27
Five In-depth Technology and Architecture Sessions on Data Virtualization Session 2: Performance
| Date post: | 18-Jul-2015 |
| Category: |
Data & Analytics |
| Upload: | denodo |
| View: | 181 times |
| Download: | 0 times |

Five In-depth Technology and Architecture Sessions on Data Virtualization
Session 2: Performance

Today’s Speaker
■ Paul Moxon
Senior Director, Product Management

Architect-to-Architect Series
■ Series of five webinars over next 2 months
■ Deeper look into Denodo Platform
■ Architectural Overview
■ Performance (today’s session)
■ Scalability
■ Data Discovery and Governance
■ Security

Denodo Express
■ Denodo Express
■ Free to Download
■ Fully functioning Data Virtualization Platform
■ Single user, supports common data sources
■ Many of the same capabilities of Denodo Platform
■ Performance, Data Discovery, Governance, internal Security, Publishing, …
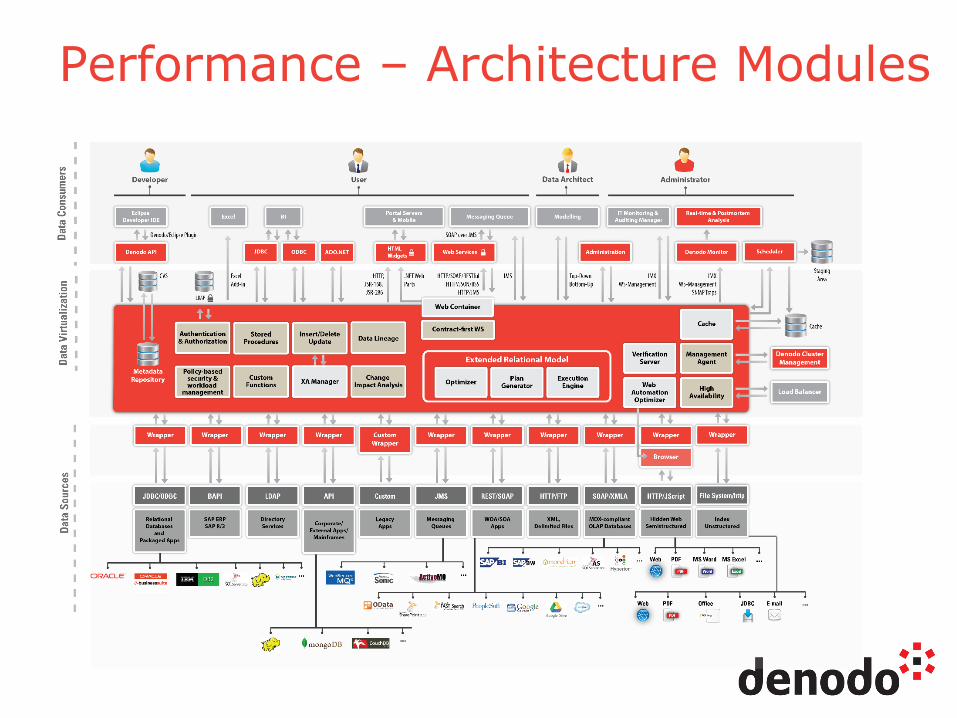
Performance – Architecture Modules
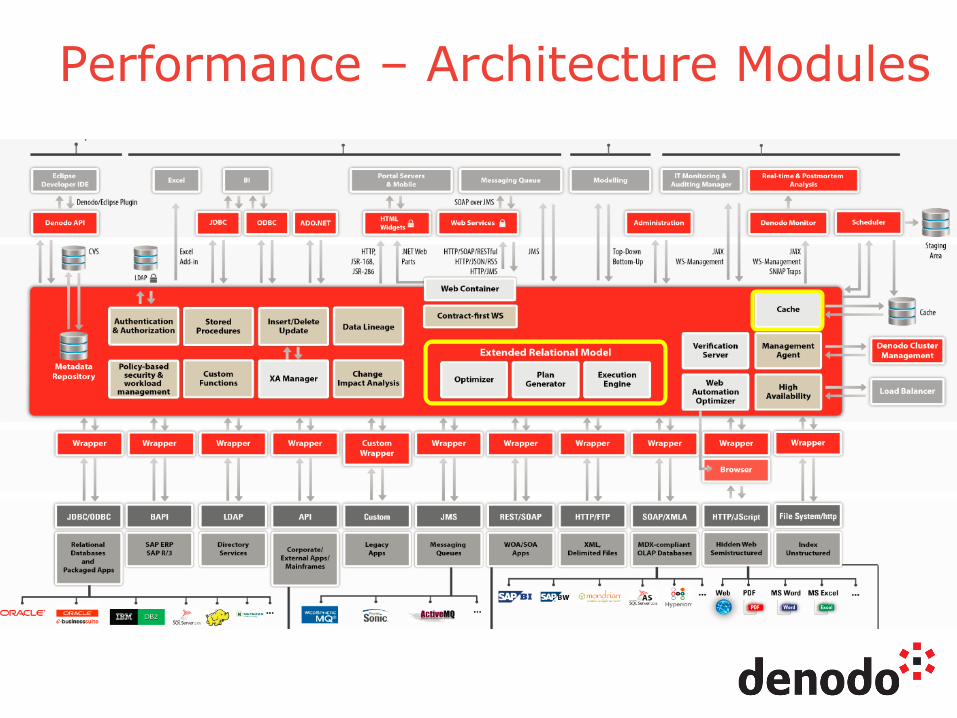
Performance – Architecture Modules

Performance – Optimizer, etc.
■ Optimizer
■ The Optimizer applies state-of-the-art optimization techniques to relational and non-relational sources.
■ Query Plan Generator
■ The Plan Generator is in charge of generating possible execution plans for the query and selecting the optimum one.
■ Execution Engine
■ Responsible for executing the selected query plan, executing the necessary sub-queries on the sources (or collecting data from cache as appropriate) and integrating the results to generate the global response.

Performance Optimization
■ Advanced Query Optimization
■ Cost and Source Constraint Based Query Plans
■ Query Delegation
■ Automatic Query Rewriting
■ Join Optimizations
■ Data Movement
■ Asynchronous Multi-threaded Processing
■ Server Throttling Mechanisms
■ Scalability
■ Caching
■ Multiple configuration modes – full or partial

Static vs. Dynamic Optimization
■ Static optimization
■ Takes place before query is executed
■ Rewrite query in more optimal way
■ Push-down delegation
■ Optimize query by – where possible – pushing down sub-trees to underlying data source
■ Delegate functions to underlying data source
■ Dynamic optimization
■ Use statistics and indices to estimate costs of alternative execution plans
■ Select Join methods and Join ordering

Cost-based Optimization
■ Objective – select best execution method for each operation
■ Estimate query costs based on:
■ View statistics
■ No. of rows, row size, for each field: max value, min value, no. of different values, …
■ View indices
■ Available indices, type of indices (clustered, hash, …)
■ Data source I/O information
■ Block size, blocks/read operation, data transfer rate, …

Source Constraint Optimization
■ Denodo Platform optimization has to work across multiple diverse data source types
■ Not just relational databases
■ Not all data sources have same capabilities
■ Recognize and optimize for constraints in underlying data sources
■ e.g. MySQL can be ordered for Merge join…but a delimited file cannot

Statistics Gathering

Query Delegation
■ Objective – Push the processing to the data
■ Utilize power and optimizations of underlying data sources
■ Especially relational databases and data warehouses
■ Minimize expensive data movement
■ Delegation mechanisms
■ Vendor specific SQL dialect
■ Function delegation
■ Configurable by data source
■ Delegate SQL operations
■ e.g. Join, Union, Group By, Order By, etc.

Automatic Query Rewriting
■ Objective – Rewrite query in a more optimal manner before the query is executed
■ Static optimization technique
■ Typical optimizations:
■ Simplify partitioned unions
■ Remove redundant sub-views
■ Transform outer joins to inner joins
■ Static join reordering to maximize delegation

Simplify Partitioned Unions
Select * from Sales_Product where region=‘NA'
North America
EMEA
Sales_NA Product_EMEA
North America
Product_NA
EMEA
Sales_EMEA
U U
|><|
S S S S
region=‘NA' region=‘NA' region=‘EMEA' region=‘EMEA'
Join cannot be delegated

Simplify Partitioned Unions (Cont’d)
Select * from Sales_Product where region=‘NA'
North America
Sales_NA
North America
Product_NA
U U
|><|
S S
region=‘NA' region=‘NA'
Join can be delegated

Transform Outer Joins to Inner Joins
As a.iinc_id = c.pinc_id ∴ c.pinc_id cannot be null
DS2
internet_inc
DS3
phone_inc
DS1
Internet_inc
||><|
|><|
S
b c
a.iinc_id = c.pinc_id
a
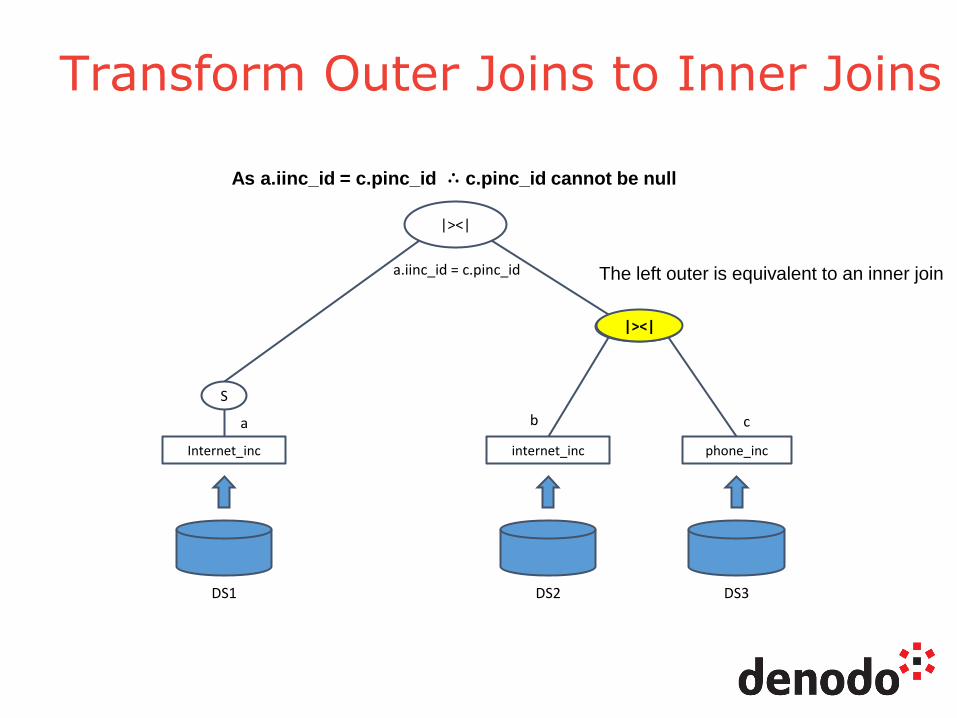
Transform Outer Joins to Inner Joins
As a.iinc_id = c.pinc_id ∴ c.pinc_id cannot be null
DS2
internet_inc
DS3
phone_inc
DS1
Internet_inc
||><|
|><|
S
b c
a.iinc_id = c.pinc_id
a
The left outer is equivalent to an inner join
|><|

Join Optimizations
■ Multiple Join options:
■ Merge
■ Nested
■ Nested Parallel
■ Hash
■ Optimizer automatically selects based on statistics and source capabilities
■ e.g. when using databases joining two large datasets, Merge Join is preferred
■ e.g. if one dataset is significantly larger, use Nested Join

Join Optimizations (Cont’d)
■ You can override the optimizer

Data Movement
■ Typically used when one dataset is significantly smaller and aggregations performed on joined data
1. Execute query in DS1 and fetch its data
2. Create a temporary table in DS2 and insert data from step 1
3. When step 2 is completed, execute the JOIN in DS2 and return the results to the DV layer
DS1
DS2

Query Plans
■ Optimizer calculates cost of multiple plans and selects ‘best’ plan
■ Cost estimates:
1. Traverse query tree top-down looking for ‘interesting’ patterns
• e.g. ‘GROUP BY region’ can execute faster if rows arrive ordered by ‘region’
2. Estimate costs of sub-queries on data sources
• Use source statistics and constraints
3. Traverse tree bottom-up to calculate costs for each node
• Choose execution with minimum cost
• Remember ‘interesting’ patterns (overall cost vs. node cost)

Other Optimization Techniques
■ Asynchronous Multi-threaded Processing
■ Execute multiple queries in parallel
■ Server Throttling Mechanisms
■ Controls to limit concurrency
■ Waiting queues for inbound connections
■ Connection pools for data sources
■ Swapping data to disk to handle large datasets

Caching
■ Caching – for slow sources and protect operational data sources
■ Caching enabled at view level
■ Enables mixed mode query plans
■ Caching modes
■ Full – all data in cache
■ Partial – query-by-query
■ Manual refresh or automated refresh

Q&A

Data Virtualization – Next Steps
Move forward at your own pace
Download Denodo Express –
The fastest way to Data Virtualization
Denodo Community: Documents, Videos, Tutorials, more.
Attend Architect-to-Architect Series
Performance
Scalability
Move forward with one of our Data Virtualization experts
Phone: (+1) 877-556-2531 (NA)
Phone: (+44) (0)20 7869 8053 (EMEA)
Email: [email protected] | www.denodo.com
Data Discovery and Governance
Security

Five In-depth Technology and Architecture Sessions
on Data Virtualization
Thank You!
Next Session Session 3
Denodo Platform: Scalability

















