Page 1
Welcome to DARK2 (IT, MN and PhD)
Erik HagerstenUppsala University
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh2
DARK22004
DARK2 On the web
DARK2, Autumn 2004Welcome!NewsFormsScheduleSlidesPapersAssignmentsReading instructionsExam
(Links
www.it.uu.se/edu/course/homepage/dark2/ht04
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh3
DARK22004
Literature Computer Architecture A Quantitative Approach (3rd edition)
Lecturer Erik Hagersten gives most lectures and is responsible for the courseHåkan Zeffer is responsible for the laborations and the hand-insJakob Engblom guest lecturer in embedded systemsJakob Carlström guest lecturer in network processorsJukka Rantakokko guest lecturer in parallel programming
Mandatory Assignment
There are two lab assignments that all participants have to complete before a hard deadline. (+ a Microprocessor Report if you are doing the MN2 version)
Optional Assignment
Ther are three (optional) hand-in assignments : Memory, CPU, Multiprocessors. You will get extra credit on the exam …
Examination Written exam at the end of the course. No books are allowed.
www.it.uu.se/edu/course/homepage/dark2/ht04
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh4
DARK22004
DARK2 in a nutshell1. Memory Systems
Caches, VM, DRAM, microbenchmarks, optimizing SW
2. Multiprocessors TLP: coherence, interconnects, scalability, clusters, …
3. CPUsILP: pipelines, scheduling, superscalars, VLIWs,embedded, …
4. FutureTechnology impact, TLP+ILP in the CPU,…
Page 2
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh5
DARK22004
Lab1
Run programs in a architecture simulator modeling cache and memoryStudy performance when you:
change the cache modelchange the program
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh6
DARK22004
Lab2
Write your own ”microbenchmark” and find out everything about your favorite computer’s memory system
Introduction to Computer Architecture
Erik HagerstenUppsala University
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh8
DARK22004
What is computer architecture?
“Bridging the gap between programs and transistors”
“Finding the best model to execute the programs” best={fast, cheap, energy-efficient, reliable, predictable, …}
…
Page 3
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh9
DARK22004
”Only” 20 years ago: APZ 212”the AXE supercomputer”
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh10
DARK22004
APZ 212marketing brochure quotes:
”Very compact”6 times the performance1/6:th the size1/5 the power consumption
”A breakthrough in computer science””Why more CPU power?””All the power needed for future development””…800,000 BHCA, should that ever be needed””SPC computer science at its most elegance””Using 64 kbit memory chips””1500W power consumption
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh11
DARK22004
CPU Improvements
2000 2005 2010 2015 Year
Relative Performance[log scale]
Historical ra
te: 55% /year
1000
100
10
1
??
????
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh12
DARK22004
How do we get good performance?
Creating and exploring:1) Locality
a) Spatial locality b) Temporal localityc) Geographical locality
2) Parallelisma) Instruction levelb) Thread level
Page 4
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh13
DARK22004
Execution in a CPU
”Machine Code”
”Data”CPU
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh14
DARK22004
RegisterRegister--basedbased machinemachineExample: C := A + B
654321
A:12B:14C:10
LD R1, [A]LD R7, [B]ADD R2, R1, R7ST R2, [C]
Data:
7891011
?
? ?
”Machine Code”1212
14
+
26
14
12
14
1226
26Programcounter
(PC)
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh15
DARK22004
How ”long” is a CPU cycle?
1982: 5MHz200ns 60 m (in vacum)
2002: 3GHz clock0.3ns 10cm (in vacum)0.3ns 3mm (on silicon)
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh16
DARK22004
Lifting the CPU hood (simplified…)
DCBA
CPU
Mem
Instructions:
Page 5
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh17
DARK22004
Pipeline
DCBA
Mem
Instructions:
I R X WRegs
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh18
DARK22004
Pipeline
A
Mem
I R X WRegs
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh19
DARK22004
Pipeline
A
Mem
I R X WRegs
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh20
DARK22004
Pipeline
A
Mem
I R X WRegs
Page 6
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh21
DARK22004
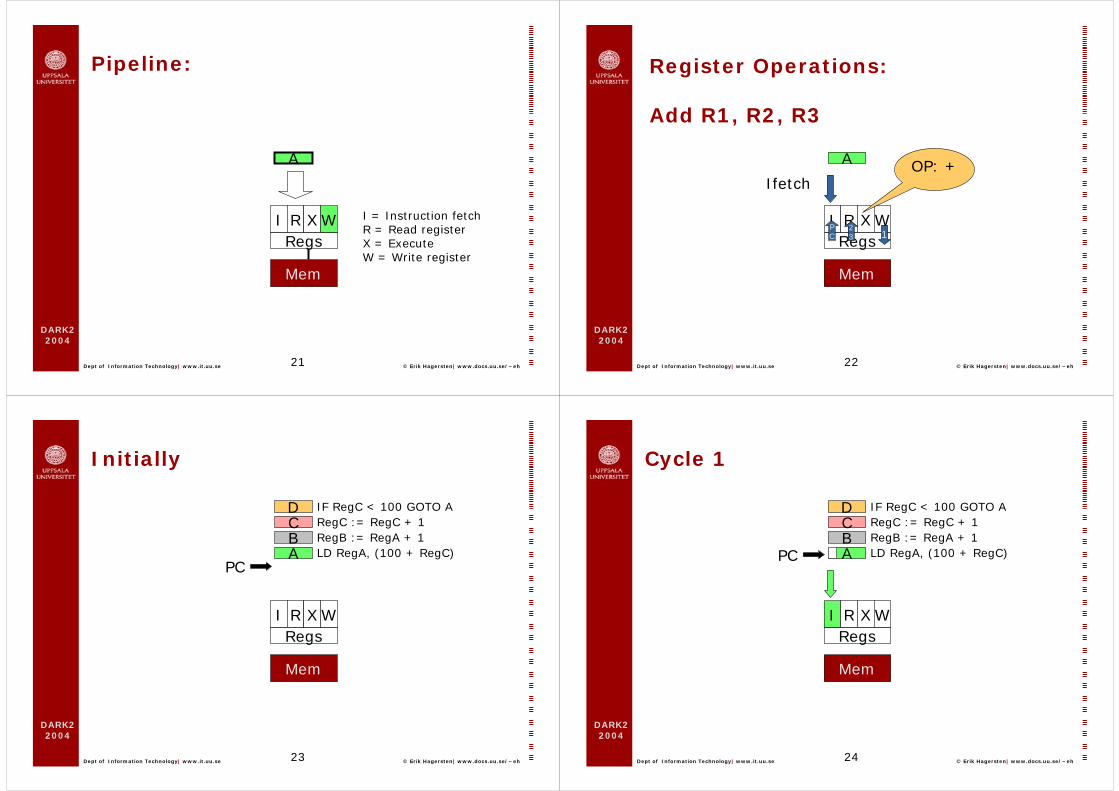
Pipeline:
A
Mem
I R X WRegs
I = Instruction fetchR = Read registerX = ExecuteW = Write register
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh22
DARK22004
Register Operations:
Add R1, R2, R3
A
Mem
I R X WRegs
23 1
OP: +Ifetch
PC
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh23
DARK22004
Initially
DCBA
Mem
I R X WRegs
LD RegA, (100 + RegC)
IF RegC < 100 GOTO A
RegB := RegA + 1RegC := RegC + 1
PC
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh24
DARK22004
Cycle 1
DCBA
Mem
I R X WRegs
LD RegA, (100 + RegC)
IF RegC < 100 GOTO A
RegB := RegA + 1RegC := RegC + 1
PC
Page 7
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh25
DARK22004
Cycle 2
DCBA
Mem
I R X WRegs
LD RegA, (100 + RegC)
IF RegC < 100 GOTO A
RegB := RegA + 1RegC := RegC + 1
PC
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh26
DARK22004
Cycle 3
DCBA
Mem
I R X WRegs
LD RegA, (100 + RegC)
IF RegC < 100 GOTO A
RegB := RegA + 1RegC := RegC + 1
+
PC
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh27
DARK22004
Cycle 4
DCBA
Mem
I R X WRegs
LD RegA, (100 + RegC)
IF RegC < 100 GOTO A
RegB := RegA + 1RegC := RegC + 1
+
PC
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh28
DARK22004
Cycle 5
DCBA
Mem
I R X WRegs
LD RegA, (100 + RegC)
IF RegC < 100 GOTO A
RegB := RegA + 1RegC := RegC + 1
+
PC
A
Page 8
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh29
DARK22004
Cycle 6
DCBA
Mem
I R X WRegs
LD RegA, (100 + RegC)
IF RegC < 100 GOTO A
RegB := RegA + 1RegC := RegC + 1
<
PC
A
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh30
DARK22004
Cycle 7
DCBA
Mem
I R X WRegs
LD RegA, (100 + RegC)
IF RegC < 100 GOTO A
RegB := RegA + 1RegC := RegC + 1
PC
A
Branch Next PC
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh31
DARK22004
Cycle 8
DCBA
Mem
I R X WRegs
LD RegA, (100 + RegC)
IF RegC < 100 GOTO A
RegB := RegA + 1RegC := RegC + 1
PC
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh32
DARK22004
Pipelining: a great idea??
Great instruction throughput (one/cycle)!Explored instruction-level parallelism (ILP)!Requires ”enough” ”independent” instructions
Control dependenceData dependence
Page 9
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh33
DARK22004
Data dependency
DCBA
Mem
I R X WRegs
LD RegA, (100 + RegC)
IF RegC < 100 GOTO A
RegB := RegA + 1RegC := RegC + 1
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh34
DARK22004
Today: ~10-20 stages and 4-6 pipes
Mem
I RRegs
+Shorter cycletime (more MHz)+ Even more ILP (parallel pipelines)- Branch delay even more expensive- Even harder to find ”enough” independent instr.
I R B M MW
I R B M MW
I R B M MW
I
I
I
I
Issuelogic
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh35
DARK22004
Modern MEM: ~150 CPU cycles
I RRegs
I R B M MW
I R B M MW
I R B M MW
I
I
I
I
Issuelogic
Mem
250 cycles+Shorter cycletime (more MHz)- Branch delay even more expensive- Memory access even more expensive- Even harder to find ”enough” independent instr.
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh36
DARK22004
Connecting to the Memory SystemConnecting to the Memory System
II RR XX MM WW
(d)(d)
s1s1s2s2
stst datadata
pcpc
dest datadest data
Data
Instr
DataDataMemoryMemorySystemSystem
IInstrnstrMemoryMemorySystemSystem
Page 10
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh37
DARK22004
Fix: Use a cache
Mem
I RRegs
B M MW
I R B M MW
I R B M MW
I R B M MW
I
I
I
I
Issuelogic
250cycles 1GB
64kB$10 cycles
Caches and more cachesor
spam, spam, spam and spam
Erik HagerstenUppsala University, Sweden
[email protected]
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh39
DARK22004
Webster about “cache”
1. cache \'kash\ n [F, fr. cacher to press, hide, fr. (assumed) VL coacticare to press] together, fr. L coactare to compel, fr. coactus, pp. of cogere to compel - more at COGENT 1a: ahiding place esp. for concealing and preserving provisions or implements 1b: a secure place of storage 2: something hidden or stored in a cache
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh40
DARK22004
Cache knowledge useful when...
Designing a new computerWriting an optimized program
or compileror operating system …
Implementing software cachingWeb cachesProxiesFile systems
Page 11
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh41
DARK22004
Memory/storage
sram dram disk
sram
2000: 1ns 1ns 3ns 10ns 150ns 5 000 000ns1kB 64k 4MB 1GB 1 TB
(1982: 200ns 200ns 200ns 10 000 000ns)Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh42
DARK22004
Address Book CacheLooking for Tommy’s Telephone Number
ÖÄÅZYXVUT
TOMMY 12345
ÖÄÅZYXV
“Address Tag”
One entry per page =>Direct-mapped caches with 28 entries
“Data”
Indexingfunction
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh43
DARK22004
Address Book CacheLooking for Tommy’s Number
ÖÄÅZYXVUT
OMMY 12345
TOMMY
EQ?
index
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh44
DARK22004
Address Book CacheLooking for Tomas’ Number
ÖÄÅZYXVUT
OMMY 12345
TOMAS
EQ?
index
Miss!Lookup Tomas’ number inthe telephone directory
Page 12
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh45
DARK22004
Address Book CacheLooking for Tomas’ Number
ZYXVUT
OMMY 12345
TOMASindex
Replace TOMMY’s datawith TOMAS’ data. There is no other choice(direct mapped)
OMAS 23457
ÖÄÅ
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh46
DARK22004
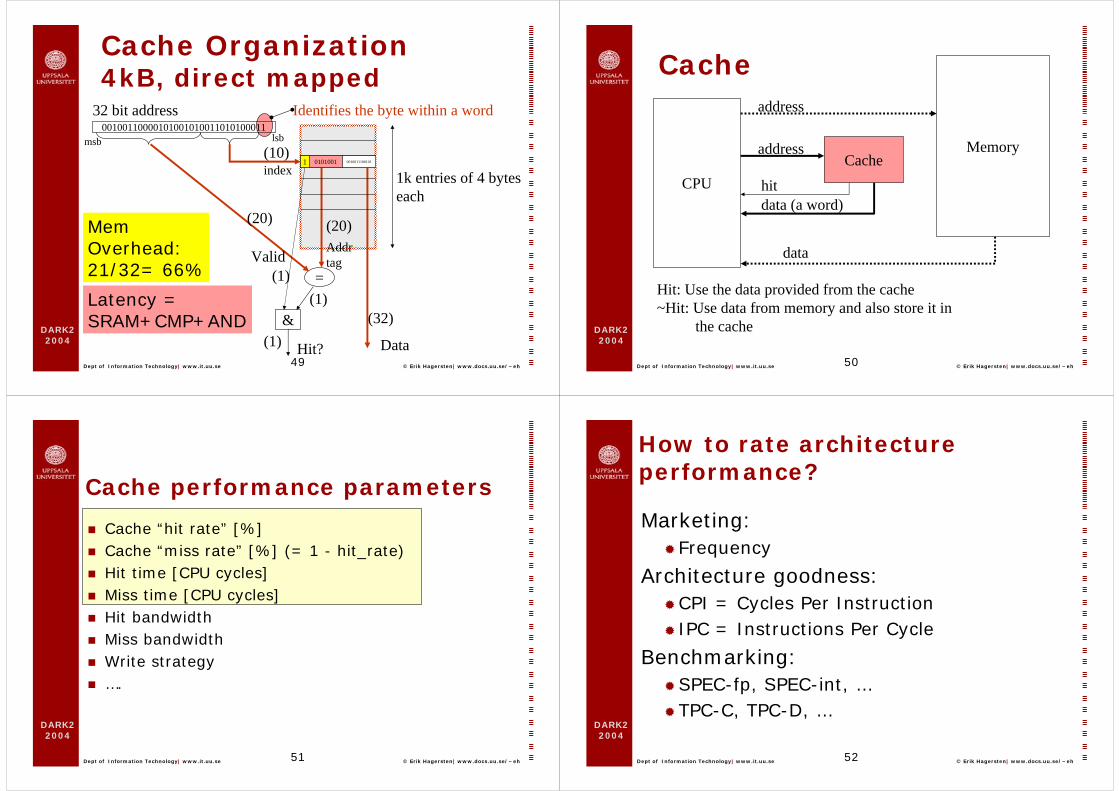
Cache
CPUCache
address
data (a word)hit
Memory
address
data
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh47
DARK22004
Cache Organization
Cache
OMAS 23457
TOMAS
index
=
Hit (1)
(1)
(4) (4)
1
Addrtag
&
(1)
Data (5 digits)
(1)Valid
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh48
DARK22004
Cache
Cache Organization (really)4kB, direct mapped
index
=
Hit?(1)(32)
1
Addrtag
&
(1)
Data
(1)
Valid
00100110000101001010011010100011
1k entries of 4 bytes each
(?)
(?)(?)
0101001 0010011100101
32 bit address identifying a byte in memory
OrdinaryMemory
msb lsb
”Byte”
What is a goodindex
function
Page 13
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh49
DARK22004
Cache Organization4kB, direct mapped
index
=
Hit?(1)(32)
1
Addrtag
&
(1)
Data
(1)
Valid
00100110000101001010011010100011
1k entries of 4 bytes each
(10)
(20) (20)
0101001 0010011100101
32 bit address Identifies the byte within a word
msb lsb
MemOverhead:21/32= 66%
Latency =SRAM+CMP+AND
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh50
DARK22004
Cache
CPUCache
address
data (a word)hit
Memory
address
data
Hit: Use the data provided from the cache~Hit: Use data from memory and also store it in
the cache
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh51
DARK22004
Cache performance parameters
Cache “hit rate” [%]Cache “miss rate” [%] (= 1 - hit_rate) Hit time [CPU cycles]Miss time [CPU cycles]Hit bandwidthMiss bandwidthWrite strategy….
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh52
DARK22004
How to rate architecture performance?
Marketing:Frequency
Architecture goodness: CPI = Cycles Per InstructionIPC = Instructions Per Cycle
Benchmarking:SPEC-fp, SPEC-int, …TPC-C, TPC-D, …
Page 14
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh53
DARK22004
Cache performance exampleAssumption:Infinite bandwidthA perfect 1.0 CyclesPerInstruction (CPI) CPU100% instruction cache hit rate
Total number of cycles =#Instr. * ( (1 - mem_ratio) * 1 +
mem_ratio * avg_mem_accesstime) =
= #Instr * ( (1- mem_ratio) + mem_ratio * (hit_rate * hit_time +
(1 - hit_rate) * miss_time)
CPI = 1 -mem_ratio + mem_ratio * (hit_rate * hit_time +
(1 - hit_rate) * miss_time)
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh54
DARK22004
Example Numbers
CPI = 1 - mem_ratio + mem_ratio * (hit_rate * hit_time) +mem_ratio * (1 - hit_rate) * miss_time)
mem_ratio = 0.25hit_rate = 0.85hit_time = 3miss_time = 100
CPI = 0.75 + 0.25 * 0.85 * 3 + 0.25 * 0.15 * 100 =
0.75 + 0.64 + 3.75 = 5.14CPU HIT MISS
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh55
DARK22004
What if ...
CPI = 1 -mem_ratio + mem_ratio * (hit_rate * hit_time) +mem_ratio * (1 - hit_rate) * miss_time)
mem_ratio = 0.25hit_rate = 0.85hit_time = 3 CPU HIT MISSmiss_time = 100 == > 0.75 + 0.64 + 3.75 = 5.14
•Twice as fast CPU ==> 0.37 + 0.64 + 3.75 = 4.77
•Faster memory (70c) ==> 0.75 + 0.64 + 2.62 = 4.01
•Improve hit_rate (0.95) => 0.75 + 0.71 + 1.25 = 2.71
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh56
DARK22004
How to get more effective caches:
Larger cache (more capacity)Cache block size (larger cache lines)More placement choice (more associativity)Innovative caches (victim, skewed, …)Cache hierarchies (L1, L2, L3, CMR)Latency-hiding (weaker memory models)Latency-avoiding (prefetching)Cache avoiding (cache bypass)Optimized application/compiler…
Page 15
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh57
DARK22004
Why do you miss in a cache
Mark Hill’s three “Cs”Compulsory miss (touching data for the first time)Capacity miss (the cache is too small)Conflict misses (imperfect cache implementation)
(Multiprocessors)Communication (imposed by communication)False sharing (side-effect from large cache blocks)
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh58
DARK22004
Avoiding Capacity Misses –a huge address bookLots of pages. One entry per page.
Ö
Ä
Å
Z
Y
X
ÖV
ÖU
ÖT
LING 12345
ÖÖ
ÖÄ
ÖÅ
ÖZ
ÖY
ÖX
“Address Tag”
One entry per page =>Direct-mapped caches with 784 (28 x 28) entries
“Data”
NewIndexingfunction
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh59
DARK22004
Cache Organization1MB, direct mapped
index
=
Hit?(1)
(32)
1
Addrtag
&
(1)
Data
(1)
Valid
00100110000101001010011010100011
256k entries
(18)
(12) (12)
0101001 0010011100101
32 bit address Identifies the byte within a word
msb lsb
MemOverhead:13/32= 40%
Latency =SRAM+CMP+AND
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh60
DARK22004
Pros/Cons Large Caches++ The safest way to get improved hit rate-- SRAMs are very expensive!!-- Larger size ==> slower speed
more load on “signals”longer distances
-- (power consumption)-- (reliability)
Page 16
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh61
DARK22004
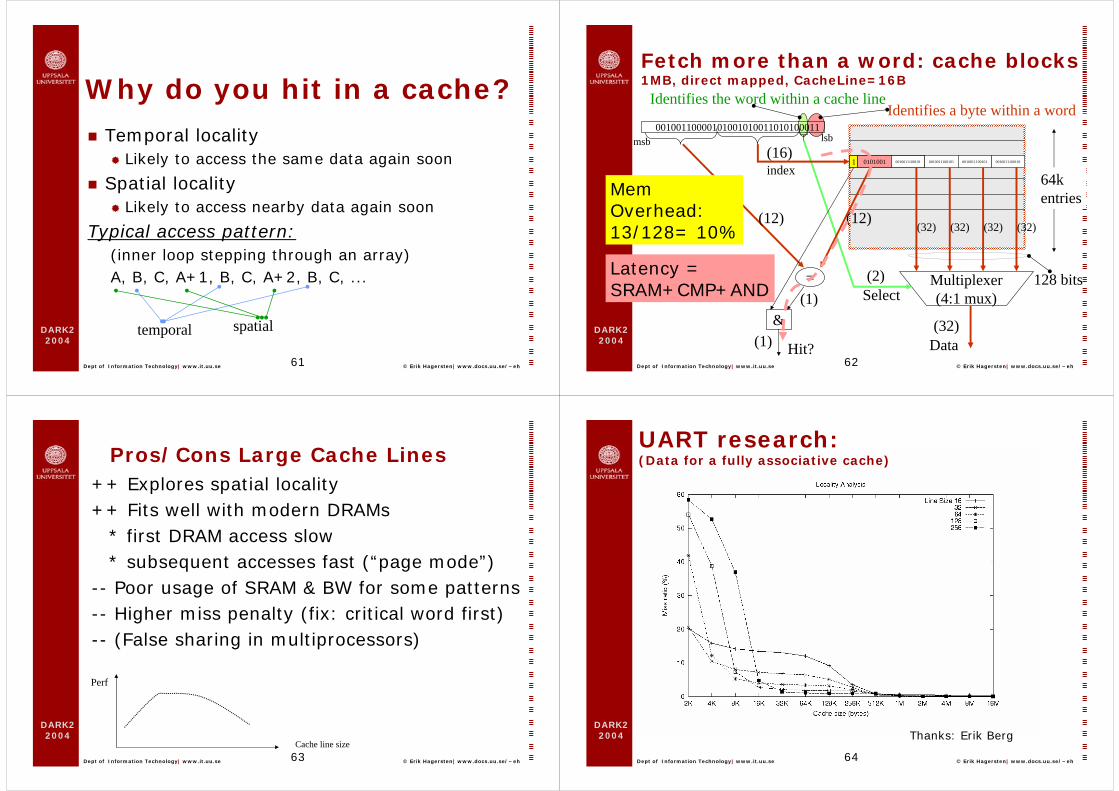
Why do you hit in a cache?Temporal locality
Likely to access the same data again soon
Spatial localityLikely to access nearby data again soon
Typical access pattern:(inner loop stepping through an array) A, B, C, A+1, B, C, A+2, B, C, ...
temporal spatial
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh62
DARK22004
(32)Data
Multiplexer(4:1 mux)
Identifies the word within a cache line
(2)Select
Identifies a byte within a word
Fetch more than a word: cache blocks1MB, direct mapped, CacheLine=16B
1
00100110000101001010011010100011
64k entries
0101001 0010011100101(16)index
0010011100101 0010011100101 0010011100101
=
Hit?(1)&
(1)
(12) (12)(32) (32) (32) (32)
128 bits
msb lsb
MemOverhead:13/128= 10%
Latency =SRAM+CMP+AND
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh63
DARK22004
Pros/Cons Large Cache Lines++ Explores spatial locality++ Fits well with modern DRAMs
* first DRAM access slow* subsequent accesses fast (“page mode”)
-- Poor usage of SRAM & BW for some patterns-- Higher miss penalty (fix: critical word first)-- (False sharing in multiprocessors)
Cache line size
Perf
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh64
DARK22004 Thanks: Erik Berg
UART research: (Data for a fully associative cache)
Page 17
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh65
DARK22004
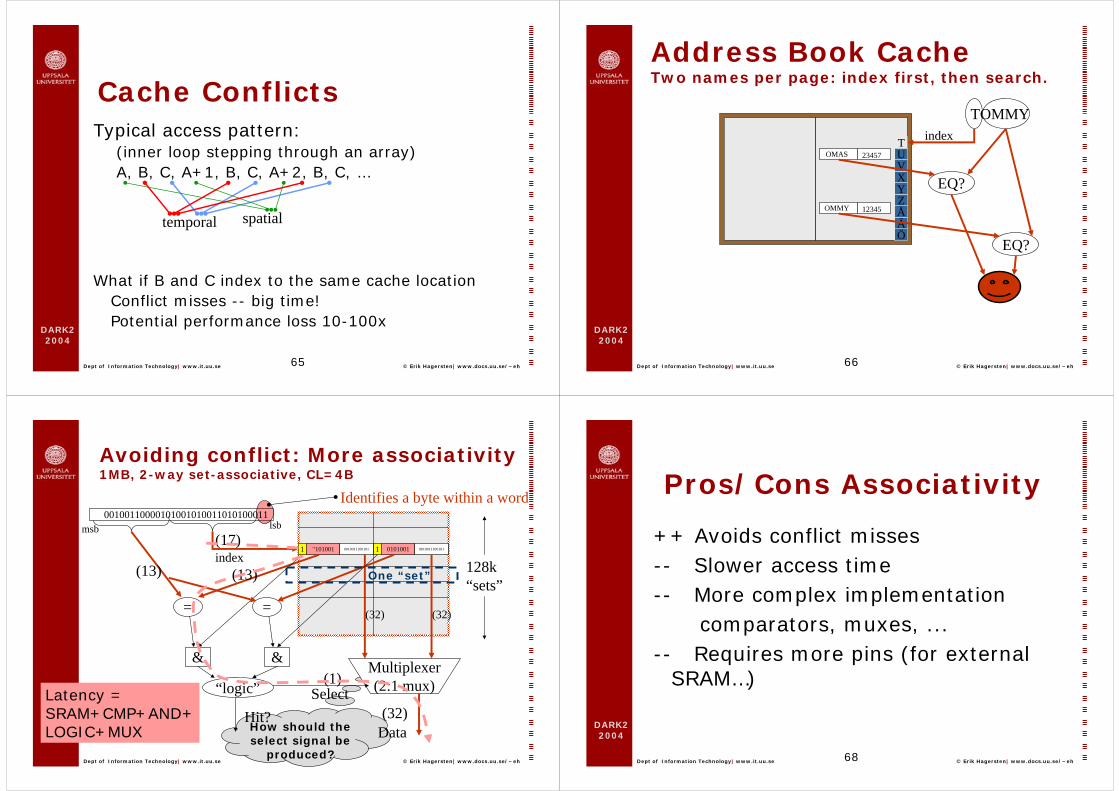
Cache ConflictsTypical access pattern:
(inner loop stepping through an array) A, B, C, A+1, B, C, A+2, B, C, …
What if B and C index to the same cache locationConflict misses -- big time!Potential performance loss 10-100x
temporal spatial
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh66
DARK22004
Address Book CacheTwo names per page: index first, then search.
ÖÄÅZYXVUT
OMAS
TOMMY
EQ?
index
12345
23457
OMMY
EQ?
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh67
DARK22004
How should the select signal be
produced?
Avoiding conflict: More associativity1MB, 2-way set-associative, CL=4B
index
(32)
1
Data
00100110000101001010011010100011
128k “sets”
(17)0101001 0010011100101
Identifies a byte within a word
Multiplexer(2:1 mux)
(32) (32)
1 0101001 0010011100101
Hit?
=
&
(13)
(1)Select
(13)
=
&
“logic”
msb lsb
Latency =SRAM+CMP+AND+LOGIC+MUX
One “set”
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh68
DARK22004
Pros/Cons Associativity
++ Avoids conflict misses-- Slower access time-- More complex implementation
comparators, muxes, ...-- Requires more pins (for external
SRAM…)
Page 18
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh69
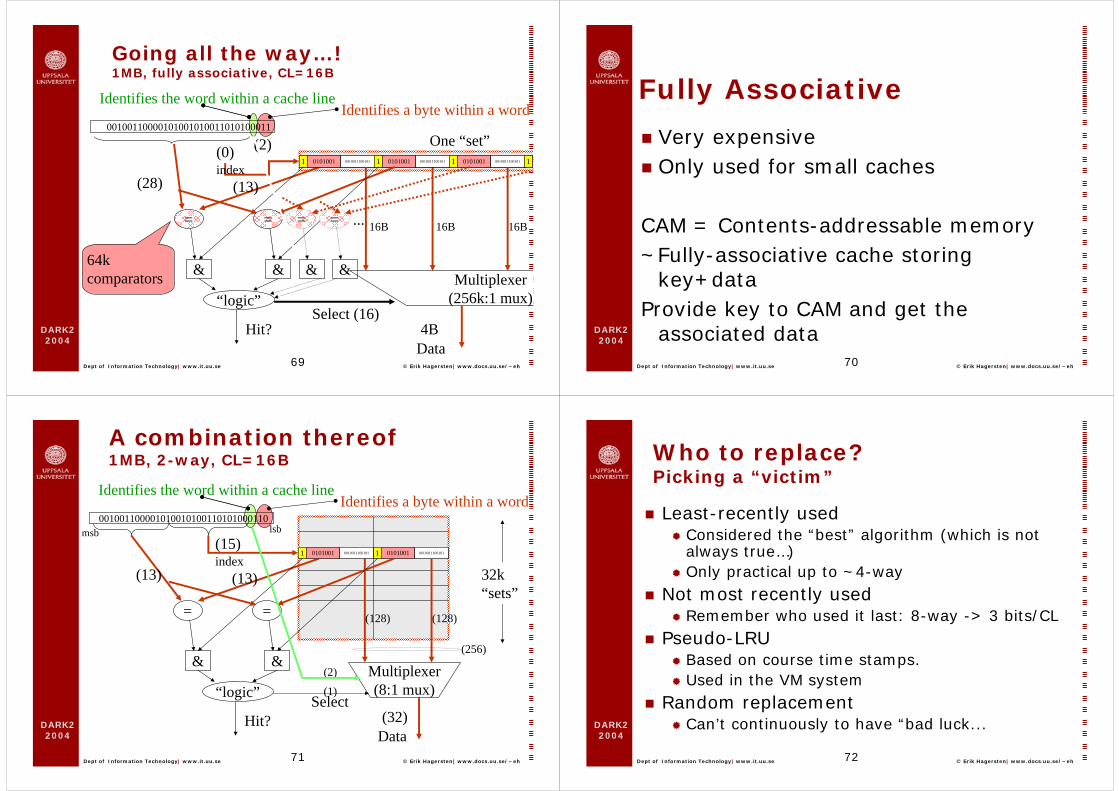
DARK22004
Going all the way…!1MB, fully associative, CL=16B
index
=
Hit? 4B
1
&
Data
00100110000101001010011010100011One “set”
(0)
(28)0101001 0010011100101
Identifies a byte within a word
Multiplexer(256k:1 mux)
Identifies the word within a cache line
Select (16)
(13)
16B 16B
1 0101001 0010011100101
=
&
“logic”
(2)1 0101001 0010011100101 1
=
&
=
&
16B...
64kcomparators
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh70
DARK22004
Fully Associative
Very expensiveOnly used for small caches
CAM = Contents-addressable memory~Fully-associative cache storing
key+dataProvide key to CAM and get the
associated data
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh71
DARK22004
A combination thereof1MB, 2-way, CL=16B
index
=
Hit? (32)
1
&
Data
001001100001010010100110101000110
32k “sets”
(15)
(13)0101001 0010011100101
Identifies a byte within a word
Multiplexer(8:1 mux)
Identifies the word within a cache line
(1)Select
(13)
(128) (128)
1 0101001 0010011100101
=
&
“logic”(2)
(256)
msb lsb
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh72
DARK22004
Who to replace?Picking a “victim”
Least-recently usedConsidered the “best” algorithm (which is not always true…)Only practical up to ~4-way
Not most recently usedRemember who used it last: 8-way -> 3 bits/CL
Pseudo-LRUBased on course time stamps. Used in the VM system
Random replacementCan’t continuously to have “bad luck...
Page 19
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh73
DARK22004
4-way sub-blocked cache1MB, direct mapped, Block=64B, sub-block=16B
index
=
Hit?
(4)
(32)
1
&
Data
00100110000101001010011010100011
16k
(14)
(12)
0101001 0010011100101
Identifies a byte within a word
0010011100101
16:1 mux
Identifies the word within a cache line
(2)
(12)(128) (128) (128) (128)
512 bits
0 1 0
& & &
logic4:1 mux(2)
Sub block within a block
msb lsb
MemOverhead:16/512= 3%
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh74
DARK22004
Pros/Cons Sub-blocking++ Lowers the memory overhead++ Avoids problems with false sharing++ Avoids problems with bandwidth waste -- Will not explore as much spatial locality-- Still poor utilization of SRAM -- Fewer sparse “things”
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh75
DARK22004
Replacing dirty cache linesWrite-back
Write dirty data back to memory (next level) at replacementA “dirty bit” indicates an altered cache line
Write-through Always write through to the next level (as well)
data will never be dirty no write-backs
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh76
DARK22004
Write Buffer/Store Buffer
Do not need the old value for a store
Write around (no write allocate in caches) used for lower level smaller caches
CPU
cache
WB:
stores loads
===
Page 20
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh77
DARK22004
Innovative cache: Victim cache
CPU
Cacheaddress
datahit Memory
address
data
Victim Cache (VC): a small, fairly associative cache (~10s of entries)Lookup: search cache and VC in parallelCache replacement: move victim to the VC and replace in VCVC hit: swap VC data with the corresponding data in Cache
VCaddress
data (a word)
hit
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh78
DARK22004
Skewed Associative CacheA, B and C have a three-way conflict
2-wayABC
4-wayABC
It has been shown that 2-way skewed performs roughly the same as 4-way caches
2-way skewedABC
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh79
DARK22004
Skewed-associative cache:Different indexing functions
index
=
1
&
00100110000101001010011010100011
128k entries
(17)
(13)
0101001 0010011100101
32 bit address Identifies the byte within a word
1 0101001 0010011100101
f1
f2
(>18)
(>18) (17)
msb lsb
2:1mux
=
&
function
(32) (32)
(32)
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh80
DARK22004
UART: Elbow cacheIncrease “associativity” when needed
Performs roughly the same as an 8-way cacheSlightly fasterUses much less power!!
AB
If severe conflict:make room
ABC
Conflict!!ABC
Page 21
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh81
DARK22004
Cache Hierarchy Latency
300:1 between on-chip SRAM - DRAMcache hierarchies
L1: small on-chip cache Runs in tandem with pipeline smallVIPT caches adds constraints (more later…)
L2: large SRAM on-chip Communication latency becomes more important
L3: Off-chip SRAMHuge cache ~10x faster than DRAM
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh82
DARK22004
Cache Hierarchy
CPU
L1$on-chip
L2$on-module
L3$on-board
Memory
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh83
DARK22004
Topology of caches: Harvard Arch
CPU needs a new instruction each cycle25% of instruction LD/ST Data and Instr. have different access patterns
==> Separate D and I first level cache==> Unified 2nd and 3rd level caches
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh84
DARK22004
Common Cache Structurefor Servers
CPU
I$ D$
L2$
L3$...
L1: CL=32B, Size=32kB, 4-way, 1ns, split I/DL2: CL=128B, Size= 1MB, 8-way, 4ns, unifiedL3: CL=128B, Size= 32MB, 2-way, 15ns, unified
Page 22
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh85
DARK22004
Why do you miss in a cache
Mark Hill’s three “Cs”Compulsory miss (touching data for the first time)Capacity miss (the cache is too small)Conflict misses (imperfect cache implementation)
(Multiprocessors)Communication (imposed by communication)False sharing (side-effect from large cache blocks)
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh86
DARK22004
How are we doing?
Creating and exploring:1) Locality
a) Spatial locality b) Temporal localityc) Geographical locality
2) Parallelisma) Instruction levelb) Thread level
Memory Technology
Erik HagerstenUppsala University, Sweden
[email protected]
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh88
DARK22004
Main memory characteristicsMain memory characteristics
Performance of main memory:Access time: time between address is latched and data is available (~50ns)Cycle time: time between requests (~100 ns)Total access time: from ld to REG valid (~150ns)
• Main memory is built from DRAM: Dynamic RAM• 1 transistor/bit ==> more error prune and slow• Refresh and precharge
• Cache memory is built from SRAM: Static RAM• about 4-6 transistors/bit
Page 23
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh89
DARK22004
DRAM organizationDRAM organization4Mbit memory array One bit memory cell
Bit line
Word line
CapacitanceR
owde
cod e
r
RAS
Address11
(4) Dataout
Column decoder CAS
Column latch
2048×2048cell matrix
The address is multiplexed Row/Address Strobe (RAS/CAS)“Thin” organizations (between x16 and x1) to decrease pin loadRefresh of memory cells decreases bandwidthBit-error rate creates a need for error-correction (ECC)
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh90
DARK22004
SRAM organizationSRAM organization
Row
dec
oder
Column decoder
512×512×4cell matrix
In buffer
Diff.
-am
plify
er
A1A2A3A4A5A6A7A8A9
A 0 A 10
A 11
A 12
A 13
A 14
A 15
A 16
A 17
I /O3
I /O2
I /O1
I /O0
CE
WEOE
Address is typically not multiplexedEach cell consists of about 4-6 transistorsWider organization (x18 or x36), typically few chipsOften parity protected (ECC becoming more common)
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh91
DARK22004
Error Detection and CorrectionError Detection and Correction
Error-correction and detectionE.g., 64 bit data protected by 8 bits of ECC
Protects DRAM and high-availability SRAM applicationsDouble bit error detection (”crash and burn” )Chip kill detection (all bits of one chip stuck at all-1 or all-0)Single bit correctionNeed “memory scrubbing” in order to get good coverage
ParityE.g., 8 bit data protected by 1 bit parity
Protects SRAM and data pathsSingle-bit ”crash and burn” detectionNot sufficient for large SRAMs today!!
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh92
DARK22004
Correcting the ErrorCorrecting the ErrorCorrection on the fly by hardware
no performance-glitchgreat for cycle-level redundancyfixes the problem for now…
Trap to softwarecorrect the data value and write back to memory
Memory scrubberkernel process that periodically touches all of memory
Page 24
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh93
DARK22004
Improving main memoryImproving main memory performanceperformance
Page-mode => faster access within a small distanceImproves bandwidth per pin -- not time to critical wordSingle wide bank improves access time to the complete CLMultiple banks improves bandwidth
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh94
DARK22004
Newer kind of DRAM...SDRAM
Mem controller provides strobe for next seq. access
DDR-DRAMTransfer data on both edges
RAMBUSFast unidirectional circular busSplit transaction addr/dataEach DRAM devices implements RAS/CAS/refresh…internally
CPU and DRAM on the same chip?? (IMEM)...
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh95
DARK22004
Physical memory, little endian
Big Endian
Little Endian
00 00 00 5f
lsbmsb
0
64MB
00 00 00 5f
lsbmsb
0
64MB
Store the value 0x5F
o H e l l
lsbmsb
0
64MB
o l l e H
lsbmsb
0
64MB
Store the string Hello
4 5 6 7 0 1 2 3
lsbmsb
0
64MB
7 6 5 4 3 2 1 0
lsbmsb
0
64MB
Numbering the bytes
Word
Virtual Memory System
Erik HagerstenUppsala University, Sweden
[email protected]
Page 25
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh97
DARK22004
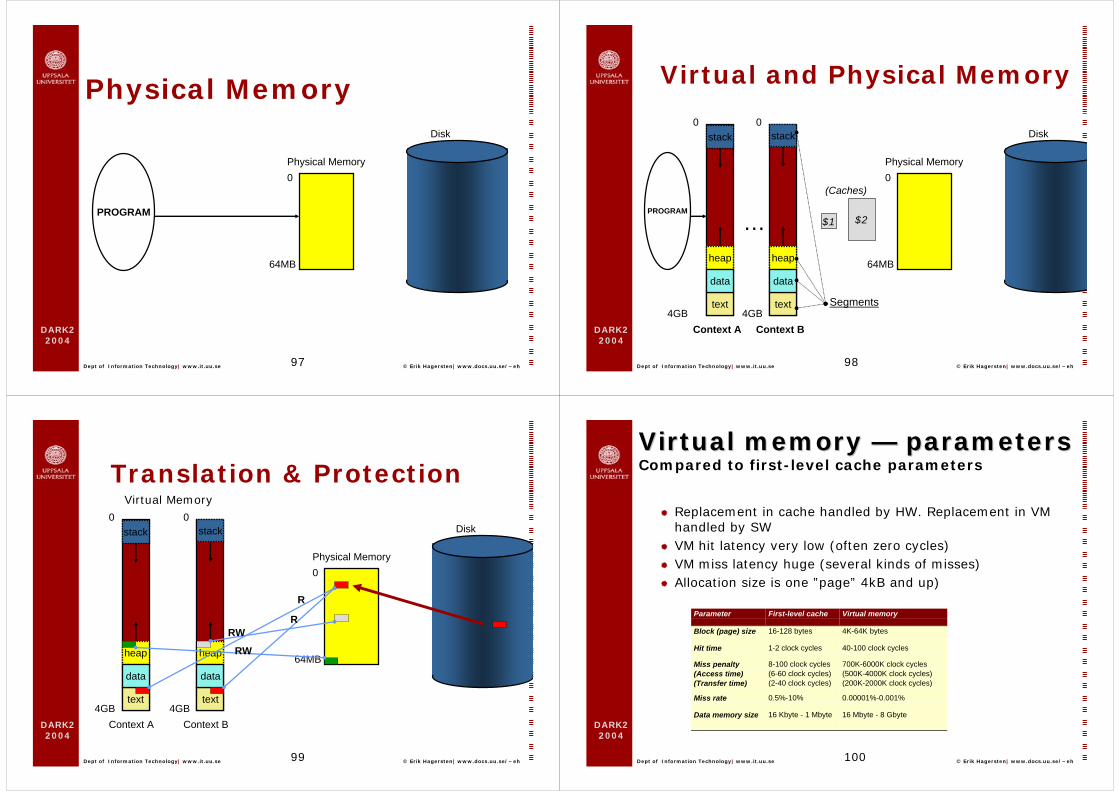
Physical Memory
Physical Memory
Disk
0
64MB
PROGRAM
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh98
DARK22004
Virtual and Physical Memory
0
4GBtext
heap
data
stack
Context A
0
4GBtext
heap
data
stack
Context B
Physical Memory
Disk
0
64MB
Segments
…PROGRAM
$2$1
(Caches)
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh99
DARK22004
Translation & Protection0
4GBtext
heap
data
Context A
0
4GBtext
heap
data
Context B
Physical Memory
Disk
0
64MB
R
RRW
RW
stack stack
Virtual Memory
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh100
DARK22004
Virtual memory Virtual memory —— parametersparametersCompared to first-level cache parameters
Parameter First-level cache Virtual memory
Block (page) size 16-128 bytes 4K-64K bytes
Hit time 1-2 clock cycles 40-100 clock cycles
Miss penalty(Access time)(Transfer time)
8-100 clock cycles(6-60 clock cycles)(2-40 clock cycles)
700K-6000K clock cycles(500K-4000K clock cycles)(200K-2000K clock cycles)
Miss rate 0.5%-10% 0.00001%-0.001%
Data memory size 16 Kbyte - 1 Mbyte 16 Mbyte - 8 Gbyte
Replacement in cache handled by HW. Replacement in VM handled by SWVM hit latency very low (often zero cycles)VM miss latency huge (several kinds of misses)Allocation size is one ”page” 4kB and up)
Page 26
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh101
DARK22004
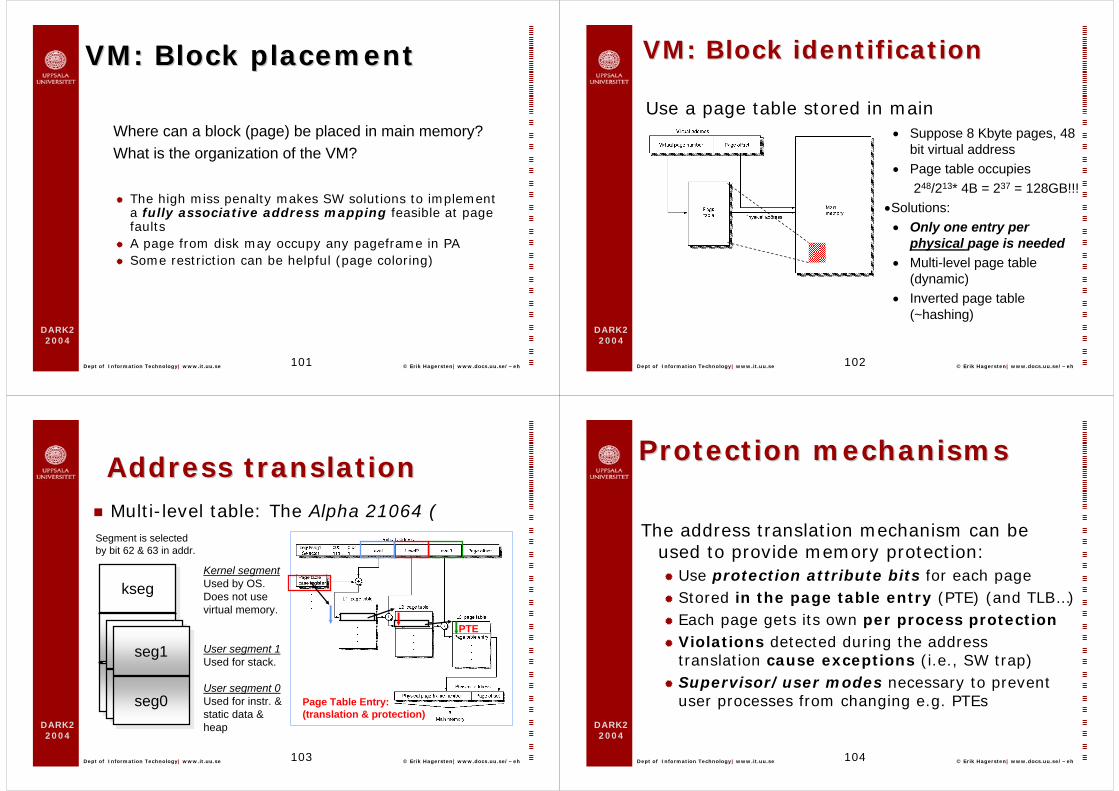
VM: Block placementVM: Block placement
Where can a block (page) be placed in main memory?What is the organization of the VM?
The high miss penalty makes SW solutions to implement a fully associative address mapping feasible at page faultsA page from disk may occupy any pageframe in PASome restriction can be helpful (page coloring)
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh102
DARK22004
VM: Block identificationVM: Block identification
Use a page table stored in main memory: • Suppose 8 Kbyte pages, 48
bit virtual address• Page table occupies
248/213* 4B = 237 = 128GB!!!•Solutions:• Only one entry per
physical page is needed• Multi-level page table
(dynamic)• Inverted page table
(~hashing)
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh103
DARK22004
ksegkseg
Address translationAddress translationMulti-level table: The Alpha 21064 (
seg1seg1
seg0seg0
seg1seg1
seg0seg0
seg1seg1
seg0seg0
Kernel segmentUsed by OS.Does not use virtual memory.
User segment 1Used for stack.
User segment 0Used for instr. &static data & heap
Segment is selectedby bit 62 & 63 in addr.
PTE
Page Table Entry:(translation & protection)
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh104
DARK22004
Protection mechanismsProtection mechanisms
The address translation mechanism can be used to provide memory protection:
Use protection attribute bits for each pageStored in the page table entry (PTE) (and TLB…)Each page gets its own per process protectionViolations detected during the address translation cause exceptions (i.e., SW trap)Supervisor/user modes necessary to prevent user processes from changing e.g. PTEs
Page 27
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh105
DARK22004
Fast address translationFast address translation
How do we avoid three extra memory references for each original memory reference?
Store the most commonly used address translations in a cache—Translation Look-aside Buffer (TLB)
==> The caches rears their ugly faces again!
P TLBlookup
Cache Main memory
VA PA
Transl.in mem
Data
Addr
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh106
DARK22004
Do we need a fast TLB?
Why do a TLB lookup for every L1 access?Why not cache virtual addresses instead?
Move the TLB on the other side of the cacheIt is only needed for finding stuff in Memory anyhowThe TLB can be made larger and slower – or can it?
P TLBlookup
Cache Main memory
VA PA
Transl.in mem
Data
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh107
DARK22004
Aliasing ProblemAliasing Problem
The same physical page may be accessed using different virtual addresses
A virtual cache will cause confusion -- a write by one process may not be observedFlushing the cache on each process switch is slow (and may only help partly)=>VIPT (VirtuallyIndexedPhysicallyTagged) is the answer
Direct-mapped cache no larger than a pageNo more sets than there are cache lines on a page + logicPage coloring can be used to guarantee correspondence between more PA and VA bits (e.g., Sun Microsystems)
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh108
DARK22004
Virtually Indexed Physically Tagged =VIPT
Have to guarantee that all aliases have the same indexL1_cache_size < (page-size * associativity)Page coloring can help further
P TLBlookup
Cache
Main memory
VAPA
Transl.in memData
=Index
PA Addr tag
Hit
Page 28
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh109
DARK22004
What is the capacity of the TLBWhat is the capacity of the TLB
Typical TLB size = 0.5 - 2kBEach translation entry 4 - 8B ==> 32 - 500
entriesTypical page size = 4kB - 16kB TLB-reach = 0.1MB - 8MB
FIX:Multiple page sizes, e.g., 8kB and 8 MBTSB -- A direct-mapped translation in memory as a “second-level TLB”
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh110
DARK22004
VM: Page replacementVM: Page replacement
Most important: minimize number of page faults
Page replacement strategies:• FIFO—First-In-First-Out
• LRU—Least Recently Used
• Approximation to LRU• Each page has a reference bit that is set on a reference• The OS periodically resets the reference bits• When a page is replaced, a page with a reference bit that is not
set is chosen
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh111
DARK22004
So far…
DataL1$
UnifiedL2$
CPU
PFhandler
I
Pagefault
D
Disk
Memory
DDDDDDD
I
DDDDD
I II I
TLB miss TLB(transl$)
TLBfill
PT PTPTPTPTPT
TLB fill
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh112
DARK22004
Adding TSB (software TLB cache)
TLBDAtrans$
TLBfill
PFhandler
PT PTPTPTPTPT
DDDDDDD
I
DDDDD
I II I
I
DataL1$Page
fault
TLB missUnified
L2$
D
CPU
MemoryDisk
TSB
TLB fill
Page 29
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh113
DARK22004
VM: Write strategyVM: Write strategy
Write back!Write through is impossible to use:
Too long access time to diskThe write buffer would need to be prohibitivelylargeThe I/O system would need an extremely high bandwidth
Write back or Write through?
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh114
DARK22004
VM dictionaryVM dictionaryVirtual Memory System The “cache” languge
Virtual address ~Cache address
Physical address ~Cache location
Page ~Huge cache block
Page fault ~Extremely painfull $miss
Page-fault handler ~The software filling the $
Page-out Write-back if dirty
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh115
DARK22004
Putting it all togetherPutting it all together
TLBDAtrans$
TLBfill
PFhandler
PT PTPTPTPTPT
DDDDDDD
I
DDDDD
I II I
I
DataL1$Page
fault
TLB miss
TLBIAtrans$
InstrL1$ Unified
L2$
D
CPU
1-2ns 2-4ns 10-20ns
150ns
500ns
2-10ms
MemoryDisk
TLB fill L2 miss
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh116
DARK22004
SummarySummary
Cache memories:HW-managementSeparate instruction and data caches permits simultaneous instruction fetch and data accessFour questions:
Block placementBlock identificationBlock replacementWrite strategy
Virtual memory:Software-managementVery high miss penalty => miss rate must be very lowAlso supports:
memory protectionmultiprogramming
Page 30
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh117
DARK22004
Caches Everywhere…
D cacheI cacheL2 cacheL3 cacheITLBDTLBTSBVirtual memory systemBranch predictorsDirectory cache…
Exploring the Memory of a Computer System
Erik HagerstenUppsala University, Sweden
[email protected]
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh119
DARK22004
Micro Benchmark Signature
for (times = 0; times < Max; times++) /* many times*/for (i=0; i < ArraySize; i = i + Stride)
dummy = A[i]; /* touch an item in the array */
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh120
DARK22004
Micro Benchmark Signature
for (times = 0; times < Max; times++) /* many times*/for (i=0; i < ArraySize; i = i + Stride)
dummy = A[i]; /* touch an item in the array */
Tim
e (n
s)Stride (bytes)
4 16 64 256 1 K 4 K 16 K 64 K 256 K 1 M 4 M0
100
200
300
400
500
600
700
8 M4 M2 M1 M
512 K256 K128 K
64 K32 K16 K
Stride(bytes)
Avg
tim
e (n
s)
Page 31
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh121
DARK22004
Stepping through the array
for (times = 0; times < Max; times++) /* many times*/for (i=0; i < ArraySize; i = i + Stride)
dummy = A[i]; /* touch an item in the array */
0 Array Size = 16, Stride=4
0 Array Size = 32, Stride=4
0 Array Size = 16, Stride=8
0 Array Size = 32, Stride=8Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh122
DARK22004
Micro Benchmark Signature
for (times = 0; times < Max; time++) /* many times*/for (i=0; i < ArraySize; i = i + Stride)
dummy = A[i]; /* touch an item in the array */
Tim
e (n
s)
Stride (bytes)
4 16 64 256 1 K 4 K 16 K 64 K 256 K 1 M 4 M0
100
200
300
400
500
600
700
8 M4 M2 M1 M
512 K256 K128 K
64 K32 K16 K
ArraySize=8MB
ArraySize=512kB
ArraySize=32-256kB
ArraySize=16kB
Stride(bytes)
Avg
tim
e (n
s)Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh123
DARK22004
Micro Benchmark Signaturefor (times = 0; times < Max; time++) /* many times*/
for (i=0; i < ArraySize; i = i + Stride)dummy = A[i]; /* touch an item in the array */
Tim
e (n
s)
Stride (bytes)
4 16 64 256 1 K 4 K 16 K 64 K 256 K 1 M 4 M0
100
200
300
400
500
600
700
8 M4 M2 M1 M
512 K256 K128 K
64 K32 K16 K
ArraySize=8MB
ArraySize=512kB
ArraySize=32kB-256kB
ArraySize=16kB
L1$ hit
L2$hit=40ns
Mem=300ns
Mem+TLBmiss
L2$ block size=64B
Pagesize=8k ==> #TLB entries = 32-64
(56 normal+8 large)
L1$ block size=16B
L2$+TLBmiss
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh124
DARK22004
Twice as large L2 cache…
for (times = 0; times < Max; time++) /* many times*/for (i=0; i < ArraySize; i = i + Stride)
dummy = A[i]; /* touch an item in the array */
Tim
e (n
s)
Stride (bytes)
4 16 64 256 1 K 4 K 16 K 64 K 256 K 1 M 4 M0
100
200
300
400
500
600
700
8 M4 M2 M1 M
512 K256 K128 K
64 K32 K16 K
ArraySize=8MB
ArraySize=512kB
ArraySize=32-256kB
ArraySize=16kB
Stride(bytes)Avg
tim
e (n
s)
ArraySize=1M
Page 32
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh125
DARK22004
Twice as large TLB…
for (times = 0; times < Max; time++) /* many times*/for (i=0; i < ArraySize; i = i + Stride)
dummy = A[i]; /* touch an item in the array */
Tim
e (n
s)
Stride (bytes)
4 16 64 256 1 K 4 K 16 K 64 K 256 K 1 M 4 M0
100
200
300
400
500
600
700
8 M4 M2 M1 M
512 K256 K128 K
64 K32 K16 K
ArraySize=8MB
ArraySize=512kB
ArraySize=32-256kB
ArraySize=16kB
Stride(bytes)
Avg
tim
e (n
s)
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh126
DARK22004
SGI Challenge Memory System Performance
Tim
e (n
s)
Stride (bytes)
4 16 64 256 1 K 4 K 16 K 64 K 256 K 1 M 4 M0
500
1,000
1,500
TLB
MEM
L2
8 M4 M2 M
1 M512 K256 K128 K
64 K32 K16 K
Stride(bytes)
Avg
tim
e (n
s)
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh127
DARK22004
Can software help us?
How are we doing?
Creating and exploring:1) Locality
a) Spatial locality b) Temporal localityc) Geographical locality
2) Parallelisma) Instruction levelb) Thread level
Optimizing for cache performance
Erik HagerstenUppsala University, Sweden
[email protected]
Page 33
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh129
DARK22004
What is the potential gain?
Latency difference L1$ and mem: ~50xBandwidth difference L1$ and mem: ~20xRepeated TLB misses adds a factor ~2-3xExecute from L1$ instead from mem ==> 50-150x improvementAt least a factor 2-4x is within reach
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh130
DARK22004
Optimizing for cache performance
Keep the active footprint smallUse the entire cache line once it has been brought into the cacheFetch a cache line prior to its usageLet the CPU that already has the data in its cache do the job...
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh131
DARK22004
Merging arrays (align)/* Unoptimized */int info1[MAX]int info2[MAX]int key[MAX]
/* Optimized */struct merged_a {
align ...int key, info1, info2;
};struct merged_a merge_array[size];
/* AltOptimized */struct merged_a {
int key, info1, info2, dummy;
};
struct merge merge_array[size];
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh132
DARK22004
Loop Interchange (for C)/* Unoptimized */for (j = 0; j < N; j = j + 1)
for (i = 0; i < N; i = i + 1)x[i][j] = 2 * x[i][j];
/* Optimized */for (i = 0; i < N; i = i + 1)
for (j = 0; j < N; j = j + 1)x[i][j] = 2 * x[i][j];
(FORTRAN: The other way around!)
Page 34
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh133
DARK22004
Merging arrays/* Unoptimized */int record[MAX]int key[MAX]
/* Optimized */struct merge {
int record;int key;
};struct merge merge_array[size];
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh134
DARK22004
Loop Merging/* Unoptimized */for (i = 0; i < N; i = i + 1)
for (j = 0; j < N; j = j + 1)a[i][j] = 2 * b[i][j];
for (i = 0; i < N; i = i + 1)for (j = 0; j < N; j = j + 1)
c[i][j] = K * b[i][j] + d[i][j]/2
/* Optimized */for (i = 0; i < N; i = i + 1)
for (j = 0; j < N; j = j + 1)a[i][j] = 2 * b[i][j];c[i][j] = K * b[i][j] + d[i][j]/2;
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh135
DARK22004
Padding of data structures
j
i
1024
1024
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh136
DARK22004
Padding of data structures
j
i
1024+padding
1024
Page 35
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh137
DARK22004
Blocking
/* Unoptimized ARRAY: x = y * z */for (i = 0; i < N; i = i + 1)
for (j = 0; j < N; j = j + 1){r = 0;for (k = 0; k < N; k = k + 1)
r = r + y[i][k] * z[k][j];x[i][j] = r;};
j
i
X: k
i
Y: j
k
Z:
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh138
DARK22004
Blocking
/* Optimized ARRAY: X = Y * Z */for (jj = 0; jj < N; jj = jj + B) for (kk = 0; kk < N; kk = kk + B)for (i = 0; i < N; i = i + 1)
for (j = jj; j < min(jj+B,N); j = j + 1){r = 0;for (k = kk; k < min(kk+B,N); k = k + 1)
r = r + y[i][k] * z[k][j];x[i][j] += r;};
j
i
X: k
i
Y: j
k
Z:First block
Second blockPartial solution
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh139
DARK22004
Prefetching/* Unoptimized */for (j = 0; j < N; j = j + 1)
for (i = 0; i < N; i = i + 1)x[i][j] = 2 * x[i][j];
/* Optimized */for (i = 0; i < N; i = i + 1)
for (j = 0; j < N/4; j = j + 4)PREFETCH x[i][j+8] x[i][j] = 2 * x[i][j];
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh140
DARK22004
Cache Affinity
Schedule the process on the processor it last ranCaches are warmed up ...
Page 36
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh141
DARK22004
How are we doing?
Creating and exploring:1) Locality
a) Spatial locality b) Temporal localityc) Geographical locality
2) Parallelisma) Instruction levelb) Thread level
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh142
DARK22004
Lab1
Run programs in a architecturesimulator modelling cache and memoryStudy performance when you:
change the cache modelchange the program
Dept of Information Technology| www.it.uu.se © Erik Hagersten| www.docs.uu.se/~eh143
DARK22004
Lab2
Write your own ”microbenchmark” and find out everything about your favorit computer’s memory system