on shared semantics and building of a scientific database of significant body and environmental parameters and its matching with existing knowledge and empirical expertise for the study of diabetes.
20
http://www.metabo-eu.org/
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 79 of 91 DATE 2012-03-05
8.1.2 DIAdvisor
DIAdvisor21
is FP7 project developing a tool for people with diabetes to better predict and thereby control their blood glucose level. By a unique prediction of how blood glucose levels will develop short term, DIAdvisor is expected to minimise time spent outside the normal glucose levels. Prediction will come from glucose measurements, insulin delivery data and specific patient parameters, and result in advice on how to adapt individual therapy in order to obtain more stable disease control in everyday life.
Figure 29 showing the DIAdvisor information flows.
8.1.3 P-CEZANNE
The main objective of P-CEZANNE is to research and develop a novel implantable long-term nano-sensor for continuous BGL monitoring. The nano-sensor is linked to the wireless device platform of the ICT system and the data will be automatically collected, stored and processed. The novelty of P-CEZANNE lies within the nano-sensor containing living cells or proteins, a compact capsule with optics and microelectronics that measures continuously to provide physicians with online medical data. The processed data will also be used for automatic regulating of the glucose level by linking it to an insulin pump that accurately releases insulin into the body in response to the fluctuations of glucose concentrations. The project focuses on sensor and pump technology, which is very relevant for the REACTION project. Conversely, the service oriented architecture in REACTION could be a strong supplement to the data processing infrastructure in P-CEZANNE
22.
8.1.4 TMA-BRIDGE
This project, “Telemedicine Alliance - A Bridge Towards a Coordinate eHealth Implementation”23
, is a Support Action funded under FP6 with the aim of building a vision for provision of Telemedicine and eHealth to European citizens by 2010. The project will assess societal (health related), scientific, technical as well as organisational questions and propose solutions, which are relevant for REACTION.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 80 of 91 DATE 2012-03-05
8.1.5 TELEMEDICARE
“Telematic Support for Patient Focused Distant Care” is the title of a FP5 STREP project24
that aimed to develop an open telemedicine platform solution for RPM with body sensors that supply medical data to the patient's computer through wireless communication. The computer would analyse and store the data and trigger medical supervision, treatment or care by two-way communication over the Internet with care providers.
8.1.6 M2DM
“Multi-Access Services for telematic Management of Diabetes Mellitus”, a FP5 STREP25
which aimed to provide multi-access services to residential and mobile diabetic patients and new means to information access to physicians and patients, including Web-based services. The project is focused on technological solutions based on a central server system. This project intends to provide a sustainable service care to residential and mobile diabetic patients aiming to increase the quality of patient's care through improving communication between patients and caregivers. M2DM incorporates new telemedicine services that emphasise the provision of personal health care 24 hours a day and provides new means to information access to physicians and patients. A Multi-Access Server (MAS) is defined in the project comprising a full range of non-expensive and widely accepted information technologies offering to users a universal, easy-to-use, on-line and cost-effective access to telemedicine and information services. M2DM will provide the capability of effectively managing the knowledge necessary for the complex and distributed process of chronic disease care.
8.1.7 MOBILALARM
An eTEN programme with overriding objective in market validation project. The aim is to test and evaluate the technical and economic characteristics of an innovative, mobile, trans-European emergency and assistance service and to prepare for its rapid roll-out. Extending the present reach of "normal" alarm services far beyond the home environment will be of great benefit to many people: not only to older and safety-conscious persons, but also to those with certain disabilities or those with chronic illnesses.
Figure 30 The Tunstall mobile alarm device.
The mobile alarm service will promote independent living and support wider participation of these people in individual and social activities. Diabetes patients may need a mobile alarm service in
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 81 of 91 DATE 2012-03-05
emergency situation in cases they do not have insulin readily available. Because of its design the mobile device is also usable with blurred vision and even faster and easier to use than a normal mobile phone
26.
8.1.8 ARGOS
The overall goal of the ARGOS eHealth Pilot Project27
is to contribute to establishing a “Transatlantic Observatory for Meeting Global Health Policy Challenges through ICT-Enabled Solutions” in order to develop and promote “Common Methods for Responding to Global eHealth Challenges in the EU and the US”. EU and US care about the global challenges because (a) citizens travel and migrate globally and there is a wish to foster good healthcare everywhere (b) the EU and US wish to refine their products to better penetrate global markets (c) experiences and lessons learned globally are useful in Europe and the US. The Observatory will promote mutual understanding and learning among EU and US policy researchers and policy makers on the following general challenges with global dimension:
1. Improving health and well-being of citizens through accelerating eHealth strategy development and through supporting large scale eHealth infrastructure implementations;
2. Supporting R&D in eHealth to promote the benefits from the pursuit of consistent strategies.
8.1.9 SMARTPERSONALHEALTH
Smart Personal Health28
is a new European Initiative to promote awareness about issues and challenges related to personal health systems interoperability, from technical to organisational and legal aspects (SmartPersonalHealth, 2010). The project will run throughout 2010. The key activities of Smart Personal Health include three thematically focused regional stakeholder workshops and one central pan-European PHS Interoperability Conference. The next coming workshop is to be held in Berlin 21
st September 2010. The programme is run by Continua Health Alliance, IHE-Europe, ETSI
and Empirica, coordinated by The Centre, and funded under European Commission's FP7 Programme.
8.1.10 HEARTCYCLE
Heartcycle will provide a closed-loop disease management solution being able to serve both Heart Failure (HF) patients and Chronic Heart Disease (CHD) patients, including possible co-morbidities hypertension, diabetes and arrhythmias. This will be achieved by multi-parametric monitoring and analysis of vital signs and other measurements. The system contains: a patient loop interacting directly with the patient to support the daily treatment and a professional loop involving medical professionals, e.g. alerting to revisit the care plan. The patient loop is connected with hospital information systems, to ensure optimal and personalised care.
26
http://www.mobilalarm-eu.org/index.htm 27
http://argos.eurorec.org/ 28
http://sph.continuaalliance.org/project.html
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 82 of 91 DATE 2012-03-05
Figure 31 showing a scheme over the Heartcycle context aggregation.
Heartcycle will implement sensors such as cuff-less blood pressure, wearable SpO2, as well as an inductive impedance and an electronic acupuncture system, Further sensor development within the project concern contact-less ECG, arrays of electrets foils, motion-compensation in ECG and a cardiac performance monitor (bio-impedance) The Heartcycle patient platform involves dynamic context awareness in a user interaction workflow, sensor network middleware for sensors abstraction and decision support for medication compliance coaching.
The Heartcycle project uses ontologies as a mean to formalize its data model because it by that can ease the sharing of information among different entities in the Patient Loop and outside of it, and because ontologies offer ready-to-use methods to do implement reasoning on contextual data. The model will be implemented using the OWL-DL language as it represents the state of the art in ontologies that need to be processed automatically. It also allows the maximum expressiveness without losing computational completeness and decidability of reasoning systems. Other specifications of the language (OWL-Lite and OWL-Full) are either too limited in expressivity, or does not guarantee its computation
29.
The model in Figure 31 provides basic data of the context. The source can gather data from: 1) local sensors using the sensor middleware, 2) use other external sources (for example the weather forecast from a web site or the health care plan from the hospital’s server) and/or 3) use fixed data, known a priori. The context aggregator (what resembles data fusion in REACTION) combines two or more context sources in order to provide more significant data. One example could be an aggregator that takes the current position of the user from one source and the fixed position of some assets from another source. The aggregator could combine these data and provide the relative proximity of the user to the assets. This idea is one of the basics in the REACTION contextual processing and should be regarded to fulfil the function of a low level data fusion.
29
http://heartcycle.med.auth.gr/
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 83 of 91 DATE 2012-03-05
8.1.11 SEMANTIC HEALTH
The objective in the Semantic Health project30
is to efficiently implement eHealth to meet the rising needs of mobile citizens, patients and providers. This need and the fragmented interoperability initiatives must come together and coordinate with the increasing need to link clinical data to information from basic biological sciences and evidence of best clinical practice.
This project develops a European and global roadmap for RESEARCH in health-ICT by focusing on semantic interoperability issues of e-Health systems and infrastructures. The work of this project will be based on consensus of the research community, and validated by stakeholders, industry and member state health authorities. The roadmap will identify key short-term (2-5 years) and medium-term (4-10 years) research needs to achieve semantic interoperability of eHealth systems (including issues of nomenclatures presently in use, classifications, terminologies, ontologies, EHR and messaging models, public health and secondary uses, and decision support, their relationships, mapping needs, limitations). It will further analyse unsolved research issues arising in the context of realistic approaches to priority clinical and public health settings (reflecting on models of use, benefits expected, concrete application experience and lessons learned; relevance of open source model) and finally take into account the impact of non-technological (health policy, legal, socio-economic) aspects, reflects and integrates results of related FP6 (e-Health ERA, I2-Health and other) studies.
8.1.12 HEARTFAID
The HEARTFAID (a knowledge based platform of services for supporting medical-clinical management of heart failure within elderly population) R&D project took place with the financial support of the European Community, under the Sixth Framework Program, Information Society Technology – ICT for Health.
Heart Failure is one of the most remarkable health problems for prevalence and morbidity, especially in the developed western countries, with a strong impact in terms of social and economic effects. All these aspects are typically emphasized within the elderly population, with very frequent hospital admissions and a significant increase of medical costs.
HEARTFAID had the aim to make more effective and efficient all the processes related to diagnosis, prognosis and treatment of the Heart Failure within elderly population. This general goal was achieved by developing and providing an innovative technological platform that:
integrates biomedical data within electronic health record systems, for easy and ubiquitous access to heterogeneous patients data;
provides services for healthcare professionals, including patient telemonitoring, signal and image processing, alert and alarm system;
supports clinical decision in the heart failure domain, based on pattern recognition in historical data, knowledge discovery analysis and inferences on patients’ clinical data.
The core of HEARTFAID platform is the Knowledge Level, formalizing all the pre-existing clinical knowledge about Heart Failure. Novel, useful and non-trivial knowledge is extracted from the Knowledge Base and the data collected during the project, by using innovative knowledge discovery processes. If the Knowledge Base represents the heart of HEARTFAID platform, the “brain” of the platform is the Decision Support Systems (DSS). The DSS has the main goal to provide a valid support to the health care operators and the decision makers operating in the field of heart diseases.
HEARTFAID strategic impact mainly regards the improvement of the quality of life of Heart Failure patients and the decreasing of the social and economic costs.
HEARTFAID applications bring an important increase of the treatment quality of the individual patient, by ensuring the possibility to personalize the therapy and have a real-time monitoring and assistance of the patient with all his historical data and his complete health profile available to all physicians in charge and the DSS to support in the identification of the best treatment. On the other hand, the optimization of the therapy processes assures the control and reduction of the overall economic and social costs of medical care, by decreasing the frequency of hospital admissions. Moreover, the results of HEARTFAID and the technical solutions created inside the project are used in order to:
improve the Heart Failure clinical guidelines and protocols;
30
http://www.semantichealth.org/index.html
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 84 of 91 DATE 2012-03-05
develop new models and procedures on the basis of which organize the health care delivery;
suggest new directives and research policies to policy makers.
The platform was tested in 3 clinical sites of two different European countries (HEARTFAID 2006).
8.2 Other projects
Of course there also exists non EU funded or other global projects that are relevant to the REACTION project in many ways. Some of these projects are reviewed here.
8.2.1 TeleMedIS
This is an Israel-Sweden bi-national R&D project by which objective was to develop a wireless and wearable telehealth system and with the aim to develop and evaluate a unique telemedicine platform and wireless wrist-wearable monitoring system for the Swedish healthcare system. This project initiative is administered under the umbrella of Eureka and its duration was 18 months.
The TeleMedIS system consists of the TeleMed Home Care Platform developed by Karolinska Institute and Telehealth Monitoring Wristwatch developed by Tadiran LifeCare, connected over the wireless network, provided by TeliaSonera. The TMW is a special version of Aerotel's MDKeeper wrist wearable monitoring device and can measure 1-lead ECG, blood oxygen saturation level (SpO2), and pulse (heart rate).
Figure 32 TeleMedIS system layout.
As summary, TeleMedIS is focusing on the development, testing and planning for commercialization of a wireless remote monitoring telehealth system but also on the mobile aspects of telehealth, utilizing wireless communications infrastructure. It tries to make it an innovative and promising evolution in healthcare delivery
31.
8.2.2 openEHR
openEHR is a not-for-profit company, limited by guarantee that works towards enabling ICT to effectively support healthcare, medical research and related areas. As ICT is used ubiquitously elsewhere, it is contra dictionary far from effective in Healthcare. The main challenge for health ICT is to represent the semantics of its sector, which by the experience so far in this deliverable is far more complex than in other industries. Also, managing this requires a knowledge-oriented computing
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 85 of 91 DATE 2012-03-05
framework that includes ontologies, terminology and a semantically enabled health computing platform in which complex meaning can be represented and shared. Simultaneously, the framework must support the economically viable construction of maintainable and adaptable health computing systems and patient-centric electronic health records (EHRs). Technically, openEHR concerns creating specifications, open source software and tools for such a framework (i.e. platform). For the clinical side, it is about creating high-quality, re-usable clinical models of content and process (i.e. known as archetypes) along with formal interfaces to terminology. openEHR Includes XML libraries and development resources that can come to be useful within REACTION.
Figure 33 showing the openEHR service architecture.
Figure 33 shows an engineering view of the architectural framework of openEHR. It is that of a service-oriented system of systems with distinct services for EHR, demographics, workflow, administration, knowledge, terminology, identification, security, orchestration and discovery. One of the major features of openEHR is the a semantic architecture for the information-rich services These services include EHR, demographics and administration, and their corresponding user. The advantages of the openEHR service architecture are the following: semantic coherence in the application, a high level of re-use of artefacts, a single, stable reference model for sharing clinical and related information, a standardised query language for writing portable queries and a standardised, re-usable way of connecting to terminology (openEHR 2010).
8.2.3 PROJECT HEALTHDESIGN
This project first developed a prototype personal health record (PHR) application that captures information about daily life which of course is important for diabetes management. It also gives action-oriented advice for self-care. The application is not a standalone device; rather, it is a set of rules, algorithms and data structures with user interfaces that consumers can access on the Web via a computer or Internet-enabled mobile device. The PHR application analyses, summarises and displays data, advising users on nutrition, daily physical activity, blood glucose, emotional state, and the inbound interaction of all these factors. It also enables consumers to conduct “what if” analyses that can predict the health results of choices they might be considering, such as the effects of a particular meal on blood glucose levels.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 86 of 91 DATE 2012-03-05
The Project HealthDesign Common Platform is on the other hand a set of software components (i.e. consisting of different applications such as the PHR application) that provide common, shared functions to a variety of personal health applications (PHAs). The goal of “centralising” these functions is to reduce personal health application implementation time and increase interoperability among different PHAs. The common platform components are at this moment implemented as web services that PHAs may access via standard web interfaces. There also exist services for storing observations and medications, as well as for providing authentication, registry, and access-control functions. The common HealthDesign platform was designed and implemented as a suite of modular software components that interoperate through formal APIs. Each component interfaces both with the PHAs and with other platform components.
Figure 34 showing the common platform components in HealthDesign.
Analysing Figure 34 will show that services may be available in a shared environment, allowing multiple PHAs to store and retrieve common data. It will also be able to share users’ authentication (login) information and patients’ access-control (security) rules. The figure depicts this mode which enables the greatest interoperability across PHAs. If a patient enters information by one PHA this may then be shared with other PHAs, and patients can centrally manage the rules for sharing their information.
The public APIs that is supplied by the HealthDesign project allow PHAs to access the components over a wide area network as web services and as the common platform architecture is an instance of a Service Oriented Architecture (SOA), each of its components will be implemented as a Java software package that uses a MySQL relational database and runs on a Linux server (all technologies used in the implementation are available as open source software). If factors such as performance or security prohibit a web-services architecture, then the source code would be available and could instead be compiled directly into Java-based applications. Alternatively, the components could be hosted on any other (non-Linux) server platform that supports the Java runtime engine (e.g., Windows). The Common Platform is also available under open source license where all PHA developers are invited to download the source code and host it on their own infrastructure
32.
8.2.4 CoBrA Context Broker Architecture
Context Broker Architecture (CoBrA) is an agent based architecture that supports context-aware systems in smart spaces. The central part of this architecture is an intelligent agent called context broker. It maintains a shared model of context on the behalf of a community of agents, services, and devices in the space while at the same time provides privacy protections for the users in the space by enforcing the policy rules that they define.
32
http://www.projecthealthdesign.org/
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 87 of 91 DATE 2012-03-05
CoBrA provides a set of ontologies called COBRA-ONT in order to support context reasoning and knowledge sharing. These sets are expressed in the Web Ontology Language OWL, and the COBRA-ONT defines typical concepts that describe e.g. an intelligent meeting room environment
33.
Figure 35 CoBrA architectural structure for agents and smart spaces.
The key differences between CoBrA and other similar architectures are the following and can be viewed in Figure 35:
CoBrA uses the Web Ontology Language OWL, a W3C Semantic Web standard, to define ontologies of context (people, agents, devices, events, time, space, etc.). But in other systems, this context might often be implemented as programming language objects (e.g., Java classes) and thereby lack the expressive power to support context reasoning and high-level knowledge sharing.
In order to maintain a shared model of context for all computing entities in an associated space, CoBrA provides a resource-rich context broker while it in other systems it is mostly given individual entities which are usually required to manage their own contextual knowledge.
CoBrA allows the users to define privacy policy to control the sharing and the use of their situational information while it in most other systems involve some computing entities that are usually free to share any acquired situational information of a user.
8.2.5 SMARTDIAB
SMARTDIAB was a Greek funded project with the aim to integrate the state-of-the-art technologies in the fields of biosensors, telecommunications, simulation algorithms, and data mining in order to develop a Type 1 diabetes patient's management system. The developed a smart biosensor able to measure the blood glucose concentration and this sensor is communicating with a programmable micro-pump for insulin infusion. The measured blood glucose levels provide input to an Insulin Infusion Advisory System (IIAS), which is used for the calculation of the insulin pumps infusion parameters. Whenever the IIAS calculations are out of predefined bounds, appropriate information will be forwarded to the Diabetes Patient Management System (DPMS) which is located in a medical centre. The DPMS will contain a database management system but also advanced tools for the intelligent processing of the available diabetes patients information. The communication part of the system is based on Wireless Personal Area Network (WPAN) and mobile communications networks (GPRS, UMTS)
34.
33
http://cobra.umbc.edu/ 34
http://www.biosim.ntua.gr/smartdiab/
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 88 of 91 DATE 2012-03-05
8.2.6 GESI DHE
This product is actually not a project per se but rather a product that has derived from the HISA perspective. The DHE is an integrated middleware platform that is designed and developed by GESI. The purpose of the product is to organise a common and open repository for all data, making that data available to all applications through stable and public interfaces. It is complied with the European standard extensions of CEN 12967 (HISA) and it represents the main and qualifying constituent of an entire HIS35.
35
http://www.gesi.it/gesi_en/prodotti.asp
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 89 of 91 DATE 2012-03-05
APPENDIX: Resources
This section is intended as reference to various eHealth related technical development tools and resources, with potential use in the REACTION development effort.
8.3 Libraries
Libraries in the world of computer are a collection of routines (sub-) or classes that are used to enable further development of software. They contain code and data to provide services to programs that are independent of application purpose. Therefore, libraries are not executables but rather make together with pure executables references that are links to each other in a linked software setting that allows test running of application.
8.3.1 Open Health Tools:
Open Health Tools is an open source community and has the vision to enable a ubiquitous ecosystem where members of the Health and IT professions can collaborate to build interoperable systems. These systems are supposed to enable patients and their care providers to have access to vital and reliable medical information at the time and place it is needed (OHT 2010). Open Health Tools generates an active ecosystem involving software product and service companies, medical equipment companies, health care providers, insurance companies, government health service agencies, and standards organizations. Among Open Health Tools projects one can (by becoming an active contributor) download great number of satisfying code, frameworks, and other resources. Some examples of these are:
HL7 Tooling project aims to provide second generation tools to support the HL7 version3 message modelling methodology. The toolset is based on the Eclipse Platform and/or Eclipse Tools. The HL7 tools supports the v3 message modelling methodology that is designed to be an integral part of a wider suite of tools covering conformance/testing, clinical modelling and terminology maintenance.
Model-Driven Health Tools (MDHT) is making excellent progress toward model-driven code generation using EMF
36. The RIM Core Tools component enables importing HL7 MIF 2.1.4
models into UML, supported by a UML profile for the HL7 Development Framework (HDF). The result is EMF-based Java code generation for any HL7 v3 RIM message model.
Stepstone project is as a collaborative effort between IBM and the University of Florida. Its' aim is to provide a reference implementation for device-driven patient monitoring services. It builds on Eclipse SODA to provide a stepping stone for those looking to build health and wellness solutions using embedded technology, SOA, and open standards. Stepstone leverages the OSGi standard for Java to enable dynamic interaction with medical devices and their integration with backend systems and processes. It is still a young project but some future objectives are: A production-ready device manager project with dynamic provisioning (p2) and extension points for customizable vendor additions, A tooling "SDK" (built on Device Kit?) to help device manufacturers and application vendors to build, test, and work with new devices, possibly before they even have the hardware, An in-home RCP application for working with medical devices, A clinician-based RCP application to store and work with medical device data and patient records and A J2EE based home health application that expands the current backend with more robust capabilities.
OpenExchange platform provides standards based core infrastructure to exchange patient health information in a secure and timely manner. It also can advance the quality, safety and efficiency of healthcare delivery. The platform is a critical element of HIE (Health Information Exchange) infrastructure by providing clinicians and other members of the healthcare community with the right information at the right time. The platform facilitates and streamlines the sharing of patient information throughout an IHE community. OpenExchange consists of several open source projects that use Integrating the Healthcare Enterprise (IHE) profiles as the set of fundamental requirements.
36
EMF is a modeling framework and code generation facility. It helps building tools and other applications based on a structured data model and from where its specification is described in XMI. EMF provides tools and runtime support to produce a set of Java classes for the model, a set of adapter classes that enable viewing and command-based editing of the model, and a basic editor.
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 90 of 91 DATE 2012-03-05
8.3.2 Morfeo Project:
The Morfeo Project is a FP7 framework. The MORFEO community provides an open framework for collaboration among enterprises, universities, research centres and public administrations that to achieve the below-mentioned goals:
To speed up the development of SOA-related software standards as a key element for both system integration and the evolution of an ecosystem of proliferating services and its network.
Create business opportunities in the field and integrate solutions targeting enterprises and the administration based on standard platforms and applications developed within the community.
Improve the productivity and assure the quality of open-source software-related developments in order to make them integrated with the standard software development infrastructure.
Work and act as a catalyst for R&D&I projects in the software field that naturally integrate a range of scientific and technological aspects.
In the project's open source webpage (Morfeo 2010) there can be found full code coverage and vast classes implementing the 11073, 20601 standards and around thirteen different SDKs for mobile solutions and programming languages (Morfeo 2010).
8.3.3 The Open Healthcare Group
The Open Healthcare Group (OHG) is an organization devoted to the promotion and distribution of an open source health record called XChart. By using the latest XML Internet technology, OHG have developed source code for a health record that will help other developer to automate and streamline medical data. Furthermore, since XChart uses an open source code, it will be able to develop and customize own templates (The Open Healthcare Group 2009). The resources found at OHG are interesting from the REACTION point of view. It includes a XML MIME Transformation Protocol (XMTP), Draft ASTM XML Healthcare DTDs, Resource Directory Description Language (RDDL), and an interesting presentation of Healthcare, XML and the Semantic Web (The Open Healthcare Group 2009). The question is to what extent it is reusable for the REACTION platform. Deeper technical insight in the view of the REACTION project requirements is required and preferably covered by D2.3 - Technology watch.
8.3.4 Zephyropen
Zephyr Open is a new code project to provide a framework for Bluetooth physiological sensors such as heart rate monitors and Wii Remotes. These are just the starting point, but Zephyropen will continue to grow the device list as they enter the market. With the framework there is a simple SWING Application that enables search and connect to any Zephyr products and by which users can connect devices and view reports in real time. This data can also be streamed to the web via FTP or directly (via ATOM feeds) into your Gmail account. Zephyropen will be releasing free VO2max testing and estimation software for OSX, PC and cell phones. Users can also edit, graph and export their data from the Google Documents web application. Zephyropen will be totally free to stream any data in and do tests, but full featured applications will unfortunately be licensed (Zephyropen 2010).
8.4 Development tools and frameworks
A development tool (i.e. programming tool) is a program or application that creates, debugs or in other way supports other applications. Frameworks on the other hand are abstractions by which common code with generic functionality within an application can be selectively specialised. Frameworks are also libraries in a way that they support reusable abstractions by APIs. As the Hydra Middleware is built as a .NET with the programming languages C# and Eclipse Java solution it is essential to consider these languages and pertaining frameworks when implementing the REACTION platform due to systematic interoperability and foremost as it has been mentioned before in the beginning of this chapter: code reuse.
8.4.1 .NET Micro Framework
Device drivers for a broad range of Wi-Fi radios are already now available on Microsoft operating systems and Linux. But for the embedded operating systems that run on most medical devices, the Wi-Fi device drivers are scarce. So, rather than writing their own (an expensive and time-consuming
D4-1 State of the Art: Concepts and Technology for a unified data fusion architecture REACTION (FP7 248590)
VERSION 2.0 91 of 91 DATE 2012-03-05
process) there are some medical device makers that are selecting Windows Embedded CE instead of an embedded OS. But for resource-constrained medical devices, however, the CE is too “big”. and for others, it is simply too complex and inefficient. Then an more attractive alternative from Microsoft may be the .NET Micro Framework. This is by Microsoft called as an innovative development and execution environment for resource-constrained devices. The .NET Micro Framework is a runtime module (bootable) that requires only 300 KB of memory. Still, it provides a full managed execution environment as the module can run on top of an underlying operating system or natively on a device. According to Microsoft, a typical .NET Micro Framework device has a 32-bit processor with no external memory management unit and as little as 64K of random-access memory (RAM). One, for the REACTION development team, goal of the .NET Micro Framework is to bring the programming paradigm of Microsoft’s .NET environment to the embedded world and this can be made possible with the help of a fully integrated Visual Studio experience where the .NET Micro Framework enables application developers to use familiar .NET tools on desktop systems and then deploy the applications on any embedded systems. The version 3.0 of the .NET Micro Framework, those applications can take advantage of a richer set of facilities for secure connectivity. As from the middle of 2009, Wi-Fi connectivity options are included, namely 802.11a/b/g (Microsoft .NET 2010).
8.4.2 Open Healthcare Framework (OHF) for Eclipse:
The Eclipse Open Healthcare Framework (OHF) is a project within Eclipse (Eclipse Projects 2010) that is formed for the purpose of expediting healthcare informatics technology. The project is composed of extensible frameworks and tools which emphasize the use of existing and emerging standards in order to encourage interoperable open source infrastructure and thereby lowering integration barriers. OHF currently provide tools and Frameworks for HL7, IHE, Terminology, Devices, and Public Healthcare Maintenance. The components are:
CTS HL7 common terminology service built upon LexGrid repositories and technologies.
HL7v2 and HL7v3 Health Level 7 v2.x and v3 toolkit.
IHE Implementations of Integrating the Healthcare Enterprise profiles.
OHF Bridge Implementations of IHE profiles for use with a Web services wrapper.
SODA Service oriented device architecture device integration including Device Kit and SAT.
8.4.3 LinkEHR
LinkEHR is a result of a coordinate project sponsored by the Spanish Education Ministry. The granted project was titled “Semantic Web Technologies-Based Platform for the Management of Standardized Electronic Health Records” and ended in December 2007. The aim of this project was to design, implement and evaluate a platform for the publication of medical data. It was also meant to serve as an intelligent web access to the clinical information of patients which already exists at health organizations, based on standards and formal methods for the description of the clinical meaning. The project is based on:
A dual model approach for the Electronic Health Record (EHR) architecture was used, in particular the European Standard CEN/TC251 EN13606 and OpenEHR.
Ontology technologies were used for the semantic representation of both reference models and archetypes.
Archetypes are considered to be a view that provides abstraction in interfacing between data sources and reference models used to communication clinical data and therefore were archetypes used as to describe and standardize legacy data.
LinkEHR-Ed: this is the main component of the system. It is a model-independent tool that was implemented over the Eclipse framework for developing integration archetypes. These are the core of LinkEHR and an integration archetype is a kind of archetype that is meant for importing non-normalized data into an archetype guided and EHR extract ones. LinkEHR-Ed allows creating or editing archetypes based on any reference model. It is independent from the model since it only needs an XML schema definition of it in order to be able to work. LinkEHR-Ed further allows mapping archetypes to data sources and automatically generates the needed queries to the system in order to get the EHR Extract. The LinkEHR currently works with CEN EN13606, openEHR, CCR, CDA and openMRS (LinkEHR Normalization Platform 2010).