97
Deep understanding of structures in the visual world - II Wanli Ouyang (欧阳万里) The University of Sydney

Deep understanding of structures in the visual world - II
Wanli Ouyang (欧阳万里)
The University of Sydney

Outline
2
• Introduction
• Learning Structured
– Output (continued)
– Hidden factors
– Features
• Network design
• Conclusion

Outline
3
• Introduction
• Learning Structured
– Output (continued)
– Hidden factors
– Features
• Network design
• Conclusion

24/4/2018
Object detection
Human pose estimation
Relationship detection
WomanChild Tooth brush Tooth brush
Use UseWatch
Mom and her cute baby are brushing teeth
Region captioning
Person Re-identification
4
Action recognition

Challenges -- person• Intra-class variation
• Color

Challenges -- person• Intra-class variation
• Color
• Occlusion

Challenges -- person• Intra-class variation
• Color
• Occlusion
• Deformation

Outline
8
• Introduction
• Learning Structured
– Output (continued)
– Hidden factors
– Features
• Network design
• Conclusion

Is deep model a black box?
9

殊途同归

Model structures among neurons
h1
x
y
h2
11
Conventional Structured output

Learning structure of output and features for …
Orientation
Lean
Interaction
Distance
M ulti-task R ecurrentN euralN etw ork for Im m ediacy Prediction
X iao C hu W anliO uyang W eiYang X iaogang W angD epartm entofElectronic Engineering,The C hinese U niversity ofH ong K [email protected] [email protected] [email protected]
A bstract
In this paper,w e propose to predict im m ediacy for in-teracting persons from stillim ages. A com plete im m ediacysetincludes interactions,relative distance,body leaning di-rection and standing orientation.These m easuresare foundto be related to the attitude,socialrelationship, socialin-teraction, action, nationality, and religion of the com m u-nicators. 1 A large-scale dataset w ith 10,000 im ages isconstructed, in w hich all the im m ediacy cues and the hu-m an poses are annotated. W e propose a rich setofim m e-diacy representations thathelp to predictim m ediacy fromim perfect1-person and 2-person pose estim ation results.Am ulti-task deep recurrentneuralnetw ork is constructed totake the proposed rich im m ediacy representations asthe in-putand learn the com plex relationship am ong im m ediacypredictions through m ultiple steps ofrefinem ent. The effec-tiveness ofthe proposed approach is proved through exten-sive experim ents on the large-scale dataset.
1.Introduction
The concept of im m ediacy w as first introduced byM ehrabian [18] to rate the nonverbal behaviors that havebeen found to be significant indicators of com m unicators’attitude tow ard addressees. In [18], several typical im -m ediacy cues w ere defined: touching, relative distance,body leaning direction, eye contact and standing orienta-tion (listed in the order of im portance). A com plete setofim m ediacy cues defined in this w ork are show n in Fig. 1.These cues are im portant attributes found to be related tothe inter-person attitude, social relationship, and religionof the com m unicators [17, 36, 12]. Im m ediacy cues re-portthe com m unicators’attitude w hich is usefulin build-ing up socialnetw orks.W ith vastdata available from socialnetw orking sites, connections am ong people can be builtup autom atically by analyzing im m ediacy cues from visualdata. Second, these im m ediacy cues are useful for exist-ing vision tasks,such as hum an pose estim ation [38,32],socialrelationship,socialrole [27],and action recognition
1The dataset can be found at http://www.ee.cuhk.edu.hk/
˜xgwang/projectpage_immediacy.html
(a) Interaction
Shoulder
To
shoulder
Holding-
handsHug
Arm
in
arm
Arm over
the
shoulderHigh five
Examples of immediacy
(e) (f) (g)
(d) Orientation (c) Leaning direction
[-10° 10°] >10°<-10°
(b) Relative distance
Adjacent Far
Holding
from
behind
Figure 1.The tasks ofim m ediacy prediction and three exam ples.D etailed definitions ofim m ediacy cues can be found in Sec.3
[16]. The im m ediacy cue“touch-code”is the sam e as in-teraction recognition and has been recognized by our so-ciety [37,13,23] for a long tim e. H ow ever, a com pletedatasetproviding allthe im m ediacy cues is absent. In ad-dition, there is only little research on im m ediacy analysisfrom the com putervision pointofview .
In orderto predictim m ediacy,itis naturalto use the in-form ation from 1-person pose estim ation [38]and 2-personpose estim ation,w hich w ascalled touch-code in [37].H ow -ever,touch-code and single person pose estim ation are im -perfect. Especially, w hen people have interaction, inter-occlusion, lim b am biguities, and large pose variation in-evitably occur.These cause the difficulty in im m ediacy pre-diction.O n the otherhand,interacting personsprovide extrarepresentations thatm otivate ourw ork.
First, there are extra inform ation sources unexploredw hen persons interact. Since both 1-person or 2-personpose estim ation are im perfect, extra inform ation sources,i.e., overlap of body parts, body location relative to tw opersons’center,and consistency betw een 1-person and 2-person estim ation,are helpfulforim m ediacy prediction asw ellas addressing pose estim ation errors. A s an exam pleforoverlap ofbody parts,w hen allofperson A and person
1
M ulti-task R ecurrentN euralN etw ork for Im m ediacy Prediction
X iao C hu W anliO uyang W eiYang X iaogang W angD epartm entofElectronic Engineering,The C hinese U niversity ofH ong K [email protected] [email protected] [email protected]
A bstract
In this paper,w e propose to predict im m ediacy for in-teracting persons from stillim ages. A com plete im m ediacysetincludes interactions,relative distance,body leaning di-rection and standing orientation.These m easuresare foundto be related to the attitude,socialrelationship,socialin-teraction, action, nationality, and religion of the com m u-nicators. 1 A large-scale dataset w ith 10,000 im ages isconstructed, in w hich allthe im m ediacy cues and the hu-m an poses are annotated. W e propose a rich setofim m e-diacy representations thathelp to predict im m ediacy fromim perfect1-person and 2-person pose estim ation results.Am ulti-task deep recurrentneuralnetw ork is constructed totake the proposed rich im m ediacy representations asthe in-putand learn the com plex relationship am ong im m ediacypredictions through m ultiple steps ofrefinem ent. The effec-tiveness ofthe proposed approach is proved through exten-sive experim ents on the large-scale dataset.
1.Introduction
The concept of im m ediacy w as first introduced byM ehrabian [18] to rate the nonverbal behaviors that havebeen found to be significant indicators of com m unicators’attitude tow ard addressees. In [18], several typical im -m ediacy cues w ere defined: touching, relative distance,body leaning direction, eye contact and standing orienta-tion (listed in the order ofim portance). A com plete setofim m ediacy cues defined in this w ork are show n in Fig. 1.These cues are im portant attributes found to be related tothe inter-person attitude, social relationship, and religionof the com m unicators [17, 36, 12]. Im m ediacy cues re-portthe com m unicators’attitude w hich is usefulin build-ing up socialnetw orks.W ith vastdata available from socialnetw orking sites, connections am ong people can be builtup autom atically by analyzing im m ediacy cues from visualdata. Second, these im m ediacy cues are useful for exist-ing vision tasks,such as hum an pose estim ation [38,32],socialrelationship,socialrole [27],and action recognition
1The dataset can be found at http://www.ee.cuhk.edu.hk/
˜xgwang/projectpage_immediacy.html
(a) Interaction
Shoulder
To
shoulder
Holding-
handsHug
Arm
in
arm
Arm over
the
shoulderHigh five
Examples of immediacy
(e) (f) (g)
(d) Orientation (c) Leaning direction
[-10° 10°] >10°<-10°
(b) Relative distance
Adjacent Far
Holding
from
behind
Figure 1.The tasks ofim m ediacy prediction and three exam ples.D etailed definitions ofim m ediacy cues can be found in Sec.3
[16]. The im m ediacy cue“touch-code”is the sam e as in-teraction recognition and has been recognized by our so-ciety [37,13,23] for a long tim e. H ow ever, a com pletedatasetproviding allthe im m ediacy cues is absent. In ad-dition, there is only little research on im m ediacy analysisfrom the com putervision pointofview .
In orderto predictim m ediacy,itis naturalto use the in-form ation from 1-person pose estim ation [38]and 2-personpose estim ation,w hich w ascalled touch-code in [37].H ow -ever,touch-code and single person pose estim ation are im -perfect. Especially, w hen people have interaction, inter-occlusion, lim b am biguities, and large pose variation in-evitably occur.These cause the difficulty in im m ediacy pre-diction.O n theotherhand,interacting personsprovideextrarepresentations thatm otivate ourw ork.
First, there are extra inform ation sources unexploredw hen persons interact. Since both 1-person or 2-personpose estim ation are im perfect, extra inform ation sources,i.e., overlap of body parts, body location relative to tw opersons’center,and consistency betw een 1-person and 2-person estim ation,are helpfulforim m ediacy prediction asw ellas addressing pose estim ation errors. A s an exam pleforoverlap ofbody parts,w hen allofperson A and person
1
ICCV’15 oral
Body joints
CVPR’14CVPR’16 oral
Multiple immediacy factors
CVPR’17TPAMI’18
Multiple scales
Human pose estimation
Relationship detection Monocular depth estimation

Learning structure of output and features for …
Orientation
Lean
Interaction
Distance
M ulti-task R ecurrentN euralN etw ork for Im m ediacy Prediction
X iao C hu W anliO uyang W eiYang X iaogang W angD epartm entofElectronic Engineering,The C hinese U niversity ofH ong K [email protected] [email protected] [email protected]
A bstract
In this paper,w e propose to predict im m ediacy for in-teracting persons from stillim ages. A com plete im m ediacysetincludes interactions,relative distance,body leaning di-rection and standing orientation.These m easuresare foundto be related to the attitude,socialrelationship, socialin-teraction, action, nationality, and religion of the com m u-nicators. 1 A large-scale dataset w ith 10,000 im ages isconstructed, in w hich all the im m ediacy cues and the hu-m an poses are annotated. W e propose a rich setofim m e-diacy representations thathelp to predictim m ediacy fromim perfect1-person and 2-person pose estim ation results.Am ulti-task deep recurrentneuralnetw ork is constructed totake the proposed rich im m ediacy representations asthe in-putand learn the com plex relationship am ong im m ediacypredictions through m ultiple steps ofrefinem ent. The effec-tiveness ofthe proposed approach is proved through exten-sive experim ents on the large-scale dataset.
1.Introduction
The concept of im m ediacy w as first introduced byM ehrabian [18] to rate the nonverbal behaviors that havebeen found to be significant indicators of com m unicators’attitude tow ard addressees. In [18], several typical im -m ediacy cues w ere defined: touching, relative distance,body leaning direction, eye contact and standing orienta-tion (listed in the order of im portance). A com plete setofim m ediacy cues defined in this w ork are show n in Fig. 1.These cues are im portant attributes found to be related tothe inter-person attitude, social relationship, and religionof the com m unicators [17, 36, 12]. Im m ediacy cues re-portthe com m unicators’attitude w hich is usefulin build-ing up socialnetw orks.W ith vastdata available from socialnetw orking sites, connections am ong people can be builtup autom atically by analyzing im m ediacy cues from visualdata. Second, these im m ediacy cues are useful for exist-ing vision tasks,such as hum an pose estim ation [38,32],socialrelationship,socialrole [27],and action recognition
1The dataset can be found at http://www.ee.cuhk.edu.hk/
˜xgwang/projectpage_immediacy.html
(a) Interaction
Shoulder
To
shoulder
Holding-
handsHug
Arm
in
arm
Arm over
the
shoulderHigh five
Examples of immediacy
(e) (f) (g)
(d) Orientation (c) Leaning direction
[-10° 10°] >10°<-10°
(b) Relative distance
Adjacent Far
Holding
from
behind
Figure 1.The tasks ofim m ediacy prediction and three exam ples.D etailed definitions ofim m ediacy cues can be found in Sec.3
[16]. The im m ediacy cue“touch-code”is the sam e as in-teraction recognition and has been recognized by our so-ciety [37,13,23] for a long tim e. H ow ever, a com pletedatasetproviding allthe im m ediacy cues is absent. In ad-dition, there is only little research on im m ediacy analysisfrom the com putervision pointofview .
In orderto predictim m ediacy,itis naturalto use the in-form ation from 1-person pose estim ation [38]and 2-personpose estim ation,w hich w ascalled touch-code in [37].H ow -ever,touch-code and single person pose estim ation are im -perfect. Especially, w hen people have interaction, inter-occlusion, lim b am biguities, and large pose variation in-evitably occur.These cause the difficulty in im m ediacy pre-diction.O n the otherhand,interacting personsprovide extrarepresentations thatm otivate ourw ork.
First, there are extra inform ation sources unexploredw hen persons interact. Since both 1-person or 2-personpose estim ation are im perfect, extra inform ation sources,i.e., overlap of body parts, body location relative to tw opersons’center,and consistency betw een 1-person and 2-person estim ation,are helpfulforim m ediacy prediction asw ellas addressing pose estim ation errors. A s an exam pleforoverlap ofbody parts,w hen allofperson A and person
1
M ulti-task R ecurrentN euralN etw ork for Im m ediacy Prediction
X iao C hu W anliO uyang W eiYang X iaogang W angD epartm entofElectronic Engineering,The C hinese U niversity ofH ong K [email protected] [email protected] [email protected]
A bstract
In this paper,w e propose to predict im m ediacy for in-teracting persons from stillim ages. A com plete im m ediacysetincludes interactions,relative distance,body leaning di-rection and standing orientation.These m easuresare foundto be related to the attitude,socialrelationship,socialin-teraction, action, nationality, and religion of the com m u-nicators. 1 A large-scale dataset w ith 10,000 im ages isconstructed, in w hich allthe im m ediacy cues and the hu-m an poses are annotated. W e propose a rich setofim m e-diacy representations thathelp to predict im m ediacy fromim perfect1-person and 2-person pose estim ation results.Am ulti-task deep recurrentneuralnetw ork is constructed totake the proposed rich im m ediacy representations asthe in-putand learn the com plex relationship am ong im m ediacypredictions through m ultiple steps ofrefinem ent. The effec-tiveness ofthe proposed approach is proved through exten-sive experim ents on the large-scale dataset.
1.Introduction
The concept of im m ediacy w as first introduced byM ehrabian [18] to rate the nonverbal behaviors that havebeen found to be significant indicators of com m unicators’attitude tow ard addressees. In [18], several typical im -m ediacy cues w ere defined: touching, relative distance,body leaning direction, eye contact and standing orienta-tion (listed in the order ofim portance). A com plete setofim m ediacy cues defined in this w ork are show n in Fig. 1.These cues are im portant attributes found to be related tothe inter-person attitude, social relationship, and religionof the com m unicators [17, 36, 12]. Im m ediacy cues re-portthe com m unicators’attitude w hich is usefulin build-ing up socialnetw orks.W ith vastdata available from socialnetw orking sites, connections am ong people can be builtup autom atically by analyzing im m ediacy cues from visualdata. Second, these im m ediacy cues are useful for exist-ing vision tasks,such as hum an pose estim ation [38,32],socialrelationship,socialrole [27],and action recognition
1The dataset can be found at http://www.ee.cuhk.edu.hk/
˜xgwang/projectpage_immediacy.html
(a) Interaction
Shoulder
To
shoulder
Holding-
handsHug
Arm
in
arm
Arm over
the
shoulderHigh five
Examples of immediacy
(e) (f) (g)
(d) Orientation (c) Leaning direction
[-10° 10°] >10°<-10°
(b) Relative distance
Adjacent Far
Holding
from
behind
Figure 1.The tasks ofim m ediacy prediction and three exam ples.D etailed definitions ofim m ediacy cues can be found in Sec.3
[16]. The im m ediacy cue“touch-code”is the sam e as in-teraction recognition and has been recognized by our so-ciety [37,13,23] for a long tim e. H ow ever, a com pletedatasetproviding allthe im m ediacy cues is absent. In ad-dition, there is only little research on im m ediacy analysisfrom the com putervision pointofview .
In orderto predictim m ediacy,itis naturalto use the in-form ation from 1-person pose estim ation [38]and 2-personpose estim ation,w hich w ascalled touch-code in [37].H ow -ever,touch-code and single person pose estim ation are im -perfect. Especially, w hen people have interaction, inter-occlusion, lim b am biguities, and large pose variation in-evitably occur.These cause the difficulty in im m ediacy pre-diction.O n theotherhand,interacting personsprovideextrarepresentations thatm otivate ourw ork.
First, there are extra inform ation sources unexploredw hen persons interact. Since both 1-person or 2-personpose estim ation are im perfect, extra inform ation sources,i.e., overlap of body parts, body location relative to tw opersons’center,and consistency betw een 1-person and 2-person estim ation,are helpfulforim m ediacy prediction asw ellas addressing pose estim ation errors. A s an exam pleforoverlap ofbody parts,w hen allofperson A and person
1
CVPR’18
Multiple immediacy factors Multiple modalities
Relationship detection Person re-identification
Body joints
CVPR’14CVPR’16 oral
Human pose estimation
ICCV’15 oral

Model structures among neurons
h1
x
y
h2
14
ConventionalStructured hidden
factorStructured output

24/4/2018
Object detectionWomanChild Tooth brush Tooth brush
15

Challenges -- person• Intra-class variation
• Color
• Occlusion
• Deformation
Hidden

17
• N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. CVPR, 2005. (10,000+ citations)
• P. Felzenszwalb, D. McAlester, and D. Ramanan. A Discriminatively Trained, Multiscale, Deformable Part Model. CVPR, 2008. (4000+ citations)
• W. Ouyang and X. Wang. A Discriminative Deep Model for Pedestrian Detection with Occlusion Handling. CVPR, 2012.

18
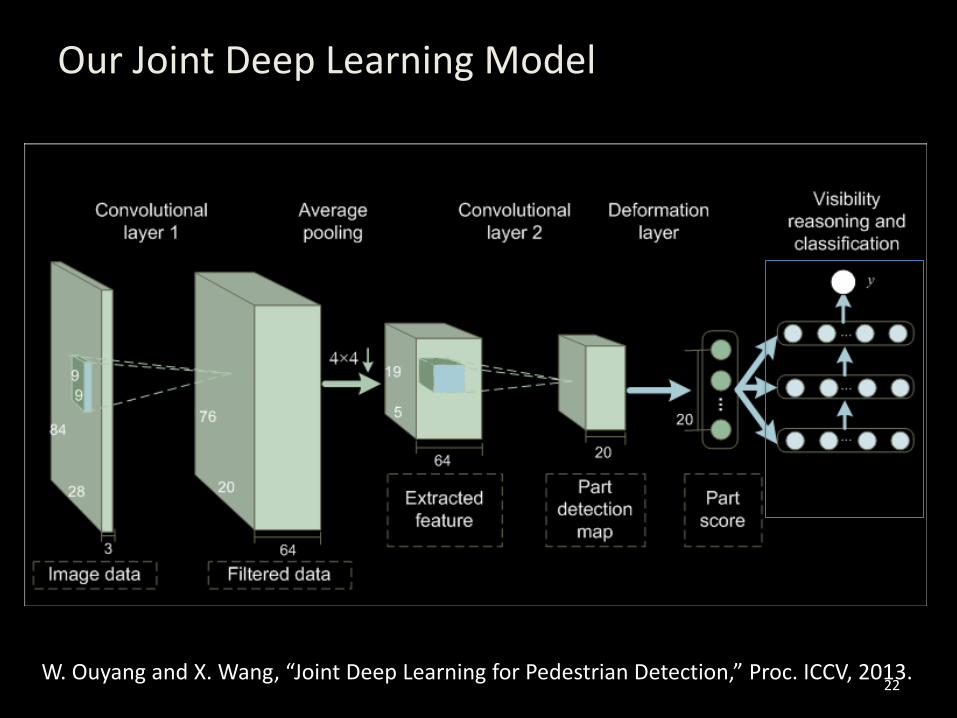
Our Joint Deep Learning Model
W. Ouyang and X. Wang, “Joint Deep Learning for Pedestrian Detection,” Proc. ICCV, 2013.

19
Our Joint Deep Learning Model
W. Ouyang and X. Wang, “Joint Deep Learning for Pedestrian Detection,” Proc. ICCV, 2013.
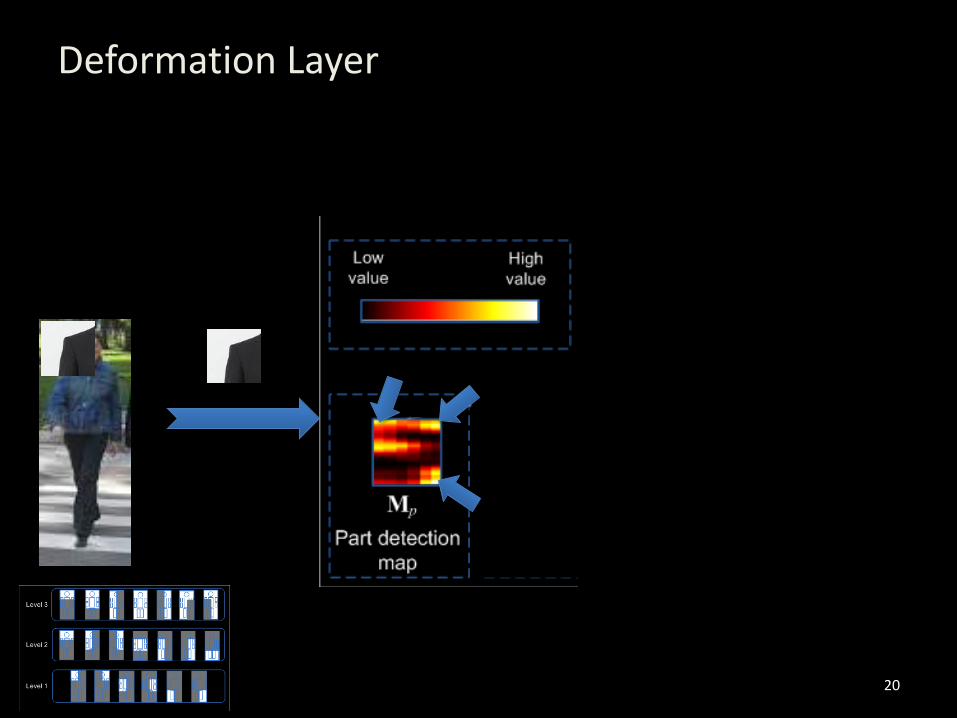
20
Deformation Layer

21
Deformation Layer
22
Our Joint Deep Learning Model
W. Ouyang and X. Wang, “Joint Deep Learning for Pedestrian Detection,” Proc. ICCV, 2013.

23
Visibility Reasoning with Deep Belief Net
Correlates with part detection score
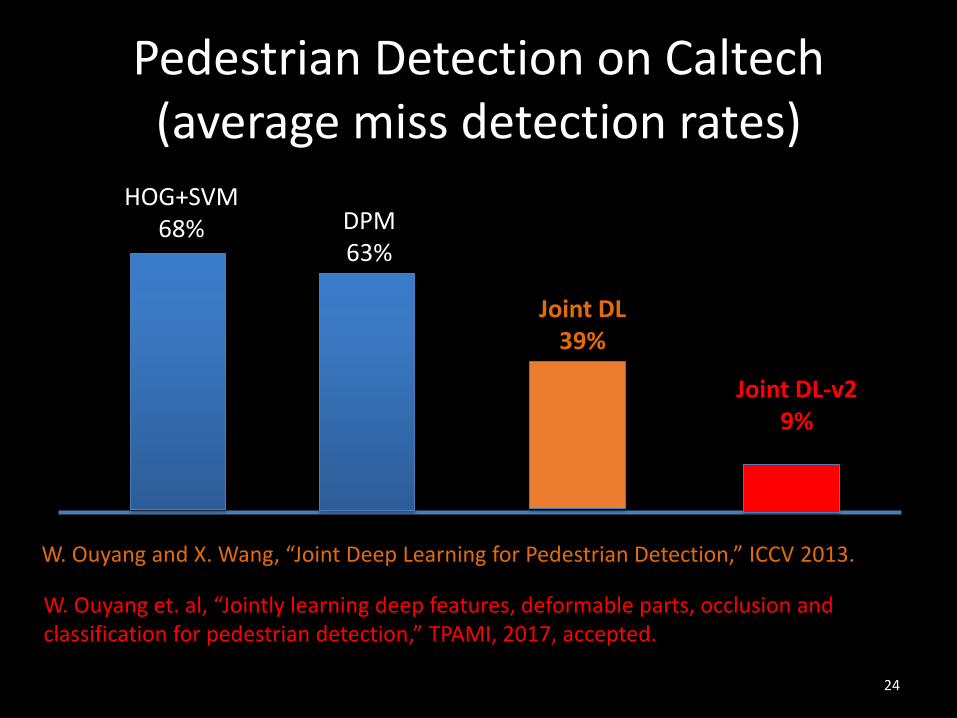
Pedestrian Detection on Caltech (average miss detection rates)
24
HOG+SVM68% DPM
63%
Joint DL39%
W. Ouyang and X. Wang, “Joint Deep Learning for Pedestrian Detection,” ICCV 2013.
Joint DL-v29%
W. Ouyang et. al, “Jointly learning deep features, deformable parts, occlusion and classification for pedestrian detection,” TPAMI, 2017, accepted.

Generalize from single pedestrian to multiple pedestrians
Single pedestrian
Multiple pedestriansIJCV’16
Generic Object detectionTPAMI’17
Deformation
Visibility

Model structures among neurons
h1
x
y
h2
26
ConventionalStructured hidden
factorStructured output

Is deep model a black box?
27
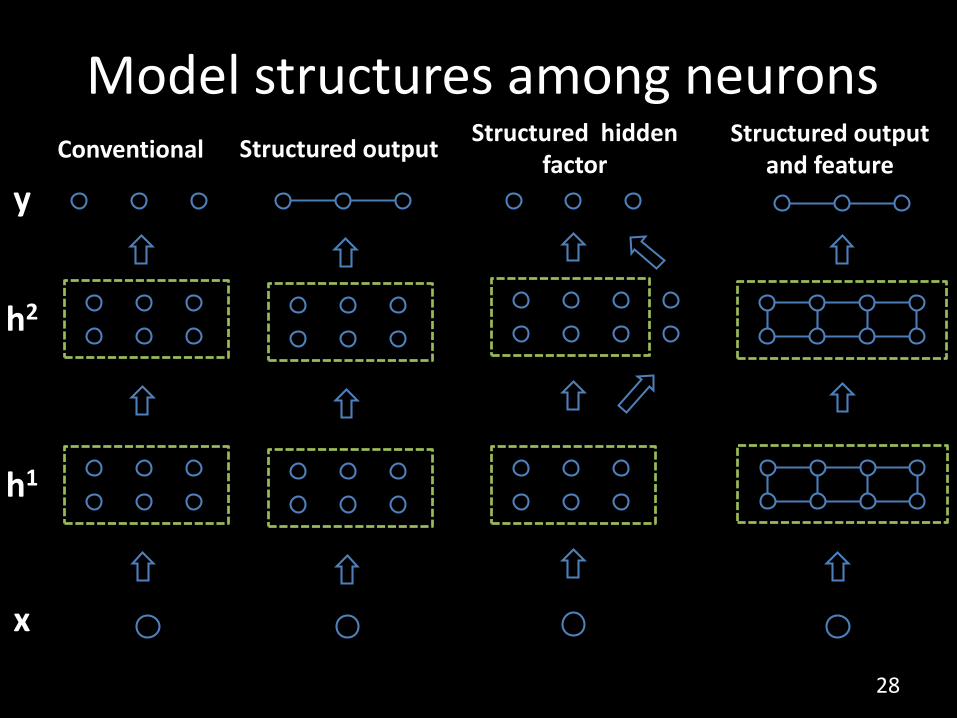
Model structures among neurons
h1
x
y
h2
28
ConventionalStructured output
and featureStructured hidden
factorStructured output

h
x
y
Structure in neurons
• Conventional neural networks
– Neurons in the same layer have no connections
Neurons in brain

24/4/2018
Object detectionWomanChild Tooth brush Tooth brush
30

Message from past ImageNet Challenge
Design a good learning strategy (VGG, BN) or a good branching structure (Inception, ResNet) to make the model deeper
8 8 19 22
152
0
50
100
150
200
AlexNet(ILSVRC 2012)
ZF-Net,Overfeat
(ILSVRC 2013)
VGG (ILSVRC2014)
GoogleNet(ILSVRC 2014)
ResNet(ILSVRC 2015)
Number of layers
31

Message from past ImageNet Challenge
Design a good learning strategy (VGG, BN) or a good branching structure (Inception, ResNet) to make the model deeper

Is deeper the only way to go?

What can our vision researchers’ observation help?

What can our vision researchers’ observation help?
GBD-Net

GBD-Net
Context
What can our vision researchers’ observation help?

Context
Visual context helps to identify objects

38
Visual context helps to identify objects
Context

Motivation
With the deep model, what can we do for context?

Motivation
With the deep model, what can we do for context?
Learning relationship among features of different resolutions and contextual regions.

Motivation
With the deep model, what can we do for context?
Learning relationship among features of different resolutions and contextual regions.
Rabbit ear
Rabbit head

Motivation
With the deep model, what can we do for context?
Learning relationship among features of different resolutions and contextual regions.
Features of different contextual regions validate each other
Rabbit ear
Rabbit head

Motivation
With the deep model, what can we do for context?
Learning relationship among features of different resolutions and contextual regions.
Features of different contextual regions validate each other
Rabbit ear
Rabbit head

Motivation
With the deep model, what can we do for context?
Learning relationship among features of different resolutions and contextual regions.
Features of different contextual regions validate each other
Not always true
Rabbit ear
Rabbit head

Motivation
With the deep model, what can we do for context?
Learning relationship among features of different resolutions and contextual regions.
Features of different contextual regions validate each other
Not always true
Rabbit ear
Rabbit head
Human face
Rabbit ear
Rabbit head

Motivation
With the deep model, what can we do for context?
Learning relationship among features of different resolutions and contextual regions.
Features of different contextual regions validate each other
Control the flow of message passing
Rabbit ear
Rabbit head Rabbit head
Human face
Rabbit ear

Fast R-CNN

Gated bi-directional CNN (GBD-Net)

Gated bi-directional CNN (GBD-Net)

Gated bi-directional CNN (GBD-Net)
Features of different context and resolution

Gated bi-directional CNN (GBD-Net)
Features of different context and resolution

Gated bi-directional CNN (GBD-Net)
Features of different context and resolution

Gated bi-directional CNN (GBD-Net)
Passing messages among these features

Independent features

Passing message in one direction

Passing message in two directions

Passing message with gates
+3.7% mAP on BN-Inception
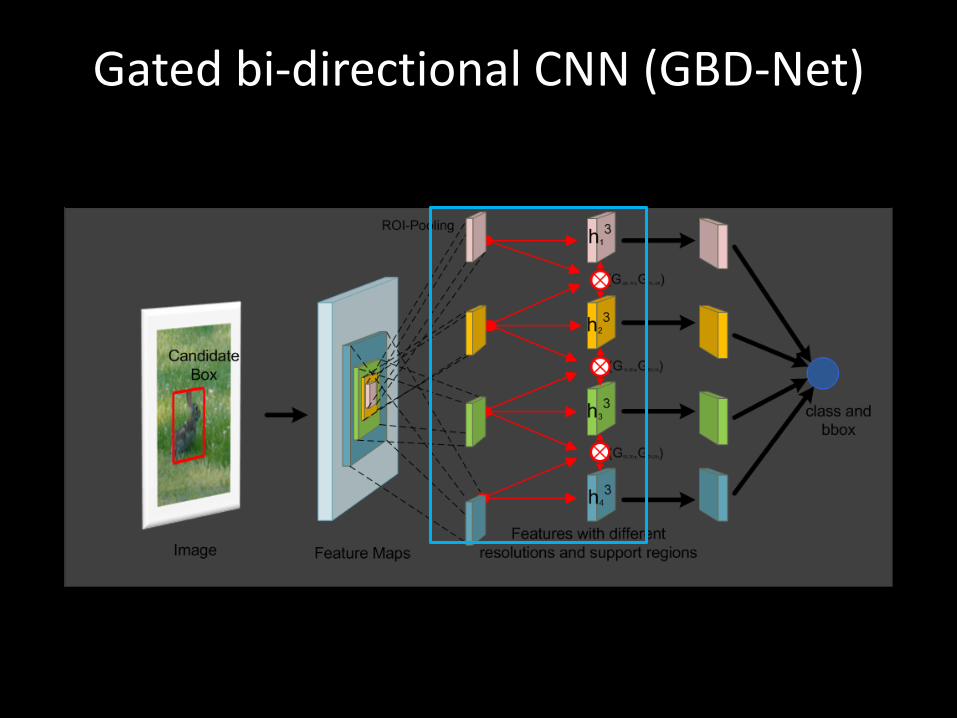
Gated bi-directional CNN (GBD-Net)

Improvement from GBD-net
DataSet ImageNet val2 Pascal VOC 07 COCO (AP) COCO (AP50)
Without GBD 48.4 73.1 24.4 39.3
+ GBD 52.1 77.2 27 45.8
BN-net (BN-Inceptio) as the baseline
+3.7 mAP +4.1 mAP+2.6 AP
+6.5 AP50
0
2
4
6
8
ImageNetval2
Pascal VOC07
COCO (AP) COCO (AP50)

Mean Averaged Precision (mAP)
UvA-Euvision22.581%
ILSVRC 2013ILSVRC 2014
GoogleGoogLeNet
43.9%
DeepID-Net50.3%
CVPR15TPAMI17
W. Ouyang and X. Wang, et al. “DeepID-Net: Deformable Deep Convolutional Neural Networks for Object Detection,” CVPR15, TPAMI17
MSRAResNet62.0%
CVPR’15
GBD-Net66.3%
ECCV16TPAMI17
ILSVRC 2015 ILSVRC 2016
X. Zeng, W. Ouyang, J. Yan, etc, “Crafting gbd-net for object detection,” ECCV16, TPAMI 2017

Brief summary
Features matter
Observations from vision researchers also matter
Use deep model as a tool to model the relationship among features
Gated bi-directional network (GBD-Net)
Pass messages among features with different contextual regions
Code: https://github.com/craftGBD/craftGBDZeng et al. “Crafting GBD-Net for Object Detection,” TPAMI, accepted.
61

Structured features
Model structure among features of
different contextual regions
62
ECCV’16, TPAMI’17

Structured features
Model structure among features of
different contextual regions
different body joints
63
ECCV’16, TPAMI’17
CVPR’ 16

VGG𝑐𝑜𝑛𝑣1~6\{𝑝𝑜𝑜𝑙4,5}
A1
A2A3
A4
A5 A6
A7
A8
A9A10
B1
B2B3
B4
B5 B6
B7
B8
B9B10
Structured Feature Learning
Po
sitiv
e D
ire
ctio
n
Re
ve
rt D
ire
ctio
n

Structured features
Model structure among features of
different contextual regions
different body joints
different semantic meanings
65
ECCV’16, TPAMI’17 CVPR’ 16
ICCV’17
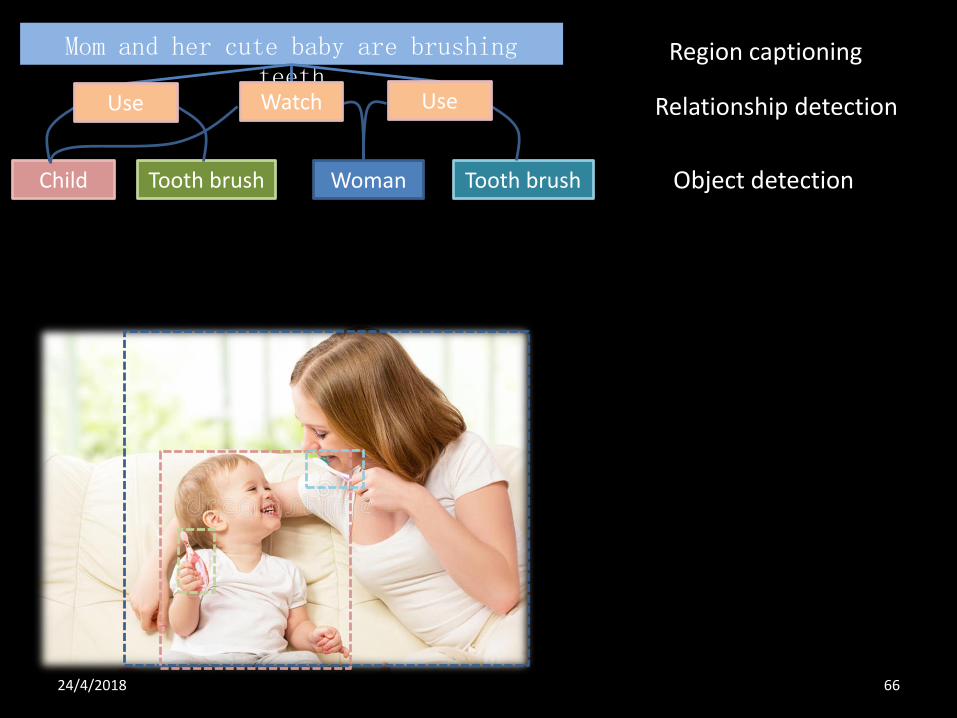
24/4/2018
Object detection
Relationship detection
WomanChild Tooth brush Tooth brush
Mom and her cute baby are brushing teeth
Region captioning
66
Use UseWatch

Structured features
Model structure among features of
different contextual regions
different body joints
different semantic meanings
67
ECCV’16, TPAMI’17 CVPR’ 16
ICCV’17

Motivation
• Debate
– Lack of "general theory"
• Solution
– Probabilistic model, conditional random field, is used as the theory
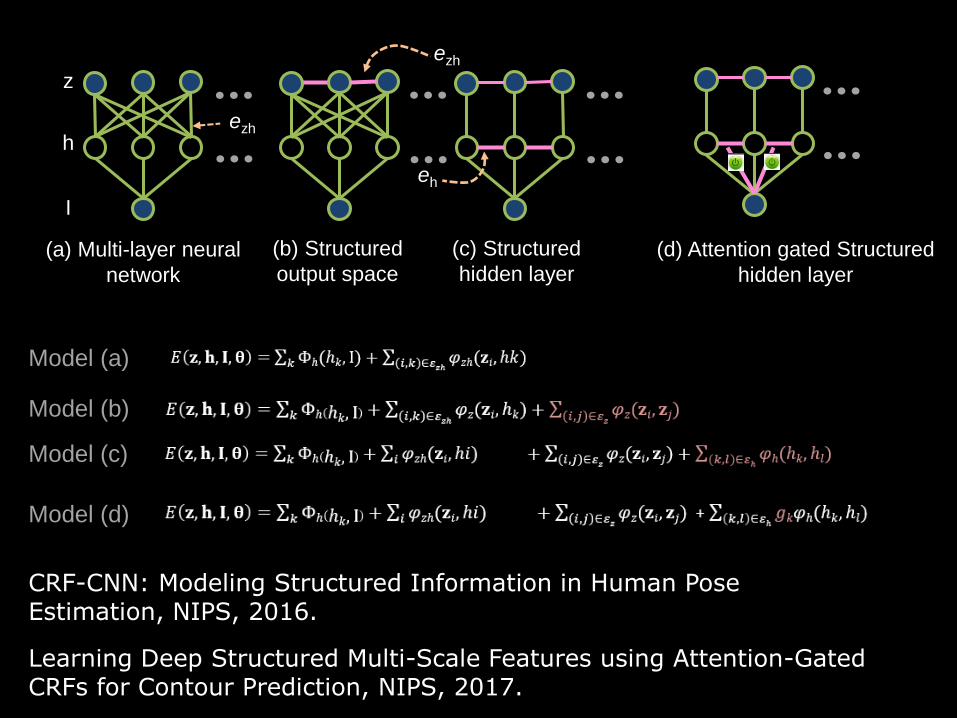
…
…
…
…
…
…
(a) Multi-layer neural
network
(b) Structured
output space
(c) Structured
hidden layer
I
h
z
ezh
ezh
eh
…
…
(d) Attention gated Structured
hidden layer
Learning Deep Structured Multi-Scale Features using Attention-Gated CRFs for Contour Prediction, NIPS, 2017.
Model (a)
Model (b)
Model (c)
Model (d)
CRF-CNN: Modeling Structured Information in Human Pose Estimation, NIPS, 2016.

Message passing
• Belief propagation

Model structures among neurons
h1
x
y
h2
71
ConventionalStructured hidden
factorStructured output
Structured output and feature

Outline
72
• Introduction
• Learning
– Structured output
– Structured Hidden factors
– Structure of features
• Network design
• Conclusion

Evolution of Network Architectures
2012 2014 2015 2016
AlexNet GoogLeNet ResNet IR-v2

PolyNet: Best Performing Network
CVPR 2017
Input
ReLU
+
Output
Inception𝐹
Inception𝐹
Input
ReLU
+
Output
Inception𝐹
Inception𝐺
Input
ReLU
+
Output
Inception𝐹
Inception𝐺
PolyInception Family
A B C
PolyNet
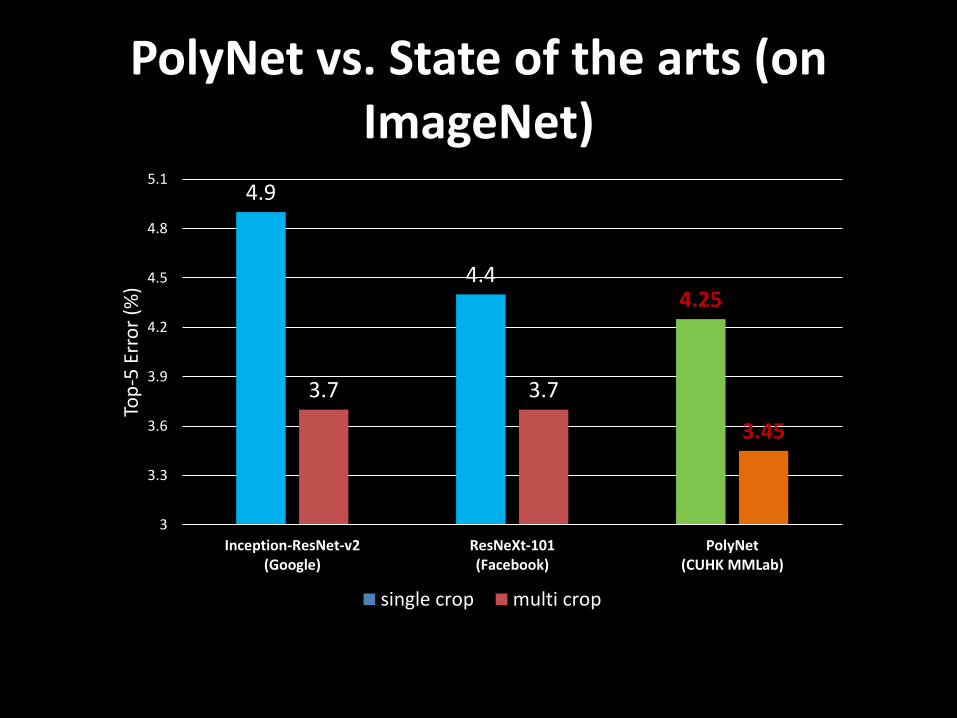
PolyNet vs. State of the arts (on ImageNet)
4.9
4.44.25
3.7 3.7
3.45
3
3.3
3.6
3.9
4.2
4.5
4.8
5.1
Inception-ResNet-v2(Google)
ResNeXt-101(Facebook)
PolyNet(CUHK MMLab)
Top
-5 E
rro
r (%
)
single crop multi crop

Feature Pyramids
• Motivation
– Local visual patterns of different sizes
– We need diversified features for representing them
[1] Wei Yang , et al. Learning Feature Pyramids for Human Pose Estimation, ICCV 2017.

Residual Block Inception-Residual Block
1x1 conv
3x3 conv
1x1 conv
1x1 conv
1x1 conv
…
Up sample
Up sample
Down sample
Down sample
Feature pyramid module [1]
x(l+1)
x(l)
[1] Wei Yang , et al. Learning Feature Pyramids for Human Pose Estimation, ICCV 2017.
How to design deep model for visual patterns with different sizes?
3x3 3x3
Diversified neurons with different receptive fields

Inception-Residual Block
1x1 conv
3x3 conv
1x1 conv
1x1 conv
1x1 conv
…
Up sample
Up sample
Down sample
Down sample
Feature pyramid module [1]
x(l+1)
x(l)
[1] Wei Yang , et al. Learning Feature Pyramids for Human Pose Estimation, ICCV 2017.
How to initialize multi-branch CNN?
3x3 3x3
Diversified neurons with different receptive fields
Poly-Net
Experimental results
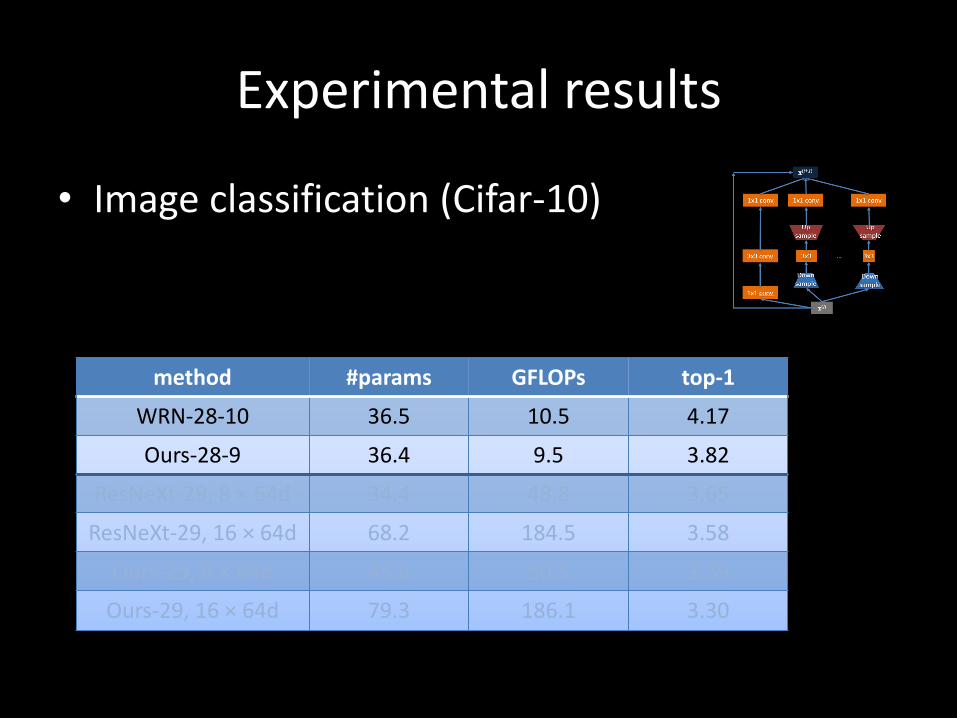
• Image classification (Cifar-10)
method #params GFLOPs top-1
WRN-28-10 36.5 10.5 4.17
Ours-28-9 36.4 9.5 3.82
ResNeXt-29, 8 × 64d 34.4 48.8 3.65
ResNeXt-29, 16 × 64d 68.2 184.5 3.58
Ours-29, 8 × 64d 45.6 50.5 3.39
Ours-29, 16 × 64d 79.3 186.1 3.30

Experimental results
• Image classification (Cifar-10)
method #params GFLOPs top-1
WRN-28-10 36.5 10.5 4.17
Ours-28-9 36.4 9.5 3.82
ResNeXt-29, 8 × 64d 34.4 48.8 3.65
ResNeXt-29, 16 × 64d 68.2 184.5 3.58
Ours-29, 8 × 64d 45.6 50.5 3.39
Ours-29, 16 × 64d 79.3 186.1 3.30
Experimental results
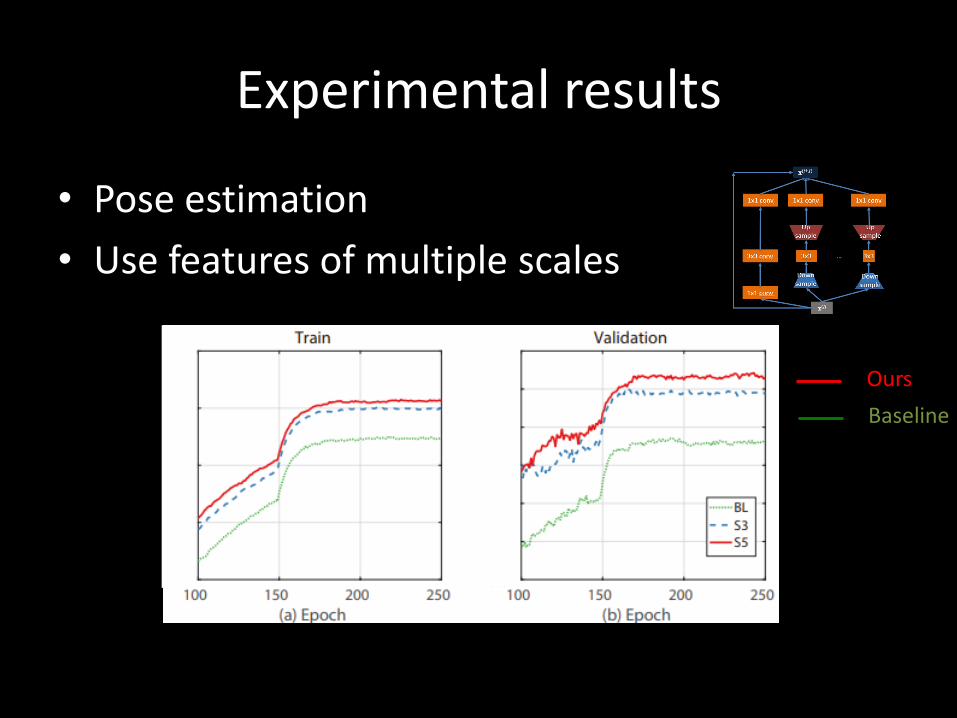
• Pose estimation
• Use features of multiple scales
Ours
Baseline

Experimental results
• Pose estimation
• Initialize multi-branch CNN
Ours
Baseline

Action Recognition
• Recognize action from videos

Optical flow guided feature
−

Optical flow guided feature
{vx , vy} = optical flow
Coefficient for optical flow:
Optical flow:
Intuitive Inspiration

Optical flow guided feature
Feature flow:
{ } = feature flow
−

Optical Flow Guided Feature (OFF): Experimental results
1. OFF with only RGB inputs is comparable with the other state-of-the-art methods using optical flow as input.
0 50 100 150 200 250
RGB + Optical flow + I3D
RGB + OFF
RGB + OFF + Optical Flow
FPS
92.0 92.5 93.0 93.5 94.0 94.5 95.0 95.5 96.0
RGB + Optical flow + I3D
RGB + OFF
RGB + OFF + Optical Flow
Accuracy (%)

Take home message
88
• Structured deep learning is effective for multiple vision tasks
• Structural information originates from our observation
• Model structures in both output and intermediate neural layers
• End-to-end joint training bridges the gap between structure modeling and feature learning

Wider Person Challenge (ECCV 2018)
• Face Detection
www.wider-challenge.org

Wider Person Challenge (ECCV 2018)
• Face Detection
• Pedestrian Detection
www.wider-challenge.org

Wider Person Challenge (ECCV 2018)
• Face Detection
• Pedestrian Detection
• Person Search
www.wider-challenge.org

We are hiring
• Multimedia lab
– At Hong Kong, Singapore, Sydney
– PhD, CSC, Intern, Postdoc
欧阳万里@悉尼大学
吕健勤@南洋理工
汤晓鸥 王晓刚 林达华 李鸿升
@香港中文大学

Action recognition

Input image
Feature maps for downward lower arm
ℎ𝑚
Feature maps for elbow
𝑒𝑛
⨂
Learned kernel
Shifted feature maps
⨁
Updated feature maps for elbow
94

95

96

97
















