19
Cloudera Data Engineering and Data Science
| Date post: | 21-Jan-2018 |
| Category: |
Technology |
| Upload: | jason-hubbard |
| View: | 105 times |
| Download: | 2 times |

1© Cloudera, Inc. All rights reserved.
Cloudera Data Engineering and Data
Science

2© Cloudera, Inc. All rights reserved.
We are in the age of machine learning
Data has never been
more plentiful
Open source data science and
machine learning libraries are
rapidly evolving
Flexible commodity storage and
compute make scalable
production machine learning
affordable
Data Analytics Deployment

3© Cloudera, Inc. All rights reserved.
But there are practical challenges
Most data science done at
small scale, individually,
and is difficult to replicate
Very few models
reach production
Teams have different,
conflicting requests for
languages & libraries
Native formats and
security can make data
access challenging
Data Analytics Deployment
4© Cloudera, Inc. All rights reserved.
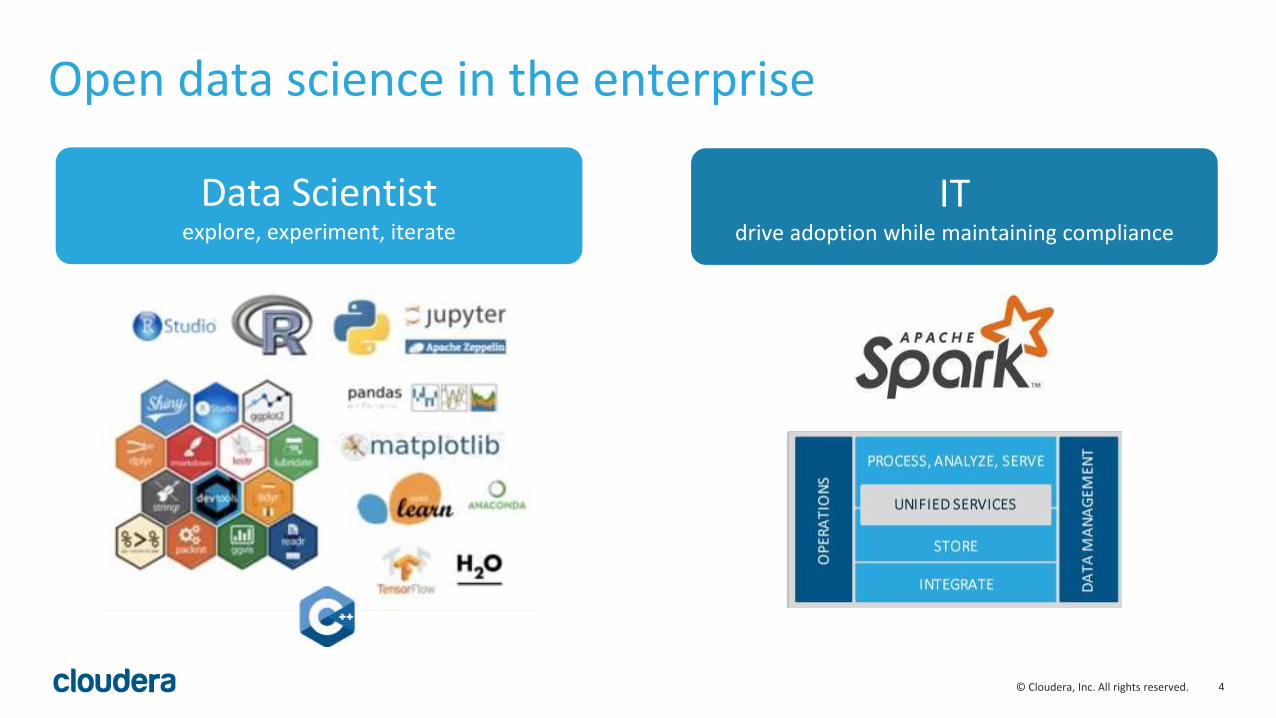
Open data science in the enterprise
ITdrive adoption while maintaining compliance
Data Scientistexplore, experiment, iterate
5© Cloudera, Inc. All rights reserved.
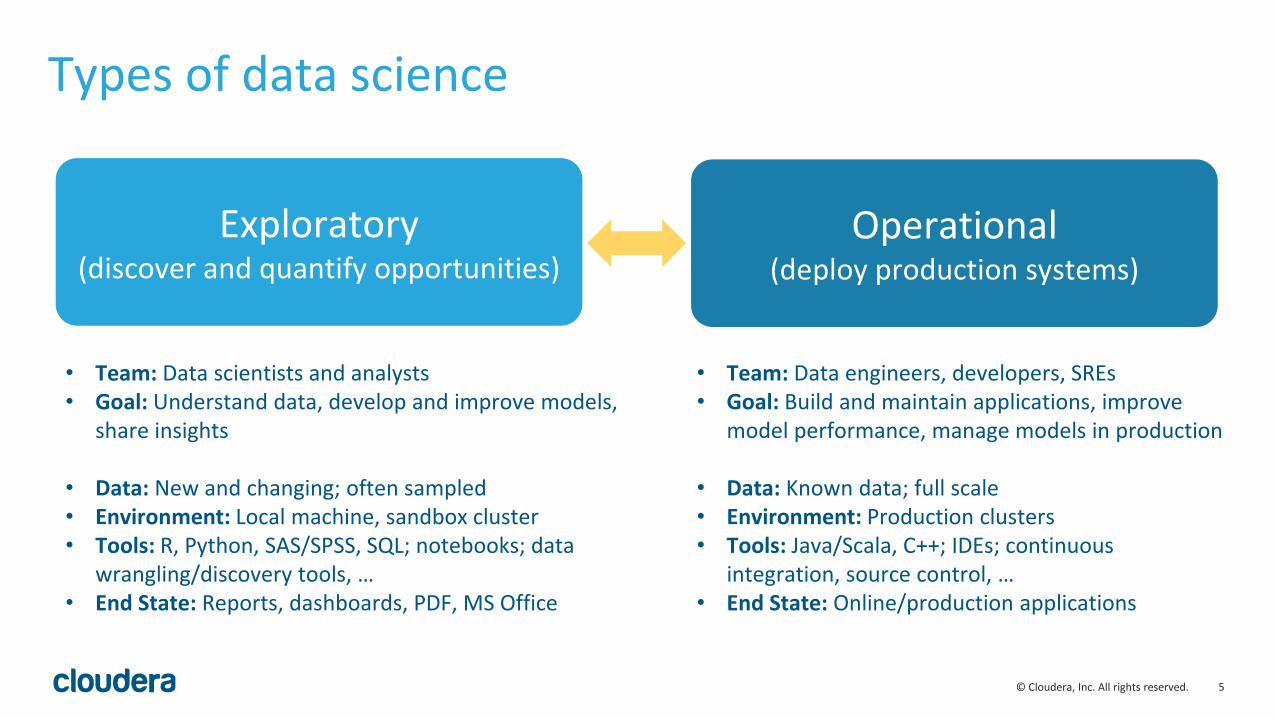
• Team: Data scientists and analysts• Goal: Understand data, develop and improve models,
share insights
• Data: New and changing; often sampled• Environment: Local machine, sandbox cluster• Tools: R, Python, SAS/SPSS, SQL; notebooks; data
wrangling/discovery tools, …• End State: Reports, dashboards, PDF, MS Office
• Team: Data engineers, developers, SREs• Goal: Build and maintain applications, improve
model performance, manage models in production
• Data: Known data; full scale• Environment: Production clusters• Tools: Java/Scala, C++; IDEs; continuous
integration, source control, …• End State: Online/production applications
Types of data science
Exploratory(discover and quantify opportunities)
Operational(deploy production systems)
6© Cloudera, Inc. All rights reserved.
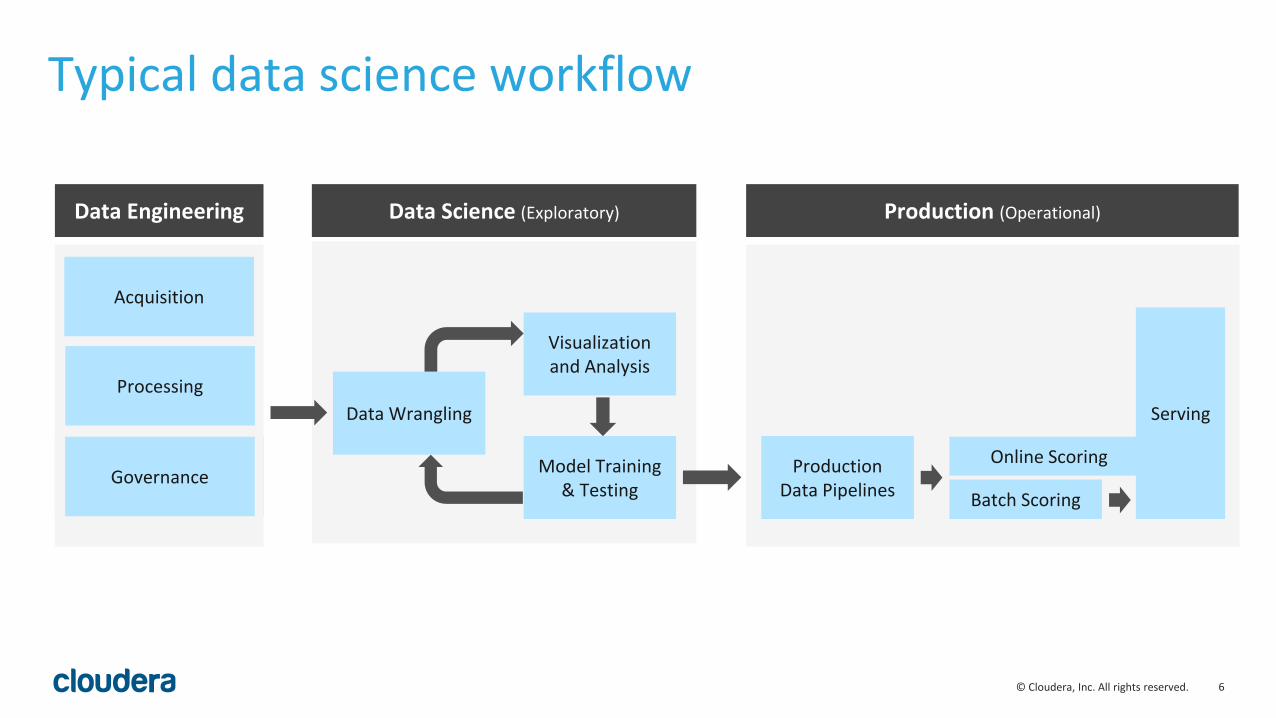
Typical data science workflow
Data Engineering Data Science (Exploratory) Production (Operational)
Data Wrangling
Visualization and Analysis
Model Training & Testing
ProductionData Pipelines Batch Scoring
Online Scoring
Serving
Data GovernanceGovernance
Processing
Acquisition
7© Cloudera, Inc. All rights reserved.
Apache Spark
Apache Spark is at the core of our data science
experience
• Libraries for common machine learning
• Trusted in production by our customers
• Delivered with expert support and training
• A requirement for our Data Science Workbench
Apache Spark is a huge driver for machine
learning
• Native language development tools
• Reliable operation at big data scale
• Native access to Hadoop data for testing and training
Spark 2.0 is here
• Separate parcel for easy implementation for multiple Spark instances
• Better Streaming Performance
• Machine Learning Persistence
8© Cloudera, Inc. All rights reserved.
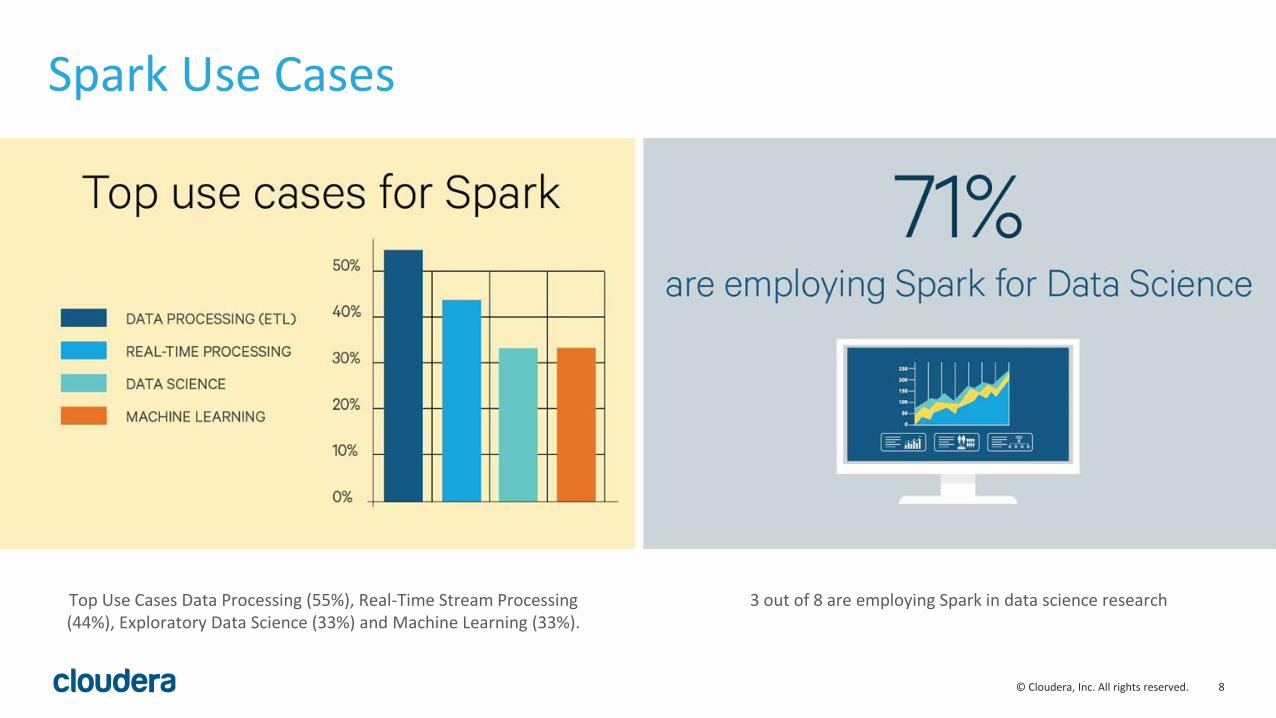
Spark Use Cases
Top Use Cases Data Processing (55%), Real-Time Stream Processing (44%), Exploratory Data Science (33%) and Machine Learning (33%).
3 out of 8 are employing Spark in data science research

9© Cloudera, Inc. All rights reserved.
Deep learning in Cloudera with Apache Spark
• Two packages:
• CaffeOnSpark
• TensorFlowOnSpark
• Developed by Yahoo
• Python and Scala APIs
• All DL architectures
• Integrated pipeline
• Run on existing clusters
• Training and inference
• Open source DL library
• Developed by Skymind
• Built on JVMs
• Supports CPUs and
GPUs
• Java, Scala, Python APIs
• Training and inference
• Imports models from:
• TensorFlow
• Caffe
• Torch
• Theano
• Runs on existing clusters
• Deep learning framework
• Developed by Intel
• Supports CPUs only
• Leverages Intel MKL
• Scala, Python APIs
• Imports models from:
• TensorFlow
• Caffe
• Torch
• Runs on existing clusters
Spark Packages DL4J BigDL

10© Cloudera, Inc. All rights reserved.
Solving Data Science is a Full-Stack Problem
• Leverage Big Data
• Enable real-time use cases
• Provide sufficient toolset for the Data Analysts
• Provide sufficient toolset for the Data Scientists + Data Engineers
• Provide standard data governance capabilities
• Provide standard security across the stack
• Provide flexible deployment options
• Integrate with partner tools
• Provide management tools that make it easy for IT to deploy/maintain
✓Hadoop
✓Kafka, Spark Streaming
✓Spark, Hive, Hue
✓Data Science Workbench
✓Navigator + Partners
✓Kerberos, Sentry, Record Service, KMS/KTS
✓Cloudera Director
✓Rich Ecosystem
✓Cloudera Manager/Director

11© Cloudera, Inc. All rights reserved.
Data Science WorkbenchSelf-service data science for the enterprise
12© Cloudera, Inc. All rights reserved.
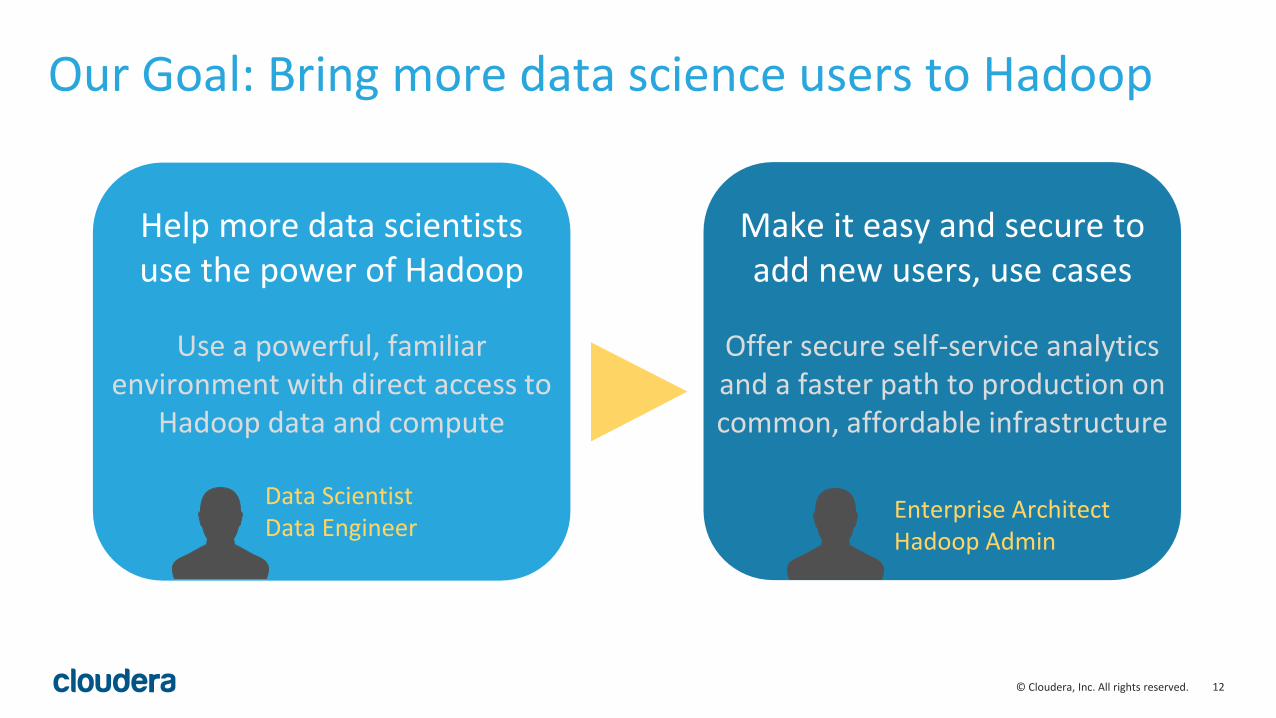
Our Goal: Bring more data science users to Hadoop
Help more data scientistsuse the power of Hadoop
Use a powerful, familiar environment with direct access to
Hadoop data and compute
Data ScientistData Engineer
Make it easy and secure to add new users, use cases
Offer secure self-service analytics and a faster path to production on common, affordable infrastructure
Enterprise ArchitectHadoop Admin

13© Cloudera, Inc. All rights reserved.
Accelerates data science from
development to production with:
●Secure self-service data access
●On-demand compute
●Support for Python, R, and Scala
●Project dependency isolation for
multiple library versions
●Workflow automation, version
control, collaboration and sharing
Cloudera Data Science WorkbenchSelf-service data science for the enterprise
14© Cloudera, Inc. All rights reserved.
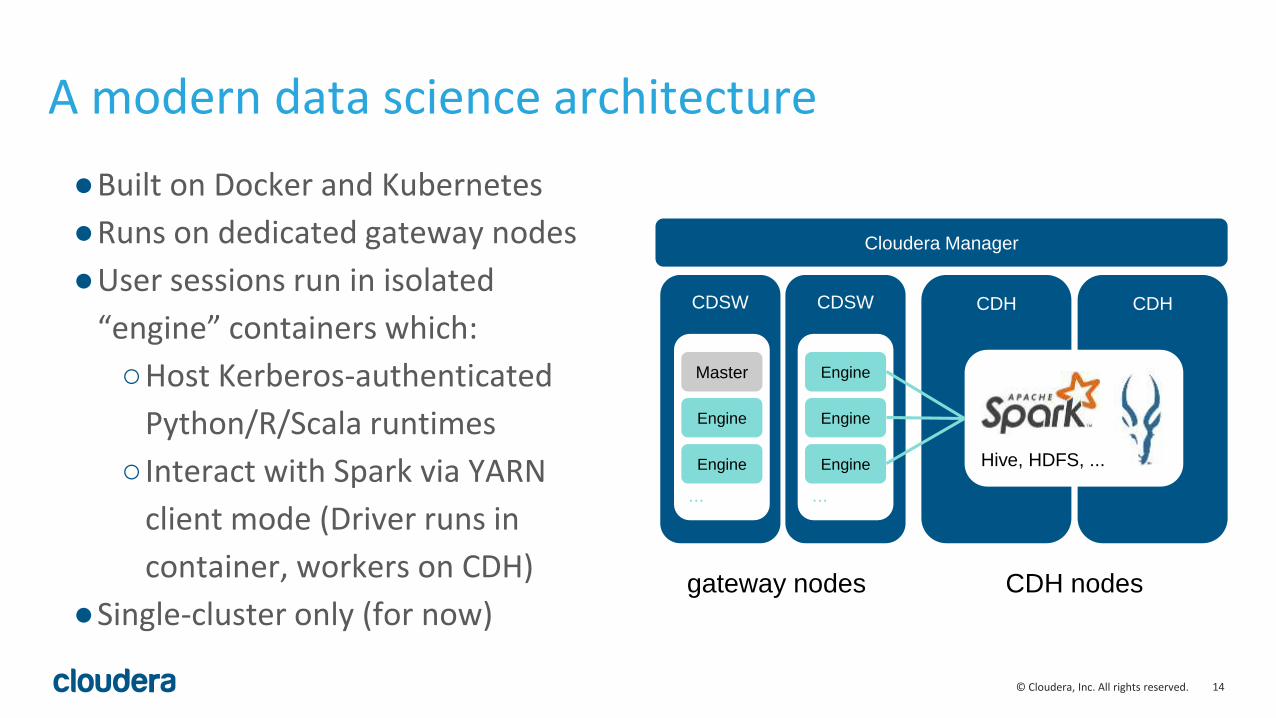
A modern data science architecture
CDH CDH
Cloudera Manager
gateway nodes CDH nodes
●Built on Docker and Kubernetes
●Runs on dedicated gateway nodes
●User sessions run in isolated
“engine” containers which:
○Host Kerberos-authenticated
Python/R/Scala runtimes
○ Interact with Spark via YARN
client mode (Driver runs in
container, workers on CDH)
●Single-cluster only (for now)
Hive, HDFS, ...
CDSW CDSW
...
Master
...
Engine
EngineEngine
EngineEngine

15© Cloudera, Inc. All rights reserved.
“Our data scientists want GPUs, but we can’t find a way to deliver multi-tenancy.If they go to the cloud on their own, it’s expensive and we lose governance.”
●Extend existing CDSW benefits to GPU-optimized deep learning tools
●Schedule & share GPU resources
●Train on GPUs, deploy on CPUs
●Works on-premises or cloud
Accelerated deep learning on-demand with GPUs
Data Science Workbench
GPUCPU
CDH
CPU
CDH
CPU
single-node
training
distributed
training, scoring
Multi-tenant GPU support on-premises or
cloud

16© Cloudera, Inc. All rights reserved.
What is the Data Science Workbench?
WorkbenchIntegrated development environment for
Python, R, and Scala with support for
Spark 2 and connectivity to secured
Hadoop clusters.
ProjectsCollaborative hub for enterprise data
science with isolated projects, secure
collaboration, and simple dependency
management.
JobsLightweight job and pipeline system for data science workloads that supports real-time monitoring, results tracking, and email alerting.

17© Cloudera, Inc. All rights reserved.
Demo

18© Cloudera, Inc. All rights reserved.
Key BenefitsHow is Cloudera Data Science different?
Works with fully secured clusters
One tool for multiple languages (Python, R, Scala)
Multi-tenant Architecture
Common Platform


















