Page 1
Dealing with Noisy and/or
Sparse Data: The Case for
Hybrid Approaches
Abeer Alwan
Speech Processing and Auditory Perception Laboratory
(SPAPL) Department of Electrical Engineering, UCLA
http://www.ee.ucla.edu/~spapl [email protected]
Page 2
Key Argument for Hybrid Approaches
in Speech Processing: Variability
• The variability in the way humans produce speech due to, for example, gender, accent, age, and emotion necessitates data-drivenapproaches to capture significant trends/behavior in the data.
• The same variability, however, may not be modeled adequately by such systems especially if data are limited and/or corrupted by noise.
Page 3
Projects (last 5 years)Hybrid Statistical Modeling and Knowledge-
Based Approach to Improve:
-rapid speaker normalization (including kids speech)
-cross-language adaptation
-height estimation
-noise robust ASR
Speech Production Modeling
-modeling the voice source by using high-speed imaging
Bird Song and Species Identification
Funding sources in the last 5 years: NSF, DARPA, and industry.
Page 4
Challenges in ASR of Kids’ Speech
• Lack of large databases of children’s speech
• Significant intra- and inter-speaker variability
• Significant variability in pronunciations due to
different linguistic backgrounds, and
misarticulations
• Low signal-to-noise ratio in the classroom
• Distinguishing reading errors from
pronunciation differences
Page 5
Adult male:
vowel /uw/
8-year old boy saying
the same vowel
Effect of Age on Resonances
Children have shorter vocal tracts, and hence higher resonances. More
variability than adults. Less control of articulators. Higher Pitch.
Page 6
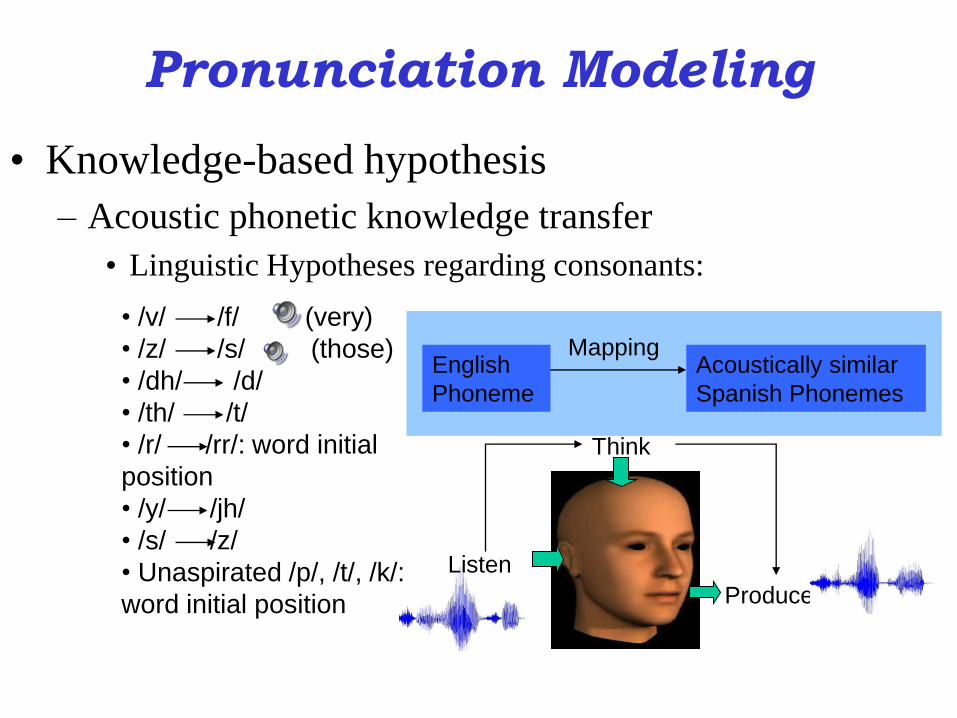
Pronunciation Modeling
• Knowledge-based hypothesis
– Acoustic phonetic knowledge transfer
• Linguistic Hypotheses regarding consonants:
English
Phoneme
Acoustically similar
Spanish Phonemes
Mapping
Think
Listen
Produce
• /v/ /f/ (very)
• /z/ /s/ (those)
• /dh/ /d/
• /th/ /t/
• /r/ /rr/: word initial
position
• /y/ /jh/
• /s/ /z/
• Unaspirated /p/, /t/, /k/:
word initial position
Page 7
Using subglottal resonances for speaker ID and speaker
normalization
(2010-2015)
• The subglottal system is practically time invariant unlike the
supraglottal vocal tract.
– Can potentially characterize a speaker better, or at least provide complementary information.
Time (ms)
Freq
uen
cy
(H
z)
0 400 800 1200 16000
1000
2000
3000
Time (ms)
Freq
uen
cy
(H
z)
0 400 800 1200 16000
1000
2000
3000
Time (ms)
Freq
uen
cy
(H
z)
0 400 800 1200 16000
1000
2000
3000
green dots:
formants
red dots:
SGRs
Page 8
Height estimation: evaluation
Using Sg1 Using Sg2 Ganchev et al.
mean abs. error 5.3 cm 5.4 cm 5.3 cm
RMS error 6.6 cm 6.7 cm 6.8 cm
• Training data: SGRs and heights of 50 speakers.
• Evaluation data: speech signals of 604 speakers.
• Main advantages of the proposed algorithm:
– Only 1 feature (Sg1 or Sg2), as opposed to 50 vocal-tract features for Ganchev et al.
– Very little training data (50 speakers vs. 468).
(Speech Communication, 2013)
Page 9
9
Correlogram
Averaged across channels
Summary Correlogram
Filtered time
waveform
Low
Fre
q.
Hig
h F
req
.
Auditory Filterbank
Sp
eech
::
::
Short-Time
AutoCorr.
Short-Time
AutoCorr.
(2010-2014)
Concept of Correlogram-based Time-Freq
Domain Pitch Estimation
9
Page 10
Variance and Invariance in Speech Quality
• Data collected in collaboration with the Linguistics department and Medical school
• Inter-speaker variability– Day/time variability (session variability)
– Read speech vs. conversational speech
– Low-affect speech vs. high-affect speech
• Recordings– Steady-state vowel /a/ (3 repetition)
– Reading sentences
– Explaining something to someone they do not know
– Phone call to someone they know
– Telling something unimportant/ joyful/ annoying
– Speaking to pets
10
Page 11
Research Directions
• Analysis and recognition of kids’ speech (including
longitudinal studies)
• Studies of the role of articulatory/linguistic features in
speech processing (human and machine)
• Studies of natural emotions (not acted)
• Human and Machine Recognition in naturally-noisy data
• Analysis and recognition of disordered speech
• Articulatory data: ultrasound, MRI, EMMA, high-speed
imaging
• Accented speech
Page 12
Evaluating Proposals/Ideas at Academic
Institutions
• Academic research should be exploratory in
nature and the source of creative ideas
which may or may not lend itself to
immediate practical success.
Page 13
Subglottal Resonances
• Subglottal features are useful for: (1) height estimation, (2)
speaker normalization for ASR, (3) speaker identification,
and (4) cross-language adaptation.
– Effective with limited data.
– Robust to environmental noise.
Collaborative research with psychology and speech science.