38
Database Management 9. course
| Date post: | 30-Dec-2015 |
| Category: |
Documents |
| Upload: | alexis-wood |
| View: | 225 times |
| Download: | 0 times |

Database Management
9. course

Execution of queries

Query evaluation
QueryParse,
compileRelational
algebra
Optimize
Execution plan
Evaluate
Statistics
Query output
Data

• Query– SQL
• Parse– Correct SQL query?
• Relational algebra– Understandable for the computer
• Optimize– Based on what?

• Execution plan– If several queries give the same result: which is
the best?• Evaluate– Find the proper data records
• Query output– Give answer to the user

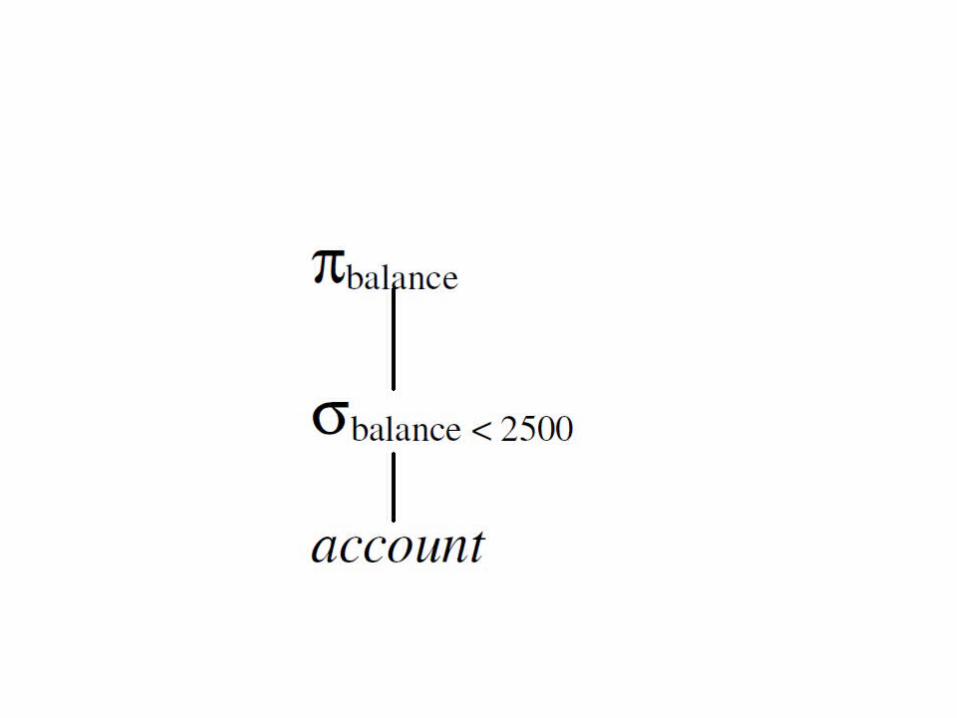
Optimization example
• Data of a bank• select balance from account
where balance<2500• Two relational algebra representation

• The cost of an operation depends on the algorithms we can use: e.g. an index speeds up the selection
• Primitive: elemental operation (projection, selection, …)
• Pipeline: building blocks for evaluations and statistics
• Input of a primitive=output of the previous primitive

Catalogue cost approximation
• For choosing the proper strategy• The approximation of cost is needed• Cost approximation can be done based on
several attributes– Space– Time
• Statistics are stored in the catalogue

Content of the catalogue
• Number of records in relation r: nr
• Number of blocks used for relation r: br
• Size of one records in relation r: sr
• Number of records in one block: fr
• Number of different values of attribute A in relation r: V(A,r) = |πA(r)|
• Average number of records that fulfills an equality selection for attribute A: SC(A,r)

Catalogue information about indexes
• Hash tables are considered as special indexes• Average number of pointers in one node
(averge number of children): fi
• Height of tree i: HTi=|log fi V(A,r)| or in case of hash, HTi=1
• Lowest level index Block (number of leaf nodes): LBi

• Statistics should be updated after every modification expensive
• Updated when DB has time• Not always consistent, but gives good
approximation

Cost of operations
• Just approximations: reading/writing is assumed to need the same time

Equality selection
• Full scan: br
• Binary search: – Blocks are sequential on the disk– File is ordered by attribute A– Just for equality search
• For clustered index on search key: HTi+1• For clustered index not on search key: HTi+• For unclustered index: HTi+SC(A,r)

Range selection
• Selection: σA≤v(r)– If v is unknown: nr/2– If v is known (with uniform distribution):
• With clustered index– If v is unknown: HTi+br/2– If v is known:
where c is the number of records that fulfills A≤v
• With unclustered index: HTi+LBi/2+nr/2– Sometimes better to use full scan

Types of join
• and , • Natural join:• T• Outer join– Left join: – Right join:– Full join:
• Theta join:
Distinct

• Nested loop join of relations r and s:FOR trr DO BEGIN
FOR tss DO BEGIN
test (tr, ts) if they fulfill Θ
IF yes THEN add (tr, ts)
ENDENDWorst case cost: nr*bs+br

Nested with blocks
FOR brr DO BEGIN
FOR bss DO BEGIN
FOR trbr DO BEGIN
FOR ts bs DO BEGIN
test (tr, ts) if they fulfill Θ
IF yes THEN add (tr, ts)
ENDEND
ENDENDWorst case: br*bs+br

Indexed nested-loop join
• If one of the relations is indexed• No need for full scan• Cost: br + nr*c, where c is the cost of selection
on s

Merge join
• First sort the relations based on the join attributes
• Reading the relations once is enough• Cost: cost of sorting+br+bs

Other operations
• Filter repetition (distinct)– Sort– Delete
• Cost: cost of sorting• Projection: cost of sorting +(filter repetition+)br
• Union: Sort relations+merge+filter repetition• Intersection: sort both+select common rows• Difference: sort+delete rows from 2nd relation

Evaluation - Materialization
• Tree of operations• Leaves: relations• Nodes: operations• Cost: storing temporal
relations + cost of operations
• Parallel processing

Pipelining
• Temporal storing is reduced• Result records are given for the next process and
not stored any more• Save memory (records are stored, not relations)• Sorting is not possible• Demand-driven pipeline: system requires data
when needed• Data-driven pipeline: operations push data to the
pipeline without request until the buffer gets full

Pipeline evaluation
• Records arrive one after another• Merge cannot be used• Indexed nested-loop join can be used

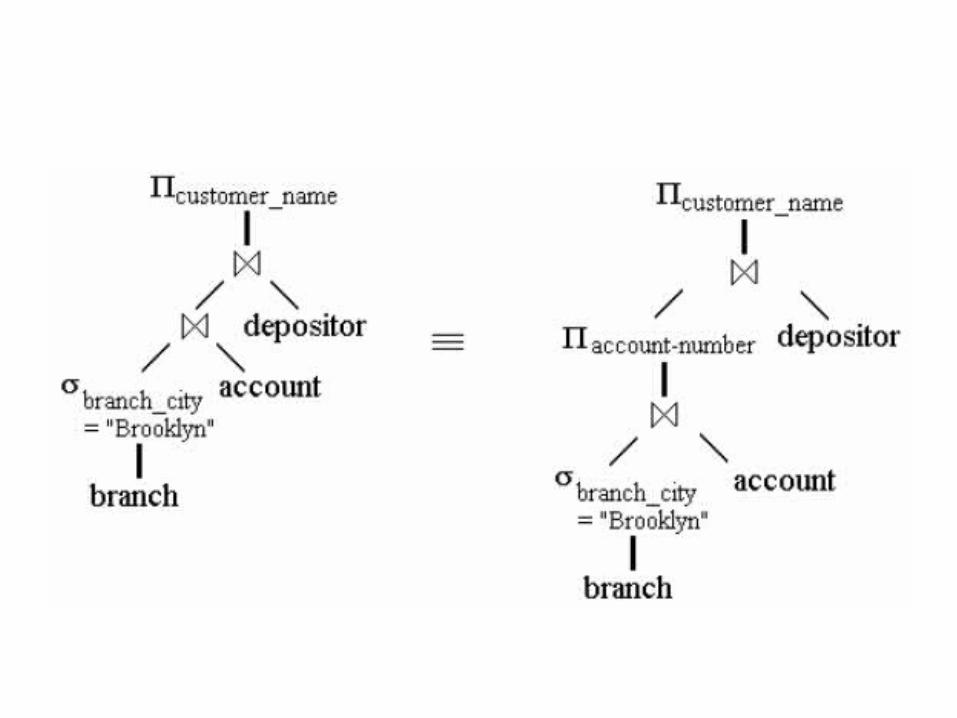
Transformation of relational expressions
• Transform to equivalent expressions with smaller evaluation time
• Example: Give me the names of customers who have account in Brooklyn
• Time consuming (selection after join 3 tables)
• Much better

Equivalence rules
• Predicates: Θ, Θ1, Θ2
• Attributes: L1, L2, L3
• Relational algebra expression: E, E1, E2
• Cascade selection: • Commutativity:• Cascade projection:• Connection of join and Descartes
multipliation:

• Commutativity of theta-join:
• Associativity of natural join:
• Distributivity of selection on join– Θ0 contains attributes from E1

• Distributivity of projection on theta-join– L1, L2 contains attributes from E1, E2 and in the join
condition there are attributes only from L1
– L1, L2 contains attributes from E1, E2
L3, L4 contains attributes from E1, E2 but not from L1
and in the join condition there are attributes only from L3 and

• Commutativity of union and intersection
• Assiciativity of union and intersection
• Distributivity of selection on union, intersection, and difference
• Distributivity of projection on union

• These are only examples!

Choosing evaluation plan
• Create algorithm for the expressions• Give order for the operations• Take them into processes• Example:
pipeline pipeline
use 1. indexuse linear
scan
Sort to filter repetition

Cost-based optimization
• List all the equivalent expressions• Assign execution plan for every plan• Calculate the cost for every plan• Choose the cheapest (based on
approximations and statistics)• Disadvantage: if too many plan, then too many
pre calculations

Example
• Joining 3 relations: 6 ways and parenthesized in two ways: (2*(n-1)!) / (n-1)!
• If n=10 then 176 billions of plans…• Solution: use some heuristics• Consider• First optimal join for the first 3 relations, then
join with the rest:• 12+12 plans remain not good!

Rules for heuristics
• Do the selection at the beginning to reduce the number of rows
• Do the projection as soon as possible to reduce the size of rows
• Split the conjunction of selections to sequence of selections (use only one selection at the time)
• Push down the selections on the tree• Use the selection or join which results in the
least number of rows use associativity of join

• If join is equivalent to a Descartes multiplication and a selection comes next then merge them into a join operation: less records are generated
• Break the projection lists, push them up on the tree (sometimes new projections can be generated)
• Search subtrees where pipeline can be applied

1. By applying the rules, several trees are got2. Calculate the cost3. Apply the cheapest• The optimization adds a cost optimize it• The optimal optimizer optimizes the cost of its
own work and the execution too.

Thank you for your attention!

















