30
©2015 LinkedIn Corporation. All Rights Reserved. 1 Methods for approaching content relevance at LinkedIn Ajit Singh DataEngConf, April 7 th 2016
| Date post: | 12-Apr-2017 |
| Category: |
Technology |
| Upload: | hakka-labs |
| View: | 221 times |
| Download: | 0 times |

©2015 LinkedIn Corporation. All Rights Reserved. 1
Methods for approaching content relevance at LinkedIn Ajit Singh DataEngConf, April 7th 2016

©2015 LinkedIn Corporation. All Rights Reserved. 2 2
Who am I ?
• Builds models and infrastructure which serves those models in production.
• Background in machine learning
• Ph.D. Machine Learning, CMU • Post-doc, University of Washington.

©2015 LinkedIn Corporation. All Rights Reserved. 3 3
Who Do I Work With ?
Engineering team with expertise in machine learning and systems.

©2015 LinkedIn Corporation. All Rights Reserved. 4 4
Why attend this talk ?
Feed Slideshare
Rich media: slides and video, with transcripts
Pulse Content discovery.
Groups Conversation Threads
©2015 LinkedIn Corporation. All Rights Reserved. 5 5
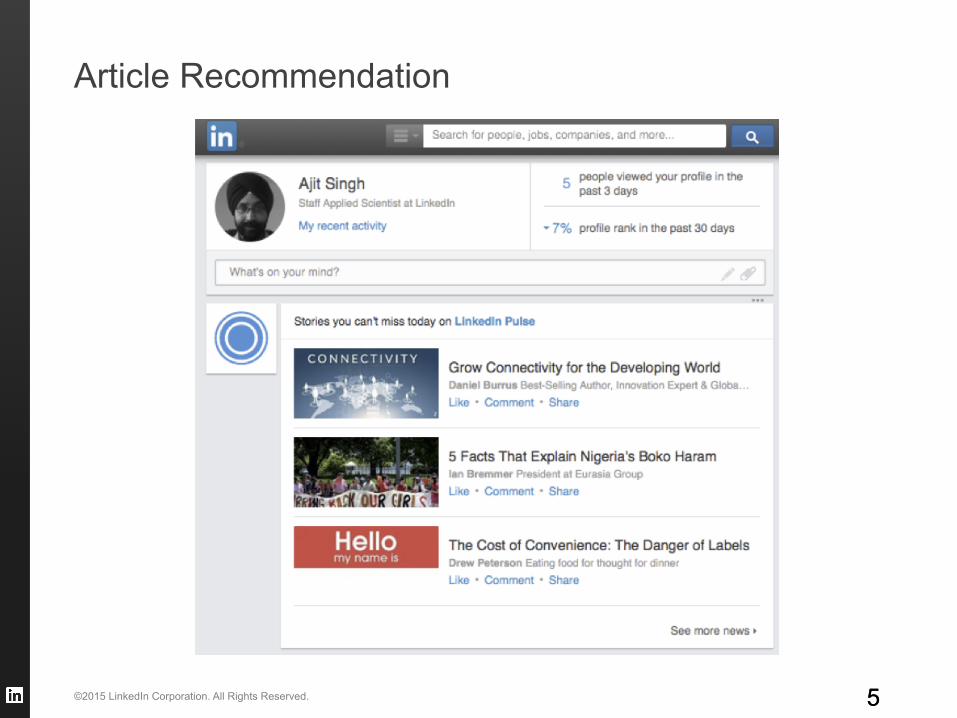
Article Recommendation

©2015 LinkedIn Corporation. All Rights Reserved. 6
Common Pattern for Recommendations Keep it Simple
1. Feature Extraction – What do I know about this content ?
2. Indexing & Search – How do I store and retrieve documents and their features? – What candidates should I consider for this request ?
3. Recommendation – What should I show you ?
6

©2015 LinkedIn Corporation. All Rights Reserved. 7 7
Engineering Stacks
Offline (minutes – days)
• Hadoop • Spark • “Big Data” tools
Nearline (seconds – hours)
• Samza • Spark Streaming, Storm
Online (milliseconds)
• Services • DB, Distributed Key-Value Stores


©2015 LinkedIn Corporation. All Rights Reserved. 9 9
Kinds of Model Features
§ Member Features – What we know about the viewer or guest. – E.g., Industry, Skills, Languages Spoken
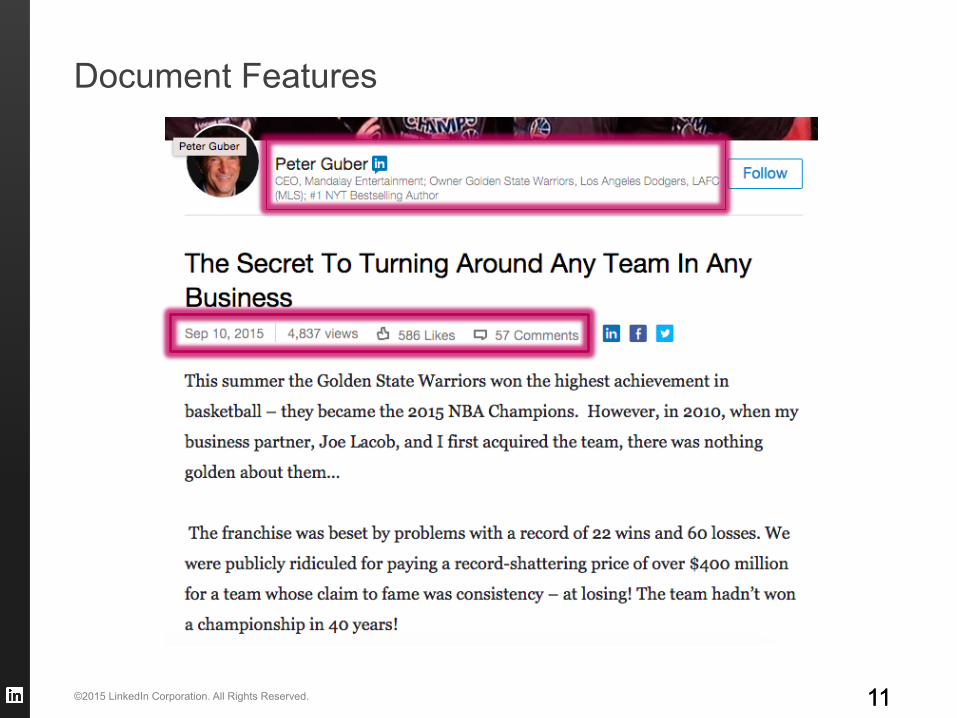
§ Document Features – What we know about a candidate item for recommendation. – E.g., For articles: vector-space, topics, social gestures.
§ Engagement – Aggregations of tracking data – E.g., Per-item click-through rates, Dwell time. – Think OLAP cubes.

©2015 LinkedIn Corporation. All Rights Reserved. 10 10
Document Features
©2015 LinkedIn Corporation. All Rights Reserved. 11 11
Document Features

©2015 LinkedIn Corporation. All Rights Reserved. 12 12
NLP
§ Featurizers which process text one document at a time. – Foundational:
§ Tokenization, Lemmatization, Stop-word removal => Vector-space models § Text near-deduplication (w-shingling, SpotSigs) § Language detection
– Classifiers: § Explicitly categorize the document into one or more label sets.
§ Fast Prototyping – Build a library first – Deploy the library to Hadoop first: e.g., via Pig, Scalding. – Don’t build a near-real time system till you have validated features.

©2015 LinkedIn Corporation. All Rights Reserved. 13 13
Near-Real Time Feature Generation
§ Before starting, ask yourself – do I need near-real time features?

14
Offline
Nearline
Online
Article DB
1
Article Stream
Article Stream
2
Language
Topics
Entity Extractors
Text Hashes
Language Features
Topic Features
Entity Features
Hash Features
Language Features
Hash Features
Topic Features
Entity Features
Search Index
3
6
5
Other Features
4 OfflineProducer

©2015 LinkedIn Corporation. All Rights Reserved. 15
Pre-computed Recommendations When you can stick to the offline world.
§ In many cases the recommendation problem is constrained: e.g., – You know which users are likely to visit in a given time period. – Documents being considered will not change quickly.
§ Give me the top-k documents by highest normalized click-through rate. – Recommendations are pushed (e-mail, push notifications)
§ Just pre-compute recommendations for likely-to-visit users – Obvious parallelization via Hadoop. – Agile development. – Send recommendations to a distributed key-value store to serve.
§ Presupposes having good tracking & data pipelines (data lake).
15

©2015 LinkedIn Corporation. All Rights Reserved. 16 16
Data Science / Engineering Contracts
§ How do I get my data into the near real-time flow ?
§ How do I deploy a model for feature X ? § What if my model has a large number of parameters ?
– Language models are notoriously huge. – Memory is often a tighter constraint than CPU.
§ What if I want to A/B test different versions of a feature ?
§ What happens if a feature source fails ?


©2015 LinkedIn Corporation. All Rights Reserved. 18 18
Search Indices
§ We use an in-house search system called Galene.
§ Store features as searchable facets within the index.

©2015 LinkedIn Corporation. All Rights Reserved. 19 19
Why ?
§ Flexible candidate selection, – Give me all the English-language documents ingested in the last four
days, which also mention the term “Lectra”.
– Give me all promoted articles tagged with “Grace Hopper 2016”
§ Consolidate state management across search & recommendations.

©2015 LinkedIn Corporation. All Rights Reserved. 20 20
Search Verticals
Search Federator
Recommender
…
Pre-computed Recommendations
Articles Slides
Groups Courses
Search Verticals
Search
quer
y
formulated query
look
up
lookup

©2015 LinkedIn Corporation. All Rights Reserved. 21 21
Continuum between Search & Recommendations
Search Recommendation
Navigational Broad / Exploratory
Guided & Faceted Search
Empty Search


©2015 LinkedIn Corporation. All Rights Reserved. 23 23
Homepage Module

Epsilon-Greedy Explore/Exploit
Target’s Red Ink Runs out in Canada.
Why we need “Economy Wide” Airline Seats.
How much work is too much work?
We can learn from barn raisers.
#1
#2
#3
#4
0.3241%
0.5923%
0.4864%
0.0231%
24

©2015 LinkedIn Corporation. All Rights Reserved. 25 25
Key Ideas
§ Online Algorithm – The model continuous updates with feedback from decisions. – Infrastructure components:
§ Near real-time counting (OLAP). § Efficient scoring of k-candidates per-request.
– Allows for warm/cold-start models (c.f., Thompson sampling)
§ What algorithms do well vs. what humans do well. – Candidate selection by human editors. – Ranking via algorithms.

©2015 LinkedIn Corporation. All Rights Reserved. 26 26
Algorithm Aversion
“Although people may be willing to trust an algorithm in the absence of experience with it, seeing it perform—and almost inevitably err—will cause them to abandon it in favor of a human judge. This may occur even when people see the algorithm outperform the human.”
Dietvorst et al. J. Exp. Psych Res. 2014

Man + Machine

©2015 LinkedIn Corporation. All Rights Reserved. 28 28
Engineering & Data Science
§ The core challenge is that data-driven products are complex – Tracking – Data Warehousing – Offline Infrastructure (Hadoop & Spark) – Modelers – Nearline & Online Infrastructure
§ Craftsmanship – Clear contracts are critical
§ Are you providing recommendations ? § Are you providing data sets ? § Are you providing modeling infrastructure to other teams ?

©2015 LinkedIn Corporation. All Rights Reserved. 29
Align on Metrics Know why something matters.
§ True North Metrics: – Track the health of a product. – Usually affected by many aspects of the product; not just relevance. – May not be measurable on short-time spans.
§ e.g., Revenue in a subscription funnel.
§ Signpost Metrics: – Leading indicators of health for a true north. – Measurable, often via an A/B test.
§ Relevance Metrics: – You have an optimization problem, this is what it optimizes. – Rare that you can directly optimize your true north metric.


















