DELIVERABLE This project has received financial support from the European Union Horizon 2020 Programme under grant agreement no. 688203. D4.4 Framework for Knowledge Extraction from IoT Data Sources Project Acronym: bIoTope Project title: Building an IoT Open Innovation Ecosystem for Connected Smart Objects Grant Agreement No. 688203 Website: www.bIoTope-project.org Version: 1.0 Date: 2017-06-30 Responsible Partner: EPFL Editor: Prodromos Kolyvakis Contributing Partners: Fraunhofer, BIBA, CSIRO, AALTO:CS, eccenca and Enervent Dissemination Level: Public X Confidential – only consortium members and European Commission Services Ref. Ares(2017)3188041 - 26/06/2017
Transcript
DELIVERABLE
This project has received financial support from the European Union Horizon 2020 Programme under grant agreement no. 688203.
D4.4 Framework for Knowledge Extraction from
IoT Data Sources
Project Acronym: bIoTope
Project title: Building an IoT Open Innovation Ecosystem for Connected Smart Objects
Grant Agreement No. 688203
Website: www.bIoTope-project.org
Version: 1.0
Date: 2017-06-30
Responsible Partner: EPFL
Editor: Prodromos Kolyvakis
Contributing Partners: Fraunhofer, BIBA, CSIRO, AALTO:CS, eccenca and Enervent
Dissemination Level: Public X
Confidential – only consortium members and European Commission Services
Ref. Ares(2017)3188041 - 26/06/2017
D4.4 Framework for Knowledge Extraction from IoT Data Sources
0.9a 16/06/2016 Robert Hellbach BIBA Whole manuscript’s review & revision
0.9b 20/06/2016 Prodromos Kolyvakis
EPFL Changes based on the received
feedback
1.0 20/06/2016 Prodromos Kolyvakis
EPFL Final Version
Every effort has been made to ensure that all statements and information contained herein are accurate, however the bIoTope Project Partners accept no liability for any error or omission in the same.
D4.4 Framework for Knowledge Extraction from IoT Data Sources
The bIoTope project lays the foundation for creating open innovation ecosystems supporting the Internet of Things (IoT) by providing a platform that enables companies to easily create new IoT systems and to rapidly harness available information using advanced Systems-of-Systems (SoS) capabilities for connected smart objects and easily creating innovative business processes. The main purpose of this deliverable is to propose an architecture and implement a framework that is capable to let the users to extract valuable knowledge out of IoT data sources and thus permitting the user to gain insight into the interactions of various phenomena of the everyday life. Toward this direction, a plethora of knowledge extraction and data fusion mechanisms are presented and implemented inside the Knowledge as a Service (KnaaS) framework. In order to measure the effectiveness of the proposed conceptual framework as well as the prototype implementation of it various scenarios of the Lyon’s Heat Wave Mitigation use case are examined and concrete implemented solutions are provided. More specifically, the studied scenarios show how the data fusion and the knowledge discovery capabilities can be used to inform the citizens of Urban Community of Lyon about the local heat conditions of their region and help the citizens ventilate their homes accordingly. In addition, it is demonstrated how a service can be set up through the KnaaS framework that enables to establish the correlation between traffic and temperature data. It should be highlighted that the Lyon’s Heat Wave Mitigation Pilot use case was chosen as it was considered the most representative as far as the knowledge extraction process is concerned. However, the work presented in this deliverable is by no means specific to this use case. The deliverable takes into account use cases and interaction scenarios defined in Deliverable D2.1 as well as the Conceptual Architecture of the bIoTope Knowledge Framework introduced in Deliverable D4.2, and shows how the proposed approach supports them. From a technology perspective, the contributions of this deliverable are in accordance with the activities of WP5, and the work we report in this deliverable has been closely coordinated with D5.4 (led by Fraunhofer). Last but not least, special consideration was given so as the Knowledge as a Service framework presented in this deliverable to provide a concrete integration of the O-MI/O-DF RDF Integration Server (OORI) Server introduced in D5.2 with the aim to (a) exploit the advanced querying capabilities offered by it inside the KnaaS framework and (b) to facilitate the interaction of User Interaction (UI) as a Service and Knowledge as a Service towards the creation of a sustainable bIoTope ecosystem.
D4.4 Framework for Knowledge Extraction from IoT Data Sources
This deliverable illustrates some of the core features of the prototype reference implementation of Knowledge
Extraction Framework from IoT data sources, which enables the efficient knowledge discovery in the bIoTope
ecosystem through a plethora of different extraction and fusion algorithms. The Knowledge Extraction
Framework consists the key technology enabler of KnaaS, and from a practical perspective it could be seen as
the key realization component of KnaaS. From a theoretical perspective, the KnaaS framework, however, is
more general as it defines also the key requirements that any possible third-party service providers, who are
willing to provide a domain-specific KnaaS services and join bIoTope ecosystems should confront with1.
In order to understand the key challenges of the bIoTope’s Knowledge Extraction Framework as well as the
design choices, this document deals with the following questions:
How the knowledge extraction can be formally defined?
Which are the primary functions of a Knowledge Extraction Framework so as to play such a role?
Can the reasoning mechanisms offered by the Knowledge Extraction Framework be exhaustive?
Which types of interfacing and interaction mechanisms should be implemented between the
Knowledge as a Service framework and the other bIoTope components?
1.2. Audience
The target audience of the deliverable includes groups within and outside the consortium, in particular:
Researchers, developers and integrators of the bIoTope consortium: This deliverable illustrates important aspects of the bIoTope context service formulation and delivery and will therefore serve as valuable input for stakeholders within the bIoTope consortium, notably stakeholders that work on the design of the bIoTope infrastructure and/or its implementation in the scope of the bIoTope open source project.
Researchers within other IERC and IoT EPI projects: The deliverable illustrates some of the core implementation concepts of bIoTope and will therefore be of interest to researchers in other IERC and IoT- European Platforms Initiative (IoT-EPI) projects, notably researchers working on projects that interact closely with bIoTope.
Researchers working on IoT: The deliverable will be also of interest to broader groups of IoT researchers, since it provides new insights into IoT open innovation ecosystem (e.g., sensors / cloud computing) integration. As a public document, the deliverable will be accessible to such groups.
Open source community: In the medium term, bIoTope intends to build an open source community based on the bIoTope IoT platform ecosystem. This deliverable may serve as a guide to some of the introductory, yet important topics and functionalities of bIoTope.
1.3. Content of this Document
This deliverable reports our work on the implementation of the core knowledge extraction and data fusion
mechanisms of the Knowledge Extraction Framework paving the way to the bIoTope’s Knowledge as a Service
(Knaas) Framework. After reporting the state-of-the-art of knowledge extraction in IoT, this report presents
the key features of the knowledge extraction functionalities, while illustrating the interaction between the
1 For further information, please refer to chapter 3.
D4.4 Framework for Knowledge Extraction from IoT Data Sources
that had extra symptoms not exhibited by the patient. This step, corresponding to the notion of knowledge
derived from information [8]. Although, the treatment appeared in [8], [9] defines a lot of additional axioms
that information function should fulfill like secondary reflexivity, transitivity, etc., we have chosen to omit
them for the sake of simplicity.
Based on the above definitions, we will proceed in defining what the knowledge is. Let 𝛫: 𝛺 → 2𝛺 be the
knowledge function. 𝐾(𝜔) is interpreted as the set of states that, based on what someone knows, the
individual cannot rule out when the state is ω. We should emphasize on the fact that we did not impose any
additional requirements on the steps in reasoning, deduction, induction, and abduction (for further
information please see section 2.4). We impose only the following requirements [8]:
1. Knowledge should be based on information received. 2. Knowledge should reflect reasoning about the information. 3. Knowledge should be derived exclusively from the available information.
Based on the above definition and requirements, we have proceeded in illustrating the key concepts of
Bonanno’s model of how information and knowledge can be defined. Of course, we did not aim at a complete
presentation of Bonanno’s theory. For a strict and formal definition of information and knowledge, which is
confronted with the above statements, please refer to [8], [9]
2.3. Multi-sensor Data fusion and the JDL/DFIG model
“By 2020, wirelessly networked sensors in everything we own will form a new Web. But it will only be of value
if the “terabyte torrent” of data it generates can be collected, analysed and interpreted” [11]. IoT would
produce substantial amount of data [12] that are less useful unless we are able to derive knowledge using
them. Data fusion is a data processing technique that associates, combines, aggregates, and integrates data
from different sources. It helps to build knowledge about certain events and environments, which is not
possible by using individual sensors separately. Data fusion also helps to build a context-awareness model that
helps to understand situational context [6]. The boundary between sensor fusion and sensor integration is
quite fuzzy and the terms are used interchangeably sometimes. Joshi and Sanderson describe multi-sensor
fusion as part of the multi-sensor integration process [13]. This process refers to the synergistic use of multiple
sensors to improve operation of the system as a whole and includes sensor planning and sensor architecture.
Data fusion in the IoT environment consists one of the most important challenges that need to be addressed
to develop innovative services. In particular, in smart cities applications, when 50 to 100 billion devices start
sensing [14], it would be essential to fuse, and reason about the data automatically and intelligently. A recent
work from a group of researchers from MIT [15] demonstrate the potential of fusing data from disparate data
sources in smart city to understand a city’s attractiveness. The work focuses on cities in Spain and shows how
the fusion of big data sets can provide insights into the way people visit cities. Such a correlation of data from
a variety of data sources play a vital role in delivering services successfully in smart cities of the future. Fusion
is a broad term that can be interpreted in many ways. Hall and Llinas [16] have defined the sensor data fusion
as a method of combining sensor data from multiple sensors to produce more accurate, more complete, and
more dependable information that could not be possible to achieve through a single sensor. Nakamura et al.
[17] have defined data fusion based on three key operations: complementary, redundant, and cooperative.
Complementary means putting bits and pieces of a large picture together. A single sensor cannot say
much about the environment as it would be focused on measuring a single factor such as temperature.
However, when we have data sensed through a number of different sensors, we can understand the
environment in a much better way.
D4.4 Framework for Knowledge Extraction from IoT Data Sources
Estimation and prediction of signal/object observable states on the basis of pixel/signal level data association and characterization.
Level 1:
Object Assessment
Estimation and prediction of entity states on the basis of observation-to-track association, continuous state estimation (e.g. kinematics) and discrete state estimation (e.g. target type and ID).
Level 2:
Situation Assessment
Estimation and prediction of relations among entities, to include force structure and cross force relations, communications and perceptual influences, physical context, etc.
Level 3:
Impact Assessment
Estimation and prediction of effects on situations of planned or estimated/predicted actions by the participants; to include interactions between action plans of multiple players (e.g. assessing susceptibilities and vulnerabilities to estimated/predicted threat actions given one’s own planned actions).
Level 4:
Process Refinement
Adaptive data acquisition and processing to support mission objectives.
Level 5:
User Refinement
Adaptive determination of who queries information and who has access to
information (e.g. information operations) and adaptive data retrieved and
displayed to support cognitive decision making and actions (e.g. human computer
interface) [22].
Although the JDL Model (Level 1–4) is still in use today, it is often criticized for its implication that the levels
necessarily happen in order and also for its lack of adequate representation of the potential for a human-in-
the-loop [23]. The DFIG model (Level 0–5) explored the implications of situation awareness, user refinement,
and mission management [24]. Despite these shortcomings, the JDL/DFIG models are useful for visualizing the
data fusion process, facilitating discussion and common understanding [25], and important for systems-level
information fusion design [24].
2.4. Knowledge Extraction
Knowledge extraction – also known as Knowledge Discovery and Data Mining (KDD) – concerns the creation
of knowledge out of information coming from structured and unstructured data sources. Examples of
structured sources include relational databases, NoSQL, or XML format data, whereas unstructured sources
can include text data or documents and images, which are largely accessible via the Web. It is an
interdisciplinary area focusing upon methodologies for extracting useful knowledge from data. The ongoing
rapid growth of online data due to the Internet and the widespread use of databases have created an immense
need for KDD methodologies. The challenge of extracting knowledge from data draws upon research in
statistics, databases, pattern recognition, machine learning, data visualization, optimization, and high-
performance computing, to deliver advanced business intelligence and web discovery solutions. In bIoTope,
ecosystem applications will be accessed through O-MI/O-DF compatible wrappers2. Hence, this approach
facilitates the exchange of information and permits the knowledge extraction process to be performed in a
uniform manner. However, the knowledge extraction remains a key challenge as it requires a bunch of
different advanced techniques to be performed upon the data so as to gain valuable insight into the data. Data
Fusion, which is a very important aspect of Knowledge Extraction, is a bunch of data processing techniques
that permits the association, combination, aggregation, and integration of data coming from different and
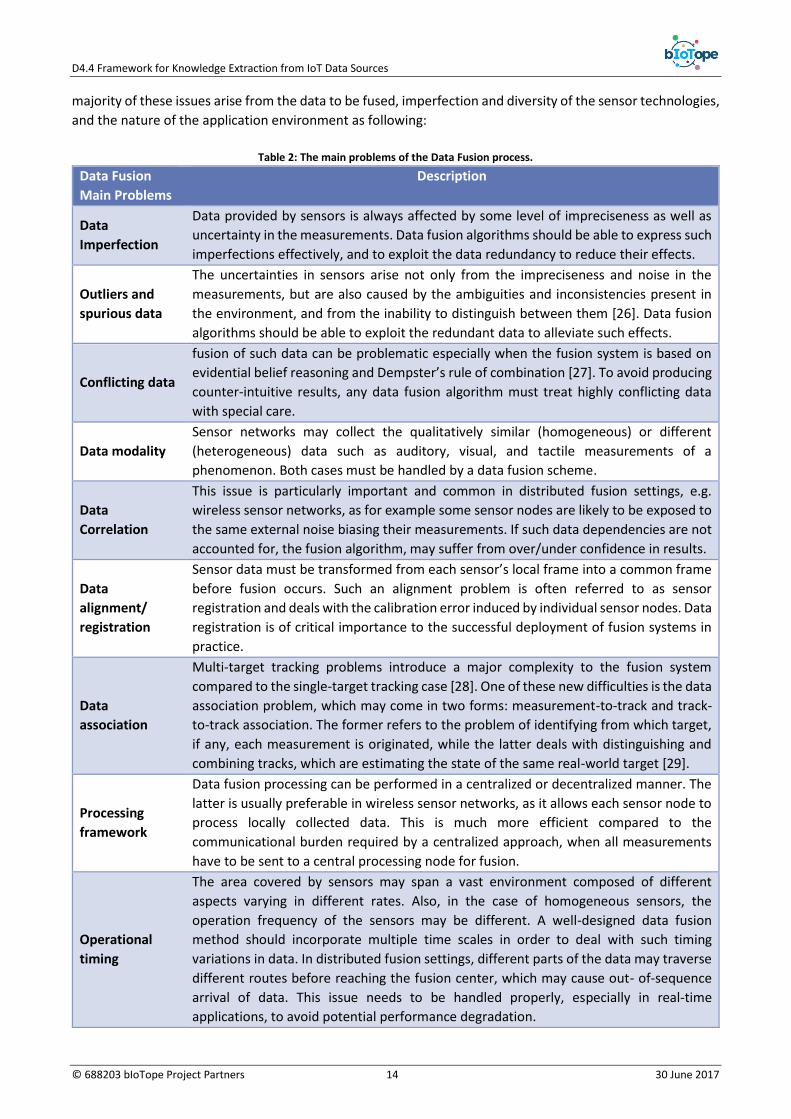
heterogeneous data sources. There are a number of issues that make data fusion a challenging task. The
2 For further information, please refer to the section 2.3 in Deliverable D4.2.
D4.4 Framework for Knowledge Extraction from IoT Data Sources
2. The availability of annotating heterogeneous data for the purpose of being integrated and understood
in an inference engine, e.g., probabilistic, first order logic reasoning, etc.
3. The capacity of inferring new information from data, and managing the inferred knowledge.
4. The possibility of annotating relevantly the response of knowledge services for the purpose of posting
the answer on user devices or activating operations as well as republishing it.
Thus, the KnaaS will offer to possibility to an agent, either user or a software program, to gather relevant data,
to further annotate throughout the intermediate steps the heterogeneous data, inferring new information
out of the incoming information and markup relevantly the response of knowledge services. We would like to
highlight that as O-DF will be the basic data format to exchange information among the bIoTope ecosystem, a
lot of consideration is given into integrating the semantic annotation into O-DF messages. For that reason, we
have mentioned previously to further annotate the heterogeneous data coming to the KnaaS7. Last but not
least, the second requirement is not restrictive as far as the reasoning techniques are concerned. Thus, the
inference capabilities of bIoTope’s KnaaS do not aim to be exhaustive. It is clear that if a new platform, which
offers ‘Knowledge as a Service’ capabilities enters the bIoTope ecosystem will probably provide similar or
complementary inference capabilities. This is in accordance with the overall objective of bIoTope, which is to
create a system of systems where information from cross domain platforms, devices and other information
sources can be accessed when, and as needed using standardized open APIs.
The above-mentioned functional building blocks are sequentially arranged on Figure 5 respecting the order of
processing.
3.1. Knowledge Extraction Architecture in bIoTope KnaaS framework
We provide a prototype implementation that has some knowledge fusion and inference capabilities, using the
KnaaS conceptual architecture presented in Figure 4. To be in accordance with both the ‘Everything as a
Service’ principles as well as the bIoTope’s open APIs requirement we have a chosen a service-based approach,
i.e, a Knowledge Service Request will be sent to KnaaS and the communication will be achieved through O-
MI/O-DF.
Figure 68 provides an overview of the components that KnaaS offers (indicated by the dashed green line) and
their interfaces. Inside the KnaaS, different knowledge extraction mechanisms are provided in order to fuse
and/or reason upon the available information. The KnaaS consists of a visual programming interface in which
different knowledge extraction algorithms can be deployed through a drag-and-drop mechanism. At the same
time, the KnaaS framework permits the direct implementation of advanced knowledge extraction methods,
7 For further information, please refer to the 2.3 section in Deliverable D4.2. 8 For the creation of Figure 6 icons from www.flaticon.com and the Linking Open Data cloud diagram 2017 [54] were used.
Knowledge
inferencing
Data from
context, big
data, other
sources
Semantic
annotation
Response
markup
Figure 5: Key processing blocks required in knowledge framework and knowledge processing
the bIoTope Knowledge Framework (Figure 4) as well as with the four requirements provided in
Section 3.9
3.2. Integration Workflow with Existing bIoTope Components
Figure 7: Example workflow for KnaaS integration with bIoTope.
Figure 7 describes the systems involved in our proposed approach and the information flow between them.
On the left hand side of the figure, the IoT Environment of a user, exemplarily called “Jeremy”, is illustrated
by a dashed-line circulated area. It consists of an O-MI node and the user itself, interacting with another
system, the IoTBnB platform. This platform enables to index and expose the IoT data/service description so as
the IoT stakeholders can easily find IoT data/services. The systems within the dashed-lined grey areas already
exist and numerous instances are deployed on the Web. Our contribution in this deliverable, the Knowledge
as a Service – KnaaS– is outlined on the right hand side of Figure 7 using the green dashed line.
A typical workflow of KnaaS integrated in the bIoTope ecosystem could look as follows:
1. Jeremy decides to expose IoT data/service through an O-MI node/server. To increase the visibility of his data/service (possibly based on financial motives), he registers his node on the IoTBnB marketplace.
2. As Jeremy wants also to publish/expose and potentially sell the results of more advanced data analysis based on his own data, he purchases — maybe for free, through the IoTBnB marketplace — the access to the KnaaS component.
3. To benefit from this service, he needs to provide some information to the KnaaS such as his O-MI node URL, the associated infoItems on which he wants a knowledge extraction, data fusion, etc.
9 Later references will be provided in the rest of the Section to that artificial scenario, for that reason we will refer to this
as AUCS (Artificial Use Case Scenario).
D4.4 Framework for Knowledge Extraction from IoT Data Sources
4. Based on this information, Jeremy chooses the available knowledge fusion and knowledge reasoning black boxes that are provided and combines them in an easy, visual and as far as possible without programming way. When this procedure ends the knowledge Extraction process (which has been just created) can be started.
5. The KnaaS component sends the results as an O-MI/O-DF message (either a write request if the Jeremy enables the KnaaS to do that, or as a simple O-MI response that Jeremy would need to handle).
3.3. Knowledge Extraction Implementation
As it was described in great detail in section 2.4 the art of knowledge extraction is more about choosing among
a set of appropriate fusing tools rather than choosing one to solve each specific task. For that reason, it is
crucial to provide the end user with a great variety of knowledge extraction algorithms in order to permit the
production of new information out of the already available data sources. Moreover, IoT asks for simplicity as
well as ease of usage.
Among one of the best practices in IoT today is Node-RED. Node-RED is a visual tool for wiring the Internet of
Things, but it can also be used for other types of applications to quickly assemble flows of services. The reason
why ‘Node’ is in the name is because the tool is implemented as Node application but from a consumer point
of view that’s really only an internal implementation detail. Node-RED is available as open source and has
been implemented by the IBM Emerging Technology organization. However, even Node-RED is quite simplistic
and permits a bunch of different functionalities, the decision to be built upon the Node server adds the
restriction of the wiring services to be programmed via the JavaScript languages with has a lot of limitations
regarding the available knowledge extraction libraries. On the other hand, there is a vast increase in the
knowledge extraction frameworks which offer an API for the Python language or they are written in the Python
language, i.e., [47]–[52]. Based on the conclusions of section 2.4 a special consideration should be given in
order the KnaaS to be easily extendible and adaptable. For that reason, there should be an easy mechanism
to further extend and add all the functionalities that these libraries provide.
Leveraging both advantages that Node-RED offers with those of well-known inference libraries was the
architectural decision that we have made. Toward that direction, we have integrated a python functionality
on Node-RED which permits the integration of many Knowledge Extraction Frameworks. This python addition
makes easy the extension of KnaaS with new fusing and reasoning functionalities.
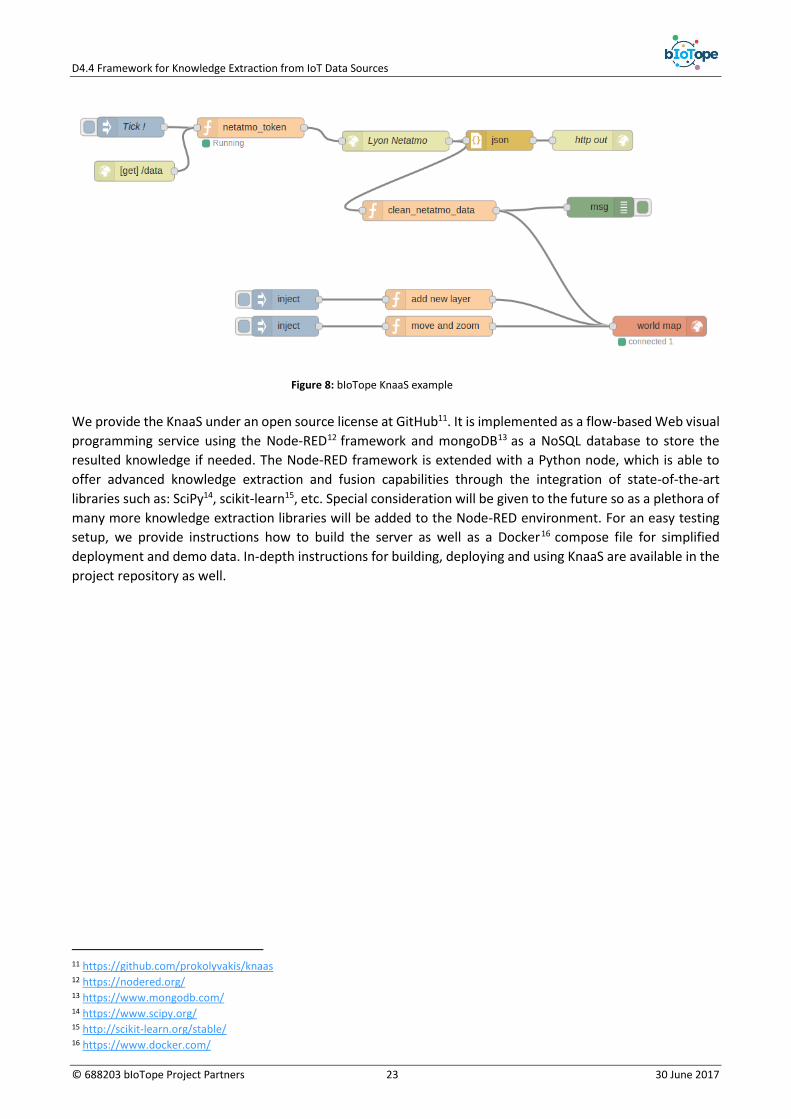
In Figure 8 there is an example of the visual and user-friendly interface that the KnaaS will provide. KnaaS
provides capabilities for knowledge extraction from heterogeneous data sources. It is currently designed to
be installed as a stand-alone server on the Web, exposing its services as REST endpoints. However, if sensitive
information should be processed, operating a public KnaaS server may raises security or privacy concerns.
Therefore, it is also possible to run KnaaS within the premises of, e.g., the user Jeremy. In the future we also
plan to integrate KnaaS’s functionality with the capabilities of O-MI nodes so that they can directly deal with
data and avoid privacy, security or performance problems. In addition, the integration of O-MI nodes has
already implemented10 and the full functionality of KnaaS, together with examples, will be provided in next
release. With regard to the AUCS (Artificial Use Case Scenario) introduced in section 3.1, a user is able to (a)
access data available in the Web through e.g., an O-MI query, a SPARQL query, etc., to (b) fuse them and
extract knowledge out of them through pre-custom nodes and/or by writing his/her own custom functions in
JavaScript or Python, and finally to (c) harvest the resulted knowledge. Last but not least, the user is able to
markup the resulted knowledge, and encode it in an O-DF message if resulted knowledge will be exposed in
the bIoTope ecosystem.
10 https://github.com/skubler/Node-Red-OMI and https://github.com/skubler/Node-Red-ODF
In this deliverable, we demonstrated the core knowledge extraction and data fusion mechanisms of the Knowledge Extraction Framework. We provide a prototypical implementation of the Knowledge Extraction Framework in the frame of Knowledge as a Service provisioning and outline how it can be integrated with existing services in the bIoTope ecosystem. For the purpose of demonstrating the strengths of the bIoTope’s KnaaS framework and helping the readers understand the proposed approach, different scenarios of Heat Wave Mitigation Pilot Use Case of the Urban Community of Lyon were examined and implemented in the frame of KnaaS. Our immediate next steps will concentrate on extending further the reasoning and fusing mechanisms of the Knowledge Extraction Framework and provide more advanced capabilities in a user-friendly way based on the visual programming principles that the KnaaS implementation was based. Additionally, special consideration will be given to the efficient handling of the semantic annotations within the O-MI/O-DF messages based on the new extended O-DF messages with semantics achieved by the coordinated work among WP3, WP4 and WP5. Last but not least, we will work on ameliorating the interactions with other bIoTopes’ components towards realizing a sustainable bIoTope ecosystem.
D4.4 Framework for Knowledge Extraction from IoT Data Sources
[1] J. Mineraud, O. Mazhelis, X. Su, and S. Tarkoma, “A gap analysis of Internet-of-Things platforms,” Comput. Commun., vol. 89, pp. 5–16, 2016.
[2] K. Framling, S. Kubler, and A. Buda, “Universal Messaging Standards for the IoT From a Lifecycle Management Perspective,” IEEE Internet Things J., vol. 1, no. 4, pp. 319–327, Aug. 2014.
[3] The Open Group, “Open Messaging Interface (O-MI), an Open Group Internet of Things (IoT) Standard - C14B.” [Online]. Available: https://www2.opengroup.org/ogsys/catalog/C14B. [Accessed: 21-Feb-2017].
[4] The Open Group, “Open Data Format (O-DF), an Open Group Internet of Things (IoT) Standard.” [Online]. Available: http://www.opengroup.org/iot/odf/index.htm. [Accessed: 21-Feb-2017].
[5] I. F. Akyildiz, Weilian Su, Y. Sankarasubramaniam, and E. Cayirci, “A survey on sensor networks,” IEEE Commun. Mag., vol. 40, no. 8, pp. 102–114, Aug. 2002.
[6] M. Wang et al., “City Data Fusion:,” Int. J. Distrib. Syst. Technol., vol. 7, no. 1, pp. 15–36, Jan. 2016. [7] J. Hintikka, “Knowledge and belief: an introduction to the logic of the two notions,” 1962. [8] G. Bonanno, “Information, knowledge and belief,” Bull. Econ. Res., 2002. [9] P. Battigalli and G. Bonanno, “Recent results on belief, knowledge and the epistemic foundations of
game theory,” Res. Econ., 1999. [10] A. Doyle, “The Annotated Sherlock Holmes (Vol. 1),” I (New York, 1967), 1967. [11] M. Raskino, J. Fenn, and A. Linden, “Extracting Value From the Massively Connected World of 2015.
Gartner Research, 1 April 2005.” . [12] C. Perera, C. H. Liu, and S. Jayawardena, “The Emerging Internet of Things Marketplace From an
Industrial Perspective: A Survey,” IEEE Trans. Emerg. Top. Comput., vol. 3, no. 4, pp. 585–598, Dec. 2015.
[13] R. Joshi and A. C. (Arthur C. . Sanderson, Multisensor fusion : a minimal representation framework. World Scientific, 1999.
[14] A. Zaslavsky, A. Zaslavsky, C. Perera, and D. Georgakopoulos, “Sensing as a Service and Big Data.” [15] S. Sobolevsky et al., “Scaling of City Attractiveness for Foreign Visitors through Big Data of Human
Economical and Social Media Activity,” in 2015 IEEE International Congress on Big Data, 2015, pp. 600–607.
[16] D. L. Hall and J. Llinas, “An introduction to multisensor data fusion,” Proc. IEEE, vol. 85, no. 1, pp. 6–23, 1997.
[17] E. F. Nakamura, A. A. F. Loureiro, and A. C. Frery, “Information fusion for wireless sensor networks,” ACM Comput. Surv., vol. 39, no. 3, p. 9–es, Sep. 2007.
[18] A. N. Shulsky and G. J. Schmitt, Silent warfare : understanding the world of intelligence. Brassey’s, Inc, 2002.
[19] J. R. Boyd, “A discourse on winning and losing. Maxwell Air Force Base, AL: Air University,” Libr. Doc. No. MU, vol. 43947, p. 79, 1987.
[20] O. E. Drummond, “Methodologies for performance evaluation of multitarget multisensor tracking,” 1999, pp. 355–369.
[21] H. Fourati and K. Iniewski, Multisensor data fusion : from algorithms and architectural design to applications. .
[22] E. Blasch and S. Plano, “DFIG Level 5 (User Refinement) issues supporting Situational Assessment Reasoning,” in 2005 7th International Conference on Information Fusion, 2005, pp. xxxv–xliii.
[23] E. P. Blasch and S. Plano, “JDL level 5 fusion model: user refinement issues and applications in group tracking,” 2002, pp. 270–279.
[24] E. Blasch, E. Bosse, and D. A. Lambert, High-level information fusion management and systems design. Norwood, MA: Artech House, 2012.
[25] M. E. Liggins, D. L. (David L. Hall, and J. Llinas, Handbook of multisensor data fusion : theory and practice. CRC Press, 2009.
[26] M. Kumar, D. P. Garg, and R. A. Zachery, “A generalized approach for inconsistency detection in data fusion from multiple sensors,” in 2006 American Control Conference, 2006, p. 6 pp.
[27] P. Smets and Philippe, “Analyzing the combination of conflicting belief functions,” Inf. Fusion, vol. 8,
D4.4 Framework for Knowledge Extraction from IoT Data Sources
no. 4, pp. 387–412, Oct. 2007. [28] R. P. S. Mahler, “Statistics 101 for multisensor, multitarget data fusion,” IEEE Aerosp. Electron. Syst.
Mag., vol. 19, no. 1, pp. 53–64, Jan. 2004. [29] D. Smith and S. Singh, “Approaches to Multisensor Data Fusion in Target Tracking: A Survey,” IEEE
Trans. Knowl. Data Eng., vol. 18, no. 12, pp. 1696–1710, Dec. 2006. [30] Yunmin Zhu, Enbin Song, Jie Zhou, and Zhisheng You, “Optimal dimensionality reduction of sensor data
in multisensor estimation fusion,” IEEE Trans. Signal Process., vol. 53, no. 5, pp. 1631–1639, May 2005. [31] B. L. Milenova and M. M. Campos, “Mining high-dimensional data for information fusion: a database-
centric approach,” in 2005 7th International Conference on Information Fusion, 2005, p. 7 pp. [32] B. Khaleghi, A. Khamis, F. O. Karray, and S. N. Razavi, “Multisensor data fusion: A review of the state-
of-the-art,” Inf. Fusion, vol. 14, no. 1, pp. 28–44, 2013. [33] F. Sheridan, “A survey of techniques for inference under uncertainty,” Artif. Intell. Rev., 1991. [34] H. Durrant-Whyte and T. Henderson, “Multisensor data fusion,” Springer Handb. Robot., 2016. [35] L. Zadeh, “Fuzzy sets,” Inf. Control, 1965. [36] F. Karray and C. De Silva, “Soft computing and intelligent systems design: theory, tools, and
applications,” 2004. [37] C. Negoita, L. Zadeh, and H. Zimmermann, “Fuzzy sets as a basis for a theory of possibility,” Fuzzy sets
Syst., 1978. [38] Z. Pawlak, “Rough sets: Theoretical aspects of reasoning about data,” 2012. [39] G. Shafer, “A mathematical theory of evidence,” 1976. [40] L. Bottou and Leon, “From machine learning to machine reasoning,” Mach. Learn., vol. 94, no. 2, pp.
133–149, Feb. 2014. [41] R. Kohavi and F. Provost, “Glossary of terms,” Mach. Learn., vol. 30, no. 2–3, pp. 271–274, 1998. [42] A. Munoz, “Machine Learning and Optimization,” URL https//www. cims. nyu. edu/~
munoz/files/ml_optimization. pdf [accessed 2016-03-02][WebCite Cache ID 6fiLfZvnG], 2014. [43] I. Pratt-Hartmann, “First-Order Mereotopology,” in Handbook of Spatial Logics, Dordrecht: Springer
Netherlands, 2007, pp. 13–97. [44] V. N. Vapnik, The nature of statistical learning theory. Springer, 2000. [45] X. Wu et al., “Knowledge Engineering with Big Data,” IEEE Intell. Syst., vol. 30, no. 5, pp. 46–55, Sep.
2015. [46] Xindong Wu, Xingquan Zhu, Gong-Qing Wu, and Wei Ding, “Data mining with big data,” IEEE Trans.
Knowl. Data Eng., vol. 26, no. 1, pp. 97–107, Jan. 2014. [47] J. Bergstra, O. Breuleux, and F. Bastien, “Theano: A CPU and GPU math compiler in Python,” Proc. 9th
Python, 2010. [48] T. Schaul, J. Bayer, D. Wierstra, Y. Sun, and M. Felder, “PyBrain,” Mach. Learn. …, 2010. [49] F. Pedregosa, G. Varoquaux, and A. Gramfort, “Scikit-learn: Machine learning in Python,” Mach. Learn.
…, 2011. [50] J. Demšar, B. Zupan, G. Leban, and T. Curk, “Orange: From experimental machine learning to interactive
data mining,” Princ. Data Min. …, 2004. [51] S. Sonnenburg, S. Henschel, C. Widmer, and J. Behr, “The SHOGUN machine learning toolbox,” Mach.
Learn. …, 2010. [52] D. King, “Dlib-ml: A machine learning toolkit,” J. Mach. Learn. Res., 2009. [53] U. M. Fayyad, A. Wierse, and G. G. Grinstein, Information visualization in data mining and knowledge
discovery. Morgan Kaufmann, 2002. [54] A. J. and R. C. Andrejs Abele, John P. McCrae, Paul Buitelaar, “Linking Open Data cloud diagram 2017.”
[Online]. Available: http://lod-cloud.net/.
D4.4 Framework for Knowledge Extraction from IoT Data Sources