@graphific Roelof Pieters Introduc0on to Deep Learning for NLP 22 January 2015 Stockholm Natural Language Processing Meetup FEEDA Slides at: http://www.slideshare.net/roelofp/220115dlmeetup 1
Transcript
@graphificRoelof Pieters
Introduc0on to Deep Learning for NLP
22 January 2015 Stockholm Natural Language Processing Meetup
• vision: make learning algorithms better and easier to use
• goal: revolutions in (practical) advances for machine learning and AI
• Deep Learning = subfield of Machine Learning
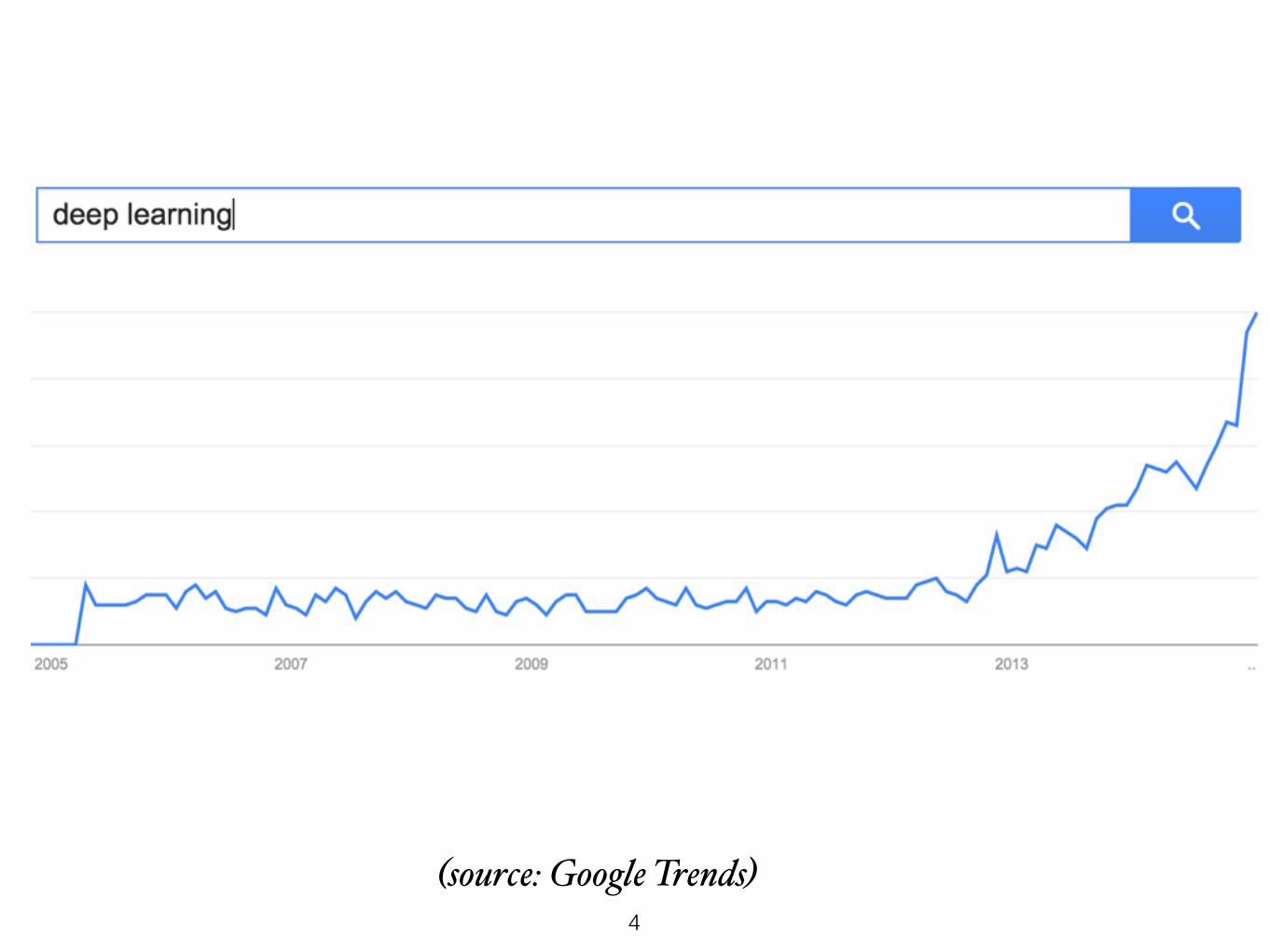
Deep Learning ??
6
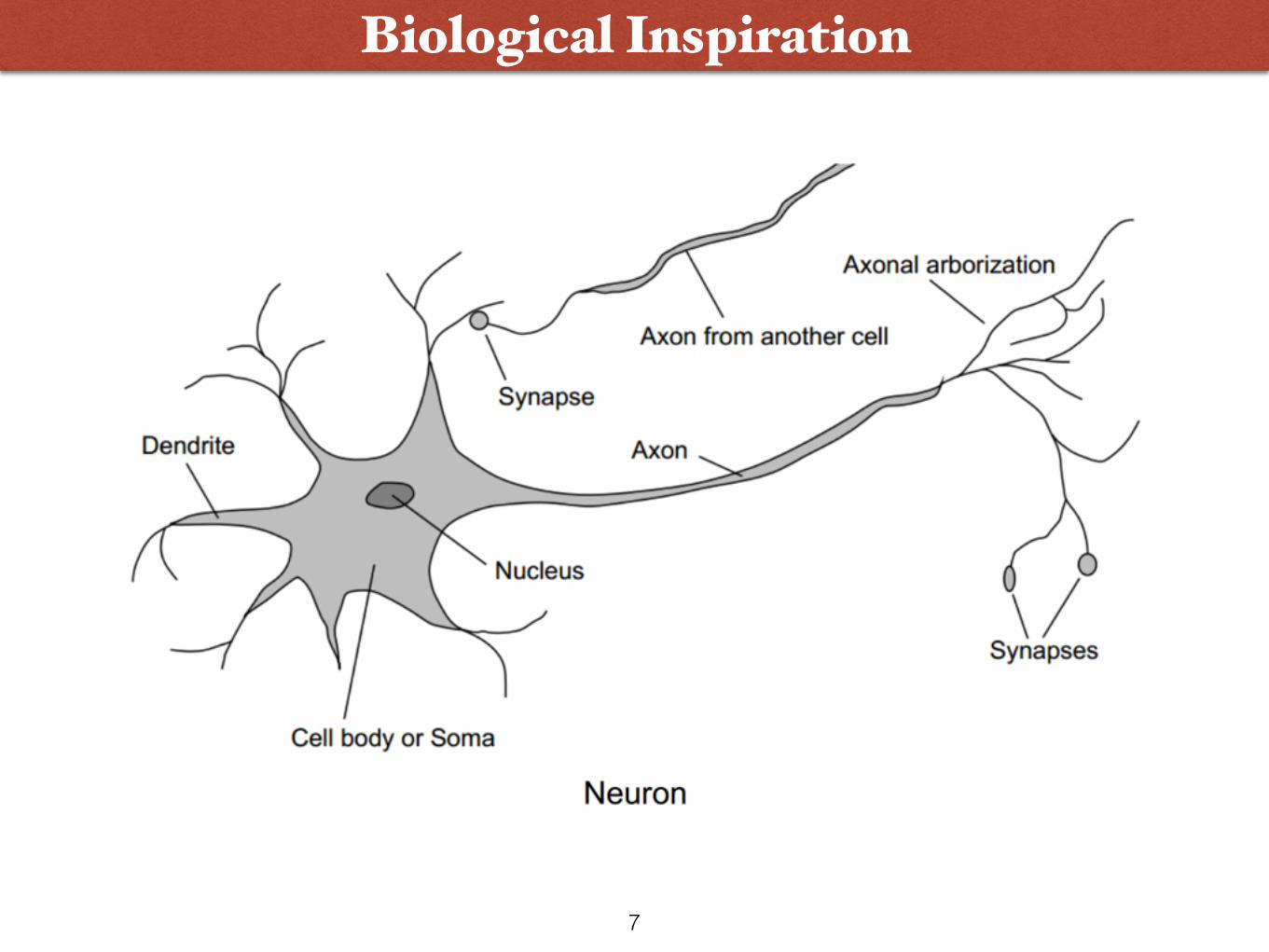
Biological Inspiration
7
Deep Learning ??
8
DL: Impact
9
Speech Recognition
DL: Impact
10
Deep Learning for the win!a few examples:
• IJCNN 2011 Traffic Sign Recognition Competition• ISBI 2012 Segmentation of neuronal structures in EM stacks
challenge• ICDAR 2011 Chinese handwriting recognition
• Deals with “construction and study of systems that can learn from data”
Machine Learning ??
A computer program is said to learn from experience (E) with respect to some class of tasks (T) and performance measure (P), if its performance at tasks in T, as measured by P, improves with experience E
— T. Mitchell 1997
11
Machine Learning ??
Traditional Programming:
Data
ProgramOutput
DataProgram
Output
Machine Learning:
12
Supervised (inductive) learning
• Training data includes desired outputs
Unsupervised learning
• Training data does not include desired outputs
Semi-supervised learning
• Training data includes a few desired outputs
Reinforcement learning
• Rewards from sequence of actions
Types of Learning
13
ML: Traditional Approach
1. Gather as much LABELED data as you can get
2. Throw some algorithms at it (mainly put in an SVM and keep it at that)
3. If you actually have tried more algos: Pick the best
4. Spend hours hand engineering some features / feature selection / dimensionality reduction (PCA, SVD, etc)
5. Repeat…
For each new problem/question::
14
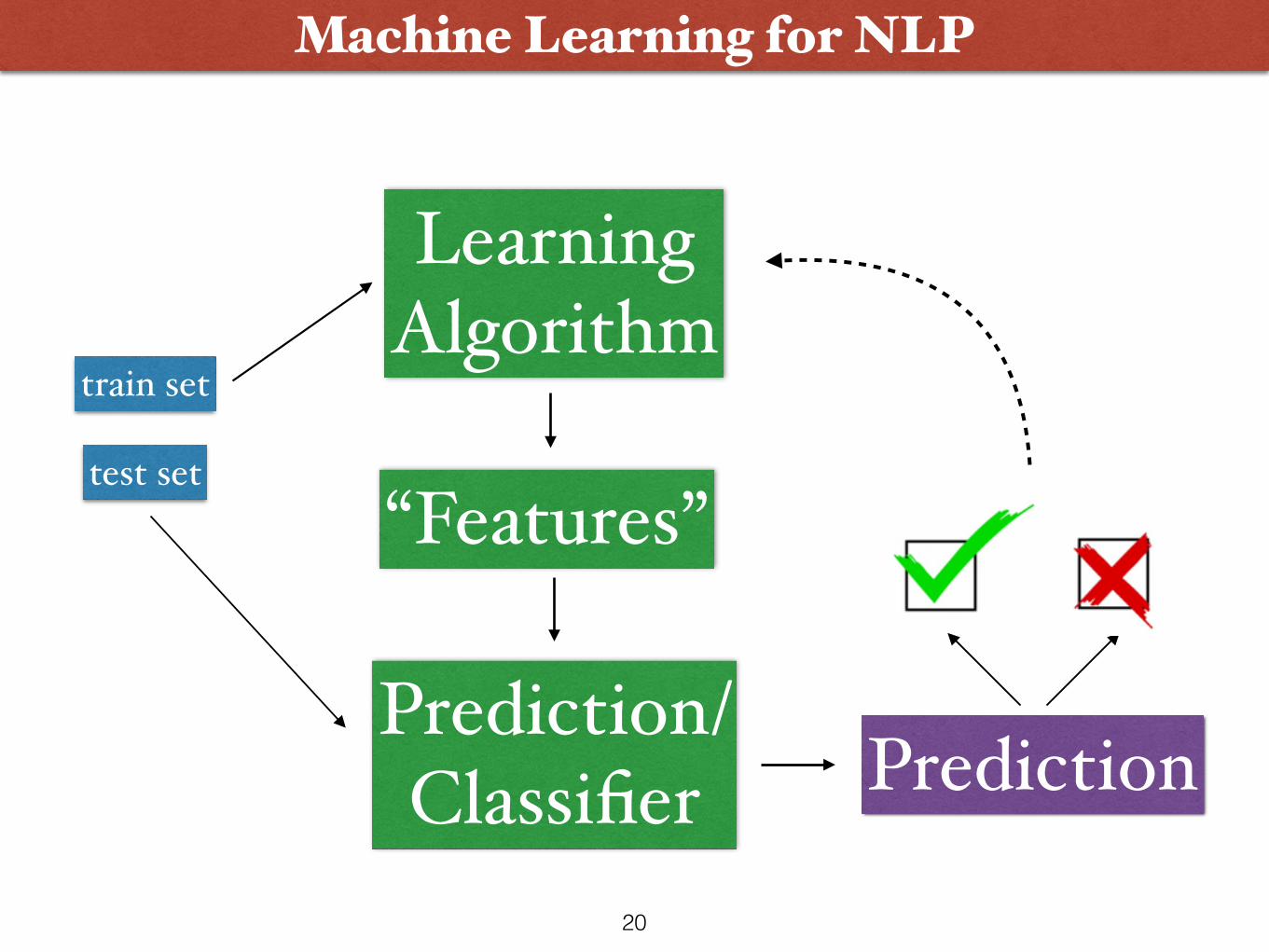
Machine Learning for NLP
Data
Classic Approach: Data is fed into a learning algorithm:
• Until the early 1990’s, NLP systems were built manually with hand-crafted dictionaries and rules.
• As large electronic text corpora became increasingly available, researchers began using machine learning techniques to automatically build NLP systems.
• Today, the vast majority of NLP systems use machine learning.
21
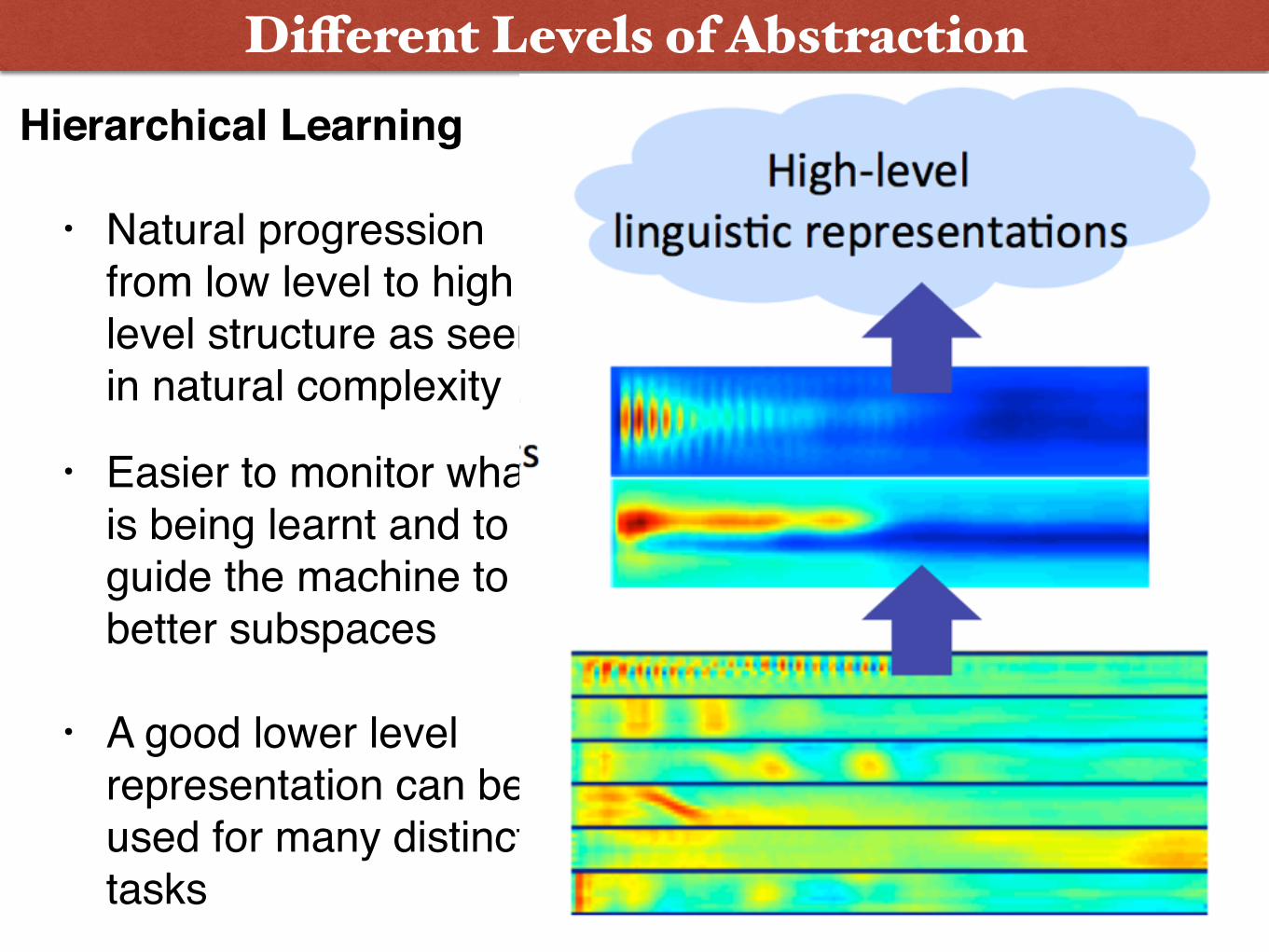
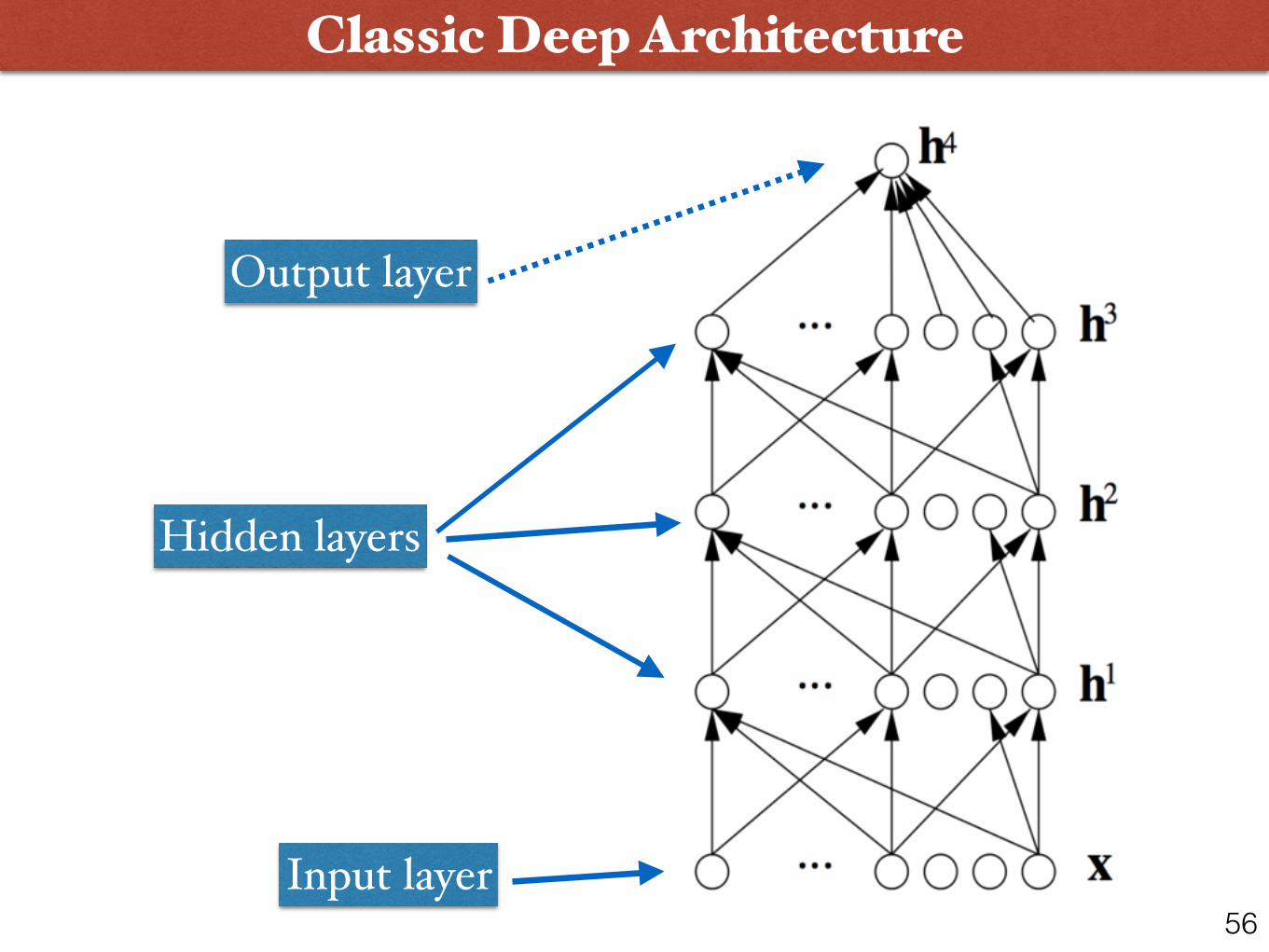
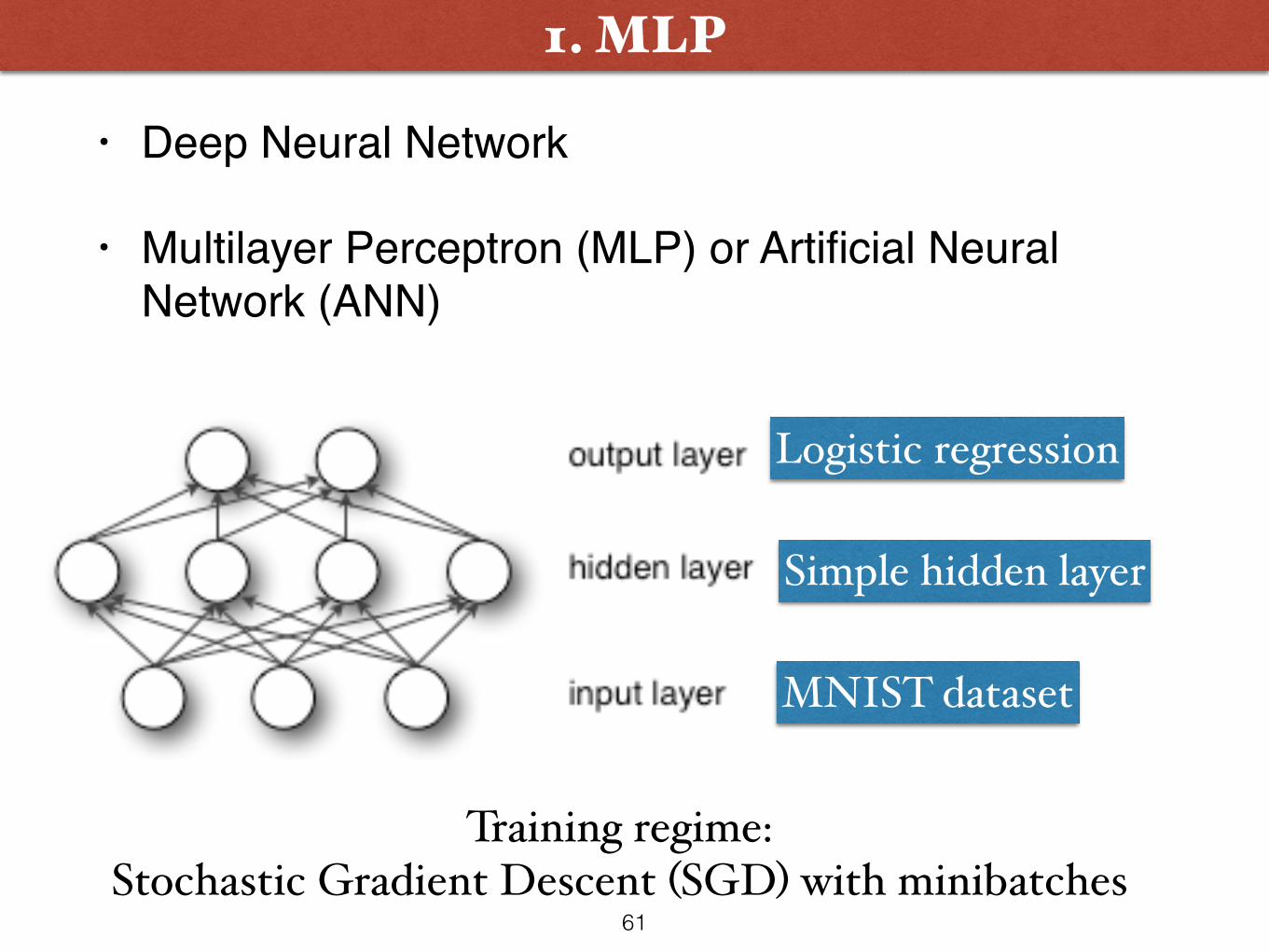
2. Neural Networks and a short history lesson
22
Perceptron (1957)
Frank Rosenblatt (1928-1971)
Original Perceptron
Simplified model:
(From Perceptrons by M. L Minsky and S. Papert, 1969, Cambridge, MA: MIT Press. Copyright 1969
1974 Paul Werbos’ invents Backpropagation algorithm for NN1986 Backdrop popularized by Rumelhart, Hinton, Williams1990: Renewed Interest in NN’s
29
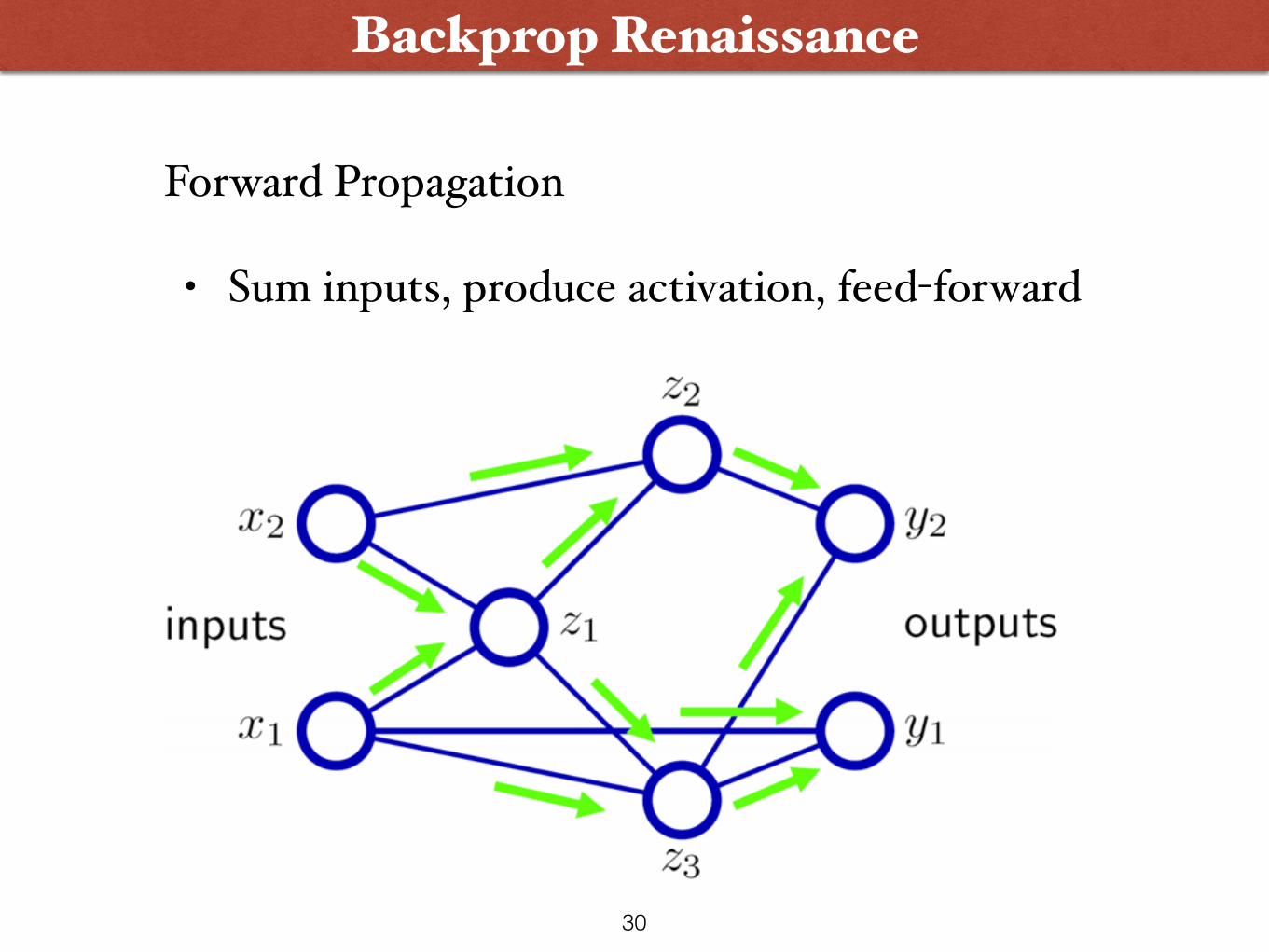
Backprop Renaissance
Forward Propagation
• Sum inputs, produce activation, feed-forward
30
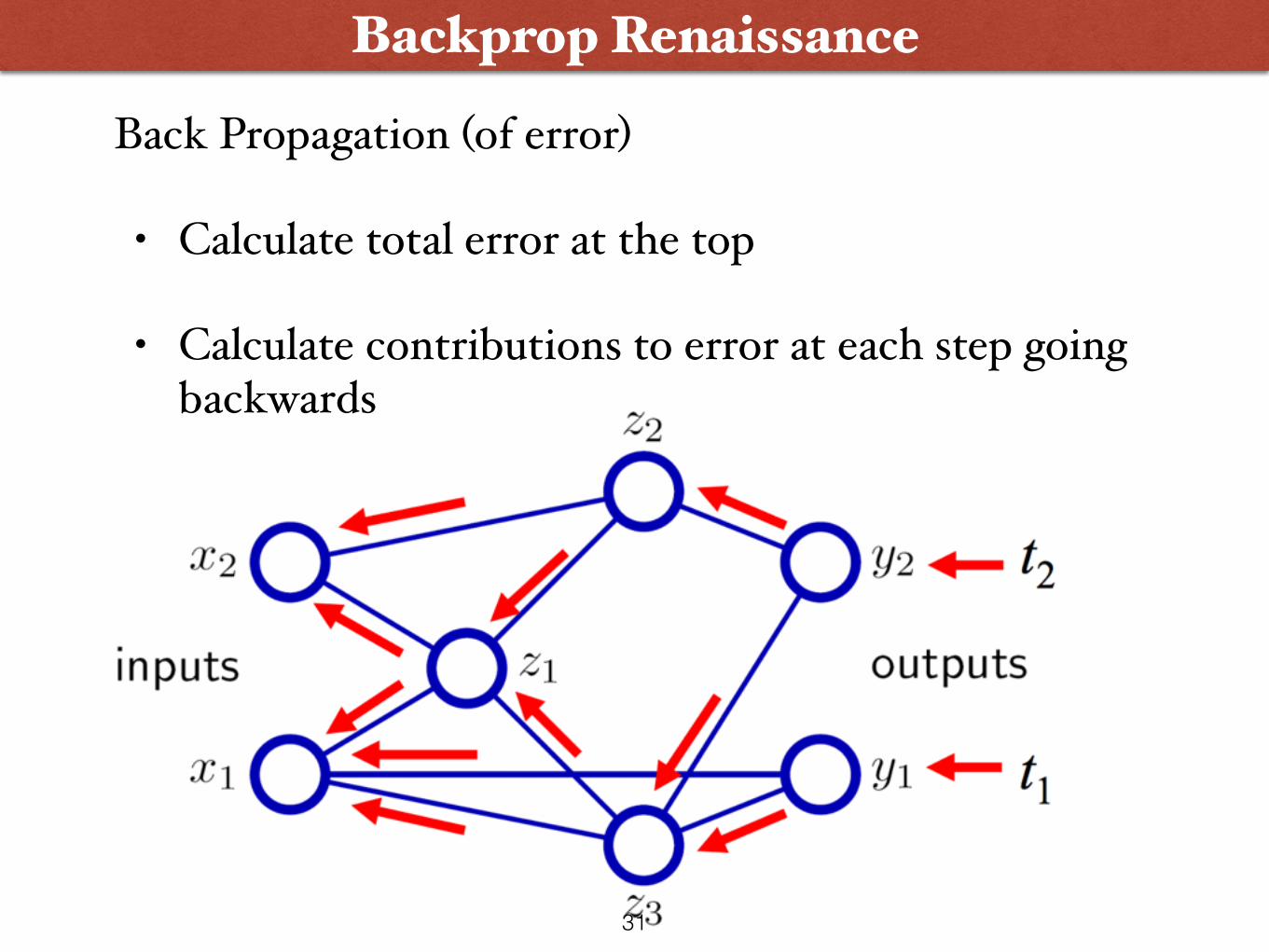
Backprop Renaissance
Back Propagation (of error)
• Calculate total error at the top
• Calculate contributions to error at each step going backwards
31
• Compute gradient of example-wise loss wrt parameters
• Simply applying the derivative chain rule wisely
• If computing the loss (example, parameters) is O(n)computation, then so is computing the gradient
Backpropagation
32
Simple Chain Rule
33
Training procedure
• Initialize randomly• Sequentially give it data.• See what the difference is between network output
and actual output.• Update the weights according to this error.• End result: give a model input, and it produces a
proper output.
Quest for the weights. The weights are the model!
To reiterate:
34
So why only now?
• Inspired by the architectural depth of the brain, researchers wanted for decades to train deep multi-layer neural networks.
• No successful attempts were reported before 2006 …Exception: convolutional neural networks, LeCun 1998
• SVM: Vapnik and his co-workers developed the Support Vector Machine (1993) (shallow architecture).
• Breakthrough in 2006!
35
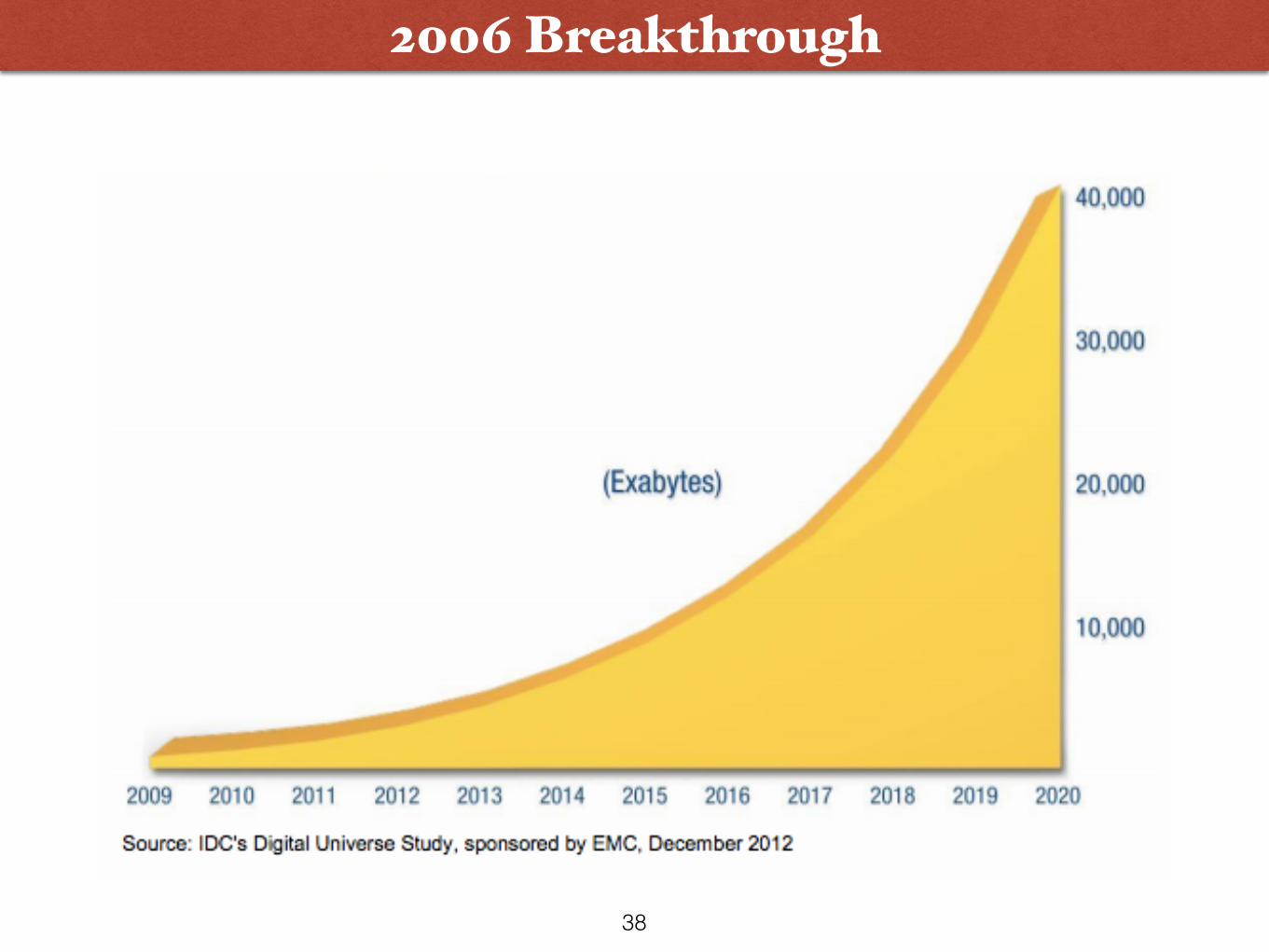
2006 Breakthrough
• More data
• Faster hardware: GPU’s, multi-core CPU’s
• Working ideas on how to train deep architectures
36
2006 Breakthrough
• More data
• Faster hardware: GPU’s, multi-core CPU’s
• Working ideas on how to train deep architectures
37
2006 Breakthrough
38
2006 Breakthrough
• More data
• Faster hardware: GPU’s, multi-core CPU’s
• Working ideas on how to train deep architectures
39
2006 Breakthrough
40
2006 Breakthrough
• More data
• Faster hardware: GPU’s, multi-core CPU’s
• Working ideas on how to train deep architectures
41
2006 Breakthrough
Stacked Restricted Boltzman Machines* (RBM) Hinton, G. E, Osindero, S., and Teh, Y. W. (2006).A fast learning algorithm for deep belief nets.Neural Computation, 18:1527-1554.
Stacked Autoencoders (AE) Bengio, Y., Lamblin, P., Popovici, P., Larochelle, H. (2007).Greedy Layer-Wise Training of Deep Networks,Advances in Neural Information Processing Systems 19
Currently an explosion of developments• Hessian-Free networks (2010)• Long Short Term Memory (2011)• Large Convolutional nets, max-pooling (2011)• Nesterov’s Gradient Descent (2013)
Currently state of the art but...• No way of doing logical inference (extrapolation)• No easy integration of abstract knowledge• Hypothetic space bias might not conform with reality
65
Deep Learning: Future Challenges
a
66
Szegedy, C., Wojciech, Z., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I., Fergus, R. (2013) Intriguing properties of neural networks
Collobert, R., Weston, J., Bottou, L., Karlen, M., Kavukcuoglu, K., Kuksa, P. (2011) . Natural Language Processing (almost) from Scratch
76
Multi-embeddings: Stanford (2012)
Eric H. Huang, Richard Socher, Christopher D. Manning, Andrew Y. Ng Improving Word Representations via Global Context and Multiple Word Prototypes
77
Linguistic Regularities: Mikolov (2013)
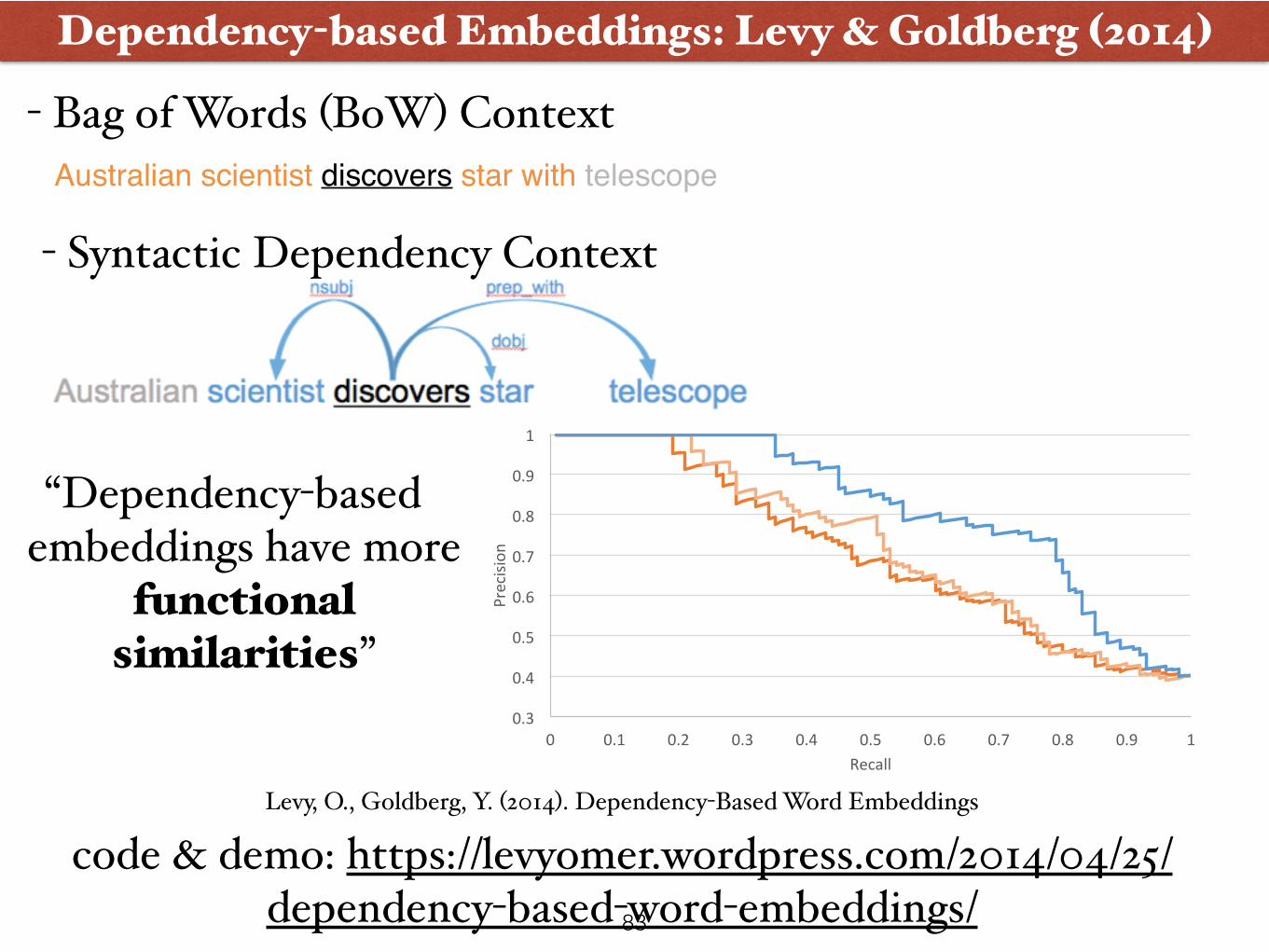
code & info: https://code.google.com/p/word2vec/ Mikolov, T., Yih, W., & Zweig, G. (2013). Linguistic Regularities in Continuous Space Word Representations
Mikolov, T., Le, V. L., Sutskever, I. (2013) . Exploiting Similarities among Languages for Machine Translation79
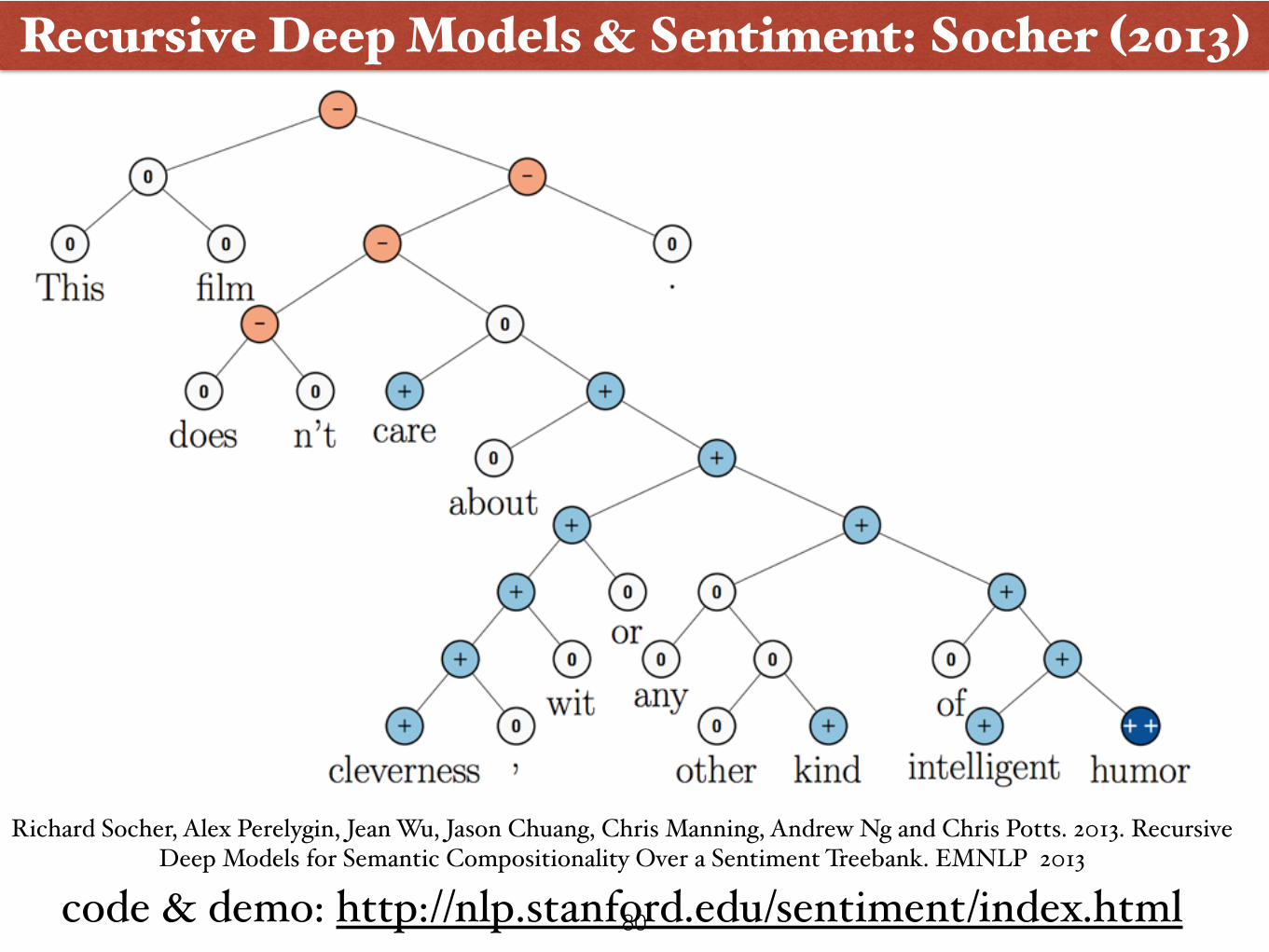
Recursive Deep Models & Sentiment: Socher (2013)
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Chris Manning, Andrew Ng and Chris Potts. 2013. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. EMNLP 2013