Dan Jurafsky Text Normalization • Every NLP task needs to do text normalization: 1. Segmenting/tokenizing words in running text 2. Normalizing word formats 3. Segmenting sentences in running text
Transcript
Dan Jurafsky
Text Normalization• Every NLP task needs to do text
normalization: 1. Segmenting/tokenizing words in running text2. Normalizing word formats3. Segmenting sentences in running text
Basic Text Processing
-1Word tokenization
Dan Jurafsky
How many words?
• I do uh main- mainly business data processing• Fragments, filled pauses
• Seuss’s cat in the hat is different from other cats! • Lemma: same stem, part of speech, rough word sense• cat and cats = same lemma
• Wordform: the full inflected surface form• cat and cats = different wordforms
Dan Jurafsky
How many words?EXAMPLE:Input: Friends, Romans, Countrymen, lend me your ears; Output: Friends Romans Countrymen lend me your ears
Input :they lay back on the San Francisco grass and looked at the stars and their.• Type: an element of the vocabulary (Lemma type or Wordform type) بدون تكرار• Token: an instance of that type in running text.ر بالتكرا• How many?
• 15 tokens (or 14)• Output: they lay back on the San Francisco grass and looked at the stars and their =15 tokens• Output: they lay back on the SanFrancisco grass and looked at the stars and their =14 tokens• 13 types (or 12) (or 11?)• Output: they lay back on the San Francisco grass and looked at the stars and their=13 tokens• Output: they lay back on the SanFrancisco grass and looked at the stars and their=12 tokens• Output: they lay back on the SanFrancisco grass and looked at the stars and their=11 tokens
Dan Jurafsky
How many words?
N = number of tokensV = vocabulary = set of types
|V| is the size of the vocabulary
Tokens = N Types = |V|
Switchboard phone conversations
2.4 million 20 thousand
Shakespeare 884,000 31 thousand
Google N-grams 1 trillion 13 million
Dan Jurafsky
Issues in Tokenization• The major question of the tokenization phase is what are the correct tokens to use? In
previous example1, it looks fairly trivial: you chop on whitespace and throw away punctuation characters. This is a starting point, but even for English there are a number of tricky cases. For example, what do you do about the various uses of the apostrophe for possession, contractions and hyphenation?
1. apostrophe for possession:Ex: Finland’s capital Finland Finlands Finland’s ?
2. Contractions:Ex: what’re, I’m, isn’t What are, I am, is not
3. Hyphenation:Ex: Hewlett-Packard Hewlett Packard ?Ex: state-of-the-art state of the art ?
Dan Jurafsky
7
4. Ex: Lowercase lower-case lowercase lower case ?5. Splitting on white space can also split what should be regarded as a single token:
Ex: San Francisco one token or two?6. EX: m.p.h., PhD. ??
Dan Jurafsky
Tokenization: language issues
• French• L'ensemble one token or two?• L ? L’ ? Le ?
• German noun compounds are not segmented• Lebensversicherungsgesellschaftsangestellter• ‘life insurance company employee’• German information retrieval needs compound splitter
Dan Jurafsky
Tokenization: language issues• Chinese and Japanese no spaces between words:
• 莎拉波娃现在居住在美国东南部的佛罗里达。• 莎拉波娃 现在 居住 在 美国 东南部 的 佛罗里达• Sharapova now lives in US southeastern Florida
• Further complicated in Japanese, with multiple alphabets intermingled• Dates/amounts in multiple formats
フォーチュン 500 社は情報不足のため時間あた $500K( 約 6,000 万円 )
Katakana Hiragana Kanji Romaji
End-user can express query entirely in hiragana!
Dan Jurafsky
Max-match segmentation illustration
• Thecatinthehat• Thetabledownthere
• Doesn’t generally work in English!
• But works astonishingly well in Chinese• 莎拉波娃现在居住在美国东南部的佛罗里达。• 莎拉波娃 现在 居住 在 美国 东南部 的 佛罗里达
• Modern probabilistic segmentation algorithms even better
the table down there
the cat in the hat
theta bled own there
Basic Text Processing
2-Word Normalization and Stemming
Dan Jurafsky
Normalization• In Information Retrieval : Having broken up our documents (and also our query) into tokens, the easy
case is if tokens in the query just match tokens in the token list of the document. However, there are many cases when two character sequences are not quite the same but you would like a match to occur.
• For instance, if you search for USA, you might hope to also match documents containing U.S.A• Another example: the tokens computer should be linked to other tokens that can be synonyms of the
word computer like PC, Laptop, Mac etc. So when a user searches for Computer the results of the documents that contains the token PC, Laptop, Mac Should also be displayed to the user
• Token normalization has as a goal to link together tokens with similar meaning.• Token normalization: is the process of canonicalizing or standardizing tokens so that matches
occur despite superficial differences in the character sequences of the tokens.
Dan Jurafsky
NormalizationTo do Normalization:1. The most standard way to normalize is to implicitly create equivalence classes:
• By Using Mapping rules that remove characters like hyphens or deleting periods in a token • The terms that happen to become identical as the result of these rules are the equivalence classes.
Examples: by deleting periods in U.S.A, (U.S.A and USA) are equivalence classes. Then searching for U.S.A will retrieve documents that contain U.S.A or USAby deleting hyphens in anti-discriminatory, (antidiscriminatory , anti-discriminatory) are equivalence classes. Then searching for anti-discriminatory will retrieve documents that contain antidiscriminatory or anti-discriminatory.
• Disadvantage: if I put in as my query term C.A.T., I might be rather upset if it matches every appearance of the word cat in documents
Dan Jurafsky
14
2. Alternative: asymmetric expansion:• The usual way is to index unnormalized tokens and to maintain a query expansion list of multiple
vocabulary entries to consider for a certain query term as you see in figure 2.6.• Example:
• Potentially more powerful.• Disadvantage: less efficient and more complicated because it is adding a query expansion
dictionary and requires more processing at query time(solving part of problem by using case folding
Dan Jurafsky
Case folding• Applications like Information Retrieval (IR): reduce all letters to lower case in the document Since users
tend to use lower case word when he is searching.1. The simplest cast folding
• is to convert to lowercase words at the beginning of a sentence • and all words occurring in a title that is all uppercase or in which most or all words are
capitalized. These words are usually ordinary words that have been capitalized2. Avoid make cast folding to Mid-sentence capitalized words because many proper nouns are derived
from common nouns and so are distinguished only by case, including:• Companies (General Motors, The Associated Press) • Government organizations (the Fed vs. fed)• Person names (Bush, Black)
• For sentiment analysis, Machine translation, Information extraction• Case is helpful (US versus us is important), so we do not need case folding
Dan Jurafsky
Lemmatization• Lemmatization: By the use of a vocabulary and morphological analysis of words to remove inflectional
endings only or variant forms and to return the base form LEMMA or dictionary form of a word • am, are, is be
• car, cars, car's, cars' car
• Example: the boy's cars are different colors the boy car be different color
• Goal of Lemmatization: have to find correct dictionary headword form (lemma)
• Machine translation• Spanish quiero (‘I want’), quieres (‘you want’) same lemma as querer ‘want’
Dan Jurafsky
Morphology
• Morphemes:• The small meaningful units that make up words• Stems: The core meaning-bearing units• Affixes: Bits and pieces that adhere to stems• Often with grammatical functions
Dan Jurafsky
Stemming
• Stemming: is crude chopping of affixes to Reduce terms to their stems in information retrieval in the hope of achieving this goal correctly most of the time.• language dependent• e.g., automate(s), automatic, automation all reduced to automat.
for example compressed and compression are both accepted as equivalent to compress.
for exampl compress andcompress ar both acceptas equival to compress
Dan Jurafsky
19
Lemmatization and stemming
• Example:• If confronted with the token saw,
• stemming might return just s,• whereas lemmatization would attempt to return either see or saw
depending on whether the use of the token was as a verb or a noun.
Dan Jurafsky
Porter’s algorithmThe most common English stemmer
Step 1asses ss caresses caressies i ponies poniss ss caress caresss ø cats cat
Step 1b(*v*)ing ø walking walk sing sing(*v*)ed ø plastered plaster…
Step 2 (for long stems)ational ate relational relateizer ize digitizer digitizeator ate operator operate…
1312 King 548 being 541 nothing 388 king 375 bring 358 thing 307 ring 152 something 145 coming 130 morning
Basic Text Processing
3-Sentence Segmentation and
Decision Trees
Dan Jurafsky
Sentence Segmentation• Things ending in !, ? are relatively unambiguous• Period “.” is quite ambiguous. Period can be:
• Sentence boundary• But also it also used for Abbreviations like( Inc.) or (Dr.) (etc.)and• Numbers like( .02%) or (4.3)
• So we can not assume that period is the end of the sentence.• To solve the period problem we need to build a binary classifier
• Looks at a “.”• Decide weather period is EndOfSentence/NotEndOfSentence• To make Classifiers: we can use hand-written rules, regular expressions, or
machine-learning
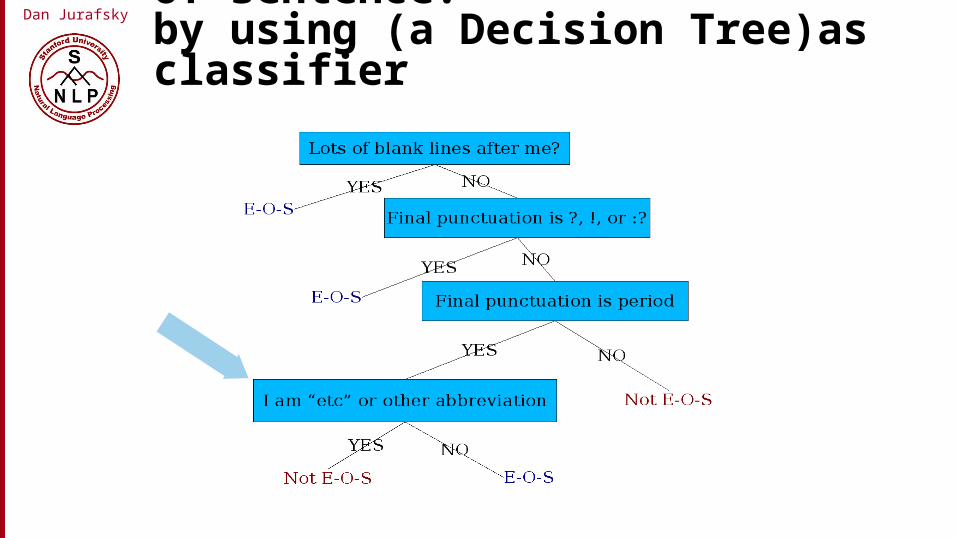
Dan Jurafsky Determining if a word is end-of-sentence: by using (a Decision Tree)as classifier
Dan Jurafsky
More sophisticated decision tree features
• Simple features:• Case of word with “.”: Upper, Lower, Cap, Number• Case of word after “.”: Upper, Lower, Cap, Number
• Numeric features:• Length of word with “.” (Ex: abbreviations tend to be short)• Probability(word with “.” occurs at end-of-s)• Probability(word after “.” occurs at beginning-of-s)(Ex: .The)
“The” is very likely to come after “.”
Dan Jurafsky
Implementing Decision Trees
• A decision tree is just an if-then-else statement• The interesting research is choosing the features• Setting up the structure is often too hard to do by hand
• Hand-building only possible for very simple features, domains• For numeric features, it’s too hard
• Instead, structure usually learned by machine learning from a training corpus